由浅入深:Stable-Diffusion 原理解析01 —— 基本概念的介绍
由浅入深:Stable-Diffusion 原理解析01 —— 基本概念的介绍
基于最近一段时间的学习,对Stable-Diffusion大模型也有了一定程度的理解。而网络上的信息比较碎片化,直接上手论文又较难理解,本文旨在帮助那些刚上手SD模型,并且想要进一步了解模型的用户。
如果对您有所帮助,希望多多支持!
1. 什么是Stable Diffusion?它是怎么组成的?

Stable Diffusion就是一种深度学习模型(后文简称SD模型)。它是由几个模块组成的
Text Encoder
这一部分的主要功能是,把提示词(prompt)转化成计算机能够理解的一种数学表示,是一种 Clip 模型,此模型在后面系列中会重点介绍,本文只做功能上的诠释。输入的提示词最终能够生成图像,肯定离不开AI对提示词的“理解”,而 Clip 就是一种能够支持多模态输入的语言模型。
需要注意的是,在谷歌的 Imagen 模型中提到,语言模型比图像生成模型更关键
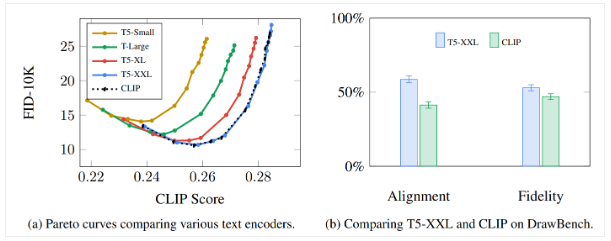
Imagen 是由谷歌公司提出的一种 txt2img 的 Diffusion 模型,它和Stable在根本原理上大体一致,都是一种扩散(Diffusion)模型。本文的后面会介绍不同扩散模型之间的区别。从商业角度来讲,SD模型是开源的,而Imagen是闭源的,我们无法了解更详细的信息。
Image Information Creator
在获得了提示词等条件后,SD模型需要根据这些提示词抽象成的数学信息,来对一张随机的图(它看起来只是纯随机的像素点,也称为噪声noise)进行一些“改变”,最终得到一个结果。而这个“改变”的过程,我们使用的方法是“扩散(Diffusion)”,这也就扩散模型这个名字的由来。当然,整个扩散模型过程实际上很复杂,也有许多优化的地方,在本系列后面的文章中会对于扩散模型的数学推导和实现进行详细介绍。
图像信息创建器(Image Information Creator)是整个SD模型的核心所在,也是它的性能比其他模型更好的关键所在。从技术角度来说,它由UNet神经网络和调度算法组成,在本系列后面的文章中也会进行详细介绍。
Image Decoder
在经过上述过程,得到了一个结果之后,利用图像解码器,将结果图像(一种低维度的信息)转化为最终生成的图像。
这里的 Decoder 模型只会运行一次,将潜空间(latent space)的图(4*64*64)转化为人眼能够欣赏的 RGB 的图像(3*512*512)(这里默认生成一张512*512大小的图)
2. 扩散模型(Diffusion model)

扩散模型是一种深度学习模型,它是一种生成式模型。它的灵感来源于非平衡热力学。它定义了一个扩散步骤的马尔科夫链(当前状态只与上一状态有关),具体来说,需要先进行前向扩散,逐步在真实数据样本中添加噪声,然后学习反向扩散(逆扩散)过程,从噪声中构建所需的数据样本。
具体的扩散过程中含有许多优美的数学推导,也进行了一系列的假设,在后续系列介绍扩散模型的数学原理时,会单独进行分享。
以下是扩散的过程:
前向扩散(Forward diffusion)
前向扩散就是将高斯噪声加入到用来训练的图像中,让它的图像特征逐渐减弱,分布更加符合高斯分布。图像的有序性和规律性会随着噪声的不断增加而越来越弱。

反向扩散 (Reverse diffusion)
反向扩散的前提是一张完全随机的高斯噪声,而为了最终能够得到一张我们想要的图片,我们需要知道图像中添加了多少的噪声。这就是扩散模型的关键所在:噪声预测器 noise predictor。科学家和工程师们使用大量的图片和数据来训练这样一个噪声预测器,最终得到一个能够预测噪音的工具。
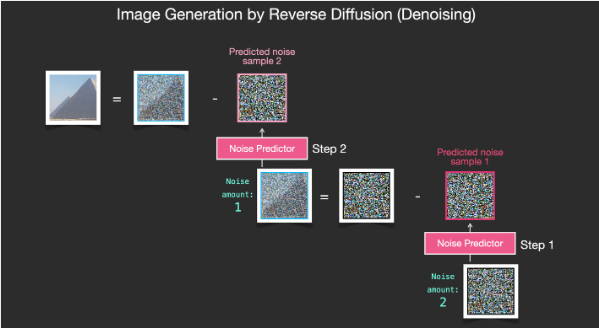
在 SD 模型中,深度学习使用 Unet神经网络。
SD模型在纯随机的噪声图片内,不断预测噪声,随后减去预测的部分,最终就可以得到一张图片。
噪声预测器是和训练的数据高度相关的,这是因为我们在训练时,让预测出来的噪声是倾向于接近“训练集内原始图片添加噪声后的结果”的。所以在图片中把预测出来的噪声减掉后,最后得到的清晰图片与训练集的原图有着相同的信息分布规律。
Stable Diffusion 模型的原理
接下来我们介绍 SD 模型,之前提到的扩散和预测等过程,本质上都是数学计算。
而目前来说,我们的独立计算机算力都是难以支持这些扩散模型的,而 SD 模型,主要就是解决了计算速度的问题。
潜在扩散模型(latent diffusion model)
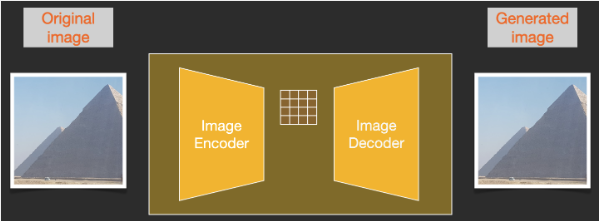
扩散模型的计算量较大,它的原因之一就在于图像本身过大。比如一张 512*512 的图片,访问一遍完整的图片(包括 RGB)都需要约78万的计算/访问次数,SD 模型可以将图像压缩在潜空间(latent space)中(4*64*64),相比于原空间,小了48倍,所以 SD 模型的计算速度可以提升许多。
但并不是所有的扩散模型都采取了类似的策略,比如前文提到的 Imagen 模型,就是在像素空间内进行计算,生成一个较小的图片,随后将图片重新放大到 512*512 的大小。
变分自编码器(VAE,Variantional Autoencoder)
对 SD 模型作图比较熟悉的可以了解,VAE 在图像生成时接近“滤镜”的效果,在效果层面作用不如Lora,而在原理上,VAE 就重要的多,它是 SD 可以将模型转化到潜空间的保障。
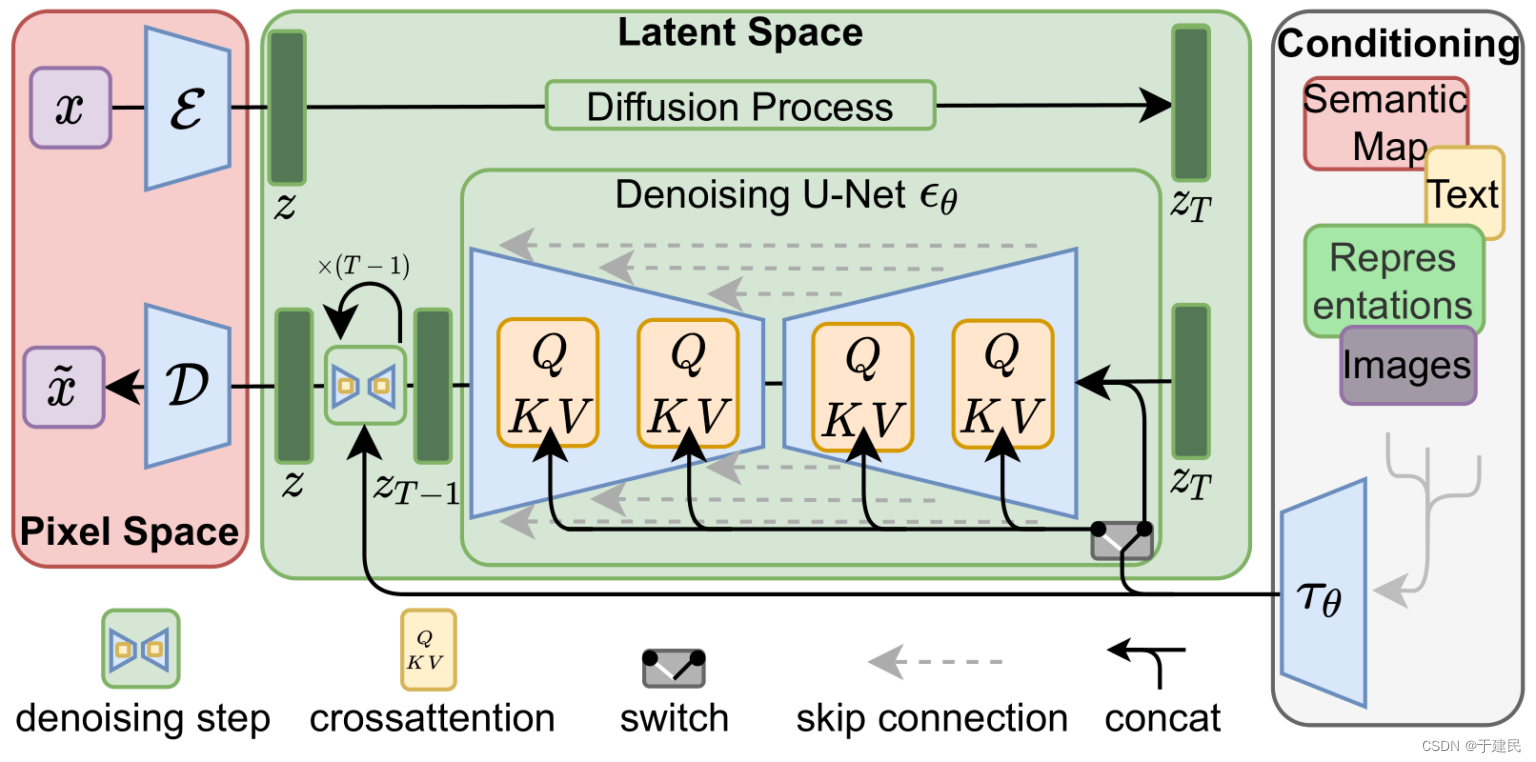
所以,SD 模型并没有在原本的像素空间内生成噪声去破坏训练图像,而是在潜空间内,用潜在噪声破坏“图像在潜空间的表示”
而把图像压缩为潜在空间而不会丢失信息,原因在于流形假设,它的含义是,在信息的高维空间表示中,往往存在着冗余,这也就意味着他们存在“被转化为低维空间信息表示同时不丢失太多信息”的机会。
就像如果用三维坐标去表示球面某个坐标,那么有太多的坐标属性都被浪费了,他们可能在球内可能在球外。无论如何,这种高维表示方法的信息密度较低,而生活的经验告诉我们,在地球上,只需要经度和纬度就可以表示一个球面的位置,此时信息的表示维度就降低了。
从深度学习的几何层面来说,它描述了自然界中,同一种类别的高维数据,往往可以集中在某个低维的某个流形结构里。
同时,还存在聚类假设,它描述了对于同一个类别的高维数据,在不同的子类中对应了低维空间中流形结构的不同概率分布,而机器学习可以通过这些概率分布之间的差别对子类进行区分
而深度学习本身就是从数据中学习这种流形结构和概率分布。同样还能得到一个结论,现实中,自然界的图像信息基本都符合流式分布,而不是随机的,无论是人脸还是花草树木,一切的图像特征都能在某个低维度的某个流形附近分布,所以我们可以通过深度学习的方式最终得到结果
提示条件的引入
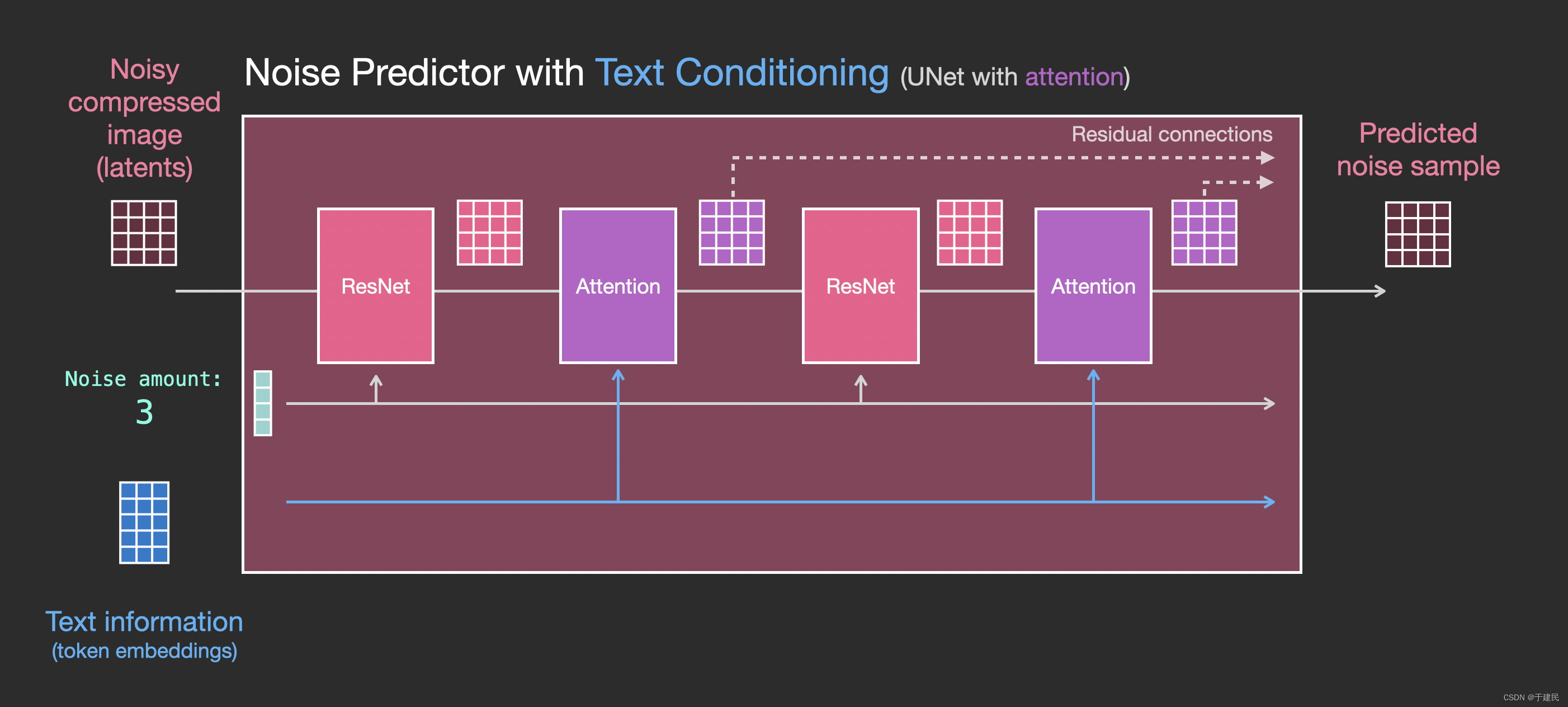
至此,本文已经基本介绍了 SD 模型的工作原理,但是仍未涉及 SD 模型的一个核心点 —— 提示词(Prompt),这部分主要侧重于工程和生产。
我们之前在扩散模型中,对于噪声预测器进行了介绍,而其实噪声预测器的输入除了步数,图片之外,还有提示词。
在 Clip 模型中,将每一个提示词固定在一个嵌入向量里。最后在文本转换器(Text transformer)内进一步处理嵌入,最后作为条件影响 noise perdictor
嵌入(Embedding)也是一个十分关键的机制,整个馈送的过程需要仔细阅读代码才可以完全理解,同时对此感兴趣可以阅读代码分析系列
Img2Img
SD 模型的另一核心功能,Img2Img,是 SDEdit 中首次提到的方法,它主要做的工作是,不是完全随机地在潜空间内生成一个高斯噪声,而是在输入图片本身添加一定的噪声,添加噪声的程度和设置的参数有关。
总结
至此,本文介绍了 SD 模型的基础流程和概念,本着互联网的开源精神做出技术分享。
因为篇幅受限,还有许多十分有价值的内容没有介绍。比如采样器(Sampler),超网络(HyperNetwork),Unet,Lora等。这些内容都会在后续的文章中,逐步深入地介绍。
希望对您有所帮助。
附录
参考文章:
- The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time. (jalammar.github.io)
- 【Stable Diffusion】之原理篇 - 知乎 (zhihu.com)
- [2006.11239] Denoising Diffusion Probabilistic Models (arxiv.org)
- 深入浅出讲解Stable Diffusion原理,新手也能看明白 - 知乎 (zhihu.com)
- [2205.11487] Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (arxiv.org)
- Stable Diffusion原理解读 - 知乎 (zhihu.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号