java并发编程(五)——线程池
线程池
什么是线程池
我们可以在不影响一个线程的情况下创建另一个线程去完成任务,这样可以提高执行效率。但是如果同一时刻有大量的任务需要执行,而这些任务又比较简单,那么每次都创建一个新的线程肯定会耗费很多时间。为了减少创建线程所花费的时间,人们想出了线程池的办法。线程池中预先创建了一定数量的线程,当需要线程执行任务时就从线程池中取,当任务执行完后,线程不会消亡,而是继续执行其它任务。
线程池的优点:
1、减少资源开销。不会每次都创建新线程,而是从线程池中取。
2、提高响应速度。线程已经提前创建好了,需要执行任务时直接用就可以了。
3、便于管理。线程是一种稀缺资源,如果不加以控制,不仅会浪费大量资源,而且可能影响系统的稳定性。使用线程池可以对线程的创建和停止,线程的数量加以控制,使线程处在可控的范围内,不仅便于管理,而且方便调优。
线程池的构成:一般来说线程池由下面几部分构成
1、核心线程。已经创建好的并处在运行状态的一定数量的线程,它们不断从阻塞队列中获取任务并执行。
2、阻塞队列。用来存储工作线程来不及处理的任务,当所有的工作线程都被占用后,之后的任务就会进入阻塞队列,等待某个线程执行完后才有机会被处理。
线程池的创建:创建线程池有两种方式
1、使用 ThreadPoolExecutor 类
2、使用 Executors 类
ThreadPoolExecutor
Excutor接口
ThreadPoolExecutor的顶层接口是 Excutor,Excutor接口位于 java.util.concurrent 包下,该接口中只提供了一个用于接收Runnable类型参数的方法excute(Runnabel task),用于接收一个任务。我们之前使用Thread类来创建线程并执行任务。但是在Excutor中我们可以这样创建一个线程并执行任务。
public class Demo implements Executor{ @Override public void execute(Runnable r) { r.run(); //既可以在execute方法中直接执行任务 new Thread(r).start(); //也可以新建一个线程去执行任务 } }
ExcutorService接口
ExcutorService 是一个比 Excutor 使用更广泛的子接口,提供了线程生命周期管理的方法。Excutor 中只有一个用于接收任务的excute方法,该方法没有返回值。而 ExcutorService 的submit()方法可以返回一个Future对象,用来获取任务的执行结果。ExcutorService 拓展了 Excutor,在开发中使用的更多。下面是两者的区别:
| Executor | ExecutorService |
|---|---|
| Executor 是 Java 线程池的核心接口,用来并发执行提交的任务 | ExecutorService 是 Executor 接口的扩展,提供了异步执行和关闭线程池的方法 |
| 提供execute()方法用来提交任务 | 提供submit()方法用来提交任务 |
| execute()方法无返回值 | submit()方法返回Future对象,可用来获取任务执行结果 |
| 不能取消任务 | 可以通过Future.cancel()取消pending中的任务 |
| 没有提供和关闭线程池有关的方法 | 提供了关闭线程池的方法 |
ThreadPoolExecutor
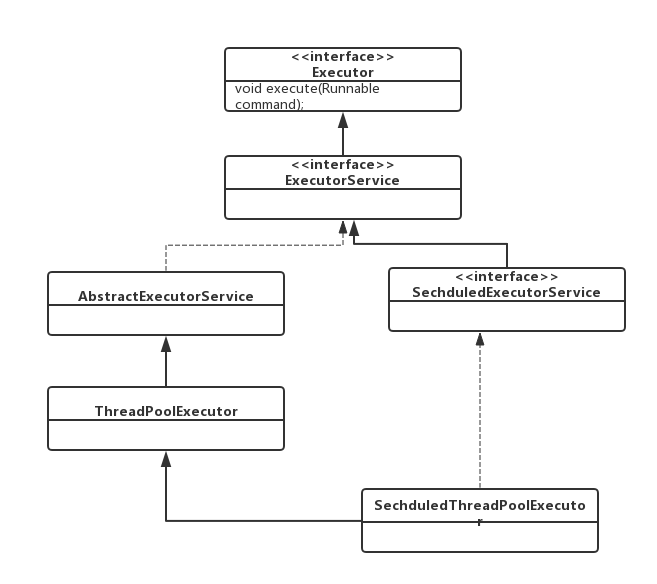
从上面的类图我们看到 ExcutorService 接口的实现类是 AbstractExecutorService,这是一个抽象类,而这个类的子类就是ThreadPoolExecutor。
创建线程池
我们可以通过ThreadPoolExecutor类的构造方法来创建线程池。这个类共有四个构造方法

public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; }
上面就是 ThreadPoolExecutor 类中的一个构造方法。该方法一共有七个参数:
- corePoolSize:线程池中核心线程的数目。当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有基本线程。
- maximumPoolSize:线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的救急线程执行任务。值得注意的是,如果使用了无界的任务队列这个参数就没什么效果。
- keepAliveTime:救急线程空闲后存活的时间。所以,如果任务很多,并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率。很多地方把 keepAliveTime 当做核心线程的存活时间,这是不完全的。JVM 中默认是不回收核心线程的,keepAliveTime 表示的是救急线程空闲后存活的时间。但是通过设置 allowCoreThreadTimeOut,也可以让 JVM 回收空闲后的核心线程。allowCoreThreadTimeOut 默认为 false,不回收核心线程。
- unit:救急线程存活的时间单位。
- workQueue:任务队列。用来保存等待执行的任务的阻塞队列。
- threadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字。
- handler:饱和策略。当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。

提交任务
通过构造方法创建了线程池之后,可以使用execute()和submit()向线程池中提交任务,这两个方法都是接收 Runnabel 类型的参数,当然,submit() 比 execute() 功能更多。
execute方法用于不需要返回值的任务,所以无法判断任务是否被线程池执行成功。(之后还会讲到其他的方式提交任务)
threadsPool.execute(new Runnable() { @Override public void run() { // TODO Auto-generated method stub } });
submit 方法会返回一个 Future 对象。通过这个对象可以判断任务是否执行成功,并且通过 Future 的 get() 可以获取返回值。下面是 get 方法的实现
public V get() throws InterruptedException, ExecutionException { int s = state; // 只要状态值小于 COMPLETING, 就说明任务还未完成, 去等待完成 if (s <= COMPLETING) s = awaitDone(false, 0L); // 只要等待完成, 再去把结果取回即可 return report(s); }
下面代码是使用submit执行任务,并获取任务的返回值
Future<Object> future = executor.submit(harReturnValuetask); try { Object s = future.get(); } catch (InterruptedException e) { // 处理中断异常 } catch (ExecutionException e) { // 处理无法执行任务异常 } finally { // 关闭线程池 executor.shutdown(); }
关闭线程池
可以通过线程池的 shutdown() 和 shutdownNow() 来关闭线程池。
shutdown():将线程池的状态设置为SHUTDOWN,然后中断所有没有执行任务的线程。
shutdownNow():将线程池的状态设置为STOP,然后中断所有线程并返回等待执行的任务列表。
线程池的状态
线程池使用 int 的高三位来存储线程池的状态,其它的位数用来存储线程的数量,这些信息用是原子变量 ctl 来进行存储的。之所以这么做是为了只进行一次 CAS 操作就可以既改变线程池的状态,又可以改变线程池中线程的数量。线程池共有五种状态:
1、RUNNING(运行状态):线程池被创建后就处于RUNNIG状态,接受新任务,并且也能处理阻塞队列中的任务。
2、SHUTDOWN(关闭状态):不接受新任务,但可以处理阻塞队列中的任务。
3、STOP(停止状态):中断正在执行的任务,并且抛弃阻塞队列的任务。
4、TIDYIDNG(整理状态):如果所有的任务都执行完了,线程池就会进入该状态。该状态会执行 terminated 方法进入TERMINATED。
5、TERMINATED(终止状态):执行完 terminated 方法后就会进入该状态,默认 terminated 方法什么也不做。
Excutors
通过 ThreadPoolExcutor 可以创建一个线程池,但是上面的方法有些复杂,方法的参数过多,给开发造成不必要的麻烦。所以在 JDK1.5 中就引入了一个工具类 Excutors,这个类提供了众多的工厂方法,可以更方便的方式创建线程池。下面是通过 Excutors 来创建线程池。
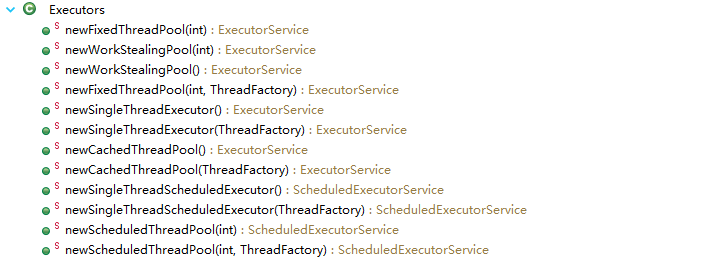
通过Executors可以创建四种线程池
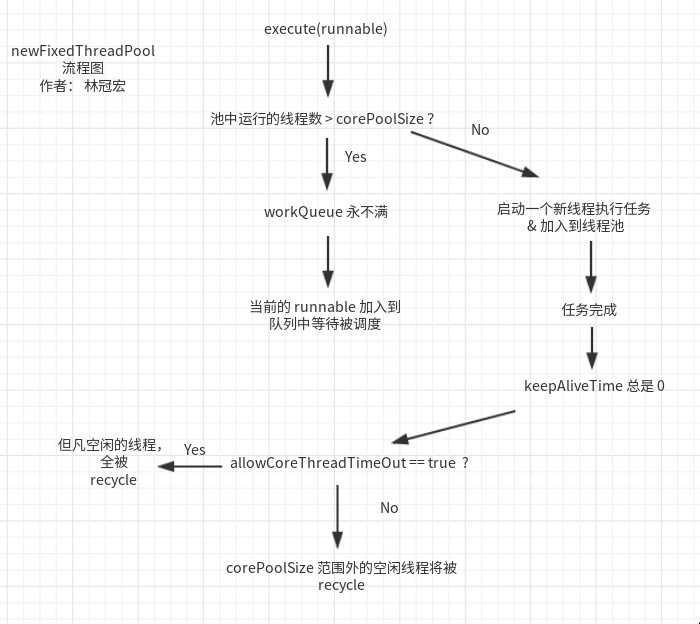
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads){ return new ThreadPoolExecutor( nThreads, // corePoolSize nThreads, // maximumPoolSize == corePoolSize 0L, // 空闲时间限制是 0 TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>() // 无界阻塞队列 ); }
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(), threadFactory); }
上面就是该方法的源码,可以看到,创建固定大小的线程池其实就是核心线程数等于最大工作线程数,阻塞队列是无界的。
import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class ThreadPool { public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(3);
for(int i=0; i<5; i++){ executor.submit(()->{ System.out.println("当前执行的线程是------>" + Thread.currentThread().getName()); }); } } } /* 当前执行的线程是------>pool-1-thread-1 当前执行的线程是------>pool-1-thread-2 当前执行的线程是------>pool-1-thread-3 当前执行的线程是------>pool-1-thread-1 当前执行的线程是------>pool-1-thread-2
线程不会被移除,程序不会结束 */
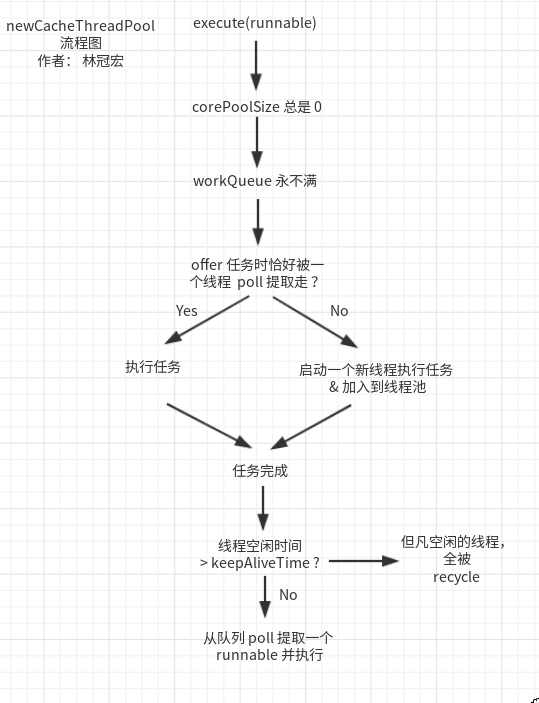
newCacheThreadPool
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, //核心线程数为0 60L, TimeUnit.SECONDS, //线程存活时间默认为60秒 new SynchronousQueue<Runnable>()); }
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>(), threadFactory); }
通过上面两个方法可以创建带缓存的线程池,该线程池核心线程数为 0,即每当有新任务提交时都会创建一个线程,最大线程数为 Integer.MAX_VALUE,该线程在空闲后默认存活时间为 60 秒。
源码的注释中给出了该方法的说明:
该方法的目的是创建一个线程池。
该线程池在前面的线程可用时将会重用之前的线程,否则则创建新的线程。
该线程池对执行短的异步任务性能提升很大。
调用execute函数如果之前构造的线程没有销毁(60s保活期,没任务超期销毁)则会重用之前的线程。
60秒内没被用过的线程将会被终止从线程池缓存中移除掉。
因此该线程池闲置时不会消耗任何资源。
带缓存的线程池相较于固定大小的线程池来说,核心线程为 0,每次有任务时会先检查是否有空闲线程,有的话就使用空闲线程,否则创建一个新的线程执行任务。当一个线程空闲 60s 后就会被移除,也就是线程池空闲后不会占用任何资源,而固定大小的线程池不会主动移除空闲后的核心线程。
import java.util.concurrent.*; public class ThreadPool { public static void main(String[] args) throws InterruptedException { ExecutorService executor = Executors.newCachedThreadPool(); for(int i=0; i<20; i++){ Thread.sleep(15000); executor.submit(()->{ System.out.println("当前执行的线程是------>" + Thread.currentThread().getName()); try { Thread.sleep(50000); } catch (InterruptedException e) { e.printStackTrace(); } }); } } } /* 当前执行的线程是------>pool-1-thread-1 当前执行的线程是------>pool-1-thread-2 当前执行的线程是------>pool-1-thread-3 当前执行的线程是------>pool-1-thread-4 当前执行的线程是------>pool-1-thread-1 当前执行的线程是------>pool-1-thread-2 当前执行的线程是------>pool-1-thread-3 当前执行的线程是------>pool-1-thread-4 当前执行的线程是------>pool-1-thread-1 当前执行的线程是------>pool-1-thread-2 当前执行的线程是------>pool-1-thread-3 当前执行的线程是------>pool-1-thread-4 当前执行的线程是------>pool-1-thread-1 当前执行的线程是------>pool-1-thread-2 当前执行的线程是------>pool-1-thread-3 当前执行的线程是------>pool-1-thread-4 当前执行的线程是------>pool-1-thread-1 当前执行的线程是------>pool-1-thread-2 当前执行的线程是------>pool-1-thread-3 当前执行的线程是------>pool-1-thread-4 Process finished with exit code 0 程序正常结束 */
newSingleThreadPool
public static ExecutorService newSingleThreadExecutor() { return new Executors.FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, //核心线程数为1,最大线程数为1 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); //使用无界队列,任务按照提交的顺序执行 }
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) { return new Executors.FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(), threadFactory)); }
用该方法可以创建一个单线程的线程池,该线程池中最多只有一个线程,所有任务串行的按照任务提交的顺序执行。如果该线程因为异常结束,线程池会再创建一个线程来代替。看起来 newSingleThreadPool 和 newFixedThreadPool(1) 没什么区别。
import java.util.concurrent.*; public class ThreadPool { public static void main(String[] args) { ExecutorService executor = Executors.newSingleThreadExecutor(); for (int i = 0; i < 20; i++) { executor.submit(() -> { System.out.println("当前执行的线程是------>" + Thread.currentThread().getName()); }); } } }
newScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); }
public static ScheduledExecutorService newScheduledThreadPool( int corePoolSize, ThreadFactory threadFactory) { return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory); }
public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, //最大线程数为Integer.MAX_VALUE new ScheduledThreadPoolExecutor.DelayedWorkQueue()); }
与上面有所不同,该方法的返回值是 ScheduledExecutorService。最大线程数为 Integer.MAX_VALUE。创建一个延时线程池后,调用 schedule 方法可以延时执行提交的任务。
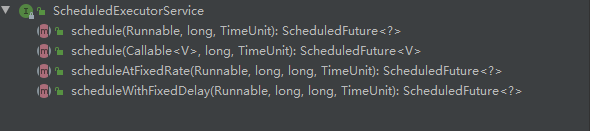
import java.util.concurrent.*; import static java.util.concurrent.TimeUnit.NANOSECONDS; public class ThreadPool { public static void main(String[] args) { ScheduledExecutorService executor = Executors.newScheduledThreadPool(3); for (int i = 0; i < 3; i++) { executor.schedule(() -> { System.out.println("当前执行的线程是------>" + Thread.currentThread().getName()); }, 3, TimeUnit.SECONDS); //每个创建的线程会等待3s再执行 } } }
阻塞队列
Java 中,队列包括阻塞队列和非阻塞队列。比如 PriorityQueue、LinkedList(LinkedList 是双向链表,它实现了Dequeue接口)这些都是非阻塞队列。使用非阻塞队列的时候有一个很大问题就是:它不会对当前线程产生阻塞,那么在面对类似消费者-生产者的模型时,就必须额外地实现同步策略以及线程间唤醒策略,这个实现起来就非常麻烦。但是有了阻塞队列就不一样了,它会对当前线程产生阻塞,比如一个线程从一个空的阻塞队列中取元素,此时线程会被阻塞直到阻塞队列中有了元素。当队列中有元素后,被阻塞的线程会自动被唤醒(不需要我们编写代码去唤醒)。这样提供了极大的方便性。
JDK中一共提供了提供了八种阻塞队列,它们都是 BlockingQueue 的直接或者间接实现类
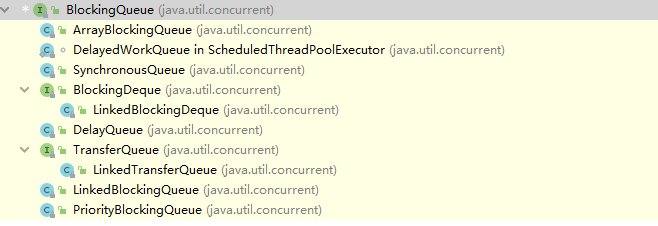
我们常用的阻塞队列如下表

阻塞队列和非阻塞队列中的常用方法
非阻塞队列中的几个主要方法
add(E e):将元素e插入到队列末尾,如果插入成功,则返回true;如果插入失败(即队列已满),则会抛出异常;
remove():移除队首元素,若移除成功,则返回true;如果移除失败(队列为空),则会抛出异常;
offer(E e):将元素e插入到队列末尾,如果插入成功,则返回true;如果插入失败(即队列已满),则返回false;
poll():移除并获取队首元素,若成功,则返回队首元素;否则返回null;
peek():获取队首元素,若成功,则返回队首元素;否则返回null。
对于非阻塞队列,一般情况下建议使用offer、poll和peek三个方法,不建议使用add和remove方法。因为使用offer、poll和peek三个方法可以通过返回值判断操作成功与否,而使用add和remove方法却不能达到这样的效果。注意,非阻塞队列中的方法都没有进行同步措施。
阻塞队列中的几个主要方法
阻塞队列包括了非阻塞队列中的大部分方法,上面列举的5个方法在阻塞队列中都存在,但是要注意这5个方法在阻塞队列中都进行了同步措施。除此之外,阻塞队列提供了另外4个非常有用的方法:
put(E e):向队尾存入元素,如果队列满,则等待;
take():从队首取元素,如果队列为空,则等待;
offer(E e,long timeout, TimeUnit unit):向队尾存入元素,如果队列满,则等待一定的时间,当时间期限达到时,如果还没有插入成功,则返回false;否则返回true;
poll(long timeout, TimeUnit unit):从队首取元素,如果队列空,则等待一定的时间,当时间期限达到时,如果取到,则返回null;否则返回取得的元素;
ArrayBlockingQueue
ArrayBlockingQueue 是数组实现的线程安全的有界的阻塞队列。
线程安全是指,ArrayBlockingQueue内部通过“互斥锁”保护竞争资源,实现了多线程对竞争资源的互斥访问。
有界是指,ArrayBlockingQueue对应的数组是有界限的。
阻塞队列是指,多线程访问竞争资源时,当竞争资源已被某线程获取时,其它要获取该资源的线程需要阻塞等待。
在创建ArrayBlockingQueue对象时必须制定容量大小。并且可以指定公平性与非公平性,默认情况下为非公平的,即不保证等待时间最长的队列最优先能够访问队列。
ArrayBlockingQueue原理
1、ArrayBlockingQueue继承于AbstractQueue,并且它实现了BlockingQueue接口。
2、ArrayBlockingQueue内部是通过 Object[] 数组保存数据的,也就是说ArrayBlockingQueue本质上是通过数组实现的。ArrayBlockingQueue的大小即数组的容量,是创建ArrayBlockingQueue时指定的。
3、ArrayBlockingQueue与ReentrantLock是组合关系,ArrayBlockingQueue中包含一个ReentrantLock对象(lock)。ReentrantLock是可重入的互斥锁,ArrayBlockingQueue就是根据该互斥锁实现“多线程对竞争资源的互斥访问”。而且,ReentrantLock分为公平锁和非公平锁,关于具体使用公平锁还是非公平锁,在创建ArrayBlockingQueue时可以指定;而且,ArrayBlockingQueue默认会使用非公平锁。
4、ArrayBlockingQueue与Condition是组合关系,ArrayBlockingQueue中包含两个Condition对象(notEmpty和notFull)。而且,Condition又依赖于ArrayBlockingQueue而存在,通过Condition可以实现对ArrayBlockingQueue的更精确的访问
某线程(线程A)要取数据时,数组正好为空,则该线程会执行notEmpty.await()进行等待;当其它某个线程(线程B)向数组中插入了数据之后,会调用notEmpty.signal()唤醒“notEmpty上的等待线程”。此时,线程A会被唤醒从而得以继续运行。
若某线程(线程H)要插入数据时,数组已满,则该线程会它执行notFull.await()进行等待;当其它某个线程(线程I)取出数据之后,会调用notFull.signal()唤醒“notFull上的等待线程”。此时,线程H就会被唤醒从而得以继续运行。
ArrayBlockingQueue源码
构造函数
//创建一个指定容量和默认访问策略(是否公平锁)的 ArrayBlockingQueue public ArrayBlockingQueue(int capacity) { this(capacity, false); } //创建一个指定容量和指定访问策略的 ArrayBlockingQueue public ArrayBlockingQueue(int capacity, boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = new Object[capacity]; lock = new ReentrantLock(fair); notEmpty = lock.newCondition(); notFull = lock.newCondition(); } //创建一个具有给定的(固定)容量和指定访问策略的 ArrayBlockingQueue //它最初包含给定 collection 的元素,并以 collection 迭代器的遍历顺序添加元素。 public ArrayBlockingQueue(int capacity, boolean fair, Collection<? extends E> c) { this(capacity, fair); final ReentrantLock lock = this.lock; lock.lock(); // Lock only for visibility, not mutual exclusion try { final Object[] items = this.items; int i = 0; try { for (E e : c) items[i++] = Objects.requireNonNull(e); } catch (ArrayIndexOutOfBoundsException ex) { throw new IllegalArgumentException(); } count = i; putIndex = (i == capacity) ? 0 : i; } finally { lock.unlock(); } }
1、 items是保存“阻塞队列”数据的数组。它的定义如下:

2、 fair 是“可重入的独占锁(ReentrantLock)”的类型。fair 为 true,表示是公平锁;fair 为 false,表示是非公平锁。 notEmpty 和 notFull 是锁的两个 Condition 条件。它们的定义如下:

Lock 的作用是提供独占锁机制,来保护竞争资源;而Condition是为了更加精细的对锁进行控制,它依赖于Lock,通过某个条件对多线程进行控制。 notEmpty表示“锁的非空条件”。当某线程想从队列中取数据时,而此时又没有数据,则该线程通过notEmpty.await()进行等待;当其它线程向队列中插入了元素之后,就调用notEmpty.signal()唤醒“之前通过notEmpty.await()进入等待状态的线程”。 同理,notFull表示“锁的满条件”。当某线程想向队列中插入元素,而此时队列已满时,该线程等待;当其它线程从队列中取出元素之后,就唤醒该等待的线程。
ArrayBlockingQueue 方法列表
// 将指定的元素插入到此队列的尾部(如果立即可行且不会超过该队列的容量),在成功时返回 true,如果此队列已满,则抛出 IllegalStateException。 boolean add(E e) // 自动移除此队列中的所有元素。 void clear() // 如果此队列包含指定的元素,则返回 true。 boolean contains(Object o) // 移除此队列中所有可用的元素,并将它们添加到给定 collection 中。 int drainTo(Collection<? super E> c) // 最多从此队列中移除给定数量的可用元素,并将这些元素添加到给定 collection 中。 int drainTo(Collection<? super E> c, int maxElements) // 返回在此队列中的元素上按适当顺序进行迭代的迭代器。 Iterator<E> iterator() // 将指定的元素插入到此队列的尾部(如果立即可行且不会超过该队列的容量),在成功时返回 true,如果此队列已满,则返回 false。 boolean offer(E e) // 将指定的元素插入此队列的尾部,如果该队列已满,则在到达指定的等待时间之前等待可用的空间。 boolean offer(E e, long timeout, TimeUnit unit) // 获取但不移除此队列的头;如果此队列为空,则返回 null。 E peek() // 获取并移除此队列的头,如果此队列为空,则返回 null。 E poll() // 获取并移除此队列的头部,在指定的等待时间前等待可用的元素(如果有必要)。 E poll(long timeout, TimeUnit unit) // 将指定的元素插入此队列的尾部,如果该队列已满,则等待可用的空间。 void put(E e) // 返回在无阻塞的理想情况下(不存在内存或资源约束)此队列能接受的其他元素数量。 int remainingCapacity() // 从此队列中移除指定元素的单个实例(如果存在)。 boolean remove(Object o) // 返回此队列中元素的数量。 int size() // 获取并移除此队列的头部,在元素变得可用之前一直等待(如果有必要)。 E take() // 返回一个按适当顺序包含此队列中所有元素的数组。 Object[] toArray() // 返回一个按适当顺序包含此队列中所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。 <T> T[] toArray(T[] a) // 返回此 collection 的字符串表示形式。 String toString()
入队操作
//offer(E e)的作用是将e插入阻塞队列的尾部。 //如果队列已满,则返回false,表示插入失败;否则,插入元素,并返回true。 public boolean offer(E e) { //判断e是否为空,如果为空则抛出NullPointerException Objects.requireNonNull(e); //获取锁 final ReentrantLock lock = this.lock; //可以通过可中断锁lock.lockInterruptibly()来设置超时等待 lock.lock(); try { //如果队列已满则返回false if (count == items.length) return false; else { //如果队列未满则入队 enqueue(e); return true; } } finally { lock.unlock(); } }
private void enqueue(E e) { //获取当前队列元素数组 final Object[] items = this.items; items[putIndex] = e; //将e插入队列 //如果插入e后队列满了,那么将下一次插入的索引设置为0 if (++putIndex == items.length) putIndex = 0; //队列中元素个数加一 count++; //唤醒noEmpty上等待的线程,如果有的话 notEmpty.signal(); }
count表示”队列中的元素个数“。除此之外,队列中还有另外两个遍历 takeIndex 和 putIndex。takeIndex 表示下一个被取出元素的索引,putIndex表 示下一个被添加元素的索引。它们的定义如下:

出队操作
public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == 0) notEmpty.await(); return dequeue(); } finally { lock.unlock(); } }
private E dequeue() { final Object[] items = this.items; @SuppressWarnings("unchecked") E e = (E) items[takeIndex]; items[takeIndex] = null; if (++takeIndex == items.length) takeIndex = 0; count--; if (itrs != null) itrs.elementDequeued(); notFull.signal(); return e; }
private E dequeue() { final Object[] items = this.items; E e = (E) items[takeIndex]; items[takeIndex] = null; //循环队列,如果到了队尾,那么从0开始取数据 if (++takeIndex == items.length) takeIndex = 0; //出队,总元素个数减一 count--; if (itrs != null) itrs.elementDequeued(); notFull.signal(); //唤醒notFull上等待的线程 return e; }
参考资料
Java中线程池ThreadPoolExecutor原理探究

 浙公网安备 33010602011771号
浙公网安备 33010602011771号