
福大软工1816 · 第五次作业 - 结对作业2
结对成员:031602631 苏韫月、031602147 郑愈明
博客链接:Github项目地址
附加题相关文件提取码:jbj4
具体分工
- 苏韫月:爬虫实现,论文列表爬取实现、附加题功能实现、WordCount基本函数功能实现
- 郑愈明:命令行参数功能实现、词组统计功能实现、单元测试、性能分析
代码规范
- 命名规范
- 变量——Camel形式;所有类型/类/函数名——Pascal形式。
- 类和函数名应根据各自的功能命名,要求一眼就知道是做什么的
- 注释规范
说明性文件头部注释 注释必须列出:内容、功能,头文件的注释中还应有函数功能简要说明。 /** * File name: // 文件名 * Description: // 说明此程序文件完成的主要功能 * Function List: // 主要函数列表,每条记录应包括函数名及功能简要说明 1. .... */源文件头部注释 源文件头部列出:模块功能、主要函数及功能。 /** * FileName: test.cpp * Description: // 模块描述 * Function List: // 主要函数及其功能 1. ------- */
- 书写风格规范
- 一行代码的长度不要超过VS2017的屏幕可显示范围(110个字符)
- 缩进采用VS2017默认格式
- 凡是用到{}的地方,要使“{”、“}”独占一行
- 不允许多条语句在同一行
- 有疑问的代码、测试用的代码段、函数之间、或者什么其他的地方,用注释/**/或//做出分割线,标注清楚功能、疑问、以后想要扩展的内容等等
- 短注释可以跟在一行代码后面,长的注释比如功能说明,要在函数前独占一块
- 不同的函数之间要有空行分割,函数内部功能相差较大的也要用空行分割
- 错误处理
- 文件处理要做好基本的排错处理
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 10 |
| • Estimate | • 估计这个任务需要多少时间 | 20 | 10 |
| Development | 开发 | 1340 | 1790 |
| • Analysis | • 需求分析 (包括学习新技术) | 180 | 360 |
| • Design Spec | • 生成设计文档 | 20 | 20 |
| • Design Review | • 设计复审 | 10 | 60 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| • Design | • 具体设计 | 60 | 60 |
| • Coding | • 具体编码 | 800 | 300 |
| • Code Review | • 代码复审 | 60 | 480 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 200 | 480 |
| Reporting | 报告 | 85 | 370 |
| • Test Repor | • 测试报告 | 30 | 320 |
| • Size Measurement | • 计算工作量 | 10 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 45 | 30 |
| | 合计 |1445|2170
二、需求分析
1.爬取论文信息
CVPR2018官网爬取今年的论文列表,输出到result.txt,内容包含论文题目、摘要,格式如下:
- 为爬取的论文从0开始编号,编号单独一行
- 两篇论文间以2个空行分隔
- 在每行开头插入“Title: ”、“Abstract: ”(英文冒号,后有一个空格)说明接下来的内容是论文题目,或者论文摘要
- 后续所有字符、单词、有效行、词频统计中,论文编号及其紧跟着的换行符、分隔论文的两个换行符、“Title: ”、“Abstract: ”(英文冒号,后有一个空格)均不纳入考虑范围
2.命令行参数进阶设定
- -i 参数设定读入文件的存储路径
- -o 参数设定生成文件的存储路径
- -w 参数设定是否采用不同权重计数
- 与数字 0|1搭配使用,0 表示属于 Title、Abstract 的单词权重相同均为 1 ;1 表示属于 Title 的单词权重为10,属于Abstract 单词权重为1。
- -m 参数设定统计的词组长度
- -m 参数与数字配套使用,用于设置词组长度
- -n 参数设定自定义词频统计输出的单词数量
- -n 参数与数字搭配使用,用于限制最终输出的单词(词组)的个数,表示输出频数最多的前[number]个单词(词组)
3. 多参数的混合使用
- 实际测试时,在一句命令行语句中
- -i 、-o 、-w 参数一定会出现
- -m、-n参数可能都不出现,可能只出现一个,也可能都出现
- 未出现-m参数时,不启用词组词频统计功能,默认对单词进行词频统计
- 未出现-n参数时,不启用自定义词频统计输出功能,默认输出10个
- 参数之间的顺序并不固定
4. 附加题
在博客中详细描述,并在博客中附件(.exe及.txt)为证。附加功能的加入不能影响上述基础功能的测试,分数取决于创意和所展示的完成度。
要求:发挥个人的奇思妙想,对论文列表进行更多的挖掘并进行数据分析,为你们举几个栗子:
- 从网站综合爬取论文的除题目、摘要外其他信息,如:论文类型、作者、作者单位等等
- 分析论文作者的所属地,哪些国家、哪些高校发表的论文比较多
- 分析论文列表中各位作者之间的关系,论文A的第一作者可能同时是论文B的第二作者,不同论文多位作者之间可能存在着联系
- 对数据的图形可视化做出一些努力,比如对上一条功能可以形成关系图谱
5.一些说明
以下为助教的补充说明:

三、解题思路描述与设计实现说明
1. 爬虫使用
本次爬取CVPR论文title和abstract的爬虫代码使用的是C++实现。
具体的流程图如下:

部分代码展示:
/*******************解析论文的HTML*********************/ bool Extract(int count, char * &response) { string httpResponse = response; stringstream ss; ss << count; string paper = ss.str() + "\r\n"; const char *p = httpResponse.c_str(); /****************************提取title*********************************/ char t[] = "papertitle\">\n"; char *tag = t; const char *pos = strstr(p, tag); pos += strlen(tag); const char * nextQ = strstr(pos, "<"); if (nextQ) { char * title = new char[nextQ - pos + 1]; sscanf(pos, "%[^<]", title); paper += "Title: "; paper += title; paper += "\r\n"; delete[] title; } /****************************提取abstract*********************************/ char t2[] = "abstract\" >\n"; char *tag2 = t2; const char *pos2 = strstr(p, tag2); pos2 += strlen(tag2); const char * nextQ2 = strstr(pos2, "<"); if (nextQ2) { char * abstract = new char[nextQ2 - pos2 + 1]; sscanf(pos2, "%[^<]", abstract); paper += "Abstract: "; paper += abstract; paper += "\r\n"; delete[] abstract; } ... ... /*******************解析助教提供的页面的论文的URL*********************/ void ParsepaperUrl(char * &response) { int bytes; int count = 0; string httpResponse = response; const char *p = httpResponse.c_str(); char t[] = "href=\""; char *tag = t; const char *pos = strstr(p, tag); while (pos) { pos += strlen(tag); const char * nextQ = strstr(pos, "\""); if (nextQ) { char * url = new char[nextQ - pos + 1]; sscanf(pos, "%[^\"]", url); if (strstr(url, "html")) { string paperUrl = "http://openaccess.thecvf.com/"; paperUrl += url; if (strstr(url, "\r\n1000\r\n")) { int pos = 0; while ((pos = paperUrl.find("\r\n1000\r\n")) != -1) { paperUrl.erase(pos, strlen("\r\n1000\r\n")); } } ... ...
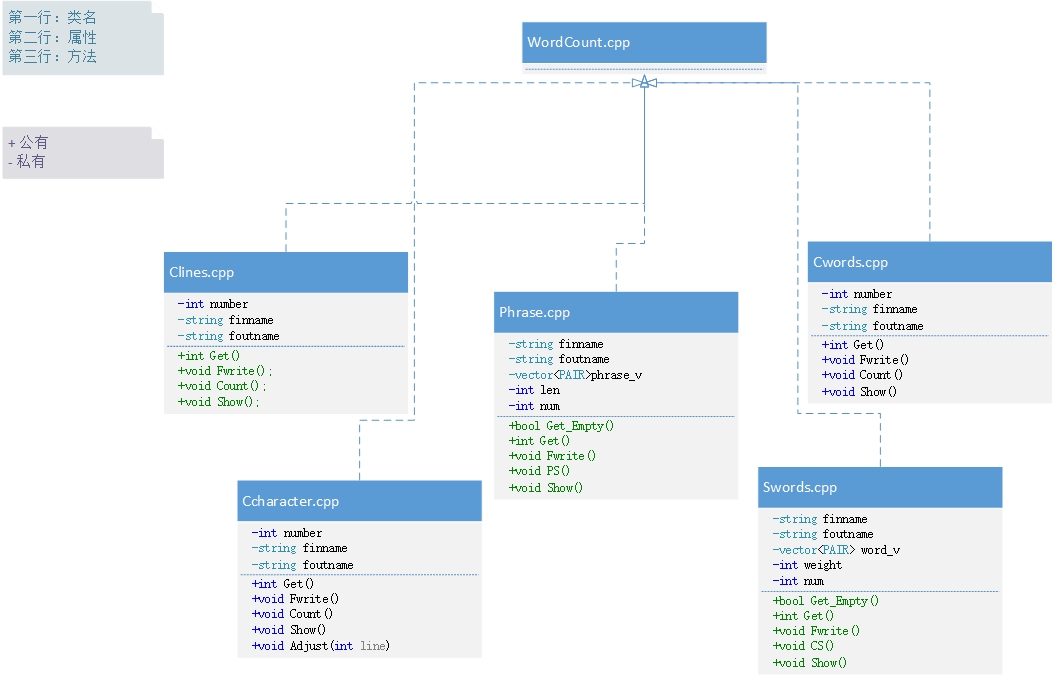
2. 代码组织与内部实现设计(类图)
3. 说明算法的关键与关键实现部分流程图
- 词组统计模块——对文件数据的处理
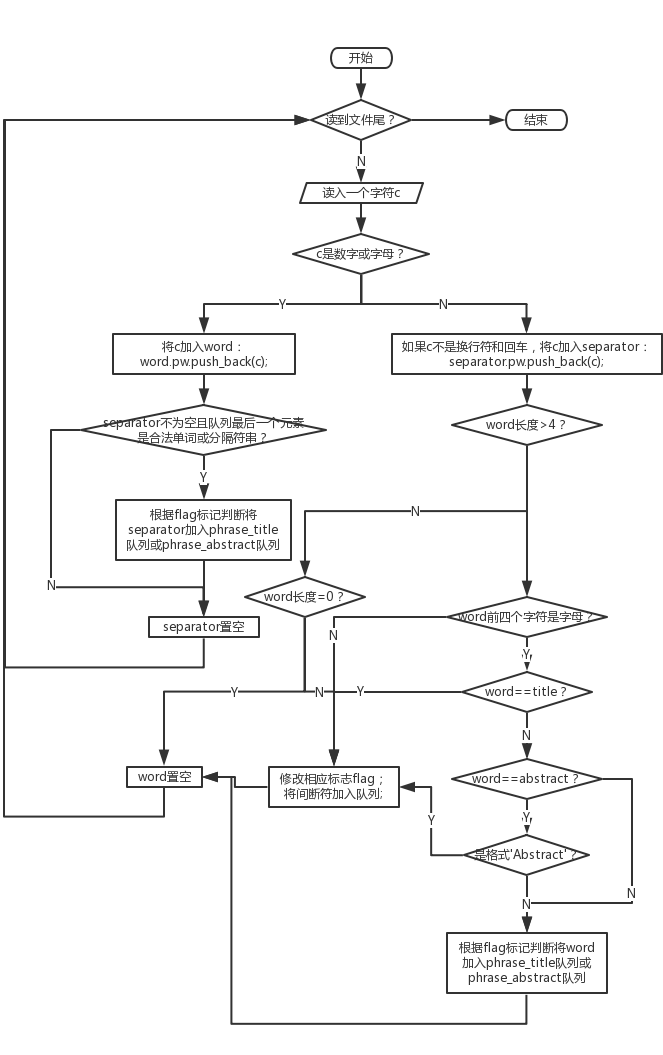
- 词组统计模块——词组判定及统计

四、附加题设计与展示
我们参考助教在附加题位置列出的文档格式,对数据进行进一步的爬取。
我们起先采用的也是C++ 实现,先将author和pdf_link的内容爬取下来。但是在助教提供的网址里根本找不到有关type的信息,因此我们历尽千辛万苦,终于在CVPR 2018 里找到了type。本来以为用C++的代码爬取就可以了,没想到这个网站是动态生成的,无奈我们才疏学浅,只好转为求助python的selenium。
我们发现这个网站的论文顺序和助教提供的那个网站的论文顺序一致,但是又缺少abstract等信息,因此“偷工减料”直接按顺序爬取type的信息,最后再用together.cpp将两份文档的内容整合在一起。
- python部分的示例代码如下:
Oral=re.compile(r'O\d') Spotlight=re.compile(r'S\d') Poster=re.compile(r'P') f = open('./Only_Type.txt', 'a',encoding='utf-8') for t in soup.find_all('a',class_='text-bold ng-binding'): k=t.parent.parent.find('h3').text if re.search('O',k): f.write('Oral\n') elif re.search('S\d',k): f.write('Spotlight\n') elif re.search('P',k): f.write('Poster\n') f.close()
- 爬取结果整合:

2.
此外,在CVPR 2018里,我们还发现每个作者后面都被标注上了所属的大学或研究机构,有的还有国家信息。因此我们同样使用python爬取这部分信息,保存在文档里面。
- 爬取结果:
然后将大学或研究机构都提取出来进行排序,输出top10这样,实现上是以
WordCount.cpp的Sword.cpp为基础进行一些修改。
输出结果:
python部分的示例代码如下:
f = open('./Authors.txt', 'a',encoding='utf-8') for author in soup.find_all('em', class_='ng-binding'): f.write(author.text) f.close()


3.
我们利用
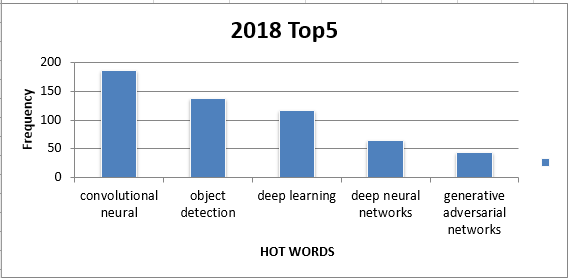
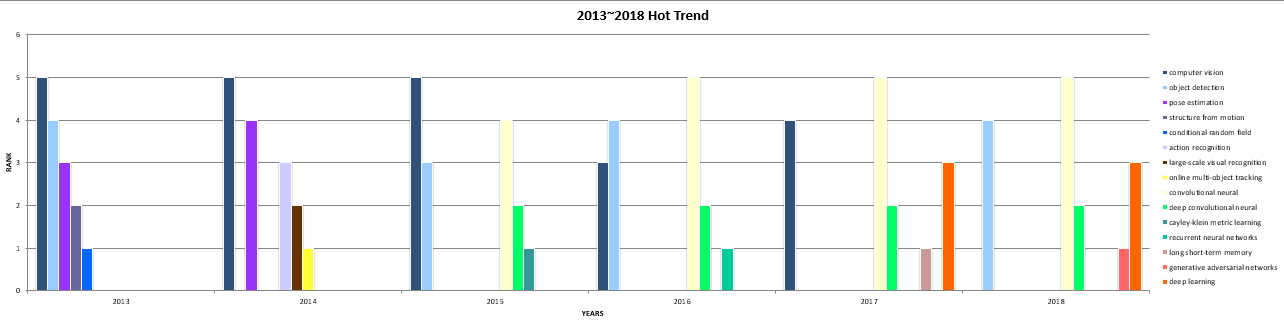
Crawler.cpp将20132018年的论文的title和abstract全爬下来,放在`result20xx.txt`文件里,并用`WordCount.cpp`对每年的爬取结果进行处理,分别选用的词组长度为25生成Top10的高频词组,然后选择其中靠谱的Top5,利用Top.py和Trend.py生成可视化数据。部分结果如下所示:
五、关键代码解释
以下对词组统计phrase.cpp功能模块进行解释:
Psort::PS()
1.结构体PWord:
- 思路:
- 用于存储合法单词和合题意的分隔符,f用于记录区分合法单词、分隔符串以及间断符。
- 代码展示如下:
struct PWord { string pw; short int f; //Is letter:1;Is separator:0 ; Is break point:-1; };2.文件数据处理:
- 思路:
- 对每一个字符进行处理,区分开合法单词、分隔符串与间断符(即非法单词),将其按序分别插入Title_Phrase队列与Abstract_Phrase队列。
- 需要注意的问题:
- 论文标准格式添加的title与abstract的需要词组分别统计,同时title与abstract不计入统计。
- 解决方案:
- flag标志单词出现在title段orabstract段;matchflag标志title与abstract的匹配(类似括号匹配)。
- 代码展示如下:
while (fin.good()) { fin >> c; if ((c >= 48 && c <= 57) || (c >= 65 && c <= 90) || (c >= 97 && c <= 122)) { if (c >= 65 && c <= 90) c += 32; word.pw.push_back(c); //Judge separator, and join into phrase queue if (wordflag == 1 && separator.pw.length()>0) { if (flag == 0) phrase_t.push(separator); else if (flag == 1) phrase_a.push(separator); } separator.pw = ""; } else { if (c != 13 && c != 10) { separator.pw.push_back(c); } //Judge word, and join into word queue if (word.pw.length() >= 4) { /**********************Is word******************************/ if ((word.pw[0] >= 97 && word.pw[0] <= 122) && (word.pw[1] >= 97 && word.pw[1] <= 122) && (word.pw[2] >= 97 && word.pw[2] <= 122) && (word.pw[3] >= 97 && word.pw[3] <= 122)) { if (word.pw == "title") { matchflag = 1; wordflag = 0; flag = 0; phrase_a.push(f); } else if (word.pw == "abstract") { if (matchflag) //Is 'Abstract' { matchflag = 0; wordflag = 0; flag = 1; phrase_t.push(f); } else //Is 'abstract' { wordflag = 1; if (flag == 0) phrase_t.push(word); else if (flag == 1) phrase_a.push(word); } } else { wordflag = 1; if (flag == 0) phrase_t.push(word); else if (flag == 1) phrase_a.push(word); } } else { if (flag == 0) phrase_t.push(f); else if (flag == 1) phrase_a.push(f); wordflag = 0; } } else if (word.pw.length() == 0) { } else { if (flag == 0) phrase_t.push(f); else if (flag == 1) phrase_a.push(f); wordflag = 0; } word.pw = ""; } }3.词组字典的构建:
思路:
- 分别对Title_Phrase队列与Abstract_Phrase队列进行词组检索,符合要求的词组序列便加入map——phrase_count中,便于之后的排序操作。以Title_Phrase队列处理为例,Abstract_Phrase队列同理。
代码展示如下:
map初始化:
//*****************For phrase************************// std::map<std::string, size_t> phrase_count; string P; P = ""; //Story phrase temporary词组构建:
(1)start==0:初始构建词组或检索到间断符重新构建词组,为方便后续构建词组,构建成功时同步记录词组中第二个单词首字母的位置、P记录最后加入字典的词组字符串。
(2)start==1:至少为第二次构建词组,此时只需将P中的第一个单词及前两个单词之间的分隔符(如果存在)去掉,并读取下一个单词加入P即可。
(3)重复以上步骤,直到Title_Phrase队列为空。
while (!phrase_t.empty()) { if (start == 1) { if (!flags) { P = P.substr(p); //Delete the first word } PWord sign = phrase_t.front(); phrase_t.pop(); if (sign.f == -1) //break point { start = 0; continue; } else if (sign.f == 1) //word component with letter { if ((P[P.size()] >= 48 && P[P.size()] <= 57) || (P[P.size()] >= 65 && P[P.size()] <= 90) || (P[P.size()] >= 97 && P[P.size()] <= 122)) { P.append(" " + sign.pw); } else //privious is separator or without word component with letter { P.append(sign.pw); } bool flagi = 1; //Flag the second word witch have not be marked yet for (int i = 0; i < P.size(); i++){•••}//seach for the second word's position if (weight == 1){ phrase_count[P] += 10; } else ++phrase_count[P];flags = 0; } else //(sign.flag==0)//separator { flags = 1; P.append(sign.pw); } } else //Constitute in the first time or once again { P = ""; short int l = len; short int flagl = 0; //Is word component by letter or not flag = 1; //Use the "flag" previous to Judge the length of phrase is enough or not while (l) { PWord sign = phrase_t.front(); phrase_t.pop(); if (sign.f == -1) //separator { flag = 0; flagl = 0; break; } else if (sign.f == 1) //Is word component by letter { if (flagl) { P.append(" " + sign.pw); } else //privious is separator or without word component with letter { flagl = 1; P.append(sign.pw); } l--; } else //(sign.flag==0) //The string with separator { if (flagl) //Is word component by letter { flagl = 0; P.append(sign.pw); } } } if (flag) { if (weight == 1) { phrase_count[P] += 10; } else ++phrase_count[P]; start = 1; bool flagi = 1; //Flag the second word witch have not be marked yet for (int i = 0; i < P.size(); i++){•••}//seach for the second word's position } } }词组排序:
利用sort函数进行排序。
//*********Sort**********// vector<PAIR>phrase_v1(phrase_count.begin(), phrase_count.end()); sort(phrase_v1.begin(), phrase_v1.end(), CmpByValue()); phrase_v = phrase_v1;
六、性能分析与改进
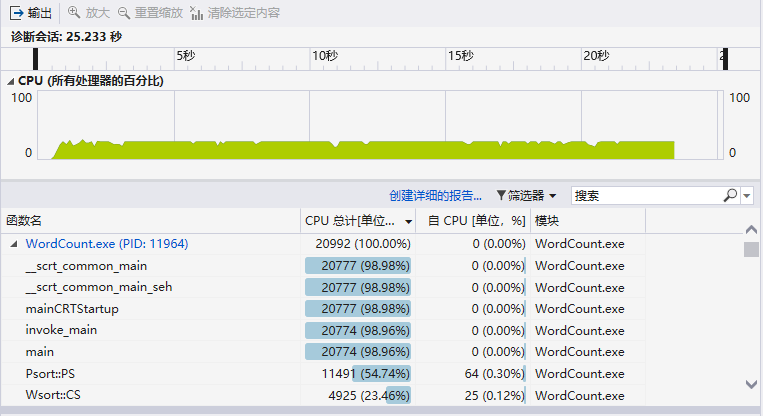
输入文件为爬取得到的标准格式文档,大小为1195KB,设定参数:-w 1 -m 3 -n 20
运行得到如下结果:
1.性能分析图
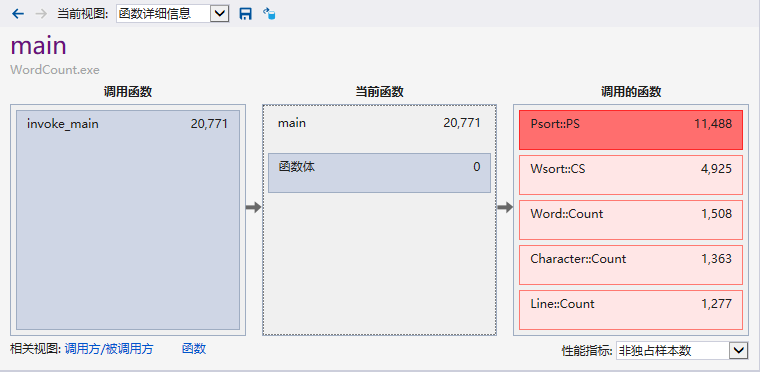
2.程序中消耗最大的函数
3.改进的思路
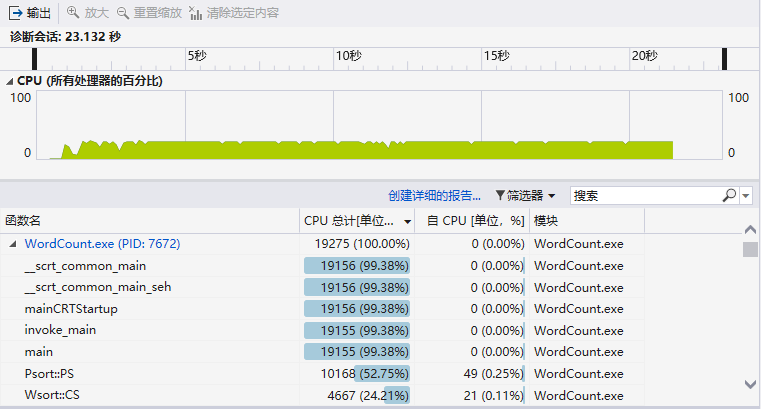
一开始使用的是从map中搜索number次频数最高的单词及词组进行词频输出;后来改为直接使用sort()函数,程序运行时间从25.233秒减少为23.132秒(提高了8%的运行速度)。
4.改进后的性能分析图
七、单元测试
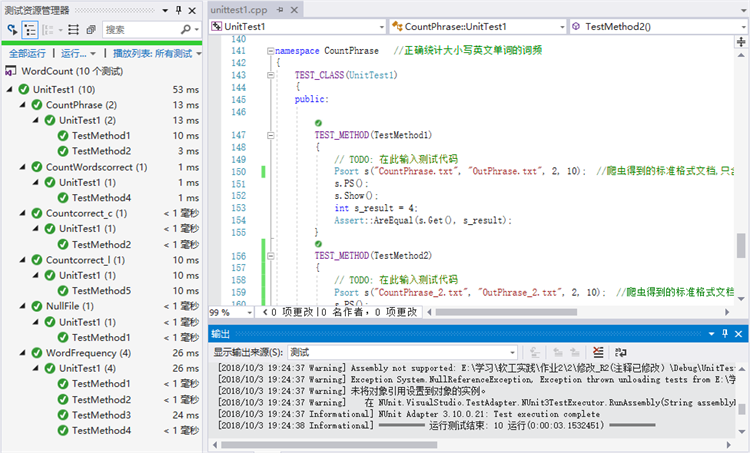
1.设计的十个单元测试如下:
| 单元测试名称 | 测试内容 | 被测试实例 |
|---|---|---|
| NullFile | 打开内容为空的文件 | 测试全部 |
| Countcorrect_l | 正确统计行数 | Clines.cpp |
| Countcorrect_c | 正确统计字符 | Ccharacter.cpp |
| CountWordscorrect | 能正确正确统计单词数 | Cwords.cpp |
| WordFrequency | 仅包含同一个有效单词,但存在多个大小写混用的版本,权重选项为0 | Swords.cpp |
| WordFrequency | 仅包含同一个有效单词,但存在多个大小写混用的版本,权重选项为1 | Swords.cpp |
| WordFrequency | 包含多个有效单词,权重选项为0 | Swords.cpp |
| WordFrequency | 包含多个有效单词,权重选项为1 | Swords.cpp |
| CountPhrase | 正确统计大小写英文单词的词频,只含有合法单词 | Phrase.cpp |
| CountPhrase | 正确统计大小写英文单词的词频,含有合法单词、非法单词及分隔符 | Phrase.cpp |
2.单元测试结果
3.项目部分单元测试代码
namespace WordFrequency //正确统计大小写英文单词的词频
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
// TODO: 在此输入测试代码
Wsort s("CountFrequency_1.txt", "OutFrequency_1.txt", 0, 1); //仅包含同一个有效单词,但存在多个大小写混用的版本,权重选项为0,统计最高词频
s.CS();
int s_result = 11;
Assert::AreEqual(s.Get(), s_result);
}
TEST_METHOD(TestMethod2)
{
// TODO: 在此输入测试代码
Wsort s("CountFrequency_1.txt", "OutFrequency_1.txt", 1, 1); //仅包含同一个有效单词,但存在多个大小写混用的版本,权重选项为1,统计最高词频
s.CS();
int s_result = 20;
Assert::AreEqual(s.Get(), s_result);
}
TEST_METHOD(TestMethod3)
{
// TODO: 在此输入测试代码
Wsort s("CountFrequency_3.txt", "OutFrequency_3.txt", 0, 1); //包含多个有效单词,权重选项为0,统计最高词频
s.CS();
int s_result = 3;
Assert::AreEqual(s.Get(), s_result);
}
TEST_METHOD(TestMethod4)
{
// TODO: 在此输入测试代码
Wsort s("CountFrequency_3.txt", "OutFrequency_3.txt", 1, 1); //包含多个有效单词,权重选项为1,统计最高词频
s.CS();
int s_result = 21;
Assert::AreEqual(s.Get(), s_result);
}
};
}
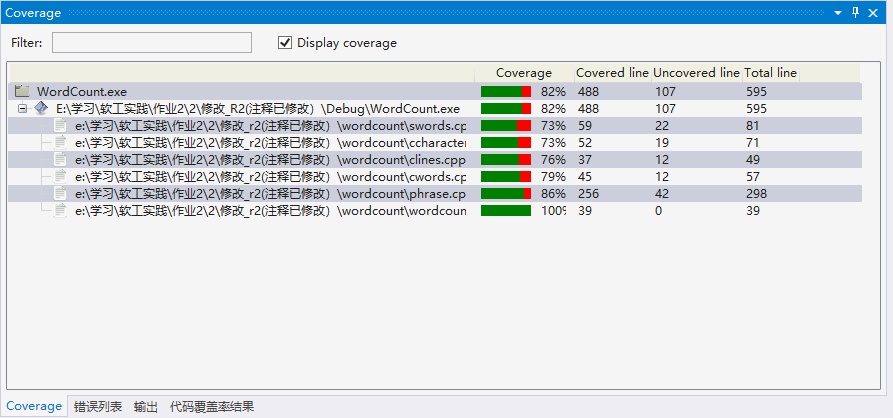
4.代码覆盖率
未覆盖到的代码基本都是异常错误处理的代码
八、Github的代码签入记录

九、遇到的代码模块异常或结对困难及解决方法
1.词组统计模块的设计
做需求分析时,一开始作业中对于词组统计部分描述的不够清晰,我们的理解也不到位,因此最开始对此模块的设计与实际要求距离较远;在经过助教的详细说明后,我们重新做了需求分析,修改模块代码,成功解决问题。
2.数据爬取
在做数据爬取时,发现CVPR官网爬取到的论文的url会被随机插入数字1000作为干扰项,导致异常,后来对爬取的url进行裁切解决问题。在用C++爬虫对附加题的信息进行爬取时,得到400错误,但网页可正常打开,分析后判断是动态生成的网页,通过python解决。
十、评价我可爱又迷人的队友
我的队友是大佬!我的队友是大佬!我的队友是大佬!【重要的事情要说三遍】
从上学期开始就一直跟着我的队友混了,从上课到作业讨论再到实验交流。然后这学期就从一句“我们一起吗!”开始了我们的结对之旅。
- 我的队友超级有责任心。她在结对开始就主动承担了很多,对这次作业很上心,完成作业期间我们一起交流了很多次,极大程度地带动了我的积极性!
- 我的队友是一个很有时间观念、很有规划的人。其实我的拖延症挺严重的,但是从接触她开始,就慢慢被她影响,对各种事务的计划安排比以前更好啦!
- 我的队友厉害又有耐心!因为我比较菜,做事情比较慢,很怕拖队友后腿qwq,但是我的队友都没有嫌弃我,教我很多东西,给我时间让我去学。
- 总之我超级喜欢我的队友!很高兴能遇见她【比心】
十一、 学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 500 | 500 | 30 | 30 | 学习VS生成命令行程序、单元测试、使用VS性能分析工具等 |
| 2 | 300 | 800 | 35 | 65 | 改进第一次作业、学习《构建之法》第3和8章、学习原型设计Axure Rp 8、画画技能++ |
| 3-5 | 1000 | 1800 | 120 | 185 | Python++、交流能力++、时间规划++ |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号