
JVM内存管理------GC算法精解(复制算法与标记/整理算法)
本次LZ和各位分享GC最后两种算法,复制算法以及标记/整理算法。上一章在讲解标记/清除算法时已经提到过,这两种算法都是在此基础上演化而来的,究竟这两种算法优化了之前标记/清除算法的哪些问题呢?
复制算法
我们首先一起来看一下复制算法的做法,复制算法将内存划分为两个区间,在任意时间点,所有动态分配的对象都只能分配在其中一个区间(称为活动区间),而另外一个区间(称为空闲区间)则是空闲的。
当有效内存空间耗尽时,JVM将暂停程序运行,开启复制算法GC线程。接下来GC线程会将活动区间内的存活对象,全部复制到空闲区间,且严格按照内存地址依次排列,与此同时,GC线程将更新存活对象的内存引用地址指向新的内存地址。
此时,空闲区间已经与活动区间交换,而垃圾对象现在已经全部留在了原来的活动区间,也就是现在的空闲区间。事实上,在活动区间转换为空间区间的同时,垃圾对象已经被一次性全部回收。
听起来复杂吗?
其实一点也不复杂,有了上一章的基础,相信各位理解这个算法不会费太多力气。LZ给各位绘制一幅图来说明问题,如下所示。

其实这个图依然是上一章的例子,只不过此时内存被复制算法分成了两部分,下面我们看下当复制算法的GC线程处理之后,两个区域会变成什么样子,如下所示。

可以看到,1和4号对象被清除了,而2、3、5、6号对象则是规则的排列在刚才的空闲区间,也就是现在的活动区间之内。此时左半部分已经变成了空闲区间,不难想象,在下一次GC之后,左边将会再次变成活动区间。
很明显,复制算法弥补了标记/清除算法中,内存布局混乱的缺点。不过与此同时,它的缺点也是相当明显的。
1、它浪费了一半的内存,这太要命了。
2、如果对象的存活率很高,我们可以极端一点,假设是100%存活,那么我们需要将所有对象都复制一遍,并将所有引用地址重置一遍。复制这一工作所花费的时间,在对象存活率达到一定程度时,将会变的不可忽视。
所以从以上描述不难看出,复制算法要想使用,最起码对象的存活率要非常低才行,而且最重要的是,我们必须要克服50%内存的浪费。
标记/整理算法
标记/整理算法与标记/清除算法非常相似,它也是分为两个阶段:标记和整理。下面LZ给各位介绍一下这两个阶段都做了什么。
标记:它的第一个阶段与标记/清除算法是一模一样的,均是遍历GC Roots,然后将存活的对象标记。
整理:移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收。因此,第二阶段才称为整理阶段。
它GC前后的图示与复制算法的图非常相似,只不过没有了活动区间和空闲区间的区别,而过程又与标记/清除算法非常相似,我们来看GC前内存中对象的状态与布局,如下图所示。
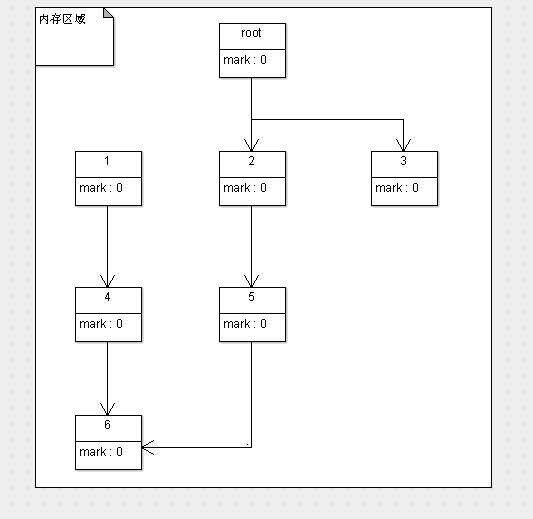
这张图其实与标记/清楚算法一模一样,只是LZ为了方便表示内存规则的连续排列,加了一个矩形表示内存区域。倘若此时GC线程开始工作,那么紧接着开始的就是标记阶段了。此阶段与标记/清除算法的标记阶段是一样一样的,我们看标记阶段过后对象的状态,如下图。

没什么可解释的,接下来,便应该是整理阶段了。我们来看当整理阶段处理完以后,内存的布局是如何的,如下图。

可以看到,标记的存活对象将会被整理,按照内存地址依次排列,而未被标记的内存会被清理掉。如此一来,当我们需要给新对象分配内存时,JVM只需要持有一个内存的起始地址即可,这比维护一个空闲列表显然少了许多开销。
不难看出,标记/整理算法不仅可以弥补标记/清除算法当中,内存区域分散的缺点,也消除了复制算法当中,内存减半的高额代价,可谓是一举两得,一箭双雕,一石两鸟,一。。。。一女两男?
不过任何算法都会有其缺点,标记/整理算法唯一的缺点就是效率也不高,不仅要标记所有存活对象,还要整理所有存活对象的引用地址。从效率上来说,标记/整理算法要低于复制算法。
算法总结
这里LZ给各位总结一下三个算法的共同点以及它们各自的优势劣势,让各位对比一下,想必会更加清晰。
它们的共同点主要有以下两点。
1、三个算法都基于根搜索算法去判断一个对象是否应该被回收,而支撑根搜索算法可以正常工作的理论依据,就是语法中变量作用域的相关内容。因此,要想防止内存泄露,最根本的办法就是掌握好变量作用域,而不应该使用前面内存管理杂谈一章中所提到的C/C++式内存管理方式。
2、在GC线程开启时,或者说GC过程开始时,它们都要暂停应用程序(stop the world)。
它们的区别LZ按照下面几点来给各位展示。(>表示前者要优于后者,=表示两者效果一样)
效率:复制算法>标记/整理算法>标记/清除算法(此处的效率只是简单的对比时间复杂度,实际情况不一定如此)。
内存整齐度:复制算法=标记/整理算法>标记/清除算法。
内存利用率:标记/整理算法=标记/清除算法>复制算法。
可以看到标记/清除算法是比较落后的算法了,但是后两种算法却是在此基础上建立的,俗话说“吃水不忘挖井人”,因此各位也莫要忘记了标记/清除这一算法前辈。而且,在某些时候,标记/清除也会有用武之地。
结束语
到此我们已经将三个算法了解清楚了,可以看出,效率上来说,复制算法是当之无愧的老大,但是却浪费了太多内存,而为了尽量兼顾上面所提到的三个指标,标记/整理算法相对来说更平滑一些,但效率上依然不尽如人意,它比复制算法多了一个标记的阶段,又比标记/清除多了一个整理内存的过程。
难道就没有一种最优算法吗?
当然是没有的,这个世界是公平的,任何东西都有两面性,试想一下,你怎么可能找到一个又漂亮又勤快又有钱又通情达理,性格又合适,家境也合适,身高长相等等等等都合适的女人?就算你找到了,至少有一点这个女人也肯定不满足,那就是多半不会恰巧又爱上了与LZ相似的各位苦逼猿友们。你是不是想说你比LZ强太多了,那LZ只想对你说,高富帅是不会爬在电脑前看技术文章的,0.0。
但是古人就是给力,古人说了,找媳妇不一定要找最好的,而是要找最合适的,听完这句话,瞬间感觉世界美好了许多。
算法也是一样的,没有最好的算法,只有最合适的算法。
既然这三种算法都各有缺陷,高人们自然不会容许这种情况发生。因此,高人们提出可以根据对象的不同特性,使用不同的算法处理,类似于萝卜白菜各有所爱的原理。于是奇迹发生了,高人们终于找到了GC算法中的神级算法-----分代搜集算法。
至于这个神级算法是如何处理的,LZ就在下一章再和各位猿友探讨了,本次就到此为止了,希望各位有所收获。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号