【论文阅读】DeepREL通过自动化关系 API 推理对深度学习库进行模糊测试
通过自动化关系 API 推理对深度学习库进行模糊测试
论文基本信息
ESEC/FSE ’22, November 14–18, 2022, Singapore, Singapore
时间:2022-11-07
CCF A
原文:https://doi.org/10.1145/3540250.3549085
摘要
近年来,深度学习(DL)受到广泛关注。同时,深度学习系统中的错误可能导致严重后果,甚至可能威胁到人类生命。因此,越来越多的研究致力于深度学习模型测试。然而,在测试深度学习库(例如 PyTorch 和 TensorFlow)方面的工作仍然有限,这些库是构建、训练和运行深度学习模型的基础。之前关于模糊测试 DL 库的工作只能为文档示例、开发人员测试或 DL 模型调用的 API 生成测试,而大量 API 未经测试。在本文中,我们提出了 DeepREL,这是第一种自动推断关系 API 以实现更有效的 DL 库模糊测试的方法。我们的基本假设是,对于被测的 DL 库,可能存在许多共享相似输入参数和输出的 API;通过这种方式,我们可以轻松地从调用的 API 中“借用”测试输入来测试其他关系 API。此外,我们将关系 API 的价值等价和状态等价概念正式化,作为有效发现错误的预言机。我们已经将 DeepREL 作为 DL 库的全自动端到端关系 API 推理和模糊测试技术实现,该技术 1) 根据 API 语法/语义信息自动推断潜在的 API 关系,2) 合成用于调用关系 API 的具体测试程序,3) 通过代表性测试输入验证推断的关系 API,最后 4) 对已验证的关系 API 进行模糊测试以发现潜在的不一致。我们对两个最流行的 DL 库 PyTorch 和 TensorFlow 的评估表明,DeepREL 可以覆盖比最先进的 FreeFuzz 多 157% 的 API。到目前为止,DeepREL 总共检测到了 162 个错误,其中 106 个已经被开发人员确认为以前未知的错误。令人惊讶的是,在三个月内,DeepREL 已经检测到整个 PyTorch 问题跟踪系统 13.5% 的高优先级错误。此外,除了 162 个代码错误外,我们还检测到 14 个文档错误(均已确认)。
关键点
为了测试关系 API 以进一步克服 FreeFuzz 的局限性,在 FreeFuzz 的基础上构建 DeepREL 来自动推断关系 API,并利用它们来模糊 DL 库。DeepREL 首先根据 API 的语法和语义信息自动推断所有可能的候选匹配 API 对。然后,DeepREL 为那些潜在的关系型 API 合成具体的测试程序。
然后,DeepREL 利用一组具有代表性的有效输入(在正常的 API 执行过程中自动跟踪)来检查推断的 API 关系是否成立。最后,DeepREL 使用经过验证的 API 对,并利用突变型模糊测试来生成一组多样性和广泛性的测试输入,以检测关系 API 之间的潜在不一致性。
解决的问题/贡献
Dimension。本文通过关系 API 推理为全自动 DL 库模糊测试开辟了新的维度。
技术。我们构建了 DeepREL,这是一个用于 DL 库测试的全自动端到端框架。DeepREL 根据 API 语法和语义信息自动推断所有可能的候选关系 API,然后通过测试程序综合进行动态验证。虽然这项工作的重点是 DL 库,但 DeepREL 的基本思想是通用的,也可以应用于其他软件系统。
评估和影响。DeepREL 涵盖的 API 比以前的工作多了 1815 个(即改进了 157%),总共检测到了 162 个错误,其中 106 个已经被开发人员确认为以前未知的错误。令人惊讶的是,DeepREL 能够在三个月内检测到整个 PyTorch 问题跟踪系统的 13.5% 的高优先级错误。此外,除了 162 个代码错误之外,我们还能够检测到 14 个文档错误(全部已确认)作为我们实验的副产品。
当前研究进度
虽然 PyTorch 中的 AdaptiveAvgPool3d 和 AdaptiveMaxPool3d 并不等效,但它们在功能上是相似的 API;因此,我们可以将第一个 API 的任何有效输入提供给第二个 API,并期望其调用也成功。基于这种直觉,我们可以很容易地“借用”为一个 API 生成的测试输入来测试其他关系 API。此外,API 关系可以直接用作差分测试的测试预言机。
本文主要方法
在 FreeFuzz 上构建我们的技术 (DeepREL),以自动推断关系 API 并利用它们来模糊 DL 库。但请注意,我们的 DeepREL 理念是通用的,可以构建在任何 API 级别的 DL 库模糊器上(例如 DocTer )。我们选择 FreeFuzz 是因为它是一种最新的最先进的技术,既公开可用又完全自动化。
自动准确获取 API 关系
DeepREL 首先根据 API 语法和语义信息自动推断所有可能的候选 API 对。然后,DeepREL 为这些潜在的关系 API 合成具体的测试程序
DeepREL 采用经过验证的 API 对,并利用基于突变的模糊测试来生成一组更加多样化和广泛的测试输入,以检测关系 API 之间的潜在不一致。
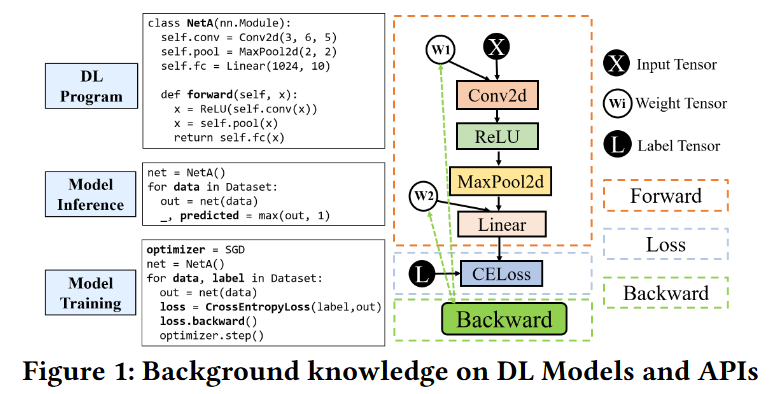
前向部分(以输入张量和权重张量为输入)、损失计算部分(需要标签张量)和后向部分(用于更新权重张量)
将程序的调用结果抽象为一组粗粒度状态:Success、Exception 和 Crash。“成功”表示程序执行正常终止,而“异常”表示程序执行引发已知异常。最后,Crash 表示程序执行崩溃并出现意外错误的情况,例如分段错误或 INTERNAL ASSERT FAILED 错误(正如 PyTorch 开发人员所评论的那样,这些错误“永远不可接受”)。
测试框架
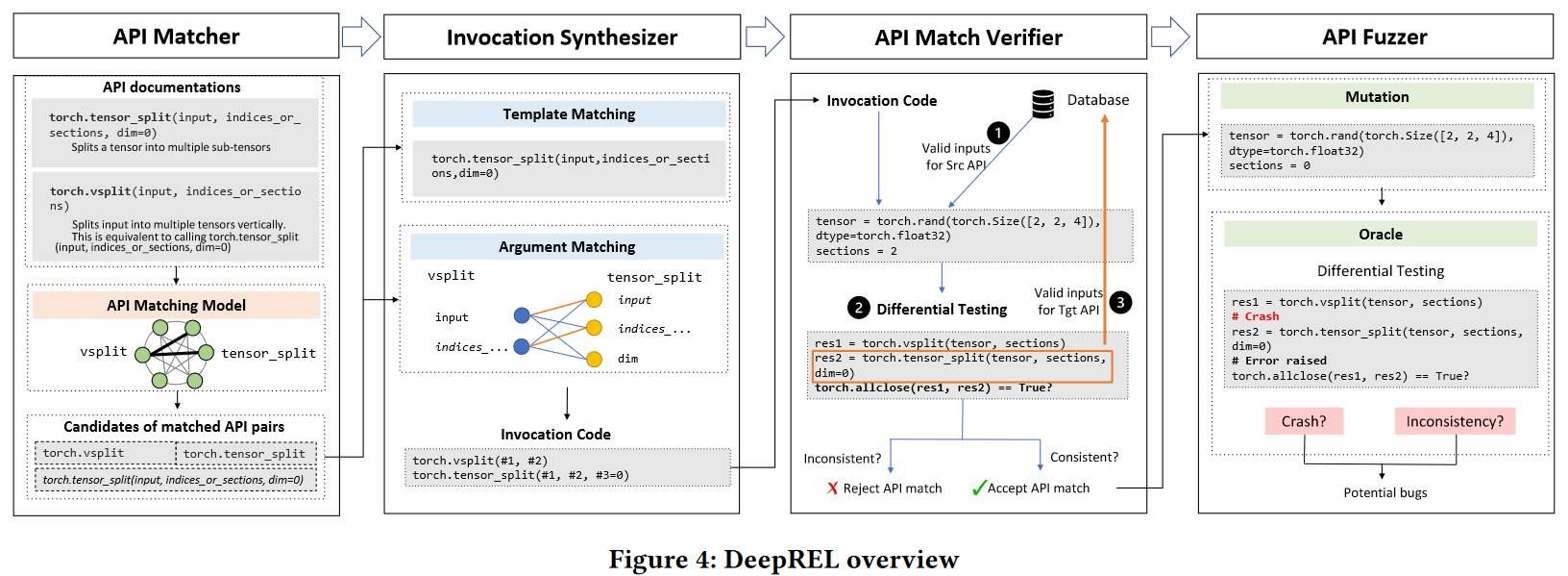
API 匹配器(第 4.1 节)。
为了测试通常具有数百甚至数千个 API 的 DL 库,第一个挑战是确定可能满足所需属性的 API 对 等效值 或 等效状态 。API Matcher 映射,每个 API 都根据 API 文档嵌入到嵌入中,并使用嵌入相似性来识别 API 对的候选者。
DeepREL 会从文档中识别潜在的匹配 API 对,计算每个 API 对的成对相似度,并将每个 API 与其 K 最近邻居配对作为候选对。K 是一个超参数,在 DeepREL 的默认设置中设置为 10。
将 API 签名映射到其 TF-IDF(术语频率-反向文档频率)嵌入[73]中,并计算嵌入相似性。
对于每个 API 对 (S,T),我们将它们的文档嵌入之间的余弦相似度计算为它们的文档相似度
调用合成器(第 4.2 节)。
给定潜在 API 对的集合,Invocation Synthesizer 决定如何调用它们。为了构造有效的调用以供以后验证,我们对源 API 施加了一个约束:它必须在数据库中至少有一个(有效)调用。这样,给定源 API 的调用,调用合成器旨在合成目标 API 的调用代码。
构建图后,DeepREL 利用 Kuhn-Munkres 算法找到最佳参数匹配,并基于该算法合成调用代码。当源 API 和目标 API 的参数数量相同时,DeepREL 会根据最佳参数匹配直接合成调用代码。否则,如果任何非可选参数不匹配,DeepREL 将中止当前 API 对,因为用于确定不匹配非可选参数值的搜索空间很大。也就是说,DeepREL 只考虑源 API 或目标 API 的可选参数匹配的情况。对于不匹配的可选参数,DeepREL 仅使用其默认值(Python 可选参数始终具有默认值)。(这里论文应该出错了,DeepREL 只考虑源 API 或目标 API 的可选参数匹配的情况,原文是说只考虑不匹配的情况)
API 匹配验证程序(第 4.3 节)。
给定匹配 API 的调用代码,此阶段将检查每个 API 对是否满足属性 Equivalencevalue 或 Equivalencestatus,并使用一组代表性输入作为验证测试输入。如果所有测试的结果值(或执行状态)一致,则 API 匹配验证程序接受 API 对作为 Equivalencevalue (resp. Equivalencestatus )。如果 API 匹配验证程序在此阶段检测到任何不一致,则会拒绝 API 对。
API 模糊器(第 4.4 节)。
最后一步是利用经过验证的 API 对来检测潜在的一致性错误。API Fuzzer 使用基于突变的模糊测试为源 API 生成大量测试输入,并使用预言机测试已验证的 API 对(第 3 节)。最后,回想一下,为了生成有效的输入,源 API 必须在数据库中至少有一个(有效)调用。DeepREL 进一步采用迭代过程来覆盖更多的 API 对(第 4.5 节)。可以将新生成的有效目标 API 调用添加到数据库中,作为下一次迭代的源 API,以检测更多潜在的 API 对。以下各节将详细解释每个阶段。
方法实现
API Matcher。为了找到高质量的匹配 API 对,我们首先使用 bs4 Python 包 [2] 来解析来自 TensorFlow 和 PyTorch 的所有 7973 个 API 的文档。我们从文档中收集 API 签名和描述。在计算 TF-IDF 嵌入之前,我们使用 Snowball 词干分析器 [55] 将标记转换为词干。至于文档嵌入,我们使用 SentenceTransformer Python 包 [12] 并采用预训练模型 all-MiniLM-L6-v2 作为我们的 SBEncoder 。
调用合成器。对于参数匹配,我们使用 munkres Python 包 [10](实现 Kuhn-Munkres 算法)来解决最大加权二分匹配问题。对于模板匹配,我们会自动从文档中搜索并提取匹配模板的代码片段。
API 匹配验证程序。我们用一组具有代表性的有效输入来验证候选 API 对之间的关系。我们从最先进的 FreeFuzz [66] 使用的各种输入源中获取了跟踪的有效输入,其中包括文档、开发人员测试和 202 个 DL 模型,并且具有验证 API 功能的代表性。我们将 FreeFuzz 数据库中最多 100 次源 API 的有效调用作为验证输入输入到源 API 和目标 API 中,并检查它们是否具有一致的行为。
API 模糊测试器。我们利用 FreeFuzz 的模糊测试策略来改变为每个源 API(在 FreeFuzz 数据库中)跟踪的所有有效输入,并在源 API 和目标 API 上运行所有生成的输入(按照 FreeFuzz [66] 的默认设置,每个源 API 为 1000 个),以检测一致性错误。
bug 判别
run_and_check 函数是用于执行给定的代码片段,并根据执行结果判断其属于哪一类结果类型(ResultType)。这个函数试图区分真正的 bug 和其他类型的测试结果。以下是对 run_and_check 函数中 if-else 判断逻辑的详细解释,以及每一类结果的分类标准:
- 错误处理(Error Handling):
如果 TorchLibrary.run_code(code) 返回错误(error 变量为 True),则结果类型被设置为 ResultType.ERROR,并将代码写入到错误目录(err_dir)。 2. 内部断言失败(Internal Assert Failure):
如果结果中存在 "INTERNAL ASSERT FAILED" 错误信息,这被认为是一个真正的 bug,结果类型被设置为 ResultType.BUG,并将代码写入到 bug 目录(bug_dir)。 3. 失败(Fail):
如果 ERR_1 和 ERR_2 都存在错误,且没有内部断言失败,结果类型被设置为 ResultType.FAIL,并将代码写入到失败目录(fail_dir)。 4. 非等价(Not Equivalent):
如果 ERR_2 存在错误,并且错误信息不是内部断言失败,也不是在允许的错误列表中(allow_error 函数返回 False),结果类型被设置为 ResultType.NOT_EQUIVALENT,并将代码写入到非等价目录(neq_dir)。 5. 成功(Success):
如果 ERR_1 和 ERR_2 都没有错误,并且当 equal_type 为 1 时,RES_1 和 RES_2 的值在一定的容忍度内相等(TorchLibrary.is_equal 函数返回 True),结果类型被设置为 ResultType.SUCCESS,并将代码写入到成功目录(success_dir)。 6. BUG 判定:
如果在任何错误信息中发现 "INTERNAL ASSERT FAILED",或者当 ERR_2 存在错误且不是内部断言失败时,结果类型被设置为 ResultType.BUG。 7. 其他情况(Other Cases):
如果 ERR_1 存在错误但没有 ERR_2,结果类型被设置为 ResultType.FAIL。
如果 strict_mode 是 False 并且 ERR_2 的错误信息在允许的错误列表中(allow_error 函数返回 True),结果类型被设置为 ResultType.FAIL。
实验
数据
mongodb 存储格式如左图,dump 文件夹下 bson 文件存储的就是数据库中的内容
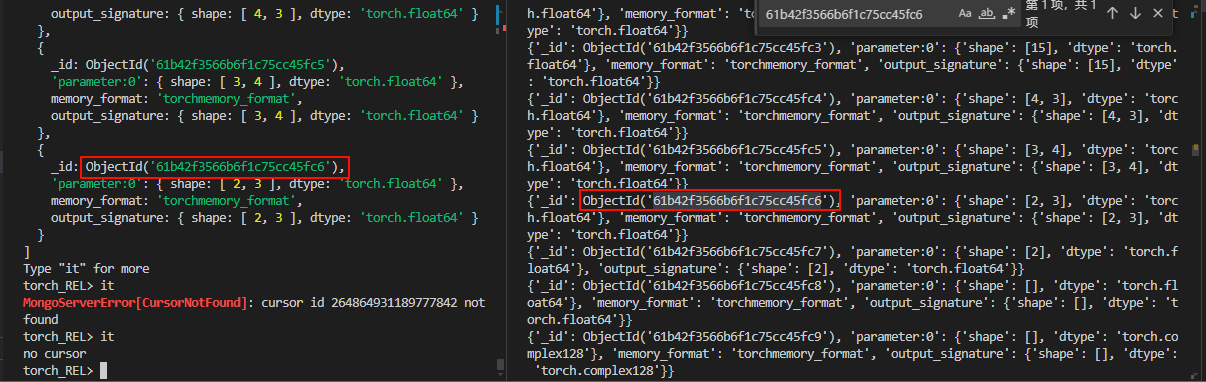
截图中的 API 可能存在问题,cursor 出现错误,但是其他 API 基本上都是对应的。
主程序 DeepREL.py
python worker.py torch.nn.GRU torch.optim.lr_scheduler.OneCycleLR 1000 ../expr/output-0 127.0.0.1 27017 torch_REL
work.py
match_api,其中 run_and_check 函数是用于执行给定的代码片段,并根据执行结果判断其属于哪一类结果类型(ResultType)。这个函数试图区分真正的 bug 和其他类型的测试结果。以下是对 run_and_check 函数中 if-else 判断逻辑的详细解释,以及每一类结果的分类标准:
def run_and_check(code,
results, error = TorchLibrary.run_code(code)
if error:
TorchLibrary.write_to_dir(err_dir, write_code)
res_type = ResultType.ERROR
else:
tgt_state = (results[ERR_2] == None)
if results[ERR_1] and results[ERR_2]:
# check
if internal_error in results[ERR_1] or internal_error in results[ERR_2]:
TorchLibrary.write_to_dir(bug_dir, write_code)
res_type = ResultType.BUG
else:
# TorchLibrary.write_to_dir(fail_dir, write_code)
res_type = ResultType.FAIL
elif not results[ERR_1] and results[ERR_2]:
if internal_error in results[ERR_2]:
TorchLibrary.write_to_dir(bug_dir, write_code)
res_type = ResultType.BUG
elif not strict_mode and allow_error(results[ERR_2]):
# TorchLibrary.write_to_dir(fail_dir, write_code)
res_type = ResultType.FAIL
else:
TorchLibrary.write_to_dir(neq_dir, write_code)
res_type = ResultType.NOT_EQUIVALENT
elif results[ERR_1]:
# TorchLibrary.write_to_dir(fail_dir, write_code)
res_type = ResultType.FAIL
elif equal_type == 1:
if TorchLibrary.is_equal(results[RES_1], results[RES_2], 1e-5):
# TorchLibrary.write_to_dir(success_dir, write_code)
res_type = ResultType.SUCCESS
else:
TorchLibrary.write_to_dir(neq_dir, write_code)
res_type = ResultType.NOT_EQUIVALENT
else:
# TorchLibrary.write_to_dir(success_dir, write_code)
res_type = ResultType.SUCCESS
return res_type, tgt_state
bug 实例
如下为一些 bug 示例:(来自文章:DLLENS: Testing Deep Learning Libraries via LLM-aided Synthesis)
1. 越界读取 (Equivalencevalue , ✓)
图 10 中显示的 bug 是通过 Equivalencevalue 在 API 对 torch.kthvalue(tensor, k) 和 tensor.kthvalue(k) 中检测到的。后一个 API 是火炬的一种方法。Tensor [5],它是 PyTorch 中的基本类。给定相同的张量(输入)和参数(k),返回的结果不相等(第 4 行)。调试后,我们发现返回的结果实际上在运行之间可能不同,这表明它从用户控制之外的内存位置读取值数据!此错误是一个无提示错误,并且具有严重的安全隐患:如果不对 k 进行适当的范围检查,用户可能能够在分配的内存边界之外读取数据(即越界读取)。此错误被标记为“高优先级”并立即修复。

2. 不一致的检查 (Equivalencestatus , ✓)
图 11 显示了 PyTorch 中 AdaptiveAvgPool3d 和 AdaptiveMaxPool3d 的一个错误(通过 Equivalencestatus 找到)。使用完全相同的输入张量(张量)和参数(output_size),AdaptiveAvgPool3d 无一例外地运行(第 3 行),但 AdaptiveMaxPool3d 抛出 RuntimeError:尝试创建具有负维的张量(第 4 行)。经过检查,我们发现 AdaptiveAvgPool3d 缺少对负整数维度的检查。这可能是灾难性的,因为用户可能会无意中将错误引入其模型中,但不会引发警告/异常。
3. 计算错误 (Equivalencevalue , ×)
图 12 中所示的 bug 是由 API 对 torch.std_mean 和 torch.mean 的 Equivalencevalue oracle 检测到的。他们俩都可以计算输入张量中所有元素的平均值。但是,DeepREL 发现,对于某些输入张量,torch.std_mean 的返回值与 torch.mean 不同。但是,开发人员表示,这两个 API 预计不会输出相同的平均值并被拒绝

结果
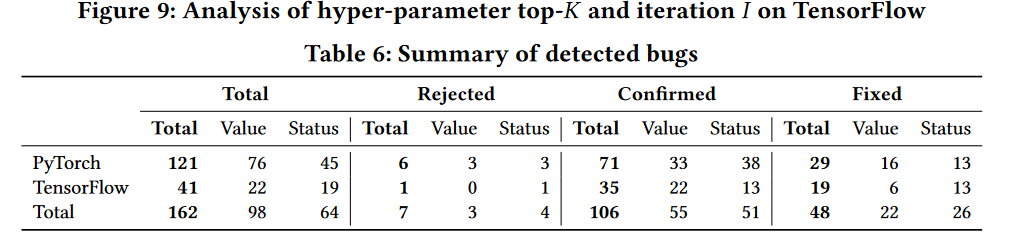
表 6 总结了 DeepREL 为所研究的 DL 库检测到的实际错误。“Total”列显示 DeepREL 检测到的 Bug 总数,“Value”和“Status”列分别显示使用 Equivalencevalue 和 Equivalencestatus 预言机检测到的 Bug 数。我们还列出了被开发人员拒绝的 bug 数量(“已拒绝”列)、确认为以前未知的 bug(“已确认”列)以及已修复的以前未知的 bug 的数量(“已修复”列)。我们可以观察到,DeepREL 总共能够检测到 162 个 bug,只有 7 个被开发人员拒绝,106 个被开发人员确认为以前未知的 bug(48 个已经修复),所有其他 bug 都在等待中。在这 106 个已确认的 bug 中,FreeFuzz 只能找到 9 个,CRADLE、AUDEE 或 LEMON 都无法检测到它们。此外,在实验过程中,我们还发现了 10 个 PyTorch 文档错误和 4 个 TensorFlow 文档错误(这些文档错误未包含在表 6 中)。
我们推出了 DeepREL,这是第一个通过推断关系 API 对 DL 库进行模糊测试的全自动端到端方法。DeepREL 可以从任何 API “借用”测试输入来测试其关系 API,并可以利用关系 API 作为执行差异测试的参考实现。对 PyTorch 和 TensorFlow 上的 DeepREL 的广泛研究表明,DeepREL 总共能够检测到 162 个 bug,其中 106 个已被开发人员确认为以前未知的 bug。值得注意的是,DeepREL 在三个月内检测到了整个 PyTorch 问题跟踪系统的 13.5% 的高优先级错误。此外,除了 162 个代码错误外,我们还能够检测到 14 个文档错误(全部已确认)。
- END -
::: block-2
一个只记录最真实学习网络安全历程的小木屋,最新文章会在公众号更新,欢迎各位师傅关注!
公众号名称:网安小木屋

博客园主页:
博客园-我记得https://www.cnblogs.com/Zyecho/
:::

 浙公网安备 33010602011771号
浙公网安备 33010602011771号