Pandas-缺失值处理
在一些数据分析业务中,数据缺失是我们经常遇见的问题,缺失值会导致数据质量的下降,从而影响模型预测的准确性,这对于机器学习和数据挖掘影响尤为严重。因此妥善的处理缺失值能够使模型预测更为准确和有效。
缺失值处理
构建数据集
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=[1, 3, 5, 7,8],columns=('F1','F2','F3')) df = df.reindex([1, 2, 3, 4, 5, 6, 7, 8]) print(df)
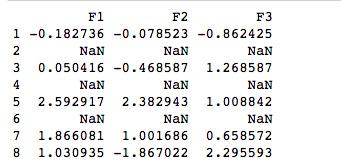
利用reindex形成缺失数据
检查缺失值
为了使检测缺失值变得更容易,Pandas 提供了 isnull() 和 notnull() 两个函数,它们同时适用于 Series 和 DataFrame 对象。
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=[1, 3, 5, 7,8],columns=('F1','F2','F3')) df = df.reindex([1, 2, 3, 4, 5, 6, 7, 8]) print(df['F1'].isnull()) print(df['F1'].notnull())
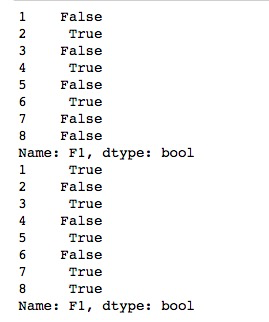
缺失数据计算
计算缺失数据时,需要注意两点:首先数据求和时,将 NA 值视为 0 ,其次,如果要计算的数据为 NA,那么结果就是 NA。示例如下:
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=[1, 3, 5, 7,8],columns=('F1','F2','F3')) df = df.reindex([1, 2, 3, 4, 5, 6, 7, 8]) print (df['F1'].sum()) print()
0.9233128233237275
清理并填充缺失值
Pandas 提供了多种方法来清除缺失值。fillna() 函数可以实现用非空数据“填充”NaN 值。
1) 用标量值替换NaN值
下列程序将 NaN 值 替换为了 0,如下所示:
print (df.fillna(0)) print (df['F1'].sum())
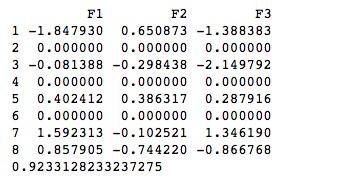
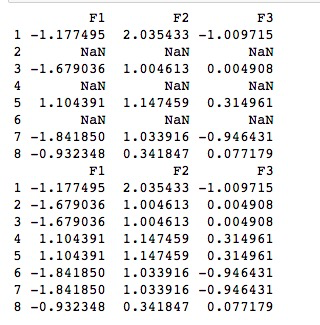
2) 向前和向后填充NA
ffill() 向前填充和 bfill() 向后填充,使用这两个函数也可以处理 NA 值。示例如下:
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=[1, 3, 5, 7,8],columns=('F1','F2','F3')) df = df.reindex([1, 2, 3, 4, 5, 6, 7, 8]) print(df) print (df.fillna(method='ffill'))
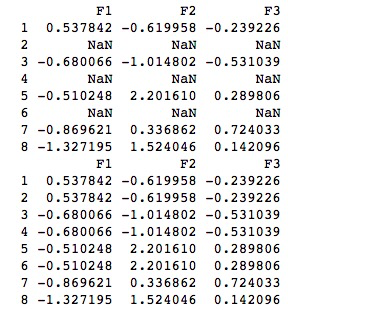
可以采用向后填充的方法
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=[1, 3, 5, 7,8],columns=('F1','F2','F3')) df = df.reindex([1, 2, 3, 4, 5, 6, 7, 8]) print(df) print (df.fillna(method='bfill'))
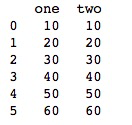
3) 使用replace替换通用值
在某些情况下,您需要使用 replace() 将 DataFrame 中的通用值替换成特定值,这和使用 fillna() 函数替换 NaN 值是类似的。示例如下:
import pandas as pd import numpy as np df = pd.DataFrame({'one':[10,20,30,40,50,-999], 'two':[-1111,0,30,40,50,60]}) #使用replace()方法 print (df.replace({-999:10,-1111:60,0:20}))
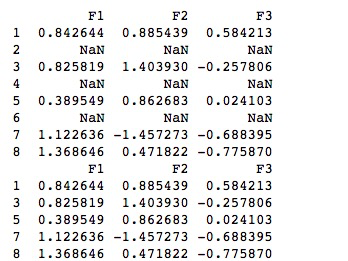
删除缺失值
如果想删除缺失值,那么使用 dropna() 函数与参数 axis 可以实现。在默认情况下,按照 axis=0 来按行处理,这意味着如果某一行中存在 NaN 值将会删除整行数据。示例如下:
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=[1, 3, 5, 7,8],columns=('F1','F2','F3')) df = df.reindex([1, 2, 3, 4, 5, 6, 7, 8]) print(df) print (df.dropna())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号