


Zookeeper
Zookeeper学习笔记
zookeeper是一个分布式协调框架,是分布是系统中的一个重要中间件。
安装
单机部署
-
zookeeper是完全使用java开发的,因此需要jdk运行环境。jdk运行环境准备此处不详细描述。
-
在官网下载最新版本的zookeeper安装包:
ubuntu@node01:~$ wget https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz -
解压压缩包
ubuntu@node01:~$ tar -xf apache-zookeeper-3.7.1-bin.tar.gz -
配置文件
ubuntu@node01:~/apache-zookeeper-3.7.1-bin/conf$ mv zoo_sample.cfg zoo.cfg ubuntu@node01:~/apache-zookeeper-3.7.1-bin/conf$ vi zoo.cfg # zoo.cfg里面的配置暂不修改,就是用默认的配置 -
启动服务
ubuntu@node01:~/apache-zookeeper-3.7.1-bin/bin$ ./zkServer.sh start ...... ubuntu@node01:~/apache-zookeeper-3.7.1-bin/bin$ ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /home/ubuntu/apache-zookeeper-3.7.1-bin/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: standalone
集群部署
上面的单机部署只是为了演示。zookeeper作为分布式中间件,为了分布式系统的稳定,肯定是要搭建集群的,保证系统稳定最低标准为3台zookeeper节点。
-
修改配置文件
# 为了方便,将文件夹重命名 ubuntu@node01:~$ mv apache-zookeeper-3.7.1-bin zookeeper ubuntu@node01:~$ cd zookeeper/ # 配置myid,另外两个节点 myid文件的值分别问2、3 ubuntu@node01:~/zookeeper$ mkdir data ubuntu@node01:~/zookeeper$ cd data ubuntu@node01:~/zookeeper/data$ echo '1' > myid ubuntu@node01:~/zookeeper/data$ ls myid ubuntu@node01:~/zookeeper/data$ cat myid 1 # 修改zoo.cfg ubuntu@node01:~$ cd ~/zookeeper/conf/ ubuntu@node01:~/zookeeper/conf$ vi zoo.cfg # 修改如下内容 dataDir=~/zookeeper/data dataLogDir=~/zookeeper/logs # 添加如下内容,集群所有节点信息 server.1=node01_ip:2888:3888 server.2=node02_ip:2888:3888 server.3=node03_ip:2888:3888 -
启动3个服务,查看日志

从上面日志可以看出,node01节点启动后,
my state: LOOKING, 此时服务仍是不可用的,还在处于选主的阶段。
而最后面,选主成功完成,
my state:FOLLOWING。
至此,zookeeper集群搭建成功。后面为了方便,本文集群搭建使用docker容器来进行。
docker编排文件:
version: '3.1'
services:
zoo1:
image: zookeeper
restart: always
hostname: node01
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
ZOO_LOG4J_PROP: "INFO,ROLLINGFILE"
ZOO_SERVERS: server.1=node01:2888:3888;2181 server.2=node02:2888:3888;2181 server.3=node03:2888:3888;2181 server.4=node04:2888:3888;2181 server.5=node05:2888:3888;2181
zoo2:
image: zookeeper
restart: always
hostname: node02
ports:
- 2182:2181
environment:
ZOO_MY_ID: 2
ZOO_LOG4J_PROP: "INFO,ROLLINGFILE"
ZOO_SERVERS: server.1=node01:2888:3888;2181 server.2=node02:2888:3888;2181 server.3=node03:2888:3888;2181 server.4=node04:2888:3888;2181 server.5=node05:2888:3888;2181
zoo3:
image: zookeeper
restart: always
hostname: node03
ports:
- 2183:2181
environment:
ZOO_MY_ID: 3
ZOO_LOG4J_PROP: "INFO,ROLLINGFILE"
ZOO_SERVERS: server.1=node01:2888:3888;2181 server.2=node02:2888:3888;2181 server.3=node03:2888:3888;2181 server.4=node04:2888:3888;2181 server.5=node05:2888:3888;2181
zoo4:
image: zookeeper
restart: always
hostname: node04
ports:
- 2183:2181
environment:
ZOO_MY_ID: 4
ZOO_LOG4J_PROP: "INFO,ROLLINGFILE"
ZOO_SERVERS: server.1=node01:2888:3888;2181 server.2=node02:2888:3888;2181 server.3=node03:2888:3888;2181 server.4=node04:2888:3888;2181 server.5=node05:2888:3888;2181
zoo5:
image: zookeeper
restart: always
hostname: node05
ports:
- 2183:2181
environment:
ZOO_MY_ID: 5
ZOO_LOG4J_PROP: "INFO,ROLLINGFILE"
ZOO_SERVERS: server.1=node01:2888:3888;2181 server.2=node02:2888:3888;2181 server.3=node03:2888:3888;2181 server.4=node04:2888:3888;2181 server.5=node05:2888:3888;2181
配置文件解析
2181、2888、3888端口的作用?
- 2181端口是提供给客户端连接的,对外提供服务。
- 2888端口是集群内部通信使用的,leader将消息同步给follower。
- 3888端口是选举leader时使用的。

启动node01节点,其他节点不启用的情况下,查看日志会发现这样的报错,无法连接到3/2的选举节点,后面跟的端口是3888,所以说3888是选举节点。
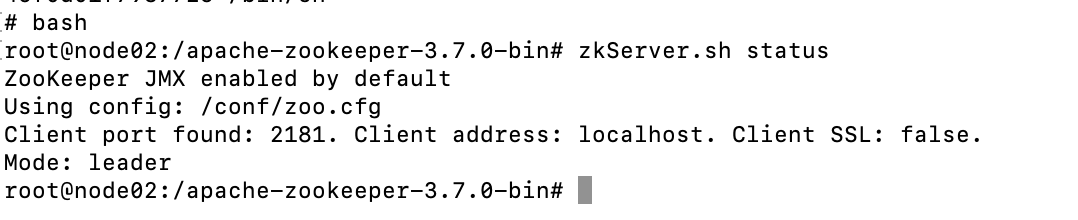
节点启动成功后,通过zkServer.sh status可以查看当前节点的状态,是leader还是follower。
可以看到node03节点是follower,打开node03节点的日志,可以看到如下内容:
follower通过2888端口与leader建立连接,同步leader的数据。
myid文件
myid文件主要是用来zookeeper集群选主阶段来表示自己的id大小,选主时使用。在zoo.cfg文件中,最后的集群配置为 server.myid, myid分别为集群其他节点对应的myid。
zoo.cfg属性
tickTime: leader与follower之间互相发送心跳的间隔时间,单位为ms。initTime: 初始延迟时间。leader允许follower最大延迟initTime * tickTime时间内向他发送心跳信息,如果超过时间没有收到,那么就会认为这个节点挂掉了。syncTime: 数据同步时间。当leader想要同步某些操作到follower时,最大允许时间为tickTime * syncTime,如果超过这个时间,那么就会认为该节点挂掉了。dataDir: zookeeper数据进行持久化时数据存放的目录dataLogDir:日志文件存放的位置clientPort: 客户端连接zookeeper服务时使用的端口号maxClientCnxns: 当前节点允许的最大客户端连接数server.myid: 集群节点信息peerType=observer:配置观察者节点,当配置此节点时,需要配合在server.myid后面追加:observer。如:node04为observer节点,那么需要在node04的zoo.cfg中添加此配置,并在集群所有节点的zoo.cfg中添加server.node04_myid=node04_ip:2888:3888:observer。
架构设计
登陆zookeeper官网,我们可以从官网页面获得如下信息:
架构图
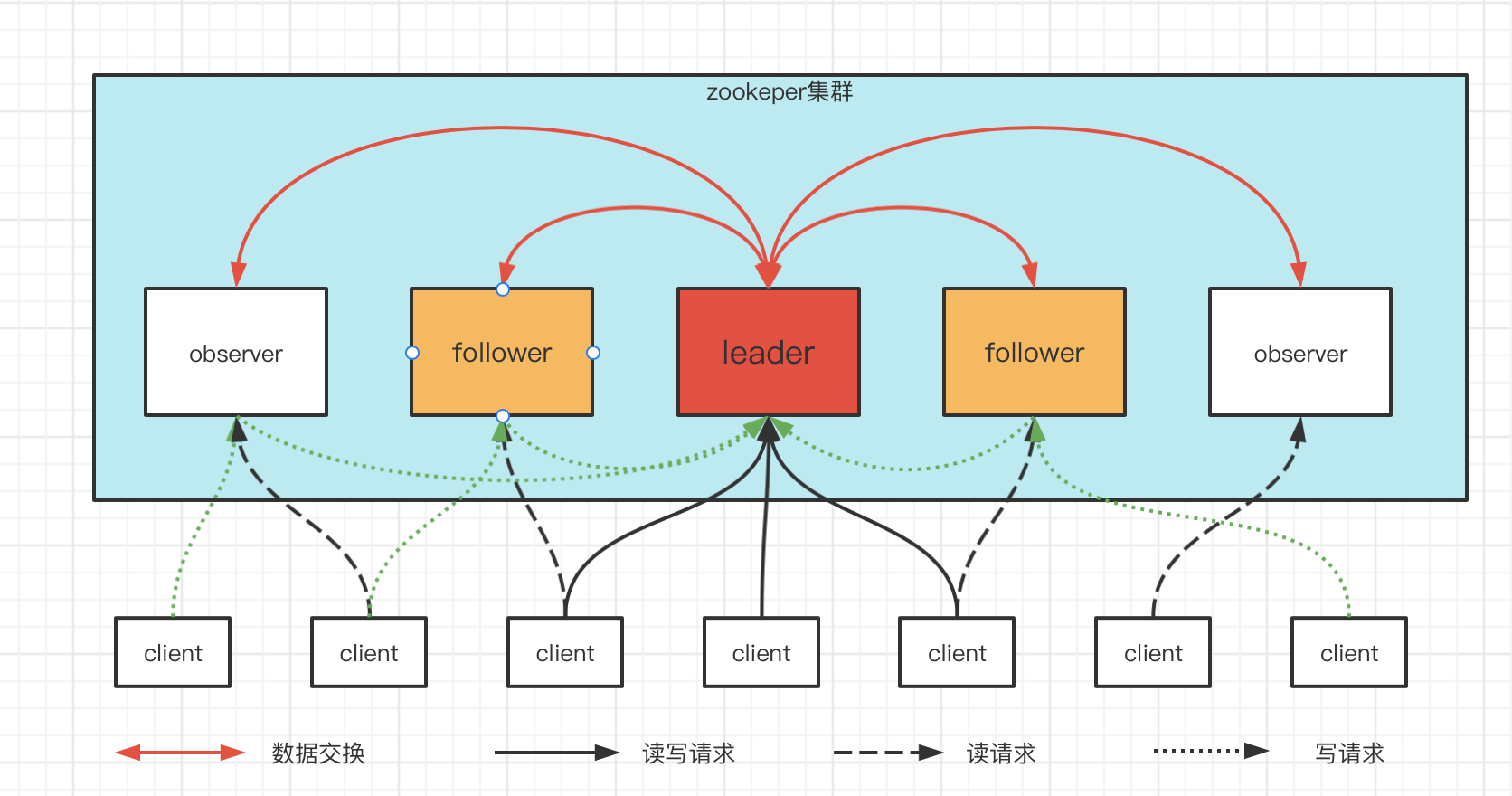
从上图中可以看出,zookeeper中主要包含3个角色:
leader:与子节点进行通信,向子节点同步数据并管理集群子节点的状态等信息;接受子节点转发过来的写请求;处理客户端的读写请求。follower:参与投票选举leader节点;接受客户端的读请求,并将写请求转发给leader节点。observer:观察leader、follower节点的状态,不参与投票;接受客户端的读请求,并将写请求转发给leader节点。可以理解observer只是为了横向拓展集群,增加读查询的能力。
同时从上图还可以看出:
- zookeeper是整个集群对外提供服务,client可以连接集群内的所有节点。
- 集群内的每个节点都可以接收客户端的读写请求,但是只有leader节点可以处理写请求。follower和observer会将写请求转发给leader节点进行处理。
可靠性
从上面的架构图我们可以很清晰的看到,zookeeper集群只有一个leader节点。看到这个我们应该快速的想到:leader肯定会挂。那么leader挂掉带来的问题就是:服务不可用(因为只有leader节点可以执行写操作,而且leader挂掉后,剩下的follower节点会开始重新选举leader节点,在这个选举过程中,整个服务是处于不可用状态的)。
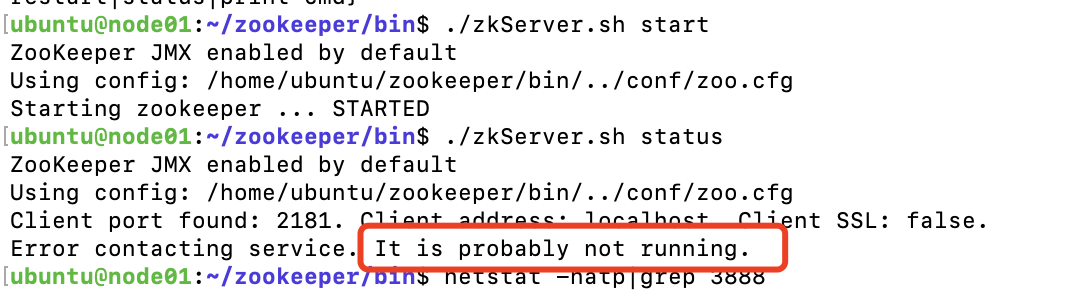
如上图,我们只启动zookeeper集群的一个节点,然后查看集群的状态,会发现此时节点启动成功了,但是服务还不能用。因为此时zookeeper正在进行选主操作,只有选出leader节点时,才能对外提供服务。
为了解决服务不可用的问题,那么需要解决的问题就是:leader挂掉时,尽快选举出新的leader。
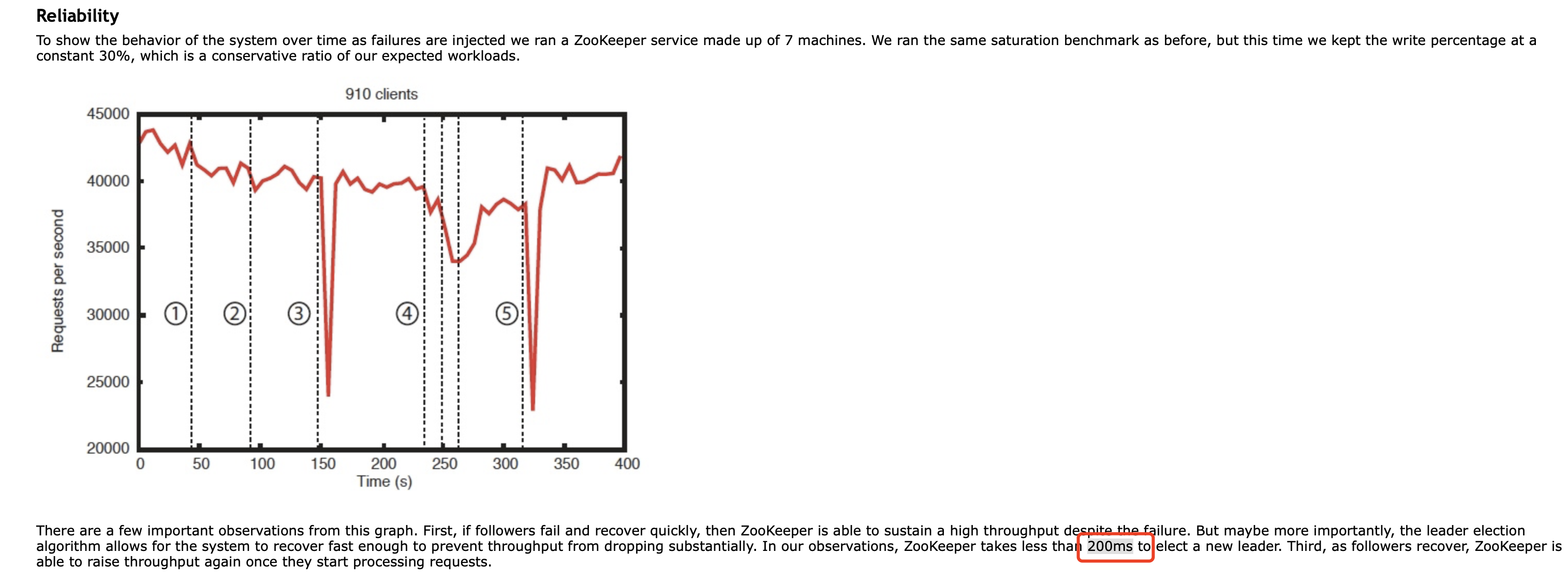
从官网可以看出,当leader挂掉时,只需要200ms就可以选举出新的leader,来保证服务的可用性。
从上面的内容还可以看出一个结论,zookeeper运行时,会有两个状态:可用和不可用,虽然zookeeper将这个不可用的时间降到了最低,但是还是有一段时间是不可用的。所以说zookeeper满足了CAP原则中的CP特性。
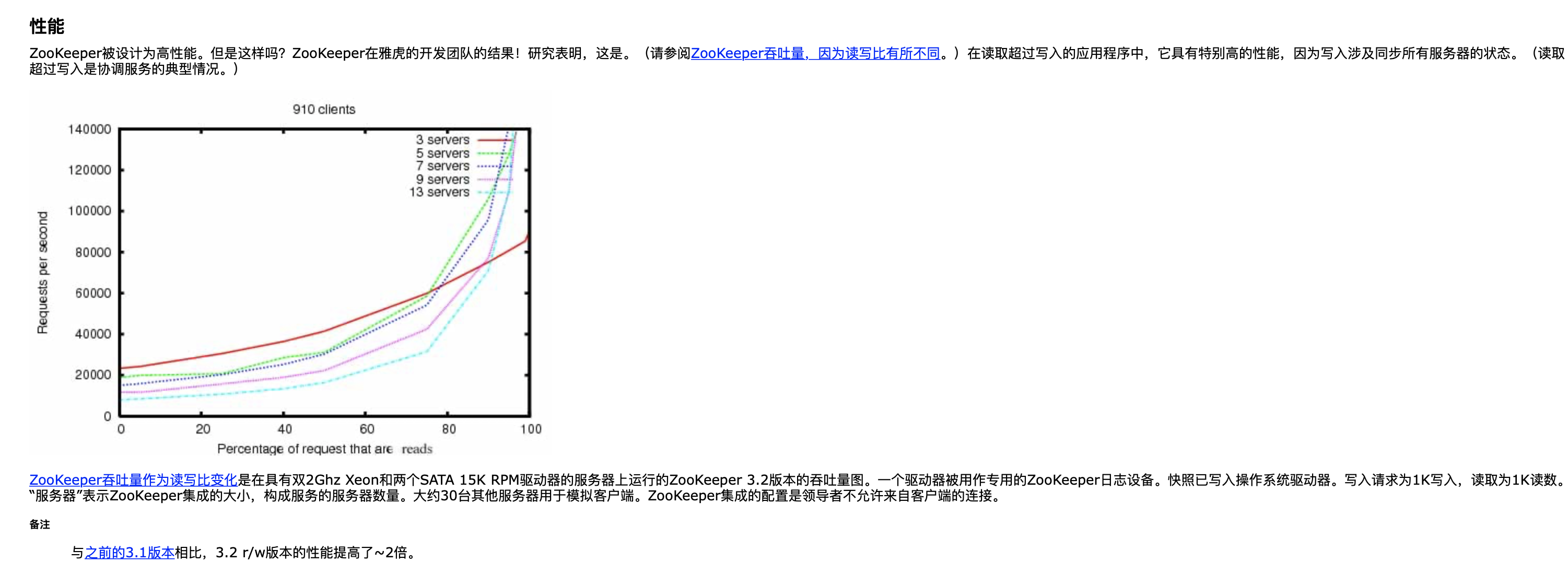
高性能
参见官网:
分层命名空间
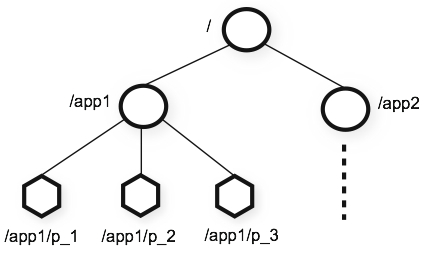
zookeeper提供了分层命名空间的概念,与标准文件系统非常相似。并提供了响应的原语来操作命名空间:
-
ls:查看节点下的子节点。使用
zkCli.sh命令联入zookeeper集群root@node01:/apache-zookeeper-3.7.0-bin/bin# ./zkCli.sh Connecting to localhost:2181 .... [zk: localhost:2181(CONNECTED) 0]使用ls命令,查看根目录下的子节点
[zk: localhost:2181(CONNECTED) 8] ls / [zookeeper]可以看到项目启动后,默认根节点下只有一个zookeeper节点。
-
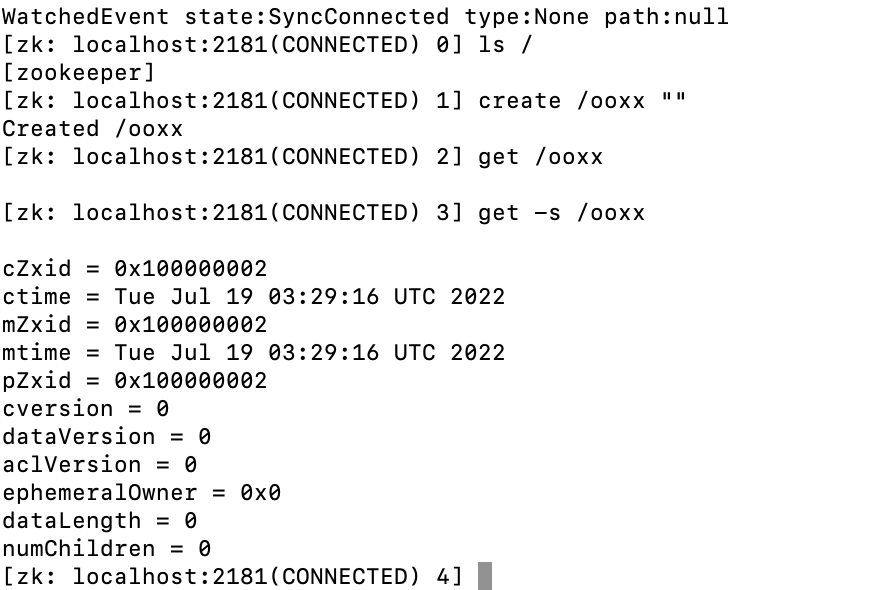
create: 创建一个节点(目录)可以通过create命令创建节点,
create [-s] [-e] path [data][zk: localhost:2181(CONNECTED) 9] create /ooxx Created /ooxx [zk: localhost:2181(CONNECTED) 11] ls / [ooxx, zookeeper]在老版本是,命令为
create [-s] [-e] path data,后面的data是必须要给的,如果不给会创建失败,可以给个空字符串"",但是必须要传data。例如:create path ""[zk: localhost:2181(CONNECTED) 31] create /xxoo "" Created /xxoocreate命令有两个参数:
[-s] [-e]注意:
-
-s 和 -e 参数可以同时存在,代表创建一个带序列的临时节点。
-
不能为临时节点创建子节点.
-
-
set: 为当前节点设置数据,zookeeper的命名空间与文件系统相似,但是zookeeper可以为每个节点存储数据。每个节点下最多可以设置1M的数据。每次set操作会将数据的版本号dataVersion+1。[zk: localhost:2181(CONNECTED) 56] set /xxoo "hello" -
get:获取当前节点的数据[zk: localhost:2181(CONNECTED) 4] get -s /xxoo hello cZxid = 0x100000003 ctime = Wed Jul 13 05:59:17 UTC 2022 mZxid = 0x100000004 mtime = Wed Jul 13 05:59:24 UTC 2022 pZxid = 0x100000003 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 5 numChildren = 0在老版本中,直接通过
get path,就可以拿到上面的信息,新版本只能拿到path下的data,所以需要加上-s。节点信息解析
从上面的信息中可以看出很多
Zxid,这其实代表是zookeeper中的事物id。cZxid: 创建此节点的事物id。ctime代表创建时间。c就代表createmZxid: 修改此节点的事物id(通过set命令来修改)。mtime代表修改时间。m就代表modifypZxid: 该节点的子节点最近一次创建/更新/删除的事物id。ephemeralOwner:如果当前节点是一个临时节点,那么就存此临时节点的sessionId。dataVersion: 数据版本。create新建的版本为0,每次set改动都会将版本号+1。
-
delete/rmr:删除节点,老版本是rmr命令,新版本3.7.0后使用delete代替。[zk: localhost:2181(CONNECTED) 6] delete /ooxx当前节点存在子节点时,不能直接删除当前节点,可以通过deleteall命令删除。
注意:
- 虽然zookeeper可以通过命名空间来存储数据,但是请不要将zookeeper当作数据库来使用,不要在zookeeper中储存太多业务相关的数据。
- zookeeper中的数据是存放在内存中的,只有存放在内存中才能支撑起zookeeper快速的查询,而数据存放在内存就一定会伴随着数据持久化。zookeeper是通过snapshot和log来持久化数据的。关于持久化可以参考zookeeper系列(四):持久化
Zxid
前面讲zookeeper满足了CAP原则中的CP特性,P很好理解,只要是集群都可以满足,那么C一致性是如何保证的?
答案就是Zxid,也叫事物id(准确说是通过ZAB协议保证的)。在之前的架构图中我们了解到:在zookeeper集群中,所有的写操作都是有leader来执行的。那么要保证数据的一致性,就是要保证leader同步数据到follower这个过程的一致性,这个过程就是通过zxid来完成的。
从上面拿一个Zxid来讲解:cZxid = 0x100000003。 0x代表是16进制的,这里是隐藏了高32位前面的0,实际应该是:0x00000001 00000003整个事物id分为高32位和低32位。
- 高32位用来表示leader的周期变化。每次发生leader发生变化时,高32位+1。
- 低32位递增计数。
整个Zxid时顺序递增,可以通过Paxos协议更好的理解Zxid。
验证zxid
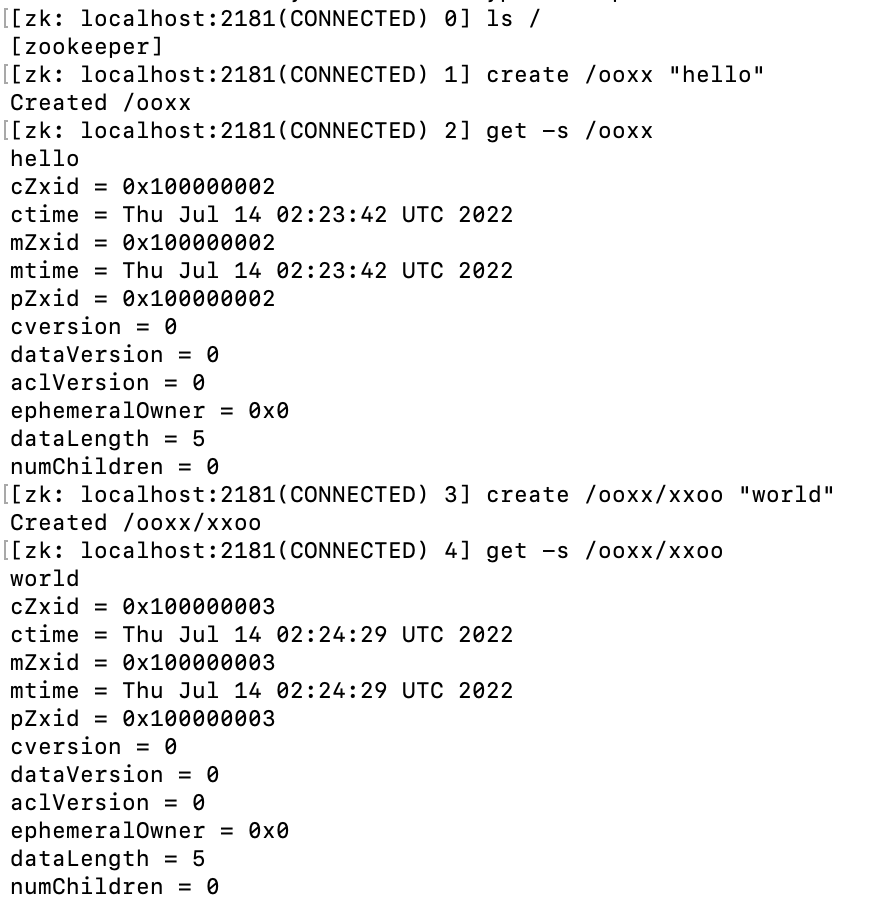
从上图可以看出zxid是递增的,每次创建都会消耗一个zxid。
细心的同学可能会发现,第一次创建节点,zxid应该从01开始的,但是实际却是从02开始的,后面session会解释。
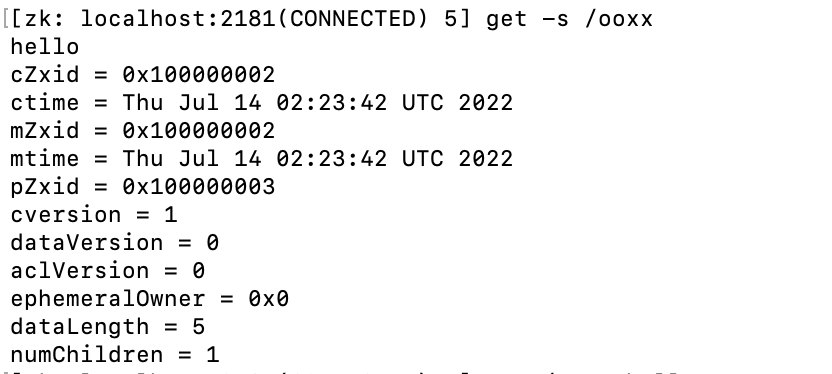
上图验证了pZxid。
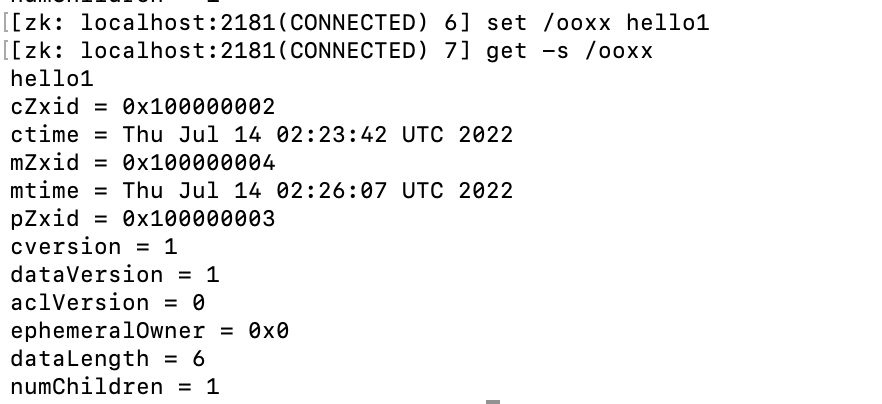
set操作也消耗了一个zxid,并且只改变了mzxid字段。
此时我们把leader宕机,选出新的leader节点后,再来看: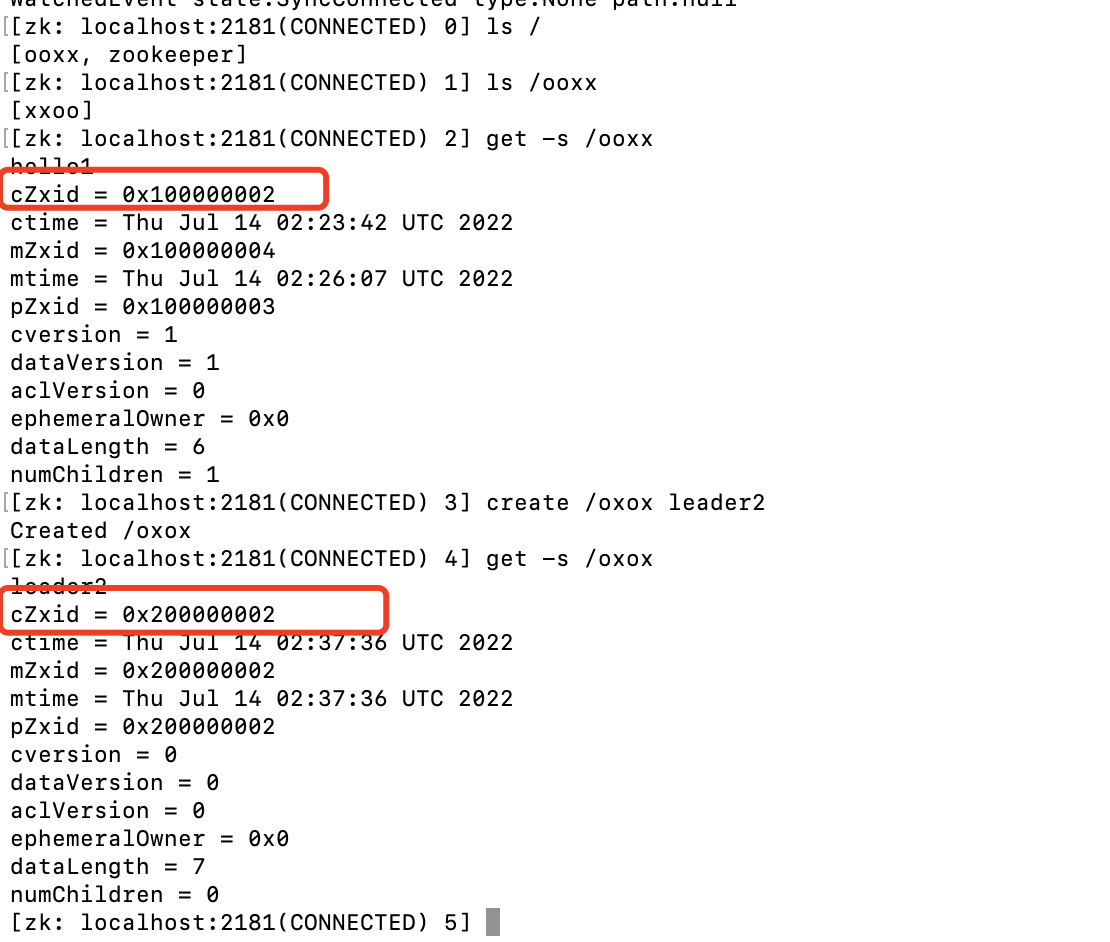
从上图可以看出,之前创建的节点,zxid的高32位是1,但是新创建的节点,zxid的高32位变成了2,并且低32位也从0开始递增。

可以在这里看出当前的leader是第几轮。当所有服务都停掉之后,从新启动服务时也会从这里加载之前的leader,保证zxid的顺序不会重复。
持久节点和临时节点
session会话
在了解持久节点和临时节点前,首先还需要了解如下知识:
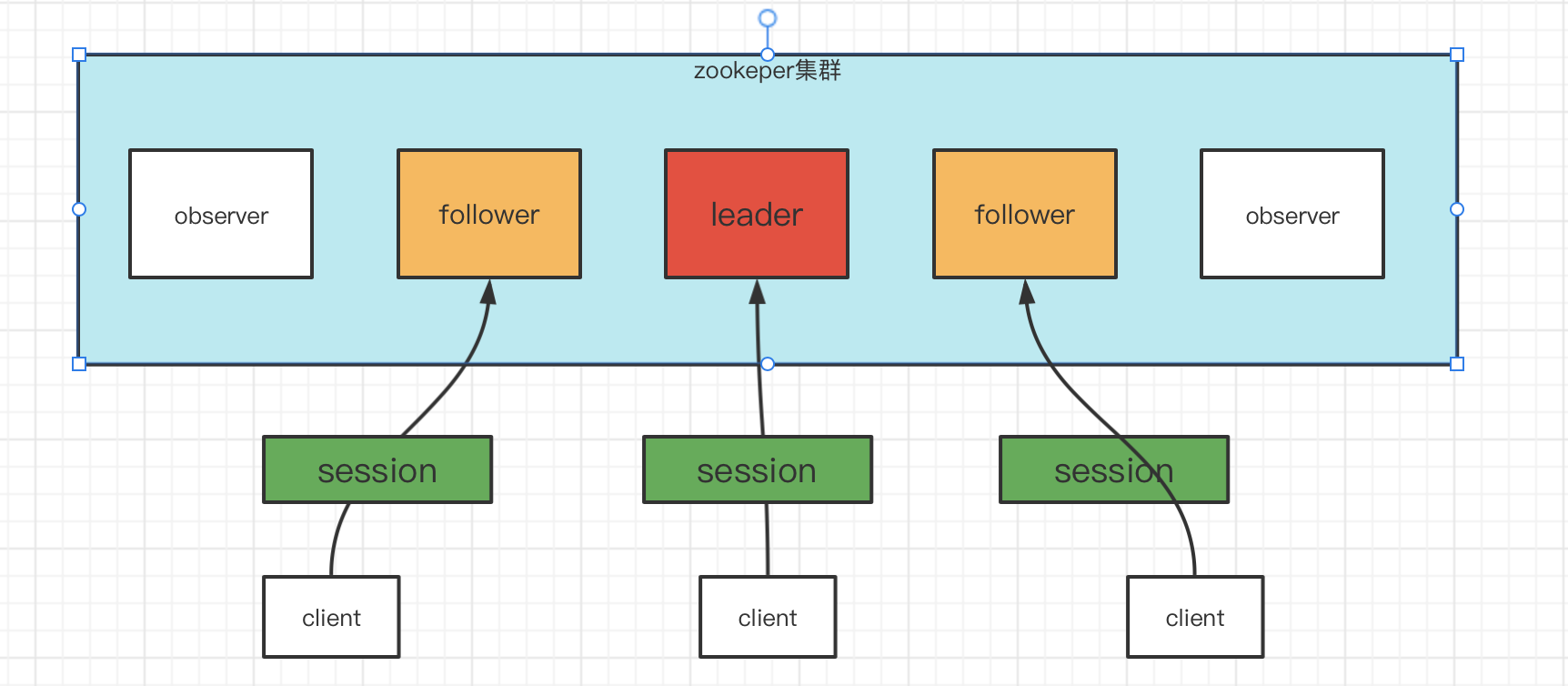
如上图,client在与zookeeper集群建立连接时,会为每个client建立一个会话,每个会话都会有一个sessionId,并且这个sessionId会同步到所有的follower节点中去。
验证session会话
将zookeeper集群状态恢复刚安装完成的状态。启动集群,通过tail监听leader的日志,通过zkCli.sh连接follower节点,可以看到如下日志:

此时再去查看任意一台follower的日志,可以看到如下:

从上面我们可以看出发生了session同步,并且消耗了一个Zxid:0x1 00000001(所以上面验证zxid是从2开始的)。
持久节点
持久节点是指通过create path data创建的节点,前面通过create创建的节点都属于持久节点。
临时节点
临时节点是通过create -e path data创建的节点,此类节点与sessionId绑定。

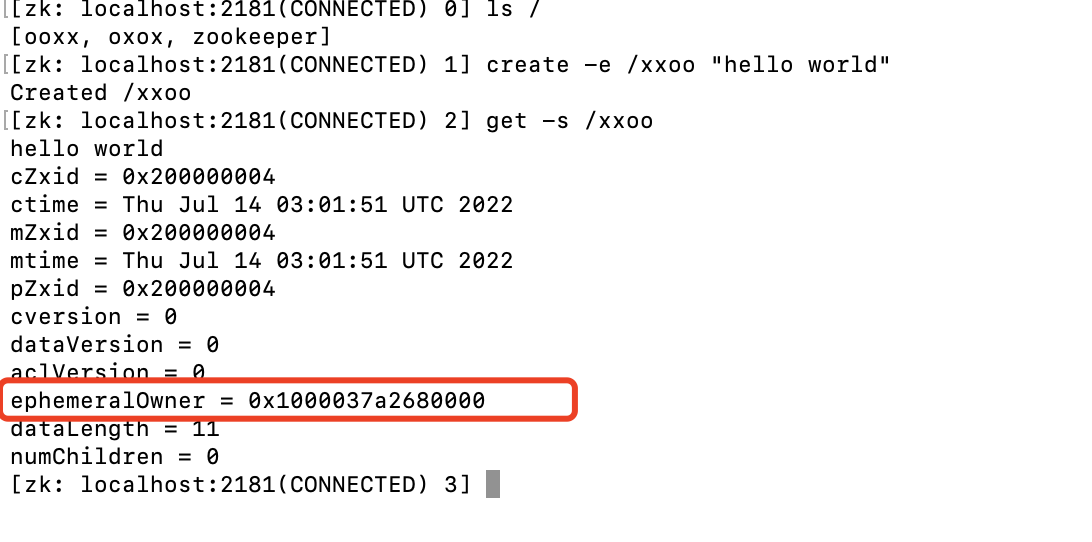
可以看到节点信息的ephemeralOwner与此次连接的sessionId是一样的。当我们退出此次连接时
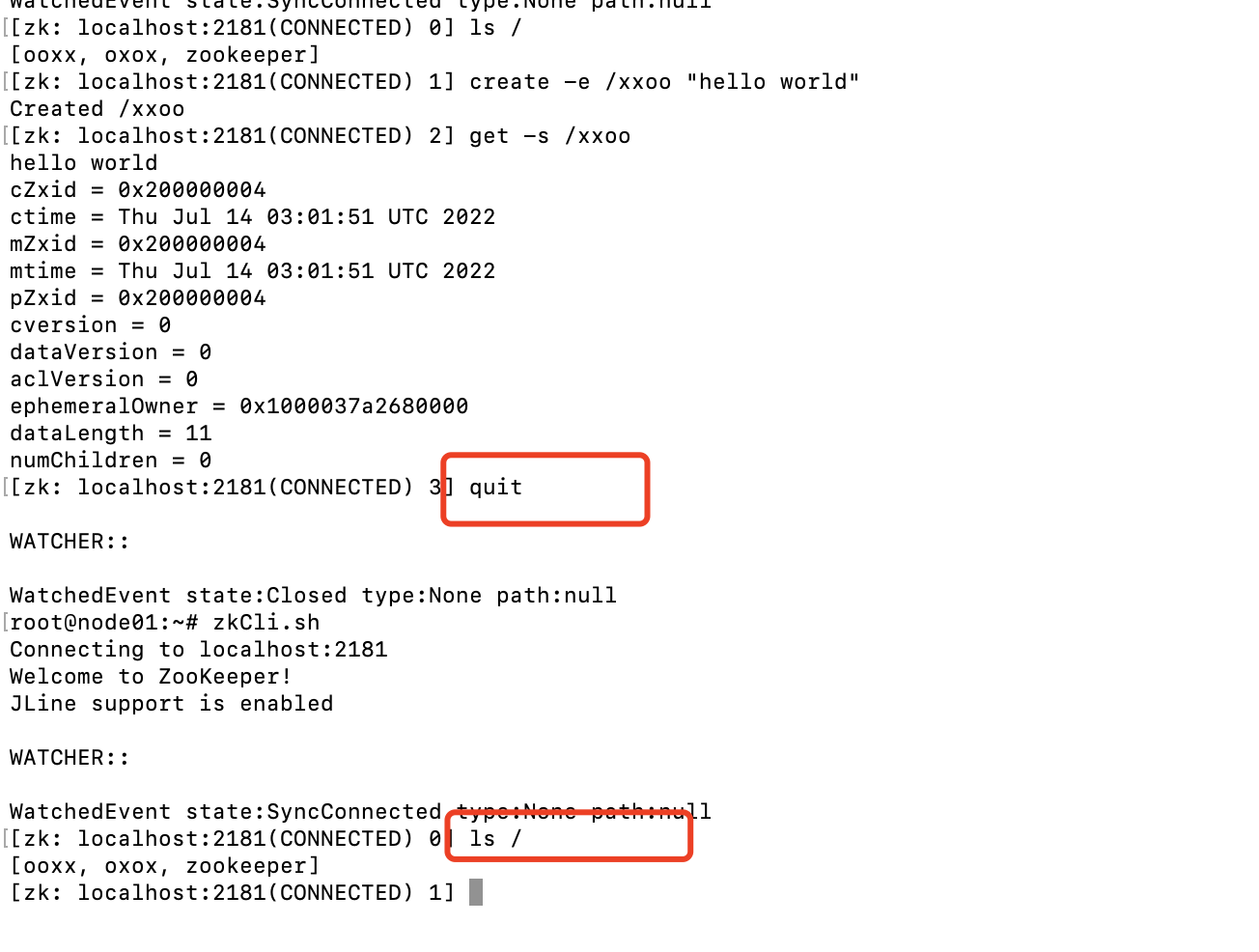
可以看到之前创建的xxoo节点随着上次会话的结束已经销毁。
-
当client连接的zookeeper节点挂掉时,临时目录是否会消失?
因为临时节点是与session绑定的,当client连接的节点挂掉时,那么client一定会与当前的集群断开连接,那么此时临时节点是否会随着session的断开而消失?
并不会。前面提到过,sessionId会通过leader同步到zookeeper的各个节点上去,同时,客户端也会缓存sessionId。如果因为zookeeper节点挂掉时导致连接断开,下次客户端请求带着sessionId去请求,仍然可以看到之前创建的节点信息。
序列节点
通过create -s path data,可以创建序列节点。在之前入过重复创建相同路径的节点时,会提示节点已经存在:

可以通过序列节点来重复创建相同名字的节点:

可以看到通过-s生成的序列节点,会自动在path后面追加序列号,序列号从0开始,由leader统一维护。leader内部维护一个字增序列,由于leader只有一个,因此可以保证不会重复。
持久节点和临时节点都可以生成序列节点。
临时节点和序列节点常被用来实现分布式锁。
paxos算法(zookeeper的核心)
Paxos算法网上有文章写的很好,所以这里引用了文章内容:Zookeeper全解析——Paxos作为灵魂
Paxos描述了这样一个场景,有一个叫做Paxos的小岛(Island)上面住了一批居民,岛上面所有的事情由一些特殊的人决定,他们叫做议员(Senator)。议员的总数(Senator Count)是确定的,不能更改。岛上每次环境事务的变更都需要通过一个提议(Proposal),每个提议都有一个编号(PID),这个编号是一直增长的,不能倒退。每个提议都需要超过半数((Senator Count)/2 +1)的议员同意才能生效。每个议员只会同意大于当前编号的提议,包括已生效的和未生效的。如果议员收到小于等于当前编号的提议,他会拒绝,并告知对方:你的提议已经有人提过了。这里的当前编号是每个议员在自己记事本上面记录的编号,他不断更新这个编号。整个议会不能保证所有议员记事本上的编号总是相同的。现在议会有一个目标:保证所有的议员对于提议都能达成一致的看法。
好,现在议会开始运作,所有议员一开始记事本上面记录的编号都是0。有一个议员发了一个提议:将电费设定为1元/度。他首先看了一下记事本,嗯,当前提议编号是0,那么我的这个提议的编号就是1,于是他给所有议员发消息:1号提议,设定电费1元/度。其他议员收到消息以后查了一下记事本,哦,当前提议编号是0,这个提议可接受,于是他记录下这个提议并回复:我接受你的1号提议,同时他在记事本上记录:当前提议编号为1。发起提议的议员收到了超过半数的回复,立即给所有人发通知:1号提议生效!收到的议员会修改他的记事本,将1好提议由记录改成正式的法令,当有人问他电费为多少时,他会查看法令并告诉对方:1元/度。
现在看冲突的解决:假设总共有三个议员S1-S3,S1和S2同时发起了一个提议:1号提议,设定电费。S1想设为1元/度, S2想设为2元/度。结果S3先收到了S1的提议,于是他做了和前面同样的操作。紧接着他又收到了S2的提议,结果他一查记事本,咦,这个提议的编号小于等于我的当前编号1,于是他拒绝了这个提议:对不起,这个提议先前提过了。于是S2的提议被拒绝,S1正式发布了提议: 1号提议生效。S2向S1或者S3打听并更新了1号法令的内容,然后他可以选择继续发起2号提议。
好,我觉得Paxos的精华就这么多内容。现在让我们来对号入座,看看在ZK Server里面Paxos是如何得以贯彻实施的。
- 小岛(Island)——ZK Server Cluster
- 议员(Senator)——ZK Server
- 提议(Proposal)——ZNode Change(Create/Delete/SetData…)
- 提议编号(PID)——Zxid(ZooKeeper Transaction Id)
- 正式法令——所有ZNode及其数据
貌似关键的概念都能一一对应上,但是等一下,Paxos岛上的议员应该是人人平等的吧,而ZK Server好像有一个Leader的概念。没错,其实Leader的概念也应该属于Paxos范畴的。如果议员人人平等,在某种情况下会由于提议的冲突而产生一个“活锁”(所谓活锁我的理解是大家都没有死,都在动,但是一直解决不了冲突问题,例如:有3个议员,同时提出了提议1,然后都互相拒绝了提议1,又继续重新发起了提议1....)。Paxos的作者Lamport在他的文章”The Part-Time Parliament“中阐述了这个问题并给出了解决方案——在所有议员中设立一个总统,只有总统有权发出提议,如果议员有自己的提议,必须发给总统并由总统来提出。好,我们又多了一个角色:总统。
- 总统——ZK Server Leader
现在我们假设总统已经选好了,下面看看ZK Server是怎么实施的。
- 情况一:读数据
屁民甲(Client)到某个议员(ZK Server)那里询问(Get)某条法令的情况(ZNode的数据),议员毫不犹豫的拿出他的记事本(local storage),查阅法令并告诉他结果,同时声明:我的数据不一定是最新的。你想要最新的数据?没问题,等着,等我找总统Sync一下再告诉你。- 情况二:写数据
屁民乙(Client)到某个议员(ZK Server)那里要求政府归还欠他的一万元钱,议员让他在办公室等着,自己将问题反映给了总统,总统询问所有议员的意见,多数议员表示欠屁民的钱一定要还,于是总统发表声明,从国库中拿出一万元还债,国库总资产由100万变成99万。屁民乙拿到钱回去了(Client函数返回)。- 情况三:leader挂了
总统突然挂了,议员接二连三的发现联系不上总统,于是各自发表声明,推选新的总统,总统大选期间政府停业,拒绝屁民的请求。
paxos协议最重要的一个概念就是超过半数。
ZAB协议
通过上面的文章,对paxos协议有了深入的了解。zookeeper在设计的时候,基于paxos协议,设计了更简单的ZAB协议:Zookeeper Atomic Broadcast协议(Zookeeper原子广播协议)。
- 原子性:一次操作要么成功,要么失败,不会存在中间状态。
- 广播:leader接收写请求后,会将请求转换成一个事物,leader要将事物广播给所有的follower。
zookeeper主要通过ZAB协议来保证一致性,也就是CP原则里的C。
一致性可以分为强一致性、弱一致性、最终一致性。
- 强一致性: 要求主节点必须等到所有的从节点都同步完数据后才会响应客户端。如果从节点挂了或者网络阻塞,那么主节点就会一直等待从节点的响应,造成服务的不可用。
- 弱一致性:主节点不强制要求从节点一定能同步自己的数据。结果就是可能集群内的不同节点数据不一致,但是换来了可用性。
- 最终一致性:最终一致性是在强一致性和弱一致性之间取的一个平衡,在保证服务可用性的前提下,只要节点中的数据在某个时间或状态下最终能够保证一致就可以。
再来回顾一下Paxos协议中的内容:
发起提议的议员收到了超过半数的回复,立即给所有人发通知:1号提议生效!
从上面的内容我们可以看出,zookeeper其实是满足的最终一致性。
具体到ZAB协议体现在:
leader将所有的写请求转换成事务(先写入本地日志),并广播给所有的follower(follower写入本地日志),只要有超过一半的follower确认收到,那么leader就会向所有的follower发送commit消息(将数据写入内存)。
leader向follower广播事务时,此时是一个同步阻塞的操作,为了提升性能,同时也为了解藕,还有就是为了保证follower按照zxid的顺序进行处理,保证消息的有序性。ZAB协议引入了队列,通过队列来完成leader与follower之间的通信。leader会为每个follower和observer维护一个队列。
通过上面的了解,可以画出ZAB协议流程图:
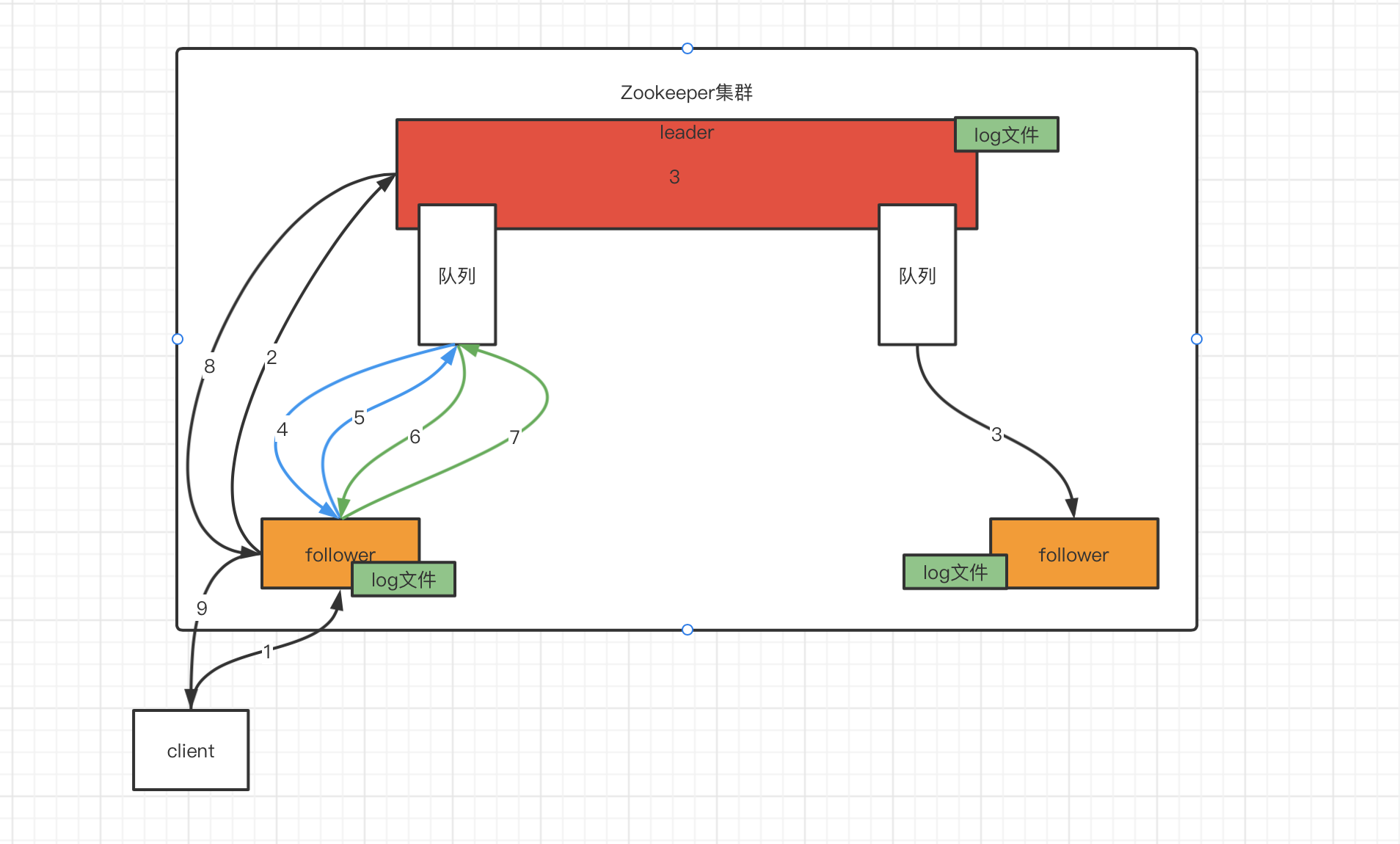
- client向follower发送写请求
- follower将写请求转发到leader
- leader将写请求转成事务,将事物写入log文件并广播给所有的follower(假设此时右边的follower网络延迟/挂了无法响应消息)
- follower从队列中读到消息,将事物写入log日志
- follower写入log成功,返回ack消息
- leader收到超过半数(leader自己会ack,左边follower返回ack)的ack消息,向follower发送commit消息,并将数据写入内存
- follower返回的commit消息的ack消息,并将数据写入内存
- leader响应将请求转发给他的follower
- follower响应client
此时,如果右边的follower有client连接上时,可以读消息,如果读到的消息不是最新的,可以通过sync从leader同步消息。
上面过程只有leader收到超过半数的ack时才会发送commit消息,如果少于半数,例如两个follower都挂了,那么服务就会处于不可用状态,可以尝试手动将两个follower服务关闭后,查看leader的状态。
选举机制
zab协议除了用在上面的消息广播上面,还存在选举机制上,也叫崩溃恢复模式。选举过程会出现在一下两种场景:
- 集群初始化选举
- leader挂掉,follower重新选举
在了解选举过程前要先想一个问题:什么样的节点才能当主节点?类比到Paxos协议的小故事中:什么样的人才适合当岛主?
- 资历最老的,经验最丰富的
- 年龄最大的
集群初始化选举
集群初始化,类比到paxos协议中就相当于一群人刚到这个小岛,大家都不熟悉,那么此时按照上面的要求来推举岛主,首先肯定是要求经验最丰富的。但是大家都是刚认识,不知道谁的经验丰富,那么就只能推举一个年龄最大的(一般年龄大的,默认经验都比较丰富)。类比到zookeeper集群中,myid就相当于是年龄。同时,paxos的核心思想超过半数同样也使用在选举过程中,具体体现在:参与选举的人数是固定的,大家开始一个一个的投票,只要有一个人投票时超过半数,并且比之前的大,那么它就是leader,即使后面还有比他大的,也只能把票投给leader,不能再参与竞争了。
验证推论
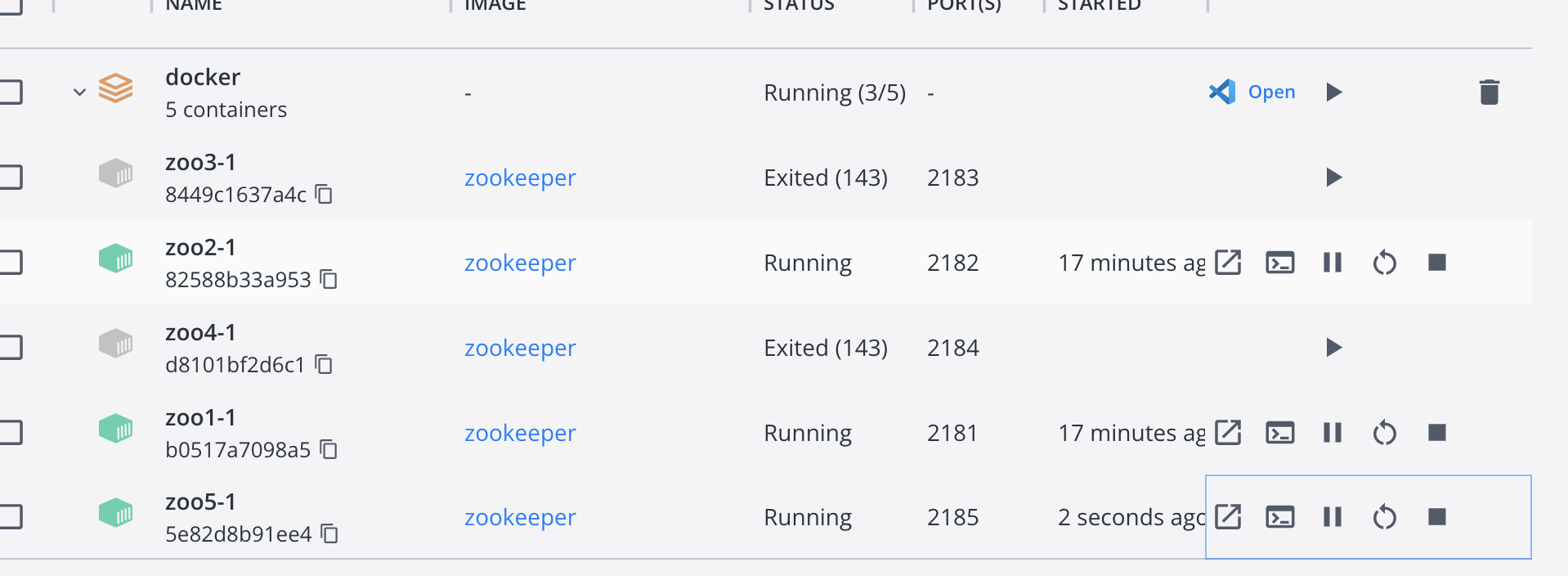
使用docker容器编排来创建5个节点,可以看到5个节点的myid分别为1、2、3、4、5。如果此时启动上面5个节点,那么根据paxos协议,超过半数(总节点数/2)+1)也就是第3台肯定是leader。下面启动docker容器docker-compose -f zoo.yml up -d。
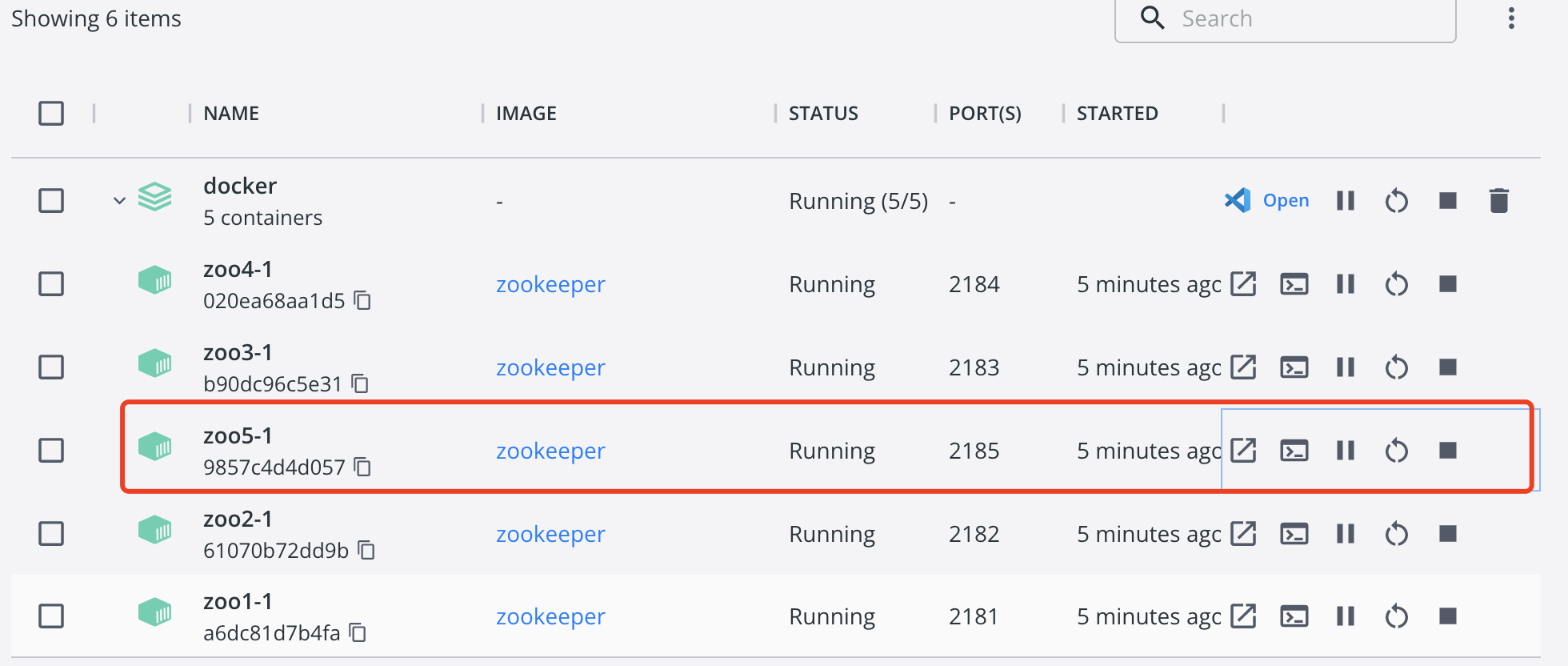
可以看到第3台为node05的节点,进入此节点的终端:
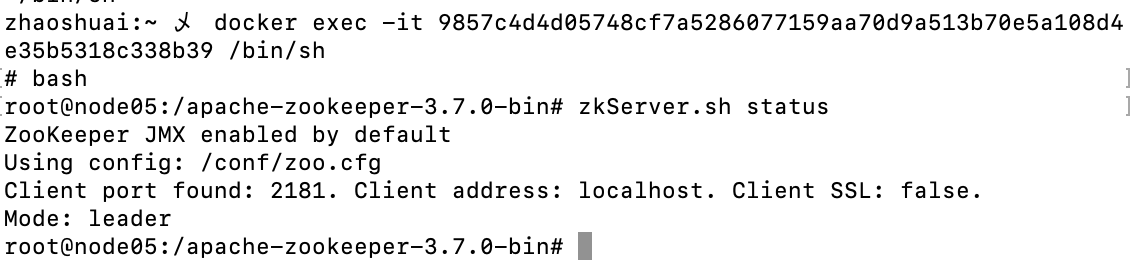
可以看到此节点确实为leader。
将所有的节点全部停掉,并清理掉data文件夹,我们一台一台的启动节点:
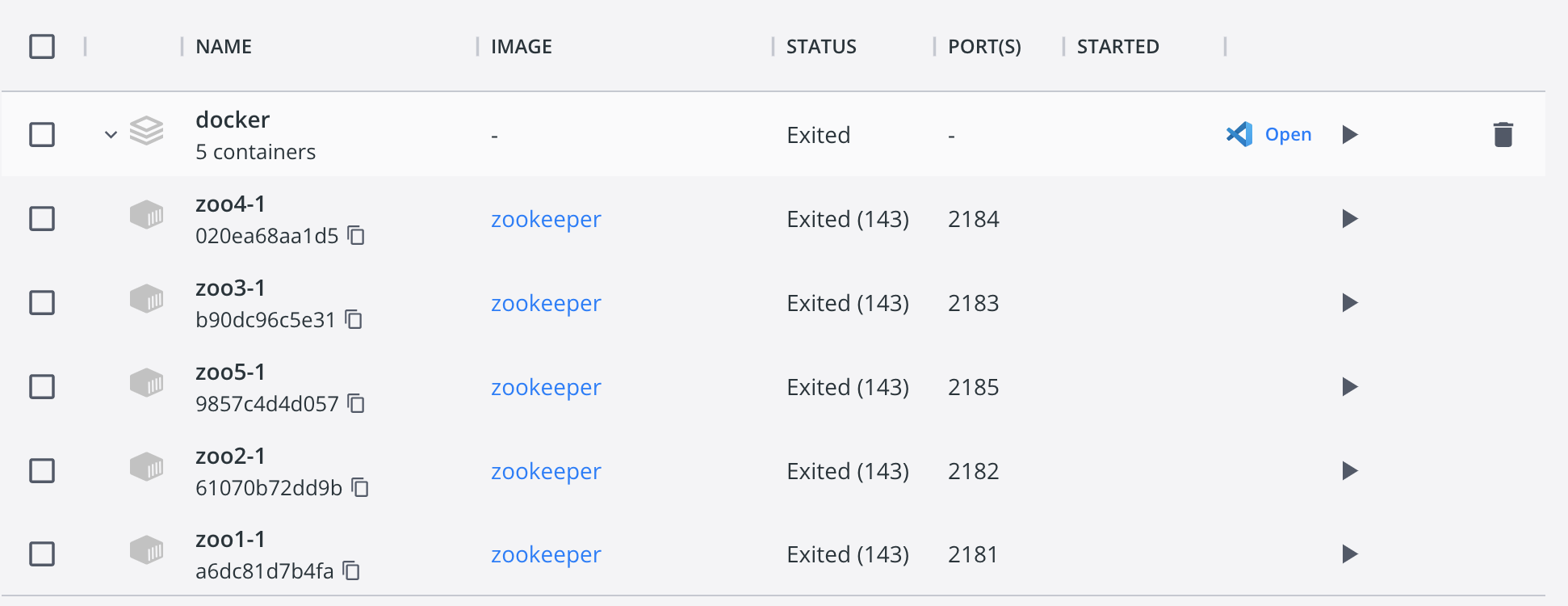
可以看到此时节点是全部停掉的。此时我们随便按照一个顺序,例如:5,2,4,1,3启动节点,那么先来猜测,首先根据经验选举,5台节点的经验是一样的(都是初始状态),那么就只能按照年龄来选举,根据超过半数选举原则,在启动节点4时,就可以选出leader,而前3台启动的服务里,myid为5的是最大的,因此可以得出5就是leader。下面按照上面的顺序5,2,4启动3个容器:
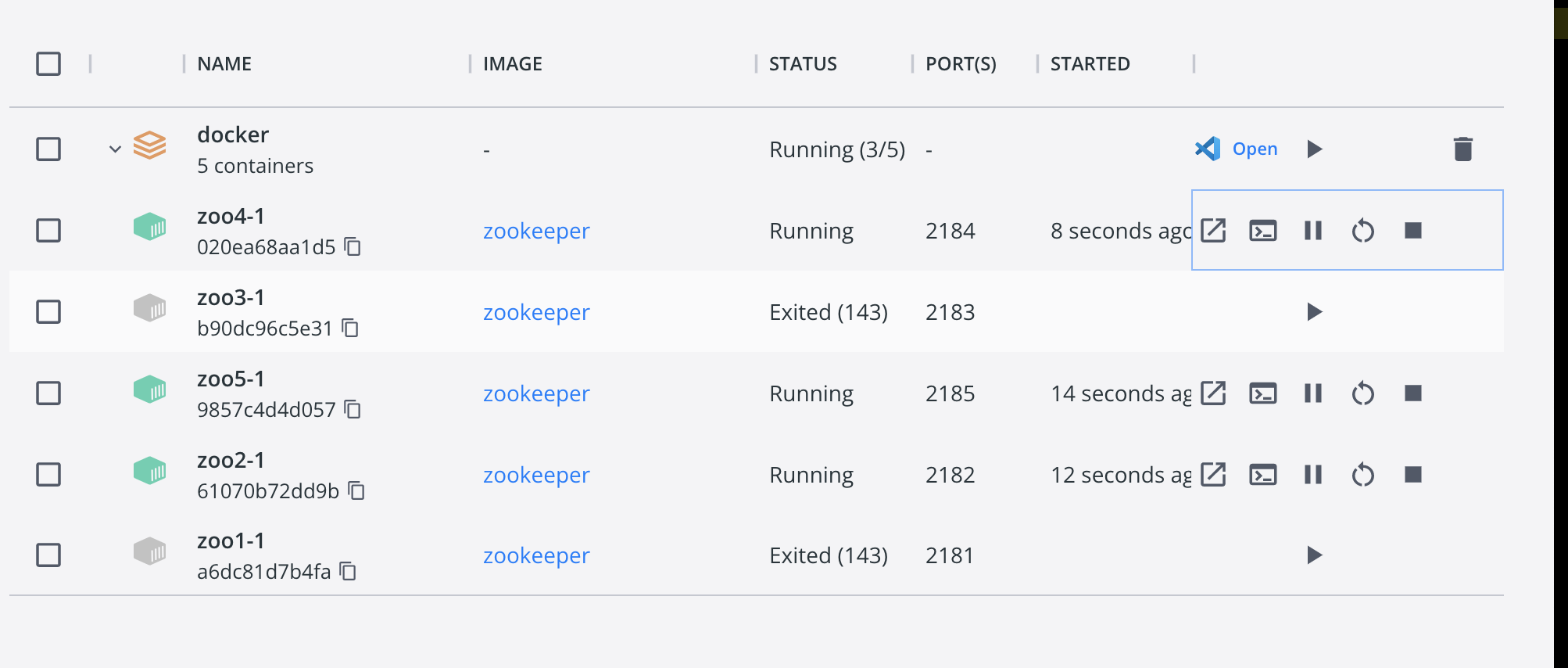
直接进入zoo5的容器控制台,查看zk状态:

可以看到完全验证了上面的推论,只启动了3台节点,就选出了leader。(感兴趣可以试试其他的排列组合,推测谁是leader并验证)
选举过程分析
将上面的所有节点全部停掉,按照myid的顺序,1、2、3、4、5来启动节点,查看节点日志来分析:
-
启动node01,查看node01的日志:

可以看到node01在不停的与2、3、4、5`的3888端口建立连接,参与选举。此时node01给自己投了一票,认为自己是leader:

sid代表服务器id。
-
启动node02,node02给自己投了一票,查看node02的日志:
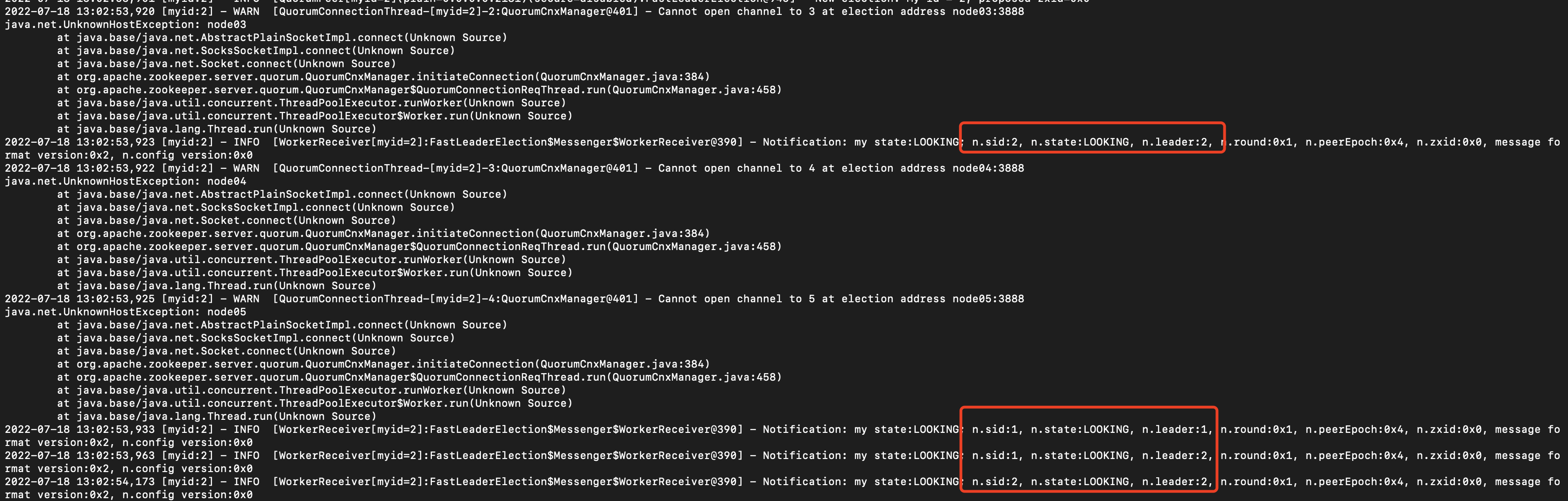
可以看到,node02启动后,首先给自己投了一票,认为自己是leader。然后收到了node01的消息,node01说:node01是leader,然后node02发现自己的myid比node01要大,然后就告诉他,node02才是leaer。然后后面又收到了node01(n.sid:1)和node02(n.sid:2)都认为node02是leader(后面此部分不再演示)。
后面node02只尝试与
3、4、5节点的3888端口建立连接,因为它已经与node01的3888端口建立了连接,它已经可以与node01通信,node01不需要再与它的3888端口建立连接。查看node01的日志:
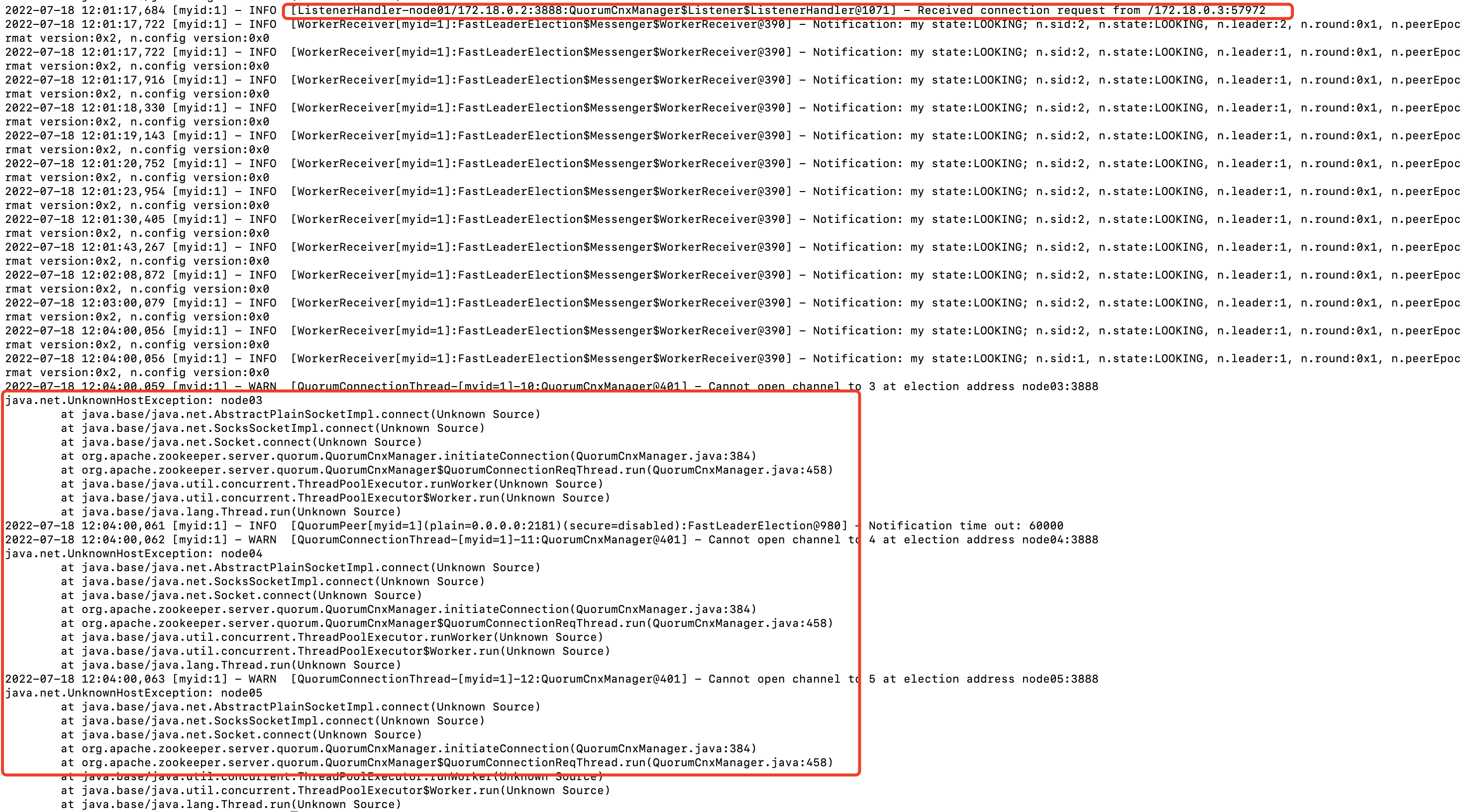
node01已经通过node02的57972端口与自己的3888端口建立了连接,此时只等待与3,4,5建立连接。
-
启动node03,此时已经超过半数,可以选出leader了,查看node01节点日志:
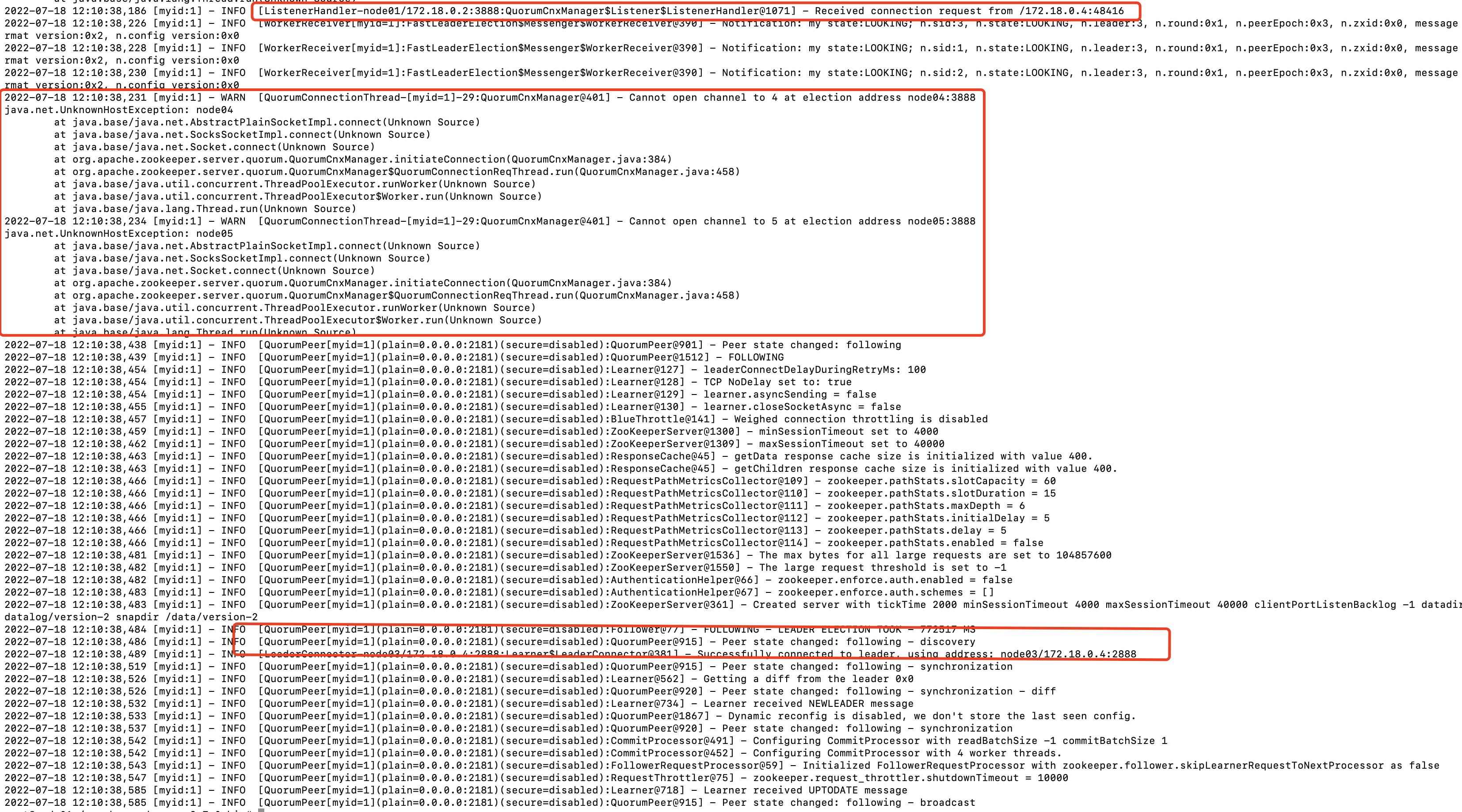
可以看出刚与node03建立连接时,此时还未选举出leader,还在同时等待与node04和node05建立连接,后面选举leader成功了,就直接从leader同步数据了,不再尝试与剩下的follower通过3888通信,因为leader已经选举完成了。并且follower开始通过leader的2888端口想自己同步数据了。
再查看node03节点日志:

同样的,确定自身是leader之后,就不再尝试与4和5建立连接了,因为自身已经是leader了,服务已经可以对外提供服务了,后面4和5如果启动了,就通过2888从leader同步数据,如果不起也不会影响当前服务的使用。
-
启动node04节点,查看日志:
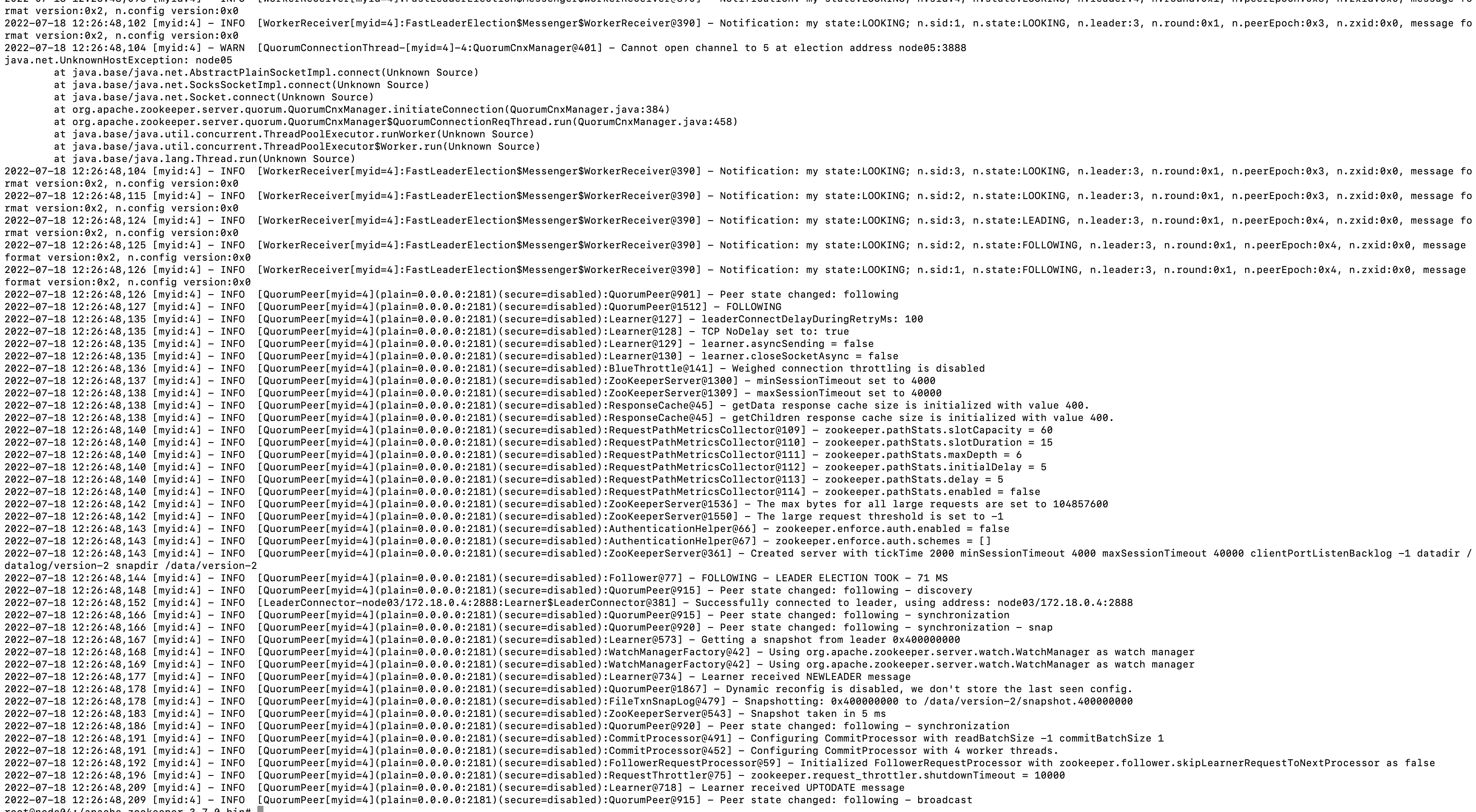
node04刚启动时选举投票,与其他节点的3888端口建立连接,然后发现已经存在leader了,那么就直接从leader同步数据了。
-
不用启动也可以猜到,节点5启动后,其他节点都启动了,直接与所有节点的3888端口建立连接,然后发现leader已经存在,直接从leader同步数据。
在上面的启动过程其实可以发现一个共性:
-
所有的节点启动后都会尝试与其他节点的3888端口建立通信。
-
节点的通信是双向的,两个节点间只要建立一次连接。
-
所有的节点启动后,都会先投自己一票

n.leader的值就是自己的myid。
整个选举过程3888连接图如下:
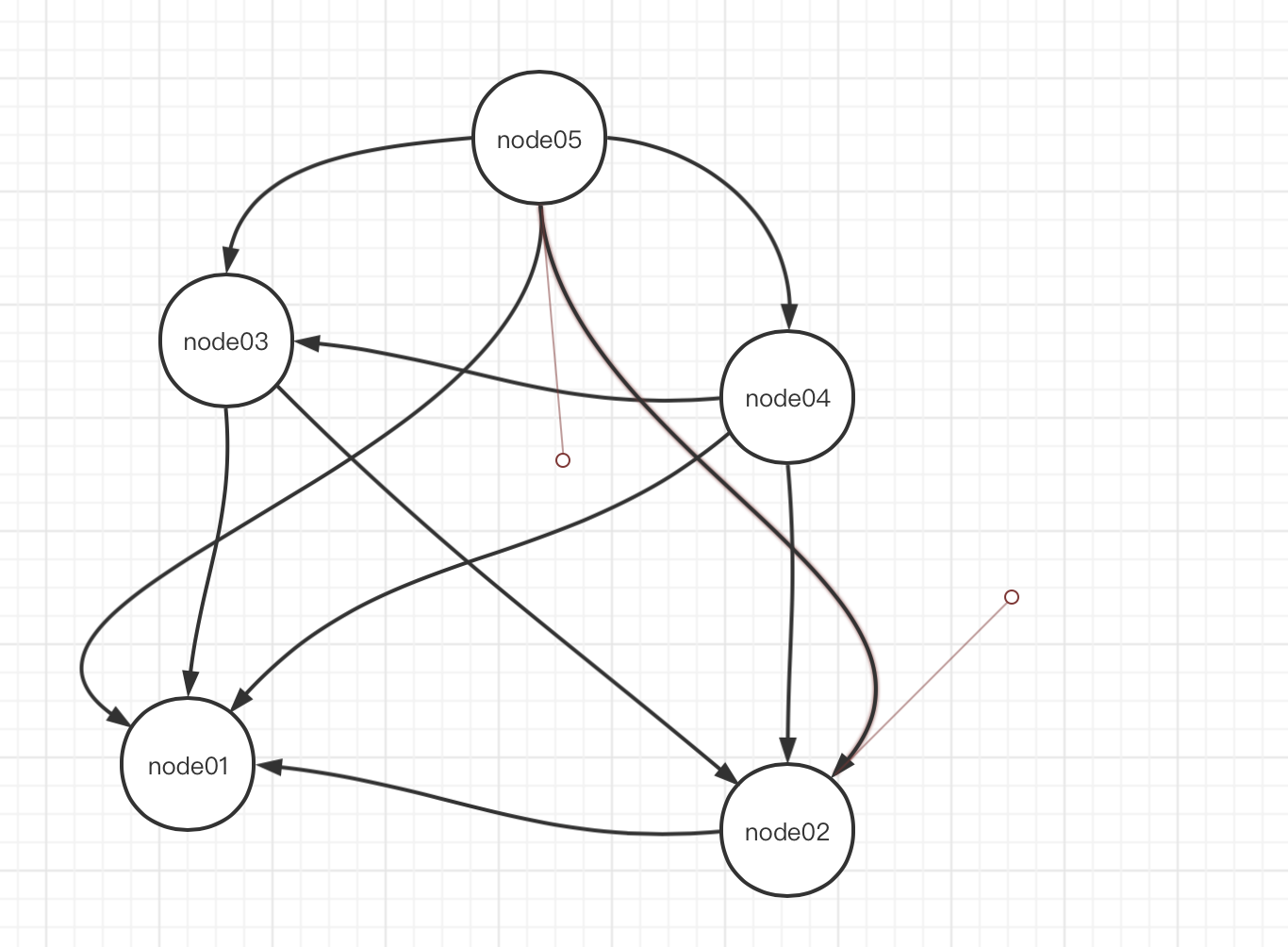
当服务按照1、2、3、4、5的顺序启动时,3888端口的连接情况如上图,node02连接node03的3888端口,node03连接node01和node02的3888端口,node04连接1、2、3的3888端口,node05连接1,2,3,4的3888端口。
选举过程如下:
- node01启动,先投了自己一票。node01票数:1,没有超过半数,服务状态为LOOKING
- node02启动,先投了自己一票。连接上node01的3888端口,然后node01告诉它,node01是leader,node02看了看自己的myid比它大,然后告诉node01,我的myid比你大,我是leader,然后node01就投给node02一票。node02票数:2,没有超过半数,服务状态为LOOKING
- node03启动,先投给自己一票。然后连接上node01和node02的3888端口,然后node01和node02都告诉他,node02是leader,node03一看,我的myid比node02的大,然后就告诉node01和node02,node01和node02就给node03投一票,说你是leader。node03此时票数:3票。此时node03的票数已经超过半数。那么node03更改服务器状态LEADING,node01与node02状态改为FOLLOWING。
- node04启动,先给自己投一票。然后与node01,node02,node03的3888端口连接,发现node03已经确定是leader了(服务器状态不是LOOKING),于是投票给node03,并将自己的状态改为FOLLOWING
- node05启动,与node04一样。
leader挂掉,重新选举
当leader挂掉,整个服务就不可用,需要新选举一个leader,此时再按照上面的要求来选举岛主:经验最丰富的(zxid最大的,说明这个节点存放的数据比其他节点的更新)。当所有的follower经验都一样时,那么此时就只能挑一个年龄大的当leader,选举时同样是超过半数就确定leader。
验证
初始化5个节点

从上图看,前3台启动的节点中,node05最大,所有node05肯定是leader:

然后通过node05进入cli客户端,开始写消息:
此时所有的follower节点都在线,那么数据会同步到所有的follower节点。如果此时将node05leader挂掉了,因为所有的follower的zxid都是一样的,将会按照myid来选举,推测新的leader为node04。
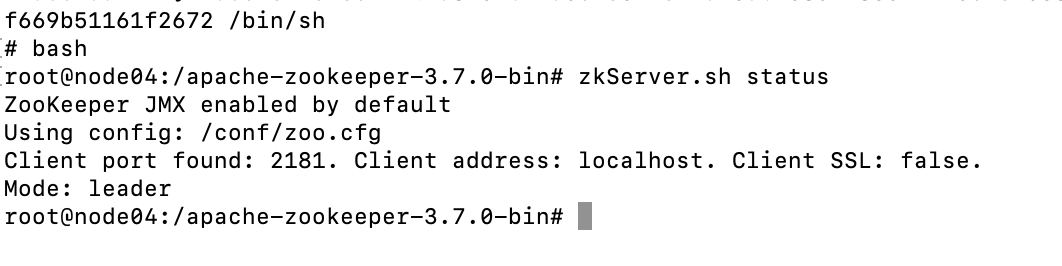
可以看到node04确实是leader。
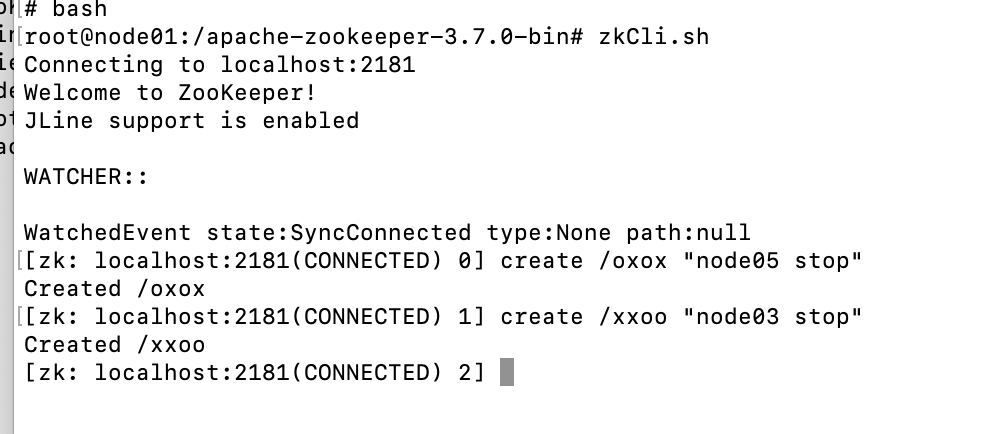
然后重新启动node05,此时node05会变成follower追随node04。

然后进入node01的客户端,写入一次数据,就停止一个容器。因为leader为4,那么就按顺序停掉5,3点(不能停掉2节点,停掉2节点,那么集群中就只剩两个存活节点了,无法保证过半,同样服务会不可用)。
此时如果node04挂了,那么无法保证过半,服务不可用:
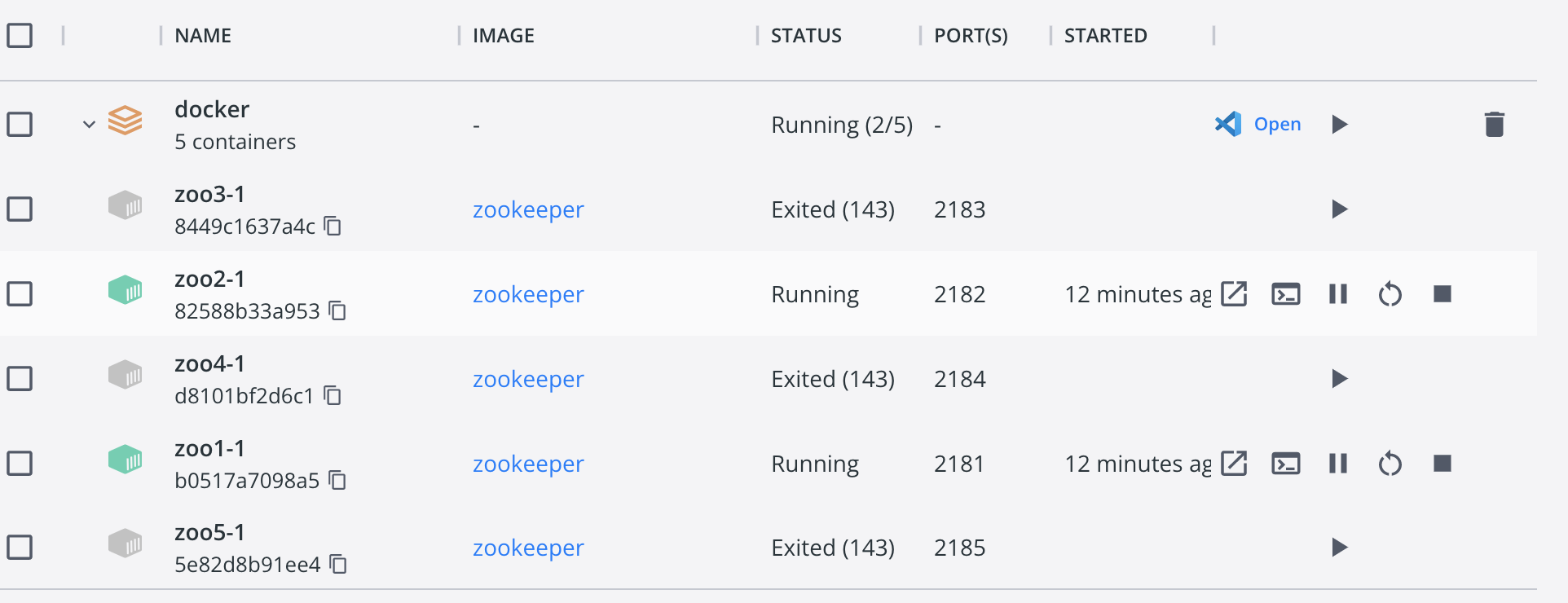

那么此时,如果再次重启节点4,因为4节点之前是leader,它的zxid与其他节点是相同的(经验最丰富),但同时它的myid又最大,所以它仍然是新的leader。
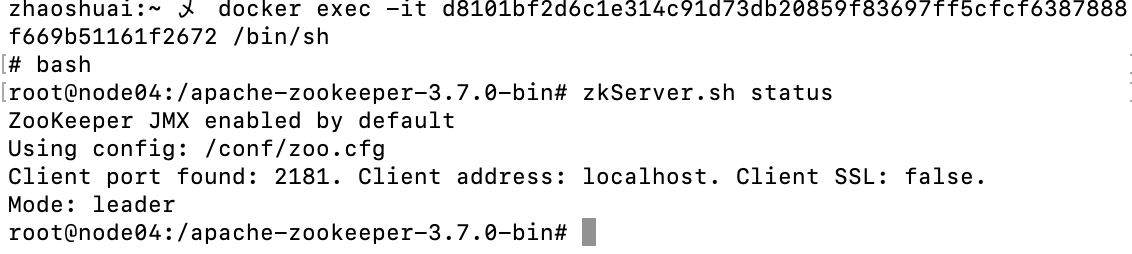
再把leader4挂掉,服务再次进入不可用状态,此时如果启动node05,那么推测一下:node05首先它的zxid是最小的(经验最小),所以肯定不会为主,然后就剩下1和 2连个节点,2的myid比较大,所以2是leader。
上面所有的选举情况都已经验证,选举过程不再详细写。
JAVA客户端简单使用
WATCH监控
在zookeeper中,提供服务的核心是分层命名空间,那么客户端在使用时,需要关注的就是分层命名空间的变化。而在分布式系统中,客户端一般是多节点,跨服务的,那么这种情况下,如何能够保证客户端实时监听节点信息的变化?
换句话说就是:当客户端改变了zookeeper中某一个path后,zookeeper如何主动通知其他的客户端?
watch就是解决上面这个问题的。其实watch相当于是zookeeper中实现的一个发布订阅功能,当某个client改变了zookeeper中的目录时,发布一个事件,然后zookeeper将此事件通知到到其他的client。
在zookeeper中,watch主要有两种:
- session级watch,生命周期随着整个session,也叫default watch,创建zk客户端时传入的。
- 某次操作的watch,一次性的。
需要注意的是watch是一次性的,因此使用一次之后就会失效,后续就监听不到了,解决办法就是在watch中重复注册这个watch。
在3.6.0之前, watch是一次性的,需要重复注册,但是会带来一个问题:当一个watch被消费后,新的watch还未注册时,如果此时节点数据发生了变化,客户端是没办法监听到新的变化的,会造成数据的丢失,因此zookeeper在3.6.0之后新增了addWatch命令,可以添加永久监听。
更多关于watch的内容,下面使用时在说
客户端简单使用
初始化客户端
创建maven项目,添加zookeeepr依赖
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.7.0</version>
</dependency>
从zookeeper压缩包的conf目录下,找到log4j.properties文件,放到自己项目的resources目录下。
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import java.util.concurrent.CountDownLatch;
/**
* @author shuai.zhao@going-link.com
* @date 2022/7/19
*/
public class SimpleDemo {
public static void main(String[] args) throws Exception {
CountDownLatch latch = new CountDownLatch(1);
// addr路径后面可以拼接path,代表path为当前服务的根目录,例如:
// new ZooKeeper("127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183/serviceA"...)
// 代表serviceA就是当前session连接的根目录,此session下所有的操作都是在serviceA目录下完成的。此方式可以保证不同服务间数据的隔离性,也更方便管理数据。但是path:serviceA不会自动创建,需要手动创建。
ZooKeeper zk = new ZooKeeper("127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183", 6000, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
System.out.println("watchedEvent = " + watchedEvent);
// path信息
String path = watchedEvent.getPath();
// session状态信息
Event.KeeperState state = watchedEvent.getState();
// 事件类型
Event.EventType type = watchedEvent.getType();
// session连接状态
switch (state) {
case SyncConnected:
//! 2. 客户端与服务端成功建立连接
System.out.println("2. 客户端建立连接成功,KeeperState:SyncConnected");
latch.countDown();
break;
case Disconnected:
System.out.println("连接终断");
break;
default:
System.out.println(state);
break;
}
// 节点事件类型, 由于此watch是监听session状态的,因此节点信息的变化不会通知到此watch。下面的分支都不会走到,type永远为null
switch (type) {
case None:
break;
case NodeCreated:
System.out.println("创建命名空间");
break;
case NodeDeleted:
System.out.println("命名空间被删除");
break;
case NodeDataChanged:
System.out.println("节点的数据被改变");
break;
case NodeChildrenChanged:
System.out.println("节点的子节点被改变");
break;
default:
break;
}
}
});
ZooKeeper.States state = zk.getState();
switch (state) {
case CONNECTING:
//!1. 由于上面 new Zookeeper() 其实是一个异步的方法,调用构造方法时立即就会返回一个zk客户端对象,但是此时可未与zk服务端真正建立连接,还处于连接中的状态
System.out.println("1. 建立连接中");
// 为了避免后面使用报错,可以使用 countdownlatch 来等待建立连接完成
latch.await();
break;
default:
break;
}
// 由于使用了countdownlatch,因此代码走到这里时,可以确定已经建立了连接,再次获取zk客户端状态
state = zk.getState();
switch (state) {
case CONNECTED:
//!3. 客户端在此获取zk状态,建立连接成功
System.out.println("3. 客户端建立连接成功,zkState:CONNECTED");
break;
default: break;
}
// 通过zk创建目录树, 可以看到上面是new Zookeeper中注册的watch是没有监听node节点信息的变化的
String pathName = zk.create("/ooxx", "hello world".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
session验证
验证上面的一个问题当client连接的zookeeper节点挂掉时,临时目录是否会消失?

可以看到刚开始客户端连接的是node02,然后我们将node02停掉,控制台打印连接中断。继续向下看日志

可以看到很快客户端就连接上了node01,还是同一个sessionId。所以临时目录不会消失。
增删改查node信息(同步阻塞方式)
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import java.util.concurrent.CountDownLatch;
/**
* @author shuai.zhao@going-link.com
* @date 2022/7/19
*/
public class SimpleDemo {
public static void main(String[] args) throws Exception {
// 主要代码为演示增删改查,所以无关代码进行简化
CountDownLatch latch = new CountDownLatch(1);
ZooKeeper zk = new ZooKeeper("127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183", 6000, (event) -> {
System.out.println(" default watcher event = " + event);
if (Watcher.Event.KeeperState.SyncConnected.equals(event.getState())) {
System.out.println("客户端建立连接成功,KeeperState:SyncConnected");
latch.countDown();
}
});
latch.await();
// 1. 新增
// create方法:
// 参数1:path
// 参数2:data
// 参数3:acl权限,暂时忽略
// 参数4:createMode:有四种取值:
// PERSISTENT: 持久节点
// EPHEMERAL: 临时节点
// PERSISTENT_SEQUENTIAL: 持久序列节点
// EPHEMERAL_SEQUENTIAL: 临时序列节点
//
// 新版本增加节点
// CONTAINER: 容器节点
// *_TTL: 带过期事件的节点
// 返回值:pathName。如果是创建序列节点,需要知道创建的节点的序列号是多少。
System.out.println("1. create 新增");
String pathName = zk.create("/oxox", "hello world".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("pathName = " + pathName);
// 可以自己尝试创建临时节点,当客户端断开后,通过zkCli查看此节点信息,当过了sessionTimeout后,临时节点才会被移除。
// 2. 查询
// getData:
// 参数1: path
// 参数2:watch,监听此节点的变化,只能用一次
// 参数3:stat,节点的元数据信息,例如:*zxid,version,ephemeralOwner等元信息
// 返回值:path下存的数据,二进制
System.out.println("2. get 查询");
final Stat stat = new Stat();
// 自定义watcher,一次性监听
byte[] data = zk.getData("/oxox", (event) -> System.out.println("customize watcher event = " + event), stat);
System.out.println("customize watcher get = " + new String(data));
// getData(path, bool, stat)等方法,bool为true时代表使用默认监听器,也就是new Zookeeper时传入的watcher。false时代表不启用watcher
// 使用default watcher,session级别,非一次性监听
byte[] data1 = zk.getData("/oxox", true, stat);
System.out.println("default watcher get = " + new String(data));
// watcher改造,重复注册监听
byte[] data2 = zk.getData("/oxox", new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("get data watcher plus...");
switch (event.getType()) {
case None:
break;
case NodeCreated:
System.out.println("节点被创建");
break;
case NodeDeleted:
System.out.println("节点被删除");
break;
case NodeDataChanged:
System.out.println("没有数据发生变化");
break;
case NodeChildrenChanged:
System.out.println("没有子节点发生变化");
break;
}
try {
System.out.println("repeat register watcher...");
zk.getData("/oxox", this, stat);
} catch (KeeperException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}, stat);
System.out.println("data2 = " + new String(data2));
// 3. set变更
// 参数1: path
// 参数2: newData
// 参数3: 期望当前path的版本号,如果当前数据版本号与期望值不一致,set操作会失败
// 参数4: 节点元数据信息,可以获取新的版本等信息
System.out.println("3. set变更");
Stat newStat = zk.setData("/oxox", "set hello oxox".getBytes(), stat.getVersion());
System.out.println("newStat = " + newStat);
// 4. delete删除
// 参数1: path
// 参数2: version version为-1时代表忽略版本号
System.out.println("4. delete删除");
zk.delete("/oxox", newStat.getVersion());
System.out.println("删除完成");
}
}
callback机制增删改查(异步)
上面的演示都是基于同步阻塞模型实现的。zookeeper还基于reactor模型实现了一套事件异步方式。回调类型如下,org.apache.zookeeper.AsyncCallback.*:
| 类型 | 描述 | 使用场景/对应异步api |
|---|---|---|
| StatCallback | 用于获取节点的状态 | exists()、setData() |
| DataCallback | 用于获取节点的数据和状态 | getData()、 |
| ACLCallback | 用于获取节点的ACL和状态 | getACL() |
| ChildrenCallback | 用于获取节点的子节点 | getChildren() |
| Children2Callback | 用于获取节点的子节点和状态 | getChildren() |
| StringCallback | 只返回节点的名称 | create() |
| Create2Callback | 返回节点名称和节点元数据stat | create() |
| VoidCallback | 空回调,不会返回任何数据 | delete()、sync() |
| MultiCallback | 用于处理有多个结果的回调 | multi()、multiInternal() |
所有需要使用callback函数的方法,都会伴随出现如下参数:
ctx: 上下文参数。将需要在callback方法中使用的上下文信息传过去。rc: 调用结果状态码,可以通过:org.apache.zookeeper.KeeperException.Code类查看错误码类型。0代表成功。path: 当前回调是哪儿个节点下的。
其他参数都是回调类型相关的参数。根据具体类型不同。
import org.apache.zookeeper.AsyncCallback;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
/**
* @author shuai.zhao@going-link.com
* @date 2022/7/21
*/
public class SimpleCallbackDemo {
public static void main(String[] args) throws Exception {
// 主要代码为演示增删改查,所以无关代码进行简化
CountDownLatch latch = new CountDownLatch(1);
ZooKeeper zk = new ZooKeeper("127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183", 6000, event -> {
System.out.println(" default watcher event = " + event);
if (Watcher.Event.KeeperState.SyncConnected.equals(event.getState())) {
System.out.println("客户端建立连接成功,KeeperState:SyncConnected");
latch.countDown();
}
});
latch.await();
System.out.println("1. create + callback创建节点");
// create
// 参数1: path
// 参数2: data
// 参数3: acl权限
// 参数4: 创建节点类型
// 参数5: 创建成功后回调函数
// 参数6: ctx,上下文参数。现在我们是使用lambda匿名函数来使用的callback,所以可以直接在函数内使用上下文参数。
// 但是实际使用时会为callback单独实现一个类,此时就无法拿到上下文参数,可以通过ctx传过去。后面参数不再不再赘述
String ctx = "hello context";
zk.create("/xoxoxo", "hello xoxoxox".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL, new AsyncCallback.StringCallback() {
@Override
public void processResult(int rc, String path, Object ctx, String name) {
System.out.println("1. create callback info: rc=" + rc + ", path=" + path + ",ctx=" + ctx + ", name=" + name);
}
}, ctx);
// 参数1: path
// 参数2: watcher
// 参数3: callback function
// 参数4: ctx。上下文参数,回调时会带着此参数
// 下面就是一个ctx的使用示例:无法在匿名函数内重新为外部变量赋值,所以将stat通过ctx传入callback函数内部,在函数内部为对象赋值
System.out.println("2. get + callback 查询节点信息");
Stat stat = new Stat();
zk.getData("/xoxoxo", event -> System.out.println("get data event = " + event), new AsyncCallback.DataCallback() {
@Override
public void processResult(int rc, String path, Object ctx, byte[] data, Stat stat) {
System.out.println("2. get data call back,rc:" + rc + ", path:" + path + ",ctx:" + ctx + ",data:" + new String(data) + ",stat" + stat);
Stat outer = (Stat) ctx;
outer.setVersion(stat.getVersion());
}
}, stat);
System.out.println("3. set + callback 设置节点信息");
zk.setData("/xoxoxo", "set hello oxox callback".getBytes(), stat.getVersion(), new AsyncCallback.StatCallback() {
@Override
public void processResult(int rc, String path, Object ctx, Stat stat) {
System.out.println("3. set data call back,rc:" + rc + ", path:" + path + ",ctx:" + ctx + ",stat" + stat);
Stat outer = (Stat) ctx;
outer.setVersion(stat.getVersion());
}
}, stat);
// 等待上面回调执行完,获取最新的stat版本号
TimeUnit.SECONDS.sleep(2);
// 同样支持异步删除
System.out.println("4. 删除节点");
zk.delete("/xoxoxo", stat.getVersion(), new AsyncCallback.VoidCallback() {
@Override
public void processResult(int rc, String path, Object ctx) {
System.out.println("4. delete status = " + rc);
}
}, "delete");
// 等待delete回调
TimeUnit.SECONDS.sleep(5);
}
}
永久监听
import org.apache.zookeeper.AddWatchMode;
import org.apache.zookeeper.AsyncCallback;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
/**
* @author shuai.zhao@going-link.com
* @date 2022/7/21
*/
public class SimpleCallbackDemo {
public static void main(String[] args) throws Exception {
// 主要代码为演示增删改查,所以无关代码进行简化
CountDownLatch latch = new CountDownLatch(1);
ZooKeeper zk = new ZooKeeper("127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183", 6000, event -> {
System.out.println(" default watcher event = " + event);
if (Watcher.Event.KeeperState.SyncConnected.equals(event.getState())) {
System.out.println("客户端建立连接成功,KeeperState:SyncConnected");
latch.countDown();
}
});
latch.await();
System.out.println("1. create 创建节点");
Stat stat = new Stat();
zk.create("/xoxoxo", "hello xoxoxox".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT, stat);
// 为节点添加永久监听
// 提供了自定义watcher和不指定watcher两种方式(不指定时使用default watcher)
// zk.addWatch("/xoxoxo", AddWatchMode.PERSISTENT);
// zk.addWatch("/xoxoxo", event -> System.out.println("event = " + event), AddWatchMode.PERSISTENT);
// 在上面两种模式上同时也提供了回调机制的callback
// 提供两种观察模式:
// AddWatchMode.PERSISTENT: 监停设置节点及子节点变化信息,只监听设置的节点,监听返回的path永远为设置的path,子节点变化统一类型为:NodeChildrenChanged(无论创建/修改/删除)
// AddWatchMode.PERSISTENT_RECURSIVE 递归监听节点及子节点,会为每个子节点都设置监听。监听时间的path为发生变化的节点的路径(子节点变化就是子节点路径)
zk.addWatch("/xoxoxo", event -> {
System.out.println("path = " + event.getPath());
switch (event.getType()) {
case None:
break;
case NodeCreated:
System.out.println("节点被创建");
break;
case NodeDeleted:
System.out.println("节点被删除");
break;
case NodeDataChanged:
System.out.println("节点数据变化");
break;
case NodeChildrenChanged:
System.out.println("子节点数据被改变");
break;
// 下面为新版本增加
case DataWatchRemoved:
System.out.println("数据监听被移除");
break;
case ChildWatchRemoved:
break;
case PersistentWatchRemoved:
break;
}
}, AddWatchMode.PERSISTENT, new AsyncCallback.VoidCallback() {
@Override
public void processResult(int rc, String path, Object ctx) {
System.out.println(rc);
}
}, null);
System.out.println("创建子节点");
zk.create("/xoxoxo/oxoxox", "child node".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("set 设置节点信息");
stat = zk.setData("/xoxoxo", "aaaaa xoxoxoxox".getBytes(), stat.getVersion());
stat = zk.setData("/xoxoxo", "hello xoxoxoxox1".getBytes(), stat.getVersion());
System.out.println("4. 删除节点");
zk.delete("/xoxoxo/oxoxox", 0);
zk.delete("/xoxoxo", stat.getVersion(), new AsyncCallback.VoidCallback() {
@Override
public void processResult(int rc, String path, Object ctx) {
System.out.println("4. delete status = " + rc);
}
}, "delete");
// 等待delete回调
TimeUnit.SECONDS.sleep(5);
}
}
WATCH及CALLBACK机制原理
watch与callback的区别
两者都是基于事件回调机制实现的,通过EventThread来触发回调。但是本质是有区别的。
- watch:客户端注册监听,服务端触发事件时会主动回调所有注册的客户端。
- callback:是使用java异步的方式使用zookeeper的api。api仍是阻塞的,但是通过客户端代码设计不阻塞等待返回结果。异步等待拿到调用结果后,调用回调方法。类似FutureTask机制。
watch原理
watch机制是基于观察者模式,可以理解为分布式场景下的观察者。watch通过两个列表(客户端和服务端各一个)来存放观察者。这两个列表在ZKWatchManager和WatchManager中。watch机制的核心也是围绕这两个类来实现。
-
客户端:
zk在客户端代码中通过
ZKWatchManager来维护监听列表:
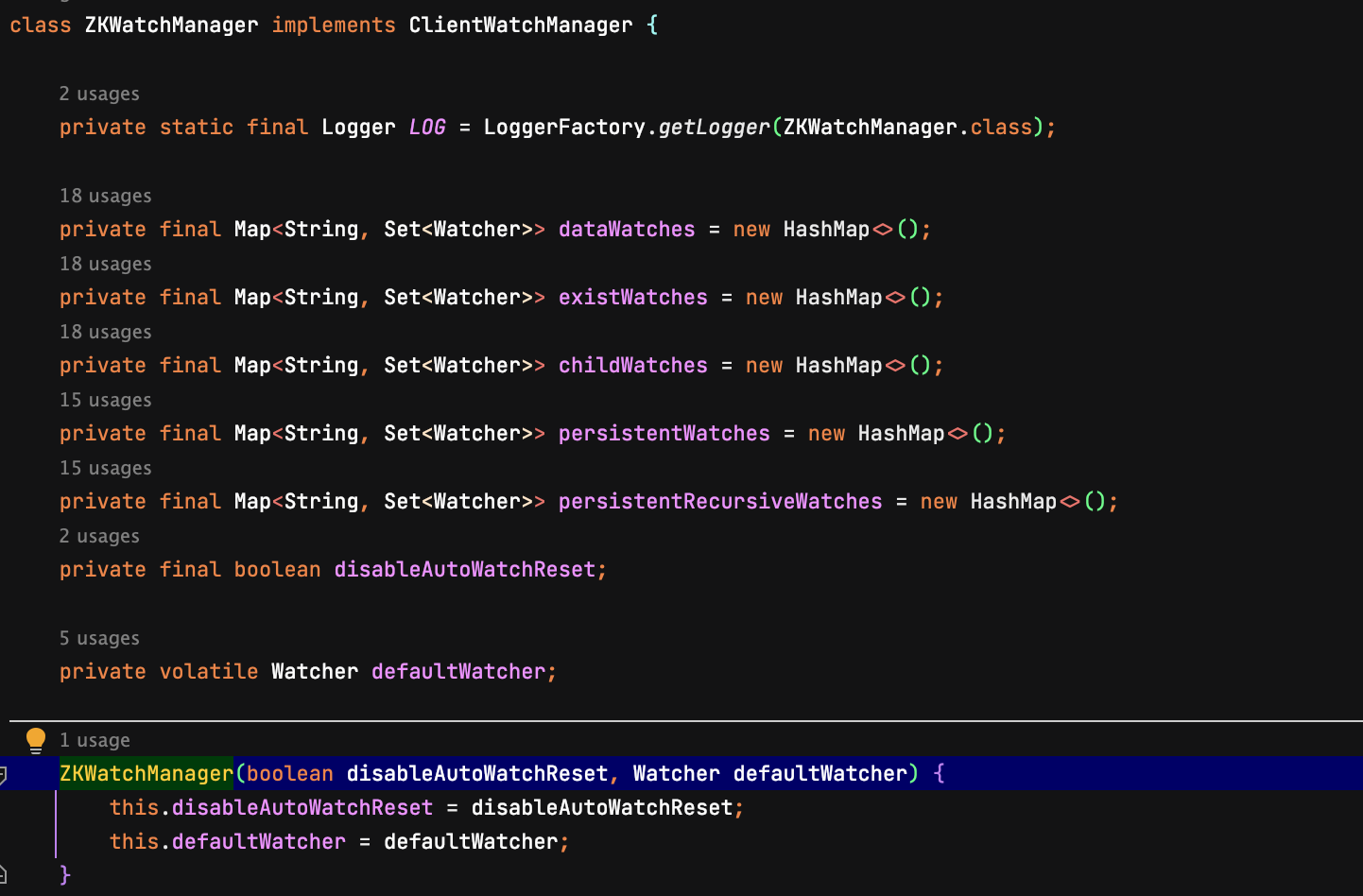
new Zookeeper时传入的watcher为defaultwatcher。在使用getdata、exists、child等方法时传入的watch会被注册到对应的列表中。当监听的节点发生变化时,服务端主动推送watch事件信息到客户端,客户端通过上面的列表查询注册的watch对象,并将watch事件推送到EventThread的事件队列中。通过EventThread完成回调。客户端主要类及方法:
ClientCnxn.SendThread:readResponse()ClientCnxnSocket:doTransport(),此方法有两个实现:NIO的和netty的。看源码需要了解NIO。 -
服务端:
服务端代码通过
WatchManager来维护监听列表: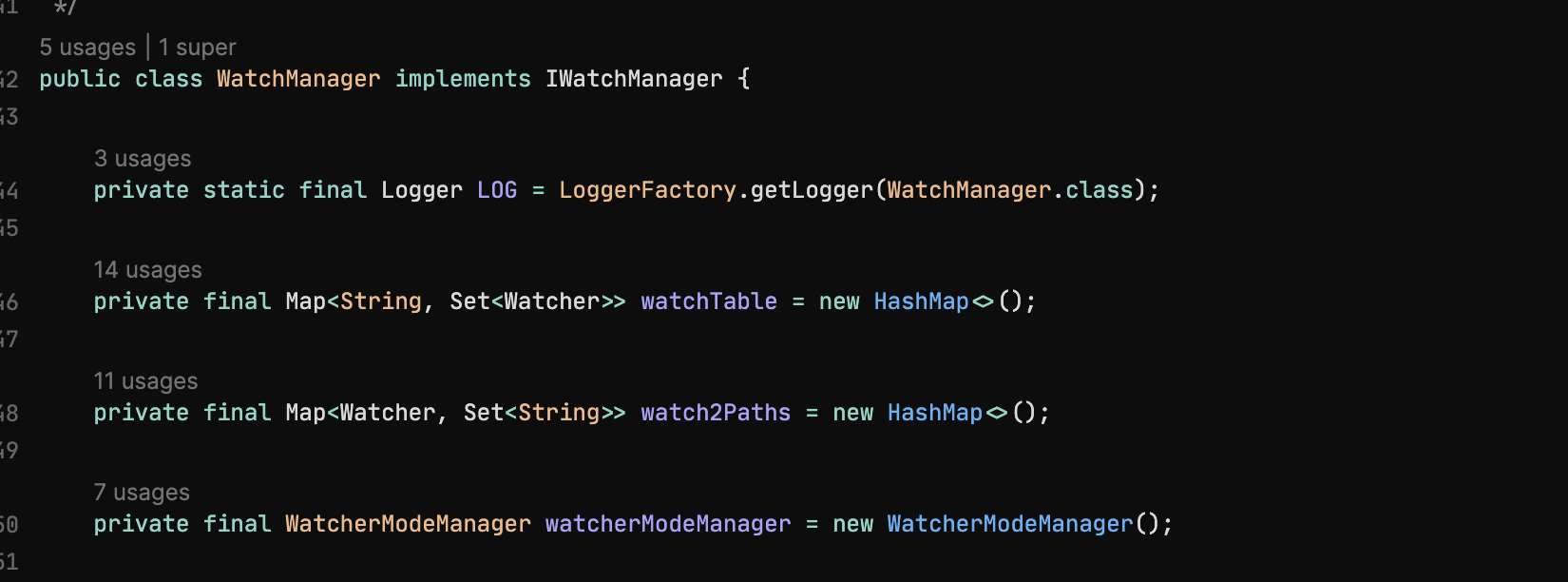
服务端收到请求客户端请求后,首先按照请求的api类型:
create/get/set...调用对应的方法在处理。如果是带watch的请求,那么会将watch添加到
WatchManager中。当调用set/create..等api时,会触发watch事件,并通知到所有监听的客户端(watch中会存放)。最终处理客户端请求的类为:
FinalRequestProcessor:processRequest(): 处理客户端请求FinalRequestProcessor:applyRequest(): 调用dataTree类处理api命令DataTree:processTxn():真正处理api命令的地方,如果是一个带watch的api,就加入WatchManager中。
高级使用
分布式配置(watch+callback)
原理:当某一个节点发生变化时,会通知所有监听这个节点的客户端获取最新的数据。
package com.xiazhi.zookeeper;
import org.apache.zookeeper.AsyncCallback;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
/**
* 分布式配置
*
* @author shuai.zhao@going-link.com
* @date 2022/7/25
*/
public class DistributedConfig {
private final String configPath;
/**
* 分布式配置的配置项内容,业务重点关注项。
*/
private final ConfigInfo configInfo;
/**
* zk客户端,处理数据同步
*/
private final ZooKeeper zk;
private final WatchCallback watchCallback;
private CountDownLatch cdl = new CountDownLatch(1);
public DistributedConfig(ZooKeeper zk, String configPath) {
this.zk = zk;
this.configPath = configPath;
this.configInfo = new ConfigInfo();
this.watchCallback = new WatchCallback(zk, configPath, this.configInfo, cdl);
}
/**
* 获取配置内容
*
* @return {@link String}
*/
public String getContent() {
// 等待验证节点是否创建,无论是否创建节点,最终都会触发getData方法,拿到最新的数据,
zk.exists(configPath, this.watchCallback, this.watchCallback, cdl);
try {
cdl.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return this.configInfo.getContent();
}
public static void run() {
ZooKeeper zk = ZKClientUtil.getZK();
DistributedConfig config = new DistributedConfig(zk, "/aaa");
String content = config.getContent();
System.out.println("content = " + content);
try {
// 阻塞线程
System.in.read();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) {
// 模拟5个客户端,使用cli修改path的值,5个客户端都会同步最新的配置信息
for (int i = 0; i < 5; i++) {
new Thread(DistributedConfig::run, "client-" + i).start();
}
try {
System.in.read();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
/**
* 配置信息
*
* @author zhaoshuai
* @date 2022/07/25
*/
class ConfigInfo {
private String content;
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
/**
* 监听器和数据,状态回调器
*
* @author zhaoshuai
* @date 2022/07/25
*/
class WatchCallback implements Watcher, AsyncCallback.DataCallback, AsyncCallback.StatCallback {
private final ZooKeeper zooKeeper;
private final String path;
private final ConfigInfo configInfo;
private final CountDownLatch countDownLatch;
public WatchCallback(ZooKeeper zooKeeper, String path, ConfigInfo configInfo, CountDownLatch countDownLatch) {
this.zooKeeper = zooKeeper;
this.path = path;
this.configInfo = configInfo;
this.countDownLatch = countDownLatch;
}
/**
* exists结果回调
*
* @param rc 钢筋混凝土
* @param path 路径
* @param ctx ctx
* @param stat 统计
*/
@Override
public void processResult(int rc, String path, Object ctx, Stat stat) {
if (stat != null) {
// 节点信息不为空,同步节点数据
this.zooKeeper.getData(this.path, this, this, null);
}
}
/**
* getData结果回调
*
* @param rc 钢筋混凝土
* @param path 路径
* @param ctx ctx
* @param data 数据
* @param stat 统计
*/
@Override
public void processResult(int rc, String path, Object ctx, byte[] data, Stat stat) {
// 调用成功,更新配置内容
if (rc == 0) {
String content = new String(data);
System.out.println("thread: " + Thread.currentThread().getName() + ", get data: " + content);
configInfo.setContent(content);
countDownLatch.countDown();
}
// 再次注册监听,监听下一次的变化。
this.zooKeeper.getData(this.path, this, this, ctx);
}
/**
* 监听器回调,node节点变化信息
*
* @param event 事件
*/
@Override
public void process(WatchedEvent event) {
switch (event.getType()) {
case None:
break;
case NodeCreated:
// 监听到节点被创建,开始从zk同步配置信息
this.zooKeeper.getData(this.path, this, this, null);
break;
case NodeDeleted:
break;
case NodeDataChanged:
// 节点的数据被修改了,同步最新的配置信息
this.zooKeeper.getData(this.path, this, this, null);
break;
case NodeChildrenChanged:
break;
}
}
}
/**
* 默认观察者
*
* @author zhaoshuai
* @date 2022/07/25
*/
class DefaultWatcher implements Watcher {
private CountDownLatch cdl;
public void setCdl(CountDownLatch cdl) {
this.cdl = cdl;
}
@Override
public void process(WatchedEvent event) {
System.out.println("Default watcher event = " + event);
if (Event.KeeperState.SyncConnected.equals(event.getState())) {
cdl.countDown();
}
}
}
/**
* zk客户端工具类
*
* @author zhaoshuai
* @date 2022/07/25
*/
class ZKClientUtil {
private static final String ADDR = "127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183/config";
public static ZooKeeper getZK() {
CountDownLatch cdl = new CountDownLatch(1);
DefaultWatcher dw = new DefaultWatcher();
dw.setCdl(cdl);
ZooKeeper zk;
try {
zk = new ZooKeeper(ADDR, 6000, dw);
cdl.await();
} catch (IOException | InterruptedException e) {
throw new RuntimeException(e);
}
return zk;
}
}
分布式锁(临时序列节点+watchcallback)
原理:分布式情况下,所有的节点抢一把锁,通过序列化为每一个节点都创建一个path,然后每个节点监听前一个节点的delete(前一个节点释放锁,后一个才能获得锁,避免羊群效应)。通过序列化保证锁争抢的顺序性(公平锁),降低网络压力,通过临时节点避免产生死锁。
package com.xiazhi.zookeeper;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
/**
* 分布式锁
*/
public class DistributedLock implements AsyncCallback.StringCallback, Watcher, AsyncCallback.Children2Callback, AsyncCallback.StatCallback {
private final ZooKeeper zooKeeper;
private final CountDownLatch lock;
/**
* 当前线程名,方便观察日志
*/
private final String threadName;
private String pathName;
public DistributedLock(ZooKeeper zooKeeper) {
this.zooKeeper = zooKeeper;
this.lock = new CountDownLatch(1);
this.threadName = Thread.currentThread().getName();
}
/**
* 加锁: 创建临时序列化节点, 并等待上一个节点释放锁。
*/
public void lock(String path) throws InterruptedException {
this.zooKeeper.create(path, threadName.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL, this, this.threadName);
this.lock.await();
}
/**
* 解锁
*/
public void unlock() {
try {
this.zooKeeper.delete(this.pathName, -1);
System.out.println(this.threadName + "unlock");
} catch (InterruptedException | KeeperException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws IOException {
for (int i = 0; i < 10; i++) {
new Thread(() -> {
ZooKeeper zk = ZKClient.getZK();
DistributedLock lock = new DistributedLock(zk);
try {
lock.lock("/lock");
// 模拟业务处理耗时
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}, "thread" + i).start();
}
System.in.read();
}
/**
* children 2 callback ,获取子节点列表
*/
@Override
public void processResult(int rc, String path, Object ctx, List<String> children, Stat stat) {
// 子节点排序
Collections.sort(children);
//System.out.println(children);
// 获取当前节点(触发查看子节点目录的节点)下标
int index = children.indexOf(this.pathName.substring(1));
// 如果当前节点就是第一个节点,那当前节点获取锁,
if (index == 0) {
lock.countDown();
} else {
// 不是第一个节点,监听前一个节点
String previousPath = children.get(index - 1);
this.zooKeeper.exists("/" + previousPath, this, this, null);
}
}
/**
* create node String callback
*/
@Override
public void processResult(int rc, String path, Object ctx, String name) {
// 节点创建成功了,获取子节点信息(监控前一个节点)
if (rc == 0) {
System.out.println("thread : " + ctx + ", create node: " + name);
this.pathName = name;
this.zooKeeper.getChildren("/", false, this, name);
}
}
/**
* exists callback
*/
@Override
public void processResult(int rc, String path, Object ctx, Stat stat) {
}
/**
* watcher process
*/
@Override
public void process(WatchedEvent event) {
//System.out.println("event.getPath() = " + event.getPath());
switch (event.getType()) {
case None:
break;
case NodeCreated:
break;
case NodeDeleted:
// 监听到前一个节点被删除了,触发自己尝试获取锁
this.zooKeeper.getChildren("/", false, this, null);
break;
case NodeDataChanged:
break;
case NodeChildrenChanged:
break;
}
}
}
/**
* zk客户端工具类
*
* @author zhaoshuai
* @date 2022/07/25
*/
class ZKClient {
private static final String ADDR = "127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183/testlocks";
public static ZooKeeper getZK() {
CountDownLatch cdl = new CountDownLatch(1);
DefaultWatcher dw = new DefaultWatcher();
dw.setCdl(cdl);
ZooKeeper zk;
try {
zk = new ZooKeeper(ADDR, 6000, dw);
cdl.await();
} catch (IOException | InterruptedException e) {
throw new RuntimeException(e);
}
return zk;
}
}
服务注册和发现(上面所有功能的组合使用)
服务注册发现使用zk的命名空间机制,在zk中存放服务端的接口信息,然后客户端watch接口目录,本地缓存服务端的接口信息如:服务地址、调用协议等信息。
- 服务注册:服务端在启动后,会将对外提供的接口注册进zk中(写入目录树)。目录格式为:
service/version/ip:port,目录为临时目录。当某个服务端挂掉时,临时目录会过期消失,然后zk通过watch通知客户端移除此服务端节点。 - 服务发现:客户端启动后,主动去get服务端注册的节点信息,并监听节点状态的变化。当客户端发起调用时,从本地加载的服务端节点中负载选出一个节点,完成调用。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?