

RocketMQ学习笔记
RocketMQ学习笔记
RocketMQ学习参考官网文档:https://github.com/apache/rocketmq/tree/master/docs/cn 。
由于RocketMQ是有国内阿里开发的MQ系统,因此RocketMQ的官网是有中文文档的,本文档也是参考官网文档整理的。
1. RocketMQ概念
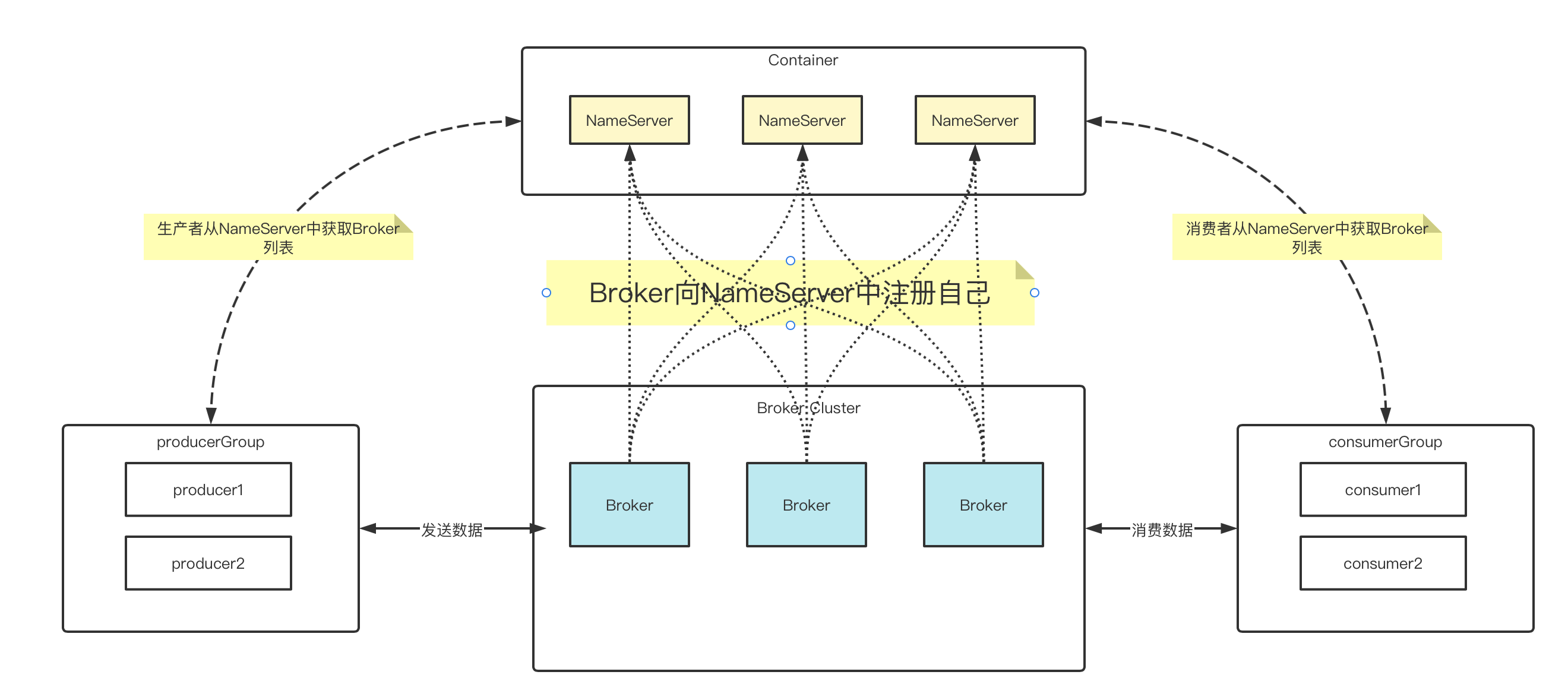
RocketMQ主要由 Producer、Broker、Consumer 三部分组成。其中Producer 负责生产消息,Consumer 负责消费消息,Broker 负责存储消息。Broker 在实际部署过程中对应一台服务器,每个 Broker 可以存储多个Topic的消息,每个Topic的消息也可以分片存储于不同的 Broker。Message Queue 用于存储消息的物理地址,每个Topic中的消息地址存储于多个 Message Queue 中。ConsumerGroup 由多个Consumer 实例构成。
-
Producer - 消息生产者:负责为mq生产消息,消息的提供方。生产者会讲生产者生产的消息发送到broker server中。rocketMQ提供多种发送模式:同步发送、异步发送、顺序发送、单向发送。同步和异步发送均需要broker返回确认收到消息,单向发送不需要。 -
Consumer - 消息消费者:负责消费消息。从broker中获取消息进行消费。获取消息两种方式:
pull:消费者主动从broker中请求拉取消息进行消费。push: 由broker主动将消息推送给消费者。
消费消息两种方式:
集群消费:由同一个消费者组Consumer Group中的所有消费者共同平分broker中的消息。广播消费:同一个消费者组中的所有消费者接收相同的消息。
-
Topic - 消息主题: 表示一类消息的集合。每个主题包含若干的消息,每个消息只能有一个主题。是RocketMQ的基本订阅单位。 -
BrokerServer - 代理服务器: 消息中转角色,负责存储消息、转发消息。由于生产者和消费者都是与业务系统绑定在一起的,因此broker也可以理解为rocketMQ的服务端本身。它负责接受生产者的消息进行存储,又负责将消息转发给消费者。在系统中起到解藕的作用。 -
NameServer - 名字服务:各个
broker实例需要向NameServer注册自己的信息,同时生产者和消费者从NameServer中获取主题对应的Broker列表。多个
NameServe之间组成集群,但是没有信息交换。因为没有信息交换,所以Broker需要向每一个NameServer注册自己,同时NameServer之间并不知道还有其他的同伴, 但是每一个NameServer中的数据都是相同的。 -
Message - 消息:整个RocketMQ的数据流转对象,物理载体。生产和消费数据的最小单位,每条消息必须属于一个主题。同时在RocketMQ中,每个消息还会拥有自己的MessageId和Keys,可以用来查询消息。 -
Tag - 标签:可以对每个消息添加标签,用于区分同一主题下不同类型的数据。
更多概念信息参见:基本概念(官网)
2. RocketMQ的架构设计
经过上面的概念了解,我们其实已经可以在脑海中构思出RocketMQ的架构图:
而消息之间的概念关系如下:
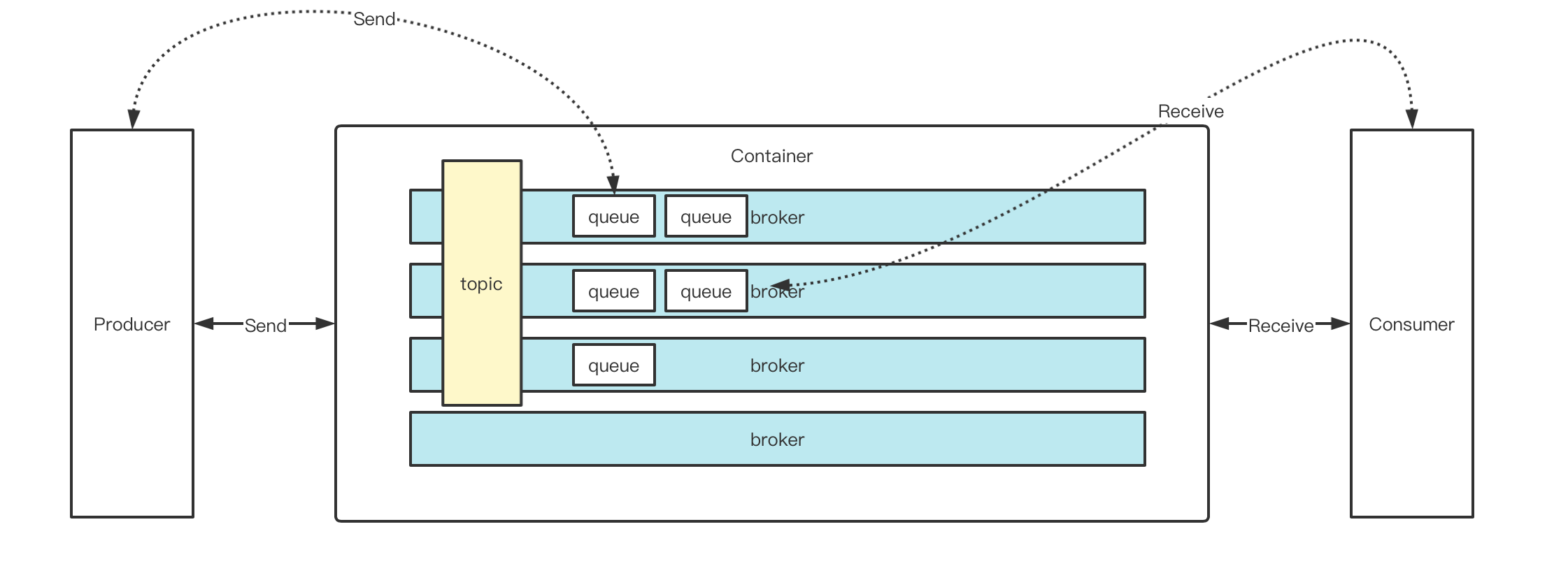
消息是以主题区分的,一个topic的数据可以分散在各个broker中,而且实际存放在broker中的队列上面。同一个topic下,一个broker上可以存在多个queue。当Producer要发送数据时,会从Namesrv中拿到topic下的所有broker及所有的queue,但是发送数据只会负载到某一个queue中。而在Consumer接收数据时,则会从Namesrv中拿到所有的broker及下面queue中的数据(可以通过指定broker和queue的方式进行消费)。
3. RocketMQ 安装部署
-
安装jdk。
-
下载压缩包。登陆
rocketmq.apache.org官网,获取最新版压缩包下载地址ubuntu@rocketmq:~$ wget https://dlcdn.apache.org/rocketmq/4.9.3/rocketmq-all-4.9.3-bin-release.zip -
解压
ubuntu@rocketmq:~$ ls rocketmq-all-4.9.3-bin-release.zip ubuntu@rocketmq:~$ unzip rocketmq-all-4.9.3-bin-release.zip -
启动服务。参考官网文档启动。
启动时可能报错,分配内存不够,修改
runserver.sh中的Xmx相关参数,改成合适的内存
4. RocketMQ简单使用
既是简单实用RocketMQ, 同时也是对上面概念的验证。
4.1 生产者发送消息
public static void producer() throws Exception {
// 定义一个producer
DefaultMQProducer producer = new DefaultMQProducer("default_group");
// 设置nameserver
producer.setNamesrvAddr("192.168.64.5:9876;192.168.64.6:9876");
producer.start();
for (int i = 0; i < 10; i++) {
Message message = new Message("test-topic", ("hello world" + i).getBytes());
// 发送消息,拿到确认信息
producer.send(message, new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
System.out.println("sendResult = " + sendResult);
}
@Override
public void onException(Throwable e) {
System.out.println("e = " + e);
}
});
}
}

可以注意到,生产者的消息都均匀的分散在两个broker中,同时在每个broker中都创建了队列。
4.2 生产者只向指定队列发送消息
static void producer1() throws Exception {
// 定义一个producer
DefaultMQProducer producer = new DefaultMQProducer("default_group");
// 设置nameserver
producer.setNamesrvAddr("192.168.64.5:9876;192.168.64.6:9876");
producer.start();
for (int i = 0; i < 10; i++) {
// 只往指定队列发送消息,拿到确认信息
MessageQueue queue = new MessageQueue("test-topic", "broker-a", 3);
Message message = new Message("test-topic", ("hello world broker-a 3" + i).getBytes());
producer.send(message, queue, new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
System.out.println("sendResult = " + sendResult);
}
@Override
public void onException(Throwable e) {
System.out.println("e = " + e);
}
});
}
}

4.3 消费者pull获取消息
static void consumerPull() throws Exception {
DefaultLitePullConsumer consumer = new DefaultLitePullConsumer("default-consumer");
consumer.setNamesrvAddr("192.168.64.5:9876;192.168.64.6:9876");
consumer.subscribe("test-topic", "*");
// 设置广播消费或集群消费
// consumer.setMessageModel(MessageModel.BROADCASTING);
consumer.start();
while (true) {
// 主动拉消息
List<MessageExt> poll = consumer.poll();
for (MessageExt messageExt : poll) {
String brokerName = messageExt.getBrokerName();
int queueId = messageExt.getQueueId();
String body = new String(messageExt.getBody());
System.out.printf("broker: %s , queueId : %s, body : %s %n", brokerName, queueId, body);
}
}
}
4.4 消费者push获取消息
static void consumerPush() throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("default-push-consumer");
consumer.setNamesrvAddr("192.168.64.5:9876;192.168.64.6:9876");
consumer.subscribe("test-topic", "*");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
for (MessageExt messageExt : msgs) {
String brokerName = messageExt.getBrokerName();
int queueId = messageExt.getQueueId();
String body = new String(messageExt.getBody());
System.out.printf("broker: %s , queueId : %s, body : %s %n", brokerName, queueId, body);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.start();
}
更多用法参见样例
5. RocketMQ设计原理
5.1 消息存储
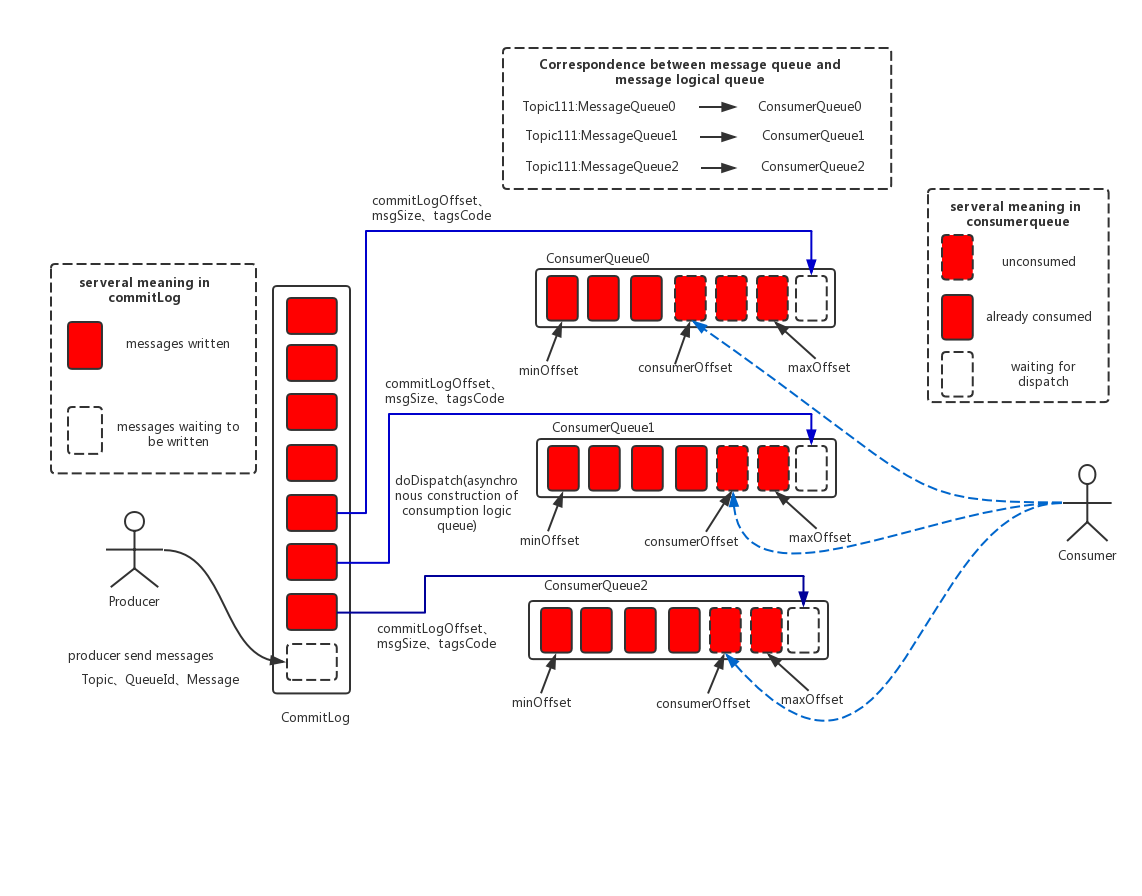
做为MQ来讲,最重要的一个问题就是:保证消息不丢失,那么就要考虑到消息的持久化问题。上图是RocketMQ的消息存储设计图。
上图中总共包含如下几个概念:
-
CommitLog:消息主体以及元数据的存储主体。是实际存储消息的文件。单个文件默认大小为1G。文件名长度为20位,左边补零,剩下为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件;默认文件位置为~/store/commitlog。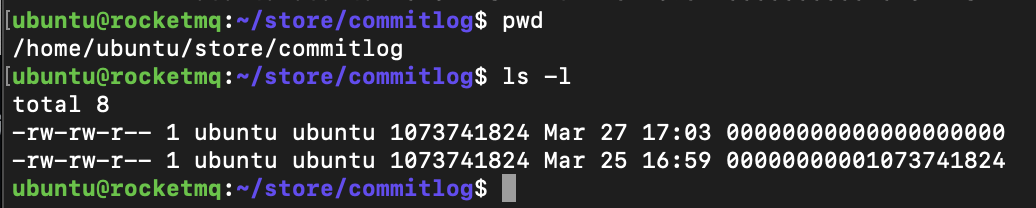
-
ComsumerQueue:消息消费队列,引入的目的主要是提高消息消费的性能,由于RocketMQ是基于主题topic的订阅模式,消息消费是针对主题进行的,如果要遍历commitlog文件中根据topic检索消息是非常低效的。Consumer即可根据ConsumeQueue来查找待消费的消息。其中,ConsumeQueue(逻辑消费队列)作为消费消息的索引,保存了指定Topic下的队列消息在CommitLog中的起始物理偏移量offset,消息大小size和消息Tag的HashCode值。consumequeue文件可以看成是基于topic的commitlog索引文件,故consumequeue文件夹的组织方式如下:topic/queue/file三层组织结构,具体存储路径为:~/store/consumequeue/{topic}/{queueId}/{fileName}。
同样consumequeue文件采取定长设计,每一个条目共20个字节,分别为8字节的commitlog物理偏移量、4字节的消息长度、8字节tag hashcode,单个文件由30W个条目组成,可以像数组一样随机访问每一个条目,每个ConsumeQueue文件大小约5.72M;
-
IndexFile:IndexFile(索引文件)提供了一种可以通过key或时间区间来查询消息的方法。Index文件的存储位置是:~\store\index${fileName},文件名fileName是以创建时的时间戳命名的。
固定的单个IndexFile文件大小约为400M,一个IndexFile可以保存 2000W个索引,IndexFile的底层存储设计为在文件系统中实现HashMap结构,故rocketmq的索引文件其底层实现为hash索引。
从上面的架构图已及概念分析,可以得出如下信息:
- 消息生产和消息消费互相隔离。producer端发送的消息最终写入的是commitLog,comsumer端先从
ConsumeQueue种读取持久化消息的起始物理位置偏移量offset,大小size和消息的tag的hashcode值,随后再从commitLog中读取待拉去消费消息的真正实体内容部分。 - CommitLog文件采用混合型存储(在一个broker下,所有topic共用一个commitLog文件),并通过建立consumeQueue的方式来区分不同topic下的不同messageQueue的消息,同时为消费消息起到了一定的缓冲作用(只有ReputMessageService异步服务线程通过doDispatch异步生成了ConsumeQueue队列的元素后,Consumer端才能进行消费)。这样,只要消息写入并刷盘至CommitLog文件后,消息就不会丢失,即使ConsumeQueue中的数据丢失,也可以通过CommitLog来恢复。
- 在一个borker内,生产者发送过来的消息是顺序写入CommitLog和ConsumeQueue的。消费端读取消息顺序读取ConsumeQueue,拿到消息在commitlog中的偏移量,但是消费端从commitlog中读取消息就会变成随机读。
顺序读和随机读
在linux中,文件是按照块存储的,每块的大小是4K。所以当创建一个文件时,即使文件是个空文件,它也会占用4K的空间。
linux通过Inode存储所有的块的位置。读文件时也是按照块来读去数据。在读取磁盘数据时,主要的时间是浪费在了寻找磁道以及旋转延迟上。所以当发生顺序读时,只需要寻找一次磁道后线性读取磁盘数据就可以了,而随机读时,由于不停的切换磁道,就会严重耗时。所以顺序读比随机读要快。
pagecache(页缓存)
页缓存是OS为了加速文件的读写做的优化。在应用程序读取文件信息时,并不是直接从磁盘加载数据的,因为磁盘的速度与cpu相比实在是太慢了,因此为了提高效率,添加了pagecache层。
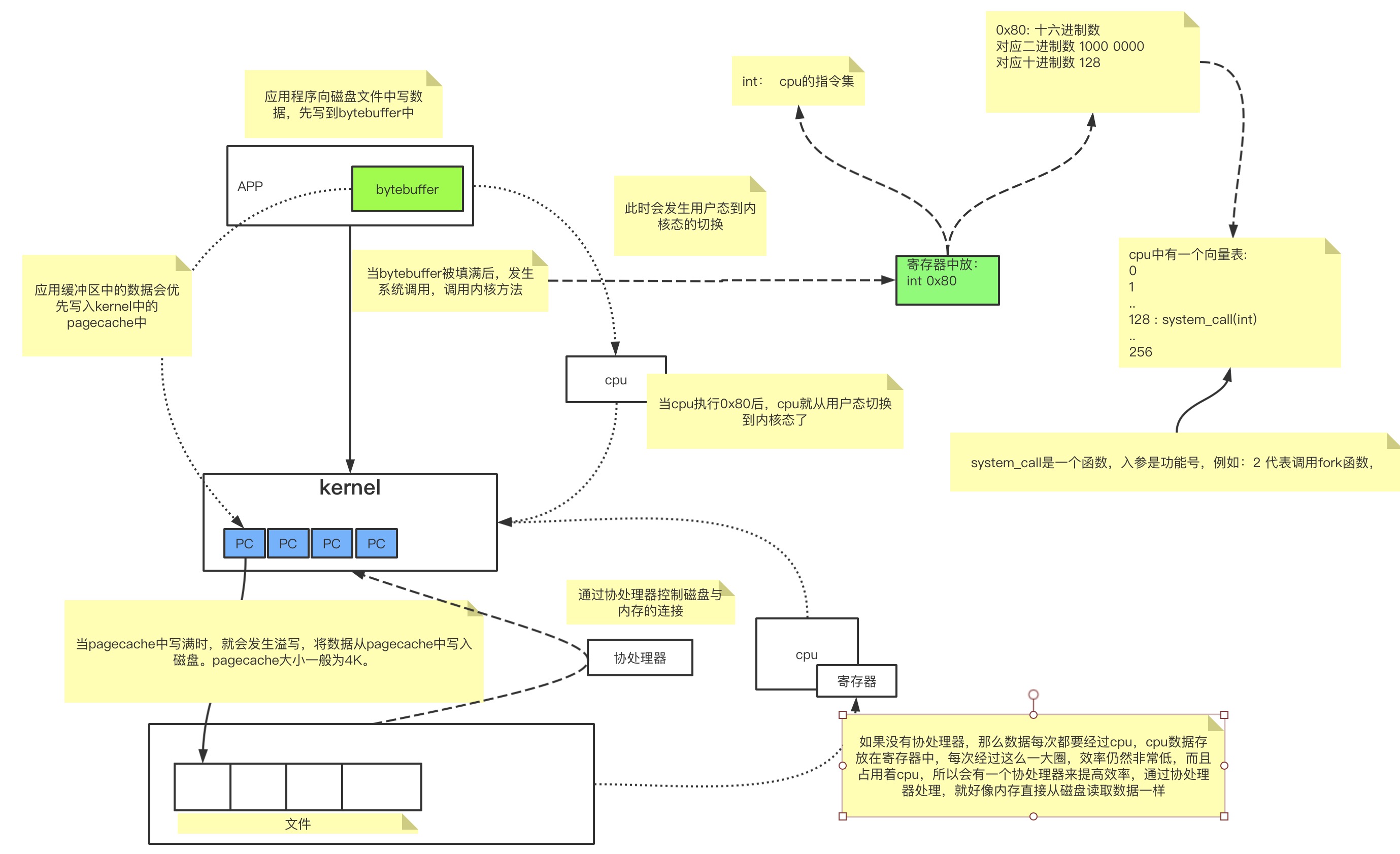
pagecache是一块内存区域,上面说linux的存储是按块存储的,pagecache的大小与文件存储块的大小是一样的,也就是说pagecache与存储块是一一对应的。
在读取文件时,cpu会直接从pagecache中读取数据,当pagecache中没有这块数据时,会发生缺页异常,从用户态切换到内核态,然后内核将磁盘块中的数据加载到pagecache中,并返回给应用程序。在发生缺页异常时,os将磁盘块中的数据加载到pagecache时,会对相邻块的数据做预读取。
当写入文件数据时也是直接写入pagecache中,然后os的刷盘机制将pagecache中的数据刷写到磁盘中。
因为pagecache机制的存在,因此对文件的读写都是在内存中进行的。顺序读时就会获得跟内存读写一样的速度。但是随机读由于可能会造成多次的缺页,每次缺页异常都会导致用户态内核态的切换,因此效率不如顺序读。
在RocketMQ中,由于ConsumeQueue中存储的数据占用空间较小,而且是顺序读取的,在pagecache机制的预读取作用下,ConsumeQueue的读性能相当于直接读内存。但是对于commitLog来说,读取消息内容大部分为随机读,会严重影响性能。
mmap
mmap又叫零拷贝。pagecache是os层对文件操作做的优化,rocektmq还在代码层使用了mmap来优化文件读写操作。
再linux中,应用程序是运行在用户态下的,而用户态下想要执行文件操作,虽然是操作pagecache,但是仍然是需要切换到内核态的。而且用户态下应用程序对文件的操作都是在虚拟内存中进行的,当虚拟内存中的数据写入pagecache时,就存在一次内存的拷贝,会浪费空间和性能。过程如下:

而使用mmap时,会直接将用户对虚拟内存的操作直接映射到pagecache中,少了一次拷贝,也少了一次上下文的切换。

rocketmq中正是因为需要使用内存映射的机制,所以文件存储都采用定长的结构来存储,方便一次将整个文件映射至内存。
消息刷盘

(1) 同步刷盘:如上图所示,只有在消息真正持久化至磁盘后RocketMQ的Broker端才会真正返回给Producer端一个成功的ACK响应。同步刷盘对MQ消息可靠性来说是一种不错的保障,但是性能上会有较大影响,一般适用于金融业务应用该模式较多。
(2) 异步刷盘:能够充分利用OS的PageCache的优势,只要消息写入PageCache即可将成功的ACK返回给Producer端。消息刷盘采用后台异步线程提交的方式进行,降低了读写延迟,提高了MQ的性能和吞吐量。
5.2 事物机制
为什么需要事物
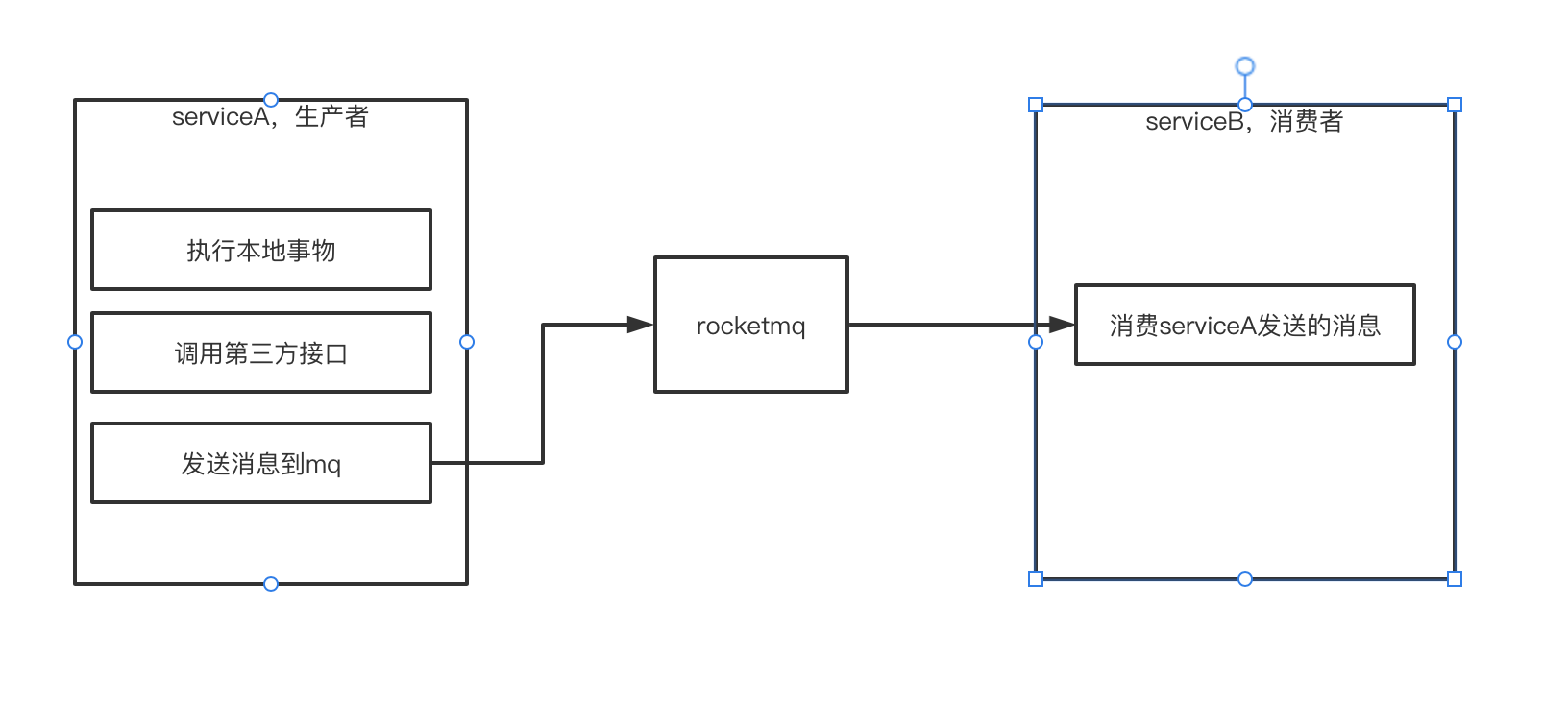
假设存在如上使用场景,serviceA需要做3件事:
- 执行本地事物
- 调用第三方接口
- 发送消息到mq,然后serviceB消费serviceA发送过来的消息
那么这个过程可能存在风险:1和2都执行成功了,但是第3步执行失败了(例如rocketmq挂了,或者serviceA与rocketmq的网络通信断了,或者serviceA挂了等情况),就会造成消息的丢失。
如果首先将消息发送到rocketmq
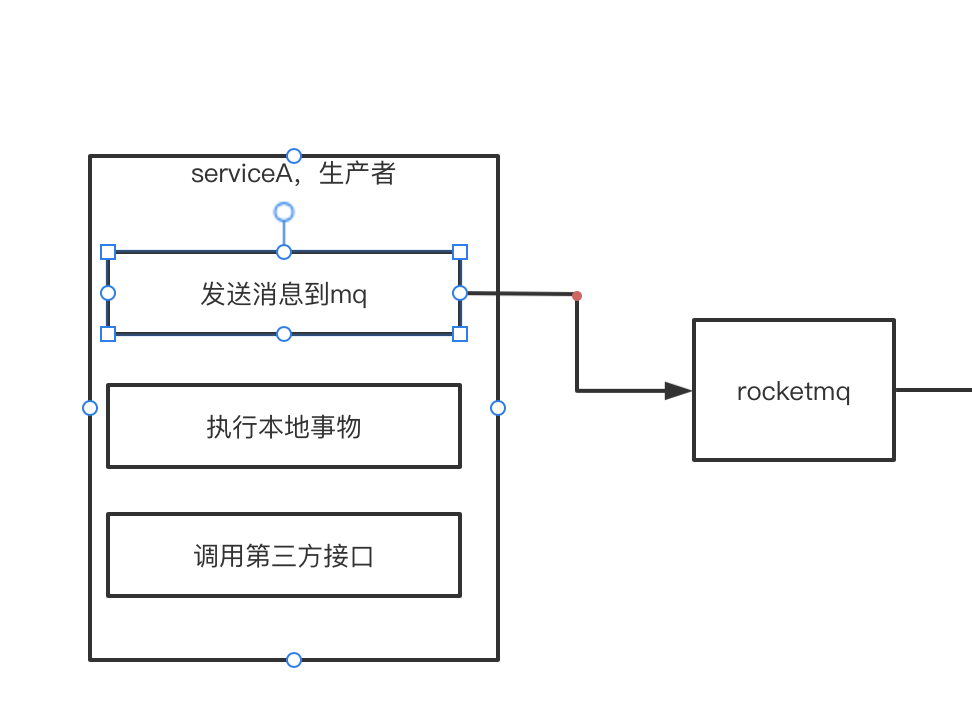
那么当消息发送到rocketmq后,消费者就可以消费消息了, 但是如果后面的本地事物或第三方接口调用等执行失败,那么本来不应该让消费者消费的消息却被消费了,就会造成数据的不一致。也会产生问题,因此就需要rocketmq的事物来保证数据的一致性。
rocketmq的事物
rocketmq的事物其实是采用了分布式事务中两阶段提交的方式来实现的。
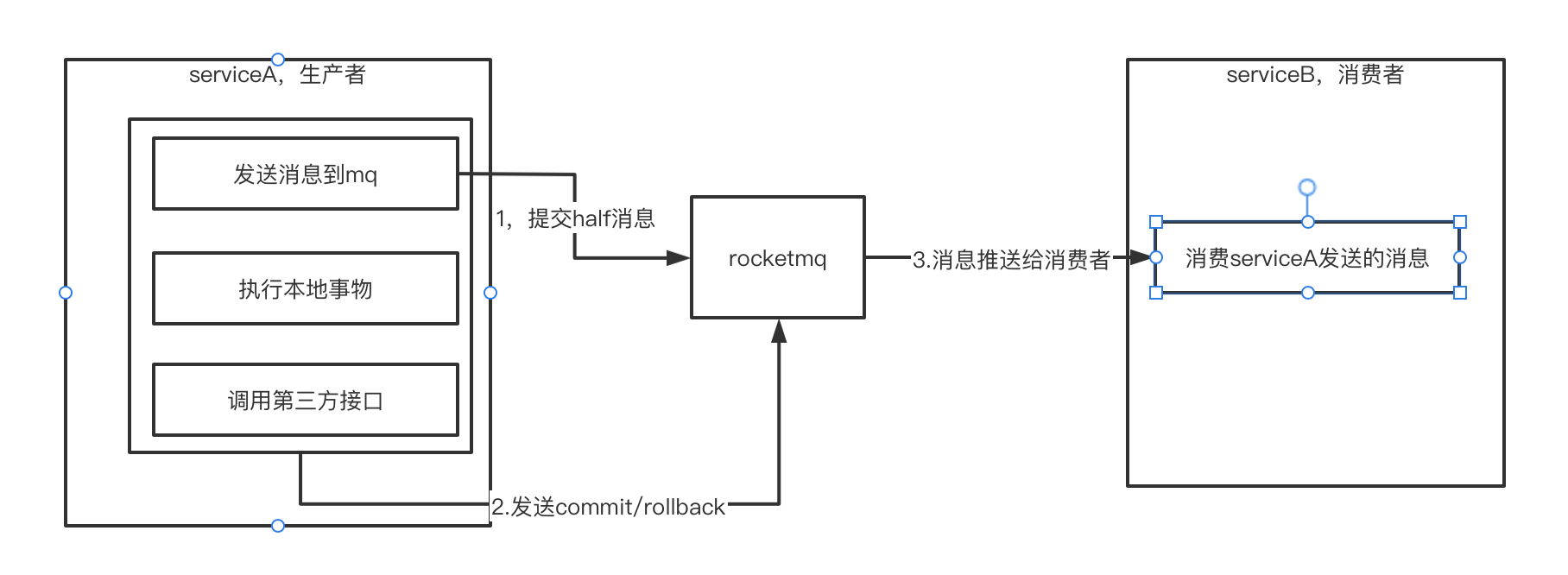
第一步一定是要先推送消息到mq
首先要判断serviceA是可以与rocketmq进行通信的,所以需要先将消息发送到mq中,但是此时发送的是half半消息(发送的是完整的消息,但是此时的消息对消费端是不可见的,所以叫做半消息,这样在事物提交之前,消费端都是看不到这条消息的)。
等到本地事物以及其他处理完成之后,再提交commit/rollback状态到rocketmq,rocketmq根据提交的状态来决定消息要不要对消费端可见。
但是现在仍然有问题:第一阶段提交半消息后,如果后面执行后面的操作时,serviceA挂了,那么这个半消息就永远无法处理了。
因此rocketmq提供了回调检查的补偿机制:
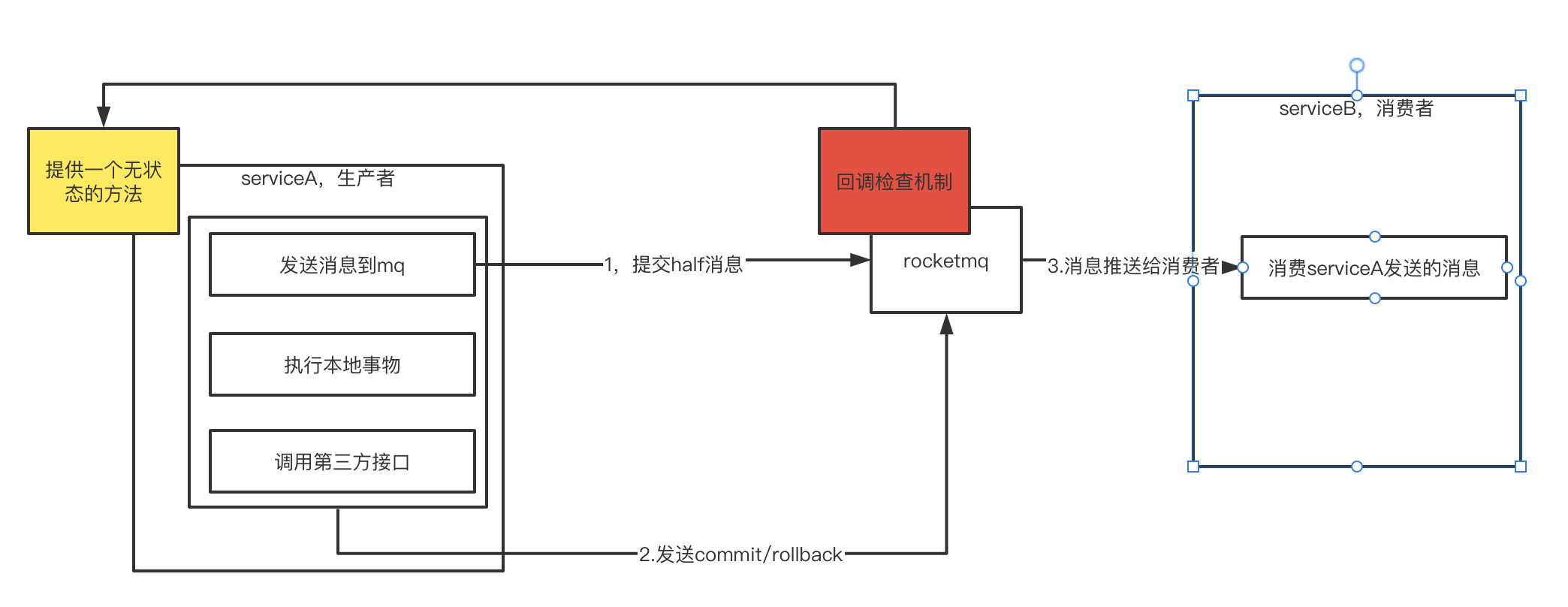
生产者这边需要提供一个无状态的检查方法,rocketmq会定时扫描半消息的数据,回调serviceA的检查方法,查询当前消息的状态(生产者在发送半消息成功后,需要记录这个消息的在rocketmq中的事物id)并返回给rocketmq。这里提供的回调检查方法一定要是无状态的。
这样即使serviceA挂掉重启之后,也可以通过回调检查机制重新提交消息的二阶段状态。
所以经过上面推理后,rocketmq的事物执行流程应该是如下:
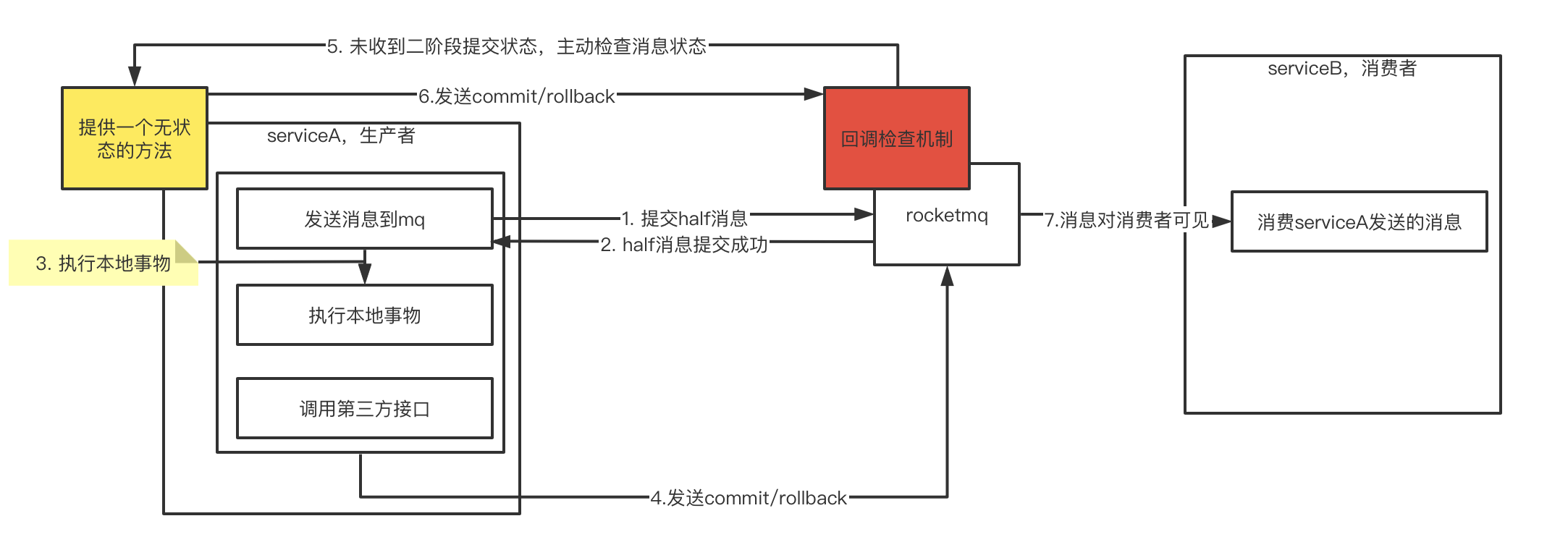
- rocketmq的回查次数默认为15次,超过次数将会认为此消息失败,可以通过broker配置
transactionCheckMax来修改这个次数。
代码验证
@Test
public void transactionProducer() throws Exception {
TransactionMQProducer producer = new TransactionMQProducer("transaction_group");
producer.setNamesrvAddr("192.168.64.5:9876;192.168.64.6:9876");
// 设置监听器
producer.setTransactionListener(new TransactionListener() {
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
// 发送半消息成功后,会调用此方法执行本地事务
System.out.println("msg = " + msg);
// 执行本地事物....
// i = 0, 二阶段提交成功
if ((Integer) arg == 0) {
return LocalTransactionState.COMMIT_MESSAGE;
}
// i = 1,二阶段回滚,消费端看不到消息
if ((Integer) arg == 1) {
return LocalTransactionState.ROLLBACK_MESSAGE;
}
// i=2, 触发重试机制,来查询消息
if ((Integer) arg == 2) {
try {
TimeUnit.SECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 当返回unKnow状态时,代表本地事物无法判断事物是否应该提交,例如本地事物中执行了异步接口调用等操作,
// 那么rocketmq就会触发回查,调用下面的checkLocalTransaction方法
return LocalTransactionState.UNKNOW;
}
return null;
}
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
// 未收到二阶段提交,走回查状态
System.out.println("msg = " + msg);
String id = msg.getUserProperty("id");
if (id.equals("2")) {
return LocalTransactionState.COMMIT_MESSAGE;
}
return LocalTransactionState.UNKNOW;
}
});
producer.start();
// 模拟发送3条消息
// i=0:发送半消息成功后处理完本地事物直接返回commit
// i=1: 二阶段提交失败
// i=2: 二阶段提交Unknow,模拟异步处理,或断电重启
for (int i = 0; i < 3; i++) {
Message message = new Message();
message.setTopic("transaction_topic");
message.setBody(("hello world" + i).getBytes());
message.putUserProperty("id", i + "");
// 1. 提交half消息
TransactionSendResult result = producer.sendMessageInTransaction(message, i);
System.out.println("result = " + result);
}
System.in.read();
}
@Test
public void consumerPush() throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("transaction_group");
consumer.setNamesrvAddr("192.168.64.5:9876;192.168.64.6:9876");
consumer.subscribe("transaction_topic", "*");
consumer.setMessageModel(MessageModel.CLUSTERING);
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
for (MessageExt messageExt : msgs) {
String brokerName = messageExt.getBrokerName();
int queueId = messageExt.getQueueId();
String body = new String(messageExt.getBody());
System.out.printf("broker: %s , queueId : %s, body : %s %n", brokerName, queueId, body);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.start();
System.in.read();
}
half半消息是如何实现的
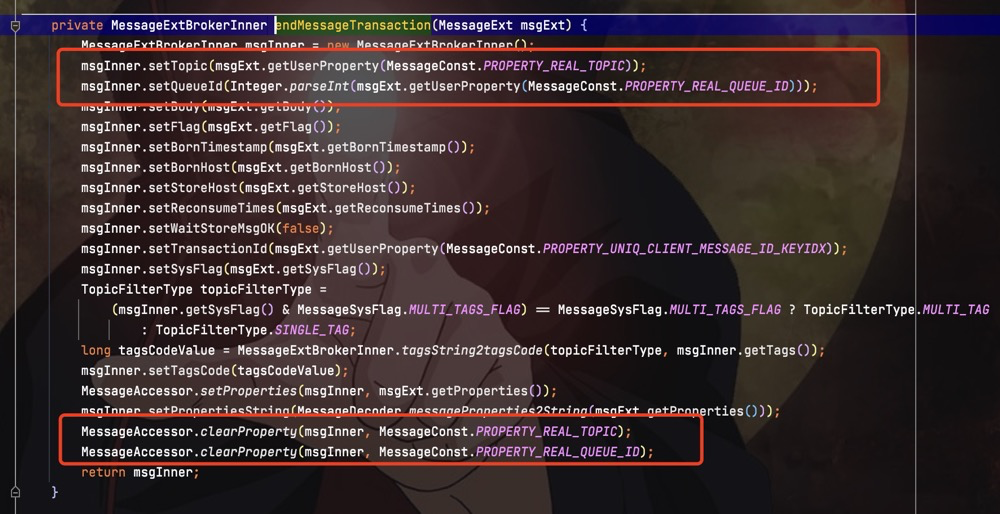
当broker收到一条事物的half消息时,并不会直接将消息写入到真实的topic中去。而是将half消息写入RMQ_SYS_TRANS_HALF_TOPIC这个topic下的consumequeue里,并将消息持久化到commitLog中。在写入RMQ_SYS_TRANS_HALF_TOPIC时,会在消息的属性中存入真实的topic
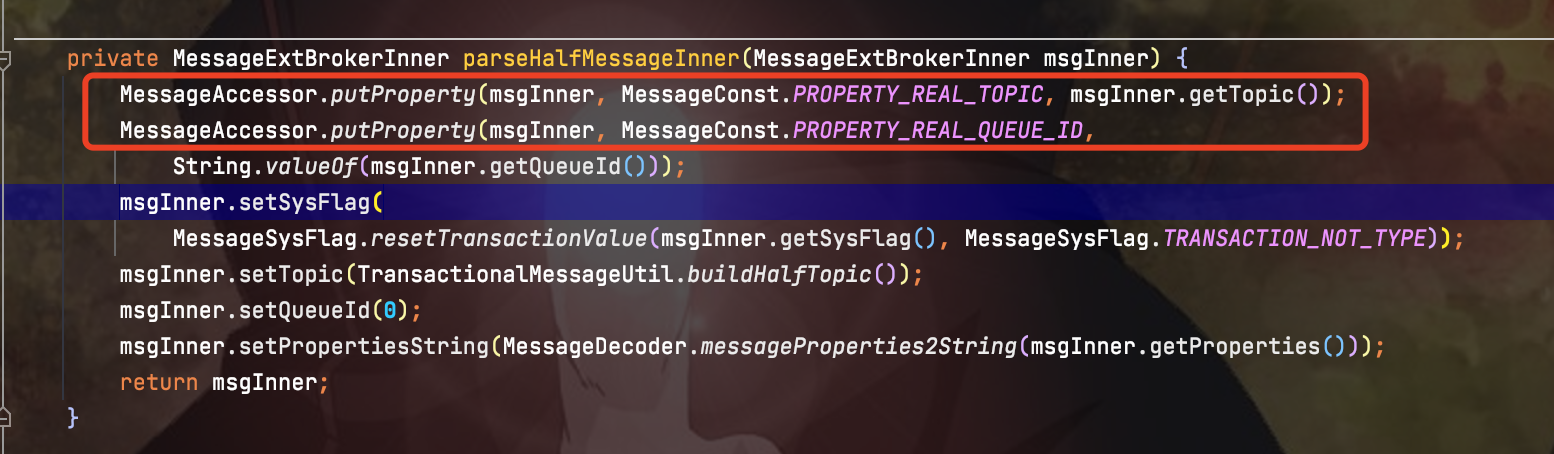
保证后面消息commit时,消息会转存入真实的topic下。
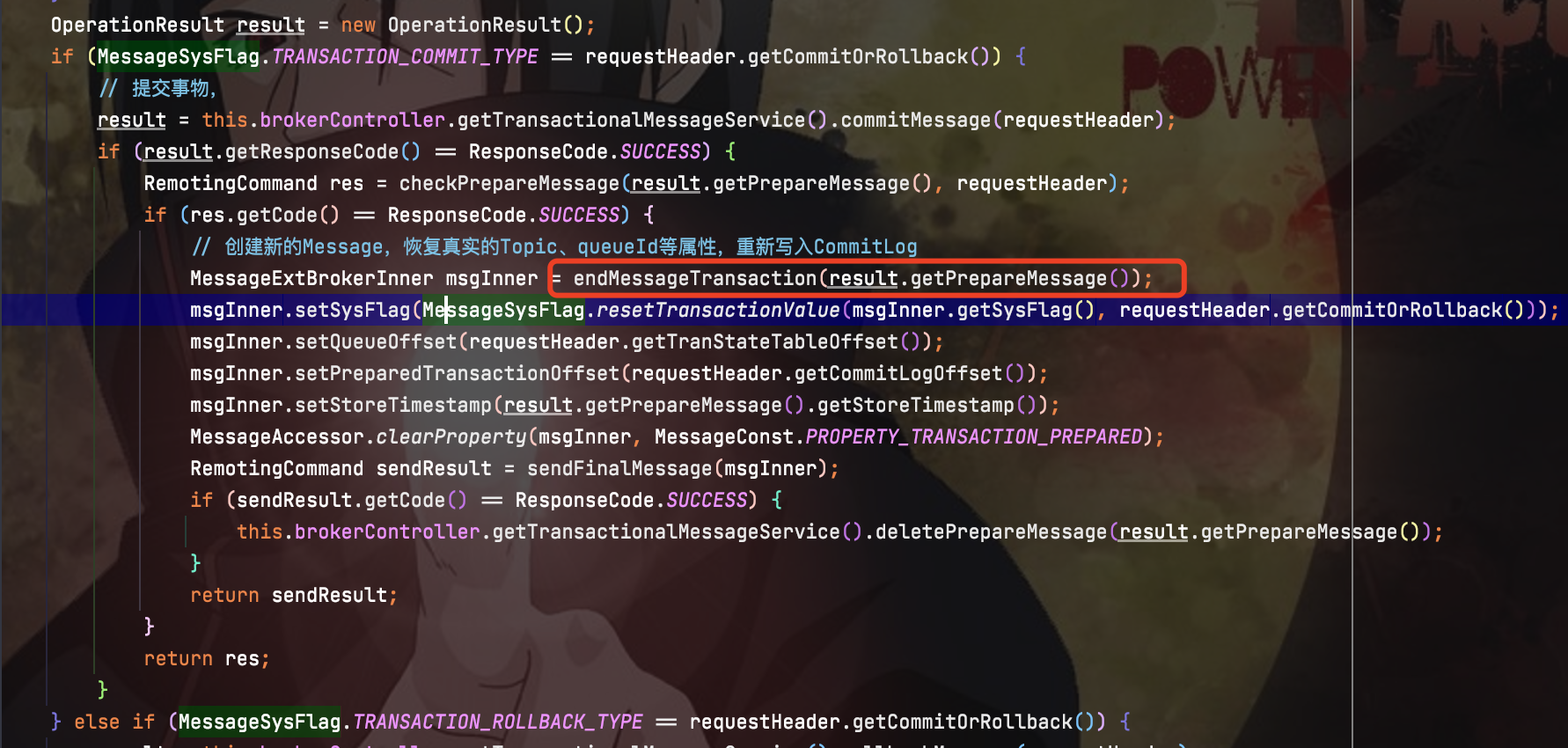
RocketMQ会有定时任务扫描RMQ_SYS_TRANS_HALF_TOPIC中的half消息,如果超过一段时间还是half消息,那么就会通过回查接口查询消息的状态。当获取到消息的最终状态后,就会讲消息从半消息队列中移除。
事实上,由于rocketmq中消息是顺序写入的,因此并不会真的从磁盘中把消息删除掉,而是通过一个op队列来操作的。当half消息的最终状态确认后--rollback或commit,就会将消息添加到一个RMQ_SYS_TRANS_OP_HALF_TOPIC主题下。当定时任务扫描时,如果half消息在此队列下,那么就是已经确认最终状态的,相当于逻辑移除half消息队列。反之如果不存在,那么就说明此half消息还未确认最终状态。
所以half消息的实现流程如下
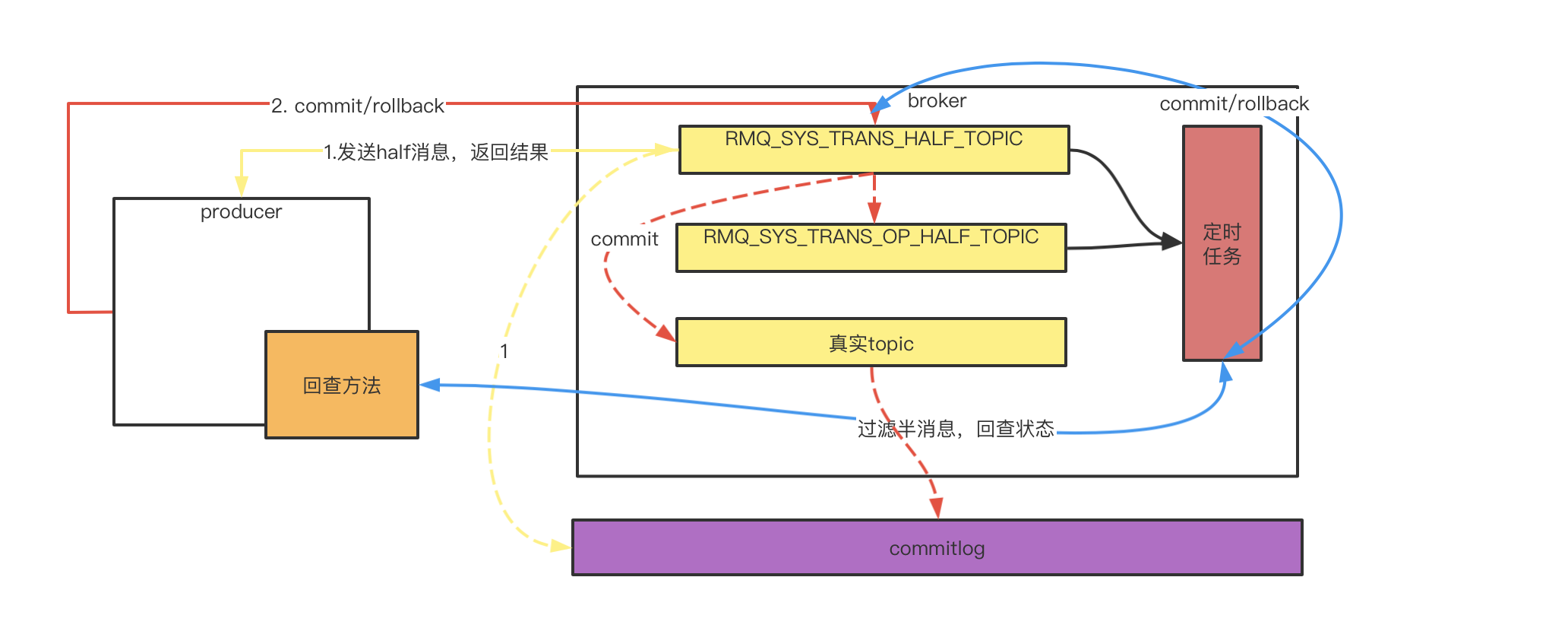
5.3 延迟队列
延迟队列的常见实现方式为:
- 消息临时存储到临时队列里
- 定时任务循环扫描临时队列,找到即将到期的消息,加入消费队列。
延迟机制一般有两种:
- 延迟时间粒度细化,支持客户自定义时间
- 延迟时间粒度粗化,给出指定的延迟时间范围
rocketmq就是使用第二种方式。rocketmq中定义了延迟级别:
| 级别 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 时间 | 1s | 5s | 10s | 30s | 1m | 2m | 3m | 4m | 5m | 6m | 7m | 8m | 9m | 10m | 20m | 30m | 1h | 2h |
延迟级别使用:
Message message = new Message("test-topic", "xxxxxx".getBytes());
// 设置延迟级别
message.setDelayTimeLevel(1);
第一种延迟方式,一般通过时间轮来实现
时间轮

简单实现
package com.gouxiazhi.io;
import java.io.IOException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
/**
* 时间轮
*
* @author zhaoshuai
*/
public class TimeRingBuffer {
// 时间轮,存放
private final Job[] ring;
private final int size;
private ExecutorService executorService = Executors.newFixedThreadPool(6);
public TimeRingBuffer() {
ring = new Job[6];
size = 6;
for (int i = 0; i < size; i++) {
ring[i] = new Job();
}
}
public void put(int delay, Runnable task) {
int cycle = delay / size;
int index = delay % size;
Job job = ring[index];
job.putTask(cycle, task);
}
public void start() {
executorService.execute(()-> {
for (int i = 0; i < size; i++) {
Job job = ring[i];
List<Runnable> list = job.jobChain.pollFirst();
if (list != null) {
executorService.execute(()-> {
list.forEach(Runnable::run);
});
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
if (i == size - 1) {
i = 0;
}
}
});
}
public static void main(String[] args) throws IOException {
TimeRingBuffer trb = new TimeRingBuffer();
trb.start();
trb.put(4, () -> System.out.println("4 = " + 4));
trb.put(10, () -> System.out.println("10 = " + 10));
trb.put(16, () -> System.out.println("16 = " + 16));
trb.put(22, () -> System.out.println("22 = " + 22));
System.in.read();
}
}
class Job {
public LinkedList<List<Runnable>> jobChain = new LinkedList<>();
public void putTask(int cycle, Runnable task) {
int size = jobChain.size();
// 长度补充
for (int i = size; i <= cycle; i++) {
jobChain.addLast(new ArrayList<>());
}
List<Runnable> tasks = jobChain.get(cycle);
tasks.add(task);
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
2019-06-27 springmvc返回json数据以及session的使用
2019-06-27 springmvc参数传递三:后台往前台传参
2019-06-27 springmvc参数传递二:模型传参(非常常用)
2019-06-27 springmvc参数传递一:形参传参(常用)