


es-基础
ES学习笔记-基础篇
ES简介
所有的应用程序都会有搜索功能,在此之前,回想我们如果想要在应用程序中实现搜索功能会如何做?
select xxx from xxx where name like '%手机%'
大多数情况下,我们使用数据库存储数据,那么当需要实现搜索功能时,会使用sql语句的like模糊匹配来实现。但是使用like的方式会存在如下缺点:
- 如果左边也有
%时,那么会导致索引失效。那么如果数据量非常巨大时,会导致效率非常低。 - 数据相关度太低。
什么是数据相关度?
我们打开京东官网,搜索关键字小米手机 可以看到如下搜索结果:
可以看到如下搜索结果: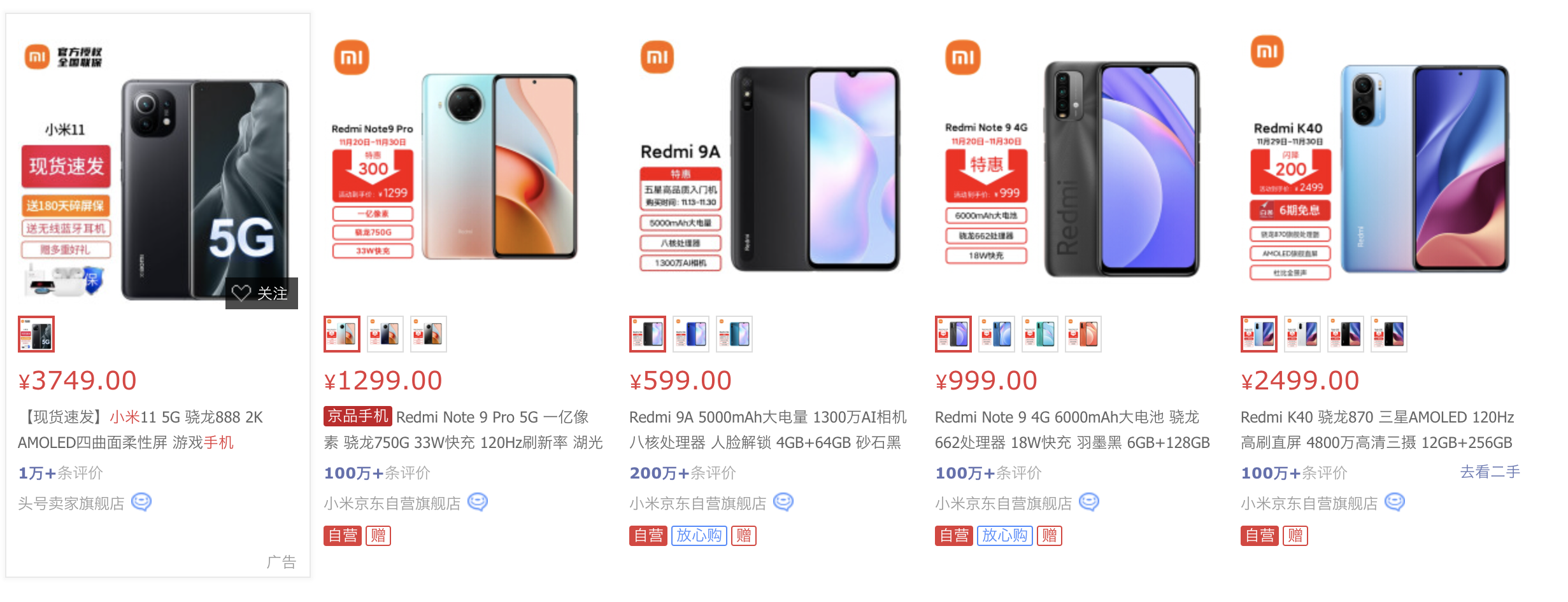 可以看到结果中包含小米11,红米等一系列手机产品。甚至翻到最后一页我们还会看到:
可以看到结果中包含小米11,红米等一系列手机产品。甚至翻到最后一页我们还会看到:
小米耳机,小米电源等产品。那么我们将上面的产品假设整理成如下一张表:
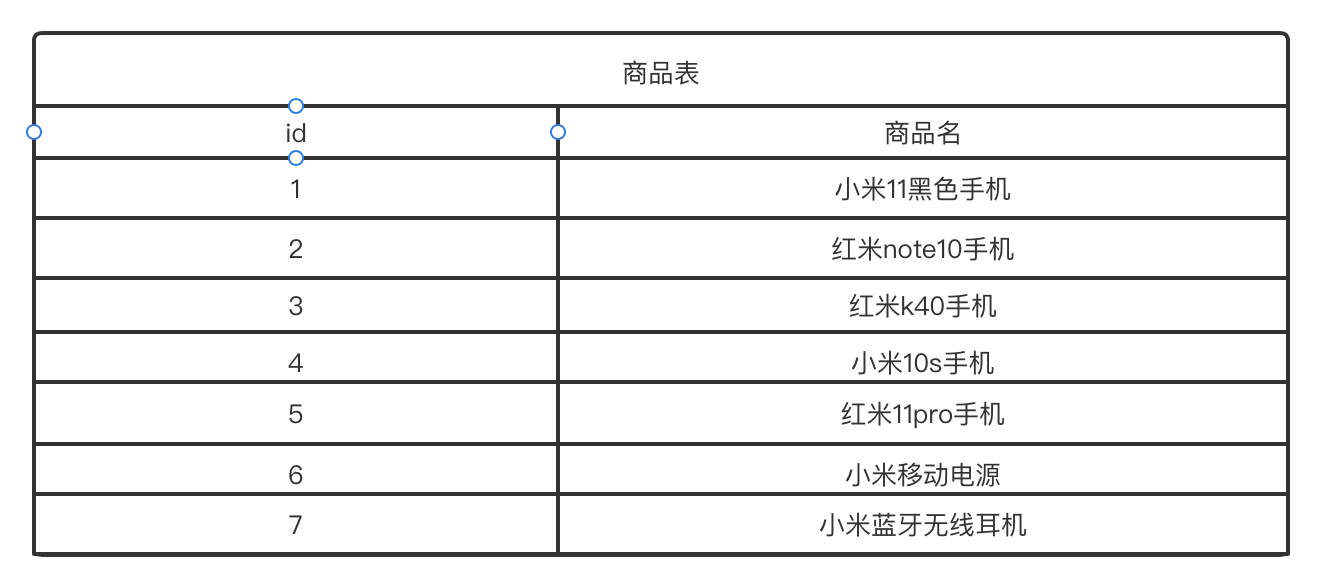
假设后台数据库是存储的这样的数据,那么我们使用like的方式搜索小米手机能够搜到什么结果?一条数据都搜不到。但是其实上面的所有数据都是与我们的小米手机相关的,也就是说理论上只要与我们的关键字相关的产品应该都能查到,这就是数据相关度。
那么如何解决上面的两个缺点呢?
搜索引擎
什么是搜索引擎?
搜索引擎是指通过一定的策略,运用特定的计算机程序从互联网搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关信息展示给用户的系统。
搜索引擎分为两类:
- 垂直搜索引擎:有针对性的针对某一个领域进行搜索。例如天猫、京东的搜索功能。
- 全文搜索引擎:只从互联网上所有的站点中查询关键字相关的内容,例如百度、谷歌。
简而言之就是:如果我在浏览器上搜索华为,那么我们会得到所有与华为相关的数据,包括华为官网、华为图片信息、华为产品、华为公司贴吧、华为论坛、华为相关八卦等等等等,这些数据都是从互联网上所有的数据中搜集的。这就是全文搜索。但是如果我们在京东搜索华为,那么只会搜索到华为相关的售卖的商品。这就是垂直搜索。
搜索引擎应该具备的特点:
- 查询速度快
- 结果准确
- 检索结果丰富
如何实现上面三个特点?
-
查询速度快。搜索引擎从全文搜索数据时,数据量是非常巨大的,要想达到速度快,首先想到的是:索引。
索引都具备如下特点:
- 帮助快速检索
- 以数据结构为载体
- 以文件形式落地
以mysql为例,在mysql中,默认使用的存储引擎为innodb,innodb索引使用B+树作为数据结构,最终是以
.ibd为后缀的文件的形式保存落地的。那么搜索引擎的索引能不能使用mysql这一套呢?
不能,因为mysql创建索引时有一个很重要的点就是索引的列不能太长。为什么列内容不能太长?
如果索引列内容过长,就会导致B+树每个节点可存储的数据量变少,直接导致B+树的深度过高,IO次数变多导致速度变慢。
而搜索引擎做全文检索时,一般数据量都是非常大的,而且数据条数也是海量的。因此搜素引擎的索引需要解决两个问题:
- 索引列数据大
- 条目数据总量大
-
结果准确和检索结果丰富这两个问题可以放在一起处理。在保证检索结果丰富的前提下,要求结果准确。
再来看一下上面的数据如何来检索能够保证检索结果丰富和结果准确的目标。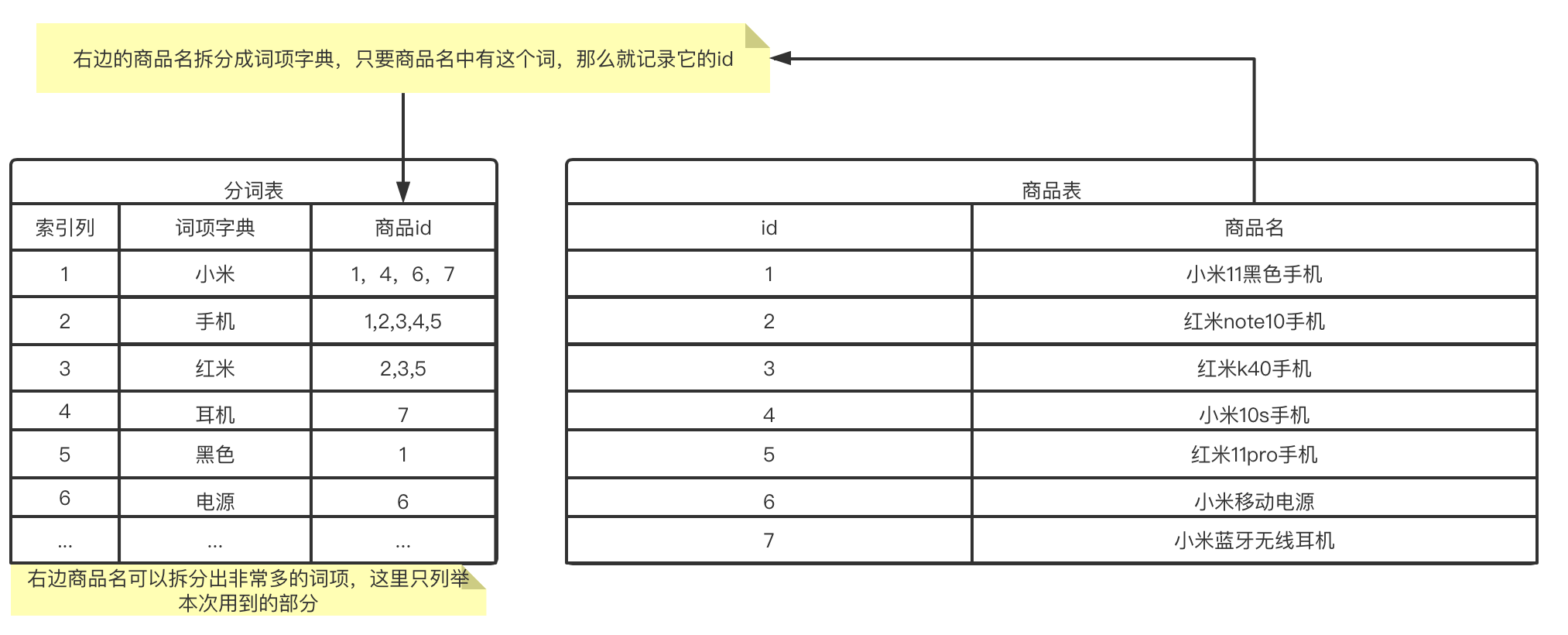 多加了一张分词表(暂且称为)。
多加了一张分词表(暂且称为)。在最开头我们说如果使用mysql的
like去搜索小米手机的话,是一条记录都搜不到的,那么此时如果我们使用上面这种方式搜索的话:-
将搜索关键字小米手机拆分为词项:
小米和手机。 -
拿着这两个词项先到分词表中查询对应的商品id:
小米:1,4,6,7手机:1,2,3,4,5上面列表取并集我们就拿到了
1,2,3,4,5,根据这些id去商品表查数据,可以看到商品名都是与搜索关键字相关的。这样就实现了检索结果丰富的目标。上面结果取交集就得到了1,4这些都是同时满足两个关键字的商品,也就是最接近搜索目标的结果。也就实现了结果准确的目标。
-
至此,搜索引擎的三个特点我们都已经聊清楚了,其实上面的三个特点都是已经被实现的,它就是lucene
Lucene
Lucene是一个成熟的全文检索库,由java语言编写,具有高性能、可伸缩的特点,并且开源免费。Lucene的作者Doug Cutting是资深的全文检索专家,lucene最开始发布在他本人的主页上,2001年10月贡献给Apache,成为Apache基金会下的一个子项目。Lucene是一个IR库(Information Retrieval library)。后来才由Shay Banon在其基础上开发了Elasticsearch。
关于Lucene不做太多介绍,但是要了解一点Lucene不是搜索引擎,但是它可以做搜索引擎。上面我们说的搜索引擎三个特点,其实Lucene都已经做了实现。
倒排索引
其实上面提到的解决方案有个名字叫做倒排索引,上面我们说的算是它的简易实现。
正排索引和倒排索引
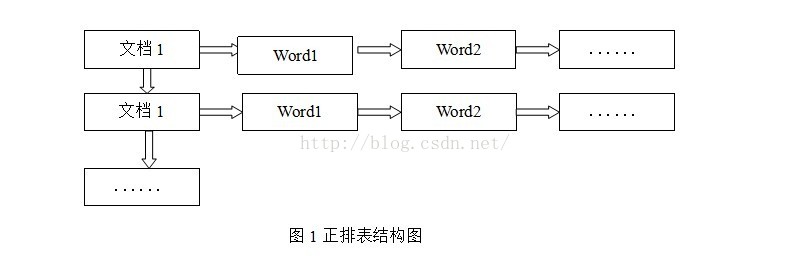
正排索引:正排表是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。
正排表结构如图1所示,这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
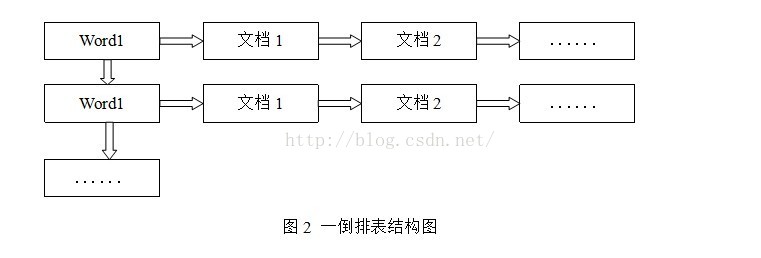
倒排索引:
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
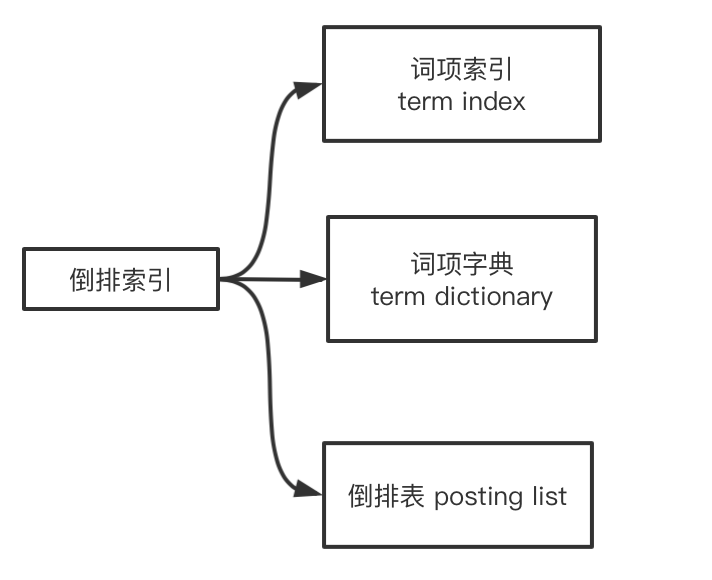
倒排表的结构图:
索引都是以数据结构为载体,以文件的形式落地。
倒排索引的数据结构
索引要想速度快,那么数据量就要保证小。在数据量巨大的情况下保证存储数据小,那么就需要压缩数据,而且为了不能影响索引的效率,就需要高效的压缩解压算法。
倒排表压缩算法
倒排表是数据id的集合,一个词项的对应的id可能会非常多,而且这些id都是数字且都是大于0的,在Lucene中针对倒排表有两种压缩算法。
FOR(Frame of Reference)算法
假设现在有一条倒排表数据,内容为如下:[334, 743, 1017, 1157, 1180, 1298, 1358, 1475, 1679, 2895, 3917, 4437, 4838, 5173, 5291, 6010, 8140, 8667, 9340, 9450]。我们假设id为int类型(实际可能为long类型),那么int类型每个数字占用4字节。上面20个数字占用空间为80个字节。
原始数据中最大的数字为9450,二进制表示为10010011101010,也就是说上面的数字,最大的有效位数为16位,只需要用16位就可以表示上面的每一个数字。也就是可以用16x20=320bit=40个字节表示上面所有的数字。
如果想要进一步缩减数字占用的空间,那就要将每一个数字变小。首先将上面postinglist数字相邻数字相减,得到:[409, 274, 140, 23, 118, 60, 117, 204, 1216, 1022, 520, 401, 335, 118, 719, 2130, 527, 673, 110],可以看到相减后的数据中最大的数字为2130,占用的位数为10000101001012位,那么所有数字就可以使用12x20=240bit=30字节。上面缩减后的数字我们可以看到,有的相差比较大,还可以将缩减后的数字分组:[409, 274, 140, 23, 118, 60, 117, 204],[1216, 1022, 520, 401, 335, 118, 719, 2130, 527, 673, 110]。第一个数字最大值4091100110019位,占用9x8=72bit=9字节。后面的占用12x11=132bit约等于17字节,那么上面所有数字就可以用9+17=26个字节表示,可以看到从最开始的80的字节,可以压缩到26个字节。这就是FOR压缩算法。下面为官网的算法图解:
如果postinglist为[1,2,3...100w]等差数列的数字,那么原占用空间:400w字节约等于3906KB,经过FOR压缩算法压缩后为[1,1,1,1....],100w个1使用FOR压缩算法,只需要100wbit=125000字节=122k。
结论:数字越密集,FOR压缩效率越高。
RBM(Roaring Bitmap)算法
bitmap位图,位图是一种映射关系。RBM算法就是利用这种映射关系,一个int类型数字占用32位,将它拆分为高16位和低16位,那么我们会发现一个关系:
以131385为例,二进制为:10 0000 0001 0011 1001,将它按照高16位和低16位拆开表示为:(2, 313)。
再将131385除65535,可以得到商为2,余数为313,也是(2, 313)。
因为16位能表示的最大值就是65535,因此按照高16位低16位拆分,其实就想当于是除了65535。
现在将数据按照高16位和低16位拆分后,那么高16位最大为65535,低16位最大也是65535。可以按照这个来组成一个映射关系。首先因为postinglist中存放的数据是文档的id,因此是不可能有重复数据的。那么也就是说,在同一个高16位下,低16位也不可能重复。那么就可以直接使用位偏移量来表示低16位数字本身。如下图:
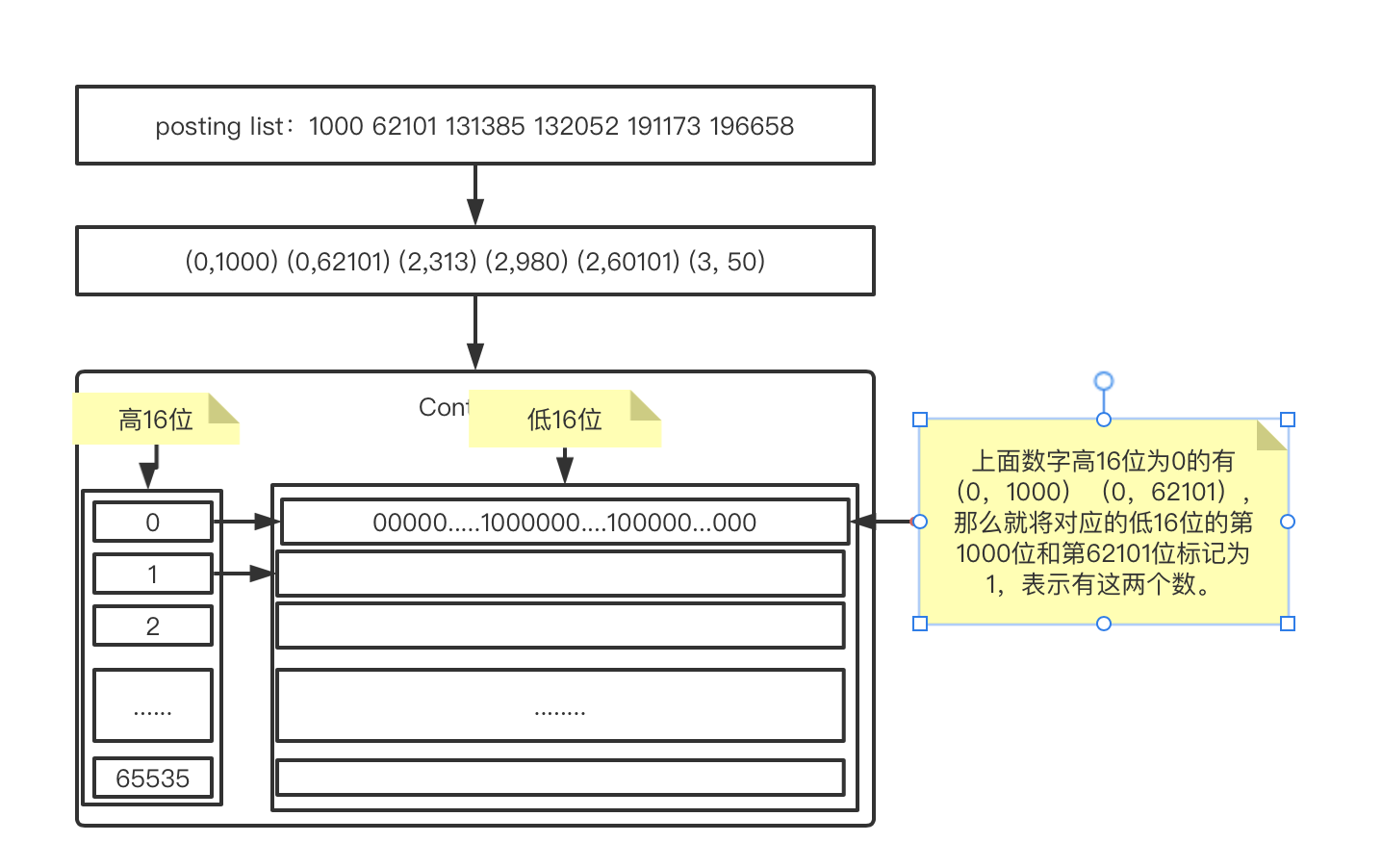
经过这么一处理,同一个高16位下,无论有多少个数(不可能超过65536个),占用空间恒定都是65536bit/8/1024=8KB的空间。这就是RBM算法。
官网RBM算法图解:
两个算法如何选择
官网提供了上面这张图,可以看出posting list数字个数小于4096时,使用FOR算法占用空间更小,超过时,使用RBM算法效率更高。lucene会动态计算决定使用哪儿中算法来压缩数据。
索引压缩算法FTS
Elasticsearch
Elastic是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎基础上的搜索引擎。当然Elasticsearch并不仅仅是Lucene那么简单,它不仅包括全文搜索功能,还可以进行一下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
ES安装
在es官网下载es压缩包,解压得到es目录。
bin: es脚本文件,包括启动脚本,安装脚本等config: es配置文件jdk: es运行环境,es是java写的,需要手动配置运行环境,如果本地没有安装java,就会使用自带的运行环境lib: es运行需要的相关类库logs: es日志文件modules: 所有包含es的模块plugins: 包含所有已经安装的插件
**学习服务器虚拟机ip为:192.168.64.2 **
单节点安装
为es创建用户组
root@node01:/# mkdir /home/es
root@node01:/# groupadd es
root@node01:/# useradd -s /bin/bash -g es es
root@node01:/# passwd es
root@node01:/# chmod -R es.es /home/es
将解压后的文件放入/home/es目录
root@node01:/home/es/elasticsearch-7.15.2# pwd
/home/es/elasticsearch-7.15.2
切换到es用户,启动es
es@node01:~/elasticsearch-7.15.2/bin$ cd
es@node01:~$ ls
elasticsearch-7.15.2 elasticsearch-7.15.2-linux-x86_64.tar.gz
es@node01:~$ cd elasticsearch-7.15.2
es@node01:~/elasticsearch-7.15.2$ cd bin/
es@node01:~/elasticsearch-7.15.2/bin$ ./elasticsearch -d
-
注意:启动报如下错误:
ERROR: [3] bootstrap checks failed. You must address the points described in the following [3] lines before starting Elasticsearch. bootstrap check failure [1] of [3]: max number of threads [3789] for user [es] is too low, increase to at least [4096] bootstrap check failure [2] of [3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] bootstrap check failure [3] of [3]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured ERROR: Elasticsearch did not exit normally - check the logs at /home/es/elasticsearch-7.15.2/logs/elasticsearch.log解决方案参见[https://www.cnblogs.com/shanfeng1000/p/14684295.html]
验证启动结果:
es@node01:~/elasticsearch-7.15.2/bin$ curl -X GET http://localhost:9200/_cat/nodes
127.0.0.1 52 93 8 0.09 0.17 0.09 cdfhilmrstw * node01
出现上面内容证明启动成功了。但是此时打开浏览器输入:http://服务器ip:9200会显示无法打开该页面。
修改es配置文件,重启es
es@node01:~/elasticsearch-7.15.2$ cd ~/elasticsearch-7.15.2/config/
es@node01:~/elasticsearch-7.15.2/config$ vi elasticsearch.yml
# 修改ip地址配置保存
network.host: 0.0.0.0
# 重启服务
es@node01:~/elasticsearch-7.15.2/config$ cd ..
es@node01:~/elasticsearch-7.15.2$ cd bin/
es@node01:~/elasticsearch-7.15.2/bin$ ./elasticsearch -d
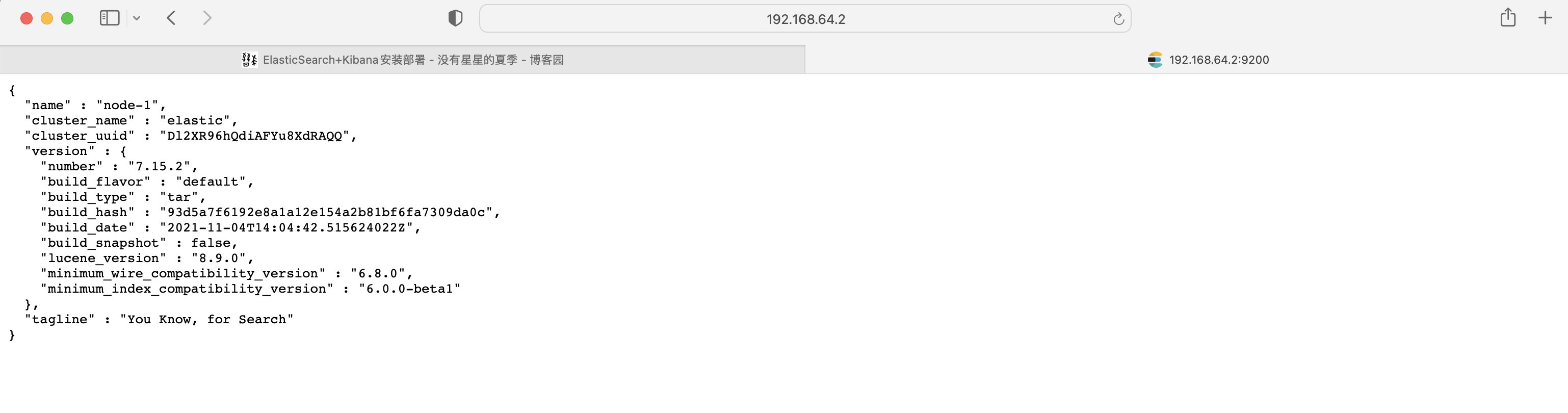
可以在浏览器进行访问了。
Kibana安装
下载地址:[ https://artifacts.elastic.co/downloads/kibana/kibana-7.15.2-linux-x86_64.tar.gz]
es@node01:~$ wget https://artifacts.elastic.co/downloads/kibana/kibana-7.15.2-linux-x86_64.tar.gz
--2021-12-10 18:33:23-- https://artifacts.elastic.co/downloads/kibana/kibana-7.15.2-linux-x86_64.tar.gz
Resolving artifacts.elastic.co (artifacts.elastic.co)... 34.120.127.130, 2600:1901:0:1d7::
Connecting to artifacts.elastic.co (artifacts.elastic.co)|34.120.127.130|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 284061836 (271M) [application/x-gzip]
Saving to: ‘kibana-7.15.2-linux-x86_64.tar.gz’
kibana-7.15.2-linux-x86_64.tar.gz 100%[===================================>] 270.90M 8.97MB/s in 28s
2021-12-10 18:33:51 (9.77 MB/s) - ‘kibana-7.15.2-linux-x86_64.tar.gz’ saved [284061836/284061836]
es@node01:~$ ls
elasticsearch-7.15.2 kibana-7.15.2-linux-x86_64.tar.gz
下载完成后,解压并启动:
es@node01:~$ ls
elasticsearch-7.15.2 kibana-7.15.2-linux-x86_64.tar.gz
es@node01:~$ tar xf kibana-7.15.2-linux-x86_64.tar.gz
es@node01:~$ ls
elasticsearch-7.15.2 kibana-7.15.2-linux-x86_64 kibana-7.15.2-linux-x86_64.tar.gz
es@node01:~$ rm -rf kibana-7.15.2-linux-x86_64.tar.gz
es@node01:~$ mv kibana-7.15.2-linux-x86_64 kibana-7.15.2
es@node01:~$ ls
elasticsearch-7.15.2 kibana-7.15.2
es@node01:~$ cd kibana-7.15.2/
es@node01:~/kibana-7.15.2$ ls
LICENSE.txt NOTICE.txt README.txt bin config data node node_modules package.json plugins src x-pack
es@node01:~/kibana-7.15.2$ cd config/
es@node01:~/kibana-7.15.2/config$ vi kibana.yml
# 配置es地址
server.host: "192.168.64.2"
elasticsearch.hosts: ["http://localhost:9200"]
es@node01:~/kibana-7.15.2/config$ cd ../bin
es@node01:~/kibana-7.15.2/bin$ ls
kibana kibana-encryption-keys kibana-keystore kibana-plugin
es@node01:~/kibana-7.15.2/bin$ ./kibana
验证启动成功:
浏览器输入:http://ip:5601
elasticsearch集群安装
ealstic本身就是分布式的,集群修改如下配置:
# node-1 master
cluster.name: elastic
node.name: node-1
path.data: data
path.logs: logs
network.host: 0.0.0.0
discovery.seed_hosts: ["192.168.64.1", "192.168.64.4"]
cluster.initial_master_nodes: ["node-1"]
# node-2 shards
cluster.name: elastic
node.name: node-2
path.data: data
path.logs: logs
network.host: 0.0.0.0
discovery.seed_hosts: ["192.168.64.1", "192.168.64.4"]
cluster.initial_master_nodes: ["node-1"]
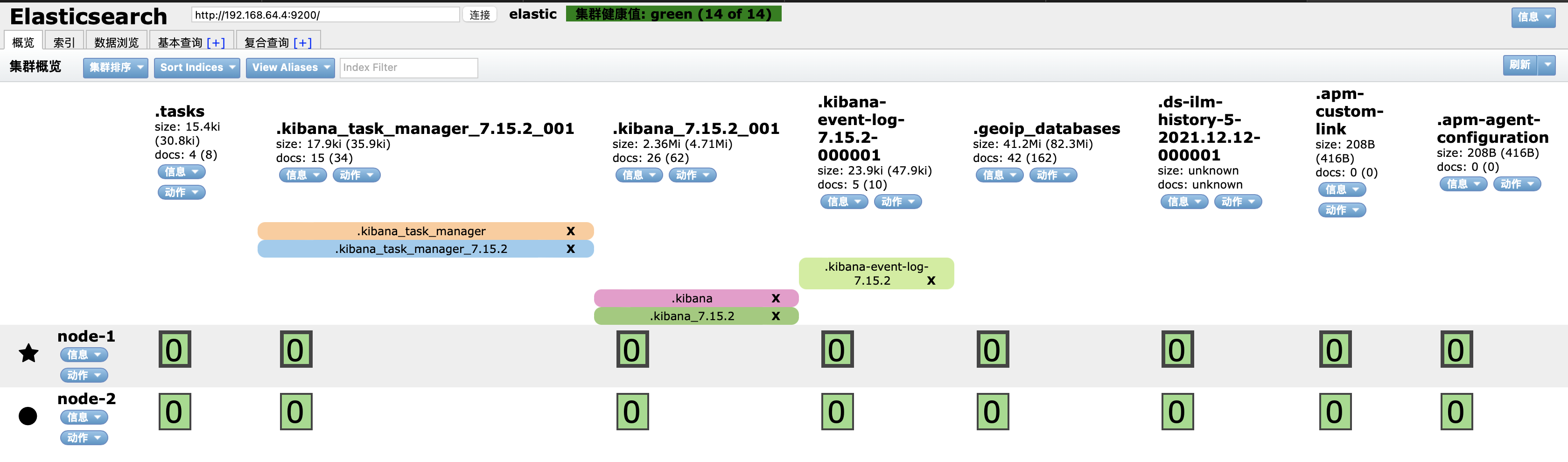
启动服务,浏览器输入:http://192.168.64.1/_cat/nodes?v
可以看到上图所示节点信息
elasticsearch-head插件安装
head插件是为了方便的管理集群信息提供的图形化界面
安装nodejs
root@node01:~# wget https://nodejs.org/dist/v16.13.1/node-v16.13.1-linux-x64.tar.xz
root@node01:~# tar xf node-v16.13.1-linux-x64.tar.xz
root@node01:~# mv node-v16.13.1-linux-x64.tar.xz nodejs
root@node01:~# cd nodejs/bin
root@node01:~# node -v
v16.13.1
安装head插件:
root@node01:~/nodejs/bin# ./npm install -g grunt-cli
root@node01:~/nodejs/bin# grunt -version
grunt-cli v1.4.3
root@node01:~/nodejs/bin# wget https://github.com/mobz/elasticsearch-head/archive/refs/heads/master.zip
root@node01:~/nodejs/bin# ll
total 78788
drwxr-xr-x 2 es es 4096 Dec 14 20:01 ./
drwxr-xr-x 6 es es 4096 Dec 1 19:29 ../
-rw-r--r-- 1 root root 1357536 Dec 14 20:01 master.zip
-rwxr-xr-x 1 es es 79310832 Dec 1 19:29 node*
lrwxrwxrwx 1 es es 38 Dec 1 19:29 npm -> ../lib/node_modules/npm/bin/npm-cli.js*
lrwxrwxrwx 1 es es 38 Dec 1 19:29 npx -> ../lib/node_modules/npm/bin/npx-cli.js*
root@node01:~/nodejs/bin# unzip master.zip
root@node01:~/nodejs/bin# ls
corepack elasticsearch-head-master master.zip node npm npx
root@node01:~/nodejs/bin# mv elasticsearch-head-master ~
root@node01:~# cd elasticsearch-head-master
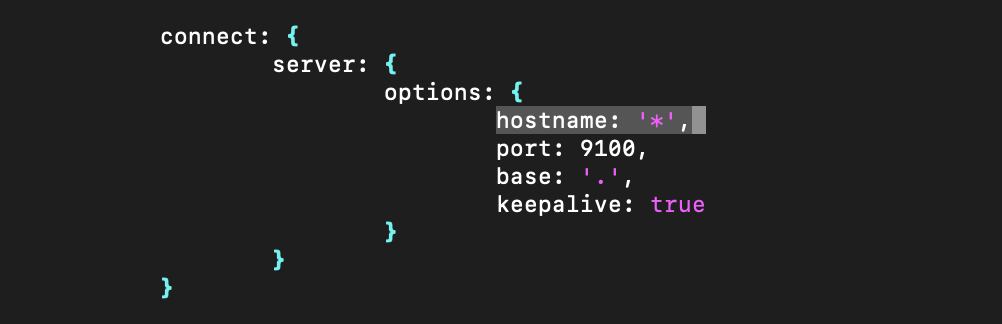
root@node01:~/elasticsearch-head-master# vi Gruntfile.js
# 添加hostname: '*',
root@node01:~# ln -s /root/nodejs/lib/node_modules/npm/bin/npm-cli.js /usr/bin/npm
root@node01:~/elasticsearch-head-master# npm run start
> elasticsearch-head@0.0.0 start
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
浏览器输入:http://localhost:9100
现在就可以清楚的看到各节点的信息了。
集群健康值有:
- green:表示primary和replica所有节点都健康
- yellow:至少有一个replica不可用,但是所有primary都为active,数据仍是完整的
- red:至少有一个primary不可用,数据不完整,集群不可用
索引基本使用
使用kibana来操作es,打开kibana的devTools菜单
es支持使用rest风格的api接口来操作数据。
索引的概念
es中,索引相当于是关系型数据库中表的概念。索引有自己的表结构,表中的每一行数据就是一个_doc。相当于关系型数据库中的行记录。
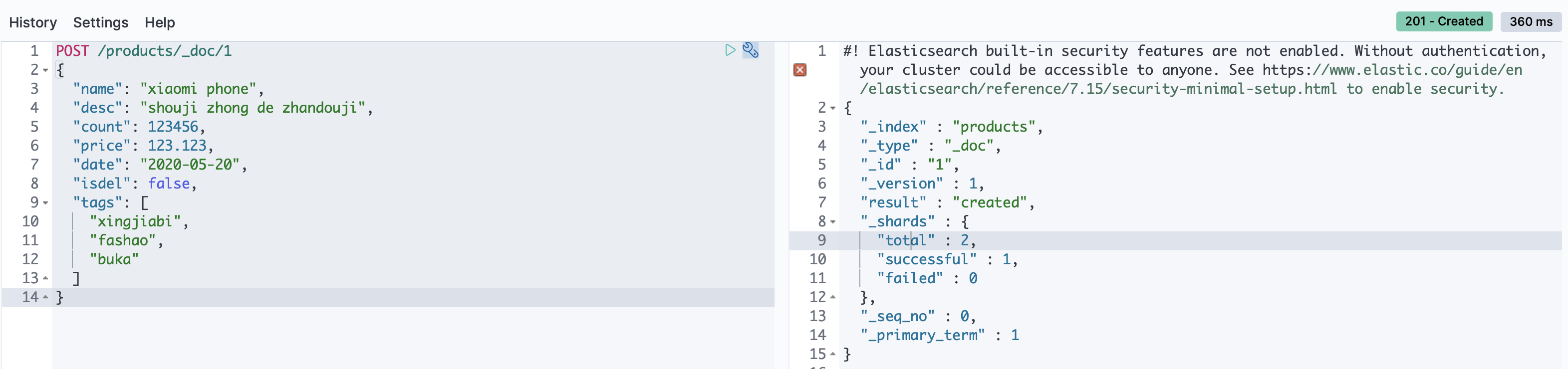
新增
POST或PUT都可以新增,
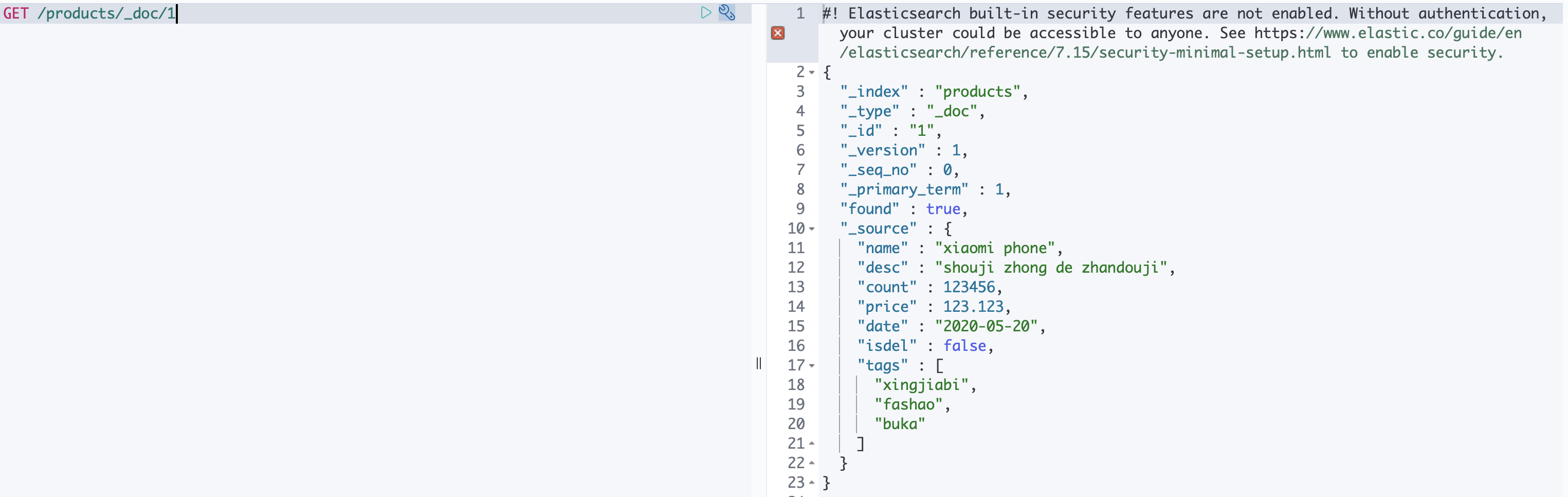
查询
修改
首先添加两条数据
修改有两种方式:
-
POST:
POST /products/_update/1 { "doc":{ "count": 12345678 } } -
PUT:

此方式会将id下的数据全部替换掉,因此如果只希望更新某一个字段,应该使用:

更新数据时,全部数据都要写上,只改需要改的数据。
-
删除

mapping
ES中的mapping有点类似与RDB中“表结构”的概念,在MySQL中,表结构里包含了字段名称,字段的类型还有索引信息等。在Mapping里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性,并且在ES中一个字段可以有对个类型。分词器、评分等概念在后面的课程讲解。
通过GET /index/_mappings可以查看索引的mapping

mapping的数据类型
es目前支持如下数据类型:
-
基本类型
-
数字类型:long、integer、short、double、float、half_float、scaled_float、unsigned_long
-
keywords:
- keyword:适用于索引结构化的字段,可以用于过滤、排序、聚合。keyword类型的字段只能通过精确值(exact value)搜索到。Id应该用keyword
- constant_keyword: 始终包含相同值的关键字字段
- wildcard:可针对类似grep的通配符查询优化日志行和类似的关键字值
关键字字段通常用于排序、汇总和Term查询。
-
时间类型:包括date和date_nanos
-
alias: 为现有字段定义别名
-
二进制:binary
-
区间类型:integer_range、float_range、long_range、double_range、date_range
-
**
text**:当一个字段是要被全文搜索的,比如Email内容、产品描述,这些字段应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。(解释一下为啥不会为text创建正排索引:大量堆空间,尤其是在加载高基数text字段时。字段数据一旦加载到堆中,就在该段的生命周期内保持在那里。同样,加载字段数据是一个昂贵的过程,可能导致用户遇到延迟问题。这就是默认情况下禁用字段数据的原因)
-
-
对象关系类型
- object:用于单个json对象
- nested:用于json对象数组
- flattened:允许将整个json对象索引为单个字段
-
结构化类型
- geo-point:纬度/经度积分
- geo-shape:用于多边形等复杂形状
- point:笛卡尔坐标点
- shape:笛卡尔任意几何图形
-
特殊类型
- IP地址
- completion:提供自动完成建议
- tocken_count: 计算字符串中令牌的数量
- Murmur3:在索引时计算值的hash并将其存储在索引中
- annotated-text:索引包含特殊标记的文本
- percolator:接收来自query-dsl的查询
- join:为同一个索引内的文档定义父/子关系
- rank_features:记录数字功能以提高查询时的点击率。
- dense_vector:记录浮点值的密集向量。
- sparse vector:记录浮点值的稀疏向量。
- search-as-you-type:针对查询优化的文本字段,以实现按需输入的完成
- histogram:histogram 用于百分位数聚合的预聚合数值。
- constant keyword:keyword当所有文档都具有相同值时的情况的 专业化。
- 数组:在Elasticsearch中,数组不需要专用的字段数据类型。默认情况下,任何字段都可以包含零个或多个值,但是,数组中的所有值都必须具有相同的数据类型。
两种映射方式
在es中mapping有两种:
-
dynamic mapping:动态映射
当使用post添加数据时,如果没有索引,那么会自动创建索引,此时索引的mapping就会按照存储的数据自动进行映射,规则如下:
-
整数:long
-
浮点数:float
-
true||flase:boolean -
日期:date
-
数组:取决于数组中第一个有效值
-
对象:object
-
字符串:如果不是数字和日期类型,那就会被映射为text和keyword两个类型。
除了上述字段类型之外,其他类型都必须显示映射,也就是必须手工指定,因为其他类型ES无法自动识别。
-
-
expllcit mapping:静态映射或手工映射或显式映射。

搜索和查询
查询上下文
使用query关键字进行数据检索,倾向于相关度搜索,故需要计算评分。搜索是elasticserch最重要的部分。
相关度评分:_score
概念:相关度评分用于对搜索结果排序,评分越高则认为其结果和搜索的预期值相关度越高,即越符合搜索预期值。在7.x之前相关度评分默认使用TF/IDF算法计算而来,7.x之后默认为BM25。
排序:相关度评分为搜索结果的排序依据,默认情况下评分越高,则结果越靠前。
元数据:_source
es在创建索引文档时,会将所有的字段json序列化,保存为_source字段。
但是es中存放的数据有些情况下数据量会非常大,而且这部分数据并没有什么用。例如:使用elk存放日志时,日志中打印了下载文件/图片的base64编码。这部分数据无意义,但是又非常占用空间。当存放在es中时,保存在_source会占用空间和浪费性能。es中有两种方式可以为索引瘦身。
-
禁用
_source:使用此方式,会导致所有的元数据都拿不到。
禁用
_source不代表不会将数据存入es了,数据仍可以查询到,并可以进行检索,只是无法直观的看到存放的数据内容了
禁用
_source优点是节省存储开销,但是会造成以下缺点:- 不支持高亮,不便于调试
- 不支持update,update_by_query等api
- 不支持reindex,更改mapping分析器和版本升级
- 通过查看索引时使用的原始文档来调试查询或聚合功能
是否禁用
_source,要取决于是什么类型的数据。如果是存日志数据,就可以禁用。如果只是为了节省空间,建议启用压缩索引而不是禁用_source -
数据源过滤器:除了禁用
_source外,还可以针对字段进行过滤保存数据源过滤器包含两个字段:
including: 指定要包含的字段excluding: 指定要排除的字段
excluding的优先级比including高

excluding和including同时有的字段,以excluding为准
支持通配符写法,但是不建议使用,因为mapping是不可变的。
常用查询语法
-
查询所有:
GET /products/_search。==select * form table_name -
带参数查询:
GET /products/_search?q=name:xiaomi==select * from table_name where name like %xiaomi%'' -
分页查询
GET /products/_search?from=0&size=2&sort=price:desc==select * from table_name limit 0, 2 order by price desc -
精准匹配
GET /products/_search?q=date:2021-06-01 -
_all搜索: 相当于在所有字段中进行搜索GET /products/_search?q=2021-06-01== select * from table_name where a = '2021-06-01' or b = '2021-06-01'...*
可以看到,搜索词为
2020-05-20,搜索命中两条,第一条date命中,第二条desc命中 -
全文检索- match
-
match:精准匹配 两个等效
两个等效 -
match_all:查询所有 两个等效
两个等效 -
multi_match:多字段匹配
-
match_phrase:短语匹配
在使用match进行匹配时,由于分词器的存在,es会将条件拆分为多个词项,然后为每个词项进行匹配并按相关度排序。例如:

使用match匹配
xiaomi nfc所有包含xiaomi或nfc的结果都会被检索出来。使用
match_phrase短语匹配,会将包含短语的结果检索出来。match_phrase的匹配有如下要求::
- match_phrase仍然会将查询短语使用分词器进行词项拆分
- 文档中必须同时包含短语拆分后的所有词项
- 所有词项在文档中的位置必须是相邻的,与匹配短语顺序一致
只有同时满足上面三个条件的短语才会被匹配上。
-
-
精准查询
-
term: 匹配和搜索词项完全相等的结果
但是如果使用
term搜索短语,想要达到match_phrase的效果:

可以看到,没有匹配到一条记录,因为term精准匹配,只能匹配单个词项,所以也就不存在term会使用分词器。
-
terms:精准匹配多个词项
这种其实相当于人工分词了,效果其实与
match是相同的 -
range: 范围查找
-
-
过滤器

es提供了两种搜索方法:
query和filter。query:query是过程导向。倾向于当前文档和查询的语句的相关度。因此会对每个结果计算相关性得分。filter:filter是结果导向,倾向于当前文档和查询的条件是不是相符。因此不会计算评分。filter能够利用缓存获取更好的性能。 -
组合查询-
bool querybool可以组合多个查询条件,bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档会合并起来计算分之值。-
must: 必须满足子句(查询)必须出现在匹配的文档中,并将有助于得分
-
filter: 过滤器不计算相关分数,cache子句必须出现在匹配的文档中。但不是像must那样,查询的分数将被忽略,Filter子句在filter上下文中进行,这意味着计分被忽略,并且子句被考虑用于缓存。
-
should: 可能满足or子句应该出现在匹配的文档中。
-
must_not: 必须不满足,不计算相关度分数。not子句不得出现在匹配的文档中。子句在过滤器上下文中执行,这意味着计分被忽略,并且子句被视为用于缓存。由于忽略计分,因此将返回所有文档的分数。
-
minimum_should_match: 参数指定should返回的文档必须匹配的子句的数量或百分比。如果bool查询包含至少一个should子句,而没有must或filter子句,则默认为1。否则默认为0。
-
分词器
分词器的主要作用是:切分词语,提高文档召回率(normalization)
normalization
normalization主要作用是:文档规范化, 提高召回率。
例如:
我们在es中存放了如下两条文档信息:
- Mr. Ma is an excellent teacher, I'm glad to meet him.
- 《Mom's friend》is an excellent film, but I haven't seen it.
我们现在搜索:Teacher ma also thinks 《mother's friends》is good。
从我们人类的思想去看,搜索的关键字分词后,Teacher与第一条中有匹配,而《mother's friends》 应该是与《Mom's friend》指的是同一个东西(搜索时可能存在记不清楚/敲错单词等),因此从人的眼光看来,这两条文档记录都应该是与搜索词相关的,应该被搜索出来。
但是计算机并不知道这些,搜索语句拆词后,进行匹配,发现并不能匹配上,因此可能会出现一条都查询不到的情况。
normalization做的事就是:
- 存储及搜索文档大小写的转换
Teacher => teacher - 词态的转换。复数变成单数
friends => friend,过去式等词态的转换him => he) - 语气助词、介词等中间词处理。

如上图: 使用english分词器对文档进行分词后,将大写变为小些,形容词变为名次,去掉了is an等语气词。
而默认的分词器是以空格为分隔符,仍会大写变小写,并不会去调语气助词及词态的转换。不同的分词器对这些有不同的实现。
分词器的构成
字符过滤器(char_filter)
主要作用:分词之前的预处理,过滤无用字符
字符过滤器有三种类型:
-
html_strip:html标签过滤器
还可以指定要保留的标签:

-
mapping:mapping字符映射
-
Pattern Replace: 正则替换
令牌过滤器(token_filter)
作用:停用词/时态转换、大小写转换、同义词转换、语气词处理等。到这里可以看出,normalization其实就是通过token_filter实现的。官网提供可用tokenFilter文档
- 同义词转换
定义近义词: 自定义近义词过滤器:
自定义近义词过滤器:
- 大小写

分词器
官方提供了15中默认的分词器:官方分词器
默认使用的英文分词器为:standard 会按照英文单词分隔符对词项进行分词。常用的分词器还有:
会按照英文单词分隔符对词项进行分词。常用的分词器还有:keyword、whitespace等。但是这些常用只是对英文来说比较常用。我们平时使用的是中文,英文分词器对于中文就不能很好的进行分词了。如果使用英文分词器对中文分词:
可以看到会对中文每一个字进行拆分,因此我们需要对中文使用中文分词器。
自定义分词器


ik分词器安装
ik分词器是中文分词器。
-
将下载后的压缩文件解压并移动到es的plugins目录下

-
重启es

可以看到使用中文分词器后,将我爱北京天安门按照中文分词习惯,拆分成了多个词项。
ik分词器的配置文件

-
IKAnalyzer.cfg.xml: 配置自定义分词配置 -
main.dic: 主词库 -
stopword.dic: 停用词 -
quantifier.dic: 特殊词库,计量单位
-
suffix.dic: 地区单位
-
surname.dic:百家姓 -
preposition.dic: 语气词
自定义词库
自定义网络词库、流行词、自造词等。这里自定义网络词的词库:

先看正常情况下,ik分词器如果对上面的词语分词:

可以看到网络词会被拆分。下面加载自定义词库:
编辑IKAnalyzer.cfg.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/custom.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
重启es服务

自定义词库热更新
在ik分词器github首页有这样写:

last-modified: 最后一次更新时间e-tag: 资源属性
-
基于远程词库
词库文件:

import cn.hutool.core.io.IoUtil; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import javax.servlet.http.HttpServletResponse; import java.io.FileInputStream; import java.io.IOException; import java.nio.charset.StandardCharsets; /** * @author shuai.zhao@going-link.com * @date 2022/1/12 */ @RestController @RequestMapping("/es-remote-dict") public class RemoteDictController { @RequestMapping("/custom-stop") public void dict(HttpServletResponse response) throws IOException { String content = IoUtil.read(new FileInputStream("/Users/zhaoshuai/stop.dic"), StandardCharsets.UTF_8); response.setContentType("text/palin;charset=utf-8"); response.setHeader("last-modified", String.valueOf(content.length())); response.setHeader("etag", String.valueOf(content.length())); response.getWriter().write(content); response.flushBuffer(); } }
启动es,看es日志:

kibana测试:

-
基于数据库
基于数据库进行热更新,需要修改ik分词器的源码,因为ik分词器本身是不支持数据库热更新的。
-
先拉取对应es版本的ik分词器源码
-
修改maven,添加mysql依赖

-
修改
Dictionary类
找到下面的初始化方法:
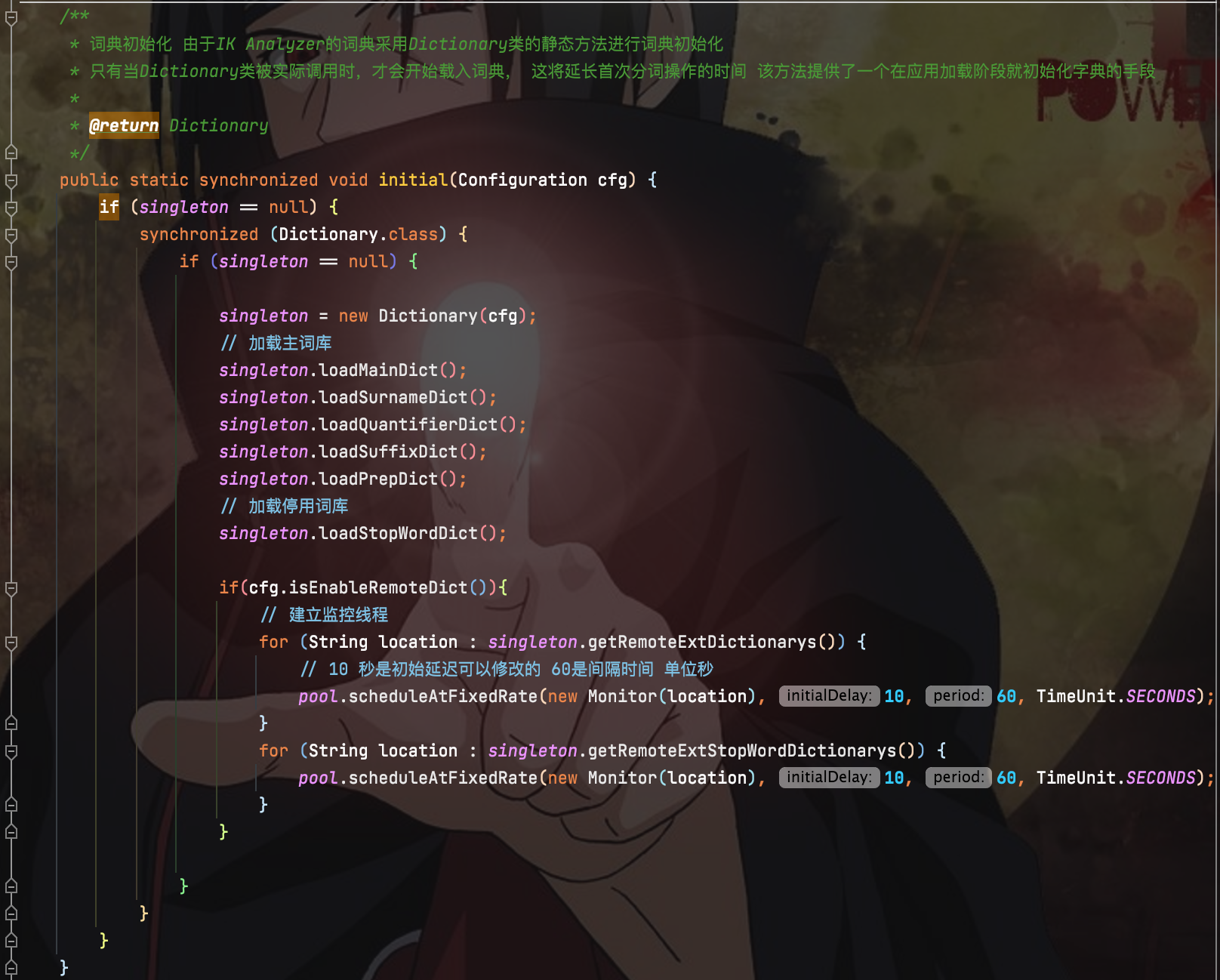
打开加载主词库的方法

可以看到有加载主词库,拓展词库,远程自定义词库。在后面添加一个我们自己定义的mysql拓展词库加载方法。

相关代码如下:
// 构造方法中加载jdbc配置信息 private Dictionary(Configuration cfg) { .... // 加载jdbc配置信息 try { Path file = PathUtils.get(getDictRoot(), JDBC_FILE_NAME); props.load(new FileInputStream(file.toFile())); } catch (Exception e) { logger.error("load jdbc properties failed", e); } } public static synchronized void initial(Configuration cfg) { if (singleton == null) { synchronized (Dictionary.class) { if (singleton == null) { singleton = new Dictionary(cfg); // 加载主词库 singleton.loadMainDict(); singleton.loadSurnameDict(); singleton.loadQuantifierDict(); singleton.loadSuffixDict(); singleton.loadPrepDict(); // 加载停用词库 singleton.loadStopWordDict(); if (cfg.isEnableRemoteDict()) { // 建立监控线程 for (String location : singleton.getRemoteExtDictionarys()) { // 10 秒是初始延迟可以修改的 60是间隔时间 单位秒 pool.scheduleAtFixedRate(new Monitor(location), 10, 60, TimeUnit.SECONDS); } for (String location : singleton.getRemoteExtStopWordDictionarys()) { pool.scheduleAtFixedRate(new Monitor(location), 10, 60, TimeUnit.SECONDS); } // 每隔一分钟,重新加载一次数据库,也可以自定义一个mysql监控器,监控最后一次修改时间 pool.scheduleAtFixedRate(singleton::loadMysqlExtDict, 10, 60, TimeUnit.SECONDS); } } } } } static { SpecialPermission.check(); AccessController.doPrivileged((PrivilegedAction<Class<?>>) () -> { try { return Class.forName("com.mysql.cj.jdbc.Driver"); } catch (ClassNotFoundException e) { logger.error("load jdbc driver error", e); } return null; }); } /** * 加载mysql拓展词库 */ private void loadMysqlExtDict() { List<String> extDictSqls = this.getMysqlExtDictionarySqls(); for (String sql : extDictSqls) { SpecialPermission.check(); List<String> words = AccessController.doPrivileged(((PrivilegedAction<List<String>>) () -> getMysqlWords(sql))); for (String word : words) { _MainDict.fillSegment(word.trim().toLowerCase().toCharArray()); } } } private List<String> getMysqlWords(String sql) { List<String> words = new ArrayList<>(); Connection conn = null; Statement stmt = null; ResultSet rs = null; try { conn = DriverManager.getConnection(props.getProperty("jdbc.url"), props.getProperty("jdbc.user"), props.getProperty("jdbc.password")); stmt = conn.createStatement(); rs = stmt.executeQuery(sql); while (rs.next()) { String theWord = rs.getString("word"); logger.info("hot word: " + theWord); words.add(theWord.trim()); } } catch (Exception e) { logger.error("erorr", e); } finally { if (rs != null) { try { rs.close(); } catch (SQLException e) { logger.error("error", e); } } if (stmt != null) { try { stmt.close(); } catch (SQLException e) { logger.error("error", e); } } if (conn != null) { try { conn.close(); } catch (SQLException e) { logger.error("error", e); } } } return words; } private List<String> getMysqlExtDictionarySqls() { return Optional.ofNullable(getProperty(MYSQL_EXT_DICT_SQL)) .map(names -> names.split(";")) .map(Arrays::asList) .orElse(Collections.emptyList()); }数据库执行sql:
CREATE SCHEMA es_dict; USE es_dict; CREATE TABLE ext_dict ( id BIGINT PRIMARY KEY auto_increment, word VARCHAR ( 60 ) NOT NULL ); CREATE TABLE ext_stop_word ( id BIGINT PRIMARY KEY auto_increment, word VARCHAR ( 60 ) NOT NULL );打包后替换掉原来的ik分词器包,将mysql驱动包放入ik文件夹下,添加mysql拓展查询sql配置:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> <!-- mysql拓展--> <!--用户可以在这里配置mysql拓展字典--> <entry key="mysql_ext_dict_sql">select word from ext_dict</entry> <!--用户可以在这里配置mysql拓展停用词字典--> <entry key="mysql_ext_stopwords_sql"></entry> </properties>启动es:
// 报错,发现插件没有jdk的访问权限,查询后修改权限 Caused by: java.security.AccessControlException: access denied ("java.lang.RuntimePermission" "setContextClassLoader") at java.security.AccessControlContext.checkPermission(AccessControlContext.java:472) at java.security.AccessController.checkPermission(AccessController.java:886)修改权限:
vi ik/plugin-security.plugin grant { // needed because of the hot reload functionality permission java.net.SocketPermission "*", "connect,resolve"; permission java.lang.RuntimePermission "createClassLoader"; permission java.lang.RuntimePermission "getClassLoader"; permission java.lang.RuntimePermission "setContextClassLoader"; permission java.lang.RuntimePermission "accessClassInPackage.sun.misc"; permission java.lang.RuntimePermission "accessClassInPackage.sun.nio.ch"; permission java.lang.RuntimePermission "accessDeclaredMembers"; permission java.lang.RuntimePermission "loadLibrary.jaas_unix"; };重启服务:

在数据库添加字典:



数据库添加热词:


上面只是简易实现,没有实现监控数据变化的,还可以自定义一个监控器,数据库添加最后一次更新时间字段,监控最后一次变更时间变化就更新数据。
-
聚合查询
聚合(agregations)不同于普通查询,是目前学到的第二种大的查询分类,第一种即query,因此在代码中的第一层嵌套由query变为了aggs。用于进行聚合的字段必须是exact value,分词字段不可进行聚合。对于text字段如果需要使用聚合,需要开启fielddata,但是通常不建议,因为fielddata是将聚合使用的数据结构由磁盘(doc_values)变为了堆内存(field_data),大数据的聚合操作很容易导致OOM。
语法
GET product/_search
{
"aggs": {
"<aggs_name>": {
"<agg_type>": {
"field": "<field_name>"
}
}
}
}
aggs_name:聚合函数的名称agg_type:聚合种类,比如是桶聚合或者是指标聚合field_name:字段名
分类
es中准备如下数据:
PUT product
{
"mappings" : {
"properties" : {
"createtime" : {
"type" : "date"
},
"date" : {
"type" : "date"
},
"desc" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"analyzer":"ik_max_word"
},
"lv" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"analyzer":"ik_max_word",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"price" : {
"type" : "long"
},
"tags" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"type" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
PUT /product/_doc/1
{
"name" : "小米手机",
"desc" : "手机中的战斗机",
"price" : 3999,
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-10-01T08:00:00Z",
"tags": [ "性价比", "发烧", "不卡顿" ]
}
PUT /product/_doc/2
{
"name" : "小米NFC手机",
"desc" : "支持全功能NFC,手机中的滑翔机",
"price" : 4999,
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-05-21T08:00:00Z",
"tags": [ "性价比", "发烧", "公交卡" ]
}
PUT /product/_doc/3
{
"name" : "NFC手机",
"desc" : "手机中的轰炸机",
"price" : 2999,
"lv":"高端机",
"type":"手机",
"createtime":"2020-06-20",
"tags": [ "性价比", "快充", "门禁卡" ]
}
PUT /product/_doc/4
{
"name" : "小米耳机",
"desc" : "耳机中的黄焖鸡",
"price" : 999,
"lv":"百元机",
"type":"耳机",
"createtime":"2020-06-23",
"tags": [ "降噪", "防水", "蓝牙" ]
}
PUT /product/_doc/5
{
"name" : "红米耳机",
"desc" : "耳机中的肯德基",
"price" : 399,
"type":"耳机",
"lv":"百元机",
"createtime":"2020-07-20",
"tags": [ "防火", "低音炮", "听声辨位" ]
}
PUT /product/_doc/6
{
"name" : "小米手机10",
"desc" : "充电贼快掉电更快,超级无敌望远镜,高刷电竞屏",
"price" : "",
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-07-27",
"tags": [ "120HZ刷新率", "120W快充", "120倍变焦" ]
}
PUT /product/_doc/7
{
"name" : "挨炮 SE2",
"desc" : "除了CPU,一无是处",
"price" : "3299",
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-07-21",
"tags": [ "割韭菜", "割韭菜", "割新韭菜" ]
}
PUT /product/_doc/8
{
"name" : "XS Max",
"desc" : "听说要出新款12手机了,终于可以换掉手中的4S了",
"price" : 4399,
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-08-19",
"tags": [ "5V1A", "4G全网通", "大" ]
}
PUT /product/_doc/9
{
"name" : "小米电视",
"desc" : "70寸性价比只选,不要一万八,要不要八千八,只要两千九百九十八",
"price" : 2998,
"lv":"高端机",
"type":"耳机",
"createtime":"2020-08-16",
"tags": [ "巨馍", "家庭影院", "游戏" ]
}
PUT /product/_doc/10
{
"name" : "红米电视",
"desc" : "我比上边那个更划算,我也2998,我也70寸,但是我更好看",
"price" : 2999,
"type":"电视",
"lv":"高端机",
"createtime":"2020-08-28",
"tags": [ "大片", "蓝光8K", "超薄" ]
}
PUT /product/_doc/11
{
"name": "红米电视",
"desc": "我比上边那个更划算,我也2998,我也70寸,但是我更好看",
"price": 2998,
"type": "电视",
"lv": "高端机",
"createtime": "2020-08-28",
"tags": [
"大片",
"蓝光8K",
"超薄"
]
}
桶聚合
类比SQL中的group by的作用,主要用于统计不同类型数据的数量
- 场景:用于统计不同种类的文档的数量,可进行嵌套统计。
- 函数:
terms - 聚合字段必须是exact value,如keyword

指标聚合
- 场景:用于统计某个指标,如最大值、最小值、平均值,可以结合桶聚合一起使用,如按照商品类型分桶,统计每个桶的平均价格。
- 函数:
avg,max,min,sum,count,state


嵌套聚合

管道聚合
-
场景:用于对聚合查询的二次聚合,如统计平均价格最低的商品分类,即先按照商品分类进行桶聚合,并计算其平均价格,然后对其平均价格计算最小值聚合
-
函数:
min_bucket、max_bucket、avg_bucket、sum_bucket、state_bucket -
注意:buckets_path为管道聚合的关键字,其值从当前聚合统计的聚合函数开始计算为第一级。比如下面例子中,my_aggs和my_min_bucket同级,my_aggs就是buckets_path值的起始值。

聚合和查询的关系
-
基于query和filter的聚合
GET product/_search { "query": {...}, "aggs": {...} }注意:执行顺序为先query后aggs,顺序和谁在上谁在下没有关系。query中可以是查询、也可以是filter、或者bool query
-
基于聚合结果的查询
GET product/_search { "aggs": {...}, "post_filter": {...} }注意:以上语法,执行顺序为先aggs后post_filter,顺序和谁在上谁在下没有关系。
聚合排序
排序语法:
GET product/_search
{
"aggs": {
"type_agg": {
"terms": {
"field": "tags",
"order": {
"<order_type>": "desc"
},
"size": 10
}
}
}
}
-
排序规则
order_type:_count: 按照数量排序_key:按照聚合结果key排序_term:已废弃,但是仍然可用,使用key代替
-
多级排序:排序的优先级,按照外层优先的顺序
-
多层排序:按照多层聚合中最里层的结果进行排序
常用查询函数
-
histogram:直方图或柱状图统计
用途:用于区间统计,如不同价格商品区间的销售情况
语法:
GET product/_search?size=0 { "aggs": { "<histogram_name>": { "histogram": { "field": "price", #字段名称 "interval": 1000, #区间间隔 "keyed": true, #返回数据的结构化类型 "min_doc_count": <num>, #返回桶的最小文档数阈值,即文档数小于num的桶不会被输出 "missing": 1999 #空值的替换值,即如果文档对应字段的值为空,则默认输出1999(参数值) } } } } -
date-histogram:基于日期的直方图,比如统计一年每个月的销售额
语法:
GET product/_search?size=0 { "aggs": { "my_date_histogram": { "date_histogram": { "field": "createtime", #字段需为date类型 "<interval_type>": "month", #时间间隔的参数可选项 "format": "yyyy-MM", #日期的格式化输出 "extended_bounds": { #输出空桶 "min": "2020-01", "max": "2020-12" } } } } }interval_type:时间间隔的参数可选项
- fixed_interval:ms(毫秒)、s(秒)、 m(分钟)、h(小时)、d(天),注意单位需要带上具体的数值,如2d为两天。需要当心当单位过小,会导致输出桶过多而导致服务崩溃。
- calendar_interval:month、year
- interval:(废弃,但是仍然可用)
-
percentile 百分位统计 或者 饼状图
-
percentiles:用于评估当前数值分布情况,比如99 percentile 是 1000 , 是指 99%的数值都在1000以内。常见的一个场景就是我们制定 SLA 的时候常说 99% 的请求延迟都在100ms 以内,这个时候你就可以用 99 percentile 来查一下,看一下 99 percenttile 的值如果在 100ms 以内,就代表SLA达标了。
语法:
GET product/_search?size=0 { "aggs": { "<percentiles_name>": { "percentiles": { "field": "price", "percents": [ percent1, #区间的数值,如5、10、30、50、99 即代表5%、10%、30%、50%、99%的数值分布 percent2, ... ] } } } } -
percentile_ranks: percentile rank 其实就是percentiles的反向查询,比如我想看一下 1000、3000 在当前数值中处于哪一个范围内,你查一下它的 rank,发现是95,99,那么说明有95%的数值都在1000以内,99%的数值都在3000以内。
GET product/_search?size=0 { "aggs": { "<percentiles_name>": { "percentile_ranks": { "field": "<field_value>", "values": [ rank1, rank2, ... ] } } } }
-
脚本查询
Scripting是Elasticsearch支持的一种专门用于复杂场景下支持自定义编程的强大的脚本功能,ES支持多种脚本语言,如painless,其语法类似于Java,也有注释、关键字、类型、变量、函数等,其就要相对于其他脚本高出几倍的性能,并且安全可靠,可以用于内联和存储脚本。
支持的语言
-
groovy:ES 1.4.x-5.0的默认脚本语言
-
painless:JavaEE使用java语言开发,.Net使用C#/F#语言开发,Flutter使用Dart语言开发,同样,ES 5.0+版本后的Scripting使用的语言默认就是painless,painless是一种专门用于Elasticsearch的简单,用于内联和存储脚本,是ES 5.0+的默认脚本语言,类似于Java,也有注释、关键字、类型、变量、函数等,是一种安全的脚本语言。并且是Elasticsearch的默认脚本语言。
-
其他:
expression:每个文档的开销较低:表达式的作用更多,可以非常快速地执行,甚至比编写native脚本还要快,支持javascript语法的子集:单个表达式。缺点:只能访问数字,布尔值,日期和geo_point字段,存储的字段不可用
mustache:提供模板参数化查询
用法
语法:ctx._source.<field_name>
POST product/_update/2
{
"script": {
"lang": "<script_language>",
"source": "script_content"
}
}


特点
- 语法简单,学习成本低
- 灵活度高,可编程能力强
- 性能相较于其他脚本语言很高
- 安全性好
- 独立语言,虽然易学但仍需单独学习
- 相较于DSL性能低
- 不适用于复杂的业务场景
正则
早先某些版本正则表达式默认情况下处于禁用模式,因为它绕过了painless的针对长时间运行和占用内存脚本的保护机制。而且有深度对战行为。如果需要开启正则,需要配置:script.painless.regex.enabled: true
注意:通常正则的使用范围比较小,应用范围基本限制在数据量比较小和并发量比较小的应用场景下。

索引的批量操作
批量查询和批量增删改
-
批量查询
GET /_mget -
批量写入:
POST /_bulk POST /<index>/_bulk {"<option>": {"metadata"}} {"data"}
注意:
bulk api对json的语法有严格的要求,除了delete外,每一个操作都要两个json串(metadata和business data),且每个json串内不能换行,非同一个json串必须换行,否则会报错;
bulk操作中,任意一个操作失败,是不会影响其他的操作的,但是在返回结果里,会告诉你异常日志
索引的操作类型
批量写入时,option有如下取值:
- create:如果在PUT数据的时候当前数据已经存在,则数据会被覆盖,如果在PUT的时候加上操作类型create,此时如果数据已存在则会返回失败,因为已经强制指定了操作类型为create,ES就不会再去执行update操作。比如:PUT /pruduct/_create/1/ ( 老版本的语法为 PUT /pruduct/_doc/1/_create )指的就是在索引product中强制创建id为1的数据,如果id为1的数据已存在,则返回失败。
- delete:删除文档,ES对文档的删除是懒删除机制,即标记删除。(lazy delete原理)
- index:在ES中,写入操作被称为Index,这里Index为动词,即索引数据为将数据创建在ES中的索引,写入数据亦可称之为“索引数据”。可以是创建,也可以是全量替换
- update:执行partial update(全量替换,部分替换)
以上四种操作类型均为写操作。ES中的数据写入均发生在Primary Shard,当数据在Primary写入完成之后会同步到相应的Replica Shard。ES的数据写入有两种方式:单个数据写入和批量写入,ES为批量写入数据提供了特有的API:_bulk。
-
优缺点
- 优点:相较于普通的Json格式的数据操作,不会产生额外的内存消耗,性能更好,常用于大数据量的批量写入
- 缺点:可读性差,可能会没有智能提示。
-
使用场景
大数据量的批量操作,比如数据从MySQL中一次性写入ES,批量写入减少了对es的请求次数,降低了内存开销以及对线程的占用。



模糊查询
前缀搜索prefix
通过某一前缀匹配,不计算相关度评分。
注意:
- 前缀搜索匹配的是term,而不是field。
- 前缀搜索的性能很差
- 前缀搜索没有缓存
- 前缀搜索尽可能把前缀长度设置的更长
语法:
GET <index>/_search
{
"query": {
"prefix": {
"<field>": {
"value": "<word_prefix>"
}
}
}
}

通配符wildcard
通配符运算符是匹配一个或多个字符的占位符。例如,*通配符运算符匹配零个或多个字符。您可以将通配符运算符与其他字符结合使用以创建通配符模式。
注意:
- 通配符匹配的也是term,而不是field
语法:
GET <index>/_search
{
"query": {
"wildcard": {
"<field>": {
"value": "<word_with_wildcard>"
}
}
}
}

正则regex
regex查询的性能可以根据提供的正则表达式而有所不同。为了提高性能,应避免使用通配符模式,如.或 .?+未经前缀或后缀
语法:
GET <index>/_search
{
"query": {
"regexp": {
"<field>": {
"value": "<regex>",
"flags": "ALL",
}
}
}
}
flags取值如下:
-
ALL:启用所有可选操作符。 -
COMPLEMENT:启用操作符。可以使用对下面最短的模式进行否定。例如a~bc # matches 'adc' and 'aec' but not 'abc' -
INTERVAL:启用<>操作符。可以使用<>匹配数值范围。例如foo<1-100> # matches 'foo1', 'foo2' ... 'foo99', 'foo100'
foo<01-100> # matches 'foo01', 'foo02' ... 'foo99', 'foo100'
-
INTERSECTION:启用&操作符,它充当AND操作符。如果左边和右边的模式都匹配,则匹配成功。例如:aaa.+&.+bbb # matches 'aaabbb'
-
ANYSTRING:启用@操作符。您可以使用@来匹配任何整个字符串。
您可以将@操作符与&和~操作符组合起来,创建一个“everything except”逻辑。例如:@&~(abc.+) # matches everything except terms beginning with 'abc'

模糊查询fuzzy
模糊查询主要用来处理:混淆字符、缺少/多出字符、字符顺序颠倒等情况
语法:
GET <index>/_search
{
"query": {
"fuzzy": {
"<field>": {
"value": "<keyword>"
}
}
}
}
可配置项:
-
value: 必输项 -
fuzziness:编辑距离,(0,1,2)并非越大越好,召回率高但结果不准确
-
两段文本之间的Damerau-Levenshtein距离是使一个字符串与另一个字符串匹配所需的插入、删除、替换和调换的数量
-
距离公式:Levenshtein是lucene的,es改进版:Damerau-Levenshtein,
axe=>aex Levenshtein=2 Damerau-Levenshtein=1
-
-
transpositions:(可选,布尔值)指示编辑是否包括两个相邻字符的变位(ab→ba)。默认为true。

短语前缀match_phrase_prefix
match_phrase:
- match_phrase会分词
- 被检索字段必须包含match_phrase中的所有词项并且顺序必须是相同的
- 被检索字段包含的match_phrase中的词项之间不能有其他词项
match_phrase_prefix与match_phrase相同,但是它多了一个特性,就是它允许在文本的最后一个词项(term)上的前缀匹配,如果 是一个单词,比如a,它会匹配文档字段所有以a开头的文档,如果是一个短语,比如 "this is ma" ,他会先在倒排索引中做以ma做前缀搜索,然后在匹配到的doc中做match_phrase查询,(网上有的说是先match_phrase,然后再进行前缀搜索, 是不对的)
语法:
GET product_en/_search
{
"query": {
"match_phrase_prefix": {
"<field>": {
"query": "zhong hongzhaji",
"max_expansions": 50,
"slop": 3
}
}
}
}
参数
- analyzer 指定何种分析器来对该短语进行分词处理
- max_expansions 限制匹配的最大词项
- boost 用于设置该查询的权重
- slop 允许短语间的词项(term)间隔:slop 参数告诉 match_phrase 查询词条相隔多远时仍然能将文档视为匹配 什么是相隔多远? 意思是说为了让查询和文档匹配你需要移动词条多少次?

搜索推荐
搜索一般都会要求具有“搜索推荐”或者叫“搜索补全”的功能,即在用户输入搜索的过程中,进行自动补全或者纠错。以此来提高搜索文档的匹配精准度,进而提升用户的搜索体验,这就是搜索推荐(Suggest)。
term suggester
term suggester正如其名,只基于tokenizer之后的单个term去匹配建议词,并不会考虑多个term之间的关系
POST <index>/_search
{
"suggest": {
"<suggest_name>": {
"text": "<search_content>",
"term": {
"suggest_mode": "<suggest_mode>",
"field": "<field_name>"
}
}
}
}
Options:
- text:用户搜索的文本
- field:要从哪个字段选取推荐数据
- analyzer:使用哪种分词器
- size:每个建议返回的最大结果数
- sort:如何按照提示词项排序,参数值只可以是以下两个枚举:
- score:分数>词频>词项本身
- frequency:词频>分数>词项本身
- suggest_mode:搜索推荐的推荐模式,参数值亦是枚举:
- missing:默认值,仅为不在索引中的词项生成建议词
- popular:仅返回与搜索词文档词频或文档词频更高的建议词
- always:根据 建议文本中的词项 推荐 任何匹配的建议词
- max_edits:可以具有最大偏移距离候选建议以便被认为是建议。只能是1到2之间的值。任何其他值都将导致引发错误的请求错误。默认为2
- prefix_length:前缀匹配的时候,必须满足的最少字符
- min_word_length:最少包含的单词数量
- min_doc_freq:最少的文档频率
- max_term_freq:最大的词频
phrase suggester
phrase suggester和term suggester相比,对建议的文本会参考上下文,也就是一个句子的其他token,不只是单纯的token距离匹配,它可以基于共生和频率选出更好的建议。
Options:
- real_word_error_likelihood: 此选项的默认值为 0.95。此选项告诉 Elasticsearch 索引中 5% 的术语拼写错误。这意味着随着这个参数的值越来越低,Elasticsearch 会将越来越多存在于索引中的术语视为拼写错误,即使它们是正确的
- max_errors:为了形成更正,最多被认为是拼写错误的术语的最大百分比。默认值为 1
- confidence:默认值为 1.0,最大值也是。该值充当与建议分数相关的阈值。只有得分超过此值的建议才会显示。例如,置信度为 1.0 只会返回得分高于输入短语的建议
- collate:告诉 Elasticsearch 根据指定的查询检查每个建议,以修剪索引中不存在匹配文档的建议。在这种情况下,它是一个匹配查询。由于此查询是模板查询,因此搜索查询是当前建议,位于查询中的参数下。可以在查询下的“params”对象中添加更多字段。同样,当参数“prune”设置为true时,我们将在响应中增加一个字段“collate_match”,指示建议结果中是否存在所有更正关键字的匹配
- direct_generator:phrase suggester使用候选生成器生成给定文本中每个项可能的项的列表。单个候选生成器类似于为文本中的每个单独的调用term suggester。生成器的输出随后与建议候选项中的候选项结合打分。目前只支持一种候选生成器,即direct_generator。建议API接受密钥直接生成器下的生成器列表;列表中的每个生成器都按原始文本中的每个项调用。
completion suggester
自动补全,自动完成,支持三种查询【前缀查询(prefix)模糊查询(fuzzy)正则表达式查询(regex)】 ,主要针对的应用场景就是"Auto Completion"。 此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响应速度要求比较苛刻。因此实现上它和前面两个Suggester采用了不同的数据结构,索引并非通过倒排来完成,而是将analyze过的数据编码成FST和索引一起存放。对于一个open状态的索引,FST会被ES整个装载到内存里的,进行前缀查找速度极快。但是FST只能用于前缀查找,这也是Completion Suggester的局限所在。
- completion:es的一种特有类型,专门为suggest提供,基于内存,性能很高。
- prefix query:基于前缀查询的搜索提示,是最常用的一种搜索推荐查询。
- prefix:客户端搜索词
- field:建议词字段
- size:需要返回的建议词数量(默认5)
- skip_duplicates:是否过滤掉重复建议,默认false
- fuzzy query
- fuzziness:允许的偏移量,默认auto
- transpositions:如果设置为true,则换位计为一次更改而不是两次更改,默认为true。
- min_length:返回模糊建议之前的最小输入长度,默认 3
- prefix_length:输入的最小长度(不检查模糊替代项)默认为 1
- unicode_aware:如果为true,则所有度量(如模糊编辑距离,换位和长度)均以Unicode代码点而不是以字节为单位。这比原始字节略慢,因此默认情况下将其设置为false。
- regex query:可以用正则表示前缀,不建议使用
context suggester
完成建议者会考虑索引中的所有文档,但是通常来说,我们在进行智能推荐的时候最好通过某些条件过滤,并且有可能会针对某些特性提升权重。
- contexts:上下文对象,可以定义多个
- name:
context的名字,用于区分同一个索引中不同的context对象。需要在查询的时候指定当前name - type:
context对象的类型,目前支持两种:category和geo,分别用于对suggest item分类和指定地理位置。 - boost:权重值,用于提升排名
- name:
- path:如果没有path,相当于在PUT数据的时候需要指定context.name字段,如果在Mapping中指定了path,在PUT数据的时候就不需要了,因为 Mapping是一次性的,而PUT数据是频繁操作,这样就简化了代码。
es客户端
es客户端为java语言提供的客户端有两种:
TransportClientRestClient
TransportClient
Java API使用的客户端名称叫TransportClient,从7.0.0开始,官方已经不建议使用TransportClient作为ES的Java客户端了,并且从8.0会被彻底删除。
注意事项
TransportClient使用transport模块(9300端口)远程连接到 Elasticsearch 集群,客户端并不加入集群,而是通过获取单个或者多个transport地址来以轮询的方式与他们通信。TransportClient使用transport协议与Elasticsearch节点通信,如果客户端的版本和与其通信的ES实例的版本不同,就会出现兼容性问题。而low-level REST使用的是HTTP协议,可以与任意版本ES集群通信。high-level REST是基于low-level REST的。
Maven依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>7.12.1</version>
</dependency>
使用
// 创建客户端连接
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName("host1"), 9300))
.addTransportAddress(new TransportAddress(InetAddress.getByName("host2"), 9300));
// 关闭客户端
client.close();
嗅探器
Settings settings = Settings.builder()
.put("client.transport.sniff", true).build();
TransportClient client = new PreBuiltTransportClient(settings);
RestClient
RestClient 是线程安全的,RestClient使用 Elasticsearch 的 HTTP 服务,默认为9200端口,这一点和transport client不同。
es提供了两个不同版本的java rest client 客户端:
- Java Low Level REST Client: 低级别的REST客户端,通过http与集群交互,用户需自己编组请求JSON串,及解析响应JSON串。兼容所有ES版本。
- Java High Level REST Client: 高级别的REST客户端,基于低级别的REST客户端,增加了编组请求JSON串、解析响应JSON串等相关api。使用的版本需要保持和ES服务端的版本一致,否则会有版本问题。
Java Low Level REST Client
maven依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.15.2</version>
</dependency>
使用
RestClient restClient = RestClient.builder(
new HttpHost("192.168.64.4", 9200, "http"),
new HttpHost("192.168.64.1", 9200, "http")).build();
Request request = new Request("GET", "/product/_search");
request.setJsonEntity("{\n" +
" \"query\": {\n" +
" \"match\": {\n" +
" \"name\": \"小米\"\n" +
" }\n" +
" }\n" +
"}");
Response response = restClient.performRequest(request);
System.out.println("response = " + IoUtil.read(response.getEntity().getContent(), StandardCharsets.UTF_8));
restClient.close();

可以看到low level rest查询时需要手动封装查询的json串,并且响应结果会将es响应原始数据全部返回,但是一般在java中使用时,只关心_hits中的数据部分,此时需要手动解数据。
嗅探器
允许从正在运行的 Elasticsearch 集群中自动发现节点并将它们设置为现有 RestClient 实例的最小库
maven依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client-sniffer</artifactId>
<version>7.15.2</version>
</dependency>
使用
// 默认每五分钟发现一次
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200, "http"))
.build();
Sniffer sniffer = Sniffer.builder(restClient).build();
//设置嗅探间隔为60000毫秒
//Sniffer sniffer = Sniffer.builder(restClient).setSniffIntervalMillis(60000).build();
//Sniffer 对象应该与RestClient 具有相同的生命周期,并在客户端之前关闭。
sniffer.close();
restClient.close();
失败时重启嗅探
启用失败时嗅探,也就是在每次失败后,节点列表会立即更新,而不是在接下来的普通嗅探轮中更新。在这种情况下,首先需要创建一个 SniffOnFailureListener 并在 RestClient 创建时提供。此外,一旦稍后创建嗅探器,它需要与同一个 SniffOnFailureListener 实例相关联,它将在每次失败时收到通知,并使用嗅探器执行额外的嗅探轮
SniffOnFailureListener sniffOnFailureListener =
new SniffOnFailureListener();
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200))
.setFailureListener(sniffOnFailureListener) //将失败侦听器设置为 RestClient 实例
.build();
Sniffer sniffer = Sniffer.builder(restClient)
.setSniffAfterFailureDelayMillis(30000) //在嗅探失败时,不仅节点在每次失败后都会更新,而且还会比平常更早安排额外的嗅探轮次,默认情况下是在失败后一分钟,假设事情会恢复正常并且我们想要检测尽快地。可以在 Sniffer 创建时通过 setSniffAfterFailureDelayMillis 方法自定义所述间隔。请注意,如果如上所述未启用故障嗅探,则最后一个配置参数无效。
.build();
sniffOnFailureListener.setSniffer(sniffer); //将 Sniffer 实例设置为失败侦听器
Java High Level REST Client
maven依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.15.2</version>
</dependency>
使用
// 创建时使用RestHighLevelClient类
SniffOnFailureListener sniffOnFailureListener = new SniffOnFailureListener();
RestHighLevelClient restClient = new RestHighLevelClient(RestClient.builder(
new HttpHost("192.168.64.4", 9200, "http"),
new HttpHost("192.168.64.1", 9200, "http")
)
.setFailureListener(sniffOnFailureListener));
SearchSourceBuilder sourceBuilder = SearchSourceBuilder.searchSource()
.query(new MatchQueryBuilder("name", "小米").analyzer("ik_max_word"));
SearchRequest request = new SearchRequest("product");
request.source(sourceBuilder);
SearchResponse response = restClient.search(request, RequestOptions.DEFAULT);
List<String> list = Arrays.stream(response.getHits().getHits()).map(SearchHit::getSourceAsString).collect(Collectors.toList());
System.out.println("response = " + list);
restClient.close();

可以看到上面查询条件部分使用建造者模式进行了封装,可以很方便的组装请求参数,并且响应报文也进行了封装,可以方便的拿到想要的数据,忽略其他的数据。使用上更加方便了。
