



网络负载均衡LVS
集群负载均衡
随着现在互联网的发展,上网的人越来越多,而中国是一个人口大国,也因此中国的互联网是使用的最多的。随着现在网上购物的崛起,一个网站的访问量就会非常的大。那么我们如何保证一个网站可以支撑起高并发的网络请求?例如淘宝双十一时每秒几千万的并发,如何使服务器支撑起这么大的并发保证服务的可用性?
网络高并发的解决方案就是做集群负载均衡。
因为本文并非一次性写完,所以下文中可能会出现上下文ip地址发生变化,属正常现象,请忽略此问题,不影响整体阅读理解
一、网络协议原理
想要了解网络高并发,首先要搞清楚网络具体是怎么通信的。
1.1 七层模型
在软件工程学中,为了解藕,通常会将应用分为多层。而七层模型OSI就是一个标准化的体系。
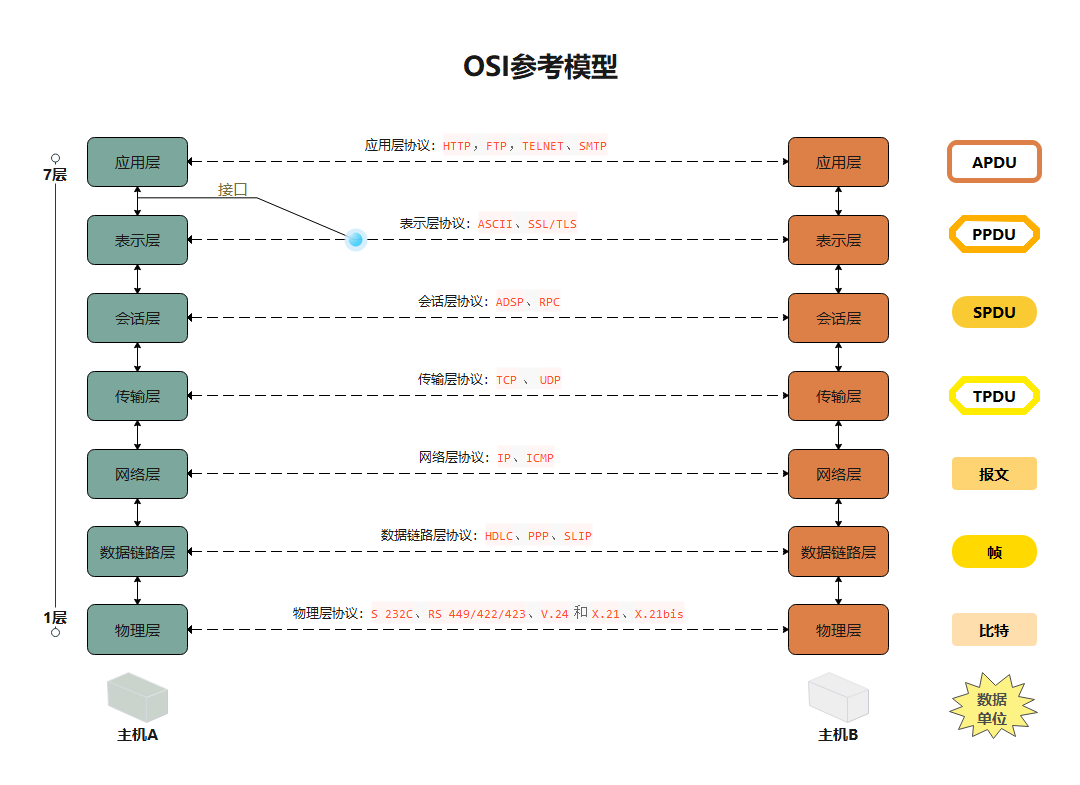
上图为软件七层模型,这七层的每层的作用如下:
- 应用层:是计算机用户以及各种应用程序和网络间的接口,其功能是直接向用户提供服务,完成用户希望在网络上完成的各种工作。
- 表示层:负责数据格式的转换,将应用处理的信息转换为适合网络传输的格式,或者将来自下层的数据转换为上层能够处理的格式。
- 会话层:建立和管理应用程序之间的通信
- 传输控制层:主要解决数据传输的问题。
- 网络层:将网络地址翻译成物理地址,决定如何将数据从起始地发送到目的地。选择最短路径
- 数据链路层:点与点间通信,定义应该使用什么样的协议来发送数据。
- 物理层:解决两个硬件之间怎么通信的问题,常见的物理媒介有光纤、电缆、中继器等。它主要定义物理设备标准,如网线的接口类型、光纤的接口类型、各种传输介质的传输速率等。
通过上面的分层之后,每一层之间都互相解藕,只要每一层对外提供的接口不变,那么每一层都可以定制实现。
在上面的图中还可以看出,每一层都有适合此层的协议,如http协议等。
什么是协议
协议就是双方的一个约定。只要通信双方都按照约定的格式处理数据,那么双方就可以接受并处理对方的数据。
例如我们在浏览器上输入:www.baidu.com,打开控制台就可以看到如下的内容:
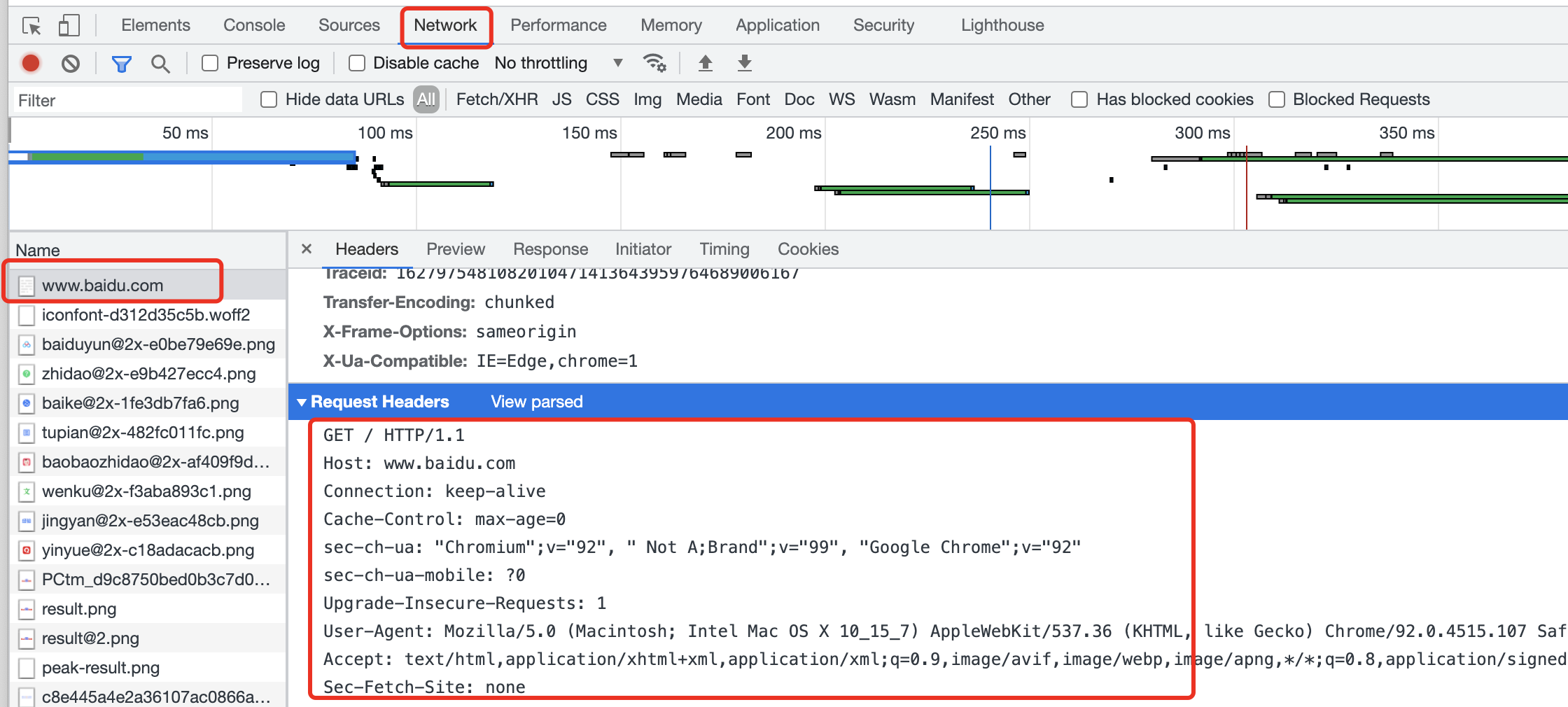
虽然我们只在浏览器中输入了一个域名,但是浏览器会自动帮我们将数据包装成http协议约定的数据格式并发送出去,服务端也会将响应数据按照协议约定的类型包装返回。如下图:
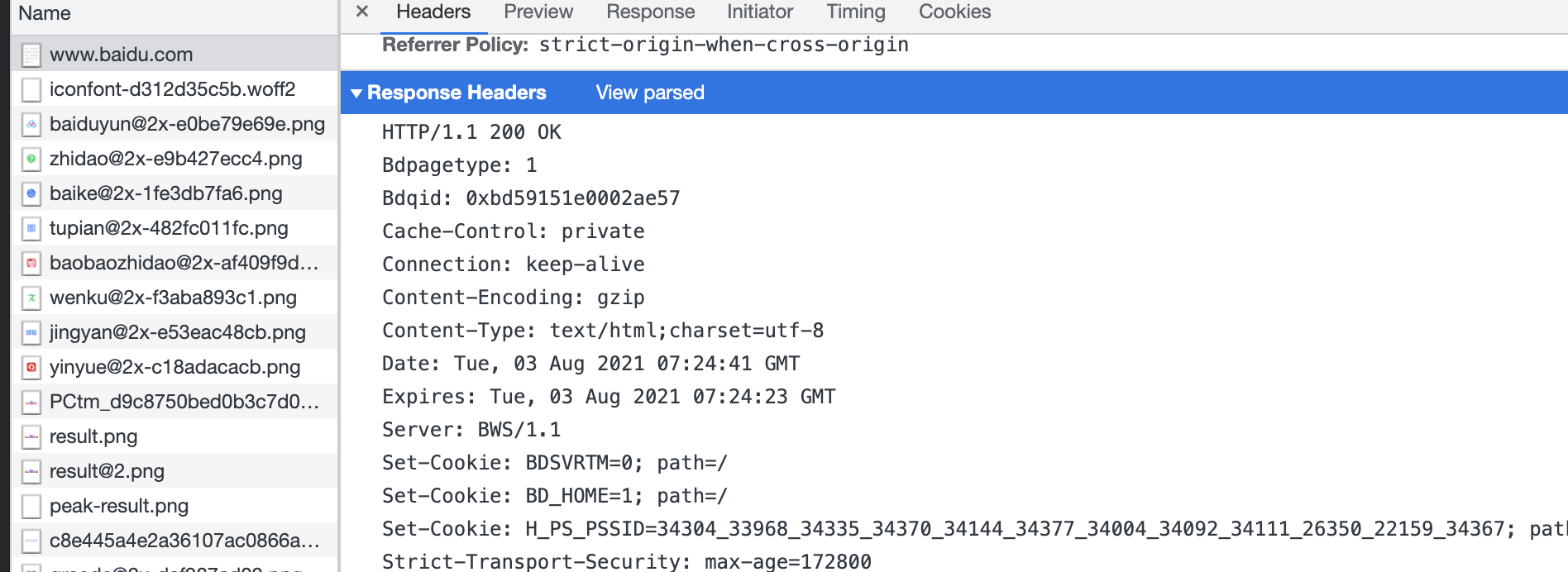
可以看到请求和响应使用的都是HTTP/1.1协议。为了更好的理解协议,我们可以不使用浏览器,自己按照http协议去包装数据发送请求。即原来浏览器的工作,我们自己来。
- 在linux终端中,不使用浏览器以及wget等命令,请求获取百度页面
xz:~ 乄 cd /proc/$$/fd
xz:fd 乄 ll
total 0
lrwx------ 1 xz xz 64 Aug 3 15:32 0 -> /dev/pts/0
lrwx------ 1 xz xz 64 Aug 3 15:32 1 -> /dev/pts/0
lrwx------ 1 xz xz 64 Aug 3 15:32 2 -> /dev/pts/0
lrwx------ 1 xz xz 64 Aug 3 15:33 255 -> /dev/pts/0
xz:fd 乄 exec 8<> /dev/tcp/www.baidu.com/80
xz:fd 乄 echo -e 'GET / HTTP/1.1\n' >& 8
xz:fd 乄 cat 0<& 8
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: no-cache
Connection: keep-alive
Content-Length: 14615
Content-Type: text/html
Date: Tue, 03 Aug 2021 08:00:14 GMT
P3p: CP=" OTI DSP COR IVA OUR IND COM "
P3p: CP=" OTI DSP COR IVA OUR IND COM "
Pragma: no-cache
......
可以看到只要按照HTTP协议的规范GET / HTTP/1.1\n去发送数据就可以发送成功。
1.2 五层模型
在实际的使用中,因为应用层,表示层以及会话层都是运行在用户态的,而下面的四层是在内核态的。可以将上面三层合并为应用层,也即应用层可以细化拆分为应用层、表示层、会话层三成。因此实际中经常见到的也有五层模型。
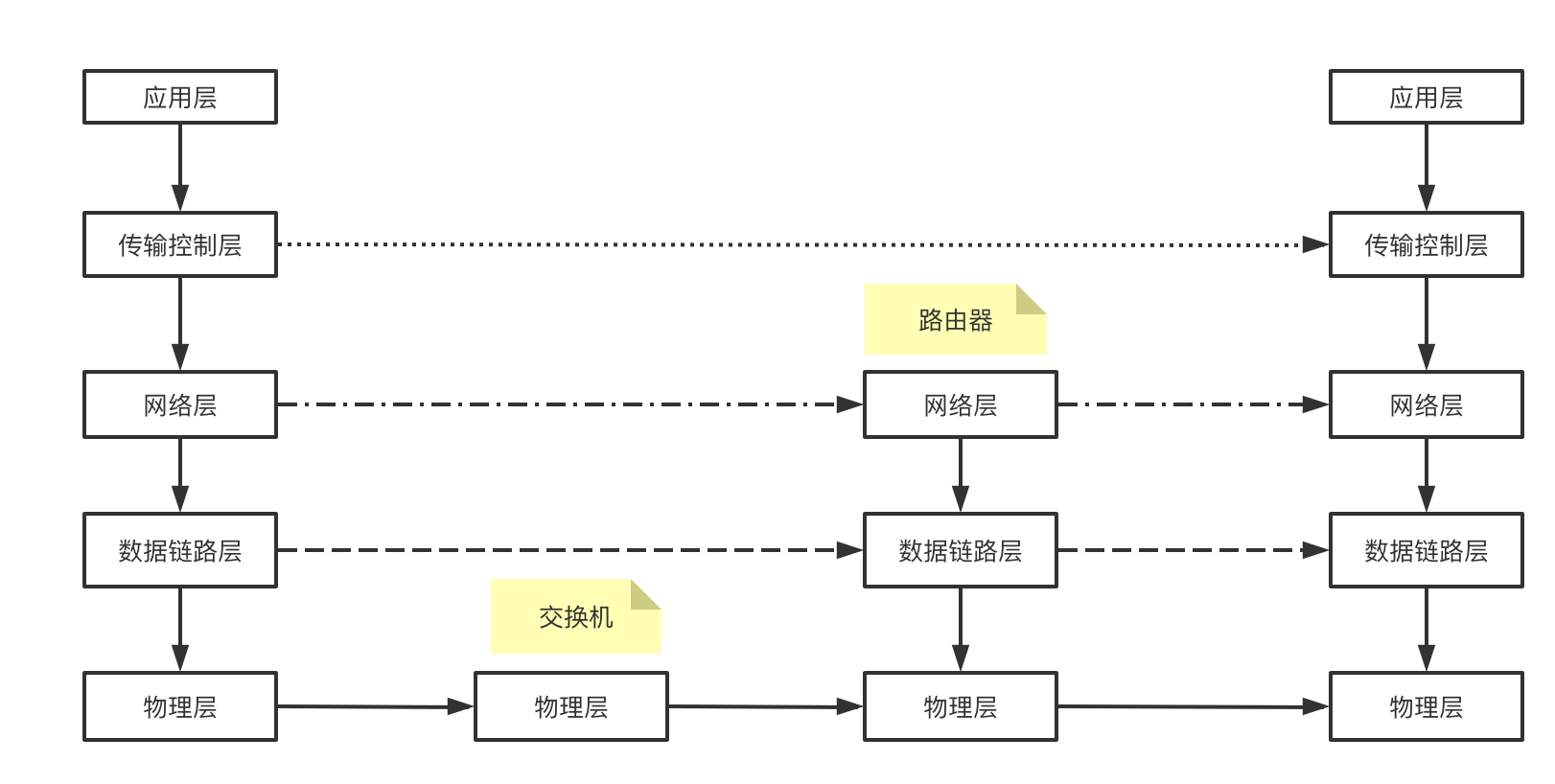
应用层通过协议约束只是对数据进行打包,应用层是无法直接建立通信的,建立通信实际是要靠下面的传输控制层。应用层准备好数据后,通过传输控制层实现端对端建立连接,然后将应用层的数据通过数据包的方式进行传输。传输控制层的协议有TCP和UDP。
- TCP协议: 面向连接的可靠的传输方式
- UDP协议:无连接的不可靠的传输方式
1.3 TCP协议
TCP协议称为面向连接的协议,因此它是实际建立连接的。而它的可靠性是通过三次握手四次分手来保证的。
面向连接
在服务器层面,两台服务器之间是通过ip进行通信的,但是ip仅能锁定主机,无法锁定是主机上的哪儿个应用。因此TCP协议在ip的基础上通过port端口号来锁定应用。在linux中可用的端口个数为65535个,而一个对外开放服务端接口可以被很多的客户端连接。tcp是通过ip+port四元组来保证一个连接的唯一性。
使用netstat -natp命令,可以看到如下信息:
[root@localhost ~]# netstat -natp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:5355 0.0.0.0:* LISTEN 1671/systemd-resolv
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 1/systemd
tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN 2061/dnsmasq
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1417/sshd
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 1415/cupsd
tcp 0 0 10.211.55.3:22 10.211.55.2:51830 ESTABLISHED 12929/sshd: root [p
tcp6 0 0 :::5355 :::* LISTEN 1671/systemd-resolv
tcp6 0 0 :::111 :::* LISTEN 1/systemd
tcp6 0 0 :::22 :::* LISTEN 1417/sshd
tcp6 0 0 ::1:631 :::* LISTEN 1415/cupsd
表头解释如下:
- proto: 代表协议,命令参数-t代表tcp协议,因此查询出来都是tcp协议
- Recv-Q:接收包大小
- Send-Q:发送包大小
- Local Address:本地地址及端口号
- Foreign Address:外来地址及端口号
- State:端口状态
- PID/Program name: 进程号/应用名
一个本地应用开放端口,可以被很多的外部客户端访问,而TCP协议就是通过Local Address + Foreign Address所组成的四元组来保证一个连接的唯一性。
表头参数缓存验证
Recv-Q/Send-Q
开启一个tcpserver端,代码如下:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.InetSocketAddress;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.Scanner;
/**
* @author shuai.zhao@going-link.com
* @date 2021/8/9
*/
public class SocketTest {
public static void main(String[] args) throws IOException {
ServerSocket ssc = new ServerSocket();
ssc.bind(new InetSocketAddress(9000));
Scanner scanner = new Scanner(System.in);
String next = scanner.next();
System.out.println("next = " + next);
try (Socket sc = ssc.accept(); BufferedReader br = new BufferedReader(new InputStreamReader(sc.getInputStream()))) {
while (true) {
String str = br.readLine();
if (str != null && !"".equals(str)) {
System.out.println("str = " + str);
} else {
break;
}
}
}
}
}
然后启动服务端,使用netstat -natp|grep 9000查看状态
xz:bio 乄 netstat -natp|grep 9000
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:9000 0.0.0.0:* LISTEN 9582/java
然后再启动一个客户端连接这个服务端:
import java.io.*;
import java.net.Socket;
import java.nio.charset.StandardCharsets;
/**
* @author shuai.zhao@going-link.com
* @date 2021/6/2
*/
public class BIOClient {
public static void main(String[] args) throws IOException {
Socket client = new Socket("127.0.0.1", 9000);
client.setTcpNoDelay(true);
client.setSendBufferSize(1024);
InputStream ins = System.in;
BufferedReader br = new BufferedReader(new InputStreamReader(ins));
OutputStream ops = client.getOutputStream();
while (true) {
String line = br.readLine();
if (line != null) {
ops.write(line.getBytes(StandardCharsets.UTF_8));
InputStream inputStream = client.getInputStream();
byte[] bytes = new byte[1024];
int len = inputStream.read(bytes);
System.out.println("new String(bytes) = " + new String(bytes, 0, len));
}
}
}
}
启动客户端,然后另起一个窗口,执行netstat命令:
xz:~ 乄 netstat -natp|grep 9000
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 1 0 0.0.0.0:9000 0.0.0.0:* LISTEN 9582/java
tcp 0 0 127.0.0.1:9000 127.0.0.1:33762 ESTABLISHED -
tcp 0 0 127.0.0.1:33762 127.0.0.1:9000 ESTABLISHED 9620/java
在客户端控制台写入数据,再次执行netstat命令:
// 客户端写入数据
xz:bio 乄 java BIOClient
skjgljsaklgjfkljgljdfklgjkldfsjgkljfdkljgkldfjgljdfkljgkldfjlgjfkgdkfjgljfgldf
// 在另一个窗口执行netstat命令
xz:~ 乄 netstat -natp|grep 9000
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 1 0 0.0.0.0:9000 0.0.0.0:* LISTEN 9582/java
tcp 78 0 127.0.0.1:9000 127.0.0.1:33762 ESTABLISHED -
tcp 0 0 127.0.0.1:33762 127.0.0.1:9000 ESTABLISHED 9620/java
可以看到,客户端写入的数据都写入了Recv-Q——服务端待接受数据。此时服务端还没有调用接受客户端方法,因此数据只能暂时换存在网卡中。这个Recv-Q大小是有限制的,当超过这个大小时,数据就会丢失。然后在服务端随便输入内容,让服务端代码继续向下走。
xz:io 乄 java SocketTest
sdfdsf
next = sdfdsf
// 另一个窗口执行
xz:~ 乄 netstat -natp|grep 9000
tcp 0 0 0.0.0.0:9000 0.0.0.0:* LISTEN 9582/java
tcp 0 0 127.0.0.1:9000 127.0.0.1:33762 ESTABLISHED 9582/java
tcp 0 0 127.0.0.1:33762 127.0.0.1:9000 ESTABLISHED 9620/java
可以看到数据被接收了。
缓存大小配置为:serverSocket.setReceiveBufferSize(10);
可以在客户端及服务端多打几个断点,查看Send-Q中的数据包
四元组
服务器通过CIP:CPORT SIP:SPORT四个纬度来标识一个链接,也就是一台客户端主机,最多可以与同一个服务端的同一个端口号建立65535个链接,四个维度只要有一个维度变化,那么就能建立一个连接。一个客户端的一个端口也可以与服务端的65535个端口建立连接
TCP三次握手
客户端和服务端使用TCP协议通信时,tcp协议是通过三次握手来建立连接的。具体操作如下:
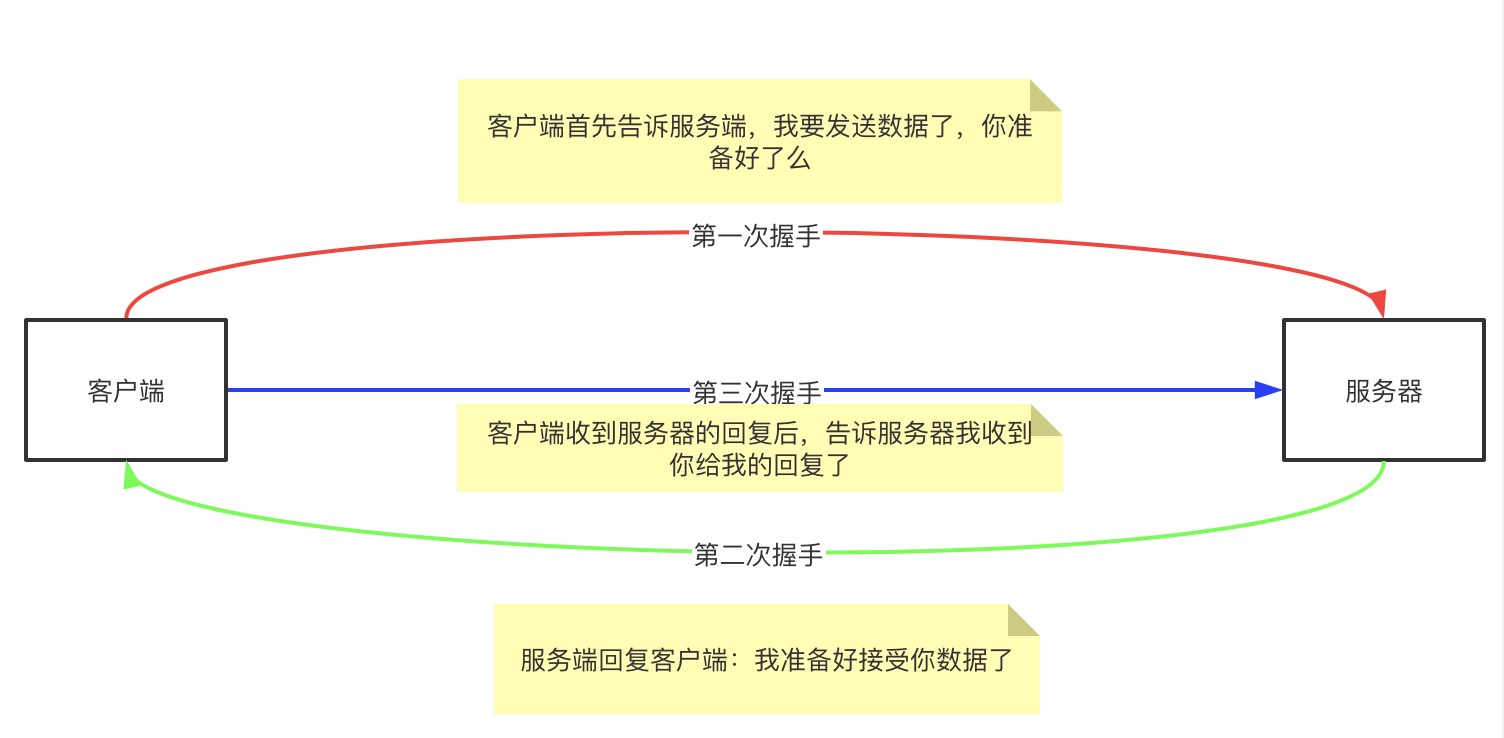
验证
手写一个socket服务端并启动,使用tcpdump抓包
[root@node01 ~]# tcpdump -nn -i lo port 9000
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
tcpdump监听的哪儿块网卡,下面使用nc连接时就要选择相应的ip地址。例如使用lo网卡,下面就使用localhost访问服务端,使用ens33网卡,就要使用192.168.226.128访问
使用nc连接服务端后,查看抓到的数据包
[root@node01 ~]# tcpdump -nn -i lo port 9000
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lo, link-type EN10MB (Ethernet), capture size 262144 bytes
10:37:23.385618 IP6 ::1.36818 > ::1.9000: Flags [S], seq 699200651, win 43690, options [mss 65476,sackOK,TS val 44785360 ecr 0,nop,wscale 7], length 0
10:37:23.385641 IP6 ::1.9000 > ::1.36818: Flags [R.], seq 0, ack 699200652, win 0, length 0
10:37:23.385837 IP 127.0.0.1.56146 > 127.0.0.1.9000: Flags [S], seq 2813937747, win 43690, options [mss 65495,sackOK,TS val 44785360 ecr 0,nop,wscale 7], length 0
10:37:23.385859 IP 127.0.0.1.9000 > 127.0.0.1.56146: Flags [S.], seq 3409361478, ack 2813937748, win 43690, options [mss 65495,sackOK,TS val 44785360 ecr 44785360,nop,wscale 7], length 0
10:37:23.385875 IP 127.0.0.1.56146 > 127.0.0.1.9000: Flags [.], ack 1, win 342, options [nop,nop,TS val 44785360 ecr 44785360], length 0
三次握手的数据包为这三条:
10:37:23.385837 IP 127.0.0.1.56146 > 127.0.0.1.9000: Flags [S], seq 2813937747, win 43690, options [mss 65495,sackOK,TS val 44785360 ecr 0,nop,wscale 7], length 0
10:37:23.385859 IP 127.0.0.1.9000 > 127.0.0.1.56146: Flags [S.], seq 3409361478, ack 2813937748, win 43690, options [mss 65495,sackOK,TS val 44785360 ecr 44785360,nop,wscale 7], length 0
10:37:23.385875 IP 127.0.0.1.56146 > 127.0.0.1.9000: Flags [.], ack 1, win 342, options [nop,nop,TS val 44785360 ecr 44785360], length 0
查看三次握手包的内容,大概由以下部分组成
10:06:11.220859时间戳,- IP
127.0.0.1.50842包来源地址,>包传输方向,127.0.0.1.9000目标地址。 Flags报文标记段:S: synF:finP:push.: ackR:
seq请求同步序列号,tcp字节流中第一个字节的序号,如果是Flags位[S]初始化状态,则值为随机数ack确认,如果为应答方(第二次握手)则为序列号 一般为seq+1,如果为包发送方win缓冲区可用字节数options选项length数据包的长度
当三次握手完成之后,就默认客户端发送的消息,服务端一定能够收到。也就是说只要完成了三次握手,就认为这次连接是可靠的,数据不会丢失。因此完成三次握手之后,客户端和服务端就会建立连接(网络世界没有绝对的可靠,所以认为三次握手后这个链接就是可靠的了)。客户端和服务端通过创建一个socket的文件描述符来建立连接。
[root@node01 ~]# netstat -natp|grep 9000
tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN 7945/./rust-socket
tcp 0 0 127.0.0.1:56146 127.0.0.1:9000 ESTABLISHED 7972/nc
tcp 0 0 127.0.0.1:9000 127.0.0.1:56146 ESTABLISHED 7945/./rust-socket
查看服务端进程7945文件描述符
[root@node01 ~]# cd /proc/7945/fd
[root@node01 fd]# ll
总用量 0
lrwx------. 1 root root 64 8月 27 10:42 0 -> /dev/pts/0
lrwx------. 1 root root 64 8月 27 10:42 1 -> /dev/pts/0
lrwx------. 1 root root 64 8月 27 10:42 2 -> /dev/pts/0
lrwx------. 1 root root 64 8月 27 10:42 3 -> socket:[90652]
lrwx------. 1 root root 64 8月 27 10:42 4 -> socket:[16707764]
文件描述符3为Listen状态的,可以在客户端简历连接前查看fd,建立链接后再查看fd,可以看到4是客户端与服务端的socket链接。
在客户端发送数据1234567
10:38:58.246985 IP 127.0.0.1.9000 > 127.0.0.1.56146: Flags [P.], seq 1:9, ack 9, win 342, options [nop,nop,TS val 44880221 ecr 44880221], length 8
10:38:58.246996 IP 127.0.0.1.56146 > 127.0.0.1.9000: Flags [.], ack 9, win 342, options [nop,nop,TS val 44880221 ecr 44880221], length 0
length为8,是因为发送实际发送数据为1234567\n,包含一个换行符。
TCP四次分手
关闭java客户端进程,监听四次分手数据包。
14:31:10.694939 IP 127.0.0.1.54560 > 127.0.0.1.9000: Flags [F.], seq 1, ack 1, win 6379, options [nop,nop,TS val 3899935821 ecr 3712799444], length 0
14:31:10.694976 IP 127.0.0.1.9000 > 127.0.0.1.54560: Flags [.], ack 2, win 6379, options [nop,nop,TS val 3712808509 ecr 3899935821], length 0
14:31:10.695032 IP 127.0.0.1.9000 > 127.0.0.1.54560: Flags [F.], seq 1, ack 2, win 6379, options [nop,nop,TS val 3712808509 ecr 3899935821], length 0
14:31:10.695087 IP 127.0.0.1.54560 > 127.0.0.1.9000: Flags [.], ack 2, win 6379, options [nop,nop,TS val 3899935821 ecr 3712808509], length 0
从上面的数据包可以看出,客户端首先发送分手数据包,然后服务端回复确认包,服务端发送分手包,客户端发送确认包。整个流程图如下:
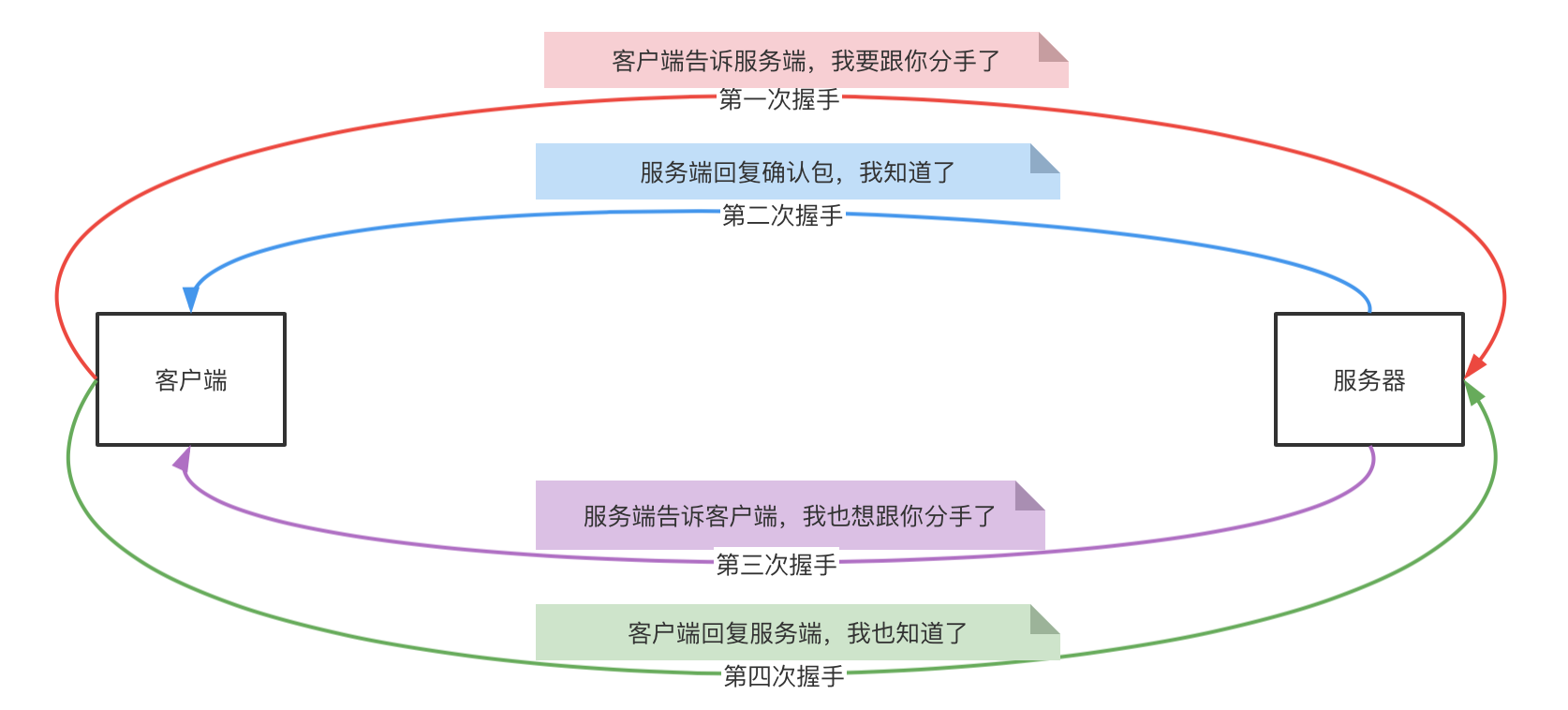
当完成上面这一套流程后,才会真的释放连接。
验证
使用客户端重新连接服务端:
xz:~ 乄 netstat -natp|grep 9000
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:9000 0.0.0.0:* LISTEN 27212/java
tcp 0 0 127.0.0.1:9000 127.0.0.1:53626 ESTABLISHED 27212/java
tcp 0 0 127.0.0.1:53626 127.0.0.1:9000 ESTABLISHED 27287/java
关闭客户端
xz:~ 乄 netstat -natp|grep 9000
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:9000 0.0.0.0:* LISTEN 27212/java
tcp 0 0 127.0.0.1:53626 127.0.0.1:9000 TIME_WAIT -
注意此时,服务端的连接已经关闭了,但是客户端的四元组仍然存在,这个连接的状态为TIME_WAIT,再等待一段时间后,再次查看四元组
xz:~ 乄 netstat -natp|grep 9000
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:9000 0.0.0.0:* LISTEN 27212/java
可以看到客户端连接已经释放。
这是因为客户端第一次发起的分手,客户端第四次分手包通知服务端,我也收到你要分手的数据包了。那么服务端收到第四次的分手包后,就可以确定四次握手已经完成了, 就会直接释放资源,但是客户端此时并不知道服务端有没有收到自己第四次的数据包,所以它会等一会儿,等待如果服务端没有收到第四次的数据包,那么服务端会重新发送要分手的数据包,客户端就可以重新回复第四次的分手确认包。如果等待一会儿后没有收到数据包,那么就可以确定服务端收到数据包了,就可以释放自己的资源了。否则如果不等待一会儿,发送完第四次分手包后直接释放资源,如果第四次分手包发生丢包,那么另一方的连接就永远不会释放了。
总结就是:先发起分手的一方,完成四次分手后需要等一会儿再释放资源
1.4 网络
在传输控制层,TCP协议通过三次握手建立连接,然后打包发送数据,但是数据是如何发送到服务端的呢?是直接一根网线连通了客户端和服务端么?肯定不可能这样搞。那么客户端第一次发送握手包时,是如何确定目标主机的位置呢?
这就是网络层所干的事。在传输控制层,TCP三次握手建立连接,但是并不是说TCP直接就发送包了, TCP也只是把数据加工,打成数据包的格式,数据的发送还是要走下面的网络层。而网络层就是确定目标主机的位置的。
我们说在传输控制层是通过ip+port的方式来确定应用程序的。而网络层就是通过ip来锁定主机的。因为在同一局域网中,ip不能重复,所以我们就可以通过ip寻找到主机,然后通过port来锁定应用,这样就能建立通信了。
但是在互联网中,ip地址那么多,而且会有很深的内部局域网关系,这种情况下,客户端是如何通过ip寻找到服务端呢?
使用route -n命令可以查看本地路由表:
[root@localhost fd]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.211.55.1 0.0.0.0 UG 100 0 0 enp0s5
10.211.55.0 0.0.0.0 255.255.255.0 U 100 0 0 enp0s5
192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0
- Destination: 表示目标ip或目标网络网段
- Gateway:表示网关地址
- Genmask:表示子网掩码
- Use Ifac:表示使用的网卡
客户端就是通过本地路由表来寻找锁定目标地址的。具体的方案称为寻找下一跳地址。
两台计算机之间通信是通过数据包的形式发送数据的。每一个数据包内都会有本地ip信息和目标ip信息。这样目标机器在收到数据后,就知道数据是从哪儿个ip发过来的,再将这个ip作为目标ip发送数据,就实现了数据的返回。两个服务器间就通信了。而客户端再发送数据时,传输控制层将数据包准备好后,就到了网络层。网络层拿到目标地址的ip,然后通过这个ip地址与子网掩码进行与运算就可以得到一个条目,知道应该走哪儿个网关。
如何计算?
下一跳
ip地址又叫点分字节数组,将一个ip地址通过.作为分隔符后,得到一个数组,数组中每一个元素最大为255,也就是一个字节所能表示的最大数,一个字节就是8位。因此255用二进制表示就是11111111。所以通过目标ip与本地路由表中的每一个条目进行&运算,然后拿结果与Destination进行匹配,就会得到一个匹配成功的。然后查看这个匹配成功的条目的gateway网关地址,这个网关地址就是下一跳的地址。数据就会被发送到网关所在的机器(服务器,路由器等)。
上面文字描述可能有调绕,画图来表示:
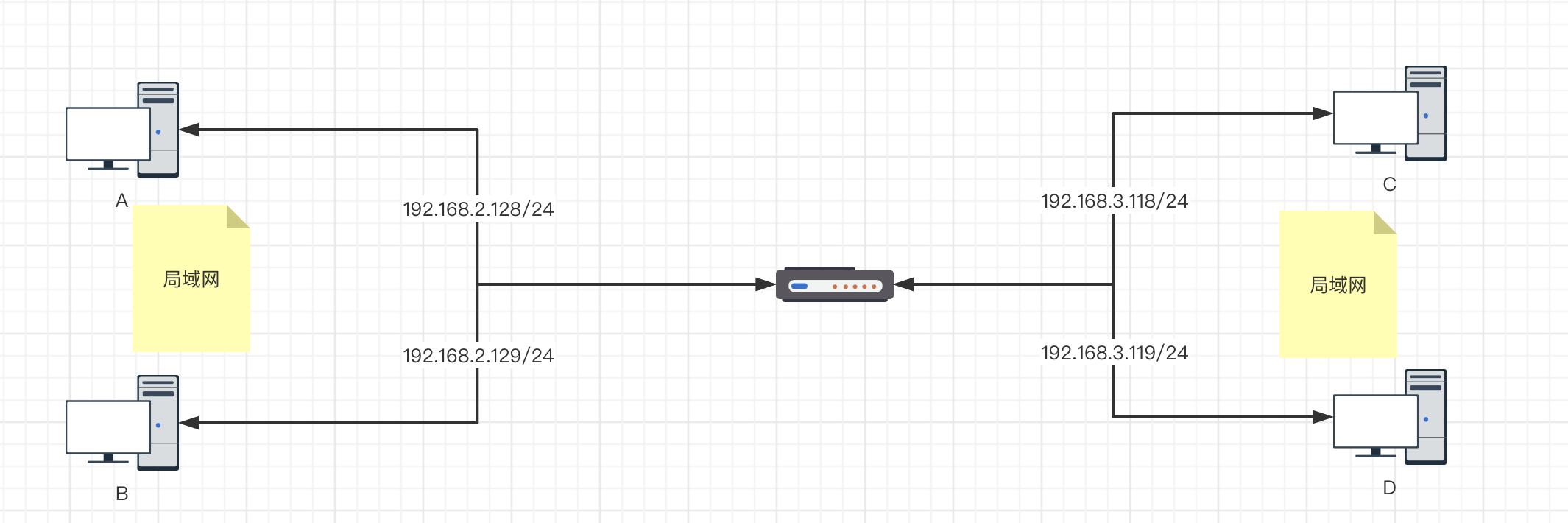
/24表示子网掩码为255.255.255.0
现在服务器A想要与服务器C建立通信,那么准备数据包ip信息为 192.168.2.128>192.168.3.118。
拿192.168.3.118^255.255.255.0得到的结果为192.168.3.0,然后与本地路由表进行匹配,匹配到一个条目,然后得到下一跳的地址是网关地址。到达网关后,网关再拿目标ip192.168.3.118与网关的本地路由表进行匹配,发现是本地的网络,然后网关就将数据包发送给C主机。
但是上面的过程有一个问题就是:A主机通过本地路由表拿到下一跳地址后,目标地址要不要变成下一跳地址?
- 如果目标地址变为网关地址,那么数据发送给网关后,网关发现数据包是给自己的,就不会转发给C了。
- 如果目标地址不变,那么本地局域网找不到目标地址,数据包发不出去。
这样看来的话,数据包好像怎样都发不出去了。这时就要用到数据链路层了。
1.5 数据链路
数据包在网络层中找到下一跳地址后,会在数据链路层对数据包再做一层包装,对数据包包上一层MAC地址(网卡地址)。
网络层有路由表,链路层也有链路表,存放的是mac地址。通过arp -an命令,可以查看链路表:
[root@localhost fd]# arp -an
? (10.211.55.2) at 92:9c:4a:ab:ce:64 [ether] on enp0s5
? (10.211.55.1) at 00:1c:42:00:00:18 [ether] on enp0s5
arp是一个协议,受限于同一局域网内,存放的是局域网内的网卡地址。arp会解释ip地址和网卡硬件地址的映射。
在网络层拿到下一跳地址后,会根据这个下一跳的网关地址通过链路表查找到这个ip对应的网卡mac地址。然后再数据包外面包上下一跳地址的mac地址后,数据包就可以发送到下一跳的节点上了。下一跳节点拿到数据包后,也会拿到目标ip地址根据本地路由表判定,如果还需要跳就会再次包上下一跳的mac地址,知道数据发送到目标节点。
具体流程图如下:
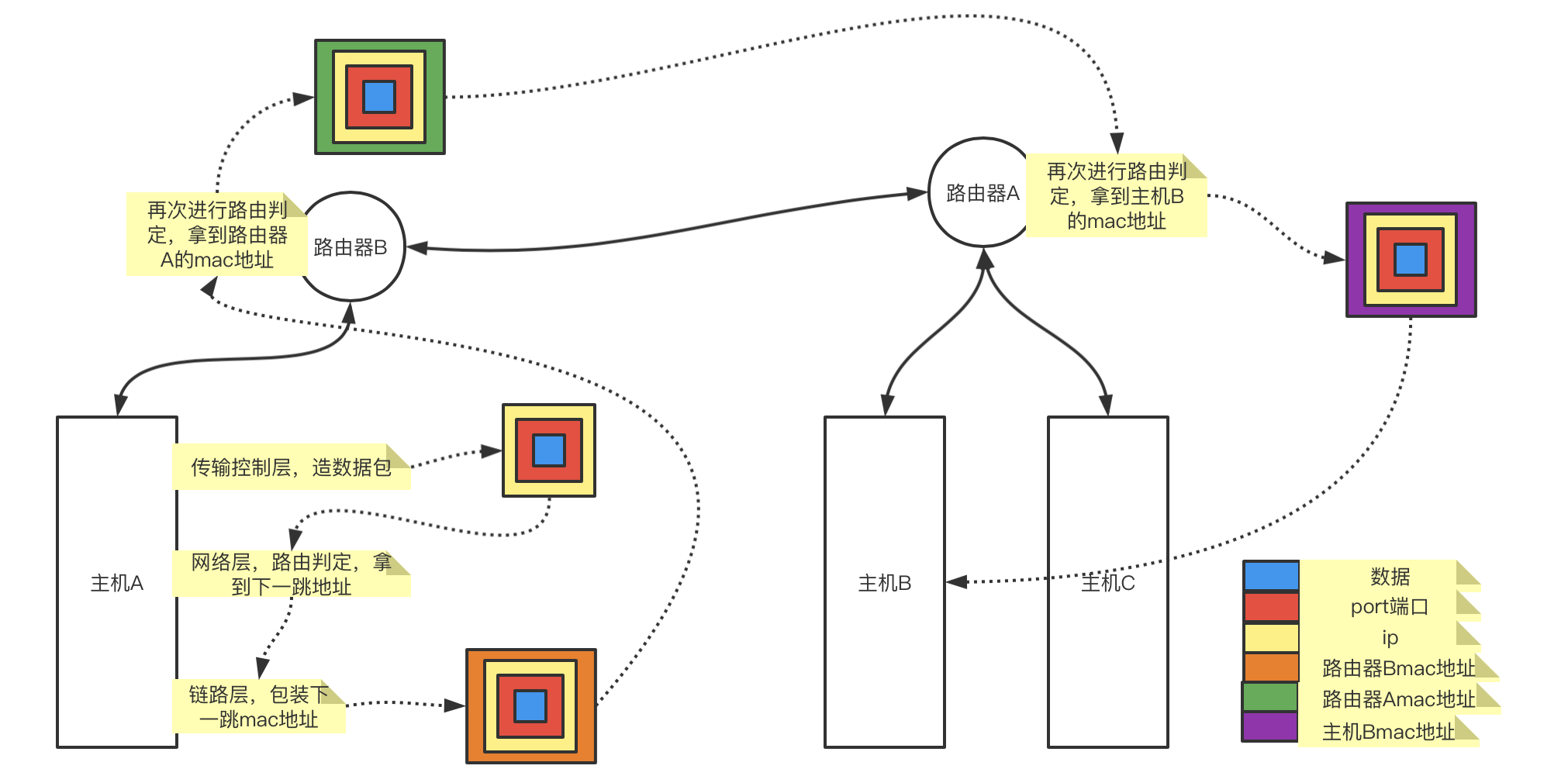
1.7 验证推论
使用window开启四台虚拟机分别做以下准备:
- node01 设置双网卡,一块网卡为仅主机模式,另一块设置为桥接模式。
- node02、node03设置为仅主机模式
- node04:桥接模式
开启上面四台虚拟机后,整体网络环境为:
- node01:192.168.218.128 192.168.0.104
- node02:192.168.218.129
- node03:192.168.218.130
- node04:192.168.0.103
那么此时因为node02和node04是不在一个网段下面的,因此node02和node04之间是无法互联的。
[root@node04 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.0.1 0.0.0.0 UG 100 0 0 ens33
192.168.0.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
[root@node04 ~]# ping 192.168.218.128
PING 192.168.218.128 (192.168.218.128) 56(84) bytes of data.
^C
--- 192.168.218.128 ping statistics ---
5 packets transmitted, 0 received, 100% packet loss, time 4013ms
[root@node04 ~]# ping 192.168.218.129
PING 192.168.218.129 (192.168.218.129) 56(84) bytes of data.
此时为node04配置路由地址:
[root@node04 ~]# route add -net 192.168.218.0/24 gw 192.168.0.104
[root@node04 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.0.1 0.0.0.0 UG 100 0 0 ens33
192.168.0.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
192.168.218.0 192.168.0.104 255.255.255.0 UG 0 0 0 ens33
[root@node04 ~]#
配置完成之后,node04就可以访问node01的ens33网卡了:
[root@node04 ~]# ping 192.168.218.128
PING 192.168.218.128 (192.168.218.128) 56(84) bytes of data.
64 bytes from 192.168.218.128: icmp_seq=1 ttl=64 time=0.710 ms
64 bytes from 192.168.218.128: icmp_seq=2 ttl=64 time=0.700 ms
64 bytes from 192.168.218.128: icmp_seq=3 ttl=64 time=0.721 ms
64 bytes from 192.168.218.128: icmp_seq=4 ttl=64 time=0.716 ms
^C
--- 192.168.218.128 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3009ms
rtt min/avg/max/mdev = 0.700/0.711/0.721/0.033 ms
[root@node04 ~]# ping 192.168.218.129
PING 192.168.218.129 (192.168.218.129) 56(84) bytes of data.
^C
--- 192.168.218.129 ping statistics ---
4 packets transmitted, 0 received, 100% packet loss, time 3000ms
[root@node04 ~]#
但是发现还是不能访问node02,node03。修改node02和node03的路由配置:
[root@node02 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.218.1 0.0.0.0 UG 100 0 0 ens33
192.168.218.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
[root@node02 ~]# route del default
[root@node02 ~]# route add default gw 192.168.218.128
[root@node02 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.218.128 0.0.0.0 UG 0 0 0 ens33
192.168.218.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
[root@node02 ~]# ping 192.168.0.103
PING 192.168.0.103 (192.168.0.103) 56(84) bytes of data.
64 bytes from 192.168.0.103: icmp_seq=1 ttl=63 time=2.39 ms
64 bytes from 192.168.0.103: icmp_seq=2 ttl=63 time=1.56 ms
node02此时可以访问node04了,node04也可以访问node02了。
[root@node04 ~]# ping 192.168.218.129
PING 192.168.218.129 (192.168.218.129) 56(84) bytes of data.
64 bytes from 192.168.218.129: icmp_seq=1 ttl=63 time=1.60 ms
64 bytes from 192.168.218.129: icmp_seq=2 ttl=63 time=1.39 ms
二、 LVS的DR、NAT、TUN模型推导
LVS:linux虚拟服务器。常用来做linux负载均衡。首先来看一下什么是负载均衡?
负载均衡就是在高并发情况下,当一台服务器撑不住的时候,使用多台服务器来进行分流。但是使用多台服务器时就会有一个问题:客户端要与服务端通信是通过ip,但是服务端做负载均衡时会有多台服务器,那么这个ip应该给谁?因为ip不能重复。所以为了解决这个问题,就希望是在客户端与服务器中间能够有一台中间负载均衡服务器,客户端的请求经过这个负载均衡服务器,由负载均衡服务器来决定这个请求交给哪儿个服务器来处理。
如果中间添加一台负载均衡服务器的话,那么对这个负载均衡服务器的要求就是要足够快——因为本来是客户端与服务端直连,因为服务端处理的慢,所以高并发情况下一台扛不住,需要做负载均衡,如果负载均衡的速度不够快的话,那么在中间层就挂了,也就不存在后面的负载均衡一说了。要想让负载均衡足够快,那么首先就要先了解后面的为什么慢。
当客户端直接访问服务端时,那么服务端就需要在传输控制层,为这次连接分配开辟资源,系统调用以及建立连接的三次握手等。所以慢,为了在中间的负载均衡层保证快,所以只要保证中间的负载均衡层不要建立连接,只做转发,不去握手。这样就可以保证足够快。
在上面的思考的基础上,我们可以画出以下的网络拓扑图:
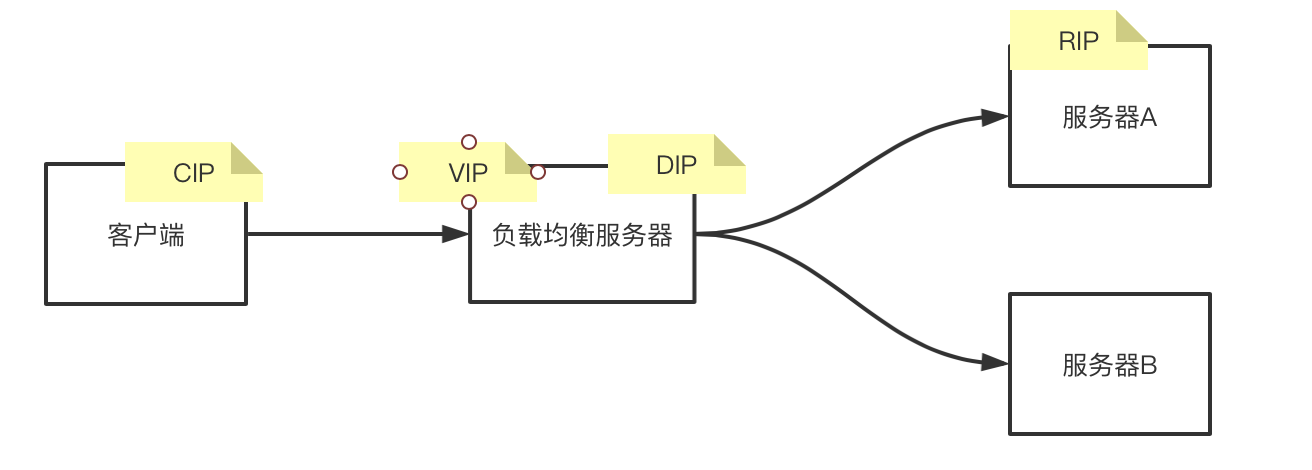
为了统一语义,后面统一用CIP,VIP等来描述:
CIP: 客户端IP地址
VIP:暴露给客户端的服务端的虚拟ip地址
DIP:负载均衡服务器的地址
RIP:真实服务器的地址
为什么要有VIP?
因为客户端是要与服务端建立连接的,客户端的数据包是要包含 CIP->RIP的,但是现在RIP有两个,客户端并不知道应该与哪儿个服务器建立连接,因此使用VIP来表示服务端ip,客户端只需要知道将数据发送给VIP,至于最终数据包会给到哪儿个服务器并不需要关心。
NET模型
在上面的网络拓扑图中,我们假设负载均衡服务器功能已经实现了, 也就是CIP->VIP的数据包可以转发到RIP,那么此时服务器会接受这个数据包么?
不会接受,因为这个数据包的目标地址是VIP,但是服务端RIP并不知道VIP是谁,因此这个数据包会被丢弃。那么这个问题该怎么解决?
我们先暂时不考虑这个问题,先来学习一些其他的知识:
在家中都会装有路由器,我们连的路由器的内网, 数据包经过路由器转发给服务器,如下图:
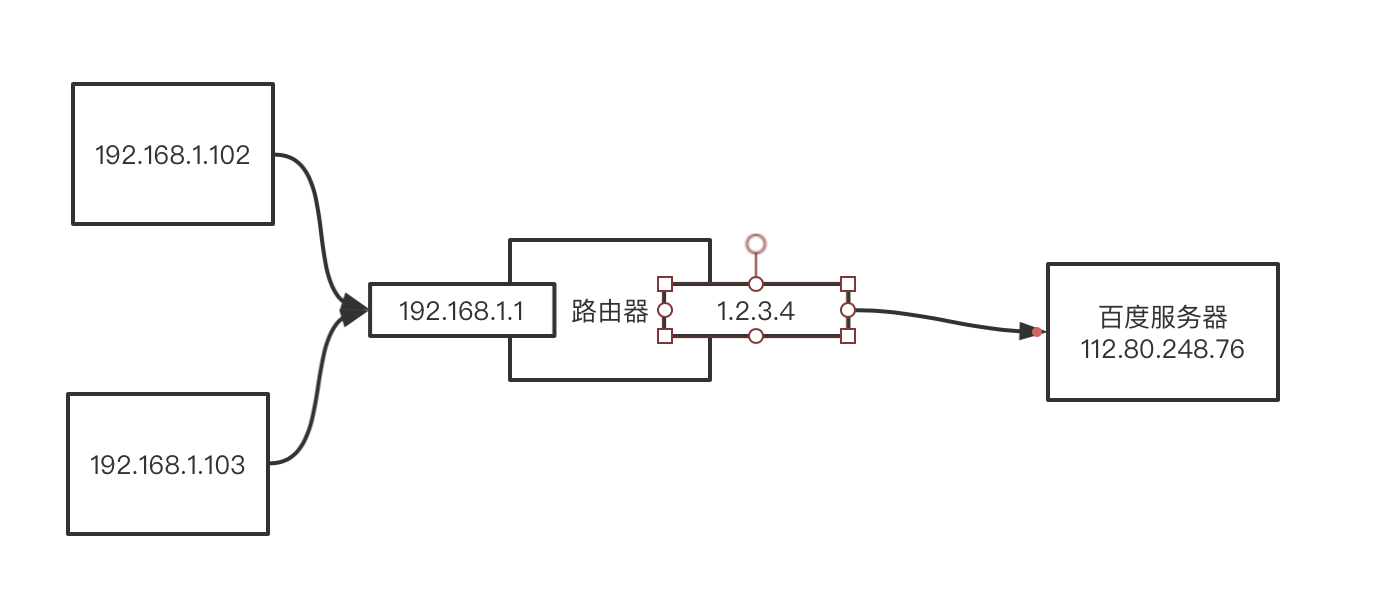
路由器有两块网卡,一块是公网地址,就是运营商分配给家庭的ip地址1.2.3.4,一块就是这个路由器的内网地址192.168.1.1。当我们想访问百度的网站时,会做如下处理:
- 首先在本地会生成一个
192.168.1.102:8090->112.80.248.76:80的数据包。 - 数据包通过本地路由表做路由判定后,经过arp转发到了路由器。
- 路由器将数据包中的来源ip+端口号替换成公网ip+自己的端口号,也就是经过路由器转发出去的包变成了
1.2.3.4:123->112.80.248.76:80 - 百度拿到数据包后,将来源ip作为目标ip,响应数据包
112.80.248.76:80->1.2.3.4:123
看了上面的过程可能会产生如下疑问:
-
为什么要替换公网ip?
因为数据包从本地发出后,经过路由器层层转发,到达百度服务器后,服务端会拿来源ip来做为目标地址,如果不替换的话,来源地址是一个内网地址,但是百度服务器端并不知道这个内网地址是哪儿,因此不知道往哪儿转发。但是替换为公网ip后,服务端就知道应该往哪儿发了。
-
为什么在3中经过路由器转发的包端口发生了变化?
客户端与服务端建立通信是靠四元组维护连接的唯一性的。现在客户端的数据包在经过路由器时ip地址会被替换为公网ip,那么假设此时
192.168.1.102:8090与192.168.1.103:8090两个客户端的8090端口都要访问百度,那么这两个客户端的源ip+端口号在经过路由器后就变成了1.2.3.4:8090,此时这两个客户端对外的数据包就是一样的了。当服务端收到数据包后回复的数据包为112.80.248.76:80->1.2.3.4:8090,路由器收到数据包,但是路由器并不知道这个数据包是下面哪儿个客户端的。因此客户端数据包在经过路由器转发时,路由器会随机取一个端口号,然后将数据包的源ip+端口号替换为 公网ip+随机端口号,同时路由器内会维护一个映射表,内容为
自身的随机端口号:源客户端ip+端口号,这样数据包响应回路由器时,路由器就可以通过这个映射表,再将响应包的目标地址替换为客户端的ip+端口号。
验证net模式
准备一台阿里云主机116.62.45.116,然后使用浏览器ip38.com查询本地公网IP,查询结果如下:
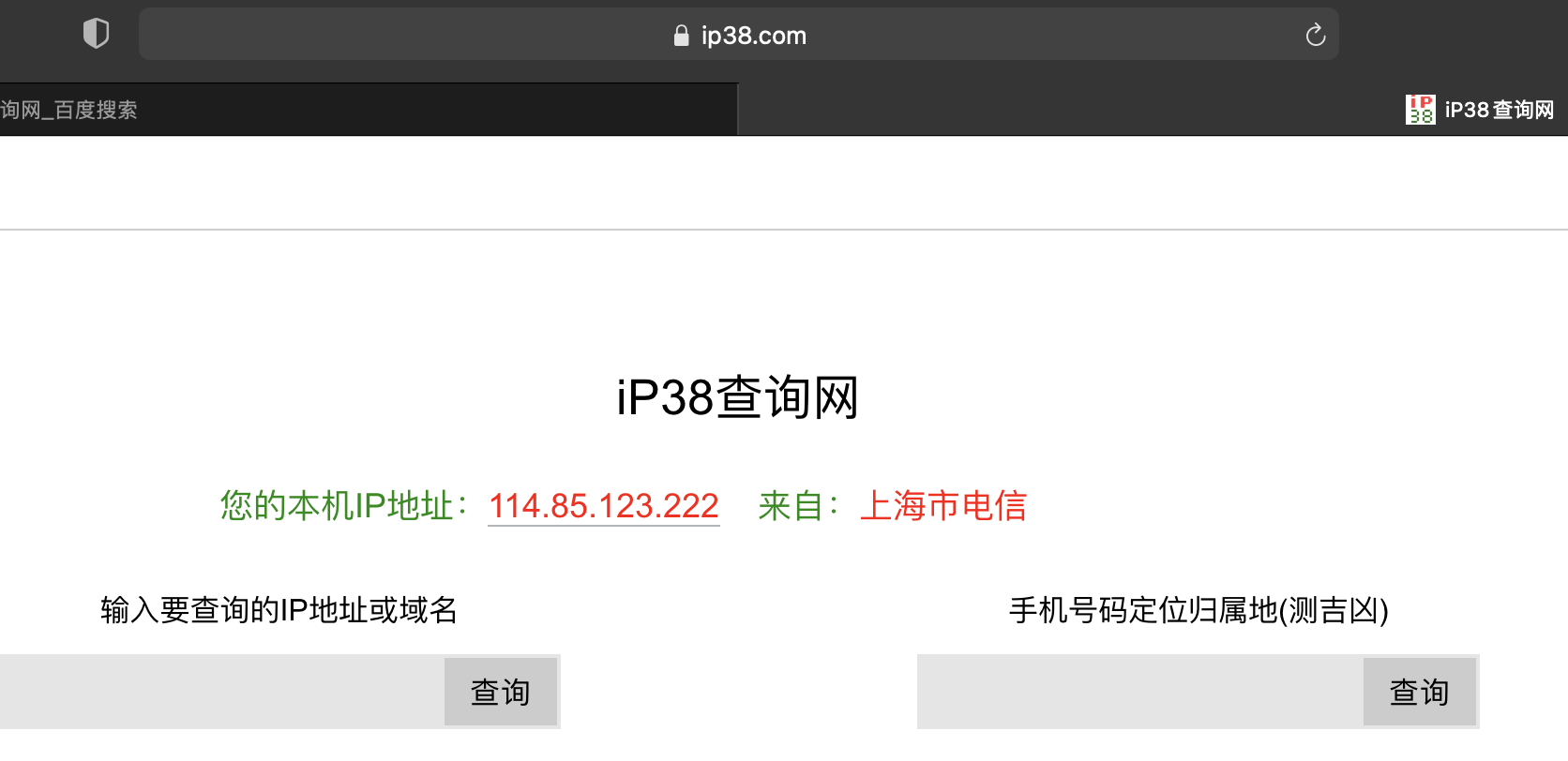
然后本地登录阿里云主机:
zhaoshuai:~ 乄 ssh xz@116.62.45.116
xz@116.62.45.116's password:
...
Welcome to Alibaba Cloud Elastic Compute Service !
xz:~ 乄
本地查看tcp连接信息:
zhaoshuai:~ 乄 netstat -nat|grep 22
tcp4 0 0 192.168.0.102.55142 116.62.45.116.22 ESTABLISHED
tcp4 0 0 192.168.0.102.55120 222.73.192.116.443 ESTABLISHED
可以看到本地的tcp连接四元组是:192.168.0.102.55142 116.62.45.116.22,再在阿里云远程主机查看tcp连接信息:172.16.120.48:22 114.85.123.222:55142可以看到路由器使用net模式发生了ip替换。
上面路由器的这个ip和端口号替换的过程其实就是net模式,那么使用这种net模式来推导lvs模型的话,整个网络拓扑图如下:
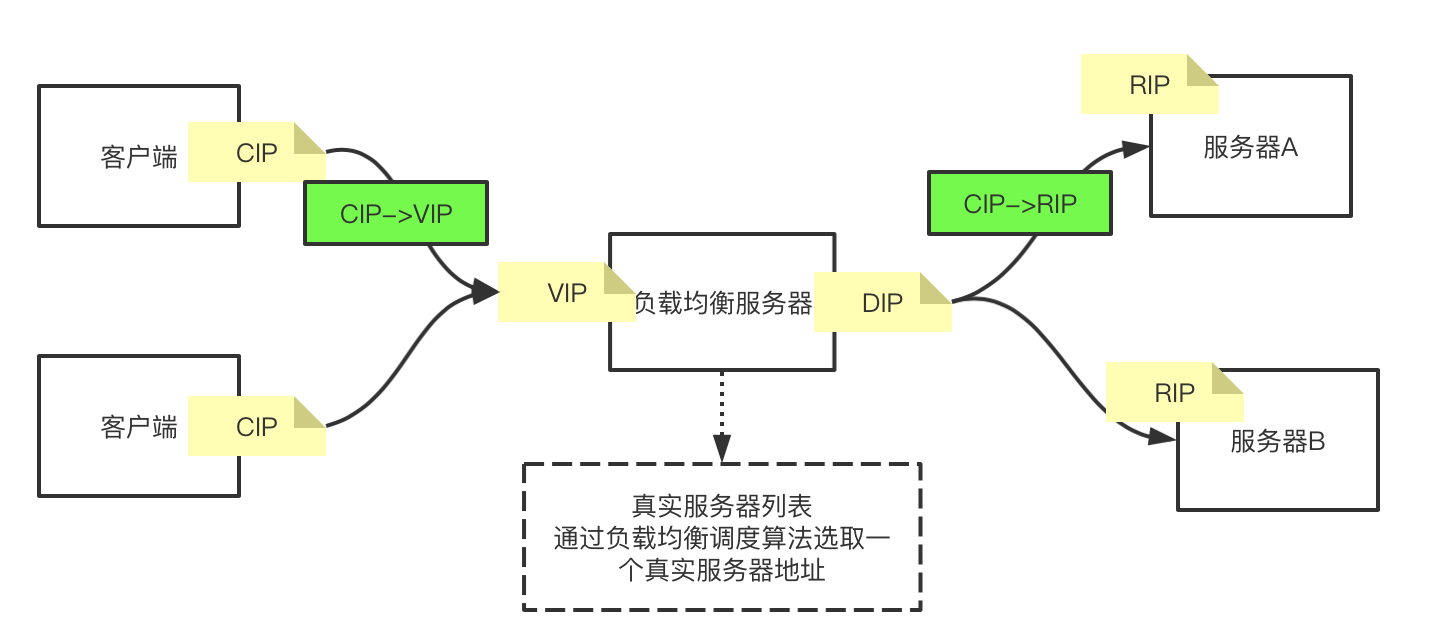
上面模型中,我们默认客户端是经过路由器转发出来的数据包,至于路由器内数据包的ip替换是属于局域网内的事,上面的模型客户端默认都是公网环境下的客户端。
那么在上面图的基础上,我们来推理客户端想访问服务端的过程:
- 客户端准备数据包
Cip:Cport->Vip:80(假设是想访问80端口) - 数据包到达负载均衡服务器VIP网卡
- 负载均衡服务器会窥探数据包的四元组,当发现目标地址是
VIP:80端口时,就知道这个数据包不是自己的,要转出去。 - 经过负载均衡服务器内的调度算法,选出一台真实服务器,将目标地址更改为真实服务器地址,此时数据包为
Cip:Cport->Rip:80
数据到达服务器A后,服务器会组装响应报文,响应报文的地址信息为:RIP->CIP,那么假设最终这个响应包能够到达客户端,但是客户端发现源地址是RIP的,客户端发送的数据包是CIP->VIP的,那么它会接受VIP->CIP的包,此时收到的数据包是RIP发来的,他就会将这个数据包丢弃。因此最终还要保证响应的包的来源地址也还是VIP。因此RIP响应的包最终还是要走负载均衡服务器,将数据包的来源地址替换为VIP,这样的话,客户端就可以收到响应的数据包了。响应过程如下:
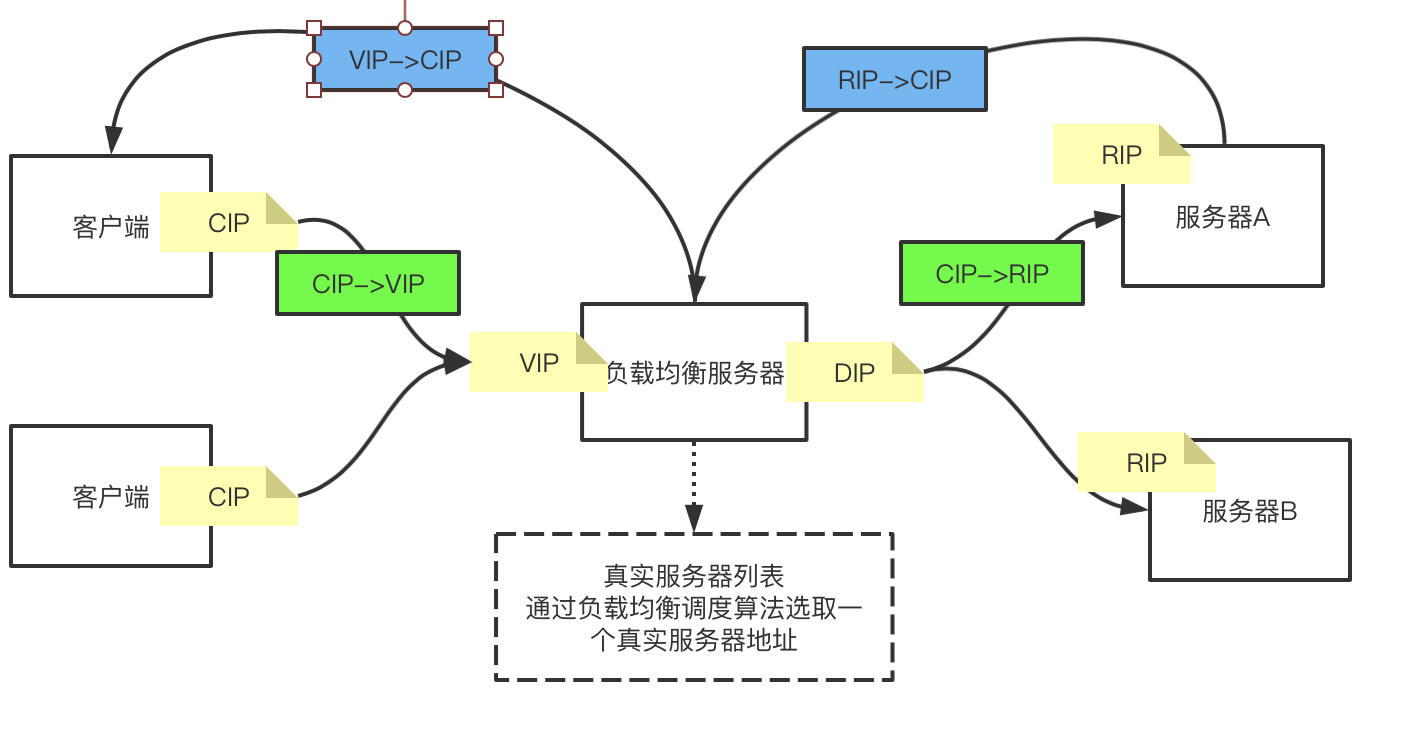
而如果要想响应的数据包也会经过负载均衡器,那么就需要服务端的默认网关为负载均衡服务器。
DR模型(直接路由模型)
上面推导了NET模型,但是net模型具有一下缺点:
- 数据包进和出都需要经过负载均衡服务器,两次都需要换地址,而所有的请求都需要经过这一站,并发量较大,会影响cpu的算力
- 平时使用时,一般都是发送的包比较小,响应的包比较大,现在进出数据包都经过负载均衡服务器,来回都走一条路,就会影响速度(影响速度的主要原因)
从上面的分析可以看出,影响net模型最大的问题就是: 来回的数据包都走一条路,所以就思考能不能想办法让回去的数据包直接到达客户端,也就是变成下面这样:
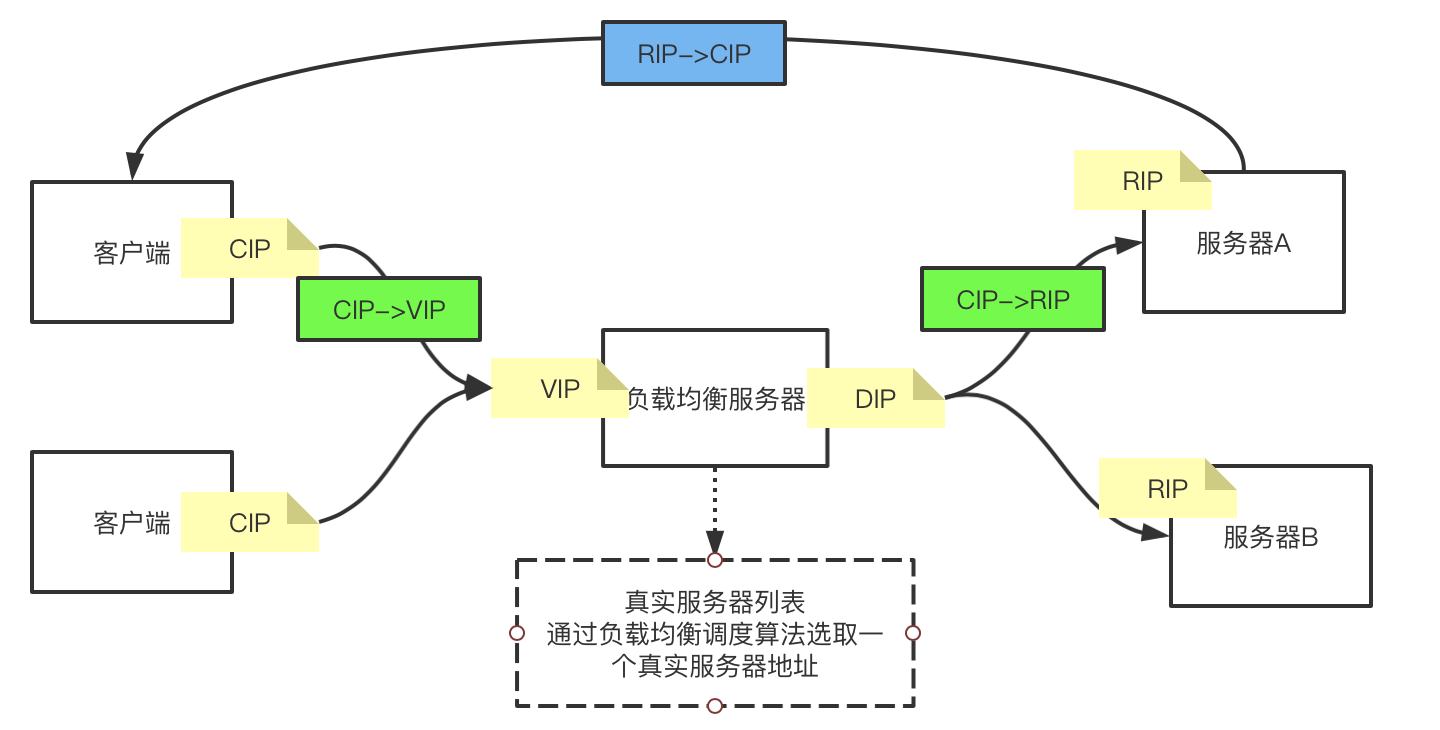
但是直接从服务器A返回的数据包是RIP->CIP时,CIP收到数据包后会直接丢弃,因为CIP并没有请求过RIP,请求的事VIP,现在返回一个RIP过来的包,CIP不会处理。要想让服务端直接将数据响应给客户端,要解决的问题就是要让数据包变成 VIP->CIP,这样客户端收到数据包后才会接收响应的数据包。根据tcp四元组信息:
xz:~ 乄 netstat -natp
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:3690 0.0.0.0:* LISTEN -
要想让返回的数据包是VIP->CIP的,那么就需要Local Address为VIP,也就是真实服务器本地需要有VIP这块网卡。而且因为真实服务器是镜像的,那么每一个真实服务器都需要有VIP的网卡。同时到达真实服务器的数据包也必须是CIP->VIP的数据包,这样服务器才会接收这个包。类似下图:
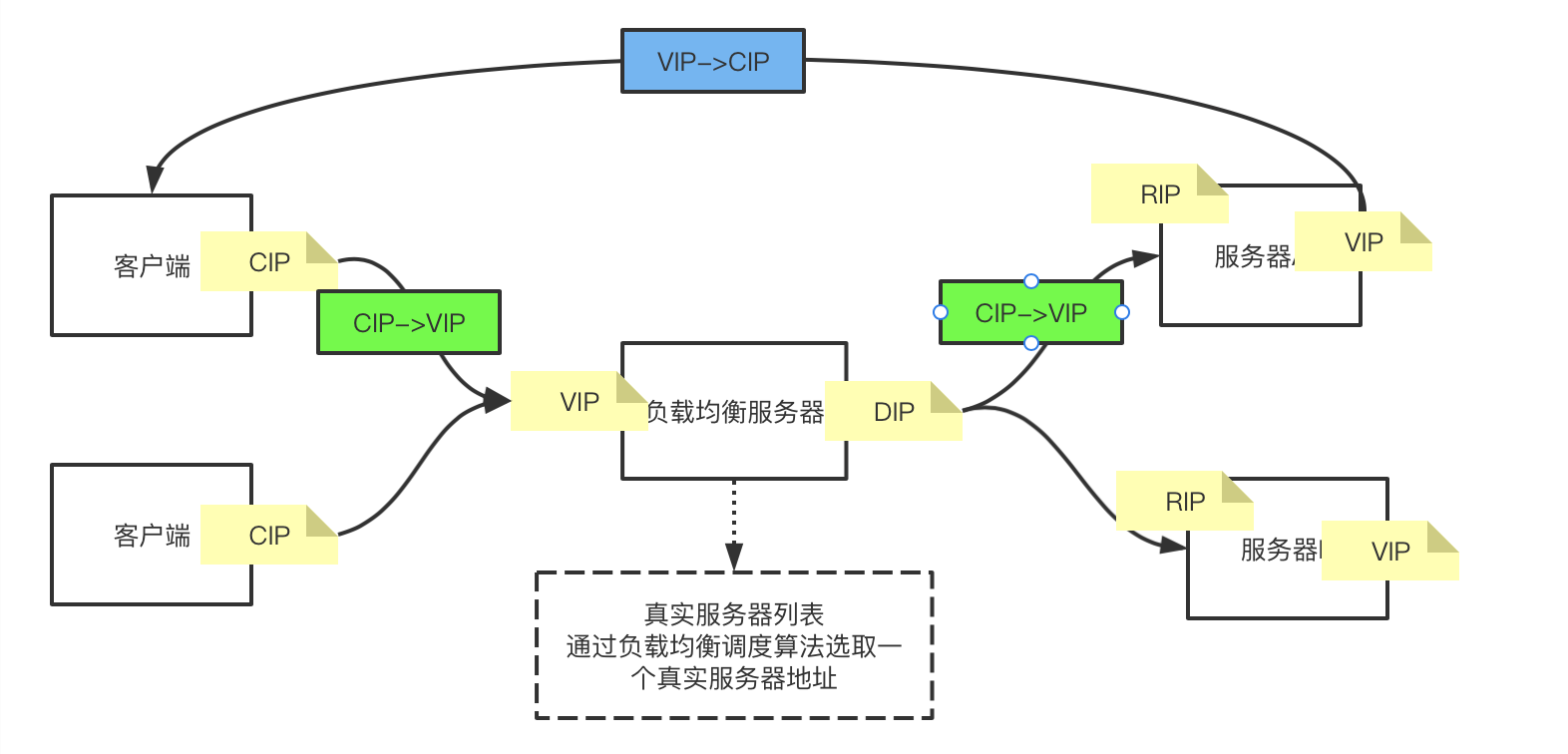
可以看到,此时有三个VIP,但是在同一个局域网中,ip不能重复,只能有一个VIP。
为了解决这个问题,我们现在假设有一种技术:可以使真实服务器的VIP对外隐藏,只对内可见,而负载均衡服务器的VIP是暴露在公网的,可以被外部访问的。
那么当客户端发送一个CIP->VIP的数据包时就一定能发送到负载均衡服务器,当发送到负载均衡服务器后,我们再假设我们可以使用另一种技术可以将数据包从负载均衡服务器转发到真实服务器,那么真实服务器一看数据包的目标地址是VIP,而自己有有一个VIP是对自己可见的,那么真实服务器就能够收下这个数据包,并组装一个VIP->CIP的响应数据包。那么就实现了数据包直接从真实服务器到客户端的过程,这个模型就是DR模型。为了实现这个模型,我们需要解决上面的两个问题:
-
VIP对外隐藏,对内可见。
执行ifconfig命令时,我们可以看到两块网卡信息:
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.16.120.48 netmask 255.255.240.0 broadcast 172.16.127.255 ether 00:16:3e:0a:e5:7c txqueuelen 1000 (Ethernet) RX packets 2651220798 bytes 593497377462 (552.7 GiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 2737692820 bytes 631812431526 (588.4 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 loop txqueuelen 1 (Local Loopback) RX packets 30102 bytes 4364929 (4.1 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 30102 bytes 4364929 (4.1 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0eth0: 物理网卡lo:虚拟网卡,linux内核通过程序模拟出的一块网卡。这块网卡就是对外隐藏对内可见的。每一块网卡上都可以有多个ip,我们可以通过在这块网卡上添加一个子ip为VIP,就可以实现VIP对外隐藏对内可见。
-
数据包到负载均衡服务器时,可以将数据包转发到真实服务器。
数据包的mac地址改为真实服务器的mac地址。
arp协议有两个配置:
- arp_ignore
- apr_
DR模型是使用最多的模型
TUN模型(隧道模型)
上面推导了DR模型,DR模型与net模型相比,优点是快,DR模型是基于二层网络协议的,而且数据包返回是直接返回给客户端的,不过负载均衡器。但是DR模型的缺点是,要保证所有的真实服务器与负载均衡服务器要是在同一个局域网内。
因为DR模型基于二层协议,也就是基于mac地址进行转发,二层arp协议只会加载同一局域网内的节点的mac地址。
同时也因为是同一局域网,那么就可能会有例如:机房停电/断网等风险。那么负载均衡器包括整个服务都是不可用的状态。那么为了解决这个问题,只需要保证真实服务器不在同一个地点就行了,但是这时DR模型就无法正常使用了。
基于上面的DR模型来说,主要的问题在于负载均衡器到真实服务器之间的数据包的传输,因此数据包到达真实服务器后直接返回CIP这一块是不需要改的,也就是说真实服务器仍是保证有一个VIP对外隐藏,对内可见。现在要解决的问题是,如何让数据包从负载均衡器到达真实服务器,只要数据包能到,那么就能建立连接。
我们假设现在有一种技术:在负载均衡器之间了真实服务器之间建立了一条隧道,当有一个数据包到达,一进门,就有一辆车拉着这个数据包直接拉到真实服务器,那么服务器就可以处理这个数据包了。这种隧道的模型就是TUN模型。TUN模型就是使用数据包背数据包的方式。
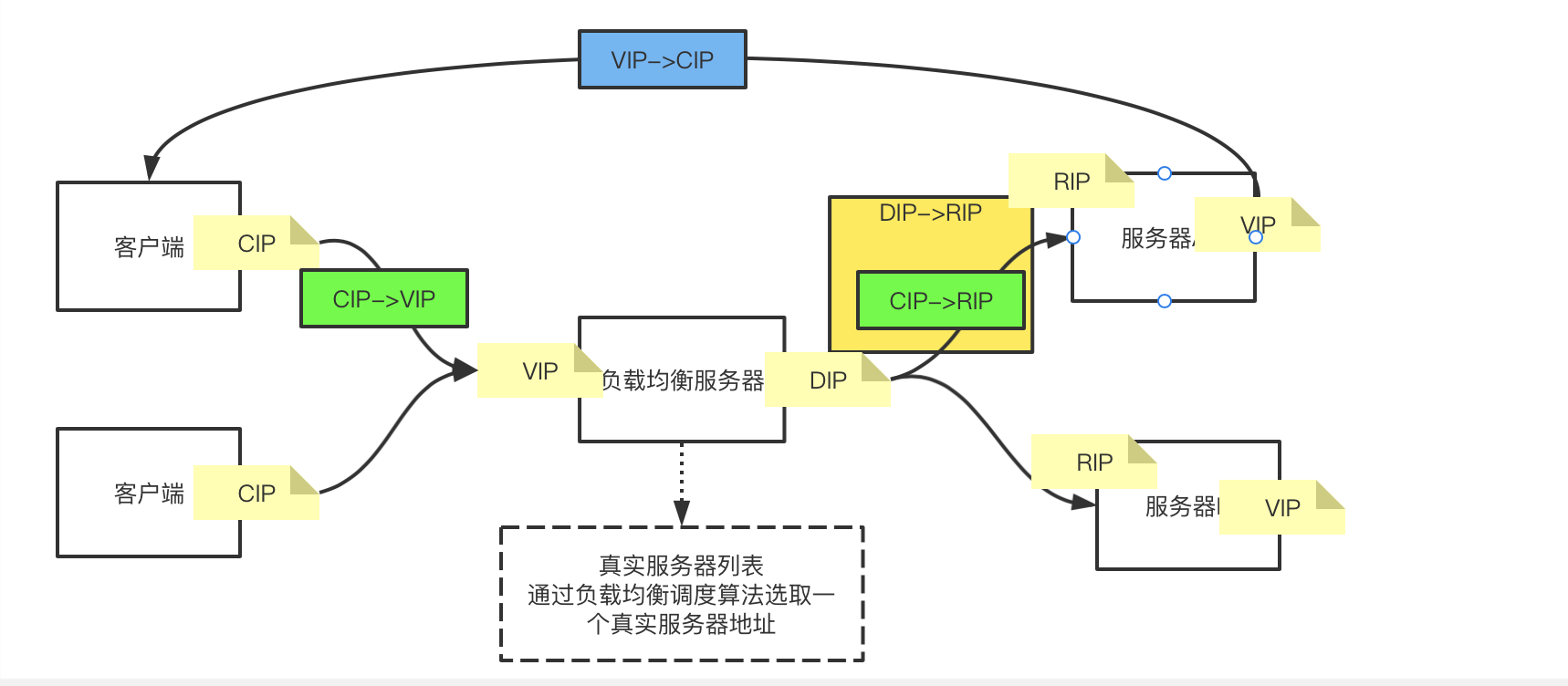
如上图:当数据包从CIP->VIP后,负载均衡器会生成一个DIP->RIP的数据包,这个数据包背着CIP->VIP的数据包,然后服务端接收数据包后,拆开拿到CIP->VIP的数据包。VPN就是使用的这种方式。
三、 ipvsadm
上面推导了三种模型的实现,下面就来实际搭建这三种模型,需要使用ipvsadm
yum -y install ipvsadm
安装后查看ipvsadm的参数,下面只列举主要参数,具体的详细参数说明可以自己搜索
[root@node01 ~]# ipvsadm -h
ipvsadm v1.27 2008/5/15 (compiled with popt and IPVS v1.2.1)
Usage:
ipvsadm -A|E -t|u|f service-address [-s scheduler] [-p [timeout]] [-M netmask] [--pe persistence_engine] [-b sched-flags]
ipvsadm -D -t|u|f service-address
ipvsadm -C
ipvsadm -R
ipvsadm -S [-n]
ipvsadm -a|e -t|u|f service-address -r server-address [options]
ipvsadm -d -t|u|f service-address -r server-address
ipvsadm -L|l [options]
ipvsadm -Z [-t|u|f service-address]
ipvsadm --set tcp tcpfin udp
ipvsadm --start-daemon state [--mcast-interface interface] [--syncid sid]
ipvsadm --stop-daemon state
ipvsadm -h
Commands:
Either long or short options are allowed.
--add-service -A add virtual service with options
--edit-service -E edit virtual service with options
--delete-service -D delete virtual service
--clear -C clear the whole table
--restore -R restore rules from stdin
--save -S save rules to stdout
--add-server -a add real server with options
--edit-server -e edit real server with options
--delete-server -d delete real server
--list -L|-l list the table
--zero -Z zero counters in a service or all services
--set tcp tcpfin udp set connection timeout values
--start-daemon start connection sync daemon
--stop-daemon stop connection sync daemon
--help -h display this help message
Options:
--tcp-service -t service-address service-address is host[:port]
--udp-service -u service-address service-address is host[:port]
--fwmark-service -f fwmark fwmark is an integer greater than zero
--ipv6 -6 fwmark entry uses IPv6
--scheduler -s scheduler one of rr|wrr|lc|wlc|lblc|lblcr|dh|sh|sed|nq,
the default scheduler is wlc.
--pe engine alternate persistence engine may be sip,
not set by default.
--persistent -p [timeout] persistent service
--netmask -M netmask persistent granularity mask
--real-server -r server-address server-address is host (and port)
--gatewaying -g gatewaying (direct routing) (default)
--ipip -i ipip encapsulation (tunneling)
--masquerading -m masquerading (NAT)
--weight -w weight capacity of real server
--u-threshold -x uthreshold upper threshold of connections
--l-threshold -y lthreshold lower threshold of connections
--mcast-interface interface multicast interface for connection sync
--syncid sid syncid for connection sync (default=255)
--connection -c output of current IPVS connections
--timeout output of timeout (tcp tcpfin udp)
--daemon output of daemon information
--stats output of statistics information
--rate output of rate information
--exact expand numbers (display exact values)
--thresholds output of thresholds information
--persistent-conn output of persistent connection info
--nosort disable sorting output of service/server entries
--sort does nothing, for backwards compatibility
--ops -o one-packet scheduling
--numeric -n numeric output of addresses and ports
--sched-flags -b flags scheduler flags (comma-separated)
挑几个主要的参数来解释(具体的参数值及解释可以在上面查找):
- A:表示添加一个负载均衡器VIP
- a: 表示添加一个真实服务器
- s: 负载均衡调度算法
- t:tcp服务
- r:真实服务器信息
- g:DR模型
- i: TUN模型
- m: NET模型
- w:添加权重
net 模型搭建
了解了上面的参数后,开始准备环境搭建模型:
-
三台虚拟机:node01, node02, node03(使用上面1.7验证环节搭建的节点)
-
node01 做负载均衡服务器,node02,node03做真实服务器,node02,node03的默认网关为node01
[root@node02 ~]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.218.128 0.0.0.0 UG 0 0 0 ens33 192.168.218.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33 -
准备一个server端程序,可以参考上面使用的server端代码,因为懒得搭建java环境,使用rust写了个服务端代码。
use std::borrow::{Borrow}; use std::io::{BufRead, BufReader, Write}; use std::net::{TcpListener, TcpStream}; use std::thread; fn main() { let listener = TcpListener::bind("192.168.218.129:9000").unwrap(); println!("服务端启动"); listener.incoming() .filter(|result| result.is_ok()) .map(|result| result.unwrap()) .for_each(|mut client| handle_client(client)); } fn handle_client(mut client: TcpStream) { thread::spawn(move || { let mut reader = BufReader::with_capacity(128, &client); let mut buf = String::new(); while reader.read_line(&mut buf).is_ok() { println!("{}", buf); write!(&client, "192.168.218.129:{}", buf); client.borrow().flush(); }; }); }在实际使用中,将响应数据中的ip地址替换为真实服务器的ip地址。分别验证功能:
-
node02
[root@node02 ~]# ll 总用量 3760 -rw-------. 1 root root 1226 8月 8 12:35 anaconda-ks.cfg -rwxr-xr-x. 1 root root 3844568 8月 28 23:52 rust-socket [root@node02 ~]# ./rust-socket 服务端启动成功另起一个链接
[root@node02 ~]# nc 192.168.218.129 9000 aaaa 192.168.218.129: aaaa -
node03
[root@node03 ~]# ./rust-socket 服务端启动成功另起一个链接
[root@node03 ~]# nc 192.168.218.130 9000 sjdhfjskdgkds 192.168.218.130: sjdhfjskdgkds
-
使用node01的192.168.0.104网卡作为对外公网暴露VIP,搭建net模型lvs。
[root@node01 ~]# ipvsadm -A -t 192.168.0.104:9000 -s rr
[root@node01 ~]# ipvsadm -a -t 192.168.0.104:9000 -r 192.168.218.129:9000 -m
[root@node01 ~]# ipvsadm -a -t 192.168.0.104:9000 -r 192.168.218.130:9000 -m
[root@node01 ~]# ipvsadm --list
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.104:cslistener rr
-> 192.168.218.129:cslistener Masq 1 0 0
-> 192.168.218.130:cslistener Masq 1 0 0
使用tcpdump监听VIP的9000端口:
[root@node01 ~]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.218.128 netmask 255.255.255.0 broadcast 192.168.218.255
inet6 fe80::3a0:bc16:b34a:94fb prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:fe:75:a7 txqueuelen 1000 (Ethernet)
RX packets 182198 bytes 258132375 (246.1 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 25792 bytes 23730883 (22.6 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens37: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.0.104 netmask 255.255.255.0 broadcast 192.168.0.255
inet6 fe80::44d1:b388:c54a:745e prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:fe:75:b1 txqueuelen 1000 (Ethernet)
RX packets 174188 bytes 25361441 (24.1 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 185588 bytes 340157047 (324.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 49 bytes 4199 (4.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 49 bytes 4199 (4.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@node01 ~]# tcpdump -nn -i ens37 port 9000
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens37, link-type EN10MB (Ethernet), capture size 262144 bytes
然后再启动两个窗口监听node02和node03的9000端口:
[root@node02 ~]# tcpdump -nn -i ens33 port 9000
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
//node03此处省略,同上
在node04(192.168.0.103)机器上访问服务端:
[root@node04 ~]# nc 192.168.0.104 9000
查看node01的tcpdump监听:
22:23:09.703868 IP 192.168.0.103.43718 > 192.168.218.129.9000: Flags [S], seq 2639448366, win 29200, options [mss 1460,sackOK,TS val 187489199 ecr 0,nop,wscale 7], length 0
22:23:09.704045 IP 192.168.218.129.9000 > 192.168.0.103.43718: Flags [S.], seq 4030848275, ack 2639448367, win 28960, options [mss 1460,sackOK,TS val 197237687 ecr 187489199,nop,wscale 7], length 0
22:23:09.704946 IP 192.168.0.103.43718 > 192.168.218.129.9000: Flags [.], ack 1, win 229, options [nop,nop,TS val 187489202 ecr 197237687], length 0
可以看到,103访问104的数据包经过node01后变成了访问node02的数据包(发生了net模式ip替换),然后拿到了响应包node02->103的包。
根据上面的数据包客户端端口,再监听客户端的端口,发送内容,可以看出客户端是将数据发送到104,拿到的数据包也是104响应的。再次证明了ip替换。
[root@node04 ~]# tcpdump -nn -i ens33 port 43728
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
22:36:21.236170 IP 192.168.0.103.43728 > 192.168.0.104.9000: Flags [P.], seq 2122576038:2122576056, ack 1751463562, win 229, options [nop,nop,TS val 188279983 ecr 198028101], length 18
22:36:21.237800 IP 192.168.0.104.9000 > 192.168.0.103.43728: Flags [P.], seq 1:17, ack 18, win 227, options [nop,nop,TS val 198071133 ecr 188279983], length 16
22:36:21.237880 IP 192.168.0.103.43728 > 192.168.0.104.9000: Flags [.], ack 17, win 229, options [nop,nop,TS val 188279985 ecr 198071133], length 0
22:36:21.238838 IP 192.168.0.104.9000 > 192.168.0.103.43728: Flags [P.], seq 17:76, ack 18, win 227, options [nop,nop,TS val 198071134 ecr 188279985], length 59
22:36:21.238867 IP 192.168.0.103.43728 > 192.168.0.104.9000: Flags [.], ack 76, win 229, options [nop,nop,TS val 188279986 ecr 198071134], length 0
发送内容:
[root@node04 ~]# nc 192.168.0.104 9000
sajklfjsalkfjklsajfas
192.168.218.129:sajklfjsalkfjklsajfas
^C
[root@node04 ~]# nc 192.168.0.104 9000
kasfsfkjsaljflsf
192.168.218.130:kasfsfkjsaljflsf
再次建立连接时就负载到了node03上,可以看出实现了负载均衡
可能遇到的问题:
如果客户端连接超时,tcpdump可以监听到发到服务端的数据包,也可以看到服务端的确认包,但是看不到第三次握手包,查看服务端默认网关是否为负载均衡服务器。
[root@node04 ~]# netstat -natp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 6824/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 6977/master
tcp 0 0 192.168.0.103:22 192.168.0.105:52459 ESTABLISHED 19832/sshd: root@pt
tcp 0 0 192.168.0.103:43728 192.168.0.104:9000 ESTABLISHED 20231/nc
tcp6 0 0 :::22 :::* LISTEN 6824/sshd
tcp6 0 0 ::1:25 :::* LISTEN 6977/master
=========================================
[root@node03 ~]# netstat -natp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 192.168.218.130:9000 0.0.0.0:* LISTEN 8992/./rust-socket
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 6812/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 6899/master
tcp 0 0 192.168.218.130:9000 192.168.0.103:43728 ESTABLISHED 8992/./rust-socket
tcp 0 0 192.168.218.130:22 192.168.218.128:58680 ESTABLISHED 8852/sshd: root@pts
tcp6 0 0 :::22 :::* LISTEN 6812/sshd
tcp6 0 0 ::1:25 :::* LISTEN 6899/master
net模型,从客户端看,客户端是与负载均衡服务器建立的连接,从服务端看,服务端与客户端建立的连接,但是因为服务端的默认网关是负载均衡服务器,所以回复包仍会经过负载均衡服务器。
dr模型搭建
上面搭建了net模型,下面搭建dr模型, 本次搭建使用的虚拟机是基于NET网络的(LVS对网络模式没有要求,上面的NET模型使用NET网络也可以搭建)
环境准备:
- node01: 192.168.226.128
- node02: 192.168.226.129
- node03: 192.168.226.130
node02-03 安装httpd yum -y install httpd
# 启动httpd
[root@node02 ~]# service httpd start
# 在httpd下创建静态页面,node03与此相同
[root@node02 ~]# cd /var/www/html/
[root@node02 html]# ls
[root@node02 html]# touch index.html
[root@node02 html]# echo "from 192.168.226.129" > index.html
验证静态页面可用
[root@node01 ~]# curl -X GET http://192.168.226.129:80/index.html
from 192.168.226.129
[root@node01 ~]# curl -X GET http://192.168.226.130:80/index.html
from 192.168.226.130
注意下面要配置DR模型一个重要配置
# node02和node03做相同配置
[root@node02 ~]# cd /proc/sys/net/ipv4/conf
[root@node02 conf]# ll
总用量 0
dr-xr-xr-x. 1 root root 0 9月 11 17:23 all
dr-xr-xr-x. 1 root root 0 9月 11 17:23 default
dr-xr-xr-x. 1 root root 0 9月 12 00:24 ens33
dr-xr-xr-x. 1 root root 0 9月 12 00:24 lo
[root@node02 conf]# cd ens33/
[root@node02 ens33]# echo 1 > arp_ignore
[root@node02 ens33]# echo 2 > arp_announce
[root@node02 ens33]# cd ..
[root@node02 conf]# cd all/
[root@node02 all]# echo 1 > arp_ignore
[root@node02 all]# echo 2 > arp_announce
关于这两个参数的作用,参考博客地址Linux内核参数之arp_ignore和arp_announce
然后就是开始搭建DR模型了
配置DR服务器VIP
[root@node01 ~]# ifconfig ens33:0 192.168.226.100/24
[root@node01 ~]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.226.128 netmask 255.255.255.0 broadcast 192.168.226.255
inet6 fe80::3a0:bc16:b34a:94fb prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:fe:75:a7 txqueuelen 1000 (Ethernet)
RX packets 5166 bytes 1122214 (1.0 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3891 bytes 457931 (447.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.226.100 netmask 255.255.255.0 broadcast 192.168.226.255
ether 00:0c:29:fe:75:a7 txqueuelen 1000 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# node01 做为LVS
[root@node01 ~]# ipvsadm -A -t 192.168.226.100:80 -s rr
[root@node01 ~]# ipvsadm -a -t 192.168.226.100:80 -r 192.168.226.129 -g
[root@node01 ~]# ipvsadm -a -t 192.168.226.100:80 -r 192.168.226.130 -g
[root@node01 ~]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.226.100:80 rr
-> 192.168.226.129:80 Route 1 0 0
-> 192.168.226.130:80 Route 1 0 0
配置真实服务器
# node02与node03配置相同
[root@node02 ~]# ifconfig lo:0 192.168.226.100 netmask 255.255.255.255
[root@node02 ~]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.226.129 netmask 255.255.255.0 broadcast 192.168.226.255
inet6 fe80::418b:5fb1:c921:125a prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:aa:05:73 txqueuelen 1000 (Ethernet)
RX packets 4209 bytes 394924 (385.6 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1654 bytes 247864 (242.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 72 bytes 6130 (5.9 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 72 bytes 6130 (5.9 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo:0: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 192.168.226.100 netmask 255.255.255.255
loop txqueuelen 1000 (Local Loopback)
测试DR模型
在浏览器输入http://192.168.226.100/index.html或者另起一台虚拟机使用curl测试,可以看到如下结果
[root@node04 ~]# curl -X GET http://192.168.226.100:80/index.html
from 192.168.226.130
[root@node04 ~]# curl -X GET http://192.168.226.100:80/index.html
from 192.168.226.129
[root@node04 ~]# curl -X GET http://192.168.226.100:80/index.html
from 192.168.226.130
[root@node04 ~]# curl -X GET http://192.168.226.100:80/index.html
from 192.168.226.129
使用netstat -natp查看连接信息
[root@node02 ~]# netstat -natp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 192.168.226.100:80 192.168.226.1:61662 SYN_RECV -
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 6822/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 6978/master
tcp 0 0 192.168.226.129:22 192.168.226.133:56330 ESTABLISHED 7374/sshd: root@pts
tcp6 0 0 :::80 :::* LISTEN 7310/httpd
tcp6 0 0 :::22 :::* LISTEN 6822/sshd
tcp6 0 0 ::1:25 :::* LISTEN 6978/master
可以看到是服务器直接与客户端建立的连接。
tun模型搭建
环境准备:
node01: 192.168.226.129/RS1node03: 192.168.226.130/RS2node04: 192.168.226.128/VS VIP: 10.10.1.100
添加隧道并开启
# 三台都做此配置
[root@node02 ~]# modprobe ipip
[root@node02 ~]# ip addr add 10.10.1.100/32 dev tunl0
[root@node02 ~]# ip link set up tunl0
[root@node02 ~]# ifconfig
...
tunl0: flags=193<UP,RUNNING,NOARP> mtu 1480
inet 10.10.1.100 netmask 255.255.255.255
tunnel txqueuelen 1000 (IPIP Tunnel)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
RS安装httpd:
[root@node01 ~]# curl -X GET http://192.168.226.129:80/index.html
from 192.168.226.129
[root@node01 ~]# curl -X GET http://192.168.226.130:80/index.html
from 192.168.226.130
修改真实服务器的rp_filter属性:
[root@node02 ~]# cd /proc/sys/net/ipv4/conf
[root@node02 conf]# echo 0 > default/rp_filter
[root@node03 conf]# echo 0 > all/rp_filter
[root@node03 conf]# echo 0 > ens33/rp_filter
[root@node03 conf]# echo 0 > lo/rp_filter
[root@node02 conf]# echo 0 > tunl0/rp_filter
搭建TUN模型
[root@node01 ~]# ipvsadm -C
[root@node01 ~]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
[root@node01 ~]# ipvsadm -A -t 10.10.1.100:80 -s rr
[root@node01 ~]# ipvsadm -a -t 10.10.1.100:80 -r 192.168.226.129:80 -i
[root@node01 ~]# ipvsadm -a -t 10.10.1.100:80 -r 192.168.226.130:80 -i
[root@node01 ~]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.10.1.100:80 rr
-> 192.168.226.129:80 Tunnel 1 0 0
-> 192.168.226.130:80 Tunnel 1 0 0
测试
[root@node04 ~]# curl -X GET http://10.10.1.100:80/index.html
from 192.168.226.129
[root@node04 ~]# curl -X GET http://10.10.1.100:80/index.html
from 192.168.226.130
四、keepalived
前面讲了LVS负载均衡,但是使用时会存在如下的问题:
- RS注册到LVS中,LVS并不知道服务是否可用,因此当RS下线时,LVS仍会继续向RS负载,造成部分用户服务不可用。
- LVS是单点的,挂掉时会造成整体服务下线
如何解决上面两个问题?
- RS会挂,那么就需要在LVS能够对RS做健康检查,当RS服务挂了的时候,从LVS中剔除挂掉的节点。当服务好了的时候再添加回去
- LVS会挂,单点故障。(使用主主、主备处理单点故障,主从模型可以用来缓解主节点压力,但是主仍是单点,需要对主做主备)
在LVS中,因为ip是不能重复的,只能有一个IP对外提供服务,因此使用可以使用主备模型解决单点问题。
上面的两个问题,我们都可以通过人力来手动的上下线,但是人力是最不靠谱的,因为人力无法及时处理,人需要休息... 因为种种的原因,我们一般都会使用程序来做这些事情。keepalived就是处理这些问题的一个程序。
如何保证高可用?
应用程序是通过ip端口对外提供服务的,因此无论一个应用服务内部有多少个服务,对外都是一个ip地址,同一个入口(因为ip地址是不允许重复的,因此当一个主机挂掉时,需要另一台来顶替工作,但是对用户端是透明的,用户端并不知道节点有没有挂,也不会知道你有几个节点,因此当主节点挂了时,备节点要拥有主节点的ip。而这个ip就是上面我们在LVS中学的VIP。)
keepalived 配置详解
安装keepalived
yum -y install keepalived
下载完成之后,查看keepalived的配置文件
[root@node01 ~]# cd /etc/keepalived/
[root@node01 keepalived]# cat keepalived.conf
配置文件内容如下:
! Configuration File for keepalived
global_defs { // 定义全局信息
...
router_id LVS_DEVEL
...
}
vrrp_instance VI_1 { //在这部分相当于配置对外VIP
state MASTER
interface eth0 //绑定到哪儿个网卡上
virtual_router_id 51
priority 100
advert_int 1
virtual_ipaddress { //虚拟ip地址 也就是配置对外VIP
192.168.200.16
}
}
virtual_server 192.168.200.100 443 { // ipvsadm -A xxxx 配置LVS服务器
delay_loop 6
lb_algo rr // -s 调度算法 rr轮询
lb_kind NAT // 负载均衡模型 NET/DR/TUN
persistence_timeout 50
protocol TCP // -t
real_server 192.168.201.100 443 { //配置真实服务器 RS ipvsadm -a -t xxx -r
weight 1 // RS权重
SSL_GET {
url {
path /
digest ff20ad2481f97b1754ef3e12ecd3a9cc
}
url {
path /mrtg/
digest 9b3a0c85a887a256d6939da88aabd8cd
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
...
从上面配置文件可以看出keepalived配置分为三个部分
-
global_defs: 全局信息定义,主要定义一些全局都会用到的变量,以及失败报警邮箱等。 -
vrrp_Instance:vrrp虚拟路由冗余协议,instance实例。定义一个实例名,一个节点可以定义多个路由协议。state: 此实例节点的状态(主机或是备机),取值MASTER/BACKUPinterface: 实例绑定的网卡名,VIP要绑定到哪儿块网卡virtual_route_id: 虚拟路由id,因为还会有一个备机,主备机通信通过这个id判断是否是同一个实例priority: 权重,通过配置此权重当主机宕机备机顶替,主机重启时重新变为MASTER,抢回VIP, 所以配置时,主机的权重要比备机大advert_int: 检查间隔。在使用主备时,主备节点之间是需要通信的,当主机一段时间内没有向备机告诉自己的健康状态,或者备机在一段时间内,与主机通信失败,那么就会认为主机已经宕机,就会自立为王,变成MASTER。virtual_ipaddress: 哪儿些VIP归这个实例
-
virtual_server: 定义VIP信息,上面virtual_ipaddress里只是写了VIP的地址,相当于记了个名,这里就是定义此VIP的详细信息-
delay_loop: 健康检查时间。主备机之间需要健康检查,同时LVS还需要检查RS实例的健康状态,当有RS挂掉时,需要剔除此负载,避免部分用户服务下线。 -
lb_algo: 负载调度算法rr|wrr|lc|wlc|lblc|lblcr|dh|sh|sed|nq -
lb_kind: 负载均衡转发模型NET|DR|TUN -
persistence_timeout: 会话保持时间。当一个用户请求到达服务器时,就会在服务器中缓存用户信息,那么下次如果负载到其他服务器就会在其他服务器也缓存用户信息,最终可能所有节点都有这个用户的信息。而这个配置就是让一段时间内的用户请求全都会负载到一台服务器,提高了空间利用率。 -
protocol:使用的协议 -
real_server: RS节点信息-
weight: 节点权重信息 -
SSL_GET|HTTP_GET: 根据使用的https|http协议,配置健康检查信息-
url: 健康检查路径url { path /index.html status_code 200 } -
connect_timeout: 连接超时时间 -
nb_get_retry: 重试次数 -
delay_before_retry: 重试间隔时间
-
-
-
上面大概写了常用的一些配置信息,如果使用时有的参数不确认,可以通过man 5 keepalived.conf查看配置文件帮助手册
其实可以发现上面的配置信息与配置ipvs时是非常像的,因此keepalived也是可以当作LVS使用的。
keepalived高可用搭建
环境准备:
- node01:192.168.226.128 keepalived Master
- node02:192.168.226.129 RS1 安装httpd
- node03:192.168.226.130 RS2 安装httpd
- node04:192.168.226.134 keepalived Backup
[root@node01 ~]# curl -X GET http://192.168.226.129:80/index.html
from 192.168.226.129
[root@node01 ~]# curl -X GET http://192.168.226.130:80/index.html
from 192.168.226.130
配置负载均衡为DR模型,因此需要更改node02,node03的arp配置,参考DR模型搭建。配置VIP为10.10.1.110。
配置keepalived
修改node01的配置文件,首先复制备份一下配置文件,然后修改配置文件信息:
vrrp_instance VI_1 {
state MASTER // 备机修改为BACKUP
interface ens33
virtual_router_id 51
priority 100 //备机修改权重小于这个值
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.10.1.100
}
}
virtual_server 10.10.1.100 80 {
delay_loop 6
lb_algo rr
lb_kind DR
persistence_timeout 0 //为了验证负载均衡测试,改为0,正常使用时不应该为0
protocol TCP
real_server 192.168.226.129 80 {
weight 1
HTTP_GET {
url {
path /index.html
status 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.226.130 80 {
weight 1
HTTP_GET {
url {
path /index.html
status 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
主备机都配置文件都准备好后,启动keepalived服务,启动服务后,可以直接通过ipvsadm查看配置信息:
[root@node01 keepalived]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.10.1.100:80 rr persistent 50
-> 192.168.226.129:80 Route 1 0 0
-> 192.168.226.130:80 Route 1 0 0
可以看到keepalived是可以做与ipvsadm一样的事情,可以配置ipvs服务。
测试服务:
当node03服务宕机时:
# node03
[root@node03 conf]# service httpd stop
Redirecting to /bin/systemctl stop httpd.service
[root@node03 conf]#
# node01
[root@node01 keepalived]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.10.1.100:80 rr persistent 50
-> 192.168.226.129:80 Route 1 0 0
可以看到当有服务宕机时,ipvsadm会自动剔除此负载,保证服务的可用性。当我们重新启动服务时,又会重新检测到服务健康,自动添加节点到ipvs。
# node03
[root@node03 conf]# service httpd start
Redirecting to /bin/systemctl start httpd.service
# node01
[root@node01 keepalived]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.10.1.100:80 rr persistent 50
-> 192.168.226.129:80 Route 1 0 0
-> 192.168.226.130:80 Route 1 0 0
这就解决了上面的第一个问题,RS挂掉时动态删除和添加RS节点。对RS做健康检查。而LVS单点故障是通过主备节点来解决的。当主节点挂掉时,VIP就会跳到备机上,保证服务的高可用。
但是主备的方式不可靠。当主节点和备机之间发生网络故障时,很容易出现两个VIP同时存在。

