

多线程与高并发(全)
多线程与高并发
一、了解多线程
什么是进程?
我们打开电脑上的qq时,点击qq.exe,电脑就会运行一个qq的程序,这个程序就叫做进程。
什么是线程?
当qq运行后, 我们可能会使用qq来打开多个聊天窗口进行聊天,那么每一个聊天窗口就算是一个线程。所以说,进程可以包括很多的线程。
线程和进程的区别?
进程是操作系统分配资源的最小单位,线程是CPU调度的最小单位。一个进程可以包括多个线程。
线程之间的执行是同时进行的,例如我们在qq聊天时,可以一边聊天,一边下载文件。此时下载文件和聊天这个两个操作就是两个线程。如果是一个线程的话,那么下载文件的过程中,我们就不能聊天了,只有等待文件下载完成之后我们才可以继续聊天,这就叫串形,而我们一边聊天一边下载就是并行。
说的再通俗一点:例如说我们现在想要打扫卫生,那么串形就是我自己一个人,就代表一个线程。我要先打扫卫生间,在打扫厨房,在打扫客厅,再打扫卧室.... 因为我一个人,所以只能按照顺序先后执行,这样的话,就会非常的耗时间。那么还有一种方式就是我找几个朋友或者找几个家政保洁一起打扫。这样的话每一个人就相当于一个线程,大家一块打扫,你打扫你的,我打扫我的,互相之间并没有关联。此时打扫卫生总耗时就是耗时最多的一个人的时间,比如客厅空间比较大,那么打扫完整个房间的总耗时就是打扫客厅的时间,这就是多线程与单线程的区别。单线程也叫串形,多线程也叫并行。
并发与并行的区别
- 并发:电脑cpu是按照时间片来执行任务的,因此当电脑上运行着多个任务时,可能A任务执行一会儿,B任务执行一会儿,但是因为CPU的任务切换时间非常短,ns(纳秒)级别,因此在我们眼中看来,就像是A任务和B任务是一块执行的,也就是说A和B是并发执行的。并发说的是在同一个时间段内,多个事情在这个时间段内交替执行。
- 并行:当电脑上有多个核时,每个核都可以执行任务,因此假设电脑有两个核心的话,那么A任务在核心1上执行,B任务在核心2上执行,此时A和B任务是一块运行的,可以称为A和B是并行运行的。并行说的是多个事情在同一个时刻发生。
并行是并发的一种,都表示任务同步运行,因此也可以称为并发,但是并发不能称为并行。
下面以图片来理解并发和并行:
一个咖啡机就代表一个cpu核,上面的图一个咖啡机,排了两个队,那么这两个队交替到咖啡机接咖啡,交替前进就是并发。而下面两个咖啡机,每个咖啡机前都有一个队伍,这两个队伍是一起执行的,这两个队伍就叫做并行。
并发偏重于多个任务交替执行,这多个任务之间可能是串形执行的,而并行是真正意义上的同时执行。
临界区
临界区用来表示一种公共资源或者数据,可以被多个线程使用,但每次只能有一个线程使用它,一旦临界区被占用,那么其他线程过来想要获取这个资源就只能等待。
就比如办公室里的打印机,打印机就是一个公共资源。办公室里的每一个人都可以连接打印机打印文件,那么每一个电脑与打印机的连接就可以看成是一个线程。当需要打印东西时,如果一个人正在打印,那么此时他就独占了打印机这个资源,此时另一个人也想要打印东西,那么他就只能等待前一个人打印东西完成后,他就释放这个资源了,后面的人才可以连接打印自己的东西,只要前一个人没有打印完,就是还在用这个打印机,那么后面过来的人都要排队等着。等待获取这个公共资源。
学习线程必须知道的概念:
-
阻塞:阻塞的意思就是说线程在等待一个结果,在拿到这个结果前就在这等待着,CPU空转等待拿到结果后再继续,这个等待的过程叫做阻塞。例如:我们现在要去商店买一个玩具,但是这个玩具老板需要到仓库中找,我们就要在门口等着老板找到货后才能付款离开。等待的这个过程就是阻塞。
-
锁:加锁就是控制共享资源的使用权。例如一个8车道的高速公路,也就是说可以允许8辆车同时跑,这8个车道就可以看成是八个线程,而收费站就可以看成是共享资源,如果只有一个收费站的话,那么每次都只有一个车道的车辆可以通过这个收费站,在这辆车进入收费站出站之前,这辆车对这个收费站就是独占的,此时是不允许下一辆车进入的,那么这种情况就可以看成是这辆车获取了收费站这把锁。
其实,线程获取cpu也可以看成是获取锁,在一个线程获取CPU执行的过程中,其他的线程是等待的,只有当前线程的时间片用完了,那么释放锁,其他线程抢占CPU也就是获取锁。
-
死锁:多个线程之间互相挣抢锁,互不相让的过程。以下图理解:
A、B、C、D四辆小车都在这种情况下都无法继续行驶了。他们彼此之间相互占用了其他车辆的车道,如果大家都不愿意释放自己的车道,那么这个状况将永远持续下去,谁都不可能通过,这就是死锁。
二、 线程的使用
创建线程的三种方式:
-
方式1: 继承 Thread
import java.util.concurrent.TimeUnit; /** * 通过继承方式创建线程 * * @author 赵帅 * @date 2021/1/1 */ public class CreateMyThreadByExtendThread extends Thread { @Override public void run() { try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("通过继承方式实现自定义线程,当前线程为:" + Thread.currentThread().getName()); } public static void main(String[] args) { // 当前线程为主线程 main System.out.println("Thread.currentThread().getName() = " + Thread.currentThread().getName()); // 创建一个新的线程并开启线程,打印新的线程名 CreateMyThreadByExtendThread thread = new CreateMyThreadByExtendThread(); thread.start(); } } -
方式2: 实现Runnable接口
import java.util.concurrent.TimeUnit; /** * 通过实现Runnable接口方式 * * @author 赵帅 * @date 2021/1/1 */ public class CreateMyThreadByImplRunnable implements Runnable { @Override public void run() { try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("通过实现Runnable接口方式实现自定义线程,当前线程为:" + Thread.currentThread().getName()); } public static void main(String[] args) { // 当前线程为主线程 main System.out.println("Thread.currentThread().getName() = " + Thread.currentThread().getName()); // 创建一个新的线程并开启线程,打印新的线程名 Thread thread = new Thread(new CreateMyThreadByImplRunnable()); thread.start(); } } -
方式3: Callable+Feature
import java.util.concurrent.*; /** * 通过实现Callable接口方式 * * @author 赵帅 * @date 2021/1/1 */ public class CreateMyThreadByImplCallable implements Callable<String> { @Override public String call() throws Exception { try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("通过实现Callable接口方式实现自定义线程,当前线程为:" + Thread.currentThread().getName()); return "hello"; } public static void main(String[] args) throws ExecutionException, InterruptedException { // 当前线程为主线程 main System.out.println("Thread.currentThread().getName() = " + Thread.currentThread().getName()); // callable接口实现的任务和Future接口或线程池一起使用 CreateMyThreadByImplCallable callable = new CreateMyThreadByImplCallable(); // 和Feature一起使用,Future表示未来,也就是说我执行这个任务,未来我去取任务执行的结果 FutureTask<String> task = new FutureTask<>(callable); new Thread(task).start(); System.out.println("main线程继续运行"); // 等其他线程执行完了,再来拿task的结果, System.out.println("task.get() = " + task.get()); // 使用线程池方式调用callable Future<String> submit = Executors.newSingleThreadExecutor().submit(callable); System.out.println("submit.get() = " + submit.get()); } }
三种方式的区别
通过上面三种创建线程的方式,我们对线程的使用有了基本的了解 ,下面我们来分析这三种方式有什么区别:
- 继承Thread: 通过继承方式创建线程,因为java单继承的特性,使用的限制就非常多了,使用不方便。
- 实现Runnable: 因为单继承的限制,所以出现了Runnable,接口可以多实现,因此大大提高了程序的灵活性。但是无论是继承Thread还是实现Runnable接口,线程执行的方法都是 void 返回值。
- 实现Callable: Callable接口就是为了解决线程没有返回值的问题,Callable接口有一个泛型类型,这个泛型就代表返回值的类型,使用Callable接口就可以开启一个线程取执行, Callable一般和Future接口同时使用,返回值为Future类型,可以通过Future接口的get方法拿执行结果。get()方法是一个阻塞的方法。
相同点:都是通过Thread类的start()方法来开启线程。
线程的方法
-
start(): 开启线程,使线程从新建进入就绪状态 -
sleep(): 睡眠,使当前线程休息, 需要指定睡眠时间,当执行sleep方法后进入阻塞状态, -
Join():加入线程,会将调用的线程加入当前线程。等待加入的线程执行完成后才会继续执行当前线程。/** * 线程方法示例 * @author 赵帅 * @date 2021/1/1 */ public class ThreadMethodDemo { public static void main(String[] args) throws InterruptedException { // 打印当前线程 main线程的线程名 main System.out.println("当前主线程线程名 = " + Thread.currentThread().getName()); // 创建一个新的线程 Thread thread = new Thread(() -> { // 线程进入睡眠状态 try { Thread.sleep(1000L); System.out.println("当前线程名:" + Thread.currentThread().getName()); } catch (InterruptedException e) { e.printStackTrace(); } }); // 开启线程 thread thread.start(); // thread.join(); System.out.println("主线程执行完毕"); } }打开和关闭注释thread.join()可以发现输出结果是不一样的,使用join后会等待thread执行结束后再继续执行main方法。
-
wait(): 当前线程进入等待状态,让出CPU给其他线程,自己进入等待队列,等待被唤醒。 -
notify(): 唤醒等待队列中的一个线程,唤醒后会重新进入就绪状态,准备抢夺CPU。 -
notifyAll(): 唤醒等待队列中的所有线程,抢夺CPU。 -
yield(): 让出CPU。当前线程让出CPU给其他的线程执行,但是自己也会进入就绪状态参与CPU的抢夺,因此调用yield方法后,仍然可能继续获得CPU。import java.util.concurrent.TimeUnit; /** * 线程方法示例 * @author 赵帅 * @date 2021/1/1 */ public class ThreadMethodDemo { public static void main(String[] args) throws InterruptedException { // 打印当前线程 main线程的线程名 main System.out.println("当前主线程线程名 = " + Thread.currentThread().getName()); Object obj = new Object(); // 创建一个新的线程 Thread thread = new Thread(() -> { // 线程进入睡眠状态 try { synchronized (obj) { obj.wait(); System.out.println("当前线程名:" + Thread.currentThread().getName()); } } catch (InterruptedException e) { e.printStackTrace(); } }); // 开启线程 thread thread.start(); System.out.println("主线程执行完毕"); // 等待thread进入等待状态释放锁,否则会产生死锁 TimeUnit.SECONDS.sleep(6); synchronized (obj) { obj.notify(); } } }
注意:wait和notify只能在synchronized同步代码块中调用,否则会抛异常。
- Interrupt(): 中断线程,调用此方法后,会将线程的中断标志设置为true。
线程的状态
一个完整的线程的生命周期应该包含以下几个方面:
- 新建(New):创建了一个线程,但是还没有调用start方法
- 就绪(Runnable):调用了start()方法,线程准备获取CPU运行
- 运行(Running):线程获取CPU成功,正在运行
- 等待(Waiting):等待状态,和TimeWaiting一样都是等待状态, 不同的是Waiting是没有时间限制的等,而TimeWaiting会进入一个有时间限制的等。例如调用wait()方法后就会进入一个无限制的等,等待调用notify唤醒,而调用sleep( time)就会进入一个有时间限制的等。等待结束后(被唤醒或sleep时间到期)后就会重新进入就绪队列,等待获取CPU继续向下执行。
- 阻塞(Blocked):多个线程再等待临界区资源时,进入阻塞状态。
- 销毁(Teminated): 线程执行完毕,进入销毁状态,这个状态是不可逆的,是最终状态,当进入这个状态时,就代表线程执行结束了。
以一张图来理解这几个状态:

简单介绍一个线程的生命周期:
当我们使用 new Thread()创建一个线程时,那么这个线程就处于创建状态;当我们调用start()方法后,此时线程就处于就绪状态(进入就绪状态后就不可能再进入创建状态了),但是调用start()方法后并不是说立马就会被CPU执行,而是会参与CPU的抢夺,当这个线程拿到CPU后,就会被执行。那么拿到CPU后就进入了运行状态。当调用了sleep或wait方法后,线程就进入了等待状态, 当等待状态被唤醒后,就会重新进入就绪队列等待获取CPU,当访问同步资源时或其他阻塞式操作时就会进入阻塞状态,阻塞状态结束重新进入就绪状态获取CPU。当线程运行完成后进入Teminate状态后,就代表线程执行结束了。
sleep操作不释放锁,wait操作释放锁。
三、Synchronized
synchronized 是java中的关键字,通过synchronized加锁保证多线程情况下临界区资源的安全访问。那么synchronized是如何实现的?
JMM模型
要了解synchronized的底层原理,首先需要了解java的内存模型。JMM内存模型是围绕线程的可见性、原子性、有序性建立的。java的内存模型分为堆内存和线程内存,也就是说java会对每一个线程都分配一块内存空间,线程内存主要存放堆栈信息和临时变量等。当创建一个对象时,如果用到了主内存中的变量,那么会将这个变量拷贝一份副本,在这个线程中对这个变量的所有操作,都是对这个副本操作的。以下面这个程序来证明这一点。
import java.util.concurrent.TimeUnit;
/**
* 证明JMM模型中,线程对共享资源的操作,操作的是副本。
* @author 赵帅
* @date 2021/1/4
*/
public class JMMTest {
/**
* 线程是否继续循环
*/
private static volatile boolean running = true;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
while (running) {
}
}, "thread-0").start();
TimeUnit.SECONDS.sleep(1);
running = false;
System.out.println("main线程结束");
}
}
在上面这个程序中,我们定义了一个变量running,标记是否继续循环,在main方法中开启了一个线程,如果running=false时就会结束循环,结束这个线程。然后我们在main线程中将这个running更改为false。运行后发现线程并不会终止。说明在main线程中更改running的值后,thread-0线程中的running的值仍为true。这也就证明了main线程和thread-0线程的running变量并不是同一个变量。
总结一下上面的内容:
- 变量的定义都在主内存中。
- 每一个线程都有自己的工作内存,保存该线程使用到的变量的副本。
- 线程对共享变量的所有操作都在自己的工作内存中,不能直接操作主内存。
- 不同的线程之间不能访问其他线程工作内存中的变量,变量值的传递需要通过主内存来进行。
我们如何让main线程中的变量值修改后,thread-0就知道了呢?
对running变量添加volatile关键字修饰:private static volatile boolean running = true;
此时线程就能正常结束了。
volatile
volatile关键字有两个作用:
-
保证线程可见性: 通过缓存一致性协议实现。上面在running变量上添加volatile就是使用的保证线程可见性这个特性。当在变量上添加volatile之后,那么如果这个变量的值发生更改,就会将这个内存副本中变量的值,同步到主内存中去,主内存中的值发生更改,然后主内存将更改后的变量同步到其他的线程。这样就实现的线程间变量的可见性。
-
禁止指令重排序:通过内存屏障load-store实现。
指令重排序:一个类文件在编译后会转换成CPU能够识别的指令,CPU的速度很快,为了提升效率,会执行多条指令,CPU会对这多条指令进行优化。例如:
int a = 1; int b = 2;变量a和变量b在定义上没有依赖关系,那么CPU在执行时可能会先执行b=2,再执行a=1。这都是CPU为了提升效率做的优化。当然发生重排序的概率非常小。但是这种情况是存在的。
经典问题:DCL单例是否需要添加volatile?
什么是DCL单例?
Double check lock 双重检查锁。
/** * @author 赵帅 * @date 2021/1/5 */ public class DCLDemo { private static volatile DCLDemo INSTANCE; private String name = "hello"; private DCLDemo(){} public static DCLDemo getInstance(){ if (INSTANCE == null) { synchronized (DCLDemo.class) { if (INSTANCE == null) { INSTANCE = new DCLDemo(); } } } return INSTANCE; } }上面代码就是DCL单例模式。那么INSTANCE要不要加volatile?
首先我们来了解对象的创建过程:
Object obj = new Object();创建这个对象会经历:
- 为这个对象开辟一个内存区域
- 复制对象引用
- 利用对象引用调用构造方法
- 将引用赋值给obj。
那么如果发生指令重排序,即3、4两条指令的顺序变了。先将引用指向了对象,此时还没有执行第3条指令,即对象的构造方法还没有被执行,此时如果第二个线程调用了这个方法,那么在第一个判断,
if(INSTANCE == null)判断结果为false,那么直接就返回了这个对象,这个对象是有问题的,就会出异常。所以DCL单例需要添加volatile。
volatile是如何实现禁止指令重排序的?
volatile内存屏障针对不同的操作系统会有不同的实现。只要是在每一个指令的前后添加内存屏障,前一条指令执行完才能执行后一条指令。主要通过lfence,sfence,mfence实现。在jvm层级的实现为:
loadload、loadstore、storeload、storestore。
更多的关于JMM内存模型会在后面的jvm中详细描述。
synchronized
在学习synchroinzed前,我们首先需要了解什么是线程安全性?
当多个线程操作共享资源时,如果最终的结果与我们预想的一致,那么就是线程安全的,否则就是线程不安全的。
看下面代码:
/**
* @author 赵帅
* @date 2021/1/6
*/
public class ThreadDemo {
private int num = 0;
public void fun() {
for (int i = 0; i < 1000; i++) {
num++;
}
}
public static void main(String[] args) throws InterruptedException {
ThreadDemo demo = new ThreadDemo();
for (int i = 0; i < 10; i++) {
new Thread(demo::fun).start();
}
TimeUnit.SECONDS.sleep(5);
System.out.println("demo.num = " + demo.num);
}
}
我们定义了一个num值为0;在fun方法中我们对这个num自增1000次;在main方法中我们启动了十个线程来调用这个方法,那么最终num的值应该是10*1000=10000。期望值是10000,但是执行方法后,无论执行几次最终的结果都不是期望值,因此这个类是线程不安全的。
总结造成线程安全问题的主要原因:
- 存在共享资源。
- 存在多个线程同时操作共享资源。
上面的问题如何解决?
为了解决这个问题,我们需要保证在一个线程操作共享数据时,其他的线程不能操作这个数据。也就是保证同一时刻有且只有一个线程可以操作共享数据,其他线程必须等待这个线程处理完后再进行,这中方式叫做互斥锁。synchroinzed关键字可以实现这个操作。synchronized可以保证在同一时刻只有一个线程执行某个方法或某个代码块。
synchronized的使用
使用synchronzed解决上面的问题:
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2021/1/6
*/
public class ThreadDemo {
private int num = 0;
private final Object lock = new Object();
public void fun() {
synchronized (lock) {
for (int i = 0; i < 1000; i++) {
num++;
}
}
}
public static void main(String[] args) throws InterruptedException {
ThreadDemo demo = new ThreadDemo();
for (int i = 0; i < 10; i++) {
new Thread(demo::fun).start();
}
TimeUnit.SECONDS.sleep(5);
System.out.println("demo.num = " + demo.num);
}
}
运行结果与期望值一致。synchronized在使用时必须锁定一个对象,可以像上面代码一样自己定义锁的对象,也可以使用如下方式:
/**
* @author 赵帅
* @date 2021/1/7
*/
public class SynchronizedDemo {
/**
* 加锁锁定的对象
*/
private final Object lock = new Object();
private static final Object STATIC_LOCK = new Object();
/**
* 方式1: 使用this关键字,锁定当前对象
*/
public void fun1() {
synchronized (this) {
// do something
}
synchronized (lock) {
// do something
}
}
/**
* 方式2:锁定方法
* 在方法上加锁,这种方式与上面一样,都是锁定的当前对象
*/
public synchronized void fun2(){}
/**
* 方式3:静态方法内加锁
* 静态方法时无法使用this,只能锁定static修饰的对象,或者使用 类对象。
* Synchronized.class 是Class对象
*/
public static void fun3() {
synchronized (SynchronizedDemo.class) {
// do something
}
synchronized (STATIC_LOCK) {
// do something
}
}
/**
* 方式4:锁定静态方法
* 锁定静态方法时,与上面方式一样,锁定的是当前类对象
*/
public static synchronized void fun4() {}
}
多个线程必须竞争同一把锁,也就是说锁对象必须相同,下面这种方式是错误的:
public void fun1() {
final Object lock = new Object();
synchronized (lock) {
// do something
}
}
每个线程进来后都会创建一个新的锁对象,线程之间不存在锁竞争,那么锁就失去了作用,因此必须保证锁定同一个对象,多个线程竞争同一把锁。
synchronized锁定的对象不能是基本类型和String类型
使用如下代码做解释:
package com.xiazhi.thread;
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2021/1/7
*/
public class SynchronizedDemo2 {
public Integer lock = 1;
public void fun1() {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + "得到锁");
try {
// 模拟执行业务代码耗时1秒
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "释放锁");
}
}
public static void main(String[] args) {
SynchronizedDemo2 demo = new SynchronizedDemo2();
for (int i = 0; i < 10; i++) {
new Thread(demo::fun1).start();
// demo.lock++; //1
}
}
}
上面代码中定义了一个Integer类型的锁,并启动了十个线程,来调用fun1方法。我们期待的输出是这样的。
Thread-0得到锁
Thread-0释放锁
Thread-9得到锁
Thread-9释放锁
Thread-8得到锁
Thread-8释放锁
Thread-7得到锁
Thread-7释放锁
Thread-6得到锁
Thread-6释放锁
Thread-5得到锁
Thread-5释放锁
Thread-4得到锁
Thread-4释放锁
Thread-3得到锁
Thread-3释放锁
Thread-2得到锁
Thread-2释放锁
Thread-1得到锁
Thread-1释放锁
线程之间因为竞争同一把锁有序执行,此时程序是可以正常运行的。但是一旦我们打开 demo.lock++这个注释,那么程序的结果就会变成这样:
Thread-0得到锁
Thread-2得到锁
Thread-1得到锁
Thread-3得到锁
Thread-4得到锁
Thread-6得到锁
Thread-7得到锁
Thread-8得到锁
Thread-9得到锁
Thread-1释放锁
Thread-4释放锁
Thread-6释放锁
Thread-0释放锁
Thread-5得到锁
Thread-2释放锁
Thread-3释放锁
Thread-7释放锁
Thread-8释放锁
Thread-9释放锁
Thread-5释放锁
每一个线程都能拿到锁,这说明线程之间并不是在竞争同一把锁了。这是因为demo.lock++实际上执行的是`demo.lock = new Integer(demo.lock+1)。可以看到,创建了一个新的对象。我们打印一下锁对象的内存地址:
package com.xiazhi.thread;
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2021/1/7
*/
public class SynchronizedDemo2 {
public Integer lock = 1;
public void fun1() {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + "得到锁");
// 打印当前锁对象的内存地址
System.out.println("当前锁对象:" + System.identityHashCode(lock));
try {
// 模拟执行业务代码耗时1秒
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "释放锁");
}
}
public static void main(String[] args) {
SynchronizedDemo2 demo = new SynchronizedDemo2();
for (int i = 0; i < 10; i++) {
new Thread(demo::fun1).start();
demo.lock++;
}
}
}
查看运行结果:
Thread-1得到锁
Thread-2得到锁
当前锁对象:245887817
Thread-0得到锁
当前锁对象:1443225064
当前锁对象:245887817
Thread-3得到锁
当前锁对象:1443225064
Thread-4得到锁
当前锁对象:1468479040
Thread-5得到锁
当前锁对象:774263507
Thread-6得到锁
当前锁对象:1022687942
Thread-7得到锁
当前锁对象:166950465
Thread-8得到锁
当前锁对象:1694292106
Thread-9得到锁
当前锁对象:1694292106
Thread-2释放锁
Thread-0释放锁
Thread-4释放锁
Thread-3释放锁
Thread-1释放锁
Thread-6释放锁
Thread-5释放锁
Thread-8释放锁
Thread-7释放锁
Thread-9释放锁
可以很明显的看到锁的对象一直在变化,而我们加锁的目的就是为了保证多个线程竞争同一把锁,现在是在竞争多把锁。线程之间就不存在竞争关系,都可以得到锁。所以不能使用Integer,其他的基本类型包装类型也是跟这个一样。所以说锁对象不能是基本类型包装类型。
如果只是因为i++这个原因的话,或许我们会想如果用final修饰为不可变对象不就可以了么。例如下面这样:
public final Integer lock = 1;
这样的话,就保证了lock对象是不可变的。这样是不是就可以了?
仍然不行。因为再Integer类内部维护着一个缓存池,缓存-128~127之间的值。
/**
* @author 赵帅
* @date 2021/1/9
*/
public class IntegerTest {
public static void main(String[] args) {
Integer var1 = 127;
Integer var2 = 127;
System.out.println(var1 == var2);// true
Integer var3 = 128;
Integer var4 = 128;
System.out.println(var3 == var4);// false
}
}
可以看到如果Integer的值在 -128~127之间的话,无论创建多少次,实际上使用的都会是一个对象。那么再使用中就会造成如下问题:
我们首先来看不使用Integer做锁的时候, 程序的运行结果:
package com.xiazhi.thread;
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2021/1/9
*/
public class SynchronizedDemo3 {
static class A{
private final Object lock = new Object();
public void fun1() {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + "获取锁");
// do something
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "释放锁");
}
}
}
static class B{
private final Object lock = new Object();
public void fun1() {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + "获取锁");
// do something
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "释放锁");
}
}
}
public static void main(String[] args) {
A a = new A();
B b = new B();
for (int i = 0; i < 5; i++) {
new Thread(a::fun1, "Class A" + i).start();
new Thread(b::fun1, "Class B" + i).start();
}
}
}
此时程序的运行结果是这样的:
Class A0获取锁
Class B0获取锁
Class A0释放锁
Class A4获取锁
Class B0释放锁
Class B4获取锁
Class A4释放锁
Class B4释放锁
Class A3获取锁
Class B3获取锁
Class A3释放锁
Class B3释放锁
Class A2获取锁
Class B2获取锁
Class A2释放锁
Class B2释放锁
Class A1获取锁
Class B1获取锁
Class A1释放锁
Class B1释放锁
可以看到,ClassA的和ClassB之间是没有锁竞争的,类A的lock和类B的lock是两把锁,这样的话,这也类关联的线程其实是两个并行的线程。A和B之间互不影响。但是如果我们将类A和类B的锁对象修改:
package com.xiazhi.thread;
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2021/1/9
*/
public class SynchronizedDemo3 {
static class A{
private final Integer lock = 1;
public void fun1() {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + "获取锁");
// do something
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "释放锁");
}
}
}
static class B{
private final Integer lock = 1;
public void fun1() {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + "获取锁");
// do something
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "释放锁");
}
}
}
public static void main(String[] args) {
A a = new A();
B b = new B();
for (int i = 0; i < 5; i++) {
new Thread(a::fun1, "Class A" + i).start();
new Thread(b::fun1, "Class B" + i).start();
}
}
}
此时再次运行程序,会发现A和B之间变成串形了,因为A和B都是用了Integer做锁,而且值一样,就变成了一把锁了。
通过上面的分析,我们知道了为什么不允许使用基本包装类型来做锁对象。那么为什么也不允许String呢?
原因与Integer缓存池一样,String创建的对象会进入常量池缓存。
synchronized保证了可见性、原子性、有序性
上面我们在讲volatile的可见性时的代码,如果我们讲代码这样更改:
import java.util.concurrent.TimeUnit;
/**
* 证明JMM模型中,线程对共享资源的操作,操作的是副本。
* @author 赵帅
* @date 2021/1/4
*/
public class JMMTest {
/**
* 线程是否继续循环
*/
private static boolean running = true; //0
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
while (running) {
System.out.println("hello"); //1
}
}, "thread-0").start();
TimeUnit.SECONDS.sleep(1);
running = false;
System.out.println("main线程结束");
}
}
我们在1处添加代码,发现0处即使没有添加volatile,代码也是能正常结束的。为什么?
查看 System.out.println的源码:
public void println(String x) {
synchronized (this) {
print(x);
newLine();
}
}
发现使用了synchronized。synchronized是保证了可见性、原子性和有序性。
synchroinzed是如何保证可见性的?
synchronized获得锁之后会执行以下内容:
- 清空工作内存中共享变量的值
- 从主内存重新拷贝需要使用的共享变量的值
- 执行代码
- 将共享变量的最新值刷新到主内存数据
- 释放锁
从上面步骤可以看出,synchroinzed保证了线程可见性。
synchronized是如何保证原子性的?
什么是原子性?
原子性是指操作是不可分的,要么全部一起执行,要么都不执行。
synchronized如何保证原子性
查看synchronized的字节码原语,synchronized是通过monitorenter和monitorexit两个命令来操作的。线程1在执行monitorenter指令的时候,会对Monitor进行加锁,加锁后其他线程无法获得锁,除非线程1主动释放锁。即使在执行过程中,由于时间片用完,线程1放弃cpu,但是它并没有解锁,由于synchronized是可重入的,下一个时间片还是只能被他自己获取到,还是会继续执行代码,直到所有代码执行完,这就保证了原子性。
synchronized是可重入锁,什么是可重入锁?
查看下面一段代码:
package com.xiazhi.thread; /** * @author 赵帅 * @date 2021/1/9 */ public class SynchronizedDemo4 { public synchronized void fun1() { fun2(); } public synchronized void fun2() { // do something } public static void main(String[] args) { SynchronizedDemo4 demo = new SynchronizedDemo4(); demo.fun1(); } }方法fun1和fun2都被synchronized修饰了,也就是说这两个方法都需要获得锁才可以执行,但是在fun1中调用了fun2方法,程序进入fun1时说明已经获得到this的锁了,之前我们说了,当锁被占用时,其他线程只有等待当前线程释放锁才可以拿到锁,但是现在线程已经拿到锁了,那么再次调用fun2是否能够调用成功?如果可以调用成功就说明这是个可重入锁。也就是说可重入锁就是指一个线程是否可以重复多次获得锁。
synchronized保证有序性
有序性是指程序执行的顺序按照代码的先后顺序执行。在并发时,程序的执行可能会出现乱序。给人的直观感觉就是:写在前面的代码,会在后面执行。但是synchronized提供了有序性保证,这其实和as-if-serial语义有关。
as-if-serial语义是指不管怎么重排序(编译器和处理器为了提高并行度),单线程程序的执行结果都不能被改变。编译器和处理器无论如何优化,都必须遵守as-if-serial语义。只要编译器和处理器都遵守了这个语义,那么就可以认为单线程程序是按照顺序执行的,由于synchronized修饰的代码,同一时间只能被同一线程访问。那么可以认为是单线程执行的。所以可以保证其有序性。
synchronized锁升级过程
synchronized在jdk早期是重量级锁。
什么是重量级锁?
要解释重量级锁和轻量级锁的概念首先需要理解用户态和内核态的。
一个对象的内容
在java中,一个对象的内容主要分为以下几个部分:
| 类型 | jvm 32位长度 | jvm64位长度 |
|---|---|---|
| markword | 64位,8字节 | 64位,8字节 |
| class类指针长度 | 32位 | 64位,开启类指针压缩后为32位,默认开启 |
| 属性长度 | 32位 | 64位,开启属性指针压缩后为32位,默认开启 |
| 补齐 | - | - |
java内存地址按照8字节对齐,因此当对象的长度不足8的倍数是,会补齐到8的倍数。例如:
Object obj = new Object();
obj对象的大小 = markword(8字节)+Object类指针长度(8字节)+属性指针长度(object无属性,0字节)==16字节,16为8的倍数,所以不需要补齐。
当开启类指针压缩时:
obj对象的大小 = markword(8字节)+Object类指针长度(4字节,开启指针压缩)+属性指针长度(object无属性,0字节)==12字节。12不是8的倍数,所以补齐4个字节,最后类大小仍为16字节。
markword
我们之前说synchronized必须锁定一个对象,那么多个线程如何判断这个对象是否已经被占用了呢?当锁定这个对象时,会对这个对象添加一个标记,标记这个对象是否加锁。这个标记就放在markword中。
锁升级
因为早期的synchronized太重,每次都要调用内核态进行操作,效率太低了,因此为了提升效率,在后来的版本中对synchronized进行了优化,添加了锁升级的过程,锁升级过程中锁的状态就记录在锁对象的markword中。整个锁升级过程如下:
- 无锁态:对象刚创建,还没有线程进来加锁。
- 偏向锁:第一个线程进来后,升级为偏向锁。
- 轻量级锁(自旋锁):当多个线程竞争这把锁时,升级为自旋锁。
- 重量级锁:当线程自旋超过10次或等待线程数超过10,升级为重量级锁。
锁升级过程与markword中内容对应关系如下:
| 锁状态 | 25bit | 4bit | 1bit | 2bit | |
|---|---|---|---|---|---|
| 23bit | 2bit | 是否偏向锁 | 锁标志位 | ||
| 无锁态 | 对象的hashcode | 分代年龄 | 0 | 01 | |
| 偏向锁 | 线程ID | epoch | 分代年龄 | 1 | 01 |
| 轻量级锁 | 指向栈中锁记录的指针 | 00 | |||
| 重量级锁 | 指向重量级锁的指针 | 10 | |||
| GC标记 | 空 | 11 | |||
思考一个问题:i++是否是原子性的?
分析i++的操作过程:
- 内存读取数据写到寄存器
- 寄存器进行自增操作
- 寄存器将值写回内存
经过上面分析可以知道,i++不是原子性的。那么如何使用多线程进行i++操作保证原子性?
上一节学习了synchronized可以保证原子性,因此我们可以使用synchronized实现:
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2021/1/13
*/
public class SynchronizedIncrementDemo {
private Integer num = 0;
public void fun1() {
synchronized (this) {
for (int i = 0; i < 1000; i++) {
num++;
}
}
}
public static void main(String[] args) throws InterruptedException {
SynchronizedIncrementDemo demo = new SynchronizedIncrementDemo();
for (int i = 0; i < 10; i++) {
new Thread(demo::fun1).start();
}
TimeUnit.SECONDS.sleep(1);
System.out.println(demo.num);
}
}
synchronized是通过加锁的方式保证原子性的。其实在操作系统底层是有CAS原语来保证原子性的。
AtomicInteger
AtomicInteger就是通过CAS实现的,上面代码用AtomicInteger实现为:
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author 赵帅
* @date 2021/1/13
*/
public class AtomicIncrementDemo {
private static AtomicInteger num = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
new Thread(()->{
for (int j = 0; j < 1000; j++) {
num.getAndIncrement();
}
}).start();
}
TimeUnit.SECONDS.sleep(1);
System.out.println("num = " + num);
}
}
什么是CAS
compare and swap比较并交换
在使用synchronized保证原子性时,是多个线程竞争同一把锁,同一时刻只有一个线程执行代码,以此保证原子性,但是当加上synchronized时就相当于多线程串形执行了,效率可能会变低(synchronized经过锁升级后,效率提高很多,并不一定比CAS低)。除了synchronized可以保证原子性,在cpu级别有compxchg指令,这个指令也可以保证原子性。
执行 compxchg指令的时候,会判读当前系统是否为多核CPU,如果是多核CPU,那么就会给总线加锁,保证只有一个线程能给总线加锁成功,加锁之后进行CAS操作,因此可以说CAS也是排他锁,不过相比synchronized,CAS属于CPU原语级别,因此多线程情况下效率会高一点。
CAS的工作原理
当我们要执行一个i++的操作时,如果用CAS去执行的话,那么执行的过程,大概就是:
- i放在内存中,值为1
- 加载i到cpu中,并设置为旧的值old,载进行+1计算的到新的值new
- 再次拿内存中的i值,得到一个期望值expect。
- 然后我们拿expect与old值就行比较,如果相等的话,就说明这个值没有在我计算的过程中没有被改变过,那么就将i的值更新为新的值。如果expect与old不相等,那么就说明i的值在我计算的过程中被修改了,那么就重新进入步骤2。
观察上面的流程,会发现整个执行过程会不断的在2~5之间进行循环,直到设置新的值成功为止,这个循环过程,线程并没有进入等待队列,就好像一直在原地转圈,因此CAS也叫自旋锁。
LongAdder
除了使用AtomicInteger,还可以使用LongAdder来保证原子性:
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.LongAdder;
/**
* @author 赵帅
* @date 2021/1/13
*/
public class LongAdderDemo {
public static LongAdder num = new LongAdder();
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
new Thread(()->{
for (int j = 0; j < 1000; j++) {
num.increment();
}
}).start();
}
TimeUnit.SECONDS.sleep(1);
System.out.println("num = " + num);
}
}
LongAdder是通过分段锁来实现的,因此在数据量非常大的时候,效率会比较高。synchronized,AtomicInteger,LongAdder都可以实现自增操作。他们之间的效率需要根据具体业务来选择,因为Synchronized经过锁升级的过程,效率并不一定比CAS低。
java中还可以通过AtomicReference<>类来创建一个保证原子性的对象。
Unsafe
查看AtomicInteger的getAndIncrement()方法源码:
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
可以看到最终使用的是Unsafe类来实现的。
什么是Unsafe
Unsafe是java底层sun.misc包下的一个类,是一个线程不安全的类,可以提供一些用于执行级别低,不安全的操作方法。如:直接访问系统内存资源,自主管理内存资源等。这些方法在提升java运行效率,增强java语言底层资源操作能力方面起到了很大的作用。但是由于Unsafe类使java语言拥有了类似C语言指针一样操作内存空间的能力,因此也增加了内存安全的风险。在程序中过度,不正确的使用Unsafe类,会使得程序出错的概率变大,是的java这个安全的语言变得不再安全。
Unsafe提供的API大致可分为:内存操作,CAS,Class,对象操作,线程调度,系统信息获取,内存屏障,数组操作等。
Unsafe的使用
查看Unsafe的源码:
private Unsafe() {
}
@CallerSensitive
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();
// 仅在引导类加载器 BootstrapClassLoader 加载时才合法
if (!VM.isSystemDomainLoader(var0.getClassLoader())) {
throw new SecurityException("Unsafe");
} else {
return theUnsafe;
}
}
可以看出Unsafe是一个单例对象,而且无法通过getUnsafe来获取Unsafe对象,因为只有在BootstrapClassLoader加载器加载时才有效,否则会抛出SecurityExecuption异常。
如果我们想要使用这个类时,可以通过反射来获取 theUnsafe属性来获取Unsafe对象实例。
public class UnsafeDemo {
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
Unsafe unsafe = (Unsafe) field.get(null);
System.out.println("unsafe = " + unsafe);
}
}
使用 Unsafe进行CAS操作
在unsafe类中操作CAS的方法有:
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
五、JUC中的锁
在前面学习了Synchronized锁,回顾synchronized:
-
可重入锁。
-
锁升级:无锁态 -> 偏向锁 -> 轻量级锁 -> 重量级锁。
-
非公平锁
公平锁和非公平锁:
当程序加锁时,肯定会有多个线程竞争这把锁,当一个线程获得锁后,那么就会有一个等待队列维护这些等待线程。
公平锁:线程遵循达到的先后顺序,先来的优先获取锁,后来的后获取锁。这样的话,内部就要维护一个有序队列
非公平锁:线程到达后直接参与竞争,如果得到锁直接执行,没有得到锁的话,就进入等待队列。
-
系统管理
因为synchronized的原语是
monitorenter,获取锁和释放锁都是jvm通过加监控和退出监控实现的。
看下面这个题:
一个线程打印ABCDEFG,另一个线程打印abcdefg,控制两个线程交替打印AaBbCcDdEeFfGg。
首先来看使用Synchronized实现:
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2021/1/13
*/
public class SynchronizedPrint {
private final Object lock = new Object();
public void fun1() {
String str = "ABCDEFG";
char[] chars = str.toCharArray();
synchronized (lock) {
for (char aChar : chars) {
System.out.print(aChar);
try {
lock.notify();
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
lock.notify();
}
}
public void fun2() {
String str = "abcdefg";
char[] chars = str.toCharArray();
synchronized (lock) {
for (char aChar : chars) {
System.out.print(aChar);
try {
lock.notify();
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
lock.notify();
}
}
public static void main(String[] args) throws InterruptedException {
SynchronizedPrint print = new SynchronizedPrint();
new Thread(print::fun1).start();
new Thread(print::fun2).start();
TimeUnit.SECONDS.sleep(1);
System.out.println("\n");
}
}
ReentrantLock
ReentrantLock是JUC包下的基于CAS实现的锁,因此是一个轻量级锁。查看ReentrantLock的构造方法可以发现ReentrantLock默认为非公平锁。
public ReentrantLock() {
sync = new NonfairSync();
}
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
ReentrantLock通过构造方法参数可以选择是公平锁或非公平锁,默认是非公平锁。
/** 创建公平锁 */
private final ReentrantLock fairLock = new ReentrantLock(true);
/** 创建非公平锁 */
private final ReentrantLock nonfairLock = new ReentrantLock();
ReentrantLock的使用
ReentrantLock在使用时需要手动的获取锁和释放锁:
import java.util.concurrent.locks.ReentrantLock;
/**
* @author 赵帅
* @date 2021/1/13
*/
public class ReentrantLockDemo {
private final ReentrantLock lock = new ReentrantLock();
public void fun1() {
lock.lock();
try {
// do something
}finally {
lock.unlock();
}
}
}
ReentrantLock需要通过lock.lock()方法获取锁,通过lock.unlock()方法释放锁。而且为了保证锁一定能狗被释放,避免死锁的发生,一般获取锁的操作紧挨着try而且finally的第一行必须为释放锁操作。
ReentrantLock是可重入锁。
因为ReentrantLock是手动获取锁因此当锁重入时,每获取一次锁就要释放一次锁。
import java.util.concurrent.locks.ReentrantLock;
/**
* @author 赵帅
* @date 2021/1/14
*/
public class ReentrantLockDemo1 {
private final ReentrantLock lock = new ReentrantLock();
public void fun1() {
lock.lock();
try {
// 锁重入
lock.lock();
try {
// do something
System.out.println("do something");
}finally {
lock.unlock();
}
}finally {
lock.unlock();
}
}
}
上面代码获取了两次锁,所以就需要手动的释放两次锁。
ReentrantLock的方法:
常用的方法有:
lock(): 获取锁unlock(): 释放锁tryLock():尝试获取锁并立即返回获取锁结果true/falsetryLock(long timeout,Timeunit unit): 延迟获取锁,在指定时间内不断尝试获取锁,如果在超时前获取到锁,则返回true,超时未获取到锁则返回false。会响应中断方法。lockInterruptibly(): 获取响应中断的锁。isHeldByCurrentThread: 当前线程是否获取锁。newCondition()获取一个条件等待对象。
上述方法的实际使用如下:
import org.junit.Test;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantLock;
/**
* @author 赵帅
* @date 2021/1/13
*/
public class ReentrantLockTest {
private final ReentrantLock lock = new ReentrantLock();
@Test
public void fun1() {
System.out.println("lock与unlock");
lock.lock();
try {
System.out.println("获取锁");
} finally{
lock.unlock();
}
}
@Test
public void fun2() throws InterruptedException {
Thread thread = new Thread(() -> {
try {
lock.lockInterruptibly();
System.out.println("获取到可响应线程中断方法的锁");
// 模拟业务耗时
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
System.out.println("线程被中断");
} finally {
lock.unlock();
}
}, "thread-1");
thread.start();
// 等待线程thread-1启动
TimeUnit.MILLISECONDS.sleep(200);
// 中断thread-1线程,此时线程thread-1会抛出InterruptedException异常
System.out.println("中断thread-1");
thread.interrupt();
}
public void run3() {
if (lock.tryLock()) {
try {
System.out.println(Thread.currentThread().getName() + "获取到锁");
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
} else {
System.out.println(Thread.currentThread().getName() + "未获取到锁");
}
}
@Test
public void fun3() {
Thread thread1 = new Thread(this::run3, "thread-1");
Thread thread2 = new Thread(this::run3, "thread-2");
thread1.start();
thread2.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void run4() {
try {
if (lock.tryLock(3L, TimeUnit.SECONDS)) {
System.out.println(Thread.currentThread().getName() + "获取锁");
TimeUnit.SECONDS.sleep(4);
} else {
System.out.println(Thread.currentThread().getName() + "未获取锁");
}
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
// 如果获取锁成功需要释放锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
System.out.println(Thread.currentThread().getName() + "释放锁");
}
}
}
@Test
public void fun4() throws InterruptedException {
Thread thread1 = new Thread(this::run4, "thread-1");
Thread thread2 = new Thread(this::run4, "thread-2");
thread1.start();
thread2.start();
thread1.join();
thread2.join();
}
}
ReentrantLock和synchronized的区别:
| 比较项 | ReentrantLock | synchronized |
|---|---|---|
| 可重入 | 支持 | 支持 |
| 响应中断 | 同时支持响应中断lock.lockInterruptibly(),不响应中断 lock.lock() |
不支持响应中断 |
| 可控性 | 手动控制加解锁 | 系统控制加解锁,人力不可控 |
| 尝试获取锁 | tryLock(),立即响应结果 |
不支持 |
| 延迟获取锁 | tryLock(timeout,timeunit)延迟超时获取锁 |
不支持 |
| 公平锁 | 支持公平锁和非公平锁 | 非公平锁 |
ReentrantLock如果使用不当,没有释放锁,就会造成死锁,而synchronized是由系统管理加锁和释放锁。
Condition
在学习synchronized时我们知道,一个锁会对应一个等待队列,可以通过wait()和notify(),notifyAll()方法来控制线程等待和唤醒。ReentrantLock同样也支持等待和唤醒,不过ReentrantLock可以通过newCondition()来开启多个等待队列,也就是说ReentrantLock一把锁可以绑定多个等待队列。
condition方法
await(): 等待状态,进入等待队列,等待唤醒,与Object的wait()方法功能相同。await(long timeout,TimeUnit unit): 进入有时间的等待状态,被唤醒或等待超时自动唤醒,与Object的wait(long timeout,TimeUnit unit)功能相同。signal(): 唤醒一个等待队列的线程,与notify()功能相同。singlaAll(): 唤醒等待队列中的所有线程,与notifyAll()功能相同。awaitUntil(Date deadline): 进入等待状态,到达指定时间后自动唤醒。awaitUninterruptibly():进入不响应线程中断方法的等待状态。awaitNanos(long timeout): 进入纳秒级等待状态,xx纳秒后自动唤醒
使用Condition
import org.junit.Test;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.ZoneOffset;
import java.util.Date;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
/**
* @author 赵帅
* @date 2021/1/14
*/
public class ConditionTest {
private final ReentrantLock lock = new ReentrantLock();
private final Condition condition = lock.newCondition();
public void run1() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "获取锁");
// 进入等待状态,响应中断,等待唤醒
condition.await();
// 进入有超时时间的等待状态,等待结束自动唤醒
condition.await(1L, TimeUnit.MICROSECONDS);
// 进入纳秒级等待状态,超时自动唤醒
condition.awaitNanos(100L);
// 进入不响应中断的等待状态,无法通过 thread.interrupt() 中断线程
condition.awaitUninterruptibly();
// 进入等待状态,指定结束等待的时间,到达时间后自动唤醒
condition.awaitUntil(Date.from(LocalDateTime.of(2021, 1, 14, 11, 45)
.atZone(ZoneId.systemDefault()).toInstant()));
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
System.out.println(Thread.currentThread().getName() + "释放锁");
}
}
public void run2() {
lock.lock();
try {
condition.signal();
System.out.println(Thread.currentThread().getName() + "获取锁");
} finally {
lock.unlock();
System.out.println(Thread.currentThread().getName() + "释放锁");
}
}
@Test
public void fun1() throws InterruptedException {
Thread thread1 = new Thread(this::run1, "thread-1");
Thread thread2 = new Thread(this::run2, "thread-2");
Thread thread3 = new Thread(this::run2, "thread-3");
thread1.start();
thread2.start();
// 等待线程1进入 lock.awaitUninterruptibly()
TimeUnit.SECONDS.sleep(2L);
thread3.start();
thread1.join();
thread2.join();
thread3.join();
}
}
Object监视器和Condition的区别
| 对比项 | Object监视器 | condition |
|---|---|---|
| 前置条件 | synchronized(obj)获取锁 |
lock.lock()获取锁,lock.newCondition()获取Condition对象 |
| 调用方式 | obj.wait() |
condition.await() |
| 等待队列个数 | 1个 | 多个 |
| 当前线程释放锁进入等待状态 | 支持 | 支持 |
| 当前线程释放锁进入超时等待状态 | 支持 | 支持 |
| 当前线程释放锁进入等待状态不响应中断 | 不支持 | 支持 |
| 当前线程释放锁进入等待状态到将来某个时间 | 不支持 | 支持 |
| 唤醒等待队列中的一个线程 | 支持 | 支持 |
| 唤醒等待队列中的所有线程 | 支持 | 支持 |
使用Condition实现阻塞队列BlockingQueue
import com.sun.org.apache.bcel.internal.generic.NEW;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
/**
* @author 赵帅
* @date 2021/1/14
*/
public class BlockingQueue<T> {
private final ReentrantLock lock = new ReentrantLock();
private final LinkedList<T> list = new LinkedList<>();
private final Condition notEmpty = lock.newCondition();
private final Condition notFull = lock.newCondition();
private final int size;
public BlockingQueue(int size) {
this.size = size;
}
/**
* 入队,如果队列不为空则阻塞。
*/
public void enqueue(T t) {
lock.lock();
try {
while (list.size() == size) {
notFull.await();
}
System.out.println("入队:" + t);
list.add(t);
notEmpty.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public T dequeue() {
lock.lock();
try {
while (list.size() == 0) {
notEmpty.await();
}
T t = list.removeFirst();
System.out.println(Thread.currentThread().getName() + ":出队:" + t);
notFull.signalAll();
return t;
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
lock.unlock();
}
return null;
}
public static void main(String[] args) {
BlockingQueue<String> queue = new BlockingQueue<>(5);
// 生产者
new Thread(() -> {
for (int i = 0; i < 100; i++) {
queue.enqueue("str" + i);
}
}, "produce-1").start();
// 消费者
for (int i = 0; i < 10; i++) {
new Thread(() -> {
for (int j = 0; j < 10; j++) {
queue.dequeue();
}
}, "consumer-" + i).start();
}
}
}
使用ReentrantLock来实现输出AbBb...这道题:
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @author 赵帅
* @date 2021/1/16
*/
public class ReentrantLockPrint {
private final ReentrantLock lock = new ReentrantLock();
private final Condition condition = lock.newCondition();
public void print(char[] array) {
lock.lock();
try {
for (char c : array) {
System.out.println(c);
condition.signal();
condition.await();
}
condition.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
char[] array1 = "ABCDEFG".toCharArray();
char[] array2 = "abcdefg".toCharArray();
ReentrantLockPrint demo = new ReentrantLockPrint();
new Thread(() -> demo.print(array1)).start();
new Thread(() -> demo.print(array2)).start();
TimeUnit.SECONDS.sleep(2);
}
}
CountDownLatch
countDownLatch,也叫门栓。使用来等待线程执行完毕的锁。方法如下:
countDownLatch在创建时需要指定一个count值,表示需要等待完成的线程数。
await(): 使当前线程进入等待状态await(long timeout,TimeUnit unit): 使当前线程进入超时等待状态,超时自动唤醒线程。countDown():使count值减1,当count的值为0时,唤醒等待状态的线程。getCount: 获取当前的count值。
使用如下:
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2020/8/5
*/
public class CountDownLatchDemo {
private static final CountDownLatch lock = new CountDownLatch(5);
private static void fun1() {
try {
System.out.println(Thread.currentThread().getName() + ":到达");
TimeUnit.SECONDS.sleep(1);
System.out.println(Thread.currentThread().getName() + ":放行");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
lock.countDown();
}
}
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 5; i++) {
new Thread(CountDownLatchDemo::fun1, "t" + i).start();
TimeUnit.SECONDS.sleep(2);
}
lock.await();
System.out.println("111");
}
}
可以看到,countDownLatch在初始化的时候,必须指定一个大小,这个大小可以理解为加了几道门拴。然后,当一个线程调用await()方法后,那么当前线程就会等待。我们初始化countDownLatch(count)时,指定了一个count,只有当这个count等于0的时候,等待才会结束,否则就会一直等待。每调用一次countDown()方法,那么count值就减1。
上面的代码我们创建了一个初始化大小为5的countDownLatch,可以为创建了一个门拴,上面有5道锁。然后在main方法中又创建了5个线程,main方法调用了await()方法等待count变成0。然后创建的5个线程,每个线程都会在执行结束时,调用countDown()来将当前的门栓减去1,当所有的线程执行结束,count值变为0。那么main方法就可以继续执行了。
CountDownLatch主要就是用来等待线程执行结束的。在之前我们都是使用thread.join()方法来将线程加入当前线程来保证线程运行结束,但是这种写法会非常麻烦,如果线程多我们就要写好多遍join。countDownLatch的作用与join方法相同。
可以理解为:打仗时,有很多个战斗小队,这些战斗小队就是一个个的线程。然后路上遭路雷区,拦住了所有的队伍(调用了
await()方法的线程)。这些队伍就停下来,进入等待的状态了。然后就要派人去排雷,每排掉一颗雷。雷的总数就减1。这样当地雷全部排完,队伍才可以继续往下执行。地雷排完之前,队伍都是处于原地等待状态。
CyclicBarrier
CyclicBarrier也叫栅栏。与CountDownLatch很相似,都是使线程在这里等待,创建时都需要指定一个int参数parties,表示这个栅栏要拦的线程总数。方法如下:
await(): 进入等待状态,并将线程数count加1,当count==parties时,唤醒所有的等待线程。await(long timeout,TimeUnit unit): 进入超时等待状态,超时自动唤醒。getParties(): 获取这个栅栏的大小,即初始化时指定的大小。getNumberWaiting(): 获取目前处于等待状态的线程数。reset(): 重置栅栏,将唤醒所有等待状态的线程。后面来的线程将重新开始计数。
CyclicBarrier的用法如下:
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2020/8/6
*/
public class CyclicBarrierDemo {
private static final CyclicBarrier barrier = new CyclicBarrier(5);
public static void fun1() {
System.out.println(Thread.currentThread().getName() + ":线程到达");
try {
barrier.await();
System.out.println(Thread.currentThread().getName() + ":释放锁");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
new Thread(CyclicBarrierDemo::fun1, "t" + i).start();
TimeUnit.SECONDS.sleep(1);
}
}
}
CyclicBarrier还可以在创建时指定最后一个线程达到时执行某个方法:
private static final CyclicBarrier barrier = new CyclicBarrier(5,()->{
System.out.println(Thread.currentThread().getName() + ":最后到达");
});
来看看CyclicBarrier的使用。首先我们创建时也需要指定一个线程数大小,然后还可以指定一个调用函数。创建成功后内部会有一个数维护当前等待的线程数。初始为0,在使用时通过await()方法进入等待时,就将这个数+1,当进入等待状态的线程数与CyclicBarrier指定的线程数相等时就唤醒所有等待的线程,并将等待的线程数清0,开始新一轮的拦截。
通俗理解就是:打仗时需要撤退,不能乱撤,得听命令,然后就有一个栅栏拦着,所有撤退的人都得等待栅栏打开你才能出。而且撤退都是分批的。不能说一群人一块冲出去,因此就编队。我这个栅栏一次只能出去五个人,人要走前先得来栅栏前面占着位置等着。等凑够5个人了,我就打开你们出去,我等下一批五个人。当创建时指定一个构造方法时,这个构造方法只有最后一个线程到达后会执行,可以理解为:我这个栅栏有一个开关控制,最后一个人过来时,你得先来我这打开开关你才能走。
CyclicBarrier与CountDownLatch的区别
- CyclicBarrier是可以重复使用的,当线程数满了后会自动清0。countDownLatch是一次性的,当数减为0后,就失效了。
- CyclicBarrier可以指定最后一个线程到达时执行一个方法。
当调用线程中断时会
Semaphore
Semaphore又叫信号量,使用方式如下:
import java.util.concurrent.Semaphore;
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2020/8/6
*/
public class SemaPhoreDemo {
private static final Semaphore semaphore = new Semaphore(5);
public static void fun1() {
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + ":获取令牌");
TimeUnit.SECONDS.sleep(8);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
semaphore.release();
System.out.println(Thread.currentThread().getName() + ":释放令牌");
}
}
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
new Thread(SemaPhoreDemo::fun1, "t" + i).start();
TimeUnit.SECONDS.sleep(1);
}
}
}
Samephore理解起来就好像一个房子,门口有保安,一个人想要进去,需要拿一个令牌,领牌的数量是有限的,令牌发完后,后来的人要在门口等着,等里面的人出来会归还领牌,这时等着的人就可以拿领牌进去了。
因此,samephore比较适合拿来做限流。
Phaser
phaser翻译过来是阶段,它维护程序执行的一个阶段一个阶段的。
import java.util.Random;
import java.util.concurrent.Phaser;
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2021/1/16
*/
public class PhaserDemo {
private static Phaser phaser = new SimplePhaser();
private static class SimplePhaser extends Phaser {
@Override
protected boolean onAdvance(int phase, int registeredParties) {
System.out.println("===============阶段" + phase + "总人数" + registeredParties);
switch (phase) {
case 0:
return false;
case 1:
return false;
case 2:
return false;
case 3:
return true;
default:
return true;
}
}
}
private static class Person implements Runnable {
private final Random random = new Random();
private String name;
public Person(String name) {
this.name = name;
}
private void sleepRandom() {
try {
TimeUnit.MILLISECONDS.sleep(random.nextInt(100));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void arrive() {
sleepRandom();
System.out.println(name + "到达");
phaser.arriveAndAwaitAdvance();
}
private void marry() {
sleepRandom();
System.out.println(name + "开始结婚");
phaser.arriveAndAwaitAdvance();
}
private void eat() {
sleepRandom();
System.out.println(name + "开始吃饭");
phaser.arriveAndAwaitAdvance();
}
private void leave() {
sleepRandom();
if ("新郎".equals(name) || "新娘".equals(name)) {
phaser.arriveAndAwaitAdvance();
} else {
System.out.println(name + "吃完饭走");
phaser.arriveAndDeregister();
}
}
@Override
public void run() {
arrive();
marry();
eat();
leave();
}
}
public static void main(String[] args) {
phaser.bulkRegister(7);
for (int i = 0; i < 5; i++) {
new Thread(new Person("路人" + i)).start();
}
new Thread(new Person("新郎")).start();
new Thread(new Person("新娘")).start();
}
}
ReadWriteLock
readwritelock,读写锁,可以拆分为读锁和写锁,读锁时共享锁,写锁时排他锁。用法如下:
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* @author 赵帅
* @date 2020/8/6
*/
public class ReadWriteLockDemo {
public static final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private static final Lock readLock = readWriteLock.readLock();
private static final Lock writeLock = readWriteLock.writeLock();
/**
* 读锁
*/
public static void fun1() {
readLock.lock();
try {
System.out.println(Thread.currentThread().getName() + ":获取读锁");
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
readLock.unlock();
System.out.println(Thread.currentThread().getName() + ":释放读锁");
}
}
public static void fun2() {
writeLock.lock();
try {
System.out.println(Thread.currentThread().getName() + ":获取写锁");
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
writeLock.unlock();
System.out.println(Thread.currentThread().getName() + ":释放写锁");
}
}
public static void main(String[] args) {
new Thread(ReadWriteLockDemo::fun1, "t").start();
new Thread(ReadWriteLockDemo::fun1, "t1").start();
new Thread(ReadWriteLockDemo::fun1, "t2").start();
new Thread(ReadWriteLockDemo::fun2, "t3").start();
new Thread(ReadWriteLockDemo::fun2, "t4").start();
}
}
LockSupport
前面的锁都需要在锁内部等待或唤醒,lockSupport支持在锁的外部唤醒指定的锁。相比之下更加灵活,用法如下:
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.LockSupport;
/**
* @author 赵帅
* @date 2020/8/6
*/
public class LockSupportDemo {
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
for (int i = 0; i < 10; i++) {
System.out.println(i);
if (i == 5) {
LockSupport.park();
}
if (i == 8) {
LockSupport.park();
}
try {
TimeUnit.MILLISECONDS.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread.start();
LockSupport.unpark(thread);
LockSupport.unpark(thread);
}
}
LockSupport可以在调用park()方法前先调用unpark()。LockSupport底层使用的是Unsafe类。
每一个线程都有一个许可
(permit),permit的值只有0和1。默认为0。当调用
unpark(thread)方法时,会将线程的permit值设置为1,多次调用unpark方法,permit的值还是1。当调用
park()方法时:
- 如果当前线程的permit的值为1。那么就会将值变为0并立即返回。
- 如果当前线程的permit的值为0,那么当前线程就会被阻塞,并等待其他线程调用
unpark(thread)将线程的值设为1,当前线程将被唤醒。然后会将permit的值设为0,并返回。
AQS
AQS全称为AbstractQueuedSynchronizer, ReentrantLock,CountDownLatch等都是通过AQS实现的。
AQS的核心是state属性,很多实现都是通过操作这个属性来实现的。而且AQS内部的方法都是操作unsafe的CAS操作实现的,因此说AQS的实现都是自旋锁。
ReentrantLock的实现:
ReentrantLock内部分为公平锁fairSync和非公平锁NonfairSync,这两个类都继承自Sync,而sync继承AQS, 当调用lock.lock()获取锁时,查看lock()方法的源码:
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
当调用lock方法时,首先会尝试修改state属性的值,从0改成1。如果失败的话,那么就调用acquire方法。acquire方法内部调用了tryAcquire(arg)方法,最终调用NonSync的nonfairTryAcquire(arg)方法,然后内部判断,如果当前的state值是0,那么就尝试将state的值设为1,如果设置1成功,则说明获取到锁,返回true,如果state的值不是0,但是加锁的线程是当前线程,也就是进入可重入锁了,那么就将state的值加1。
释放锁是,没释放一次就将state的值减1,最终保证state的值是0,那么这把锁就可以被其他线程使用了。
CountDownLatch的实现:
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
Sync(int count) {
setState(count);
}
public void countDown() {
sync.releaseShared(1);
}
CountDownLatch在创建时就讲AQS的state的值设置为count值,然后每次调用countDown方法就将state的值减1,知道state的值变为0.
六、强软弱虚四种引用以及ThreadLocal源码
强软弱虚引用
强引用
当我们使用Object obj = new Object()创建一个对象时,指向这个对象的引用就称为强引用。只要这个引用还指向一个对象,那么指向的这个对象就不会被垃圾回收器回收。
package com.gouxiazhi.reference;
/**
* 强引用
* @author 赵帅
* @date 2021/1/17
*/
public class ReferenceDemo1 {
public static void main(String[] args) {
// 启动时设置jvm初始堆和最大堆大小为3M -Xms3M -Xmx3M
// 先创建一个1M的字节数组,这是强引用
byte[] content = new byte[1024 * 1024];
// 再创建一个2M的字节数组,因为上面已经创建了1M了,强引用只要content还指向对象,就不会被垃圾回收器回收。因此会抛出内存溢出OOM异常。
// 当打开下面这句代码时,content不再指向一个对象,那么上面创建的对象就会被垃圾回收器回收,就可以正常运行了。
// content = null;
byte[] bytes = new byte[2 * 1024 * 1024];
}
}
软引用
使用软引用创建的对象,当内存不够时,就会被垃圾回收器回收。
package com.gouxiazhi.reference;
import java.lang.ref.SoftReference;
/**
* 软引用
* @author 赵帅
* @date 2021/1/17
*/
public class ReferenceDemo2 {
public static void main(String[] args) {
// 启动时设置jvm初始堆和最大堆大小为3M -Xms3M -Xmx3M
// 使用软引用创建一个1M的数组。
SoftReference<byte[]> reference = new SoftReference<>(new byte[1024 * 1024]);
System.out.println("reference = " + reference.get());
// 上面使用软引用创建了一个1M的数组,下面再创建2M的数组时,因为堆内存空间不够,就会调用gc清理掉软引用的指向的对象。因此不会抛出异常。
// 如果上面不使用软引用,而使用 byte[] a = new byte[1024*1024];就会抛出内存溢出异常。
byte[] bytes = new byte[2 * 1024 * 1024];
// 因为创建上面的对象内存不够,因此软引用指向的对象已经被回收
System.out.println("reference = " + reference.get());
}
}
弱引用
使用弱引用创建的对象,只要垃圾回收器看见,就会回收。
package com.gouxiazhi.reference;
import java.lang.ref.WeakReference;
import java.util.Arrays;
/**
* @author 赵帅
* @date 2021/1/17
*/
public class ReferenceDemo3 {
public static void main(String[] args) {
// 弱引用指向的对象,只要垃圾回收器看见就立马回收掉。
WeakReference<byte[]> weakReference = new WeakReference<>(new byte[1024 * 1024]);
System.out.println("weakReference = " + Arrays.toString(weakReference.get()));
System.gc();
System.out.println("weakReference = " + Arrays.toString(weakReference.get()));
}
}
虚引用
主要用来管理堆外内存等。
package com.gouxiazhi.reference;
import java.lang.ref.PhantomReference;
import java.lang.ref.Reference;
import java.lang.ref.ReferenceQueue;
import java.util.ArrayList;
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2021/1/17
*/
public class ReferenceDemo4 {
public static class M{
@Override
protected void finalize() throws Throwable {
System.out.println("对象被回收了");
super.finalize();
}
}
public static void main(String[] args) {
ReferenceQueue<M> referenceQueue = new ReferenceQueue<>();
// 虚引用的使用,除了指向一个对象,还需要指定一个引用队列。
PhantomReference<M> reference = new PhantomReference<>(new M(), referenceQueue);
System.out.println("reference = " + reference);
// 虚引用指向的对象无法被获取到,弱引用被垃圾回收器看见就会被回收,虚引用比弱引用级别更低
System.out.println("reference = " + reference.get()); // null
// 虚引用一般都是指向一个堆外内存,因为垃圾回收器只能回收堆内存,无法管理堆外内存.
// 如果使用java管理堆外内存。假设M代表着堆外内存,那么当虚引用被回收时,他会将自身放入referenceQueue引用队列,开启另一个线程监听这个队列,
// 当这个队列取到内容时,就代表要回收这块堆外内存了,可以执行回收堆外内存操作
new Thread(() -> {
// 如果从队列中取到虚引用,那么就表示需要回收这个堆外内存了。
Reference<? extends M> poll = referenceQueue.poll();
if (poll != null) {
System.out.println("虚引用对象被jvm回收了" + poll);
}
}).start();
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
ArrayList<byte[]> list = new ArrayList<>();
while (true) {
list.add(new byte[4 * 1024]);
}
}
}
ThreadLocal源码
查看ThreadLocal的set方法源码:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
可以看到,在set方法中,首先获取当前线程。然后通过getMap(t)获取了一个ThreadLocalMap对象。然后将要保存的对象存入了这个Map中,key值就是ThreadLoacl对象本身,value值为要保存的数据。
然后我们再点开getMap方法:
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
返回的是t.threadLocals属性值,而且这个值是ThreadLocalMap类型的。查看ThreadLocalMap类:
static class ThreadLocalMap {
/**
* The entries in this hash map extend WeakReference, using
* its main ref field as the key (which is always a
* ThreadLocal object). Note that null keys (i.e. entry.get()
* == null) mean that the key is no longer referenced, so the
* entry can be expunged from table. Such entries are referred to
* as "stale entries" in the code that follows.
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
可以看到ThreadLocalMap中存放数据的Entry节点继承自WeakReference<?>,因此说ThreadLocal底层用的是弱引用,而且在存储时,Map的key作为弱引用,也就是ThreadLocal对象本身作为弱引用存放,值是强引用存放的。
查看ThreadLocalMap类的set方法:
private void set(ThreadLocal<?> key, Object value) {
// 获取存放数据的数组,底层数据结构
Entry[] tab = table;
// 获取数组的长度
int len = tab.length;
// 计算key要存放的下标
int i = key.threadLocalHashCode & (len-1);
// 从下标i开始遍历数组,如果下标i 有元素了,也就是hash冲突了,那么就往后插并将下标自增
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
// 获取下标为i的entry元素
ThreadLocal<?> k = e.get();
// 如果此位置的key与要保存的key相同则替换值
if (k == key) {
e.value = value;
return;
}
// 如果key是空的话,说明这个位置的key已经过期被回收,则替换值为新的值。
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
// 如果下标i为空,说明这个位置是空的。插入这个位置
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
简单分析上面整个过程,整个threadlocal存放数据过程甬道图如下:

当调用threadLocal的set方法时:
- 获取当前线程的threadLocals属性。
- 调用threadLocals属性的set方法。
- 获取threadLocalMap的entry数组。
- 计算当前threadLocal对象的下标。
- 获取下标的entry,如果没有则新建一个entry,如果有的话,判断当前的key是否与要存入的key一致,如果一致,则替换值。如果key为空的话,则替换值。如果上面条件都不满足,则新建一个entry对象。
ThreadLocal造成的内存泄漏
因为ThreadLocal是将自身作为弱引用存放在ThreadLocalMap中的,因此当一个ThreadLocal对象的强引用消失时。那么这个key将会被回收,这时原来这个key对应的value值如果没有被移除的话,那么就永远无法被访问到了。而且因为这个value值是作为entry节点的value引用指向的,value引用是一个强引用,那么这时,这个value属性就永远无法被回收,也无法被访问,就会造成内存泄漏。
使用ThreadLocal如何避免内存泄漏?
使用ThreadLocal set了一个值以后,在这个线程结束之前,一定要调用remove方法移除存放的值。
七、集合容器
java中的集合主要结构如下:

集合容器的分类
集合容器从接口类型上可以Collection和Map类型,从安全性分为线程安全和线程不安全。
Collection:
Collection接口可以分为List和Set两个接口。
List是有序的,可重复的;而Set是无序的,不可重复的。
List的实现有:
- ArrayList: 线程不安全,底层使用数组存储数据。允许存空值。
- LinkedList:线程不安全,底层使用链表存储数据。允许空值。
- Vector:线程安全,底层也是使用数组存放数据。通过在方法上添加
synchronized关键字,保证安全性,因此效率非常低,不经常使用。允许空值。 - CopyOnWriteArrayList:线程安全,使用数组存放数据,写时复制,内部通过
ReentrantLock加锁保证线程安全。因为在执行写操作时,会加锁并复制数组,因此当数据非常大或频繁写操作时,效率会比较低,适合读操作多写操作少的场景。允许空值。
Set的实现有:
-
HashSet:hashset内部使用的hashmap,hashset的元素都存放在hashmap的key上。hashset的add方法:
public boolean add(E e) { // PERSENT 为常量new Object();所有的key公用一个value return map.put(e, PRESENT)==null; }因为hashset使用hashmap做存储的数据结构,因此它延续了hashmap的无序性。hashst的数据是无序的。而且是唯一不可重复的。
-
LinkedHashSet:linkedhashset继承自hashset,
public class LinkedHashSet<E> extends HashSet<E> implements Set<E>, Cloneable, java.io.Serializable {它与hashset的区别是,它是有序的。有序的原因是hashset在创建时使用的是hashmap。
public HashSet() { map = new HashMap<>(); }而LinkedHashSet在创建时使用的是LinkedHashMap
public LinkedHashSet() { super(16, .75f, true);}点进super方法:
HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap<>(initialCapacity, loadFactor); }而LinkedHashMap内部重写了Entry类,添加了before和after属性使结构链表化保证有序性。
static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } } -
TreeSet: 内部使用TreeMap存储数据。
-
CopyOnWriteArraySet
内部使用的仍是CopyOnWriteArrayList,
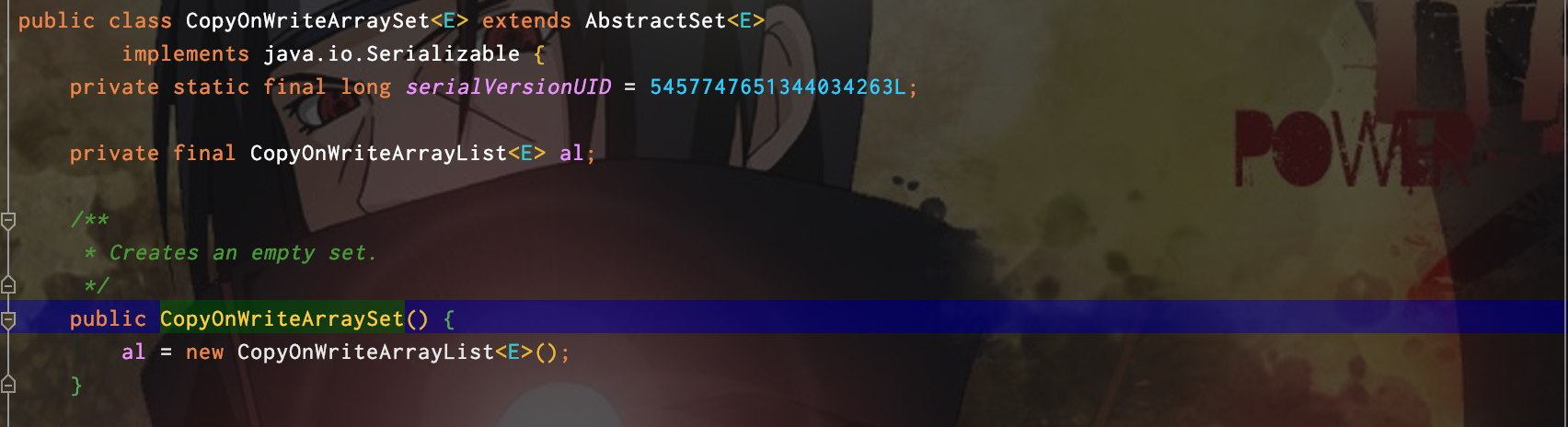
-
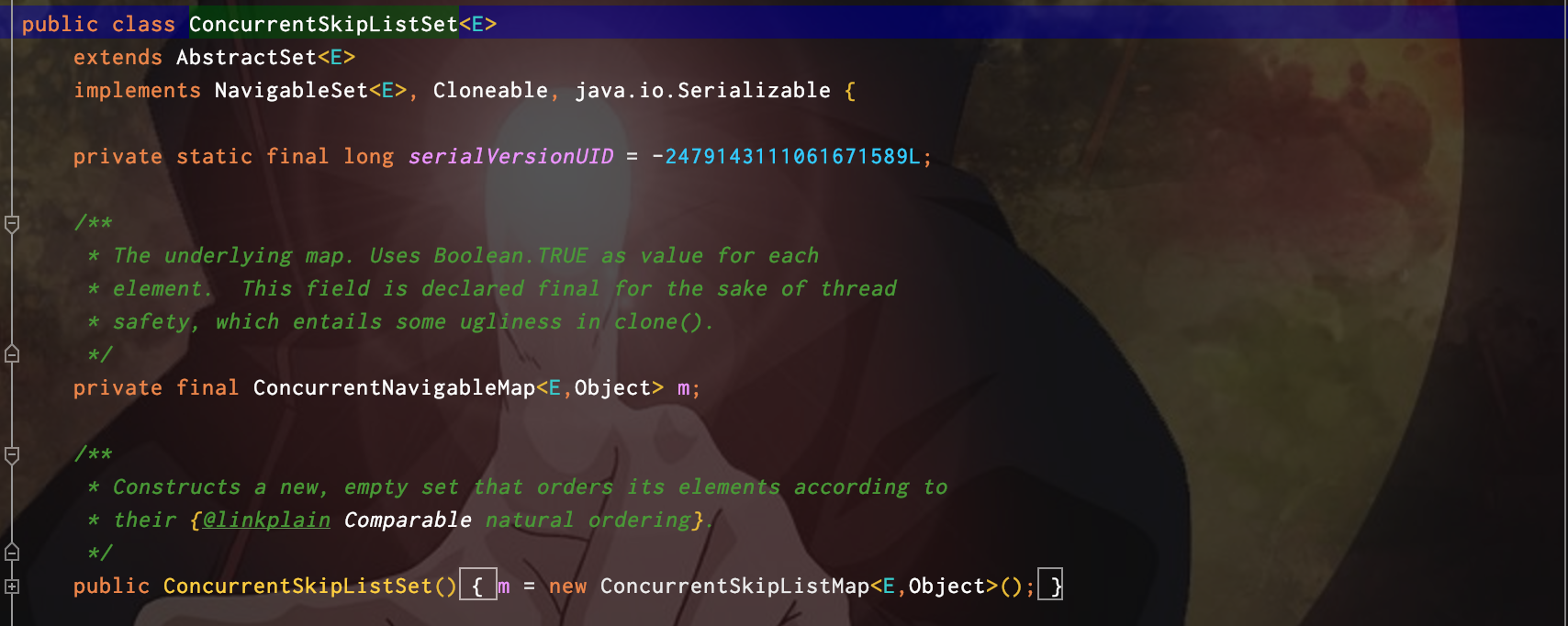
ConcurrentSkipListSet
内部使用ConcurrentSkipListMap实现:
因为Set内部都是使用对应的Map存放数据,因此数据特性与对应Map的key的特性相同。HashMap key可以为空,因此HashSet的Key也可以为空。
Map:
Map的常见实现有:
HashMap:使用hash表实现,常用,线程不安全,效率高。Key,Value都允许空值。

Hashtable:jdk早期的类,内部使用synchronized锁方法来保证线程安全性。效率非常低,基本不用。key,value都不能为空。
LinkedHashMap:内部重写Entry节点继承hashmap的Node节点,添加了头节点和尾节点,使用链表结构。HashMap的Hash桶是纯数组结构:transient Node<K,V>[] table;而LinkedHashMap在Hash桶层因为继承自HashMap,仍然是数组结构,put时,仍是计算hash值无序存储。只不过因为重写内部类及方法,因此数组中的每一个元素,都有头和尾节点,因此从某种程度上说又是有序的。使用的是HashMap,数据存放在Node节点的k,v中,因此Key,value都可以为空。
ConcurrentHashMap:线程安全的HashMap,使用CAS+分段锁保证线程的安全性。效率比Hashtable高很多。key和value都不能为空。

ConcurrentSkipListMap:使用跳表实现的线程安全的Map类型。因为使用跳表,所以查询效率非常高。key和value都不能为空。


TreeMap:通过红黑树实现。因为红黑树的特性,插入和删除效率低。key不能为空,值可以为空。
JUC下的容器
java.util.concurrent包下,添加了一个BlockingQueue接口,这个接口有很多线程安全的实现。BlockingQueue接口又继承自Queue接口。Queue接口继承自Collection接口,Queue队列,先进先出FIFO,Queue接口的方法有:
boolean add(E e):向队列中添加一个元素,如果失败会抛出异常。boolean offer(E e):向队列中添加一个元素,如果失败则返回false。E poll():移除一个元素,如果队列为空则抛出异常E remove(): 移除一个元素,如果队列为空则返回null。E element(): 检查队列头,如果队列为空则抛出异常。E peek(): 检查队列头,如果队列为空则返回null。
BlockingQueue除了继承Queue的方法之外,还添加了两个方法:
put: 添加一个元素,如果队列已满的话,则阻塞等待直到添加成功。take: 从队列中取出一个元素,如果队列为空,则阻塞等待,直到队列中有元素,取出元素。
这两个方法都是阻塞等待的。也是常用的方法。BlockingQueue的常见实现有:
-
ArrayBlockingQueue: 有界阻塞队列,内部使用数组存储数据,初始化时需要指定数组长度。内部使用一把锁ReentrantLock,拆分为两个等待队列。因为入队和出队用的是一把锁,因此生产者和消费者无法并发执行。package com.xiazhi.queue; import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.BlockingQueue; import java.util.concurrent.TimeUnit; import java.util.function.Consumer; /** * @author 赵帅 * @date 2021/1/19 */ public class ArrayBlockingQueueDemo { static BlockingQueue<String> blockingQueue = new ArrayBlockingQueue<>(2); static void consumer() { for (int i = 0; i < 50; i++) { try { String take = blockingQueue.take(); System.out.println(Thread.currentThread().getName() + "取出元素:" + take); TimeUnit.MILLISECONDS.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } } } public static void main(String[] args) { new Thread(() -> { for (int i = 0; i < 100; i++) { String element = "element" + i; System.out.println(Thread.currentThread().getName() + "存入元素:" + element); try { blockingQueue.put(element); TimeUnit.MILLISECONDS.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } } }, "provider").start(); new Thread(ArrayBlockingQueueDemo::consumer, "consumer-1").start(); new Thread(ArrayBlockingQueueDemo::consumer, "consumer-2").start(); } } -
LinkedBLockingQueue: 无界阻塞队列,内部使用链表结构,因为使用的是链表,无界,因此需要注意资源耗尽的风险。内部入队和出队是两把锁,因此可以实现生产者和消费者并发执行。package com.xiazhi.queue; import java.util.concurrent.BlockingQueue; import java.util.concurrent.LinkedBlockingQueue; import java.util.concurrent.TimeUnit; /** * @author 赵帅 * @date 2021/1/19 */ public class LinkedBlockingQueueDemo { static BlockingQueue<byte[]> blockingQueue = new LinkedBlockingQueue<>(); // 设置jvm参数 -Xms10M,-Xmx10M public static void main(String[] args) { // 生产者线程,每隔1秒存入1M数据 new Thread(() -> { try { while (true) { blockingQueue.put(new byte[1024 * 1024]); TimeUnit.SECONDS.sleep(1); } } catch (InterruptedException e) { e.printStackTrace(); } }).start(); // 消费者线程,每隔两秒取出一个元素。 new Thread(() -> { while (true) { try { blockingQueue.take(); TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } }).start(); // 上面由于消费者的消费速度低于生产者的生产速度,因此就会造成队列中的元素越来越多,最终造成内存溢出 } } -
SynchronousQueue: 同步阻塞队列,这个队列没有容量,当它接收一个元素时,必须有一个消费者消费掉这个元素,它才能接收下一个元素。package com.xiazhi.queue; import java.util.concurrent.SynchronousQueue; import java.util.concurrent.TimeUnit; /** * @author 赵帅 * @date 2021/1/19 */ public class SynchronousQueueDemo { static SynchronousQueue<String> synchronousQueue = new SynchronousQueue<>(); public static void main(String[] args) { // 生产者线程 new Thread(() -> { try { // 当有线程调用put方法时,必须等待另一个线程调用take方法取走数据,否则线程就会在此阻塞。 System.out.println(Thread.currentThread().getName() + "存入数据"); synchronousQueue.put("element"); } catch (InterruptedException e) { e.printStackTrace(); } }, "provider").start(); // 消费者线程 ,可以尝试注释消费者线程查看阻塞状态 new Thread(() -> { try { String take = synchronousQueue.take(); System.out.println(Thread.currentThread().getName() + "取出数据:" + take); } catch (InterruptedException e) { e.printStackTrace(); } }, "consumer").start(); } } -
PriorityBlockingQueue: 排序阻塞队列,队列中的元素需要实现Comparable接口,如果没有实现Comparable接口,那么在创建队列时就需要指定排序的方法。内部使用ReentrantLock一把锁,无法实现消费者生产者并发。package com.xiazhi.queue; import java.util.concurrent.BlockingQueue; import java.util.concurrent.PriorityBlockingQueue; /** * @author 赵帅 * @date 2021/1/19 */ public class PriorityBlockingQueueDemo { /** * 因为Integer类实现了Comparable接口,因此会调用 compareTo 方法排序 */ static BlockingQueue<Integer> integerBlockingQueue = new PriorityBlockingQueue<>(); /** * 如果队列中的对象是自定义类型,那么类型可以通过实现 Comparable 接口 */ static BlockingQueue<M> customBLockingQueue = new PriorityBlockingQueue<>(); /** * 如果自定义对象没有实现Comparable接口,那么在调用构造方法是需要指定排序方式,如果类型既不实现Comparable接口,构造方法又没有指定比较方法,那么会抛出异常 */ static BlockingQueue<N> customNonImplComparableBlockingQueue = new PriorityBlockingQueue<>(10, (a, b) -> { if (a.getAge() == b.getAge()) { return 0; } return a.getAge() > b.getAge() ? 1 : -1; }); static BlockingQueue<N> customQueue = new PriorityBlockingQueue<>(); static class M implements Comparable<M> { int age; public M(int age) { this.age = age; } @Override public int compareTo(M obj) { return Integer.compare(this.age, obj.age); } @Override public String toString() { return "M{" + "age=" + age + '}'; } } static class N { int age; public N(int age) { this.age = age; } public int getAge() { return age; } @Override public String toString() { return "N{" + "age=" + age + '}'; } } static void dequeue(BlockingQueue<?> blockingQueue) { while (true) { try { Object take = blockingQueue.take(); System.out.println("take = " + take); } catch (InterruptedException e) { e.printStackTrace(); } } } public static void main(String[] args) throws InterruptedException { // 系统已经实现Comparable接口的类型 new Thread(() -> dequeue(integerBlockingQueue)).start(); integerBlockingQueue.put(10); integerBlockingQueue.put(2); integerBlockingQueue.put(8); integerBlockingQueue.put(6); // 自定义实现Comparable接口的类 new Thread(() -> dequeue(customBLockingQueue)).start(); customBLockingQueue.put(new M(8)); customBLockingQueue.put(new M(93)); customBLockingQueue.put(new M(27)); customBLockingQueue.put(new M(48)); // 构造方法指定比较方法 new Thread(() -> dequeue(customNonImplComparableBlockingQueue)).start(); customNonImplComparableBlockingQueue.put(new N(39)); customNonImplComparableBlockingQueue.put(new N(19)); customNonImplComparableBlockingQueue.put(new N(5)); // 既不实现 Comparable接口,又不再构造方法指定比较方式,会抛出异常 new Thread(() -> dequeue(customQueue)).start(); customQueue.put(new N(29)); customQueue.put(new N(2)); customQueue.put(new N(18)); } } -
DelayBlockingQueue: 延时阻塞队列,每一个元素都要设置过期时间,先过期的元素会被放到队列头,如果没有过期元素,那么无法取出元素。package com.xiazhi.queue; import java.time.LocalTime; import java.util.concurrent.BlockingQueue; import java.util.concurrent.DelayQueue; import java.util.concurrent.Delayed; import java.util.concurrent.TimeUnit; /** * @author 赵帅 * @date 2021/1/19 */ public class DelayQueueDemo { /** DelayQueue中的元素需要继承自Delayed接口 */ static BlockingQueue<M> blockingQueue = new DelayQueue<>(); static class M implements Delayed{ private final LocalTime executeTime; private final String value; public M(LocalTime executeTime, String value) { this.executeTime = executeTime; this.value = value; } @Override public long getDelay(TimeUnit unit) { return unit.convert(executeTime.toSecondOfDay() - LocalTime.now().toSecondOfDay(), TimeUnit.SECONDS); } @Override public int compareTo(Delayed o) { long diffTime = this.getDelay(TimeUnit.SECONDS) - o.getDelay(TimeUnit.SECONDS); return diffTime == 0 ? 0 : diffTime > 0 ? 1 : -1; } @Override public String toString() { return "M{" + "value='" + value + '\'' + '}'; } } public static void main(String[] args) throws InterruptedException { blockingQueue.put(new M(LocalTime.of(23, 6, 18), "zhangsan")); blockingQueue.put(new M(LocalTime.of(23, 5, 50), "里斯")); blockingQueue.put(new M(LocalTime.of(23, 5, 20), "王武")); // 如果元素没有过期,那么线程处于阻塞状态 for (int i = 0; i < 3; i++) { M take = blockingQueue.take(); System.out.println("take = " + take); } } } -
ConcurrentLinkedDeque: 基于链表实现的双端队列。可以理解为线程安全的LinkedList,因为LinkedList也实现了Deque接口。Deque: 双端队列,队列是从一端进入,从另一端出去。而双端队列是指两端都可以进,两端也都可以出。package com.xiazhi.queue; import java.util.Deque; import java.util.Queue; import java.util.concurrent.ConcurrentLinkedDeque; import java.util.concurrent.ConcurrentLinkedQueue; /** * @author 赵帅 * @date 2021/1/20 */ public class ConcurrentLinkedDequeDemo { /** * Queue是一端入队,另一端出队 */ static Queue<String> queue = new ConcurrentLinkedQueue<>(); /** * Deque是双端队列,两边都可以进,两边都可以出。 */ static Deque<String> deque = new ConcurrentLinkedDeque<>(); public static void main(String[] args) { // LinkedQueue严格遵循队列先进先出的特性 queue.add("1"); queue.add("2"); queue.add("3"); queue.add("4"); for (int i = 0; i < 4; i++) { String poll = queue.poll(); System.out.println("poll = " + poll); } deque.addFirst("1"); deque.addLast("2"); String first = deque.removeFirst(); System.out.println("first = " + first); String last = deque.removeLast(); System.out.println("last = " + last); // push向栈中压入元素 deque.push("1"); deque.push("2"); deque.push("3"); // pop 弹出栈顶元素 System.out.println("pop = " + deque.pop()); System.out.println("pop = " + deque.pop()); System.out.println("pop = " + deque.pop()); } } -
LinkedTransferQueue: 链式传递队列。它更像是
SynchronousQueue,LinkedBLockingQueue,ConcurrentLinkedQueue三种队列的超集。它通过链表存储数据,因此可以当作
LinkedBLockingQueue或ConcurrentLinkedQueue使用,而且它也支持数据的传递,像SynchronousQueue。不过不同的是,SynchronousQueue只支持线程一对一的传递元素,而LinkedTransferQueue支持线程多对多的传递元素。因为SynchronousQueue是没有容量的,当一个线程放入元素,必须有另一个线程取走这个元素,就好像线程将一个元素手把手交给了另一个元素。而LinkedTransferQueue是使用链表存放数据的。他是可以存放数据的。当调用
transfer方法存入数据时,他会检测是否有消费者等待获取数据,如果有的话,他就会直接将数据给这个线程而不放入队列。
八、线程池
ThreadPoolExecutor
在之前的demo中,都是使用new Thread()手动创建线程池。但是在工作中使用的话,阿里巴巴编码规约明确说明,线程必须交给线程池来管理。避免资源耗尽的风险。
传统的手动new的方式创建的线程,如果线程非常多的话,就会非常杂乱,无法管理。线程之间互相竞争资源,容易产生线程乱入的风险。线程如果非常多,会造成线程切换频繁,浪费cpu资源。线程多也会增加系统资源耗尽的风险。
所以我们必须使用线程池管理。
关于ThreadPoolExecutor
先来查看ThreadPoolExecutor的构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
构造方法包含的参数有:
- corePoolSize:线程池的核心线程数
- maximumPoolSize: 线程池最大线程数
- keepAliveTime:空闲线程的存活时间
- unit:空闲线程存活时间单位
- workQueue:线程池等待队列。
- threadFactory:线程工厂,生产线程的类。
- handler:线程拒绝策略。当线程池满的时候,该怎么拒绝后来的线程。
要想理解上面的参数。我们首先要理解线程池的工作原理,线程池的存在就是为了管理线程。池化思想的实现无非就是:节省资源,提速,资源复用,方便管理。线程池的实现也是为了方便管理线程,复用现有线程,节省线程资源开销,避免线程过多时cpu浪费大量时间在线程的切换上。
当我们使用线程池执行任务时,会经历如下流程:

上图就是线程池的大概的工作流程,看了上面的图,大概就对线程池的参数的意义有了大概的了解了。
线程池的创建
线程池的创建可以通过new ThreadPoolExecutor()来实现。
package com.xiazhi.pool;
import java.util.concurrent.*;
/**
* @author 赵帅
* @date 2021/1/20
*/
public class ExecutorCreateDemo {
public static void main(String[] args) {
// 如果不指定threadFactory,会使用默认的线程工厂 Executors.defaultThreadFactory()
// 如果不指定拒绝策略,会使用默认的拒绝策略 new AbortPolicy()
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(4,
8,
60,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100));
}
}
java通过Executors类默认实现了几个线程池:
-
Executors.newSingleThreadExecutor(): 这是一个单线程的线程池,实现方式为public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }可以看到也是通过new ThreadPoolExecutor的方式实现,不过这个线程池的核心线程数和最大线程数都是1,因此里面永远只有一个线程。而且他的等待队列为
LinkedBlockingQueue, 这个队列是无界队列,当任务的生产速度大于消费速度时,队列就会不停的堆积,容易造成内存溢出。只有一个队列,为什么要使用线程池?
可以使用线程池来管理这个线程的生命周期。
使用方式:
@Test public void singleThreadExecutor() { ExecutorService executorService = Executors.newSingleThreadExecutor(); executorService.execute(() -> System.out.println("hello world")); } -
Executors.newFixedThreadPool(int size): 创建一个固定数量的线程池。实现为:public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }可以看到,在创建线程池时,核心线程数和最大线程数一样,而且使用的也是
LinkedBlockingQueue,使用的弊端与上面一样,容易造成内存溢出。使用方式:
@Test public void fixedThreadPool() { ExecutorService service = Executors.newFixedThreadPool(5); service.execute(() -> System.out.println("hello world")); } -
Executors.newCachedThreadPool(): 创建一个缓存线程池。此线程池的实现方式为:public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }可以看到这个线程池的核心线程数为0,最大线程数为
Integer.MAX_VALUE,可以认为最大线程数是无界的。存活时间是60秒,如果线程超过60秒没有新的任务,那么就会被销毁。使用的是SynchronousQueue。分析队列为SynchronousQueue,也就以为着每次又一个任务到达时,就必须有一个线程处理这个任务,否则就会阻塞等待。那么当一个任务到达时,如果没有空闲线程,就会不断的创建新的线程,而最大线程数为无界,当任务生产速度大于消费速度时就会增加资源耗尽的风险。而且线程数比较大时也会增加上下文切换的开销,最终造成cpu的时间全都浪费在线程切换上,最终反而降低性能。使用方式:
@Test public void cachedThreadPool() { ExecutorService executorService = Executors.newCachedThreadPool(); executorService.execute(() -> System.out.println("hello world")); } -
Executors.newScheduledThreadPool(): 创建一个定时线程池。实现为:public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue()); }最大线程数仍为
Integer.MAX_VALUE,因此会有资源耗尽的风险,而且线程存活时间为0,线程复用率低。使用方式:
@Test public void scheduledThreadPool() throws InterruptedException { ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(5); scheduledExecutorService.schedule(() -> System.out.println("hello world"), 10, TimeUnit.SECONDS); TimeUnit.SECONDS.sleep(20); }
上面集中线程池的创建方式虽然方便,但是都有缺陷,而且都会造成资源耗尽的风险。
阿里巴巴代码规约规定:禁止通过Executors创建线程池,必须通过new ThreadPoolExecutor的方式创建线程池。除了因为Executors创建的线程池存在上面的缺陷外,Executors隐藏了线程池的创建细节参数,可读性差,而且会影响初学者。
线程工厂
线程池在创建时需要手动指定线程工厂,线程工厂是为了创建线程时为线程指定名字,出问题时方便排查错误。Executors提供了一个默认的线程工厂的实现:
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
但是这个默认工厂的实现,但是在实际使用中为了能够在出问题时能够方便快速的定位,需要定义一个有意义的线程名。因此需要自定义线程工厂实现。
ThreadGroup
在DefaultThreadFactory中我们看到一个ThreadGroup的类,ThreadGroup--线程组。
我们可以把线程归属到某个线程组中,线程组中可以包含多个线程组,线程和线程组间组成树状关系。使用线程组可以方便我们管理线程。

查看ThreadGroup的构造方法:
public ThreadGroup(String name) {
this(Thread.currentThread().getThreadGroup(), name);
}
public ThreadGroup(ThreadGroup parent, String name) {
this(checkParentAccess(parent), parent, name);
}
可以指定父线程组创建线程组,当不指定父线程组时,使用当前线程作为父线程组。
创建线程关联线程组:
package com.xiazhi.pool;
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2021/1/20
*/
public class ThreadGroupDemo {
static void run() {
try {
TimeUnit.SECONDS.sleep(4);
} catch (InterruptedException e) {
System.out.println("线程被中断");
}
System.out.println("hello threadGroup");
}
public static void main(String[] args) {
// 使用new ThreadGroup()
ThreadGroup threadGroup = new ThreadGroup("test-group-1");
ThreadGroup subGroup = new ThreadGroup(threadGroup, "test-group-1");
// 创建线程时指定线程组
new Thread(threadGroup, ThreadGroupDemo::run, "thread-1").start();
new Thread(threadGroup, ThreadGroupDemo::run, "thread-2").start();
new Thread(subGroup, ThreadGroupDemo::run, "sub-thread-1").start();
// 获取活动线程数及线程组数
System.out.println("threadGroup.activeCount() = " + threadGroup.activeCount());
// 活动线程组数
System.out.println("threadGroup.activeGroupCount() = " + threadGroup.activeGroupCount());
// 打印线程组名称
System.out.println("threadGroup.getName() = " + threadGroup.getName());
// 输出线程组的所有子节点
threadGroup.list();
// 调用interrupt方法会将线程组的所有线程中断标志设置为true
threadGroup.interrupt();
}
}
自定义线程工厂
自定义线程工厂需要实现ThreadFactory接口。
package com.xiazhi.pool;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author 赵帅
* @date 2021/1/20
*/
public class SimpleThreadFactory implements ThreadFactory {
/** 线程自增id */
private final AtomicInteger number = new AtomicInteger(0);
/** 归属线程组 */
private final ThreadGroup group;
/** 线程名前缀 */
private final String prefix;
public SimpleThreadFactory() {
this.group = new ThreadGroup("test-group");
this.prefix = "pool-test-thread";
}
@Override
public Thread newThread(Runnable task) {
Thread thread = new Thread(this.group, task,
this.prefix + this.number.incrementAndGet());
if (thread.isDaemon()) {
thread.setDaemon(false);
}
return thread;
}
}
守护线程
在上面的代码中我们注意到有这么一句代码。
if (thread.isDaemon()) {
thread.setDaemon(false);
}
这段代码的意思是:判断当前线程是否是守护线程,如果是守护线程,那么就将当前线程设置为正常线程。
什么是守护线程?
守护线程是一个特殊的线程,当进程中不存在非守护线程时,守护线程就会销毁。jvm中的垃圾回收器就是守护线程,当jvm中没有运行中的非守护线程时,jvm就会退出。
守护线程的用法如下:
package com.xiazhi.pool;
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2021/1/20
*/
public class DaemonThreadDemo {
static void daemonRun() {
while (true) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("守护线程运行");
}
}
public static void main(String[] args) {
Thread daemon = new Thread(DaemonThreadDemo::daemonRun);
daemon.setDaemon(true);
Thread thread = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "开始执行");
try {
// 模拟线程处理业务耗时
TimeUnit.SECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "执行结束");
});
thread.start();
daemon.start();
}
}
线程池的拒绝策略RejectedExecutionHandler
根据上面的线程池执行的流程图,可以知道当线程池的等待队列已满,而且线程池已经达到最大线程数,那么后面再来的任务就回调用拒绝策略处理。java线程池默认提供了4种拒绝策略:
AbortPolicy: 抛出异常处理。当线程进入拒绝策略时,就会抛出RejectedExecutionException异常。DiscardPolicy: 丢弃被拒绝的任务。DiscardOldestPolicy: 丢弃最老的未被处理的任务。CallerRunsPolicy: 调用线程处理。谁提交的这个任务,那么就叫给这个线程处理。
上面四种线程拒绝策略,无论哪儿一种,再生产环境时都是不可取的,我们在工作中,一般都会自定义拒绝策略,将任务存入mq或存入其他地方,等待线程池空闲时执行。但是不能不执行。
自定义拒绝策略:
自定义拒绝策略只需要实现RejectedExecutionHandler接口。
package com.xiazhi.pool;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.RejectedExecutionHandler;
import java.util.concurrent.ThreadPoolExecutor;
/**
* @author 赵帅
* @date 2021/1/21
*/
public class MessageQueuePolicy implements RejectedExecutionHandler {
/** 模拟为mq容器,拒绝任务会被放入容器中 */
public final List<CustomTask> list = new ArrayList<>();
static class CustomTask implements Runnable, Serializable {
private final String name;
public CustomTask(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println(String.format("[%s]处理任务:%s", Thread.currentThread().getName(), name));
}
}
@Override
public void rejectedExecution(Runnable runnable, ThreadPoolExecutor executor) {
// 线程池未关闭
if (!executor.isShutdown()) {
System.out.println("进入线程拒绝策略...");
CustomTask task = (CustomTask) runnable;
list.add(task);
}
}
}
创建一个自定义线程工厂及拒绝策略的线程池
package com.xiazhi.pool;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* @author 赵帅
* @date 2021/1/21
*/
public class CustomThreadPoolDemo {
private final ExecutorService executorService;
public CustomThreadPoolDemo() {
executorService = new ThreadPoolExecutor(3,
3,
0L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10),
new SimpleThreadFactory(),
new MessageQueuePolicy());
}
public static void main(String[] args) {
CustomThreadPoolDemo poolDemo = new CustomThreadPoolDemo();
for (int i = 0; i < 20; i++) {
poolDemo.executorService.execute(new MessageQueuePolicy.CustomTask("张三"));
}
}
}
线程池的使用
线程池ThreadPoolExecutor实现了ExecutorService接口,而ExecutorService接口又继承了Executor接口,线程池的常用方法有:
void execute(Runnable command): 提交Runnable任务Future<?> submit(Runnable task): 提交Runnable任务并返回代表该任务的Future,任务成功完成后,调用Future的get()方法将返回null。Future<?> submit(Runnable task, T result): 提交Runnable任务并返回代表该任务的Future, 任务完成后调用Future的get()方法将返回给定的result。Future<T> submit(Callable<T> task): 提交带返回值的任务并返回代表该任务的Future,任务执行完成后调用Future的get()方法获取任务执行返回值。void shutdown(): 启动关闭线程池。在线程池关闭过程中,会继续执行已经提交的任务(包含等待队列中的任务),但是不会接收新的任务,当所有任务都执行完毕,线程池关闭。如果线程池已经关闭,再次调用不会有影响。List<Runnable> shutdownNow(): 马上关闭线程池。暂停所有正在执行的任务,暂停正在等待的任务的处理,并返回正在等待执行的任务列表。会给所有正在执行的线程发送interrupt()中断消息。boolean isShutdown(): 线程池是否关闭。返回是否在执行线程池的关闭程序,也可以说返回是否调用过shutdown()方法。boolean isTerminated(): 线程池是否终止。isShutdown()方法返回的是是否线程池调用过shutdown()或shutdownNow()方法,而无论调用哪儿个方法线程池都不会立即完毕,会处理完当前线程的任务或设置线程中断。无论哪儿种方式,都是无法立即结束线程的。而此方法返回的就是当前线程池中是否还有存活的线程。线程的生命周期,终止状态为Terminate,当线程池中所有线程的状态都为Terminate时,返回true。boolean awaitTermination(long timeout, TimeUnit unit): 等待终止,如果超时,立即终止List<Future<T>> invokeAll(Collection< ? extend Callable<T>> tasks): 批量执行任务,并返回代表人物的Future集合。T invokeAny(Collection<? extend Callable<T>> tasks): 批量执行任务,当有一个任务有执行结果时,返回此结果并取消其他的任务。
下面进入方法实践:
package com.xiazhi.pool;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.*;
/**
* @author 赵帅
* @date 2021/1/21
*/
public class UseThreadPoolDemo {
private static ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(3,
5,
0L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(20),
new SimpleThreadFactory());
static void runCommand() {
try {
TimeUnit.SECONDS.sleep(2);
System.out.println(String.format("[%s]开始执行command", Thread.currentThread().getName()));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
static String runTask() {
try {
TimeUnit.SECONDS.sleep(2);
System.out.println(String.format("[%s]开始执行task", Thread.currentThread().getName()));
} catch (InterruptedException e) {
e.printStackTrace();
}
return "hello world";
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 提交无返回值的Runnable任务
poolExecutor.execute(UseThreadPoolDemo::runCommand);
// 等待线程执行结束
TimeUnit.SECONDS.sleep(3);
System.out.println("============================================================");
// submit提交Runnable返回null值得任务
Future<?> result = poolExecutor.submit(UseThreadPoolDemo::runCommand);
System.out.println("submit(Runnable) result= " + result.get());
System.out.println("============================================================");
// 当任务执行结束返回指定返回值
Future<String> successful = poolExecutor.submit(UseThreadPoolDemo::runCommand, "successful");
System.out.println("successful.get() = " + successful.get());
System.out.println("============================================================");
// 提交带返回值得Callable任务
Future<String> submit = poolExecutor.submit(UseThreadPoolDemo::runTask);
System.out.println("submit.get() = " + submit.get());
System.out.println("============================================================");
// 批量提交任务执行任务,返回批量结果
List<Callable<String>> tasks = new ArrayList<>();
for (int i = 0; i < 10; i++) {
tasks.add(UseThreadPoolDemo::runTask);
}
List<Future<String>> futures = poolExecutor.invokeAll(tasks);
for (Future<String> future : futures) {
System.out.println("future.get() = " + future.get());
}
System.out.println("============================================================");
// 批量提交任务,成功任意一个取消其他任务
List<Callable<String>> anyTasks = new ArrayList<>();
for (int i = 0; i < 10; i++) {
tasks.add(UseThreadPoolDemo::runTask);
}
String resultStr = poolExecutor.invokeAny(tasks);
System.out.println("resultStr = " + resultStr);
System.out.println("============================================================");
// 关闭线程池
poolExecutor.shutdown();
System.out.println("poolExecutor.isShutdown() = " + poolExecutor.isShutdown());
System.out.println("============================================================");
System.out.println("poolExecutor.isTerminated() = " + poolExecutor.isTerminated());
System.out.println("============================================================");
TimeUnit.SECONDS.sleep(3);
System.out.println("poolExecutor.isTerminated() = " + poolExecutor.isTerminated());
}
}
线程池的大小设置
线程池的线程数大小是否越大越好?
在回答这个问题前先看下面代码:
package com.xiazhi.pool;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 要使用线程池启用多线程对一个数进行自增,从0加到1_000_000
*
* @author 赵帅
* @date 2021/1/21
*/
public class PoolThreadNumDemo {
/**
* 方式1,启动100个线程每隔线程加10_000
*/
public static void way1() throws InterruptedException, ExecutionException {
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(10, 100, 30L,
TimeUnit.SECONDS, new ArrayBlockingQueue<>(10));
AtomicInteger num = new AtomicInteger();
ArrayList<Callable<Integer>> callables = new ArrayList<>();
for (int i = 0; i < 100; i++) {
callables.add(() -> {
for (int j = 0; j < 10_000; j++) {
num.incrementAndGet();
}
return num.get();
});
}
long start = System.nanoTime();
List<Future<Integer>> futures = poolExecutor.invokeAll(callables);
for (Future<Integer> future : futures) {
future.get();
}
System.out.println(String.format("way1调用总耗时:%s,结果:%s", (System.nanoTime() - start), num.get())); // 耗时:82152778
}
/**
* 方式2,启动10个线程每隔线程加1_000_000
*/
public static void way2() throws InterruptedException, ExecutionException {
int core = Runtime.getRuntime().availableProcessors();
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(4, core + 1, 30L,
TimeUnit.SECONDS, new ArrayBlockingQueue<>(10));
AtomicInteger integer = new AtomicInteger(0);
ArrayList<Callable<Integer>> callables = new ArrayList<>();
for (int i = 0; i < 10; i++) {
callables.add(() -> {
for (int j = 0; j < 100_000; j++) {
integer.incrementAndGet();
}
return integer.get();
});
}
long start = System.nanoTime();
List<Future<Integer>> futures = poolExecutor.invokeAll(callables);
for (Future<Integer> future : futures) {
future.get();
}
System.out.println(String.format("way2调用总耗时:%s,结果:%s", (System.nanoTime() - start), integer.get()));// 耗时:32637464
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
way1();
way2();
}
}
通过上面代码可以知道并不是线程越多越好,因为线程越多带来的后果就是线程切换频繁,cpu时间都耗费在线程切换上,cpu的利用率也就变相的降低了。
那么线程数如何设置:
线程数的设置与电脑配置,也就是CPU核数有关,还要关联业务。一般可以根据公式估算线程数:
线程数=N*cpu利用率*(1+等待时间/计算时间)
当然这个公式只能作为估算值,具体的值需要根据业务以及压测结果进行调整。
线程池的拓展
线程池提供了钩子函数,可以在线程执行前,执行后,以及线程池销毁时对线程池进行自定义扩展。
package com.xiazhi.pool;
import java.util.concurrent.*;
/**
* @author 赵帅
* @date 2021/1/21
*/
public class ThreadPoolExecutorProvider extends ThreadPoolExecutor {
public ThreadPoolExecutorProvider(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
}
@Override
protected void beforeExecute(Thread t, Runnable r) {
System.out.println("线程执行前执行");
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
System.out.println("线程执行后执行");
}
@Override
protected void terminated() {
System.out.println("线程池被终止");
}
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutorProvider(1,
1,
0L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10),
Executors.defaultThreadFactory(),
new AbortPolicy());
executor.execute(() -> System.out.println("执行任务。。。"));
executor.shutdown();
}
}
线程池源码阅读
线程池代码中有一个属性:private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));这个属性是AtomicInteger类型,因此是原子性的。而且初始值为:initialValue = ctlOf(RUNNING,0)。继续查看源码:RUNNINT = -1<<29,那么最终RUNNING的值为11100000000000000000000000000000,可以注意到前三位是1,后面都是0。
继续看ctlOf(RUNNING,0)方法内部:private static int ctlOf(int rs, int wc) { return rs | wc; },那么最终ctl属性的初始值就是:11100000000000000000000000000000,其中后29位表示的是当前线程池中的线程数,而前3位表示线程池的状态。这些可以从代码中看出:
private static final int CAPACITY = (1 << COUNT_BITS) - 1; // 00011111111111111111111111111111
// 获取当前线程池状态
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 获取当前线程池中线程数量
private static int workerCountOf(int c) { return c & CAPACITY; }
到目前为止,我们可以得出线程池可以存放的最大线程数为00011111111111111111111111111111既2^29-1=536870911个线程。
查看线程池的execute(Runnable command)方法的源码:
public void execute(Runnable command) {
// 要执行的任务不能是null
if (command == null)
throw new NullPointerException();
// 获取ctl的值
int c = ctl.get();
// 获取当前线程数
if (workerCountOf(c) < corePoolSize) {
// 当前线程数小于核心线程数,直接添加新的线程,结束
if (addWorker(command, true))
return;
// 再次获取ctl的值,避免在此期间线程的状态被改变,保证数据的准确性
c = ctl.get();
}
// 当线程走到这里,说明当前线程池核心线程数已经满了
// 线程池状态为运行中并且向等待队列插入任务成功
if (isRunning(c) && workQueue.offer(command)) {
// 再次获取ctl值,保证获取最新值
int recheck = ctl.get();
// 当前线程池是关闭状态,那么从队列中移除这个任务并拒绝
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果线程池不是关闭状态或者移除队列任务失败,那么获取当前线程数,如果是0就添加一个空的worker
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 插入等待队列失败,新建线程处理
else if (!addWorker(command, false))
// 新建任务失败,说明达到最大线程数,调用拒绝策略
reject(command);
}
可以看出上面的流程分析与最开始画的线程池工作流程图是一样的,不过在细节上添加了很多判断当前线程池状态的操作。可以看出在代码中多次重新获取ctl值,用来获取当前线程池状态以及当前线程数。那么为什么要用一个值即表示线程池状态又表示线程数呢?
如果将这两个数拆出来拆成两个值,那么就需要不断的刷新两个数据的值,也就是说上面不断的获取ctl值需要获取两个值了,那么假设这种情况,我获取线程池状态,状态为运行中,然后我获取当前线程数,假设此时线程池关闭了,那么此时是不知道的,就会造成获取到的状态不是实时状态,而使用一个数操作,不仅操作方便,而且也避免了数据实时性的问题。(仅代表个人理解,如果有高见请指出)
然后我们在看上面代码,是通过addWorker(Runnable command,boolean core)方法来向线程池添加线程的。
- 参数command:要执行的任务
- 参数core: 是否是核心线程,因为核心线程是不会销毁的,而不是核心线程,当空闲时间超过存活时间会自动销毁。
查看addWorker方法:
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
// 自旋,保证修改当前线程数一定能成功
for (;;) {
// 获取线程池状态,如果线程池已经被关闭,那么就不添加到线程池了
int c = ctl.get();
int rs = runStateOf(c);
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
// 如果超过线程数限制返回失败,是核心线程就比较核心线程数,不是核心线程就比较最大线程数
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 线程数+1
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// 走到这里才真正想线程池中添加线程
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 创建一个新的线程,线程池中使用Worker创建线程,并将当前任务作为线程的第一个任务
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// 将线程添加到线程池
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
// 启动线程
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
上面创建线程池中的线程使用的是Worker来创建线程。那么创建的Worker都存放在线程池,线程池的实现就是:private final HashSet<Worker> workers = new HashSet<Worker>();这个hashSet就是线程池。查看Worker的代码:
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
// 设置状态为-1表示此worker为新建状态,还未开启线程,不支持中断
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
// Lock methods
//
// The value 0 represents the unlocked state.
// The value 1 represents the locked state.
protected boolean isHeldExclusively() {
return getState() != 0;
}
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}
可以看出Worker也继承自AQS,我们学习AQS时说AQS的核心就是state。在线程池中这个state就代表当前线程是否被使用。而且Worker也实现了Runnable接口,因此它自身就是一个线程任务,他内部的属性Thread在创建时调用了线程工程创建一个新线程。因此说一个Worker就是代表了一个可执行线程。而且这个可执行线程的run方法是:
public void run() {
runWorker(this);
}
查看runWorker方法:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
// 获取当前线程的第一个任务并将firstTask属性设置为null(也就是取出了worker的第一个任务)
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// 如果worker的第一个任务不等于空 或者 从等待队列取到的任务不是空
while (task != null || (task = getTask()) != null) {
// 执行线程的run方法。
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
//调用钩子函数
beforeExecute(wt, task);
Throwable thrown = null;
try {
//运行run方法
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 调钩子函数
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// 控制线程退出
processWorkerExit(w, completedAbruptly);
}
}
在runWorker方法中我们学习到了线程池是如何复用线程的。当一个worker的线程被启动时,会调用runWorker方法,然后内部流程为:
- 取出worker的firstTask。
- firstTask是否为空,如果为空则跳至4。
- 执行firstTask的run方法。
- 从等待队列取出task,如果task不为空则跳至2,如果为空则往下。
- 控制线程退出。
流程图如下:
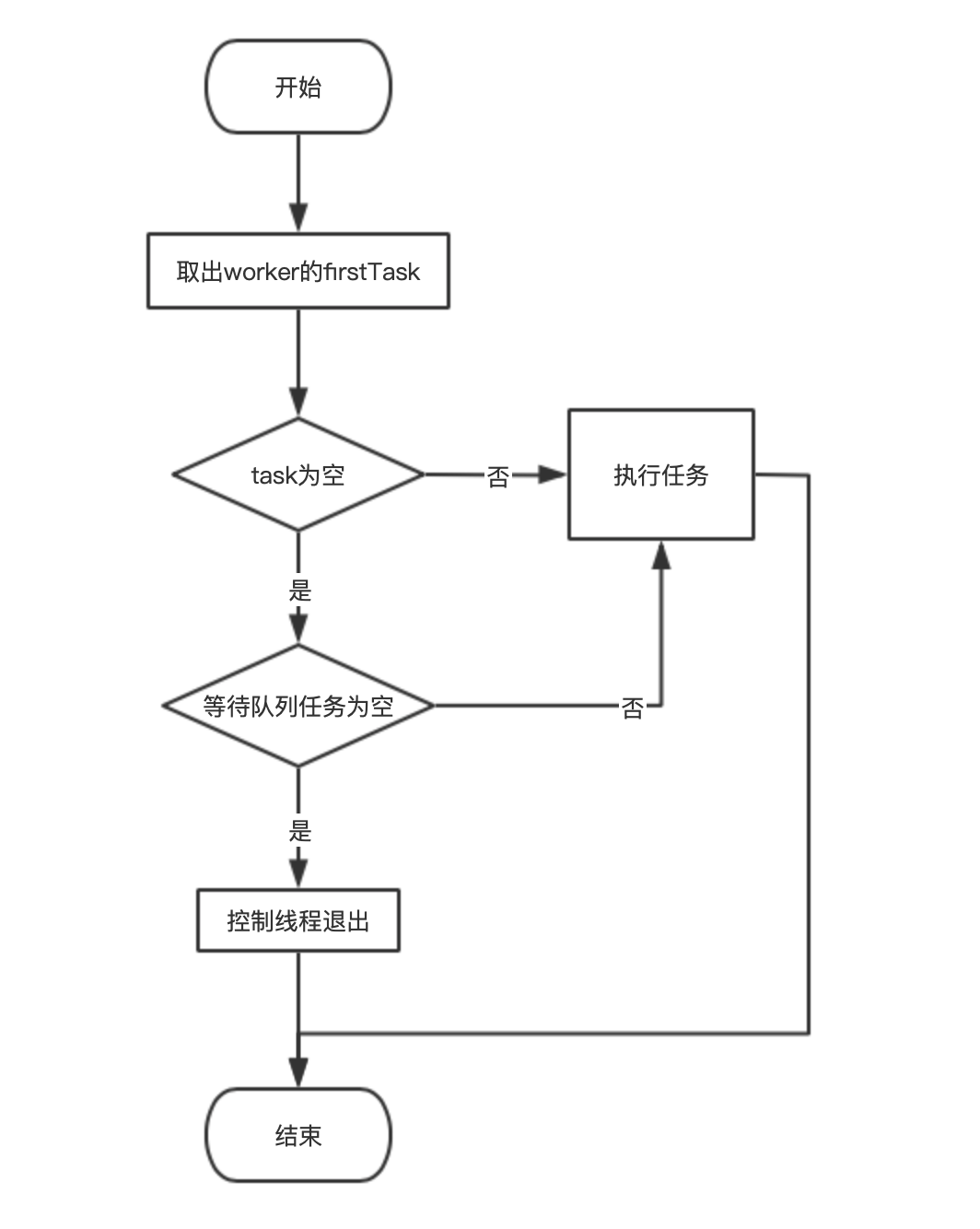
如果程序运行过程中出现异常,或者等待队列为空时就要退出异常线程或空闲线程。退出空闲线程的流程为:
- 当前线程是否需要退出(异常结束线程直接退出)
- 从线程池移除当前线程
- 如果当前线程池的线程数小于核心线程数,那么添加一个任务为空的worker
ExecutorCompletionService
在我们执行有返回值的任务时,会返回一个Future类型,可以通过future.get()方法获取返回值,但是这个get()方法时阻塞的。因此就可能会出现其他任务已经完成结果,但是我们还在阻塞等待前一个任务的结果。这样算是间接的浪费了时间。查看如下代码:
package com.xiazhi.pool;
import java.util.concurrent.*;
/**
* 假设我们现在在网上购买了电器: 电视,冰箱,洗衣机。这三个东西是一块发货的,因此可以认为这就是一个异步执行。
* 冰箱: 发货 -> 收货 10s
* 洗衣机: 发货-> 收货 15s
* 电视: 发货 -> 收货 8s
* 我们将电器从楼下搬到楼上的时间为3s
*
* @author 赵帅
* @date 2021/1/22
*/
public class NormalExecutorService {
/**
* 为了方便使用Executors,实际工作不建议使用
*/
final ExecutorService executorService = Executors.newFixedThreadPool(3);
static void transport(String shop) {
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("搬运" + shop);
}
/**
* 运输冰箱
*/
static String transportFridge() {
try {
TimeUnit.SECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("冰箱到了");
return "冰箱";
}
/**
* 运输电视
*/
static String transportTV() {
try {
TimeUnit.SECONDS.sleep(8);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("电视到了");
return "TV";
}
/**
* 运输洗衣机
*/
static String transportWashing() {
try {
TimeUnit.SECONDS.sleep(15);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("洗衣机到了");
return "洗衣机";
}
/**
* 根据上面的题意,如果我们用正常的Future.get()方法去实现的话:
*/
void way1() throws ExecutionException, InterruptedException {
long start = System.currentTimeMillis();
Future<String> fridge = executorService.submit(NormalExecutorService::transportFridge);
Future<String> washing = executorService.submit(NormalExecutorService::transportWashing);
Future<String> tv = executorService.submit(NormalExecutorService::transportTV);
transport(fridge.get());
transport(washing.get());
transport(tv.get());
System.out.println("从下单到搬运到家共计耗时:" + (System.currentTimeMillis() - start));
executorService.shutdown();
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
NormalExecutorService service = new NormalExecutorService();
service.way1();
}
}
根据执行结果可以看出,电视先到了,但是并没有先把电视机搬上楼,而是等待冰箱到了之后才搬运冰箱,然后等待洗衣机到搬运洗衣机,最后才搬运电视。总共耗时21秒。
或许我们会想调换get的顺序,先搬运电视不就好了。现在是我们知道每个任务的时间,我们或许可以调整,但是在实际工作中,大多数并行情况我们并不能确定执行的时间(网络延迟等影响),因此我们也就无法确定我们应该先等待哪儿个到达。
正确的处理思路是先到哪儿个先搬哪儿个。ExecutorCompletionService就是这样的一个作用。我们使用ExecutorCompletionService实现上面的过程:
package com.xiazhi.pool;
import java.util.concurrent.*;
/**
* 假设我们现在在网上购买了电器: 电视,冰箱,洗衣机。这三个东西是一块发货的,因此可以认为这就是一个异步执行。
* 冰箱: 发货 -> 收货 10s
* 洗衣机: 发货-> 收货 15s
* 电视: 发货 -> 收货 8s
* 我们将电器从楼下搬到楼上的时间为3s
*
* @author 赵帅
* @date 2021/1/22
*/
public class ExecutorCompolationServiceDemo {
/**
* 为了方便使用Executors,实际工作不建议使用
*/
final ExecutorService executorService = Executors.newFixedThreadPool(3);
static void transport(String shop) {
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("搬运" + shop);
}
/**
* 运输冰箱
*/
static String transportFridge() {
try {
TimeUnit.SECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("冰箱到了");
return "冰箱";
}
/**
* 运输电视
*/
static String transportTV() {
try {
TimeUnit.SECONDS.sleep(8);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("电视到了");
return "TV";
}
/**
* 运输洗衣机
*/
static String transportWashing() {
try {
TimeUnit.SECONDS.sleep(15);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("洗衣机到了");
return "洗衣机";
}
/**
* 使用executorCompletionService实现
*/
void way2() throws ExecutionException, InterruptedException {
ExecutorCompletionService<String> completionService = new ExecutorCompletionService<>(executorService);
long start = System.currentTimeMillis();
completionService.submit(NormalExecutorService::transportFridge);
completionService.submit(NormalExecutorService::transportWashing);
completionService.submit(NormalExecutorService::transportTV);
for (int i = 0; i < 3; i++) {
transport(completionService.take().get());
}
System.out.println("从下单到搬运到家共计耗时:" + (System.currentTimeMillis() - start));
executorService.shutdown();
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorCompolationServiceDemo service = new ExecutorCompolationServiceDemo();
service.way2();
}
}
可以看到执行时间在18秒,提高了3秒。
ForkJoinPool
forkjoin是指任务的拆分和合并。forkJoinPool会将一个任务拆分成多个任务队列,也就是fork,每一个任务队列是一个线程,当一个任务队列中的任务执行完之后,会从其他任务队列中偷取任务执行,然后执行结果再进行合并也就是join。java8新特性中的并行流就是通过forkJoinPool实现的。
package com.xiazhi.pool;
import java.util.Arrays;
/**
* @author 赵帅
* @date 2021/1/22
*/
public class ParallelStreamDemo {
static String[] array = new String[1_000_000];
public static void main(String[] args) {
for (int i = 0; i < array.length; i++) {
array[i] = "hello" + i;
}
Arrays.stream(array).parallel().forEach(f->{
System.out.println(Thread.currentThread().getName() + ":value:" + f);
});
}
}
观察结果可以看到启动了很多的线程。
九、 Disruptor
数据的内存结构只有数组和链表,线程安全的非阻塞队列,链表实现有ConcurrentLinkedQueue,但是却没有数组的实现,因为数组的扩张需要创建新的数组并复制元素,效率非常低。
Disruptor是使用数组实现的,内部使用的RingBuffer。特性有:高并发,无锁,直接覆盖旧的数据(降低GC频率),是基于事件的生产者消费者模式实现。
Disruptor的使用
- 事件:向disruptor数组中存放的元素。
- 事件工厂:用来生成事件对象。disruptor为了提升效率,会在初始化时就向数组中提前初始化填充好每一个位置的元素,这样当生产者进来只需要覆盖当前位置元素的属性,避免创建对象,降低GC频率,也就是复用对象。
- 事件处理器:消费事件对象。
定义事件
package com.xiazhi.disrupter;
/**
* @author 赵帅
* @date 2021/1/22
*/
public class LongEvent {
private long value;
public LongEvent() {
}
public long getValue() {
return value;
}
public void setValue(long value) {
this.value = value;
}
@Override
public String toString() {
return "LongEvent{" +
"value=" + value +
'}';
}
}
定义事件工厂
package com.xiazhi.disrupter;
import com.lmax.disruptor.EventFactory;
/**
* @author 赵帅
* @date 2021/1/22
*/
public class LongEventFactory implements EventFactory<LongEvent> {
@Override
public LongEvent newInstance() {
return new LongEvent();
}
}
定义消费者
package com.xiazhi.disrupter;
import com.lmax.disruptor.EventHandler;
/**
* @author 赵帅
* @date 2021/1/22
*/
public class LongEventPolicy implements EventHandler<LongEvent> {
@Override
public void onEvent(LongEvent longEvent, long sequence, boolean endOfBatch) throws Exception {
System.out.println(String.format("[%s]:value=%d:sequence=%d:b=%s", Thread.currentThread().getName(), longEvent.getValue(), sequence, endOfBatch));
}
}
使用Disruptor
package com.xiazhi.disrupter;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.Disruptor;
import java.util.concurrent.Executors;
/**
* @author 赵帅
* @date 2021/1/22
*/
public class DisruptorDemo {
public static void main(String[] args) {
// 创建disruptor容器
Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(new LongEventFactory(), 8, Executors.defaultThreadFactory());
// 设置消费者,当有多个消费者时传多个参数,每一个消费者就是一个线程
// disruptor.handleEventsWith(new LongEventPolicy(), new LongEventPolicy());
disruptor.handleEventsWith(new LongEventPolicy());
// 开始工作
disruptor.start();
// 获取ringBuffer
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
for (int i = 0; i <= 10; i++) {
// 获取下一个可用的序列号
long sequence = ringBuffer.next();
try {
// 获取当前位置元素
LongEvent longEvent = ringBuffer.get(sequence);
// 覆盖属性
longEvent.setValue(100L);
} finally {
//发布此位置事件
ringBuffer.publish(sequence);
}
}
// 关闭容器
disruptor.shutdown();
}
}
Disruptor的工作原理
disruptor的是基于事件实现的,那么就有了生产者(provider)和消费者(consumer)存在,生产者生产元素放入数组中,消费者从数组中消费元素,这个数组就是RingBuffer。每一个生产者和消费者内部都会有一个私有指针pri-sequence,表示当前操作的元素序号,同时RingBuffer内部也会有一个全局指针global-sequence指向最后一个可以被消费的元素。这样当生产者需要放数据时,只需要获取global-sequence的下一个位置,下一个位置如果还未被消费,那么就会进入等待策略,如果下一个位置已经被消费,那么就会直接覆盖当前位置的属性值。
当生产者需要向容器中存放数据时,只需要使用sequence%(数组长度-1)就可以得到要添加的元素应该放在哪儿个位置上,这样就实现了数组的首尾相连。
disruptor初始化时需要指定容器大小,容器大小指定为2^n,计算时可以可以使用位运算:
如果容器大小是8,要放12号元素。12%8 = 12 &(8-1)=1100&0111=0100=4。
使用位运算可以提升效率。
disruptor的8种等待策略:
disruptor使用waitStrategy接口来实现等待策略,当ringbuffer满了的时候,就会调用等待策略。内置实现了8种等待策略:
(常用)BlockingWaitStrategy: 阻塞等待策略BusySpinWaitStrategy: 线程一直自旋等待,可能比较耗费cpu。LiteBlockingWaitStrategy: 线程阻塞等待生产者唤醒,与BlockingWaitStrategy相比,区别在signalNeeded.getAndSet,如果两个线程同时访问一个访问waitfor,一个访问signalAll时,可以减少lock加锁次数.- LiteTimeoutBlockingWaitStrategy:与LiteBlockingWaitStrategy相比,设置了阻塞时间,超过时间后抛异常。
- PhasedBackoffWaitStrategy:根据时间参数和传入的等待策略来决定使用哪种等待策略
- TimeoutBlockingWaitStrategy:相对于BlockingWaitStrategy来说,设置了等待时间,超过后抛异常
(常用)YieldingWaitStrategy:尝试100次,然后Thread.yield()让出cpu。(常用)SleepingWaitStrategy: 睡眠等待。
消费者处理异常
当消费者处理出现异常时,可以通过设置异常处理器来处理异常信息。异常处理器可以通过实现:
package com.xiazhi.disrupter;
import com.lmax.disruptor.ExceptionHandler;
/**
* @author 赵帅
* @date 2021/1/23
*/
public class SimpleLongEventExceptionPolicy implements ExceptionHandler<LongEvent> {
@Override
public void handleEventException(Throwable throwable, long l, LongEvent longEvent) {
throwable.printStackTrace();
System.out.println(longEvent);
}
@Override
public void handleOnStartException(Throwable throwable) {
System.out.println("容器启动异常");
throwable.printStackTrace();
}
@Override
public void handleOnShutdownException(Throwable throwable) {
System.out.println("关闭异常");
throwable.printStackTrace();
}
}
Disruptor容器异常处理器的设置有两种方式:
-
设置默认异常处理器:
disruptor.setDefaultExceptionHandler(exceptionPolicy)SimpleLongEventExceptionPolicy exceptionPolicy = new SimpleLongEventExceptionPolicy(); disruptor.setDefaultExceptionHandler(exceptionPolicy); -
覆盖异常处理器:
disruptor.handleExceptionsFor(eventPolicy).with(exceptionPolicy);disruptor.handleEventsWith(eventPolicy); SimpleLongEventExceptionPolicy exceptionPolicy = new SimpleLongEventExceptionPolicy(); disruptor.handleExceptionsFor(eventPolicy).with(exceptionPolicy);
生产者类型
disruptor为了提升效率,还可以再初始化时配置生产者类型,如果生产者是单线程的,那么就再创建时指定生产者类型为单线程,那么就不用加锁操作,效率会再提升。
Disruptor<LongEvent> disruptor = new Disruptor<>(LongEvent::new,
64,
Executors.defaultThreadFactory(),
ProducerType.SINGLE,
new BlockingWaitStrategy());
ProducerType是一个枚举,取值有:
- SINGLE: 单线程
- MULTI:多线程(默认)
Disruptor对java8lambda的支持
disruptor为了支持java8的lambda,新增了函数式接口:EventTranslator
可以设置一个参数的:EventTranslatorOneArg,
可以设置两个参数的:EventTranslatorTowArg
可以设置三个参数的:EventTranslatorThreeArg
以及可以设置多个参数的:EventTranslatorVararg。
因此可以使用如下方式配置disruptor:
package com.xiazhi.disrupter;
import com.lmax.disruptor.BlockingWaitStrategy;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;
import java.util.Arrays;
import java.util.concurrent.Executors;
/**
* @author 赵帅
* @date 2021/1/23
*/
public class DisruptorLambdaDemo {
public static void main(String[] args) {
Disruptor<LongEvent> disruptor = new Disruptor<>(LongEvent::new,
64,
Executors.defaultThreadFactory(),
ProducerType.SINGLE,
new BlockingWaitStrategy());
disruptor.handleEventsWith(new LongEventPolicy());
disruptor.setDefaultExceptionHandler(new SimpleLongEventExceptionPolicy());
disruptor.start();
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
// 使用lambda发布事件
for (int i = 0; i < 10; i++) {
// 不设置参数的
ringBuffer.publishEvent((longEvent, sequence) -> longEvent.setValue(100L));
// 设置一个参数的
ringBuffer.publishEvent((longEvent, sequence, arg) -> longEvent.setValue(arg), i);
// 设置两个参数的
ringBuffer.publishEvent((longEvent, sequence, var1, var2) -> {
System.out.println(String.format("var1 = %s, var2 = %s", var1, var2));
longEvent.setValue(var1);
}, i, "hello world");
// 设置三个参数的
ringBuffer.publishEvent((longEvent, sequence, var1, var2, var3) -> {
System.out.println(String.format("var1 = %s, var2 = %s, var3 = %s", var1, var2, var3));
longEvent.setValue(var1);
}, i, "hello world", "arg3");
// 设置多个参数的
ringBuffer.publishEvent((longEvent, sequence, vars) -> {
System.out.println("args = " + Arrays.toString(vars));
longEvent.setValue((Integer) vars[0]);
}, i, "hello world", "arg3");
}
disruptor.shutdown();
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义