

linux配置redis
在学习redis之前,先回顾下缓存,在前面的学习中,关于缓存学习了mybatis的缓存
mybatis有一级缓存和二级缓存之分:
一级缓存:一级缓存存在于sqlsession中,是默认开启的,生命周期只在一个会话内,当会话内发生更新数据时(增删改)或会话结束时close(),缓存失效
二级缓存:二级缓存存在与命名空间中(mapper的namespace中),这个命名空间是存在服务器的内存中的(tomcat服务器的内存),当服务器关闭时,缓存失效
无论一级缓存还是二级缓存都不会永远持久化数据到硬盘中,因此mybatis的缓存使用率就会很低,而且使用的范围也很窄(只能使用到对数据库的增删改查)
当拥有的数据量较大时(假如用户表users中有十亿条数据,select * from users,mybatis无法做到大批量数据的查询,连查询都无法做到,数据也绝对不会进入缓存中)
什么样的数据可以进入缓存中?
1.经常使用的数据
2.不会经常发生改变的数据(比如说:身份证号、性别、省市区国家组织等,把经常用到并且不会经常改变的数据存入数据库中的某张表中叫做字典表)
什么是redis?
redis称之为缓存,是一个数据库(非关系型数据库)
关系型数据库:mysql,oracle;表和表之间产生关联,数据与数据之间也有关联,称之为关系型数据库
非关系型数据库:NOSQL,没有sql的数据库,数据与数据之间是独立存在的,没有关系,也没有表的概念(也就是说,在这个数据库中,不能使用sql语句select、update等)
Redis:键值对对应的数据库(数据格式以key和value对应,就像json,redis中存的就是json格式的数据)
redis中的数据类型都有什么?
redis是键值对对应的数据库,因此key只有一种类型String,value有五种类型:
List
Hash
String(使用最对的)
Set(以前的版本中是Map,新版本中是Set)
zSet
Set和zSet的区别:
Set:数据是无序的,且数据是唯一的
zSet:数据是有序的,且数据是唯一的(数据的值是唯一的,会给每个值一个关联一个double类型的score,数据的值不能重复,但是score可以重复)
所有的NOSQL数据库都会在内存中做计算,数据会永久保存在内存中
当redis启动后,redis会自动从磁盘中加载数据,将数据加载入内存中,等待客户端进行查询数据,这样客户端实际是从内存中获取数据,所以效率会非常快。
应用场景:一般只能应用与缓存,因为数据都存在了内存中,所以相应的也非常的消耗内存,
Redis是以集群的形式存在,在官方文档中说明,如果需要配置redis缓存库,至少需要六台(三主三从)
用一个图来描述redis的工作原理:

创建redis的集群,三主三从,每一个主服务器master都有一个随从follower,master主要存放数据,follower监视master是否存活,master与follower之间的数据要保持同步,这样,当master宕机时,follower就会代替master的位置,变成主节点,然后原来的主节点修好后,变成从节点监视,等待现在的主节点宕机后,就会再次成为主节点
redis的缺点:
1.redis必须以集群的形式存在(六台服务器),占用的资源就会非常的多
2.主从之间需要数据的同步,占用的磁盘空间就会非常大,master有十万条数据,follower也要有十万条数据,但是只有master中的数据才会被使用
3.redis是在内存中所运算(10万条数据缓存信息),就会占用非常大的内存
4.因为最终因为redis加载机制问题,硬盘和内存需要进行交互,会占用非常大的CPU
redis的配置:
redis要求配置三主三从,六台服务器,也就需要六台虚拟机,但是电脑配置原因,这里用一台虚拟机,开启六个端口来简单实现:
1.官网下载redis的安装包
2.将redis的安装包通过xftp传输到虚拟机,解压redis安装包
3.编译redis:进入redis主目录,输入命令 make && make install ,redis是用C语言写的,

看到如下内容表示编译成功

4.在redis的目录中创建redis_cluster文件夹
5.在redis_cluster文件夹中创建端口号的文件夹(分别创建6380..6385,redis默认的端口号为6379)

6.创建redis配置文件,在6380文件夹中创建redis.conf文件,内容如下(端口号与ip根据自己的修改)
#端口号 port 6380 #默认ip为127.0.0.1,需要改为其他节点机器可访问的ip,否则创建集群时无法访问对应的端口,无法创建集群 bind 192.168.226.129 #redis后台运行 daemonize yes #pidfile文件对应6380,6381,6382... pidfile /var/run/redis_6380.pid #开启集群,把注释#去掉 cluster-enabled yes #集群的配置,配置文件首次启动自动生成 6380,6381,6382 cluster-config-file nodes_6380.conf #请求超时,默认15秒,可自行设置 cluster-node-timeout 10100 #aof日志开启,有需要就开启,它会每次写操作都记录一条日志 appendonly yes
7.将第6步的文件复制到其他的端口文件夹中,并修改配置文件信息(端口号)
8.启动redis集群(必须在src目录下启动,在其他地方无法启动) ./redis-server ../redis_cluster/6380/redis.conf ,需要启动每一个端口

9.查看集群是否启动成功: ps -ef|grep redis

10.创建redis的缓存库,因为redis是以数据库的形式存在,原理和mysql一样,集群创建成功只能证明redis安装成功了,但是最终redis并没有自带的缓存库,需要自己手动创建
redis-cli --cluster create 192.168.226.129:6380 192.168.226.129:6381 192.168.226.129:6382 192.168.226.129:6383 192.168.226.129:6384 192.168.226.129:6385 --cluster-replicas 1
手动输入yes,看到如下信息表示成功:

11.进入redis的缓存中(也必须在src目录下进行): ./redis-cli -h 192.168.226.129 -c -p 6380
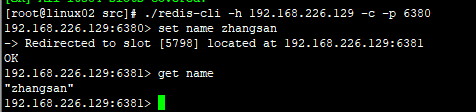
redis的简单存储数据,可以看到,进入6380端口,存入字符串数据时,数据存入了6381端口,也就是说,String类型数据存放在6381端口内
12关闭缓存库: ./redis-cli -h 192.168.226.129 -p 6380 shutdown ,需要关闭每一个端口,全部关闭(pkill redis(不推荐使用))
强调
在redis中是没有修改操作的
只有增删查
如果需要修改的话,需要进行覆盖
新增:
set key(String) value(任意改变(5种))-->返回值是"OK"
查询:
get key(String) --> value(存入的类型)
删除:
del key(String) -->返回值是Integer(受影响的行数)
设置缓存的失效时间:
expire key(String) seconds(秒,Long/Integer)-->返回值是Integer(受影响的行数)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号