

| Q | A |
|---|---|
| 这个项目属于哪个课程 | 2023数据采集与融合技术 |
| 组名、项目简介 | 组名:喵喵队、项目需求:设计出一个交互友好的多源异构数据的采集与融合的小应用 、项目目标:通过在网页中上传文本、图片、视频或音频分析其中的情感 、项目开展技术路线:前端3件套、Python、fastapi |
| 团队成员学号 | 102102143、102102140、102102141、102102152、102102117、102102114、102102121、102102132 |
| 这个项目目标 | 通过在网页中上传文本、图片、视频或音频分析其中的情感 |
项目整体介绍:
项目名称:多模态情感分析系统
项目背景:在当前的数字化时代,情感分析在各种应用中变得越来越重要,如客户服务、市场分析和社交媒体监控。多模态情感分析能够提供比单一模态更丰富、更准确的情感识别和分析。
项目目标:开发一个多模态情感分析系统,能够通过Bv号处理和分析文本、图片、音频和视频数据,从而提供综合的情感分析结果。
技术路线:
-
前端开发:
-
使用HTML、CSS和JavaScript进行界面设计,实现用户与系统的交互。
-
通过用户给出的bv号进行查询
-
-
后端开发:
-
使用Python进行后端逻辑的编写。
-
利用Flask搭建简易后端框架。
-
-
数据处理与分析:
-
文本分析:调用华为云NLP情感分析API。
-
视频分析
- 提取视频中的音频部分。
- 对提取的音频进行分析,使用同音频分析的方法。
-
音频分析
- 使用openai开源的whisper进行音频分析。
- 对上传的音频文件进行特征提取和情感识别。
-
-
结果输出与展示:将分析结果通过前端界面展示。
最终效果:
通过在本地上传文件进行分析并且得到结果
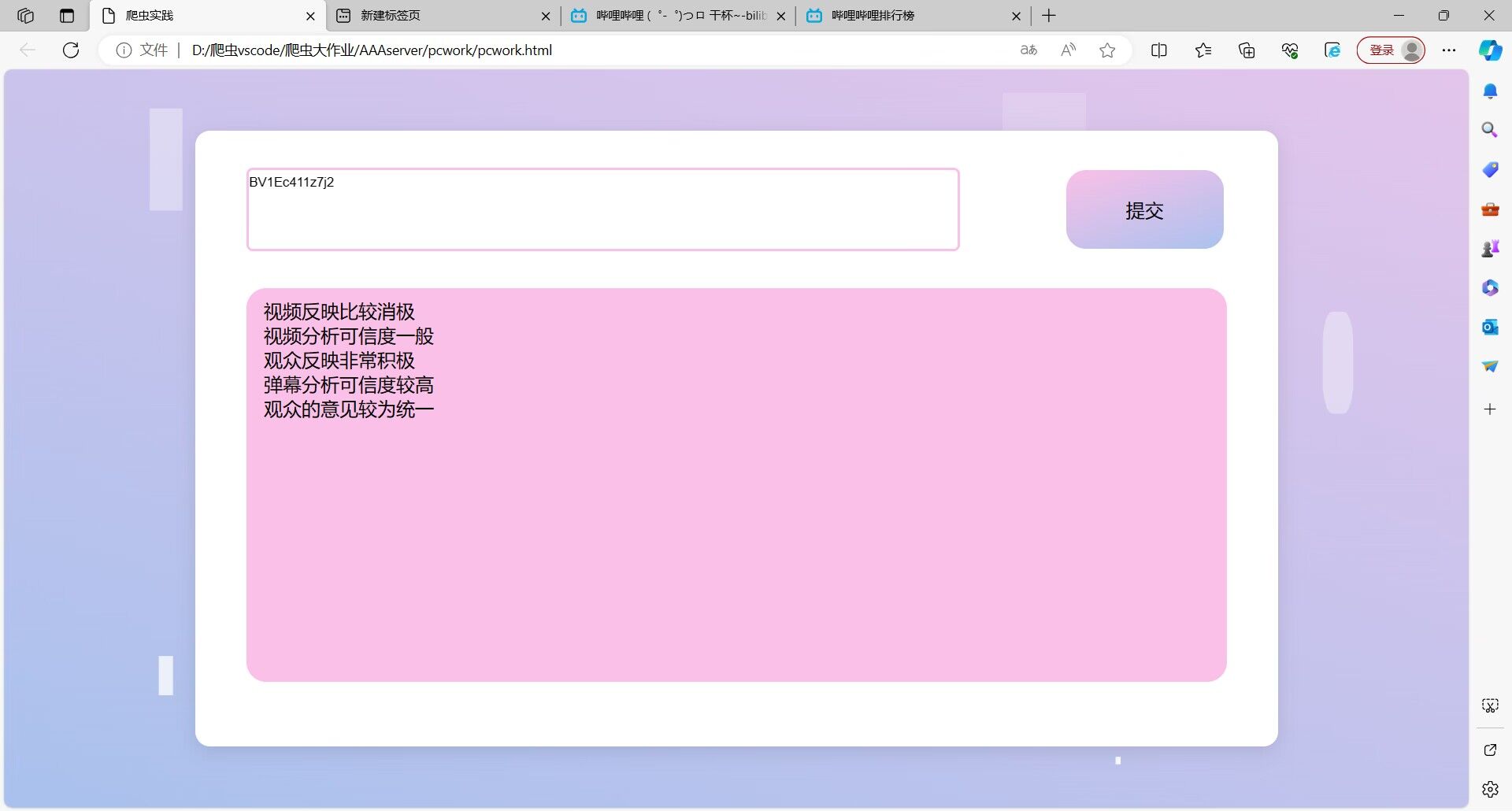
自己分工:
我与嘉禧同学合作开发情感分析部分,代码如下:
from time import sleep
import requests
import json
from datetime import datetime,timedelta
from threading import Thread
import random
class HW_NLP:
token = ''
expires_at = ''
resultMap = {}
def __init__(self) -> None:
self.updateToken()
def updateToken(self):
url = 'https://iam.cn-north-4.myhuaweicloud.com/v3/auth/tokens?nocatalog=false'
header = {
'Content-Type': 'application/json',
}
body = {
"auth": {
"identity": {
"methods": [
"password"
],
"password": {
"user": {
"domain": {
"name": "*******************"
},
"name": "NLP",
"password": "********"
}
},
},
"scope": {
"project": {
"name": "cn-north-4"
}
}
}
}
resp = requests.post(url, data=json.dumps(body), headers=header)
self.token = resp.headers["X-Subject-Token"]
expires_at = resp.json()['token']['expires_at']
expires_at=expires_at.split('.')[0]
self.expires_at = datetime.strptime(expires_at, "%Y-%m-%dT%H:%M:%S")-timedelta(minutes=30)
def nlp(self,content,id):
url = 'https://nlp-ext.cn-north-4.myhuaweicloud.com/v1/b17d60de2dd34882b320ec7af863a3b3/nlu/sentiment'
header = {
'Content-Type': 'application/json',
'X-Auth-Token': self.token
}
body = {
'content': content
}
resp = requests.post(url, data=json.dumps(body), headers=header)
print(resp.json())
self.resultMap[id].append(resp.json())
def nlp_fromList(self,strList:list) -> list:
if self.expires_at < datetime.now():
self.updateToken()
p_id = random.Random()
self.resultMap[p_id] = []
count = 0
s = ''
tPool = []
for str in strList:
# 高情商地讲是以准确率作为代价提高查询效率
if len(s) < 180:
s = s + str
else:
tPool.append(Thread(target=self.nlp,args=(s,p_id)))
s = ''
if len(s) != 0:
tPool.append(Thread(target=self.nlp,args=(s,p_id)))
for t in tPool:
t.start()
count+=1
# 每秒最多调用20次
if count == 5:
sleep(1)
for t in tPool:
t.join()
res = self.resultMap[p_id]
del self.resultMap[p_id]
return res
# example
if __name__ == '__main__':
# nlp()
str = '浑浑噩噩的头脑、失魂落魄的身体…' # 声明:华为官方提供的测试字符串,本人精神极度正常
l = [str]
# 一个程序实例化一个就够了
nlp = HW_NLP()
r = nlp.nlp_fromList(l)
print(r)# 结果:[{'result': {'content': '浑浑噩噩的头脑、失魂落魄的身体…', 'label': 0, 'confidence': 0.90706205}}]

