

数据采集与融合技术实践作业四
gitee仓库链接:gitee仓库链接
102102141 周嘉辉
作业①
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
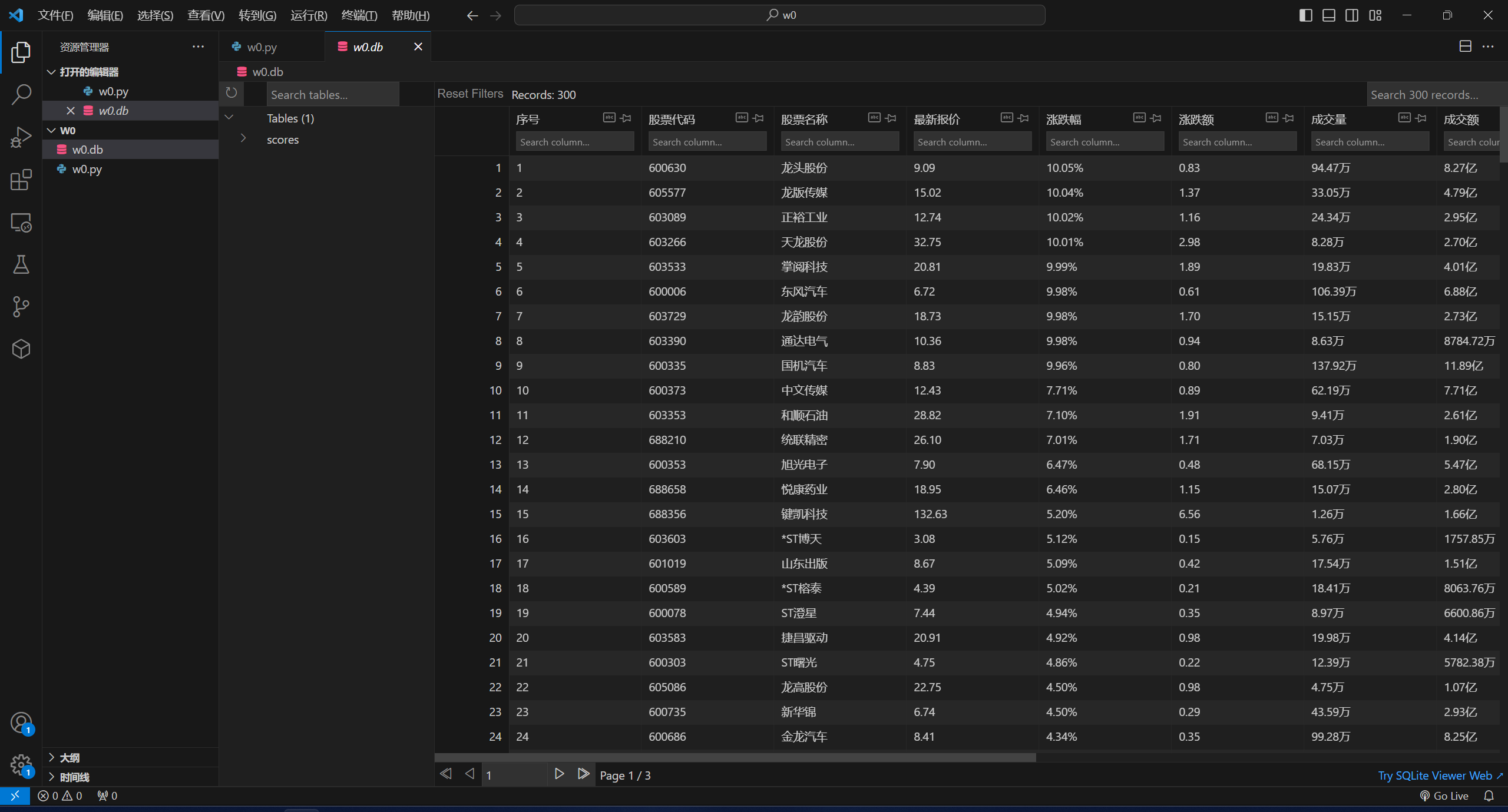
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
代码:
from selenium import webdriver
from selenium.webdriver.edge.options import Options
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.edge.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
import sqlite3
def spider():
index = 1
max_page = driver.find_element(By.CSS_SELECTOR,"#main-table_paginate > span.paginate_page > a:nth-child(5)").text
max_page = eval(max_page)
max_page = 5
print(max_page)
for page in range(max_page):
# WebDriverWait(driver, 10).until(expected_conditions.presence_of_element_located((By.CSS_SELECTOR,"#table_wrapper-table > tbody > tr")))
trlist = driver.find_elements(By.CSS_SELECTOR,"#table_wrapper-table > tbody > tr")
for tr in trlist:
res1 = [str(index)]
index += 1
for i in [2,3,5,6,7,8,9,10,11,12,13,14]:
res1.append(tr.find_element(By.CSS_SELECTOR,"td:nth-child(" + str(i)+ ")").text)
print(res1)
res.append(res1)
if page <= max_page - 2 :
next_button = driver.find_element(By.XPATH,'/html/body/div[1]/div[2]/div[2]/div[5]/div/div[2]/div/a[2]')
webdriver.ActionChains(driver).move_to_element(next_button ).click(next_button ).perform()
time.sleep(1.5)
edge_options = Options()
driver = webdriver.Edge(options=edge_options)
res = []
driver.get("http://quote.eastmoney.com/center/gridlist.html#sh_a_board")
try:
spider()
except Exception as e:
print("------------------------------------error---------------------------------------")
print(e)
driver.execute_script("window.open('http://quote.eastmoney.com/center/gridlist.html#sz_a_board','_self');")
time.sleep(1.5)
try:
spider()
except Exception as e:
print("------------------------------------error---------------------------------------")
print(e)
# driver.quit()
driver.execute_script("window.open('http://quote.eastmoney.com/center/gridlist.html#bj_a_board','_self');")
time.sleep(1.5)
try:
spider()
except Exception as e:
print("------------------------------------error---------------------------------------")
print(e)
db = sqlite3.connect('w0.db')
sql_text = '''CREATE TABLE scores
(序号 TEXT,
股票代码 TEXT,
股票名称 TEXT,
最新报价 TEXT,
涨跌幅 TEXT,
涨跌额 TEXT,
成交量 TEXT,
成交额 TEXT,
振幅 TEXT,
最高 TEXT,
最低 TEXT,
今开 TEXT,
昨收 TEXT);'''
db.execute(sql_text)
db.commit()
for item in res:
sql_text = "INSERT INTO scores VALUES('"+item[0] + "'"
for i in range(len(item) - 1):
sql_text = sql_text + ",'" + item[i+1] + "'"
sql_text = sql_text + ")"
print(sql_text)
db.execute(sql_text)
db.commit()
db.close()
结果:
心得体会:没第二题难。
gitee仓库链接:gitee仓库链接
作业②
- 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
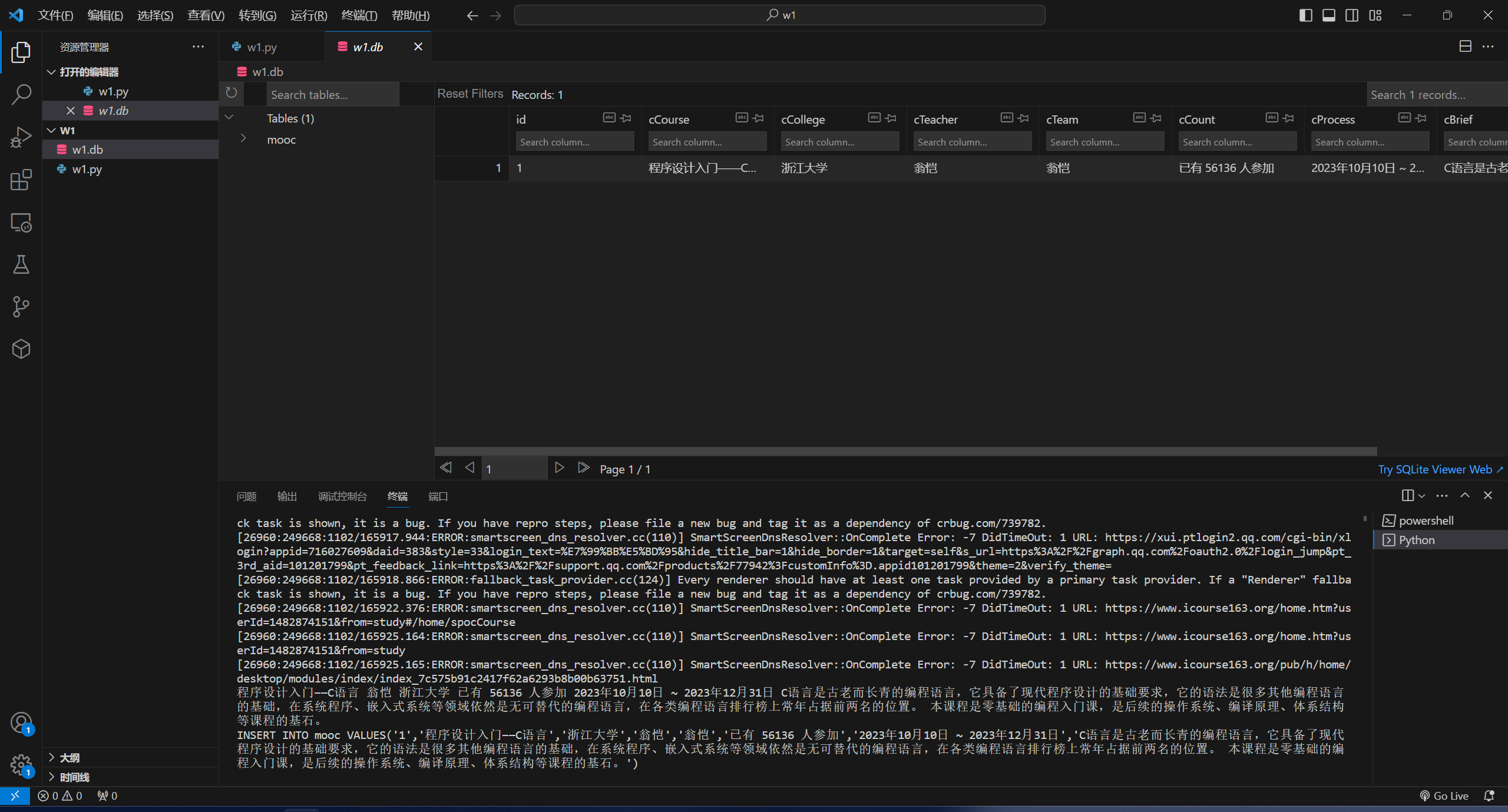
- 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
from selenium.webdriver.edge.options import Options
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.edge.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
import sqlite3
def login():
next_button = driver.find_element(By.XPATH,'//*[@id="j-topnav"]/div')
webdriver.ActionChains(driver).move_to_element(next_button ).click(next_button ).perform()
next_button = driver.find_element(By.XPATH,'/html/body/div[12]/div[2]/div/div/div/div/div/div[1]/div/div[2]/div[1]/a[1]')
webdriver.ActionChains(driver).move_to_element(next_button ).click(next_button ).perform()
time.sleep(2)
driver.switch_to.frame('ptlogin_iframe')
next_button = driver.find_element(By.CSS_SELECTOR,'#img_out_539943419')
webdriver.ActionChains(driver).move_to_element(next_button ).click(next_button ).perform()
time.sleep(15)
def spider():
# PPT也就爬了一个。。。
driver.execute_script("window.open('https://www.icourse163.org/course/ZJU-199001','_self');")
time.sleep(5)
name = driver.find_element(By.XPATH,'/html/body/div[4]/div[2]/div[1]/div/div[3]/div/div[1]/div[1]/span[1]').text
teacher = driver.find_element(By.XPATH,'/html/body/div[4]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div/div/div[2]/div/div/div/div/div/h3').text
school = driver.find_element(By.XPATH,"/html/body/div[4]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div/a/img").alt
count = driver.find_element(By.XPATH,'/html/body/div[4]/div[2]/div[1]/div/div[3]/div/div[2]/div/div[1]/div[4]/span[2]').text
time1 = driver.find_element(By.XPATH,'//*[@id="course-enroll-info"]/div/div[1]/div[2]/div/span[2]').text
brief = driver.find_element(By.XPATH,'//*[@id="j-rectxt2"]').text
print(name,teacher,school,count,time1,brief)
item = [str(1),name,school,teacher,teacher,count,time1,brief]
sql_text = "INSERT INTO mooc VALUES('"+item[0] + "'"
for i in range(len(item) - 1):
sql_text = sql_text + ",'" + item[i+1] + "'"
sql_text = sql_text + ")"
print(sql_text)
db.execute(sql_text)
db.commit()
db = sqlite3.connect('w1.db')
sql_text = '''CREATE TABLE mooc
(id TEXT,
cCourse TEXT,
cCollege TEXT,
cTeacher TEXT,
cTeam TEXT,
cCount TEXT,
cProcess TEXT,
cBrief TEXT);'''
db.execute(sql_text)
db.commit()
edge_options = Options()
driver = webdriver.Edge(options=edge_options)
res = []
driver.get("https://www.icourse163.org/home.htm?userId=1482874151#/home/spocCourse")
try:
login()
except Exception as e:
print("------------------------------------error---------------------------------------")
print(e)
try:
spider()
except Exception as e:
print("------------------------------------error---------------------------------------")
print(e)
time.sleep(999)
db.close()
结果:
心得体会:比第一题难,大伙都去整输入,感觉不如模拟点击扣扣登录hhh。
gitee仓库链接:gitee仓库链接
作业③
- 掌握大数据相关服务,熟悉Xshell的使用
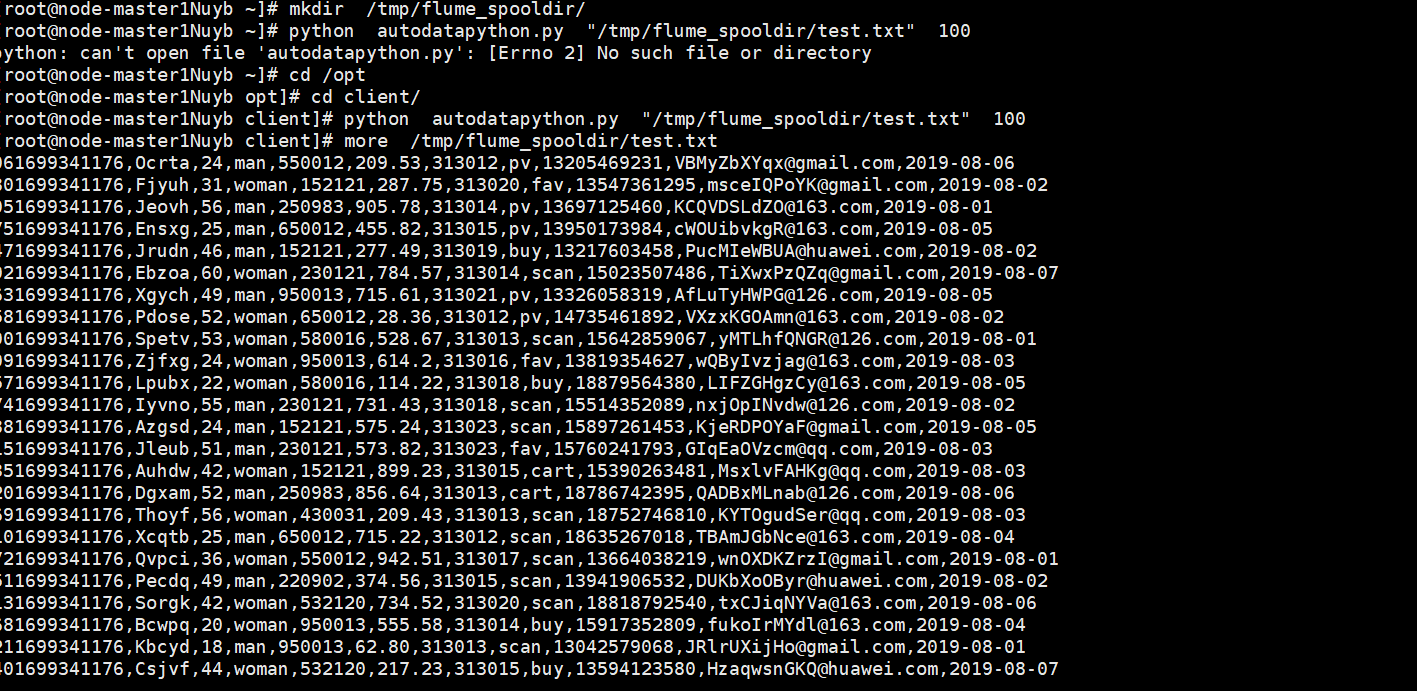
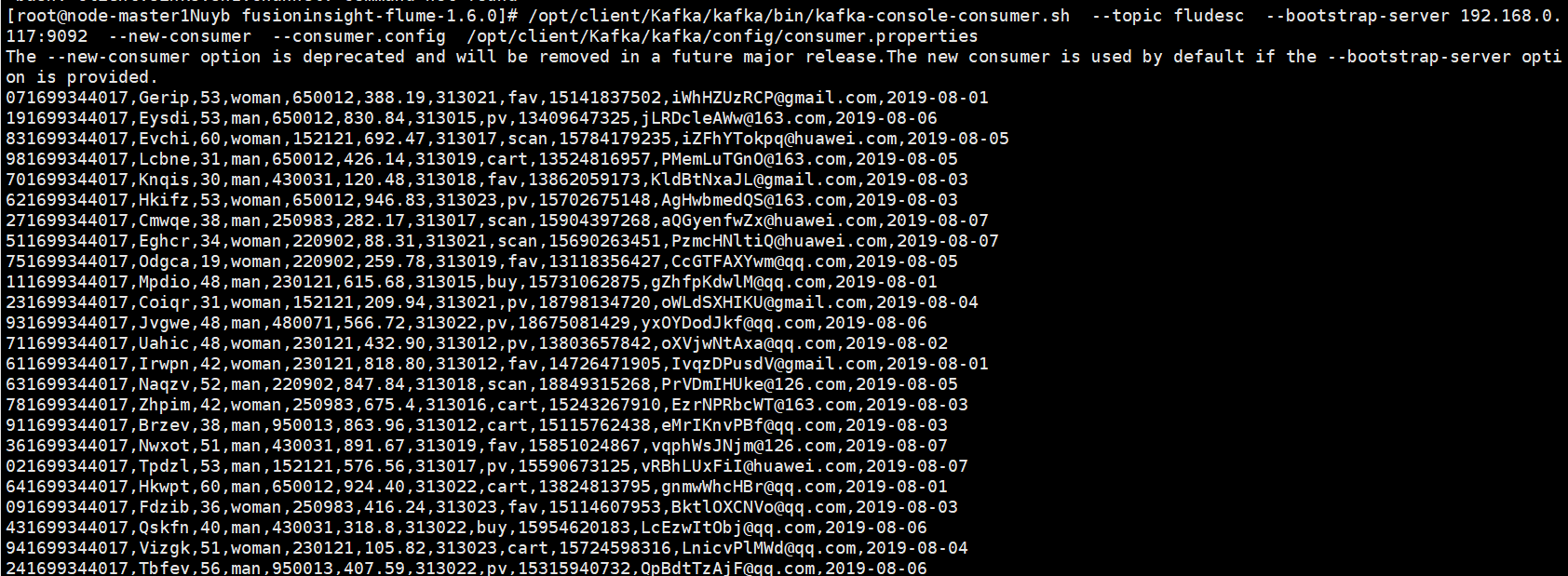
- 完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
完成代码:详见华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx
完成截图:



心得体会:复制黏贴还能复制出心得体会?

