

数据采集与融合技术实践作业一
102102141 周嘉辉
作业①
- 要求:爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
完成代码:
import urllib.request
from bs4 import BeautifulSoup as bs
from re import match
from time import sleep
import re
def Filter_rank(tag):
return tag.name == "div" and tag.has_attr("class") and 'rank' in tag['class']
print('102102143周嘉辉')
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
request = urllib.request.urlopen(url).read().decode()
soup = bs(request, 'lxml')
tags = soup.find_all('tr', attrs={"data-v-4645600d": ""})
for i in tags:
t = i.find('div', attrs={'class': 'ranking'})
n = i.find('a', attrs={'class': 'name-cn'})
c = i.find_all('td', attrs={'data-v-4645600d': ''})
if t != None and n != None:
# print(type(n.text))
name = match('.+[大学,学院]',n.text)[0]
rank = str(int(t.text))
province = ''.join(re.findall('[\u4e00-\u9fa5]', c[2].text))
type = ''.join(re.findall('[\u4e00-\u9fa5]', c[3].text))
point = ''.join(re.findall('[0-9\.]', c[4].text))
print(rank + ':' + name + ',' + province + "," + type + ',' + point)
sleep(99)
结果:

心得体会:其实是第一次作业,在家里写的,正则表达式用的非常痛苦,bs很好用,希望正则表达式用多了以后会熟练一点吧。
作业②
- 要求:设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
完成代码:
import urllib.request as rqst
from bs4 import BeautifulSoup as bs
from urllib.parse import quote
import string
import threading as t
cookie = ""
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81"
}
headers['cookie'] = cookie
print('102102143周嘉辉')
goods = []
lock = t.Lock()
# 搜索并将结果append进goods(作业要求)
def search_output(url):
global lock
url = quote(url,safe=string.printable)
res = rqst.Request(url,headers=headers)
res = rqst.urlopen(res)
res = res.read().decode('utf-8')
html = res
soup = bs(html, 'lxml')
tags = soup.find('div', attrs={"id": "J_goodsList"})
tags = tags.find_all('li', attrs={'class': "gl-item"})
lock.acquire()
try:
global num_count
global goods
for t in tags:
name = t.find('div',attrs = {'class': "p-name p-name-type-2"}).find('em').text.replace('\n',' ')
price = float(t.find('div',attrs = {'class': 'p-price'}).find('i').text)
# print(num_count,'-->',name,price)
goods.append([name,price])
except Exception as e:
print(e)
lock.release()
if __name__ == '__main__':
keyword = '背包'
url = 'https://search.jd.com/Search?keyword='+str(keyword)+'&enc=utf-8'
ts = []
t1 = t.Thread(target=search_output,args=[url])
ts.append(t1)
for i in range(1):
t1 = t.Thread(target=search_output,args=[url + '&page=' + str(i+2)])
ts.append(t1)
for i in ts:
i.start()
for i in ts:
i.join()
goods = sorted(goods,key=lambda a:a[1])
count = 1
for item in goods:
print(count,'>>',item[0],' ',item[1],'¥')
count+= 1
结果:
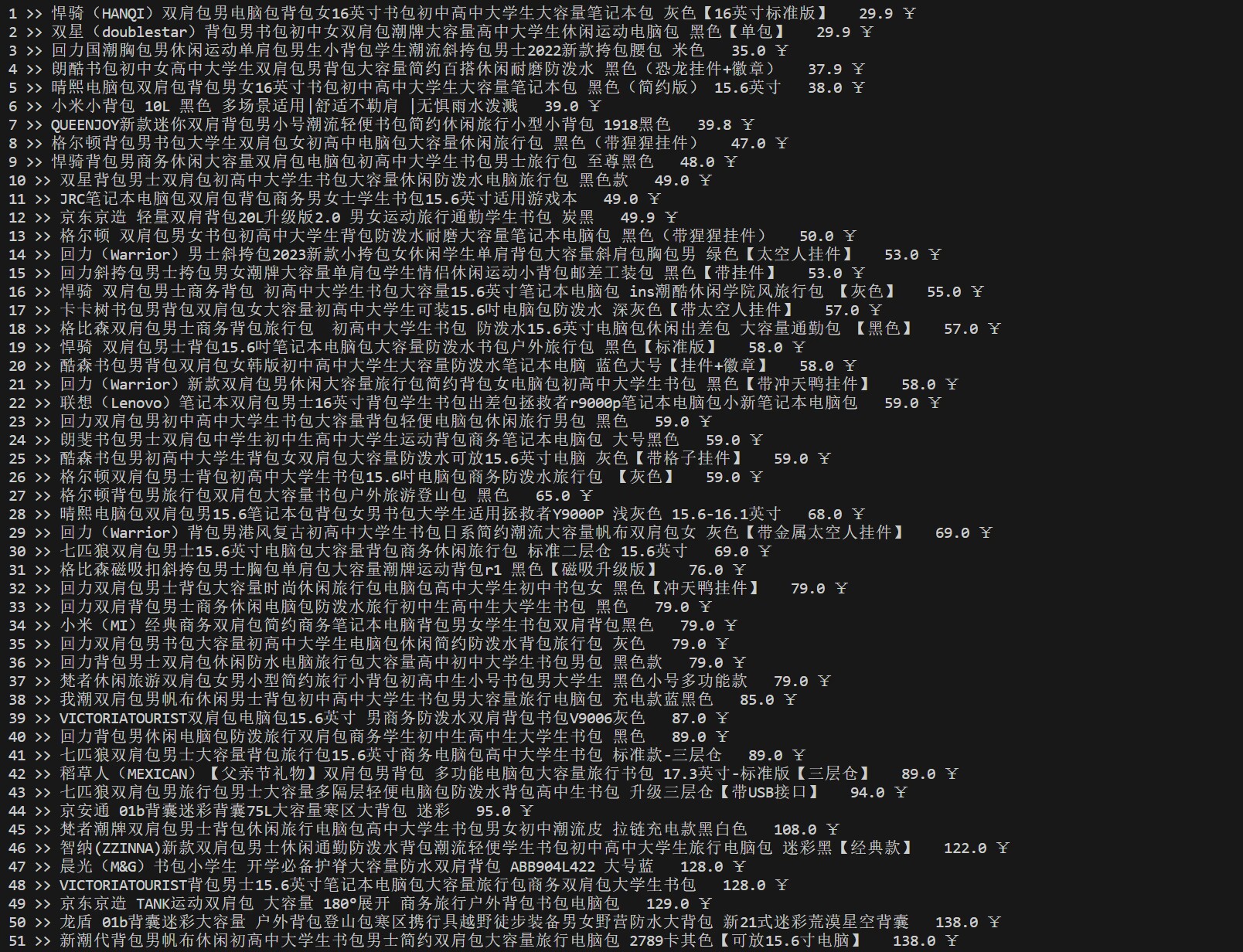
心得体会:刚开始是想爬淘宝的,但是爬不来,所以选择京东(其实本来是苏宁,只是当时正好在看京东)(另外为什么不能上传图片????)。
作业③
- 要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
完成代码:
import requests
import urllib.request as req
import os
from bs4 import BeautifulSoup
url = "https://xcb.fzu.edu.cn/info/1071/4481.htm"
output_folder = "downloaded_images"
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# response = requests.get(url)
response = req.urlopen(url).read().decode()
# print(response)
# exit()
soup = BeautifulSoup(response, 'lxml')
img_tags = soup.find_all('img')
count = 0
for img in img_tags:
img_url = 'https://xcb.fzu.edu.cn/'+img['src']
req.urlretrieve(img_url,'img'+str(count)+'.jpg')
count+=1
结果:
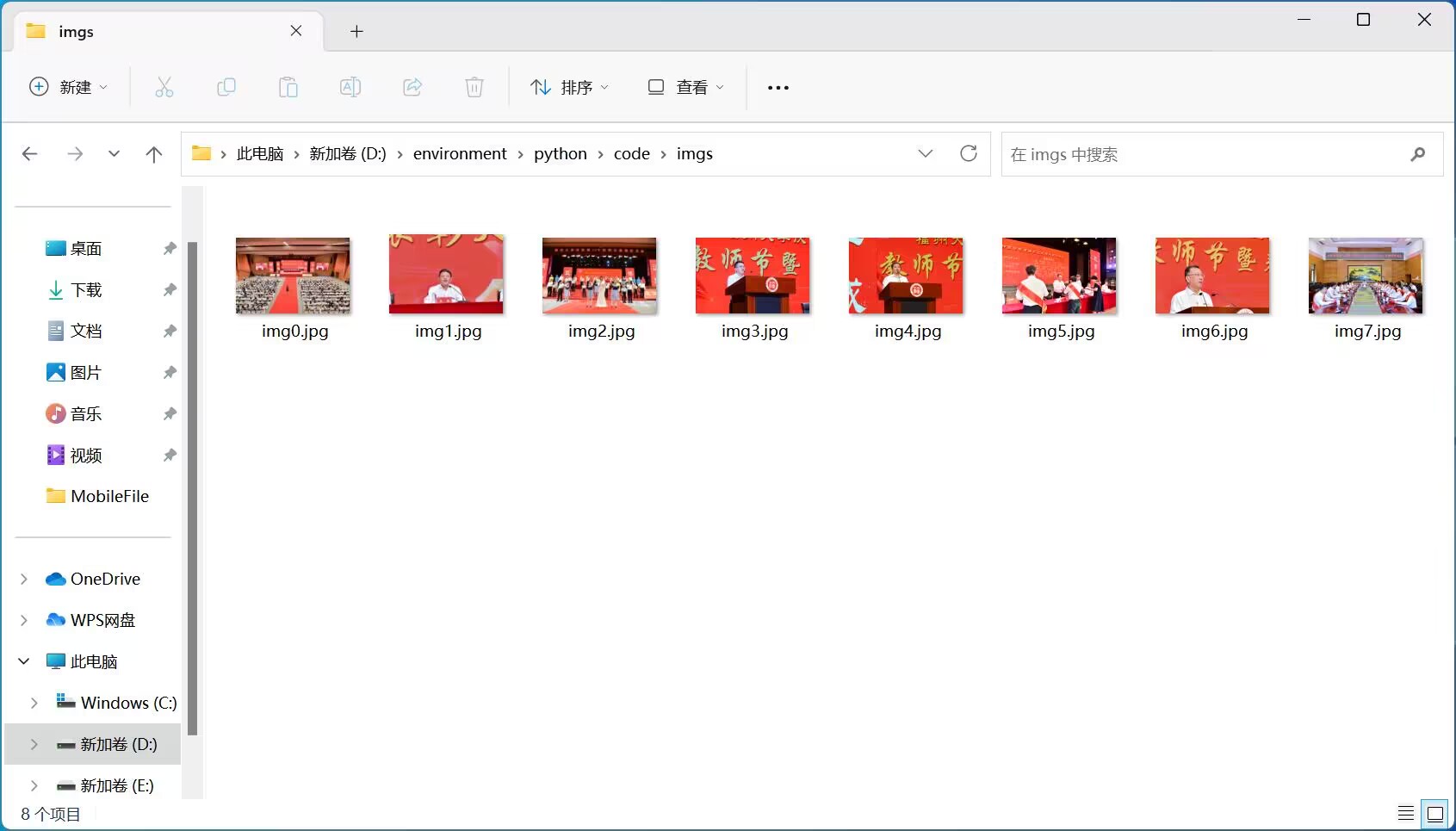
心得体会:这次作业是在课堂上完成的,但是因为我的电脑不能用,所以是在同学电脑上完成的,但是呢因为学校机房的VSCode配置的极其奇怪,找不到正确的Python版本(这个系统有3个Python版本,太可怕了,另外谢谢同学),写的很仓促,不过是能得到结果的。

