Python 垃圾回收总结
前言
最近在阅读《垃圾回收的算法与实现》,里面将讲到了一些常用的垃圾回收(Garbage Collect)算法,如:标记-清除、引用计数、分代回收等等。
后面讲到了 Python 的垃圾回收策略,在此记录一下。
衡量 GC 性能的四要素
-
吞吐量
吞吐量为单位时间内的GC出来能力。计算公式为:GC处理的堆容量 / GC花费的时间。
通常,人们都喜欢吞吐量高的GC算法。 -
最大暂停时间
GC执行过程中令用户线程暂停的最长时间。如果GC时间过长,会影响程序的正常执行。
较大的吞吐量和较短的最大暂停时间往往不可兼得。 -
堆使用效率
GC是自动内存管理功能,所以理想情况是在GC时不要占用过量的堆空间。
影响堆使用效率的两个因素是:头的大小和堆的用法。
可用的堆越大,GC运行越快;相反,越想有效地利用有限的堆,GC花费的时间就越长。 -
访问的局部性
具有引用关系的对象之间通常很可能存在连续访问的情况。这在多数程序中都很常见,称为“访问的局部性”。
考虑到访问局部性,把具有引用关系的对象安排在堆中较近的位置,能够提高数据的利用率。
Python 使用引用计数的 GC 的算法,引用计数算法的优势是可以减短最大暂停时间,缺陷是在维护计数的增量和减量上面临很大的挑战(如果忘记执行减量操作就会造成对象没有释放)。
引用计数存在哪里
对于 Python 的数据,像 List、Set、Tuple、Dict、Str、Int,在其底层的数据结构中,都会有一个PyObject类型的成员,用来维护对象的引用计数
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
struct _typeoject *ob_type;
} PyObject;
其中的ob_refcnt成员负责维持引用计数
如此,所有的内置型结构在都在开头保留了PyObject结构体来维护引用计数。

内存分配器
Python 在进行内存分配时并不是简单的调用malloc/free函数来向操作系统请求内存的。而是出于效率考虑尽可能减少系统调用,将内存分配器分成了3层。
Object-specific allocators
_____ ______ ______ ________
[ int ] [ dict ] [ list ] ... [ string ] Python core |
+3 | <----- Object-specific memory -----> | <-- Non-object memory --> |
_______________________________ | |
[ Python's object allocator ] | |
+2 | ####### Object memory ####### | <------ Internal buffers ------> |
______________________________________________________________ |
[ Python's raw memory allocator (PyMem_ API) ] |
+1 | <----- Python memory (under PyMem manager's control) ------> | |
__________________________________________________________________
[ Underlying general-purpose allocator (ex: C library malloc) ]
0 | <------ Virtual memory allocated for the python process -------> |
=========================================================================
_______________________________________________________________________
[ OS-specific Virtual Memory Manager (VMM) ]
-1 | <--- Kernel dynamic storage allocation & management (page-based) ---> |
__________________________________ __________________________________
[ ] [ ]
-2 | <-- Physical memory: ROM/RAM --> | | <-- Secondary storage (swap) --> |

第0层到第3层是 Python 实现管理的分布器层级,如果以字典对象为例,
PyDict_New() ----3层
PyObject_GC_New() ----2层
PyObject_Malloc() ----2层
new_arena() ----1层
malloc() ----0层
第0层就是直接调用操作系统提供的分配函数,如malloc。Python 并不是所有的对象生成都调用第0层,而是根据要分配内存的大小来选择不同的分配方案:
- 申请的内存大于256字节,使用第0层
- 申请的内存小于256字节,使用第一层和第二层
基于经验,我们是编码过程中使用的大量对象都是小于256字节的,并且生命周期很短,例如:
for x in range(100):
print(x)
这个过程中如果频繁调用malloc和free,效率就会很低。Python 通过增加第1层和第2层,并在第一层中会事先从第0层申请一些空间保留管理起来,当分配对象内存小于256时,使用这部分空间。
Python 管理的内存结构有3个部分:block、pool、arena,它们之间的关系如下:
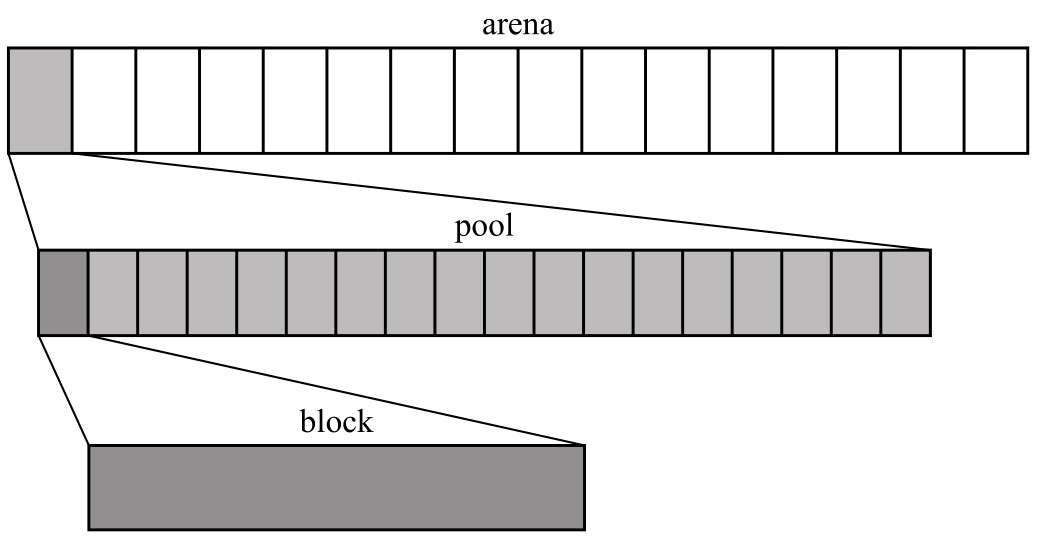
- arena 用来管理存储 pool
- pool 用来管理存储 block
- block 内存申请者可用的最小单位
为了避免频繁调用malloc()和free(),第1层的分配器会以最大的单位 arena 来保留内存。pool 是用于有效管理空的block的单位。
第2层的分配器负责管理 pool 内的 block。将 block 的开头地址返回给申请者,并释放 block 等。
分配器会将 pool 会按照8字节的倍数的大小来分割后产出若干个 block,如:8字节的 block、16字节的 block、24字节的 block、... 256字节的 block。申请内存时,会返回适合大小的 block。
第3层是对象特有的分配器,Python 中各种内置类型:如:list、dict 等,又会有各自特有的分配器,比如 dict 的分配器长这样:
#ifndef PyDict_MAXFREELIST
#define PyDict_MAXFREELIST 80
#endif
static PyDictObject *free_list[PyDict_MAXFREELIST];
static int numfree = 0;
在分配字典对象时,会先检查空闲列表free_list是否有可用对象,如果已被用尽,再去通过第2层PyObject_GC_New去申请对象。
整体下来 Python 生成字典对象时的交互如下:
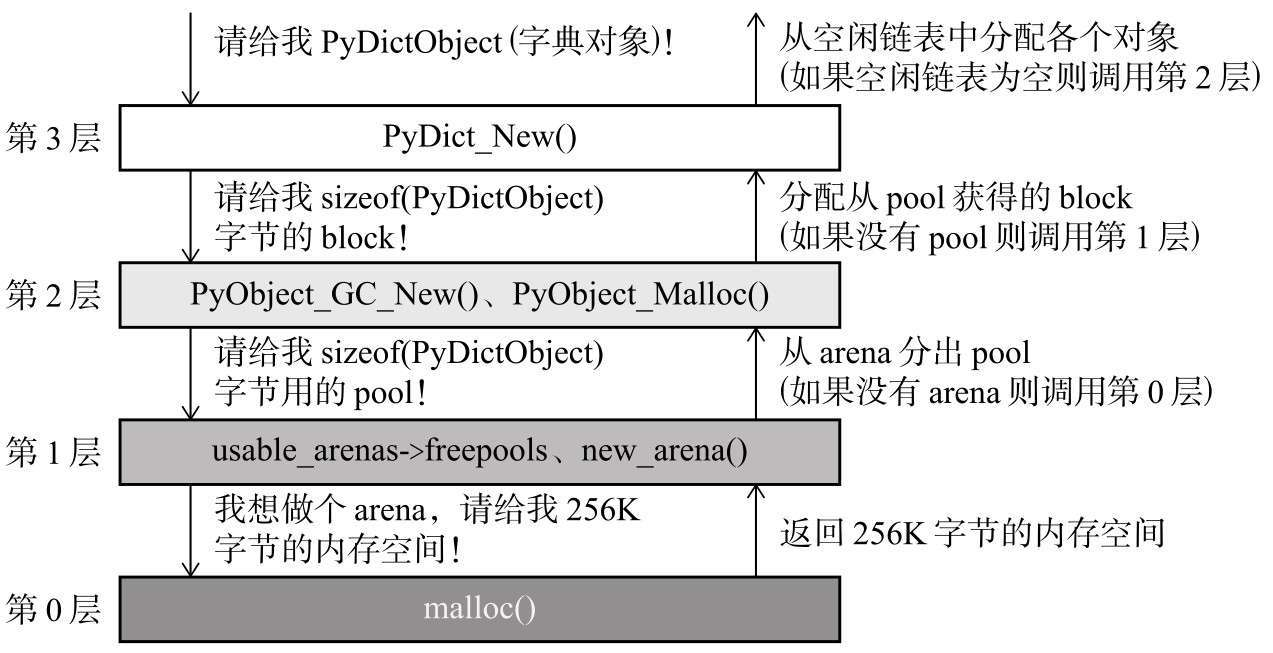
引用计数法
Python 内实现引用计数法,其实就是对各对象的引用数量变更做相应的操作,如果对象的引用数量增加,就在计数器上加1,反过来如果引用数量减少,就在计数器上减去1。
增量操作
实际的计数操作由宏Py_INCREF来实现
#define Py_INCREF(op) ( \
((PyObject*)(op))->ob_refcnt++)
ob_refcnt的类型在32位环境下是 int 型,在64位环境下是 long 型。因为有符号位,所以只有一半数值能用非负整数表示。但是因为指针基本上都是按4字节对齐的,所以即使引用计数器被所有指针引用,也不会溢出。
设计成允许存在负数是为了方便调试,当引用计数器存在负数数,就有减量操作过度或者增量操作遗留的可能。
减量操作
实际的计数操作由宏Py_DECREF来实现
#define Py_DECREF(op) \
if (--((PyObject*)(op))->ob_refcnt != 0) \
_Py_CHECK_REFCNT(op) \
else \
_Py_Dealloc((PyObject*)(op))
# define _Py_Dealloc(op) ( \
(*Py_TYPE(op)->tp_dealloc)((PyObject*)(op)))
先将计数器将量,如果不为0,调用宏_Py_CHECK_REFCNT检查引用计数器是否变为了负数。如果计数器为0,那么就调用宏_Py_Dealloc,通过Py_TYPE识别对象的类型并调用对应的负责释放各个对象的函数指针,比如:负责释放元组对象的函数指针是tupledealloc。
static void
tupledealloc(register PyTupleObject *op)
{
register Py_ssize_t i;
register Py_ssize_t len = Py_Size(op);
if (len > 0) {
i = len;
/* 将元组内的元素进行减量 */
while(--i >= 0)
Py_XDECREF(op->ob_item[i]);
}
/* 释放元组对象 */
Py_TYPE(op)->tp_free((PyObject *)op);
Py_TRASHCAN_SAFE_END(OP);
}
成员tp_free存着对各个对象的释放处理函数指针,大部分在其内部都是调用PyObect_GC_Del函数
void
PyObject_GC_Del(void *op)
{
PyGC_Head *g = AS_GC(op);
/* ... */
Pyobject_FREE(g)
}
元组的减量操作调用图如下:
Py_DECREF
_Py_Dealloc ———— 减量操作
tupledealloc
PyObject_GC_Del ———— 元组释放处理
PyObject_FREE
PyObject_Free ———— 释放内存
引用的所有权
上面已经阐明了引用计数的核心操作就是计数+1和计数-1。需要明确的是,谁来去负责进行操作,比如:A 对象通过调用函数func1获得了 B 对象,那么 B 对象的引用计数+1应该由谁去负责呢?
这里就涉及到“引用的所有权”, 即谁持有引用的所有权,谁就得承担在不需要此引用时将对象的引用计数器减量的责任。
- 传递引用所有权(返回值)
即函数方把引用的所有权和返回值一起交给调用方。由函数的调用方在引用结束时负责执行减量操作。对象生成时,会把引用所有权交给调用方,比如:字典对象的生成
PyObject *dict = PyDict_New();
/* 进行一些操作, 结束后*/
Py_DECREF(dict);
dict = NULL;
- 出借引用的所有权(返回值)
即函数方只把返回值交给调用方,至于引用的所有权则只是出借而已,调用方不能对引用计数进行减量操作。负责从“集合”中取出元素的函数,都是出借所有权,比如:元组获取指定索引的函数
PyObject *
PyTuple_GetItem(register PyObject *op, register Py_ssize_t i)
{
/*检查操作*/
return ((PyTupleObject *)op) -> ob_item[i]
}
- 占据引用的所有权(参数)
即调用方把参数传递给函数时,函数方有时会占据这个参数的引用所有权,此时由函数方负责该参数的引用管理事宜。往链表中追加元素的函数都会占据参数的引用所有权,比如:向元组指定位置增加元素的函数
PyObject *tuple, *dict;
tuple = PyTuple_New(3);
dict = PyDict_New(); /*用所有权返回给了dict*/
PyTuple_SetItem(tuple, 0, dict); /*引用所有权被tuple占据了*/
dict = NULL;
- 出借引用所有权(参数)
即调用方把参数的引用所有权借给函数方。当函数的调用方要出借引用的所有权时,从把对象交给函数之后直到函数执行结束为止,这段时间调用方都必须保留指向对象的引用的所有权。
循环引用垃圾回收
引用计数法有一个缺陷,无法解决循环引用问题,当两个对象之间相互引用,引用计数无法清零,即无法进行 GC。因此,对于循环引用,Python 通过部分标记-清除算法来解决。
算法原理:部分标记-清除算法
比如下图,左侧的三个对象之前存在循环引用,导致正常的引用计数无法将他们回收
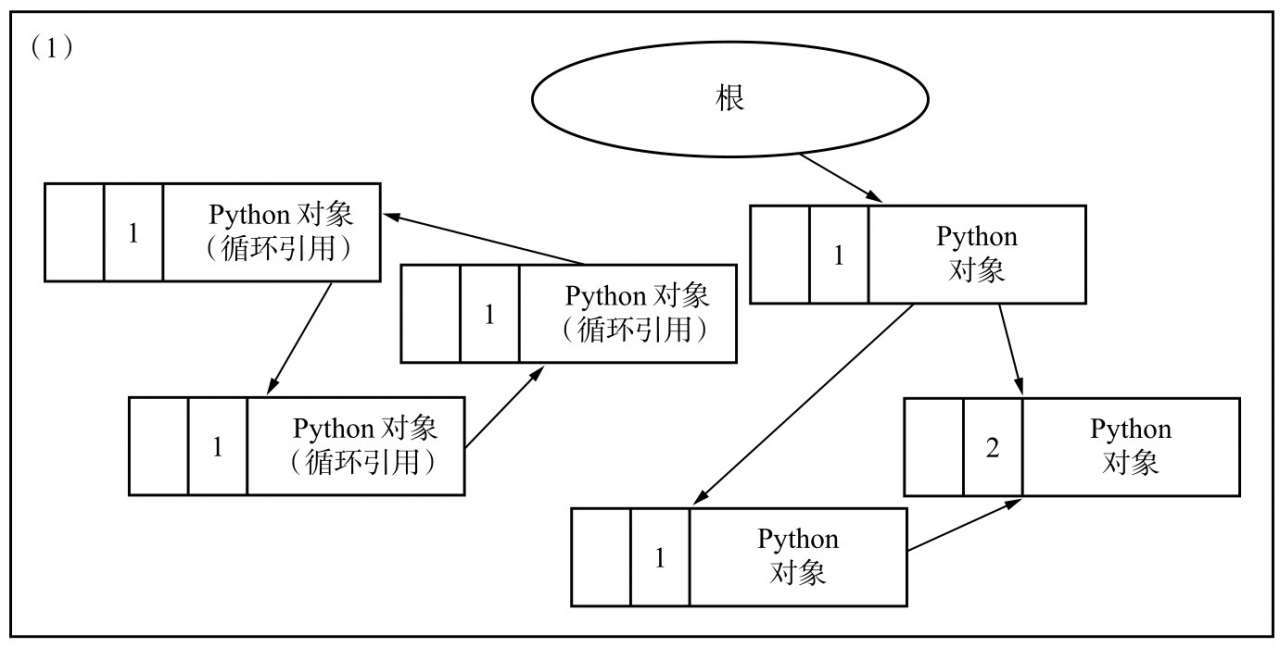
我们先将他们当前的引用计数复制到另一块区用于后面操作

有一个前提:Python 对象在生成时会将其自身连接到一个对象链表中(通过双向指向相互连接),图中用双向箭头表示
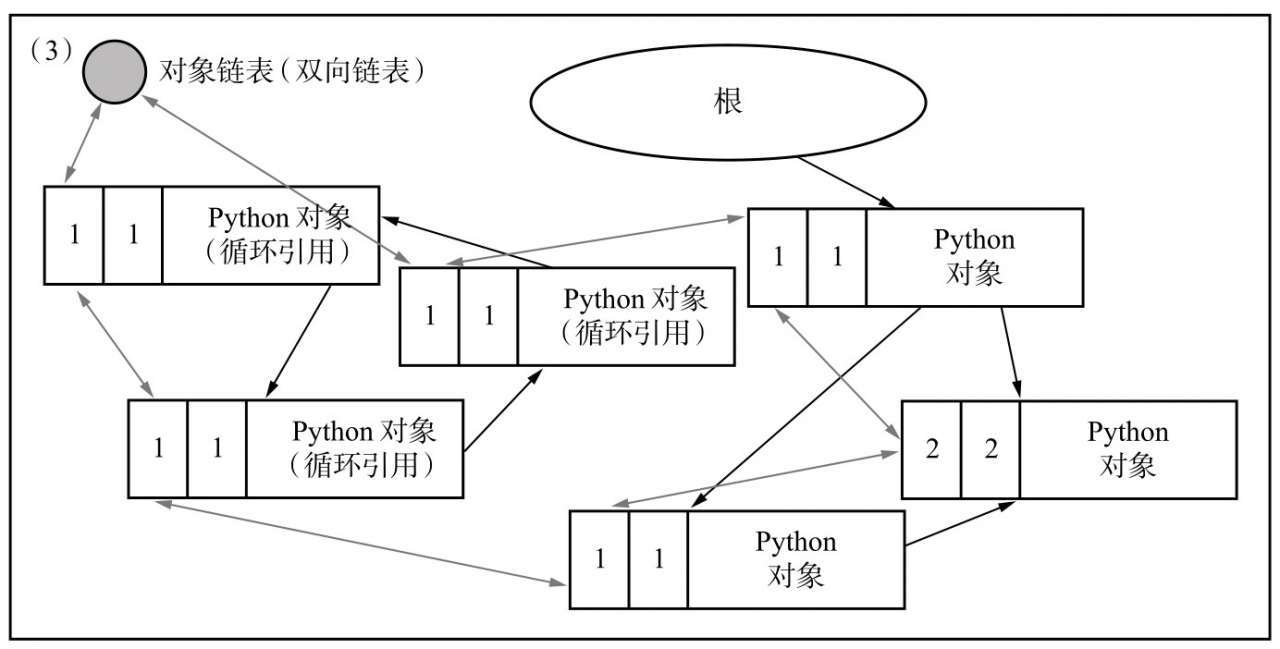
基于此,我们遍历对象链表中的所有对象,对他们所有引用的对象进行拷贝计数减一

现在进行标记操作了,我们将所有经过上步处理后拷贝计数仍然大于0的对象标记为“可达对象”,即有其他活动对象引用他们,并将他们所引用的对象也标记为可达对象,连接到可达对象链表中;然后将拷贝计数为0的对象记为“不可达对象”,连接到不可达对象链表。
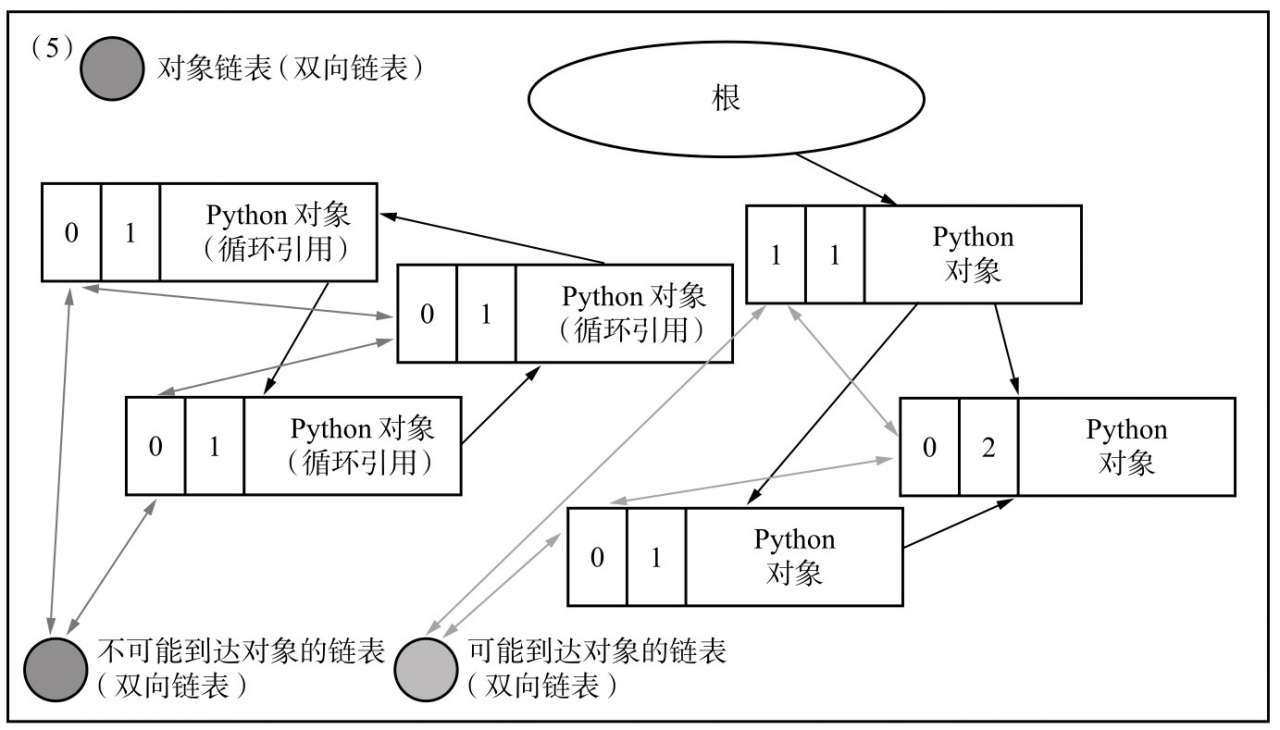
可以看到,不可达对象中即为循环引用的对象,接下来进行清除操作,我们将不可达对象链表中的对象释放内存,将可达对象链表中的对象重新连接会对象链表中
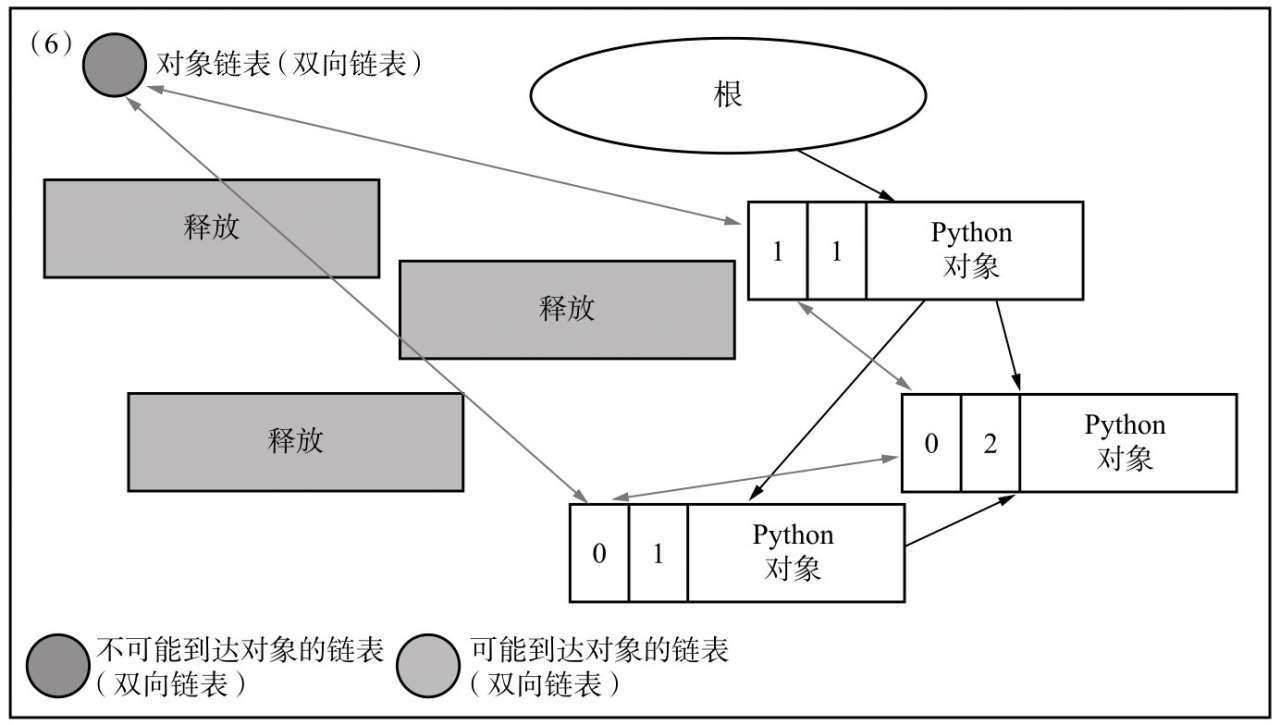
到此,我们完成了对循环引用对象的垃圾回收。
并不是所有对象都会发生循环引用
引起循环引用的根因是有些对象可能保留的指向其他对象的引用,对于这类对象,我们称之为“容器对象”。
像元组、列表和字典等,都属于容器对象,只需要对这些容器对象解决循环引用的问题。容器对象中都被分配了用于循环引用垃圾回收的头结构体。
tyepdef union _gc_head {
struct {
union _ge_head *gc_next; /*用于双向链表*/
union _gc_head *gc_prev; /*用于双向链表*/
Py_ssize_t gc_refs; /*用于复制计数*/
} gc;
long double dummy;
} PyGC_Head;
正如前面所说,容器对象生成时,会被连接到对象链表,以字典对象为例,看一下他生成时代码
PyObject *
PyDict_New(void)
{
regiseter PyDictObject *mp;
/*生成对象的操作*/
_PyObject_GC_TRACK(mp);
return (PyObject *)mp;
}
_PyObject_GC_TRACK负责连接到对象链表中的操作
#define _PyObject_GC_TRACK(o) do { \
PyGC_Head *g = _Py_AS_GC(o); \
g->gc.gc_refs = _PyGC_REFS_REACHABLE; \
g->gc.gc_next = _PyGC_generation0; \
g->gc.gc_prev = _PyGC_generation0->gc.gc_prev; \
g->gc.gc_prev ->gc.gc_next = g; \
_PyGC_generation0->gc.gc_prev = g; \
} while (0);
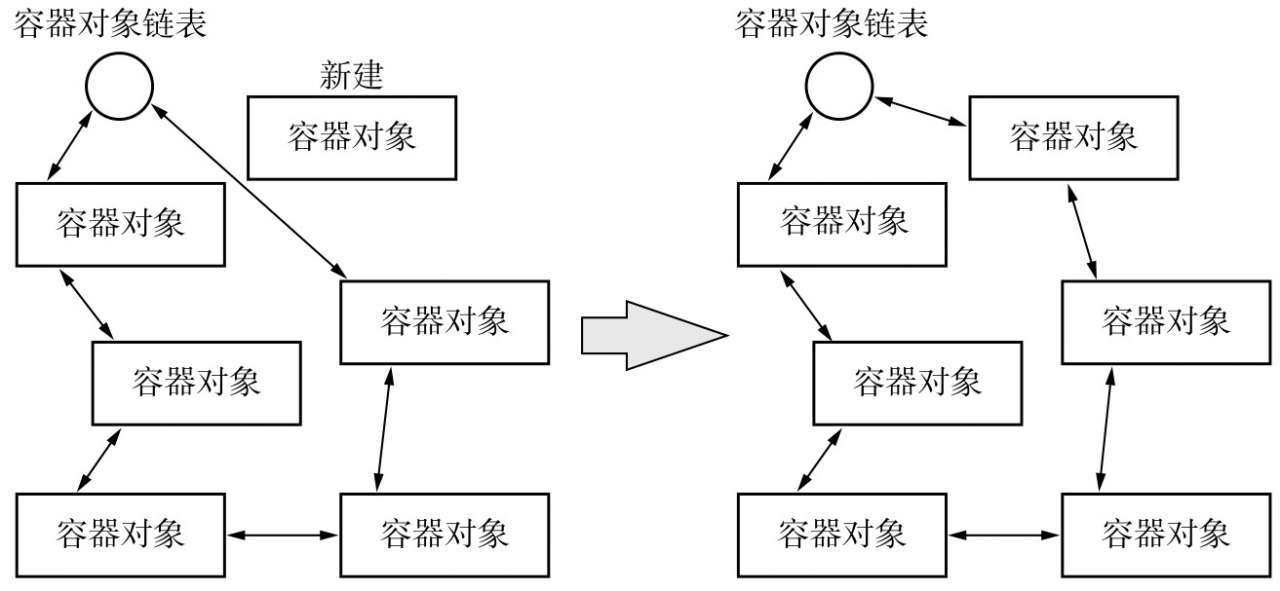
容器对象分代管理
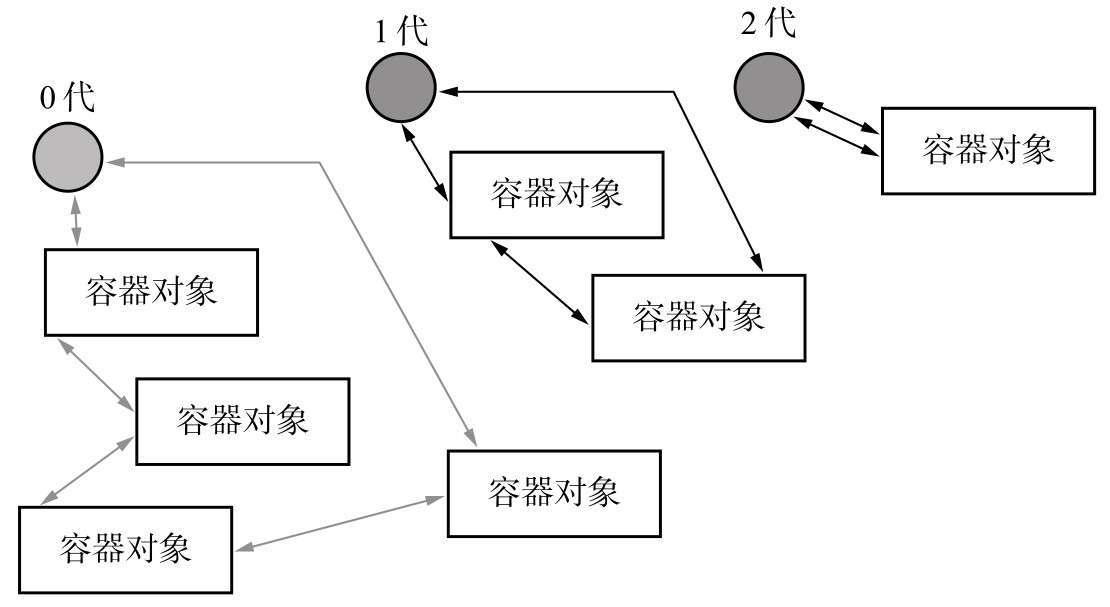
Python 将上面提到的容器对象链表划分为“0代”、“1代”、“2代”,通过下面的结构体管理
struct gc_generation {
PyGC_Head head; /* 头指正 */
int threshold; /* 开始GC的阈值 */
int count; /* 改代的对象数 */
}
# define GEN_HEAD(n) (&generations[n].head)
PyGC_Head *_PyGC_generation0 = GEN_HEAD(0); /* 0代的容器对象 */
一开始所有的容器对象都连接着0代的对象。当0代容器对象经过1次循环引用垃圾回收,仍然存活下来的对象晋升为1代;再次从循环引用垃圾回收过程中存活下来的对象晋升为2代。
移除特例
在循环引用垃圾回收过程中,我们会将有终结器的对象从不可达链表中移除
static void
move_finalizers(PyGC_Head *unreachable, PyGC_Head *finalizers)
{
PyGC_Head *gc;
PyGC_Head *next;
for (gc = unreachable->gc.gc_next; gc != unreachable; gc = next) {
PyObject *op = FROM_GC(gc);
next = gc->gc.gc_next;
if (has_finalizer(op)) {
gc_list_move(gc, finalizers);
gc->gc.gc_refs = GC_REACHABLE;
}
}
}
之所以如此,是因为想要释放循环引用的有终结器的对象是非常麻烦的。我们无法确定先释放那个对象时合理的,如果先将第1个对象释放,再释放第二个对象时执行的终结器引用了第一个对象怎么办?
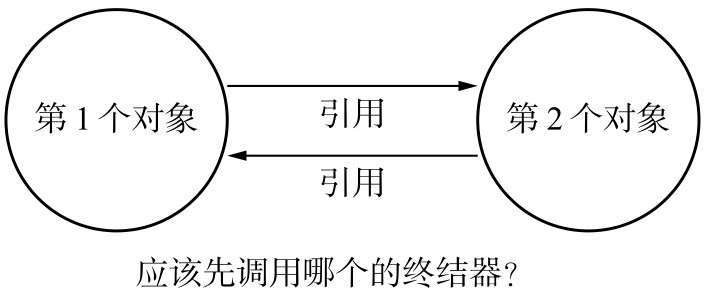
对于这些含有终结器的循环引用垃圾对象, Python 提供了全局变量garbage,让开发者内从应用程序的角度来去移除对象的循环引用。
import gc
gc.grabage
总结
Python 的 GC 分为两部分:
- 通过
引用计数算法来管理常规对象的垃圾回收,并通过优化的内存结构来尽可能减少 GC - 通过
分代+清除-标记来管理循环引用对象的垃圾回收

