
密码工程笔记
密码工程
第一部分 概述
第一章 密码学研究范围
- 密码学 安全问题 艺术&科学
- 本书旨在讨论实际应用领域————在实际系统中实现密码技术
- 保持批判精神!
1.1密码学的作用
- 密码学作为安全系统的一部分,提供访问控制功能
- 帐篷&金库 其他部分足够强壮时才能体现密码系统的效用
- 对密码系统的攻击≈合法访问,难以发现
1.2木桶原理
- 每个安全系统的安全性都取决于它最脆弱的环节————提高最脆弱环节的安全性
- 攻击树分析——>大型系统
- 对不同(目标|工具|能力~)攻击者脆弱环节不同->多脆弱环节强化->纵深防御
1.3对手设定
- 安全工程:不可预测的攻击者|其他工程:可预测的攻击者(损害)
- 以现在对抗未来:攻击者不限资源,不限技术,不限时间
1.4专业偏执狂
- 偏执狂模型:其他参与者均为恶意&多个攻击目标——>安全理念
1.4.1更广泛的好处
- 安全理念->设计&实现&测试中考虑攻击方式->发现潜在安全问题->运用到新技术中
1.4.2攻击
- 存在混淆攻击(批判)工作&人格的设计者
- 低情商:如果你这样做,攻击者会#$@%^
- 高情商:如果攻击者那样@#$%做,会怎么样呢?
1.5威胁模型
- 系统是安全的==在某些威胁下能为资产提高充分的安全保障——>构建匹配的威胁模型
1.6密码学不是唯一解决方案
- 密码学仅仅是整个安全系统的一部分,提供的安全感困难使设计者|使用者放松警惕,削弱了整个系统的安全性
- 安全感!=安全(但能体现对安全感的需求)
1.7密码学是非常难的
- 木桶原理&对手设定使密码学变得艰难
- 公布系统——>增加测试——>找到安全漏洞
1.8密码学是简单的部分
- 密码组件的边界和需求定义良好
- 密码技术可实现,安全系统的其他部分安全难以解决
1.9通用攻击
- 在系统外的超越可控范围的攻击,例如盗录视频
- 确保系统不能抵扣哪些通用攻击,避免浪费时间
1.10安全性和其他设计准则
- 安全性是众多设计准则之一
1.10.1安全性和性能
- 安全性>>>>>性能
- 防护&检测&响应
- 好消息:计算机的效率会让给我们忽略系统运行效率,以便无痛地提高安全性
- 坏消息:效率还包含进入市场的速度等,会让开发者选择性地忽略安全性
- 非从0开发——>向后兼容——>不安全
1.10.2安全性和特性
- 复杂性以特性或选项形式常出现,使系统的测试变高而提高了安全性成本
- 保持简单:减少事件交互——>提供清晰而简单的接口——>模块化
1.10.3安全性和演变的系统
- 预测系统使用情况并做好准备
1.11更多阅读材料
- 可能为入门概述 The Codebreakers -Kahn
- 历史 The Code Book
- 算法详细说明 应用密码学 -Bruce
- 百科全书 Handbook of Applied Cryptography -M&O&V
- 理论 Foundations of Cryptography -Goldreish ,Introduction of Modern Cryptography -Katz&Lindell
- 计算机安全 秘密和谎言 -Bruce
- 安全工程 Security Engineering -Ross
- 在线资源 Crypto-Gram通讯&Bruce博客
1.12专业偏执狂练习
1.12.1时事练习
1.12.2安全审查练习
1.13习题
第2章 密码学简介
2.1加密
- 一个好的加密函数除了消息长度和消息发送数据外不应提供任何信息
- Kerckhoff原则:加密方案的安全性必须仅仅依赖于对密钥的保密(算法是可公开且不可破解无密钥密文的)
2.2认证
- 为了避免重放攻击,认证集合总是会和一个编号方案结合使用
2.3公钥加密
- 公钥密码建立对称密码的密钥,将公钥密码的灵活性和对称密码的高效性结合起来
2.4数字签名
- 计算机进行数字签名,故不能保证本人实际认可
2.5PKI
- PKI优势:一次注册,随处使用
- 多层CA需要多级证书检验
- PKI问题:实体不可能被所有人信任;CA颁发错误证书的代价难以负责
2.6攻击
2.6.1唯密文攻击模型
- 只知道密文,猜测明文
2.6.2已知明文攻击模型
- 知道明密文,猜测密钥,解密其他密文
2.6.3选择明文攻击模型
- 有一定权限,将明文发送给系统可获得密文,猜测密钥,解密其他密文
2.6.4选择密文攻击模型
- 全称选择密文与明文攻击模型,相对选择明文有更高的权限,还可将密文发送给系统可获得明文,猜测密钥,解密其他密文
PS:本书中选择密文与明文=选择明文+选择密文(事实上的).在另一种说法里,选择密文=已知明文+选择密文(事实上的),选择文本=选择密文与明文
2.6.5区分攻击的目的
- 理想方案的定义,见下一章?!
- 确保组件缺陷不会产生问题
2.6.6其他类型的攻击
- 信息泄露攻击|侧信道攻击:利用时间信息和密文长度
2.7深入探讨
2.7.1生日攻击
- 基于事实:碰撞出现比我们想象的快得多
- 一个元素有等概的N中可能,预计取N^(0.5)次左右就会发生碰撞
- 生日攻击:对于64位密钥,在2^32次的密钥中就可能使用相同密钥,就可插入以前消息的密钥进行攻击破坏
- 生日界:n位01数据有2n个可能值,预计2(0.5)次会发生碰撞
2.7.2中间相遇攻击
- 与生日攻击同属碰撞攻击
- 选择232位密钥并计算好MAC,与实际的记录比对,系统密钥有1/232的概论碰撞到攻击者的密钥,工作量为232的计算与232的窃听
- 区别:生日攻击等待同一值在相同集合(窃听系统)中出现两次,中间相遇攻击有两个集合(系统与攻击者计算)等待出现交集
2.8安全等级
- 以穷举搜索度量攻击的工作量以评价安全等级,忽略了许多因素以简化安全分析
2.9性能
- 在计算机上,密码系统的性能不是问题,即使有也可通过更新硬件解决,更便宜也更安全
- 应当更多地选择安全性
2.10复杂性
- 测试仅仅能够针对功能,指出错误,而安全性不是功能的缺失,测试无法防御恶意的攻击者
- 从一开始就构建一个健壮的系统——>要求系统是简单的——>模块化
2.11习题
第二部分 消息安全
第3章 分组密码
- 最容易理解的部分&基本组件
- 在大多数应用中以"工作模式"来使用
3.1什么是分组密码
-
加密固定长度数据分组的加密函数
-
可逆且明密文的长度相同
-
Kerckhoff原则:
-
- 即使非数学上不可破解,系统也应在实质(实用)程度上无法破解。
- 系统内不应含任何机密物,即使落入敌人手中也不会造成困扰。
- 密匙必须易于沟通和记忆,而不须写下;且双方可以容易的改变密匙。
- 系统应可以用于电讯。
- 系统应可以携带,不应需要两个人或以上才能使用(应只要一个人就能使用)。
- 系统应容易使用,不致让用户的脑力过分操劳,也无需记得长串的规则。
假设用于加密和解密的算法是公开已知的
-
一个分组长度为k位的分组密码对于每一个密钥都对应一个k位值的置换。构成了庞大的映射表
32位分组——>16GB
64位分组——>1.5×108TB
-
分组密码的输出密文一般不能是明文字符串直接置换所得到的值。?要验证所有的太位输入的2*个可能值和对应的k位输出。?一般不会是直接置换
00000001—a—>01000000
00000001—b—>11011110
3.2攻击类型
-
分组密码在已知密文攻击条件下是安全的,但大多数分组密码面对明文攻击无效
-
相关密钥攻击 是一种对实际系统的攻击
攻击者:已知加密函数,未知密钥
攻击漏洞:在分组密码的标准协议中需要的两个密钥有如下关系∶一个密钥K是随机产生的,另一个密钥K'是K加上一个固定的常数。这使得同一系统的密钥间存在相关性而可以被猜测到,如一个系统通过将密钥+1的方式生成不同的(连续)密钥
-
选择密钥攻击 攻击策略?
攻击部分密钥,剩余部分采用相关密钥攻击,详见3.5.4
-
Davies-Meyer 构造:分组密码中构造散列函数的标准技术。
攻击者可以随时选择分组密码的密钥,进行相关密钥攻击和选择密钥攻击
-
分组密码应提供简单的接口,以确保所有的性质都可以被使用者合理地利用,并以交叉依赖的形式,允许接口增添其他复杂功能。
-
挑战:如何根据分组密码的功能需求确定合理的性质。
3.3理想分组密码
-
核心:随机置换
对于每个密钥值,分组密码都是一个随机置换,而且不同密钥对应的置换应该是完全独立的。
-
我们把理想分组密码当作在所有可能的分组密码集合上的均匀概率分布,它不能够在实践中获得,是一个在讨论安全性时使用的抽象概念
3.4分组密码安全的定义
- 一个安全的分组密码能够抵抗所有的攻击。
- 分组密码攻击是将分组密码从理想分组密码中分离开来的一种非通用方法。
- 理想分组密码能够为每一个密钥值实现独立选择的随机偶置换。
3.5实际分组密码
- 几乎所有分组密码都由一个弱分组密码的多次重复组成,每一次运算被称为一轮。经
过连续多轮的弱重复运算可以实现一个强分组密码。 - 同样地,大多数针对分组密码的攻击都是从轮数较少的版本开始
3.5.1DES
-
经典&应用广泛,56位密钥长度和64位分组长度提供的安全性无法满足现在的需求
-
当前采用3DES,分组长度不变,2个56位密钥长度,使用第一个加密,第二个解密,再用第一个加密
-
步骤
DES 算法有64 位明文,有16轮加密,分别被编号为1至16。每一轮使用一个48 位的轮密钥Ki。这16个轮密钥是从分组密码的 56 位密钥K中选择48位生成的,对于每一轮密钥,选择方式都是不同的。这个由主分组密码密钥生成轮密钥的算法称为子密钥生成器(key schedule)。
- 首先将明文进行IP 置换。然后将明文从中间分成左右两部分,分别是32位的L和R。在一轮加密结束后同样交换L和 R的序列以得到64 位的密文。
- 轮函数通过一系列的运算改变(L,R)的值。32位的R值首先要经过扩展函数得到48 位的输出。然后和轮密钥Ki,进行异或并将结果输入S盒。
- S(substitution替代)盒是一个公开的查找表。48位的输入被分成一些组,每组大小约为4~6位。S盒将48位的向量通过非线性映射成为32位的向量。
- 这32位经过位变换函数后与L异或得到新的L,将此L和R的值互换,进入新一轮的加密。
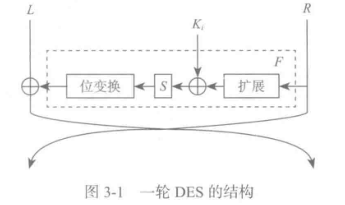
-
Feistel结构:每一轮通过L和F(Ki,R)的异或生成新的L,然后将L与R交换
方便硬件实现,可以使用相同电路进行加解密计算
-
扩散性能:输入F的任何一位发生变化都影响到输出密文的许多位(雪崩效应)
DES中由S盒、扩展函数、位变换函数的结合提供扩散性能
-
弱密钥性:每一轮的轮密钥都是由分组密码的主密钥的某些位生成的。
-
互补:如果使用取反的密钥加密取反后的明文值,那么所得到的密文是原密文的取反。
-
弱密钥性与互补性使得DES不安全,3DES也继承了这些弱点
3.5.2AES
-
Rinjdael算法,取代DES,没有采用Feistel结构
-
分组长度为128bit,密钥长度有128位、192位、256 位。使用128 位密钥加密10轮,192 位密钥加密 12轮,256 位密钥加密14轮
-
步骤
-
输入 16字节(128位)的明文,首先将明文与16字节的轮密码进行异或操作,在图中用④运算符来表示。
-
然后进入8位输入8位输出的S盒,这些S盒内部结构均是相同的。
-
输入后按照特定的顺序重新排列输出。
-
最后分为4个组,使用线性混合函数进行异或运算得到输出结果。
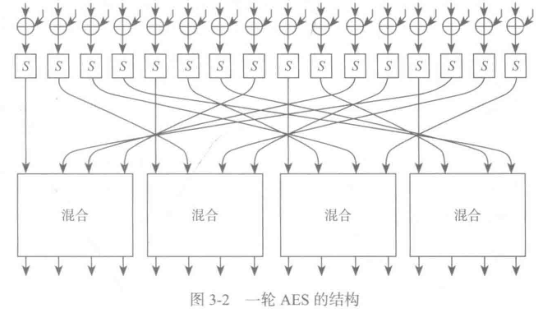
-
-
结构优缺点:每一个执行步骤都包含了多个并行运算,可以实现高速运算;解密和加密运算完全不同,需要逆转 S盒的查找表,而且混合运算的逆运算也和原混合运算不同。
-
多轮次有助于AES的安全性,但从理论上AES已经被攻破
3.5.3 Serpent
- 相对AES更注重安全性,也更加缓慢,速度仅有AES的三分之一
- 执行32轮,同时每一轮需要32个S盒查找表,可以通过将S盒转换为布尔运算提高CPU的操作速度
3.5.4 Twofish
-
速度同AES且更安全,但由于会使用密钥进行大量预运算所以更改加密密钥代价大
-
轮函数由两个g函数、一个被称为PHT的函数和密钥相加运算构成。一个g函数包含4个S盒,然后是一个线性混合函数。S盒的结构依赖于密钥,预计算结果保存在内存中。PHT函数通过32位加运算混合两个g函数的输出结果。F函数的最后部分是对密钥进行加法。
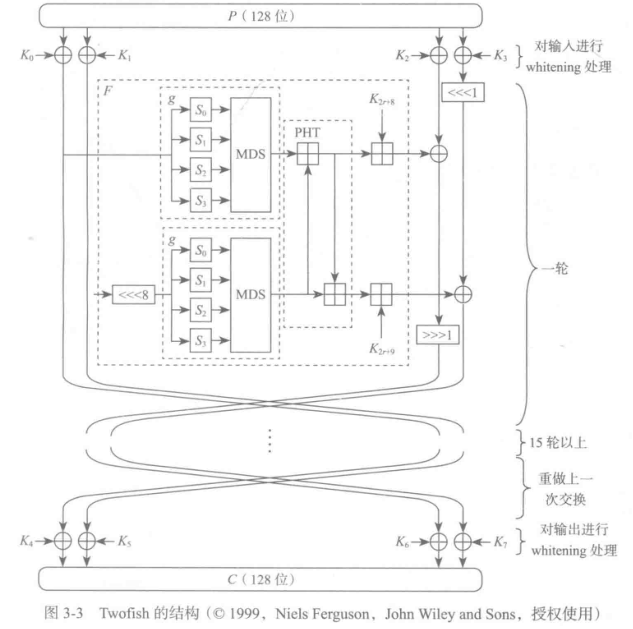
-
whitening(白化)技术:在密码算法的开始和结束使用额外的密钥加密数据,能以很小的代价使得算法更加难以攻破
3.5.5其他的AES候选算法
-
RC6
使用32位乘法,执行20论,AES竞争已经可攻破17轮
-
MARS
具有非均匀结构,使用不同种类运算,实现代价高
3.5.6如何选择分组密码
- AES执行速度快,有一定安全性,而且由于成为标准,密码库支持程度高,容易使用和实现
- 3DES安全性不足,在限制64位分组长度的情况下是最好选择
- 为提高安全性可以使用双重加密,多种算法&多种轮次&多种密钥长度,应使用不同的、独立的密钥
- 对AES安全性的判断应参考后续分析建议。另外,AES的执行时间会透漏出密钥的一些位,所以应尽量隐瞒时间信息
3.5.7如何选择密钥长度
- 对于一个n位的安全等级,分组密码的长度应该为2n位长(参考2.7的生日碰撞攻击)
- 设计强度是128位并不代表采用256位长度的密钥
3.6习题
3.1 存储一个80位密钥长度、分组长度为64位的理想分组密码需要多少空间?
答:理想密码对于每个密钥值,分组密码都是一个随机置换,而n位分组长度的分组密码的置换表大小为2n,m位密钥长度有2m个可能,所以需要280×264=2144大小的空间
3.2 DES算法有多少轮?DES的密钥长度是多少位? DES算法的分组长度是多少?3DES算法是如何根据 DES进行加密的?*
答:DES算法有16轮。密钥长度是56位。分组长度为64位。3DES算法用第一个56位密钥对明文进行DES加密,再用第二个56位密钥对上一轮的结果进行DES解密,最后用第一个56位密钥对上一轮的结果进行DES加密
3.3 AES的最常用密钥长度是多少?对于每种密钥长度,执行的轮数是多少?AES算法的分组长度是多少?
答:AES的密钥长度有128、192、256位,其中最常用密钥长度是128位。使用128 位密钥加密10轮,192 位密钥加密12轮,256 位密钥加密14轮。AES的分组长度为128位
3.4 在3DES和AES两种算法中,在什么情况下选择3DES?什么情况下选择AES?
答:在需要向后兼容或者被系统的其他部分限定为只能使用64位长度的分组时使用3DES,在其他情况下最好使用AES
3.5 假设有一台处理器可以在2-26秒执行一次 DES的加密或解密运算。设想已知DES算法下使用单个未知密钥加密的很多明文密文对。那么使用一台处理器进行穷举搜索,平均需要多长时间破译DES密钥? 如果使用214台处理器进行穷举搜索,需要多久?
答:DES算法的密钥空间为256,所以一台处理机计算256次一定可以破解DES密钥,平均计算228次,所以使用一台处理器运行22=4s即可破译,使用214台处理器需要2-12s即可破解
3.6 考虑一组新的分组密码DES2,只包括了两轮 DES 算法。DES2算法和DES算法具有相同的分组长度和密钥长度。DES算法F函数是一个有两个输入。一个输出的黑盒。输入为48位轮密钥和32 位数据段,输出为 32 位。
假设现在有大量的DES2下使用单个未知密钥加密的明文密文对。请给出一个算法计算出第一轮轮密钥和第二轮轮密钥。该算法应该比穷举搜索56位DES密钥执行更少的操作。这个算法能否转换为对DES2 算法的区分攻击呢?
答:
第4章 分组密码工作模式
- 分组密码只能加密固定长度,使用分组密码工作模式可加密非恰好分组长度的数据
- 可提供机密性,但不能进行认证。攻击会产生许多无意义垃圾信息,某些模式还允许针对性的明文修改,甚至许多数据格式可以通过局部地随机修改来操纵。
4.1填充
- 大多数模式要求明文长度是分组大小的整数倍,所以需要填充明文,但填充应可逆,以确保可用性
- 一个填充规则满足如果明文已经符合长度要求就无须进行填充是非常理想的,但这很难对所有情况都满足。对可逆的填充方案,都可以找到一些长度已适合但还需进行填充的消息,实际上所有填充规则都会给明文增加至少一个字节。不是很明白??
- 填充方案
- 明文接下来的第一个字节中填充 128,然后填充0直到整个长度满足b的倍数。填充0的字节数介于 1,⋯,b-1 之间。
- 首先计算需要填充的字节数,该字节个数n满足1≤n≤b并且n+(P)是b的倍数。然后在明文后附加n个字节,每个字节填充的值为 n。
- 解密密文后填充部分须被移除。用于移除填充的代码还应该检测是否使用了正确的填充。
4.2 ECB
- 电子密码本(ECB)分别加密明文消息的每个分组。Ci=E(K, Pi) i= 1⋯,k
- ECB有严重缺陷,明文分组相同使密文分组相同,这对攻击者是可见的。而由于编码或信息主题等问题,可能会出现大量重复分组而使信息泄露
4.3 CBC
- 密码分组链(CBC)通过将每个明文分组与前一个密文分组进行异或操作 Ci=E(K, Pi⊕Ci-1) i= 1⋯,k
- 通过前一个密文分组实现随机化,初始向量为C0或IV
4.3.1固定IV
- 实际应用中的消息经常会以相似或相同的分组开始,固定IV会使起始密文相同
4.3.2计数器IV
- 以计数器作为IV,但也可能重新生成相同的密文分组
4.3.3随机IV
-
选择随机IV并作为第一个密文块放在消息所对应的密文之前发送给接收者
-
C0=随机分组值
Ci=E(K,Pi⊕Ci-1) i= 1,…,k解密Pi=D(K,Ci)⊕Ci-1) i= 1,…,k
-
主要缺点就是密文比明文多一个分组
4.3.4瞬时IV
- 瞬时值为每一个用该密钥加密的消息分配一个唯一的数,瞬时值是消息的某种编号
- 为消息分配一个消息编号。通常,消息的编号由一个从0开始的计数器提供,而计数器在任何时候都不能返回 0,否则就会破坏唯一性。
- 由消息编号构造唯一的瞬时值。对给定的密钥,瞬时值不仅在这台计算机中是唯一的,甚至在整个系统都是唯一的。例如,同一个密钥用于加密双向的通信,此时瞬时值应该由消息编号与消息的发送方向标识组成。瞬时值的大小应该是分组密码的单个分组大小。
- 用分组密码加密瞬时值得到IV。
- 在 CBC模式下使用此 IV 对消息加密。
- 在密文中添加足够的信息使接收者能够恢复这个瞬时值。有一种方法是在明文的前面附加消息编号,或者通过可靠信道传输密文,这时消息编号将是隐含的,IV值本身(公式中的C0)不需发送。
- 任何实际系统都需要确保瞬时值的唯一性。但是并不是说可以任意选取瞬时值,所以在大多数情况下就如加密消息一样使用相同的密钥加密瞬时值。
4.4 OFB
-
输出反馈模式(OFB)不是将消息作为加密函数的输入进行加密,而是使用分组密码生成一个伪随机字节流(称为密钥流),然后将其与明文进行异或运算得到密文。这种用生成随机密钥流进行加密的方案称为流密码。
-
K0:= IV
Ki:= E(K,Ki-1) i= 1,⋯,k
Ci:=Pi⊕Ki -
优点
OFB的解密运算和加密运算完全相同,所以无须再实现解密函数。
OFB不需要对明文进行填充
-
缺点
一旦有两个不同的消息使用了同一个IV,那么这两个消息就被相同的密钥流加密。
如果一个密钥分组重复出现,那么随后密钥分组序列就与之前的重复了。
4.5 CTR
-
计数器模式(CTR) 也是流密码模式,但避免了短循环问题
-
Ki:= E(K,Nonce||i ) i=1,…, k
Ci:=Pi⊕Ki -
生成密钥流:瞬时值与计数器值连接起来,然后进行加密产生密钥流的一个密钥分组
-
瞬时值与计数器值的连接不能超过单个分组的大小
典型的分配方案是消息编号占48位,瞬时值的附加数据占16位,而其余 64位用于计数器i。这样将把系统限制为使用一个密钥只能加密248个不同的消息,每个消息最多有268字节。
-
同OFB一样,必须保证IV或瞬时值的唯一性
-
由于CTR模式的密钥流中的任意一个密钥块都可以及时计算,可以非常容易地获取明文的任一部分
-
CTR的安全性也可以被认为就是分组密码的安全性
4.6加密与认证
- CCM模式与GCM模式能够同时提供认证和加密,详见第七章
4.7如何选择工作模式
-
仅考虑使用CBC与CTR模式
-
CBC
优点:更强的健壮性,即使误用也能很好地工作
缺点:密文更长,明文需要填充,系统需要随机数生成器
-
CTR
优点:由一定健壮性,密文较短
缺点:依赖正确生成瞬时值,而在很多系统中较为困难
-
流量分析:攻击者获取并分析正在通信、在何时通信、通信的数据量、在和谁通信等信息
4.8信息泄露
- ECB:如果两个明文分组相同(Pi=Pj),那么对应的密文分组也相同(Ci=Cj)。
- CBC:由于每一个明文分组首先与前一个密文分组进行异或运算后再加密,从而使得相同的明文分组所对应的密文分组不一定相同。但这说明两个明文分组的差别等于对应密文分组的异或。如果存在大量冗余的数据,明文分组就可能被恢复。
- CTR:由于任意两个密钥分组都不相同,所以从两个相同的密文分组或两个相同的明文分组并不能获取更多信息
- OFB:只要密钥流分组没有碰撞发生,它与CTR模式一样会泄露同样多的信息;如果两个密钥流分组出现碰撞,那么后续的密钥流分组也会发生碰撞。
4.8.1碰撞的可能性
-
两个密文分组相同的概率分析:
假设总共加密M个明文分组。至于这 M个明文块是由几个长消息还是由很多个短的消息组成都无关紧要,重要的是分组的数量。在这M(M-1)/2个不同的分组对中,任意一对相等的可能性为2-n(n为分组长度)。因此,相同密文分组对数量的期望值是M(M-1)2"'。当M≈22时,这个期望值接近于1。这就是说大约加密2n/2个明文分组就很可能得到两个相等的密文分组。当n=128位时,大约加密264个明文块就可以期望得到两个相同的密文分组
-
考虑一般应用系统有30年寿命,未来人们可能会处理这么大的数值
-
加密较小的数据量会出现风险
假如处理240个分组(大约16TB的数据量),那么就有2-48次机会得到一对相同的密文分组。这是一个非常小的概率,但是对于攻击者来说,可以取定一个特殊的密钥,收集240个分组并检测重复的分组。这样成功的机会当然也很小,但是可以对大约248个密钥重复这个工作,攻击者要找到一个碰撞的计算量为240x248=288,远远小于128 位的设计强度。
4.8.2如何处理信息泄露
-
128位的安全等级难以真正达到,能够做到的是尽量接近期望的安全等级,尽量减轻有可能带来的危害。
-
CTR模式下,泄露较少,加密264分组会泄露一位信息
对策:限制单个密钥加密的信息总量、限制加密不超过260个分组
-
CBC模式下,一旦发送碰撞会泄露128bit的明文信息。
对策:降低碰撞概率,加密数据量为232个分组作用,使得泄露风险概率变为2-64
4.8.3关于数学证明
- 密码学的概率计算通常没有足够考虑独立性,但这样已经足够产生我们所需的精确程度
4.9习题
4.1 假设一明文用P表示,l(P)代表明文P的字节数。b代表分组密码分组长度(以字节为单位)。请
指出下面的填充方案的不足之处∶尽可能填充最少的字节以保证填充后明文长度是分组长度的倍数,即填充的字节数n需要满足两个条件0≤n≤b-1,n+l(P)是b的倍数,所填充的n个字节中,每个字节所填充的值为n。
答:与书中提供的第二种方法相比,n不能等于b,这意味着在l(P)恰为b的倍数时不对明文进行填充。如果l(P)==b且P的最后一个字节的值为1的话,在解密时就无法分清最后一个字节是填充还是明文的一部分了。
4.2 本章提到了四种初始向量;:固定IV、计数IV、随机IV、瞬时IV。试比较四种IV下的CBC模
式在安全性和性能方面的优缺点。
答:使用固定IV安全性最弱,但如果分组不以相同或相似开始的话理论上性能是最强的
使用计数IV相对固定IV的安全性强一些,性能略差但可以不计
使用随机IV的安全性较强,但会使密文多一个分组,性能有所降低
使用瞬时IV的安全性最强,额外信息比随机IV少得多,但在很多系统中难以正确生成瞬时值
4.3 假设攻击者已知一段 32 字节的密文 C(十六进制)如下∶
46 64 DC 06 97 BB FE 69 33 07 15 07 9B A6 C2 3D
2B 84 DE 4F 90 8D 7D 34 AA CE 96 8B 64 F3 DF 75
以及如下的32 字节的密文 C'(十六进制)∶
51 7E cc 05 C3 BD EA 3B 33 57 OE 1B D8 97 D5 30
7B D0 91 6B 8D 82 6B 35 B7 8B BB 8D 74 E2 C7 3B.
这两段密文是采用相同瞬时值的CTR模式下的加密结果,该瞬时值是隐含的,因此未包含在密
文中。又已知密文C所对应的明文P为∶
43 72 79 70 74 6F 67 72 61 70 68 79 20 43 72 79
70 74 6F 67 72 61 70 68 79 20 43 72 79 70 74 6F
试问,根据已知信息能得到对应于密文 C'的明文 P的哪些信息?
答:Ki:= E(K,Nonce||i ) i=1,…, k
Ci:=Pi⊕Ki
在知道Ci与Pi后,通过异或可以计算得到Ki。而由于Ki与Kj由相同的K和瞬时值与不同的i计算得出,在248-1次尝试进行i的累计值计算后可以计算出Kj,这样就可以破解Cj所对应的明文P
4.4 现采用 256 位密钥的AES 算法加密一段消息,加密后密文序列如下∶
87 F3 48 FF 79 B8 11 AF 38 57 D6 71 8E 5F 0F 91
7C 3D 26 F7 73 77 63 5A 5E 43 E9 B5 CC 5D 05 92
6E 26 FF C5 22 0D C7 D4 05 F1 70 86 70 E6 E0 17
加密密钥如下∶
80 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 01
该加密是采用随机IV的CBC模式。其中密文是以IV开始的。试解密该密文。可以使用现有的
密码库进行练习。
答:在“4.3.3 随机IV”中“选择随机 IV 并作为第一个密文块”判断IV(C0)长度与分组长度相同。由于AES分组长度为128bit,所以IV长度也为128bit,IV为87 F3 48 FF 79 B8 11 AF
在https://the-x.cn/zh-cn/cryptography/Aes.aspx上进行解密,得明文为
9D 23 31 81 9A CB 0D EE 8F B5 6C DC F0 F8 BA C8
41 6E 6F 74 68 65 72 20 73 65 63 72 65 74 21 20
20 41 6E 64 20 61 6E 6F 74 68 65 72 2E 20 20 20
4.5 采用 AES 算法加密一段消息,明文序列如下∶
62 6C 6F 63 6B 20 63 69 70 68 65 72 73 20 20 20
68 61 73 68 20 66 75 6E 63 74 69 6F 6E 73 20 78
62 6c 6F 63 6B 20 63 69 70 68 65 72 73 20 20 20
加密密钥如下∶
80 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 01
试使用现有的密码库加密明文。
答:使用ECB模式进行加密,得密文为
9B 75 B3 76 FD C7 83 BD 0D FF 4A C4 40 78 EA 8E
66 55 F4 22 2C 0D 41 33 64 F7 48 E0 8F 18 05 13
9B 75 B3 76 FD C7 83 BD 0D FF 4A C4 40 78 EA 8E
3B 02 FD 15 5A 14 CE C4 A8 83 34 36 6E 02 1B 05
4.6 假设P、P3是长度为两个分组大小的消息,P'是长度为一个分组长度的消息。已知C0,C1,C2,
是消息P1,P2采用随机密钥和随机ⅣV的CBC模式加密后的密文,C0,C1'是消息P1'同样采用
随机IV 的CBC模式加密后的密文,加密密钥相同。假设攻击者已知P1,P2,并且可以通过窃听
得到C0,C1,C2,C0',C1'。试在C1'=C2的条件下计算消息P1'。
第5章 散列函数
定义:一类将任意长度的输入位(或字节)串转换为固定长度的输出的函数
- 数字签名应用:消息长,公钥运算代价大,牺牲部分安全性(碰撞)取散列做签名
- 混淆!数据结构中的访问散列表,有相似特点但缺乏特殊的安全性质
- 应用:伪随机生成器&隔离系统不同部分
- 新标准候选SHA-3:类似AES选取过程,提供了更多选择
5.1散列函数的安全性
- 基本要求:单向函数——>重要性质:抗碰撞性&随机映射
- 定义:理想的散列函数是从所有可能的输入值得到所可能的有限输出值集合的一个随机映射。
- 攻击定义:对散列函数的攻击是一个区分散列函数与理想散列函数的非通用(non-generic)的方法。
- 较低的安全等级:一个512位的散列函数拥有128 位的安全等级
5.2实际的散列函数
- 好的散列函数:SHA系列SHA-1、SHA-224、SHA-256和SHA-512。已经过关注和研究的考验保证其安全性
- 迭代方式:
- 先将输入分成固定长度的分组序列m1,⋯,mk,最后一个分组要进行填充以使其达到固定的长度,分组的长度一般为512 位,最后一个分组通常包含一个表示输入长度的位串。
- 然后使用一个压缩函数和固定大小的中间状态对这些消息分组按顺序进行处理,这个过程由固定的值H开始,随后计算H0=h‘(Hi-1,mi),最后一个值Hk便为散列函数的输出。
- 优势:易于规定和实现(相对直接处理可变长度)&启动快(收到第一部分后立即开始计算)
5.2.1一种简单但不安全的散列函数
- 全0密钥,128位分组的AES???
5.2.2MD5
- 128位,相对MD4强化了抗攻击能力但同样脆弱
- 步骤:将消息分为512 位的序列分组,对最后一个分组要进行填充,消息的长度信息也在其中。MD5有128位的状态变量,它们被分为4个32位的字。压缩函数h'共有4 轮,在每一轮中,消息分组和状态变量进行混合,这种混合运算由32位的字上的加法、异或、与、或、轮转运算组合而成。每一轮将整个消息分组都混合在状态变量中,因此每个消息字都使用了4次。在4轮的压缩加'完成之后,将结果与输入状态相加得到h'的输出。
- 缺点:长度不够,264次计算后就会碰撞,王小云教授证明可以少于264次
5.2.3SHA-1
- NSA设计,NIST标准化,最早版本SHA|SHA-0,160位,同样基于MD4,相对MD5慢但更安全
- 缺陷:长度不够,280次计算后就会碰撞,王小云教授证明可以少于80次
5.2.4SHA-224、SHA-256、SHA-384和SHA-512
- 同属SHA-2系列,同SHA-1结构相似,不同长度分别与长度减半的AES和3DES配合使用
- 缺陷:时间更慢更保守
5.3散列函数的缺陷
5.3.1长度扩充
一个消息m被分成消息分组序列m1,⋯,mk,得到散列的值为H。现在选择消息m',它对应的消息分组序列为m1,⋯,mk,mk+1,由于m'的前k个块与m相同,散列值h(m)是在计算h(m')时的一个中间值,即有h(m')=h'(h(m),mk+1)
- 原因:散列函数计算的最后一步缺少一个特殊的处理,结果导致h(m)恰好是计算 h(m')时完成前k个块计算的中间状态。
- 危害:劫持者可以在消息后任意扩充信息而不被发现
5.3.2部分消息碰撞
当使用h进行散列处理时可以通过生日攻击用大约2n/2步找到两个发生碰撞的消息m和m',并使系统对消息m进行认证,然后用消息m'代替。
- 原因:由于散列函数的迭代计算结构,只要出现了碰撞而且余下的输入一样,那么散列值就一定相同。而消息m和m'有相同的散列值,因此对任意的X,有h(m||X)=h(m'|X)。注意该攻击与X无关,同一对m和 m'对任何X都适用。
- 危害:劫持者可以制造经认证的无效明文感染通信
5.4修复缺陷
- 缺陷难以避免,但必须修复。缺陷组合叠加暴露问题:聚是一坨屎,散是满天星
5.4.1一个临时的修复方法
hDBL法:用m→h(h(m)m)代替m→h(m),保证迭代运算与消息的每一位有关
- 安全性:n位有n位安全性,解决长度扩充缺陷问题
- 问题:耗时长(2倍)&启动慢(需完全读取)
5.4.2一个更有效的修复方法
hd法:用m→h(h(0b||m))代替m→h(m),在散列前先在消息之前添加一个全0的分组
- 安全性&问题:n位有n/2位安全性,解决长度扩充缺陷问题
5.4.3其他修复方法
截断输出法:如果散列函数是n位输出,那么只取其前面的n-s位(s为某个正整数)作为散列值。
- 应用:SHA-224将SHA-256丢弃32位输出,SHA384将SHA512丢弃128位输出
- 安全性:SHA-512截断输出256位可满足128位安全设计目标
5.5散列算法的选择
- 建议使用SHA系列、SHAd系列、SHA-512的截断输出函数
- 2012年10月,美国NIST选择了Keccak算法作为SHA-3的标准算法,详细介绍可参考全新的 SHA-3 加密标准 —— Keccak
5.6习题
5.1 使用软件工具生成两个消息M和M,M≠M,请使用一个已知的针对 MD5的攻击方法,产生
一个针对MD5的碰撞。产生 MD5 碰撞的代码样例请参阅http://www.schneier.com/cehtml。
答:网页失效。
0e306561559aa787d00bc6f70bbdfe3404cf03659e704f8534c00ffb659c4c8740cc942feb2da115a3f4155cbb8607497386656d7d1f34a42059d78f5a8dd1ef
0e306561559aa787d00bc6f70bbdfe3404cf03659e744f8534c00ffb659c4c8740cc942feb2da115a3f415dcbb8607497386656d7d1f34a42059d78f5a8dd1ef
**5.2 使用现有的密码库,编写一段程序来计算以下十六进制消息序列的 SHA-512 散列值∶
**48 65 6C 6C 6F 2C 20 77 6F 72 6C 64 2E 20 20 20
答:由于使用python中的hashlib库,由于库加密默认会将字符转为16进制ASCII码,所以我先将16进制转为ASCII字符,即为Hello, world. 转换后得SHA-512散列值为85027f3fa308b4f070b566ca4da26daffa65d861e6a26430d69a5ab7670a56f9a1668b802e6dfd4ddc992b93f752f29d76ce32777a3234f6a47db5aa4dc57185,同网站上比对后结果正确
import hashlib
hash = hashlib.sha512()
hash.update('Hello, world. '.encode('utf-8'))
print(hash.hexdigest())
5.3 考虑算法SHA-512-n,此散列函数是指首先运行SHA-512算法,输出取前n位作为结果。请编写程序采用生日攻击找到对 SHA-512-n的碰撞。其中。n是8到48之间的8的倍数。程序可以使用现有密码库。分别计算当n为8、16、24、32、40、48时程序所需的时间,对于每一个n值运行5次以上来进行统计。分别计算SHA-512-256、SHA-512-384、SHA-512算法执行该程序所需的时间。
5.4 使用前一小题的SHA-512-算法,请编写程序,分别恢复下列散列函数算法的散列值的原像。
采用 SHA-512-8算法的散列值(十六进制)∶
A9
采用 SHA-512-16 算法的散列值(十六进制)∶
3D4B
采用 SHA-512-24算法的散列值(十六进制)∶
3A 7F 27
采用 SHA-512-32 算法的散列值(十六进制)∶
c3 c0 35 7C
分别计算当n为8、16、24、32时程序所需的时间,对于每一个π值运行5次以上来进行统计。
程序可以使用现有密码库。分别计算SHA-512-256、SHA-512-384、SHA-512算法执行该程序所
需的时间。
5.5 在5.2.1节中,提到消息m和m'经过散列运算得到相同的值M,请给出证明。
5.6 选择两个SHA-3 候选散列函数,比较它们的性能,以及在当前最好的攻击下的安全性。SHA-3
候选算法的信息请参阅http∶/ww.schneier.com/cehtml。
问题
为什么长度扩充问题有h(m')=h'(h(m),mk+1)而不是h(m')=h(m,mk+1),h'(m)是什么意思?
实践
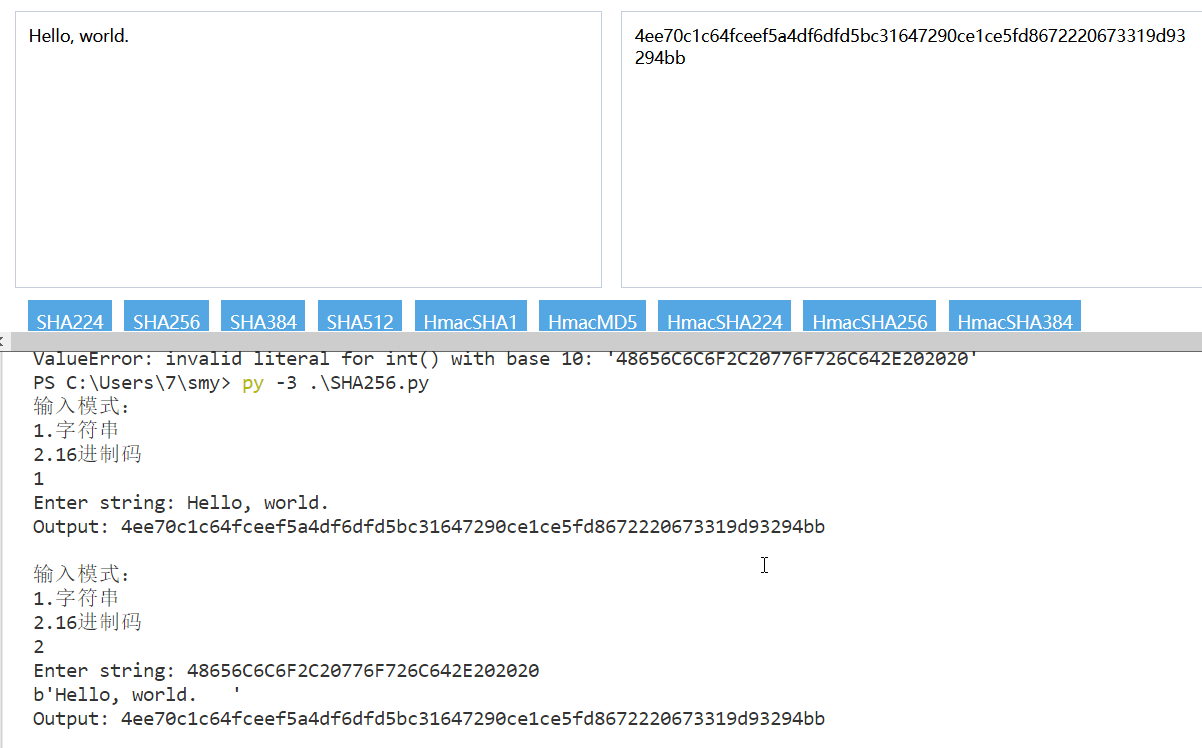
不使用库完成了SHA-256算法,并可以对字符和十六进制进行hash
a=0
class SHA256:
def __init__(self):
#64个常量
#图中Kt
self.constants = (
0x428a2f98, 0x71374491, 0xb5c0fbcf, 0xe9b5dba5,
0x3956c25b, 0x59f111f1, 0x923f82a4, 0xab1c5ed5,
0xd807aa98, 0x12835b01, 0x243185be, 0x550c7dc3,
0x72be5d74, 0x80deb1fe, 0x9bdc06a7, 0xc19bf174,
0xe49b69c1, 0xefbe4786, 0x0fc19dc6, 0x240ca1cc,
0x2de92c6f, 0x4a7484aa, 0x5cb0a9dc, 0x76f988da,
0x983e5152, 0xa831c66d, 0xb00327c8, 0xbf597fc7,
0xc6e00bf3, 0xd5a79147, 0x06ca6351, 0x14292967,
0x27b70a85, 0x2e1b2138, 0x4d2c6dfc, 0x53380d13,
0x650a7354, 0x766a0abb, 0x81c2c92e, 0x92722c85,
0xa2bfe8a1, 0xa81a664b, 0xc24b8b70, 0xc76c51a3,
0xd192e819, 0xd6990624, 0xf40e3585, 0x106aa070,
0x19a4c116, 0x1e376c08, 0x2748774c, 0x34b0bcb5,
0x391c0cb3, 0x4ed8aa4a, 0x5b9cca4f, 0x682e6ff3,
0x748f82ee, 0x78a5636f, 0x84c87814, 0x8cc70208,
0x90befffa, 0xa4506ceb, 0xbef9a3f7, 0xc67178f2)
#迭代初始值,h0,h1,...,h7
self.h = (
0x6a09e667, 0xbb67ae85, 0x3c6ef372, 0xa54ff53a,
0x510e527f, 0x9b05688c, 0x1f83d9ab, 0x5be0cd19)
#x循环右移b个bit
#rightrotate b bit
def rightrotate(self, x, b):
return ((x >> b) | (x << (32 - b))) & ((2**32)-1)
#信息预处理。附加填充和附加长度值
def Pad(self, W ,a):
if(a==1):
return bytes(W, "ascii") + b"\x80" + (b"\x00" * ((55 if (len(W) % 64) < 56 else 119) - (len(W) % 64))) + (
(len(W) << 3).to_bytes(8, "big"))
else:
return W+ b"\x80" + (b"\x00" * ((55 if (len(W) % 64) < 56 else 119) - (len(W) % 64))) + (
(len(W) << 3).to_bytes(8, "big"))
def Compress(self, Wt, Kt, A, B, C, D, E, F, G, H):
return ((H + (self.rightrotate(E, 6) ^ self.rightrotate(E, 11) ^ self.rightrotate(E, 25)) + (
(E & F) ^ (~E & G)) + Wt + Kt) + (
self.rightrotate(A, 2) ^ self.rightrotate(A, 13) ^ self.rightrotate(A, 22)) + (
(A & B) ^ (A & C) ^ (B & C))) & ((2**32)-1), A, B, C, (D + (
H + (self.rightrotate(E, 6) ^ self.rightrotate(E, 11) ^ self.rightrotate(E, 25)) + (
(E & F) ^ (~E & G)) + Wt + Kt)) & ((2**32)-1), E, F, G
def hash(self, message,a):
message = self.Pad(message,a)
digest = list(self.h)
for i in range(0, len(message), 64):
S = message[i: i + 64]
W = [int.from_bytes(S[e: e + 4], "big") for e in range(0, 64, 4)] + ([0] * 48)
#构造64个word
for j in range(16, 64):
W[j] = (W[j - 16] + (
self.rightrotate(W[j - 15], 7) ^ self.rightrotate(W[j - 15], 18) ^ (W[j - 15] >> 3)) + W[
j - 7] + (self.rightrotate(W[j - 2], 17) ^ self.rightrotate(W[j - 2], 19) ^ (
W[j - 2] >> 10))) & ((2**32)-1)
A, B, C, D, E, F, G, H = digest
for j in range(64):
A, B, C, D, E, F, G, H = self.Compress(W[j], self.constants[j], A, B, C, D, E, F, G, H)
return "".join(format(h, "02x") for h in b"".join(
d.to_bytes(4, "big") for d in [(x + y) & ((2**32)-1) for x, y in zip(digest, (A, B, C, D, E, F, G, H))]))
def main():
encoder = SHA256()
while True:
a = int(input("输入模式:\n1.字符串\n2.16进制码\n"))
if(a==1):
message = input("Enter string: ")
print(f"Output: {encoder.hash(message,a)}\n")
else:
message = str(input("Enter string: "))
b=bytes.fromhex(message)
print(b)
print(f"Output: {encoder.hash(b,a)}\n")
if __name__ == "__main__":
main()
第6章 消息认证码
消息认证码,或者MAC、用于检测对消息的篡改。
6.1MAC的作用
- 输入:固定长度的密钥K&任意长度的消息m
- 输出:产生固定长度的 MAC 值
- 过程:Alice——>Bob:m&MAC(K,m)(tag), Bob检验T=MAC(K,m')是否成立。
6.2理想MAC与MAC的安全性
- 理想MAC定义:一个从所有可能的输入到n位输出的随机映射。
- 安全性定义:对于MAC的攻击是区分 MAC函数和理想MAC函数的非通用方法。
- 攻击者并不能够完全获取密钥K的值,当然系统其他部分的缺陷可能会泄露密钥K的部分信息。
6.3CBC-MAC和CMAC
CBC-MAC
-
消息m用CBC模式进行加密,而只保留密文的最后一个分组,其余全部丢弃。
-
计算过程
H0:=IV
H1:=Ek(Pi⊕Hi-1)
MAC:=Hk
-
由结构导致的缺陷:已知M(a)=M(b),则对任意的c都有M(a||c)=M(b||c)。
-
攻击手段1:
- 攻击者收集大量消息的 MAC 值,直到产生碰撞。
- 若攻击者从发送者那里得到对消息a||c的认证码,他就可以用b||c代替消息a||c而无须改变MAC值,这个值完全可以通过接收者对 MAC值的验证,从而使接收者接到一个伪造的消息。
-
攻击手段2:假设c为一个分组长度的消息,且满足M(a||c)=M(b||c)。那么对任意分组d有M(a||d)=M(b||d)
- 攻击者收集大量消息的MAC值,直到产生碰撞,得到产生碰撞的a和b。
- 攻击者从发送者获取a||d的认证码,就可以用 b||d代替消息 a||d而无须改变 MAC 值
-
合适使用方式:
- 从l||m 构造位串s,其中1是消息m在固定长度格式下的编码长度。
- 对s进行填充使得其长度为分组长度的整数倍。
- 对填充后的位串s应用 CBC-MAC。
- 输出最后一个密文分组或它的一部分,切记不要输出任何中间值。
-
优点:与分组密码加密模式有相同模块,效率更高
-
缺点:方法难以使用
CMAC
- 基于CBC-MAC由NIST标准化
- 相比CBC-MAC只对最后一个分组的处理有所区别:在进行最后一次分组密码加密之前,CMAC将两个特殊值中的一个与最后一个分组进行异或。这些特殊值从 CMAC的密钥产生,被 CMAC 用到的那个值取决于消息的长度是否为分组块长度的倍数。在 MAC运算中引入对这些值的异或可以防御在不同长度的消息中使用 CBC-MAC 所面临的攻击。
6.4 HMAC
- 散列函数构造MAC:h(K⊕a||h(K⊕b||m)
- 由于HMAC对消息的头部进行散列运算时基于一个密钥,所以基于SHA-1的HMAC算法不会比 SHA-1算法差
- 安全性:n/2位的安全性,但需要和系统进行2n/2次交互
- 结构清晰,易于实现
6.5 GMAC
- 针对128位分组密码设计
- 三个输入:密钥、待认证消息、瞬时值,其中瞬时值是经传输或是隐含的(如包计数器)
- 攻击模型:攻击者选择n个不同的消息,然后得到每个消息对应的 MAC 值。攻击者如果不能够提出与前面选择的n个消息不同的第n+1个消息和相应的有效 MAC 值,那么这样的 MAC 就是不可伪造的。
- 问题:减少长度会将降低安全性,提供瞬时值有风险
6.6如何选择MAC
- 推荐HMAC-SHA-256:以 SHA-256 作为散列函数的HMAC。
6.7MAC的使用
- Horton 原则:认证消息所包含的含义而不是消息本身。
- MAC认证的不仅是消息m,还包括Bob解析消息m以获取含义所需要的所有信息
- 进行认证时,总要仔细考虑哪些信息应该包含在认证的范围内,确保将包括消息本身
在内的所有信息编码为一个字节串,而且编码应保证能以唯一的方式解析为原先的各个数据
域。这
6.8习题
6.1 试描述一个使用CBC-MAC进行消息认证的真实系统,并分析对于CBC-MAC进行长度扩充攻
击下的系统脆弱性
6.2 假设c为一个分组长度,a和b是多个分组长度的位串,且有M(ae)=M(be),这里M为CBC.MAC 函数。试证明对于任意分组d。有M(@小)-M(b】d小。
6.3 假设消息a和b的长度为一个分组大小,发送者分别对消息a,b、qb进行CBC-MAC运算。攻
[97击者截获经过 MAC运算后的标签,然后伪造消息抓(M(b)田M(a)④b),这个伪造后的消息标签
为 M(ab),也即消息 apb的标签。试用数学方法证明。
6.4 假设消息a的长度是一个分组的大小。假设攻击者截获MAC值r,这个值是消息a通过随机密
钥下的CBC-MAC进行计算得出的值,密钥是攻击者未知的。试解释如何选取一个长度为2个分
组的消息并伪造相应的MAC。试解释为何伪造的标签对于所选取的消息来说是有效的。
6.5 使用现有的密码库,使用基于AES的CBC-MAC算法,采用如下256位密钥∶
80 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 01
计算如下消息的 MAC 值∶
4D 41 43 73 20 61 72 65 2076 65 72 79 20 75 73
65 66 75 6c 20 69 6E 20 63 72 79 70 74 6F 67 72
61 7058 79 21 20 20 20 2020 20 20 20 20 20 20
6.6 使用现有的密码库,使用基于SHA-256的HMAC算法和如下密钥∶
0b 0b 0b 0b 0b 0b 0b 0b 0b 0b 0b 0b 0b 0b 0b 0b
0b 0b 0b 0b 0b 0b 0b 0b 0b 0b 0b 0b 0b 0b 0b 0b
计算如下消息的 MAC 值∶
4D 41 43 73 20 61 72 65 2076 65 72 79 20 75 73
65 66 75 6c 20 69 6E 20 63 72 79 70 74 6F 67 72
61 70 68 79 21
消息对应字符为MACs are very useful in cryptography!
import hmac
import hashlib
def hmac_sha256(key, value):
message = value.encode('utf-8')
return hmac.new(key.encode('utf-8'), message, digestmod=hashlib.sha256).hexdigest()
print(hmac_sha256('\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b', "MACs are very useful in cryptography!"))
计算得到mac值db8b895abc88a59cf8776a233ee1457c7239380347ef4dca8e48bc88433167eb
6.7 使用现有的密码库,采用基于AES的GMAC算法和如下256位密钥;
80 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 01
计算如下消息的 MAC 值∶
4D 41 43 73 20 61 72 65 20 76 65 72 79 20 75 73
65 66 75 6C 20 69 6E 20 63 72 79 70 74 6F 67 72
61 70 68 79 21
其中瞬时值为
00 00 00 00 00 00 00 00 00 00 00 01.
答:消息对应字符为MACs are very useful in cryptography!没有找到GMAC的实现方法
问题
为什么在6.3中说对于理想的 MAC 函数,找到了碰撞并不是问题,即使得到了满足条件M(a)= M(b)的两个消息a和b时,也不能够为新消息伪造一个 MAC 值?
第7章 安全信道
7.1安全信道的性质
大致定义:A与B间安全的连接
7.1.1角色
- 双向连接,同时有不对称(区别)
- 存在攻击者,可以读取并操纵内容
- 存储可看作向未来发送数据
7.1.2密钥
- 要求:
- 只有 Alice 和 Bob 知道密钥 K。
- 每次安全信道被初始化时,就会更新密钥 K。
- 安全信道的设计要达到128 位的安全性需要256 位长度
7.1.3消息或字节流
- 考虑离散数据流
- 密码学家视角:没有可靠的通信协议,通信意义上的可靠协议智能反丢失,且不能防止攻击者在数据流里修改、插入、(移除?)数据等主动攻击
7.1.4安全性质
- 隐私性:除了消息mi,的长度和发送时间外,Eve无法得到有关消息mi的任何其他信息
- 准确顺序:即使 Eve通过操纵正在传输的数据对信道进行攻击,Bob接收到的消息序列m'1,m'2,⋯必须是序列m'1,m'2,⋯的子序列。并且Bob很清楚地获悉他收到的是哪一个子序列(子序列就是从原序列中去掉0个或更多的元素后得到的序列)。
7.2认证与加密的顺序
-
先加密,后认证
原因:
- 先加密更安全,MAC能修补加密函数的某些缺陷
- 丢弃消息更有效,更能应对DoS类攻击
-
先认证,后加密
原因:
- 由于要先突破加密,对MAC的攻击更困难,而加密函数更为坚固
- Horton原则:要对消息的含义进行认证,而不是对消息本身进行认证。后认证会引发风险
-
同时加密和认证,将结果组合起来
原因:能够提高性能,但MAC有可能泄露消息的隐私信息
7.3安全信道设计概述
7.3.1消息编号
- 特性:单调增加且唯一
- 作用:
- 为加密算法提供需要的IV;
- 拒绝重放的消息;
- 判断在通信过程中丢失了哪些消息;
- 以正确的顺序接收消息。
- 惯例:
- 32位长度:可满足大多数应用
- 从1计数:N种可能中有N-1个作为编号,0作为编码已用完(3)
7.3.2认证
- 采用用HMAC-SHA-256作为认证函数
- Mac值a可计算如下ai:=MAC(i||l(xi)||ximi),其中l(xi)可以帮助准确地解析区域
7.3.3加密
-
使用CTR模式下的AES,且将瞬时值的处理内嵌(将消息编码作为唯一瞬时值)
-
密钥流由k0,k1,⋯组成,对瞬时值为i的消息,密钥流定义为∶k0,k1,⋯k236-1=E(K,0||i||0)||E(K,1||i||0)||…||E(K,232-1||i||0)||
每个明文分组由32 位的分组编号、32位的消息编号以及64 位的0组成
7.3.4组织格式
- 由于Bob需要知道消息编号,所以消息应由编码为 32 位整数的i(其中最低有效字节在前)与加密后的mi和 ai组成……i不加密!
7.4详细设计
7.4.1初始化
-
初始化算法包含建立密钥和建立消息编号
函数 InitializeSecureChannel 输入∶ K 256 位的信道密钥 R 角色说明,确定参与方是 Alice 还是 Bob 输出∶ S 安全信道的状态 首先计算所需要的4个密钥。这4个密钥是没有长度或以零终止的ASCII字符串。 KeySendEnc ← SHA-256 (K"Enc Alice to Bob") KeyRecEnc ← SHA-256 (K"Enc Bob to Alice") KeySendAuth ← SHA-256 (K"Auth Alice to Bob") KeyRecAuth ← SHA-256(K"Enc Bob to Alice") #如果参与方是 Bob,交换加密密钥和解密密钥。 if R= "Bob" then swap(KeySendEng, KeyRecEnc) swap (KeySendAuth, KeyRecAuth) fi #将发送和接收的计数器置0。发送计数器是发送的最后一个消息的编号,接收计数器是接收的最后一个消息的编号。 (MsgCntSend,MsgCntRec) ←-(0,0) #将状态打包 S←-(KeySendEne, KeyRecEnc, KeySendAuth, KeyReAuth, MsgCntSend, MsgCntRec) return S -
还应存在清除状态信息S的函数来清除内存
7.4.2发送消息
-
此模块以会话状态、要发送的消息以及用于认证的附加数据为输入,输出准备发送的已加密和认证的消息。接收者必须拥有相同的附加数据以进行认证检查
函数 SendMessage 输入∶ S 安全会话状态 m 要发送的消息 x 用于认证的附加数据 输出∶ r 发送给接收者的数据 首先检查消息编号并更新。 assert MsgCntSend < 2^32- 1 MsgCntSend ← MsgCotSend + 1 i ← MsgCntSend #计算认证码,l(x)和i 都用 4 个字节编码,最低有效字节在前。 a←HMAC-SHA-256(KeySendAuth, i||l(x)||x||m) t←m||a #生成密钥流。分组密码的每个明文分组由4个字节的计数器、4个字节的i以及8个全0字节组成,整数的最低有效字节在前。E是使用 256 位密钥的AES 加密算法。 K ←KeySendEnc k ←E(0||i||0)←E(0||i||0)·⋯ #形成最终的文本。i用 4个字节编码,最低有效字节在前。 t ←- i||(t⊕First-l(r)-Bytes(k)) return t -
检测消息计算器是否达到最大值
-
将i与加密和认证的消息一起发送
-
如要填充,请在解密时验证
7.4.3接收消息
-
输入有SendMessage算法计算出来的经加密和认证后的消息,以及用于认证的附加数据x
函数 ReceiveMessage 输入∶ S 安全会话状态 t 接收者收到的数据 x 用于认证的附加数据 输出∶ m 实际发送的消息 接收者收到的信息必须至少包含有4个字节的消息编号和32个字节的MAC域,这个检查保证以后对消息的分割可正常进行。 assert (1) ≥ 36 #将t分割为i、加密的消息和认证码。分割是确定的,因为i总是占用4个字节 i||t ←- 1 #生成密钥流,过程如同发送者。 K ←- KeyRecEnc k ←- E((0||i||0)E(1||i||0)… #解密消息和 MAC域并进行分割。分割是确定的,因为a总是占用 32个字节。 m||a ←t⊕First-l(r)-Bytes(k) #重新计算认证码。l(x)和i都用 4个字节编码,最低有效字节在前。 a' ← HMAC-SHA-256(KeyRecAuth,i||l(x)||x||m) if a'≠ a then destroy k,m return AuthenticationFailure else if i ≤MsgCntRec then destroy k, m return MessageOrderError fi MsgCntRec ←-i return m -
收到大量错误包应检测系统
-
在返回错误信息前销毁数据k和m
7.4.4消息的顺序
- 接收者同发送者一样,通过修改MsgCntRec变量来更新状态S
- 解决颠倒问题
- 通过修复传输层来防止消息顺序颠倒
- 保留重放保护窗口,最新消息为c则保留c-31~c的位图,相当于计网中滑动窗口?
- 当安全信道运行于可靠传输协议上时,丢包时就立即停止(表明行道出现了某种错误)
7.5备选方案
由于SHA-256的开销非常高,所以考虑使用一些专用的分组密码模式
-
OCB模式
效率很高,并行处理,但受限于专利
-
CCM模式
将CTR加密和CBC-MAC认证结合,但计算量是OCB的两倍
-
CWC模式
CTR加密,底层全域散列认证,并行处理效率高,改进模式GCM
7.6习题
7.1 在安全信道的设计中,我们提到消息编码不能重复。那么如果消息编码重复出现,会产生什么后果?
答:如果消息编码重复出现,不能判断是哪一条信息是应该放在此顺序的消息。
7.2 将本章设计的安全信道算法修改为使用先加密然后认证的顺序。
答:初始化部分不变
发送消息部分:
函数 SendMessage
输入∶ S 安全会话状态
m 要发送的消息
x 用于认证的附加数据
输出∶ r 发送给接收者的数据
首先检查消息编号并更新。
assert MsgCntSend < 2^32- 1
MsgCntSend ← MsgCotSend + 1
i ← MsgCntSend
#生成密钥流并加密
K ←KeySendEnc
k ←E(0||i||0)←E(0||i||0)·⋯
t ←- m⊕(First-l(m)-Bytes(k))
a←HMAC-SHA-256(KeySendAuth, i||l(x)||x||t)
t ←- i||t||a
return t
接受消息部分:
函数 ReceiveMessage
输入∶ S 安全会话状态
t 接收者收到的数据
x 用于认证的附加数据
输出∶ m 实际发送的消息
接收者收到的信息必须至少包含有4个字节的消息编号和32个字节的MAC域,这个检查保证以后对消息的分割可正常进行。
assert (1) ≥ 36
i||t||a ←- t
#重新计算认证码。l(x)和i都用 4个字节编码,最低有效字节在前。
a' ← HMAC-SHA-256(KeyRecAuth,i||l(x)||x||t)
if a'≠ a then
destroy k,m
return AuthenticationFailure
else if i ≤MsgCntRec then
destroy k, m
return MessageOrderError
fi
#生成密钥流并解密
K ←- KeyRecEnc
k ←- E((0||i||0)E(1||i||0)…
m ← t⊕First-l(m)-Bytes(k)
MsgCntRec ←-i
return m
7.3 修改本章的安全信道算法,其中使用专用的单密钥模式来提供加密和认证。可以使用OCB、CCM、CWC或 GCM 作为黑盒。
7.4 试分析比较在安全信道设计中以不同顺序应用加密函数和认证函数的优缺点。
答:
- 先加密,后认证可通过MAC能修补加密函数的某些缺陷,并且丢弃消息更高效,更能应对DoS类攻击,但对于MAC的攻击难以预防
- 先认证,后加密可使对MAC的攻击更困难,想要获取MAC需要破解加密,可加密函数更为坚固,还不违背Horton原则,但如果认证的安全性依赖于加密的安全性,如果不得不采用一些有缺陷的加密函数,则难以保证安全
- 同时加密和认证能够提高性能,但MAC有可能泄露消息的隐私信息
7.5 试以一个安全信道的产品或系统为例,可与习题1.8中所分析的产品或系统相同。试根据1.12 节中提到的方法,这个产品或系统进行安全审查,但这里着重讨论与安全信道相关的隐私和安全问题
7.6 假设Alice 和Bob的通信过程使用本章中所设计的安全信道。Eve是在通信过程中的窃听者。Eve通过窃听加密信道上的通信可以获得何种类型的流量分析信息?试描述一种情况,其中通过流量分析导致的信息泄露是一种非常严重的隐私问题。
答:Eve可获得轻松获得消息编号。Eve可知晓两人活动的频率,还可通过消息编号的重置判断系统开启与连接时间,如果可以通过系统外观测,还可推断其他隐私。
第8章 实现上的问题I
- 木桶原理:寻找与实现有关的漏洞比寻找加密系统的弱点更容易
- 正确实现密码学的原因:
- 让人们认识到安全性的隐患,以及正确实现安全性的重要性
- 对加密系统的攻击不可见,危害性极大
- 密码系统会得到长久的使用
8.1创建正确的程序
正确性:运行和规范完全一致
IT行业不知道如何写出正确的程序或模块
8.1.1规范
-
问题:功能规范文档缺失或缺乏,无法定义和检验正确性
-
程序规范三阶段:
-
需求规范∶关于程序应当完成的功能的非正式描述。
What而不是How,注重宏观结构,不注重实现细节
-
功能规范∶功能规范对程序的行为进行详尽的细节定义。
只对可在程序外部度量的部分进行规范。是测试已经完成的程序的基础,规范中的任意一项都可以|应该被测试。
-
实现设计∶ 指定了程序内部的工作方式,包括了所有无法从外部进行测试的部分。
好的实现设计通常将程序分成几个模块,并对各个模块的功能进行描述,好到描述可作为需求规范
-
8.1.2测试和修复
测试只能表现出错误的存在,但是不能够证明错误是不存在的
- 如果发现一个程序中的错误,首先实现一个检测这个错误的测试,并验证它能够检测出这个错误。然后修正这个错误,并确保测试程序不能再检测到这个错误。最后,继续在每一个后续版本上运行这个测试程序,以确保这个错误不再出现。
- 一旦发现了一个错误,找出引发这个错误的原因,同时全面检查程序。看在程序的其他地方是否还有类似的错误。
- 对发现的每一个错误进行跟踪。对错误进行简单的统计分析可以显示程序的哪—部分容易有错误,或哪一类错误会经常发生等等,这种反馈对一个质量控制系统来说是必要的。
8.1.3不严谨的态度
- 人们对程序中的错误有着不可置信的不严谨的态度,程序中的错误被认为是自然而然的事情。
8.1.4如何着手
- 参考航空工业:安全系统涉及行业里的每一个人;对几乎每一步操作都有非常严格的规则和过程;在出现故障的情况下有多种备用的方案。
- 编写正确程序成本高,但与潜在错误所付出的代价相比,长期来看划算
8.2制作安全的软件
标准的实现技术完全不适合于编写安全的代码。
- 正确的软件:按下按钮A,发生事件B
- 安全的软件:无论如何不会发生事件X
8.3保守秘密
我们需要防止秘密信息(密钥、数据)泄露,它们在内存中短期(瞬时?)存储
8.3.1清除状态
原则:立即将不再使用的数据清除
引申:在对存储介质失去控制之前,应该清除里面存储的信息
- 原因:数据保存的时间越长,其他人获取数据的机会就越大
- 方法:在库中依靠主程序清除秘密,如C++中对象的析构函数、Java中的finalization函数;最好在语言层面就能为清除数据提供支持
- 危险:使用库进行开发的程序员不好调用清除函数;编辑器优化后改变了函数执行过程;秘密信息已被垃圾回收程序处理而无法清除
8.3.2交换文件
- 虚拟内存系统原理:当运行一个程序时,并不是所有的数据都保存在内存里,其中有些被存在一个交换文件中,当试图访问那些不在内存中的数据时,程序就被中断,虚拟内存系统从交换文件中读出所需要的数据并放入内存,然后这个程序继续运行。另外,当需要更多的可用内存空间时,将会从被某个程序占用的内存空间中任取一块,并将这个程序写入交换文件。
8.3.3高速缓冲存储器
- 定义:存储量比较小但速度比较快的内存,在主存和CPU之间,保存了主内存中最近使用的数据的副本
- 原理:高速缓冲存储器保存了主内存中最近使用的数据的副本,如果 CPU要访问这些数据,它首先检查高速缓冲存储器。如果数据在高速缓冲存储器中,则 CPU 就会以相对较快的速度得到这些数据;如果数据不在高速缓冲存储器中,则 CPU就从主内存里读数据(相对较慢),并把数据的副本保存在高速缓冲存储器中方便以后使用。
- 风险:
- 数据的修改在高速缓冲存储器中发生而没有写入主内存
- 标记为无效数据却没清除
8.3.4内存保留数据
- 内存会驻留一些旧数据,重新通电后即可恢复部分或所有
- SRAM(静态RAM)中:如果相同的数据存入内存的同一单元一段时间,那么该数据将变成这个内存单元所优先的通电状态。(类似烧屏)
- DRAM(动态RAM)中:DRAM通过在非常小的电容器上存储一个小电荷来工作,电容器周围的绝缘材料将会受到产生的电场作用,导致这些材料发生变化,特别会引起杂质迁移。电容器不放电,数据不消失
8.3.5其他程序的访问
- 共享内存通常由两个程序设立以降低风险
- 调试器和超级用户都能够访问内存数据
8.3.6 数据完整性
传输中用MAC保证完整性,本地(使用操作系统)应保证硬件设施可靠
- 考虑到会处理大量数据,可使用ECC内存降低错误的可能性
- 应注意超级用户和调试器修改程序内存权力
8.3.7需要做的工作
- 操作系统和编程语言都不支持完全阻止泄露的功能,只能根据具体工作环境尽力而为
8.4代码质量
8.4.1简洁性
定义:消除不必要的选项和特性
目的:为减少复杂性而代理的威胁而简洁
- 不使用委员会提供的一致性设计,其加入的额外特性会增加复杂性
- 不为用户提供额外选项以保证默认的安全性,最多只提供安全or不安全
- 帮助用户做出最好的安全单一的模式选择
8.4.2模块化
定义:将系统分成一些模块,然后分别设计、分析、实现每一个模块
目的:可使复杂系统一管理
- 每一个模块都应只解决自己的问题,提供简单易懂的接口
- 可在单个模块的环境下分析原因,而不是牵一发而动全身
- 应确保任务可以大批量地完成,而且仅仅优化那些对程序可度量的性能产生重大影响的部分。
8.4.3断言
定义:每个模块都不能信任其他模块,并且始终检测参数的有效性,强迫限制调用顺序,并且拒绝执行不安全的操作
目的:捕捉尽可能多的错误
- 规范文档应带有每一个断言失败及对应的失败原因
- 任何时候,在可以对系统内部的一致性进行检查时,就应该增加一项断言。捕捉尽可能多的可以捕捉到的错误,
- 在实际系统中保留所有错误检查,使用户能够发现产生了错误结果
8.4.4缓冲区溢出
- 缓冲区溢出难以避免,所以不要使用允许缓冲区溢出的编程语言
8.4.5测试
目的:发现隐含错误而不是安全漏洞
测试集类型:
-
由模块功能规范产生的通用测试集
-
应尽量覆盖模块间的所有功能
-
理想方法:一人实现,一人测试
-
-
由模块程序员自己开发出来的测试程序,用来测试对程序实现的限制
- 需要对模块内部设计有所了解
- 伪随机数测试:可用伪随机数快速生成测试序列
- 快速测试代码:用已知正确的结果检测输出来判断代码正确性
8.5侧信道攻击
- 必要性:对没有考虑侧信道的系统,侧信道攻击的成功率很大
- 抵抗方式:结合各自应对措施,包括软硬件
- 实际上侧信道攻击难以执行,(可能)只对智能卡有真正威胁
8.6一些其他的话
-
安全性不只与密码系统的设计有关,而是和系统的各个方面都有相关,它们各尽其责以实现系统的安全性
-
保证代码质量:考虑从开始开发到最终产品的时间,而不是开始开发到第一个有缺陷版本完成的时间
-
推荐书目:
MeGraw的《Software Security∶ Building Security In》
Howard和Lipne编写的《The Security Development Lifecycle》
Dowd、McDonald和Schuh的《The Art of Software Security Assessment; Identifying and Preventing Software Vulnerabilities》
8.7习题
8.1 结合个人计算机的硬件和软件配置,分析8.3 节中所提到的各类问题。
答:在升级电脑时,如果需要二手处理硬盘的话,我们需要考虑清空硬盘中的数据防止自己的隐私泄露。仅仅格式化清空硬盘是不够的,一些数据位还是会存在原地址上,只是标志位表示那些数据位位空而已。我们可以在格式化后在硬盘中反复拷贝大文件以刷掉原地址位置上可能存在的敏感数据。软件方面,不少浏览器和社交软件上都会自动存储用户的登录密码,就像是未清空的数据位容易被攻击者利用。而且由于人的记忆是有限的,总有密码重合的情况,攻击者在略尽推理后很容易得到过去甚至未来的密码。9.6 种子文件管理
第三部分 密钥协商
第9章生成随机性
- 熵的位数n:该数有2n 个?随机期望?取值,表示某种混乱程度
- 随机变量X的熵的常用定义如下∶
H(X):=-ΣP((X=x)log2P(X = x)
9.1真实随机
- 计算机的多种熵源:按键的精确时长、鼠标的精确移动轨迹、硬盘内部湍流引起的硬盘访问时间的随机波动
- 这些熵源是可疑的:“采集到的”数据并不随机,且易受侧信道攻击
- 计算机内置真实随机数生成器:仅允许操作系统访问
9.1.1使用真实随机数的问题
- 随机数不是随时都可以获取的。Web服务器无按键&不能提供大量随机数
- 真实的随机源有可能失效。在计算机噪声环境容易失效&失效无法预测
- 从某一具体的物理事件中能够提取多少熵难以判断。
9.1.2伪随机数
- 通过确定性算法从种子计算种得到
- 初衷是消除设计上的缺陷
9.1.3真实随机数和伪随机数生成器
-
真随机数只用于作伪随机数的种子,系统会更安全
-
真随机数的协议安全性:无条件安全
伪随机数的协议安全性:在攻击者无法攻破生成器的前提下可保证计算上安全
9.2伪随机数生成器的攻击模型
关键问题:如何获取一个随机种子并保证它在实际环境中是保密的
-
内部状态:生成伪伪随机数后更新状态以保证下次请求不会得到相同随机数
攻击:通过某种方式获取内部状态后,可计算出后面所有的输出和后续所有内部状态
-
多次使用:相同实例启动的虚拟机使用相同的状态,并从磁盘上读取相同的种子文件
方案:一个真实的随机数生成器来作为熵,在不可预测的实践内提供适量熵
攻击:频繁地提交随机数,因为两次请求间所添加的熵是有限的(环境因素?)
-
防御方法:使用一个熵池来存放包含熵的传入事件,收集足够多的熵混入内部状态,以保证攻击者无法猜测出熵池中存放的数据,但难以估测熵大小以确定熵池大小
9.3 Fortuna
- 生成器负责采用一个固定长度的种子,生成任意数量的伪随机数
- 累加器负责从不同的熵源收集熵再放入熵池中,并间或地给生成器重新设定种子
- 最后,种子文件管理器负责保证即使在计算机刚刚启动时伪随机数生成器也能生成随机数
9.4生成器
-
生成器负责将固定长度的内部状态转换为任意长度的输出
-
基本上可以认为是一个计数器模式的分组密码,CTR模式能够输出一串随机数据流。
-
不能同时生成太多随机数据:为保证统计随机性
-
攻击进展的快慢不是由攻击者的计算机决定的,而是由被攻击的计算机的性能决定的
-
每次请求结束后,分组密码的密钥会被重置,但是计数器不需要重置
9.4.1初始化
- 密钥和计数器为0表示生成器没获取种子
函数 InitializeGenerator
输出∶G 生成器状态
将密钥K 和计数器 C 设置为 0。
(K,C)⬅ (0,0)
获取状态。
G⬅(K,C)
return G
9.4.2更新种子
- 为保证输入字符串和现有密钥完全混合使用散列函数
函数 Reseed
输入∶ G 生成器状态,由函数修改
s 新的额外种子
使用散列函数计算新密钥。
K⬅ SHA-256(K||s)
计数器的值加1,但要保证结果不为 0,同时标记生成器已经获取种子在生成器中,C 为 16 字节的整数并且最低有效字节在前。
C⬅ C+1
9.4.3生成块
- 生成多个随机块,但只能被生成器调用
函数 GenerateBlocks
输入∶ G 生成器状态,由函数修改
k 生成的随机块的数量
输出∶ r 16k字节的伪随机字符串
assert C ≠0
以空字符串开始。
r←ε
将k个块进行链接。
for i =1,…,k do
r← r||E(K,C)
C⬅ C+1
od
return r
9.4.4生成随机数
- 最大输出长度为220 ,同时确保之前的结果信息被清除
函数 PesudoRandomData
输入∶ G 生成器状态,由函数修改
n 生成的随机数据的字节个数
输出∶ r 长度为n字节的伪随机字符串
限制输出的长度是为了减少随机输出的统计误差,同时也需要保证n非负。
assert 0 ≤n ≤ 20
计算输出。
r ←fist-n-bytes(GenerateBlocks(G,[n/16]))
更新K以避免泄露输出。
K ⬅ GenerateBlocks(G,2)
return r
- 更新密钥后,r无法被看出来
- 保密前向:只要没有保留r的副本、没有忘记清除内存单元,生成器就无法泄露r的任何信息
9.4.5生成器速度
- 依赖于使用的分组密码算法,平均每产生1字节的输出需要花费的时间低于 20 个时钟周期。
9.5累加器
- 负责从不同的嫡源中获取实随机数,并用来更新生成器的种子。
9.5.1熵源
- 熵源选择:
- 将所有看起来不可预测的数据都用作熵源 如:按键时长和鼠标的移动
- 尽可能多地使用实际可行的其他时序上的熵源 如:按键的精确时长、鼠标的移动和点击、硬盘和打印机的响应
- 熵源都会被嵌入到操作系统的各种硬件驱动器中,用户几乎不可能完成这项工作。
- 将不同熵源产生的事件链接起来,同时为了保证链接后获得的字符串唯一标识这
些事件,必须确保这个字符串是可解析的。
9.5.2熵池
- 安全地更新生成器种子:熵池足够大以至攻击者无法穷举出熵池中事件的所有可能值
- Fortuna法:设置 32个熵池P0,P1,⋯,P31。理论上,每个熵池都包含一个(无限长的)字符串(用作散列函数输入)P0池中字符串长度足够时,就更新生成器的种子,每个种子都标记了序号1,2、3,⋯,根据种子的序号r,一个或多个池中的字符串会被用来生成种子。生成第r个种子时。如果2i是r的倍数,那么第i个熵池中的字符串就会被使用。因此,每次生成种子都会用到P0,每生成两个种子P1会被用到一次,每生成四个种子P2会被用到一次等。一旦某个熵池
参与生成新的种子,熵池中的内容就会被重置为空字符串。 - 若生成器的某个状态被泄露了,那么它恢复到安全状态的速度取决于熵(攻击者无法预测的那部分)流入熵池的速度
- 由于熵池有限,P31可能在两次更新种子之间无法收集到足够的随机性来使生成器恢复到安全状态
9.5.3实现注意事项
-
基于熵池的事件分发
-
基本方法:累加器分发
风险:攻击者调用累加器,通过额外重复调用影响“真实事件”(熵)
解决方法:产生事件的同时就确定事件将要放入的熵池号
-
累加器可以检查熵源是不是按正确的顺序将事件放入到熵池中。但不能通过验证时应延迟驱动,丢失熵
-
-
事件发送的运行时间
-
必须将事件数据添加到指定的熵池中时,我们需要计算缓冲区中的部分散列值
-
通过使CPU 总是在执行一小段的循环程序并不让它在不同的代码段之间进行切换提高性能
-
扩大熵池的缓冲区,使得在计算散列值之前缓冲区中能够收集到更多的数据
优点:减少CPU计算总时间
确定:将事件添加到熵池所需时间变长
-
9.5.4初始化
函数 InitializePRNG
输出∶R 伪随机数生成器状态
将 32 个熵池中的内容都设为空字符串。
for Pi=0..31 do
Pi⬅ ε
od
将种子更新计数器设为0。
ReseedCnt ⬅ 0
初始化生成器。
G ⬅ InitializeGenerator()
获取状态。
R ⬅ (G, ReseedCnt, P0,⋯,P31)
return R
9.5.5获取随机数据
函数 RandomData
输入∶ R 伪随机数生成器状态,由函数修改
n 生成的随机数据的字节数
输出∶ r n字节的伪随机字符串
if length(P)≥MinPoolSize Alast reseed>100 ms ago then
需要更新种子。
ReseedCnt ← ReseedCnt +1
添加需要使用的所有嫡池中字符串的散列值。
s ← ε
for i ε 0,⋯,31 do
if 2^i||ReseedCnt then
s ← s||SHA-256(Pi)
Pi ← ε
fi
od
取得随机数据之后需要更新种子。
Reseed(G, s)
fi
if ReseedCnt=0 then
报错,伪随机数生成器还没有获取种子。
else
种子已经更新(如果需要的话)。让R的生成器部分来生成随机数。
return PseudoRandomData(G,m)
fi
- 不建议使用比 32字节更小的值:熵源能够高效稳定地提供熵,种子的更新速度也会很缓慢
9.5.6添加事件
函数 AddRandomEvent
输入∶R 伪随机数生成器状态,由函数修改
s 熵源号,取值范围0,,255
i 熵池号,取值范围0,⋯,31。每个熵源必须循环地将它产生的事件分发到所有熵池中
e 事件数据,1 ~ 32 字节的字符串
首先检查参数。
assert1≤length(e)≤32^0≤s≤255^0≤i≤31
将事件数据添加到熵池中。
Pi←Pi||s||lengrh(e)||e
- 还可以让熵源仅仅把事件发送给累加器进程,再由累加器创建一个单独的线程负责所有的散列运算:设计复杂但能减轻熵源运算负担
9.6种子文件管理
- 目的:避免重启收集收集过长和首个状态可预测
9.6.1 写种子文件
函数 WriteSeedFile
输入∶R 伪随机数生成器状态,由函数修改
f 需要写入的文件
write(f,RandomData(R,64))
9.6.2 更新种子文件
函数 UpdateSeedFile
输入∶ R 伪随机数生成器状态,由函数修改
f 需要更新的文件
s ← read(f)
assert length(s) = 64
Reseed(G, s)
write(f, RandomData(R,64))
- 保证在更新种子和更新种子文件之间伪随机数生成器没有被调用过
9.6.3 读写种子文件的时间
- 在关闭计算机之前对种子文件进行更新。在不关机情况下,需要定时更新种子文件
9.6.4 备份和虚拟机
-
大多存放种子的文件系统不能避免出现重复状态
例:利用备份还原时就会出现重复状态
-
解决方法:修复备份系统使得它对伪随机数生成器敏感
-
相同问题:同一虚拟机的重启和多个虚拟机的同时开启
9.6.5文件系统更新的原子性
- flush的非即时性,受控于硬件和操作系统
- 使用日志解决,但不能达到要求
9.6.6初次启动
- 由于需要等待熵更新种子,启动时间很长,无法确认是否已经收集到足够的熵来生成良好的密钥
- good 方法:利用安装时的配置过程生成随机种子
- best方法:利用一个外部随机源创建第一个种子文件
9.7选择随机元素
- 令k为满足2* ≥n的最小整数。
- 利用伪随机数生成器生成一个k位的随机数K,K的范围为0,⋯,2'-1。
- 伪随机数生成器生成的是一定数量的字节,所以可能需要丢弃最后一个字节的部分位。
- 如果K≥n,返回第2步。
9.8习题
9.1 研究最喜欢的三种编程语言中自带的随机数生成器。你会把它们用于密码中吗?
答:python中默认使用梅森旋转生成,C中默认使用
9.4 分析伪随机数生成器和随机数生成器各自的优缺点。
答:伪随机生成器能够快速生成伪随机数,但是随机数在足够大范围内由一定规律性
随机数生成器完全随机,但生成数据慢,而且会受软硬件采集设备精度影响
9.5 使用一个能够输出随机位流的密码学伪随机数生成器,来实现一个能够从0,1,⋯,-I}
(1≤, ≤ 2')中随机选择整数的随机数生成器。
答:使用平方取中、线性同余和梅森旋转法实现了要求的随机数算法
import matplotlib.pyplot as plt
import datetime
import math
import numpy as np
import random
import time as tm
def scatter_test():
points = b
x, y = zip(*points)
plt.figure()
plt.scatter(x, y, 1,"r",".",alpha=0.1)
plt.show()
def midsquare(x,Num,time):
a_0=str(time)[-6:]
a_1=str(int(a_0)**2)
for i in range(Num):
while(len(a_1)!=len(a_0)*2):
a_1=str((x[i-1]%(i+1))%9+1)+a_1
a_2=a_1[3:9]
j=0
while(a_2[j]=='0'):
a_2=a_2+str(((x[i-1]%(i+1))%10))
j=j+1
x[i]=int(a_2)%numRange+startNum
a_0=a_2
a_1=str(int(a_2)**2)
def LCG(x,Num,time):
a_0=int(str(time)[-3:])
alpha=16807
beta=0
m= 2147483647
a=4*alpha+1
c=2*beta+1
for i in range(Num):
a_1=(a*a_0+c)%m
x[i]=a_1%numRange+startNum
a_0=a_1
def _int32(x):
return int(0xFFFFFFFF & x)
class MT19937:
def __init__(self, seed):
self.mt = [0] * 624
self.mt[0] = seed
for i in range(1, 624):
self.mt[i] = _int32(1812433253 * (self.mt[i - 1] ^ self.mt[i - 1] >> 30) + i)
def extract_number(self):
self.twist()
y = self.mt[0]
y = y ^ y >> 11
y = y ^ y << 7 & 2636928640
y = y ^ y << 15 & 4022730752
y = y ^ y >> 18
return _int32(y)
def twist(self):
for i in range(0, 624):
y = _int32((self.mt[i] & 0x80000000) + (self.mt[(i + 1) % 624] & 0x7fffffff))
self.mt[i] = y ^ self.mt[(i + 397) % 624] >> 1
if y % 2 != 0:
self.mt[i] = self.mt[i] ^ 0x9908b0df
def Mersenne(x,Num,time):
for i in range(Num):
x[i]=(MT19937(int(str(time)[-6:])+i).extract_number())%numRange+startNum
def PYTHON(x,Num,time):
for i in range(Num):
x[i] =random.randint(startNum,endNum)
if __name__ == "__main__":
while(1):
startNum = int(input("请输入起始范围:"))
endNum = int(input("请输入终止范围:"))
if(endNum>startNum):
numRange = endNum -startNum + 1
break
else:
print("请重新输入")
Num = int(input("请输入随机数个数:"))
time=datetime.datetime.now()
print(time)
a=np.arange(Num)
while 1:
print("1.平方取中\n2.线性同余\n3.梅森旋转\n4.python\n0.结束")
mode = int(input("请输入随机模式:"))
start = tm.perf_counter()
if(mode == 1):
midsquare(a,Num,time)
elif (mode == 2):
LCG(a,Num,time)
elif (mode == 3):
Mersenne(a,Num,time)
elif (mode == 4):
PYTHON(a,Num,time)
elif (mode == 0):
break
else :
print("请重新输入!")
continue
end = tm.perf_counter()
b = []
for i in range(0,Num,2):
b.append([a[i],a[i+1]])
scatter_test()
c = []
count = []
sum = 0
fc = 0
print("当前生成随机数序列:")
for i in a:
sum += i
print(hex(i),end=" ")
if i not in c:
c.append(i)
count.append(1)
else:
count[c.index(i)]+=1
ave = sum/Num
countAve = Num/len(c)
for j in count:
fc+=(j-countAve)**2
c.sort()
count.sort()
print('\n{:^10}'.format(str("n"))+'{:^10}'.format(str("randomNum"))+'{:^10}'.format(str("Time")))
for i in range(len(c)):
print('{:^10}'.format(str(i+1))+'{:^10}'.format(str(c[i]))+'{:^10}'.format(str(count[i])))
print("在"+str(startNum)+"~"+str(endNum)+"内生成"+str(Num)+"个随机数")
print("标准生成随机数类数:"+str(min(Num,numRange))+" 生成随机数类数:"+str(len(c)))
print("标准平均数:"+str((startNum+endNum)/2)+" 实际平均数:"+str(ave))
print("标准中位数:"+str((startNum+endNum)/2)+" 实际中位数:"+str(c[len(c)//2]))
print("随机出现次数方差:"+str(fc/len(c)))
print("运行时间为:"+str(end-start)+"s")
q = input("输入任意字符开启下一次循环")
print("程序结束")
第10章素数
非常重要的公钥的密码都是基于素数设计的
10.1整除性与素数
- 素数:一个数只有1和它自身两个正因子
- 合数:一个整数大于1且不为素数
引理 1 如果a|b且b|c,那么a|c。
引理 2 如果n为大于1的正整数且d为n除1之外最小的因子,那么d是素数。
-
欧几里得定理:素数有无穷多个
证明:假设素数的个数是有限的,那么一个包含所有素数的列表也是有限的,记为p1,p2,p3,⋯p,这里k表示素数的个数。定义n∶=p1p2p3⋯pk+1,即 n为所有素数的乘积加上1。
考虑n除1之外的最小因子,我们仍用d来表示这个因子。由引理2可知,d为素数且d|n;但是在那个有限的素数列表中,没有一个素数是n的因子,因为它们都是n-1的因子,n除以列表中任何一个素数p,都会有余数1,所以d为素数且不在列表中。而列表在定义时就包含了所有的素数,这样就出现了矛盾,所以素数的个数是有限的这个假设是错误的,从而可知素数有无穷多个。□ -
算数基本定理:任何一个大于1的整数都可以唯一表示为有限个素数的乘积
10.2产生小素数

- 算法思想:每一个合数c都有至少一个比c小的素因子,将比n小的数的倍数定为合数后,其余均为素数
- 值得注意的是循环和取值的范围
- 目的:利用小素数来获取大素数
10.3素数的模运算
- 方法:用p除r,去掉商,将所得的余数作为结果。so模p运算的结果在0,…,p-1中
- 基本规则:把模运算当作普通的整数运算,但是每一次的结果r都要对p进行取模运算
- 计算(amod p),就要先找到满足a=q+r且0≤r<p的整数q和r,那么 a mod p 的值就定义为 r
10.3.1加法和减法
- 加法相当于a+b(-p)
- 减法相当于a-b(+p)
- 可以在运算过程中的任何时候进行模运算
10.3.2乘法
- ab的最大可能值为(p-1)2=p-2p+1,所以就需要执行一次长除法来找到满足 ab=qp+r且0≤r<p的(q,r),去掉q,r就是结果
- 可以在运算过程中的任何时候进行模运算,迭代&直接取模都可
10.3.3群和有限域
- 有限域:模素数p的集合
- 有限域性质:
- 对运算中的每个数,可以加上或减去p的任何倍数而不改变运算的结果。
- 所有运算的结果都在0,1,⋯,p-1范围内。
- 可以在整数范围内做整个计算,只在最后一步做模运算。于是所有关于整数的代数规则(比如 a(b+c)= ab + ac)仍然适用。
- 群:在元素中定义了一种运算的集合,一个群由集合和运算构成
- 群性质:
- 群中任意两个元素进行运算的结果也是群中的元素
- 乘法运算中不能乘0:乘0无意义&0不能作除数
- 一个有限域包含加法群和乘法群
- 群可以包含子群,子群元素中运算结果仍在子群元素中
10.3.4 GCD算法
-
模p除法:乘法的逆运算,满足c · b=a(mod p)的数c即为a/b(mod p),且b≠0。
-
最大公因子GCD : gcd(a,b)是能够同时整除a和b的最大的数。
-
欧几里得算法思想:由于b mod a == b - s * a,so任何同时整除a和b的整数k也能够同时整除a和(b mod a),在a==0时,b即为a于b的公因子。

- 最大公因数GCD与最小公倍数LCM的关系:GCD(a,b)*LCM(a,b)=ab
10.3.5扩展欧几里得算法
- 目的:做模p除法
- 算法思想:找到满足gcd(a,b)=ua+vb的两个整数u和v

- 如何计算模p除法:能够在a/b(mod p)的计算中先算出gcd(b,p)=ub+vp,以得到u=gcd(b,p)/b(mod p)。而由于p为素数,所以gcd(b,p)=1,即得u=1/b(mod p)。所以au=a/b(mod p)
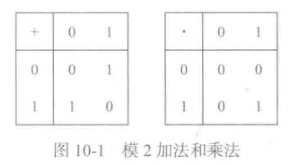
10.3.6模2运算
-
mod p的有趣特例,加法为异或XOR,乘法为AND运算,由于逆唯一(只可能为1),乘法和除法相同
10.4大素数
-
获取大素数方法:选择一个随机数并检查它是否为素数
原理:素数数量多,在在整数n的附近,大约每0.7 ln n个数中有一个数为素数,不断找必能找到


10.4.1素性测试
- Rabin-Mille目的:目的是检测一个奇数n是否为素数
- 方法:我们选择一个不超过n的随机值a,称为基,并检验a模n的某个性质,通过对不同的随机值
a重复进行这个测试,可以得到一个可信的最终结论 - 基本思想Fermat小定理:对任何素数n和所有1 ≤a<n,等式an-1mod n = 1始终成立。几乎对所有的基a都能通过Fermat 测试。

10.4.2计算模指数
-
对中间数使用mod n防止数据过大
-
二进制算法递归规则:
■如果s =0,那么结果为1。
■如果s>0并且s为偶数,那么先使用这些规则计算y=d"modn,结果为dmodn=
178]y" mod n。
■如果s>0并且s为奇数,那么先使用这些规则计算y=d-1modn。结果为amod
n = a·y mod n。 -
asmod n需要多少次乘法呢?设s有k位,即2k-1≤s<2k,至多需要进行 2k 次模n乘法.对一个2000位的数进行素性测试,则s大约也是 2000位,只需要4000次乘法,在大多数桌面计算机的计算能力之内。
-
使用Montgomery乘法等可减少计算as时间
-
直接实现模指数易遭受时间攻击,参见 15.3
10.5习题
10.2 用以下两种方法分别计算13635+16060+8190+21363(mod 29101)并比较结果是否相同∶每完成一次加法就对结果取模 29101; 先计算最终的和再对结果取模 29101。
答:结果都为1046
10.3 用以下两种方法分别计算12358·1854·14303(mod 29101)并比较结果是否相同∶每完成一次乘法就对结果取模 29101; 先计算最终的积再对结果取模 29101。
答:结果都为25392
10.4 {1,3,4} 是模 7乘法群的一个子群吗?
答:不是,如3*4=12=5(mod 7),运算结果不在子群中
10.5 使用 GCD 算法来计算 91261和117035 的GCD。
答:GCD(117035,91261)=GCD(91261,25774)=GCD(25774,13939)=GCD(13939,11835)=GCD(11835,2104)=GCD(2104,1315)=GCD(1315,789)=GCD()=GCD(789,526)=GCD(526,263)=263
第11章 Diffie- Hellman协议
公钥密码学始于 Whitfield Diffie和 Martin Hellman于1976年发表的"New Diretions in Cryptography"
- 密钥管理的困难:对于N个互相通信的用户,一共需要 N(N-1)/2个密钥。数量上的快速增长使得密钥难以管理
- Diffie和Hellman设想出公开加密,隐藏解密的方式,课解决分发密钥问题(公钥密码体制)
- DH密钥交换协议:能在不安全信道上协商得到相同密钥
11.1群
群中选择任何一个元素g,考虑序列1,g,g2,g3,⋯(模p)的无限序列,由于Zp中只有有限个,所以该序列必定会开始重复。假定从gi =gj处开始重复,其中i<j,可得1=gj-i。
- 阶:存在一个数q=j-i使得gq=1(mod p),q为g的阶。
- 生成元:此时g为此序列的生成原,此时明显q为gn(mod p)的个数
- 本原元:至少有一个元素g能够生成整个群,即可将群看作1,g1 ,g3 ,...,gp-2
- 任意g的阶都是p-1的因子
11.2基本的DH
-
可公开&基本元素:大素数p和群Zp的本原g
-
交换过程:
- Alice选择Zp中的一个随机数x,这就相当于在1,⋯,p-1中选择一个随机数,接着计算gx modp并把结果发送给 Bob
- Bob在Zp也选择一个随机数y,计算gymodp并把结果发送给Alice
- 最终的结果k定义为gxy,双方都可计算得到k

-
安全性基于离散对数问题:攻击者无法通过信道中的gx 和gy 计算得到k,最好的方式是通过gx计算出x,但相当困难
11.3中间人攻击
-
中间人可以面向A,B分别伪装成B,A
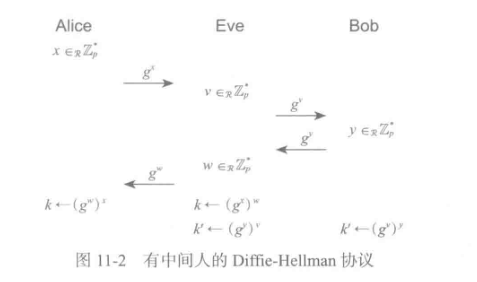
-
基础设施解决方法:使用数字电话本:使用电话本验证身份-->PKI类
-
非基础设施型:一定方法验证如电话语音,视频通话
11.4一些可能的问题
- 攻击者拦截通信并替换gx,使得到的k=1,密钥貌似完成却无效
- g非Zp本原元,子群较小容易被攻击
- 结合以上两种方式,攻击者可以拦截通信并替换gx为阶较小的h完成攻击,a和b会生成较小的子群
11.5安全的素数
-
安全素数p:形如2q+1的素数,其中q也为素数
-
安全素数生成群Zp有:
■ 只包含1的平凡子群。
■包含2 个元素的子群,即1和p-1。
■包含q 个元素的子群。
■包含 2q 个元素的整个群。 -
选取包含q个元素的子群,不用担心有更深子群的问题
-
前两个子群数量过少不安全,包含2q的子群有如下问题:
2q个数中有一半都是平方数,有一半是非平方数,攻击者可通过Legendre判断gx是否为平方数以推断x的最低位
-
A,B应检查受到的gn 是否为g生成子群中的元素:Legendre符号或r≠1且rq mod p = 1
11.6使用较小的子群
原因:安全素数方法效率不高:p有n位时,q有n-1位,求幂则约需要3n/2此乘法运算
- 选择一个256位的素数q(即2255<q<2256),然后找一个更大的素数p满足p=Nq+1,其中N为任意值。要找到这样的p,可以先在适当的范围内随机选择一个N,计算p=Nq+1,并检查p是否为素数。由于p一定是奇数,容易发现 N必为偶数。素数p可以有几千位长
- 然后需要找到一个阶为q的元素。我们使用类似于安全素数情况中的方法,在Zp中选择一个随机数a,令g= α,验证g≠1并且g=1(由于q是奇数,第二个测试条件涵盖了g=p-1)。如果g不满足这些条件,就选择另一个α并再次尝试。
- new检查1<r<p且rq=1,由于rq=1,所以只需计算re(mod_p) ,p 为至少2000位时能够节省7/8的工作俩
11.7p的长度
- 如要保证128位安全性,需要6800位的p,性能难以接受,更何况公钥本身就很慢
- 我们要仔细研究公钥操作的性能:公钥暂时用于加密对称密码的密钥,而对称密钥有更新周期,所以公钥的保护性可以没这么好,至少保证未来20年即可(对称密钥需50年)
11.8实践准则
- 选择256位的素数p,以应对碰撞攻击时有128位安全性
- 接受子群描述(p,q,g)时应验证:
- p和q 都是素数,q有256 位,并且p足够大(不要信任太小的密钥)
- q是(p-1)的因子
- g≠1且gq=1
- 接收应属于子群元素的r时应验证1<r<p且rq=1

11.9可能出错的地方
- 起因:IKE协议应用了DH协议,但没规定如何处理重发的消息
- 攻击方式:攻击者将Y替换成阶乘为d的元素(d是p-1的小因子),这样可以尝试(x mod d)的可能性以猜测Alice生成的k
- 解决方案:检查接收的每一个值都在正确的子群中
11.10习题
11.1 假设有200个人想要使用对称密钥来进行安全通信,每两个人之间都要有一个对称密钥,那么一共需要多少个对称密钥?
答:对N个通信人需要 N(N-1)/2,即需要200*199/2=19900个
11.2 计算在模p=11乘法群中分别由 3、7、10 生成的子群。
答:
由3生成的子群:1,3,4,5,9
由7生成的子群:2,3,4,5,6,7,9,10
由10生成的子群:1,10
11.4 如果在Alie和Bob两人所有的通信中,Alie使用相同的x和g,Bob使用了相同的y和g,会不会产生什么问题?
答:会产生问题.如果密钥长期不更换,攻击者会在碰撞得到x后破译过去的所有信息且继续监听破译
11.5 Alice和Bob打算利用DH协议来协商一个256 位的AES密钥,不过他们现在不知道该使用多大的公钥gx和gy,256 位、512 位还是其他值?你有什么建议
第11章问题
为何当且仅当rg=1(modp)时,r为模p平方数?
第12章RSA
- 基于大整数分解问题
- 应用于数字签名和公钥加密
12.1引言
- DH单向函数:假设p和q是公开已知的,那么可以由x计算(gx mod p),但是给定gxmodp却不能计算出x。
- RSA陷门单项函数:给定公开已知的信息n和e,容易由m计算memodn,但相反的方向却不行。不过如果知道n的因子分解,那么反向计算就变得容易了。(陷门信息:n的因式分解)
12.2中国剩余定理
已知x mod p,xmod q,那么就能够求出x,表示为已知(a,b)可求x
-
可行性证明:有唯一的x满足(a,b)
假设有x'也满足(a,b).则有d=x-x',所以d mod p = (x-x')mod p=(x mod p)-(x'mod p) = 0,可得d为p倍数,同理d为q倍数.由于1<x,x'<n-1,所以0≤d<n-2.由于p,q为不等素数,所以d为pq=n的倍数.所以d只可能为0,x唯一
12.2.1 Garner公式
((a-b)(q-1 mod p))mod p)· q +b
-
证明

-
可明显简化计算,解决CRT问题
12.2.2推广
- CRT也可为n为不同素数乘积的情形
12.2.3应用
- 做大量模运算时可大量节约时间
- 模运算:x+y的CRT表示就是((x+y)modp,(x+y)mod q),两部分可通过(x mod p)+(y mod p)modp方式解决
- 乘法运算:xy的 CRT表示是(xy mod p,xy mod q),两部分可通过(x mod p)*(y mod p)mod p方式解决
- 指数运算:。假设要计算xsmod n,指数s有k位,大约就需要 3k/2次模n乘法。另外,在我们计算(xsmodp,xsmodq)时,对于模p运算,可以把指数s模(p-1)约化,对于模q运算也类似,所以只需要计算(xsmod(p-1)mod p,xsmod(q-1)mod q)。
12.2.4结论
n=pq时,x模n可以表示为(xmodp,xmodq)对,而且这两种表示之间的转换相当简单。如果要做很多次模一个合数的乘法,而且已知该合数的因子分解,那么就可以使用CRT 表示来加快计算(如果不知道n的因子分解,就不能用它来加快计算)。
12.3模n乘法
对任何素数p,xp-1=1(mod p)对0<x<p成立,但对合数n不成立.我们需要找到指数t使得xt=1 mod n对计划所有的x成立
- 存在xt=1(mod p)和xt=1(mod q),所以p-1|t且q-1|t,所以可约定t=lcm(p-1,q-1)
- 一半来说可直接使用φ(n)=(p-1)(q-1)作为t,但lcm(p-1,q-1)更准确
12.4 RSA
- 首先随机选择两个不同的大素数p和q,计算n=pq。
- 使用两个不同的指数,通常称为e和d并且满足ed=1(mod t),其中t= lcm(p-1,q-1),部分教科书中写作ed=1(mod φ(n))。公开的指数e应该选取为某一小奇数值,并用extendedGCD函数来计算e模t的逆d,以确保ed=1(mod t)。
- 加密消息m,发送者计算密文ε=me(modn)。为了解密密文c,接收者计算e(mod n)。
这就等于(m)=m~=m"'=(m)·m=(1)·m=m(mod n),其中k是某个存在的值,所以
接收者能够解密密文 m"而得到明文 m。
(n,e)对构成了公钥,这些公钥被分发给很多不同的参与方。(p.q,t.d)构成了私钥,
由生成 RSA 密钥的人秘密保存。
12.4.1RSA数字签名
- 为了签署一个消息m,私钥的拥有者计算s=m1/emod n。现在(m,s)就是一个经过签名的消息,要验证签名,任何知道公钥的人都可以验证 se= m(mod n)是否成立。
- 只有掌握了私钥,才可以计算m的e次方根
12.4.2公开指数
攻击者可能通过说服私钥的拥有者签署消息c来解密
- 解决方法:对同一个n使用两个不同的公开指数,以消除了系统之间的相互影响,简化系统
- 可选取较小的公开指数用于签名
12.4.3私钥
- 攻击者只知道公钥(n,e),那么计算私钥(p,q,t,d)中的任何一个值都是极其困难的。只要n足够大,就没有算法能够在可以接受的时间内做到这一点。
- 解决方案:把n分解为p和q,然后再计算t 和d。
- 由于知道d等价于知道p和g,那么可以安全地假设她知道n的因子,从而可以使用CRT表示来进行计算。
12.4.4n的长度
- n应该与DH中的模p具有相同的长度
- 保护数据20年,n的绝对最小长度是2048位
- 两个素数p和q应该具有相同的长度,要得到一个k位的模n,可以生成两个随机的k/2 位的素数并把它们相乘
12.4.5生成RSA密钥
- 10.4中generateLargePrime的修改版,区别是p满足p mod 3≠1和p mod5 ≠1
- 仅指定长度无需指定范围区间

- 能够生成所有密钥参数

12.5使用RSA的缺陷
- 攻击者可通过Sign(m1)和Sign(m2)相乘得到Sign(m3)
- 加密短消息(密钥)不会模约化运算,消息会被还原
- 解决方案:使用编码函数消除原有结构(类填充),如PKCS#1 v2.1包括了两个RSA加密方案和两个RSA签名方案,并可以使用不同的散列函数
12.6加密
由于加密消息受限于n长度,所以我们不几乎不适应RSA直接加密信息
-
通用解决方案:选择一个随机的密钥K,利用RSA密钥加密K。然后使用密钥K通过分组密码或者流密码来加密实际的消息m
-
easier解决方案:选择随机数r∈Zp,作哈希K=h(r)为密钥,优点如下
- r是随机选择的,所以不可以利用r的结构来攻击加密方案中RSA这部分
- 其次散列函数保证了不同结构的r不会得到相同结构的K(除了相同输入必须产生相同的输出这一明显的必要条件)。
-
发送者对密钥进行加密

-
接收者计算K=h(c1/emod n),得到同一个密钥K。

-
安全性分析:攻击者最多只知道K,而不可能随机映射出散列函数的输入r
12.7签名
由于信息m可能有多种结构,需要统一格式
- 先对消息进行散列运算,生成k为伪随机映射随机数s

-
签名

-
验签

- 只要散列函数是安全的,就只能通过试错法来获取成(m)的值。
- 随机数生成器也是随机映射,任何人都可以产生形如(s,s1/e)的数对,其中s的值是随机的,并不会提供任何新的信息来帮助攻击者伪造签名。
- 对任何特定的消息m,只有知道私钥的人才能够计算相应的(s,s1/e)对,这是因为s必须h(m)计算出来,然后s1/e必须由s计算得到。so任何验证签名的人都知道 Alice一定给该消息进行过签名
12.8习题
12.1 设p=89,q=107,n=p,a=3,b=5,在Z上找到满足a=x(mod p)且b=x(mod g)的x。
12.2 设p=89,q=107,n=p,x=1796,y=8931,计算x+y(mod n)。要求先直接计算,再使用CRT表示计算。
12.3 设p=89.q=107,n=p,x=1796,y=8931,计算x(mod n)。要求先直接计算,再使用CRT表示计算。
12.4 设p=89,4=101,n-pg.e=3,那么(n,e)是一个有效的RSA公钥吗?如果是,就计算相应的 RSA 私钥d;如果不是,请说明理由。
12.5 设p=79,q=89.n=pq,e=3.那么(n,e)是一个有效的RSA公钥吗?如果是,就计算相应的 RSA 私钥d; 如果不是,请说明理由。
12.6 为了提高解密的速度。Alice令私钥d=3.再计算d模1的逆来作为e.这种设计决策好吗?
12.7 一个256位的 RSA 密钥(模数为256 位的密钥)和一个256位的AES密钥提供了相似的安全强度吗?
12.8 设p=71,q=89,n=pg,e=3。首先计算d.接着利用RSA 基本操作计算消息m-5416、mz= 2397、ms=m;m2(mod n)的签名,并验证m;的签名等于m和m,的签名的乘积。
第13章密码协议导论
密码协议是由协议的各个参与者之间进行一系列的消息交换组成的。
主要的挑战:协议的设计者或者实现者并不能控制协议的过程。
13.1角色
- 一般交互双方定为Alice和Bob,攻击者为Eve
- 单个实体可充当协议中的任意一方角色
13.2信任
信任是我们与他人进行所有往来(建立连接)的基础
- 信任来源:使得某一方不去进行欺骗行为的动机,而其他方知道这个动机存在,从而觉得可以在一定程度上相信与他交互的另外一方
- 伦理道德
- 名誉
- 法律
- 人身威胁
- 共同毁灭原则
- 网络上建立信任,来源:伦理道德
- 网络上建立商务信任:名誉&伦理道德
- 信任选项:有多么信任?
- 风险是信任的对立,在协议上我们讨论信任,商业上讨论风险
13.3动机
不同参与者的目标是什么?他们希望达到什么目的?
- 研究者会估计赞助的收益动向,而存在压力
- 评估者会考虑报告是否"好看",让客户满意,而存在压力
- 期权持有者会尝试赌博赚快钱,而存在压力
- 离婚律师会为赚钱而催发离婚
- 诉讼使出错者能够隐瞒、否认或者逃脱责罚。法律责任和伤害赔偿极大阻碍人们归因避错
- 密码协议:
- 密码协议依赖于动机机制。协议无法组织欺骗但可留存证据
- 密码协议改变了动机机制。协议使得一些事情不再可能发生,从而从需要考虑的动机机制里面消失了。
13.4密码协议中的信任
密码协议的作用是最小化所需的信任的量。
- 最小化:最小化彼此信任人数&信任程度
- 默认模型--偏执狂模型:假设其他参与者合谋欺骗用户
- 在模型上所作的信任修改需要被记录列出,对应需要解决的风险
13.5消息和步骤
典型的协议描述包括在协议参与者之间发送的消息数量以及每个参与者需要做的计算。
- 高层的(抽象的)协议描述能提高效率但也会产生危险:没有详尽的行为规范说明
- 解决方法:模块化,只有在最顶层的协议文档是高度差异化的
13.5.1传输层
密码学含义:让人们能够互相通信的底层通信系统
-
应能传输可变长度并不修改字符串
-
一些协议中的类魔数能提前检测同步是否正确
-
传输层可能在已加密信道上运行密码协议,此时还提供了消息保密性、认证、重放保护
13.5.2协议标识符和消息标识符
当你收到一条消息时。你会想知道这个消息属于哪个协议,以及这个协议都包含哪些消息
- 协议标识符:
- 版本信息:为未来升级提供空间
- 协议(号):属于哪个密码协议
- 消息标识符:对应协议哪部分
- 引入目的:区分主动攻击和配置、版本问题导致的意外错误
- 霍顿原则:当我们在一个协议中使用认证(或者数字签名)时,我们一般是针对数条消息和数据字段进行认证
13.5.3消息编码和解析
一条消息中每一个数据元素都需要被转化成一个字节序列。
-
接收者必须要能够解析看起来像一个字节序列的消息,将这个序列解析成其组成字段。这个解析不能被上下文信息影响
-
认证函数认证了一个字节串,并且通常在传输层对消息进行认证是最简单的。
-
可选编码:
-
TLV(Tag-Length-Value)编码
每个字段被编码成了标签(tag)、长度(length)和值(Value)三个数据元素,标签用来识别字段,长度表示这个字段的值经过编码之后的长度,值则是被编码的实际数据内容
-
XML编码
只要使用一个固定的文档类型定义(Document Type Definition,DTD)时,这个解析就不依赖于上下文
-
13.5.4协议执行状态
单个计算机有可能同时参加到几个协议执行中
- 协议状态包含了一个状态机,用于说明下一个消息的预期类型
13.5.5错误
协议通常包含了多种检查,这些检查包括验证协议类型和消息类型,检查这个消息是否是协议执行状态期待的类型,解析消息是否正确,以及执行协议指定的认证。如果里面任意一个检查失败了,我们就碰到了错误。
-
最安全处理:不给错误发送任何回复,并且马上删除协议状态
问题:导致一个不友好的系统,因为这个系统没有任何错误提示
解决方法:只在系统安全日志上添加错误信息
-
新问题:错误可能和时间攻击(timing attack)联系起来
例:智能卡按PIN码位数次序检测PIN码是否正确,提供了时间信息供攻击者"避错"
13.5.6重放和重试
-
重放攻击:是攻击者录下来一段消息,然后将这段消息重新发送出去。
-
重试攻击:攻击者发送重放和重试信息
-
使用时要确定收到信息和应受到信息的时间关系
-
三种旧消息情况:
-
你收到的消息和之前你已经响应过的消息有一样的消息标识符,并且内容也相同。
反应:回复与之前回复消息完全相同的内容
-
当你收到一个和你最后响应过的消息有相同消息标识符,但是消息的内容不一样。
反应:两条信息有一条是伪造的,应视为协议错误
-
你收到一条甚至比你之前回复过的消息更"老"的消息。
反应:忽略消息
-
13.6习题
13.1 描述一个你会定期参与其中的协议。这可能是在当地的咖啡店点一杯饮料,或者飞机着陆。谁是这个协议明显的直接参与者?有哪些参与者是外围地参与了这个协议。例如在协议的设置阶
段?为了简单起见,列举最多五个参与者。
设置一个矩阵,每一行和每一列都标注一个参与者。然后在每个单元格中描述这个行对应
的参与者是如何信任这个列对应的参与者的?
答:
13.2 考虑你的个人计算机的安全性如何。列举所有可能闯人你计算机的攻击者。他们的动机。以及对于攻击者来说相关的代价和风险。
答:
雷桑:清空他的裸照 风险:更新裸照,丧失信誉
开开:想嫖我的报告 风险:错误报告,法律制裁
涛狗:想用我的账号 风险:注销账号,共同毁灭
辰哥:想试试能不能把我电脑打开 风险:无
13.3 和习题 13.2 一样。但是把个人计算机换成银行。
答:
柜员:故意少拿钱 风险:离柜不负责
柜员:故意多拿钱 风险:转嫁给客户
客户:故意少拿钱 风险:真的少拿钱
客户:故意多拿钱 风险:吃花生米
窃贼:晚上拿钱走人 风险:被抓坐牢
抢匪:白天拿钱走人 风险:吃花生米
第14章密钥协商
从0设计协议,注意变化和挑战(威胁)
14.1初始设置
Alice和Bob通过密钥协商协议设置会话密钥k
密钥协商需要提供可识别性,可用RSA签名或密钥+MAC的形式
讨论:为何有共享密钥后还需设置会话密钥k?
- 将短期会话密钥和长期共享密钥分离开,增加系统健壮性
- 会话密钥泄露,共享密钥安全
- 共享密钥泄露,过去会话信息安全
- 共享密钥安全性弱:用户喜欢简单口令
14.2初次尝试
Alice和Bob通过最初的两个消息来执行 DH协议。Alice随后对会话密钥k计算认证并发送给 Bob,Bob检查了认证信息。同样的,Bob 也发送了关于k的认证信息并发送给 Alice。
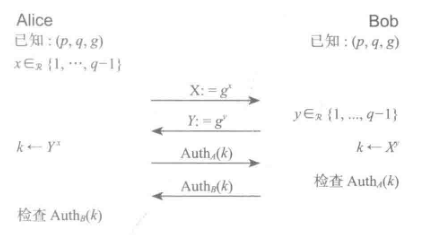
当前存在问题:
- DH协议中(p,q,g)均为常数
- 三条信息即可
- 会话密钥k被作为认证信息的输入可能会泄露k
- 认证信息太相似,对类MAC认证,Bob可直接返还Alice的认证信息
- 在认证信息交换前要注意不能用k
14.3协议会一直存在下去
版本回滚攻击:协议的版本转换带来的安全性变化会让攻击者强迫用户进行版本转换
解决方法:多版本协议,单成本较高
so:成功的协议会一直存在下去
14.4一个认证的惯例
每次某一方发送一个认证,这个认证数据里包括了所有之前已经交换过的数据:所有之前的消息和所有已经认证的消息中包括的数据字段,如身份识别符。
例:Alice的认证器不会在k上,而是会在 Alice 的识别符、Bob的识别符。X和Y上。Bob的认证器则会覆盖 Alice的认证器、Bob的识别符、X和Y,以及Auth
好处:代价小,可能攻击的空间更小.高效的散列函数进一步降低了代价
注意:认证函数只会认证一个字符串,so字节串应从一个独特的识别符开始,该识别符能够识别协议中这个认证器被使用的具体位置;编码方式应能完整恢复
14.5第二次尝试
思想:Alice选择DH参数、DH分布(Alice结果)与认证集合并发送给 Bob,Bob需要检验是否合适然后发送自己的分布和认证
具体过程:Alice首先选择了DH参数和她的 DH分布,经过认证发送给 Bob。Bob必须检查这些 DH参数是否合适,以及X是否有效。协议剩下的内容和之前的版本相似,Alice 收到Y和Auth,进行检查,然后计算 DH的结果。
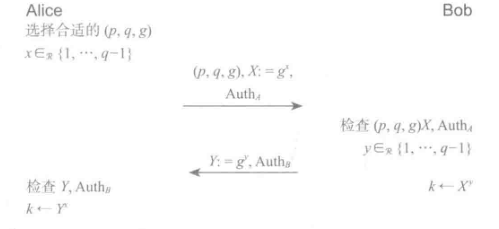
新问题:
- Bob反对该DH参数(质疑安全性低),增加协议复杂度
- Alice消息可重放(DH参数可随便选),身份不可认证
老方法:增加随机数进行认证抗重放
14.6第三次尝试
思想:与其让 Alice选择 DH协议的参数,不如让她简单地发送她的最低要求给 Bob,然后让Bob来选择这些参数
具体过程:Alice首先选择一个s,这是她想要选择的素数p的最小长度。她同样选择了一个随机的256 位字符串作为随机数N。并将两个参数发送给 Bob。Bob 选择一个合适的 DH参数集合和他的随机指数,然后将这些参数、他的DH分布和他的认证器发送给 Alice。Alice 和之前一样利用添加的认证器来完成DH协议。
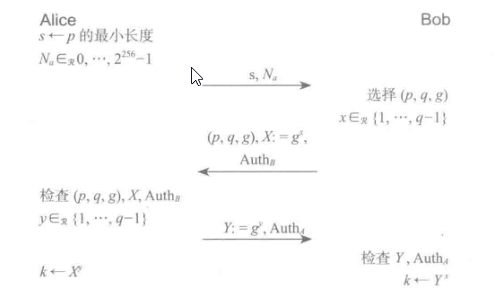
新问题:k是可变长度的数,这种代数结构容易被攻破
解决方法:对k进行散列计算使其定长
14.7最终的协议
Alice和Bob应分别限制p大小,但也不可以定长
具体过程

14.8关于协议的一些不同观点
14.8.1Alice的观点
抗重放:含Alice的随机数
检验DH参数: Alice保留y,发送Y时,她 Alice保留y,发送Y时,她清楚知道只有使得g-X成立的x的人能够计算出最后的结果,密钥k。
14.8.2Bob的观点
第一条信息只包含选定值sa和随机位Na
第二条信息是Alice已认定的信息
他清楚只有知道满足g=Y的y值的人能够计算出最终的密钥k。
14.8.3攻击者的观点
因为认证性而无法改变数据
因为随机数X而无法重放攻击
增大Sa可实现但无法算作攻击
其他方法容易暴露攻击者信息
14.8.4密钥泄露
协议总是能够针对密钥泄露的情况提供可能的最好的保护措施
丢失认证密钥:不能运行协议,可用会话密钥
丢失会话密钥:需要再运行密钥协商协议
泄露认证密钥:攻击者可伪装成用户,但无法找到从前的会话密钥
泄露会话密钥:攻击者没有获得其他信息
14.9协议的计算复杂性
无须计算:DH参数的选择和验证:已事先缓存
必须计算:
- DH协议子集里的三个指数运算。
- 生成一个认证器。
- 对一个认证器的验证。
- 若干个相对有效的操作,例如随机数生成、比较、散列函数等。
主要运行时间由DH参数中的指数决定
在模数比较大的时候,RSA签名比 DH计算慢一些。在模数比较小的时候RSA签名又相对快一些。这个平衡点(break-even point)在3000 位左右。这是因为 DH通常使用256 位的指数,而对于RSA来说这个指数取决于模数的长度。
优化技巧
使用加法链启发式算法或加法序列启发式算法减少乘法计算
14.10协议复杂性
该例甚至仍不完善!
完整密码协议需要大量描述但难以完全掌握
问题:缺少协议模块化技术
14.11一个小警告
永远用批判性、怀疑性、偏执性眼光看待协议!!
14.12基于口令的密钥协商
很多情况下没有认证系统可用,而只有一个口令
用MAC函数的问题:给定这个协议的一段上下文(通过窃听双方的通信得到)可测试任何一段口令。
理想状态:一个窃听者也无法进行线下字典攻击的密钥协商协议,如SRP协议
14.13习题
14.1 在14.5 节中,我们说明了协议的性质可能会为系统管理员提供错误信息的情况。请给出一个详细的场景说明这可能是个问题。
答:比如攻击者通过重放攻击的方式给Bob发送了消息,而Bob的日志上却显示和Alice建立了认证,与实际情况不符
14.2 假设Alice和Bob实现了14.7节中的最终协议,请问一个攻击者是否可能针对协议性质对 Alice进行拒绝服务攻击?对 Bob 呢?
答:对Alice可能进行拒绝服务攻击,因为Alice得检验多个数据是否符合要求的条件,对Bob的拒绝服务攻击效益不大
第15章实现上的问题II
15.1大整数的运算
恰当地实现大整数运算并不是件容易的事
平台相关:CPU所擅长的运算和高级语言中能使用的运算相悖
如何测试?
多数分组密码和散列函数相对容易测试:代码路径不取决于所提供的数据,或者数据对路径只有很小的影响。
大整数运算相对难以测试:在多数实现过程中,代码路径是取决于数据的。
So,我们必须小心测试大整数运算例程
A 灾难性样例

应当做什么?
- 不要自己去实现大整数运算例程。去使用一个已有的库。如果你想在这个上面花时间,就去理解和测试已有的库。
- 用很好的测试用例去测试你。确保你测试了每一个可能的代码路径。
- 在应用里面加入额外的测试。有几种技术可以达到这个目的。
15.1.1woop技术
基本思想:为了验证对随机选择的小素数的取模计算
用例:为了验证一个库的错误性,不能复用这个库来以可能的错误来验证错误,而要用woop技术尝试库是否会修改验证计算的结果
准备工作
- 使用伪随机数生成器生成随机素数t,长度在64~128位间
- 对计算中的所有大整数算出x':=(x mod t)
这样我们就可以通过woop值的运算来验证原大整数的运算了
普通加/乘法
c:=a+b,我们可以计算c'=a'+b'(mod t)验证。
c:=a·b,我们可以计算c'=a'·b'(mod t)验证。
模加法
原先计算c只需要c=(a+b)mod n,现在是c=a+b+k·n,k的选择需要满足让得到的结果c在0.⋯,n-1的范围内。这只是另外一种表示模归约的方法。在这种情况下,k可能是0或者-1,假设a和b都在范围0.⋯,n-1 内。
计算 woop的公式是c'=(a'+b'+k'·n')mod t。
在这个模加法程序的内部某处,k的值是已知的。我们需要做的是说服这个库给我们提供k,从而能够计算k。
模乘法
原先计算c只需要c=(a·b)mod n,现在是c'=a'·b'+k'·n'(mod t)
a',b',n'可计算,但k'需要算,通用方法是:先计算a·b再用长除法除以n可得k,得到余数是c,但速度非常慢
15.1.2检查DH计算
如果可能,请使用内置woop系统的库
DH协议的检查不是由计算的一方来做的,而是由接收计算结果的一方进行
由于结果错误,似乎不会有危害,但可能会泄露信息
15.1.3检查RSA加密
RSA加密更加脆弱,需要额外的检查。如果某一步出错了,可能会泄露你正在加密的秘密、或者你自己的密钥。
最好:使用woop验证。否则:
-
假设实际的RSA加密包括计算c=m5modn、其中m是消息,c是密文。为了验证这个结果,我们可以计算c1/5mod n并且和m进行比较。
缺点:验证过程很慢,并且需要知道私钥
-
选择一个随机值z,然后检查c·z5=(m·z)5modn。共计算了三次5次幂,分别是c=m5和z5(m·z)5。优点:通过选择一个随机值z。可以让任何攻击者都无法定位到导致错误的变量上。
15.1.4检查RSA签名
RSA签名相当容易检查。
签名者只需要运行签名验证算法即可。这是一个比较快的验证,如果有运算错误也很容易捕捉到。每个RSA签名计算都应当用这种方法去验证刚产生的签名,没有理由不去这么做。
15.1.5结论
以上这些检查是在大整数库的正常检查之外的额外检查,不能代替原本的正常检查
若有任意一个检查没有通过,软件不合格。
最好且唯一解是记录下这个错误,然后终止程序。
15.2更快的乘法
Montgomery方法
思想:重复地将x除以2(位运算)
15.3侧信道攻击
时间攻击在攻击公钥计算时也很有用
加密算法
要求实现时使用不同的代码路径去处理特殊情况
公钥密码
通常有一条取决于数据的代码路径
15.4协议
实现密码协议和实现通信协议区别不是那么大。
最简单方法:保持程序计数器的状态,然后简单地轮流实现协议的每一步。但会使程序其他部分等待执行完成
更好的方法:保持一个显式的协议状态,并且在每次一条消息到来时更新这个状态。"消息驱动"提供了更多灵活性
15.4.1安全信道上的协议
多数的密码协议都是在非安全信道上执行的,但是有时需要在安全信道上运行密码协议。
场景:每个用户都有一个和密钥分发中心(keydistribution center)通信的安全信道,中心使用一个简单的协议来分发密钥给用户,允许他们之间互相通信。(Kerberos协议所做的事情与此类似。)如果你在和你已经交换过密钥的某一方运行一个密码协议,你应该使用全部的安全信道功能。并且,你需要实现重放保护。这非常容易做到,可以阻止大量针对密码协议的攻击。
捷径:有时安全信道会允许协议使用捷径。例如说,如果安全信道提供了重放保护,协议本身就不需要再实现一次重放保护了。不过,老的模块化规则认为,协议应该最小化其对安全信道的依赖程度。
15.4.2接收一条消息
接收必检查
-
检查消息是否属于协议
这些信息至少需要交换一次以保证它们被包含在协议的所有认证或者签名中。
- 协议标识符∶用来识别这是哪个协议和哪个协议版本
- 协议实例标识符∶识别这条消息属于协议的哪个实例。
- 消息标识符:识别协议内部的消息。
-
检查协议状态
假设当前接收了n-1在等待n
-
若消息=n,正常执行
-
若消息>n或<n-1,可能为伪造信息应丢弃
-
若消息=n-1,进一步分析
消息内容同之前消息是否相同?
-
相同:回复消息未到达,重发即可
-
不相同:忽略或终止协议?
攻击者目的可能正是终止协议!
-
-
15.4.3超时设定
若超时,则放弃
最简单方法:发送计时消息给协议状态
针对不合适超时设定的攻击:SYN洪水攻击,最好删除旧协议
重发时间是可商讨的:根据实际情况决定
15.5习题
15.1 考虑一台计算机可能对一个密钥做的所有操作。其中哪些操作包含了时间特征,可能会泄露关于密钥的信息?
答:计算机可能会产生、分配、存储、组织、使用、销毁密钥。在产生、使用和销毁时包含时间特征(如密钥长度等引发的处理时间变化等),可能泄露关于密钥的信息
第四部分 密钥管理
第16章时钟
非密码学原语
16.1时钟的使用
密钥管理函数常常与截止时间(deadline)相关联,当前时间能够提供一个唯一值和事件发生的完整顺序。我们将详细讨论这些用法。
16.1.1有效期
在多数情况下,需要限制文件的有效期。
在现实生活中:支票、飞机票、代金券、优惠券、版权都有有限的有效期。限制数字文档有效期的标准方法是在文档内部包含有效期。
为了检查一个文档是否到期,需要知道当前时间,因此要用到时钟。
16.1.2唯一值
瞬时值的主要特点是任何一个值都不会被使用两次,至少在定义的范围内如此。
生成瞬时值的方法:
- 使用时钟的当前时间,但是需要一些机制能够保证你永远不会两次使用相同的时间信号(time code)。
- 使用伪随机数生成器。但是要的随机数相当大:256位随机瞬时值保证128位安全等级
16.1.3单调性
时间的一个有用的性质是它会一直不断向前走,从来不会停止或倒退
抗重放:在密码协议中包含时间信息可以防止攻击者把旧的消息当作有效消息放到当前协议中。
审计和日志:提供必需的数据来追踪确切的事件序列。
16.1.4实时交易
电子支付系统:
支持实时支付--实时交易系统
支持审计--清晰的交易序列
可能存在的时钟问题:
时间突然回到过去:可以很容易地发现错误
时间突然穿越未来:将无法在错误的最晚交易时间前进行交易
16.2使用实时时钟芯片
实时时钟芯片并不可靠
为啥不好使
- 可能受攻击的安全系统,要求时钟的抗干扰性更强
- 实时时钟芯片自己可能会发生故障
16.3安全性威胁
16.3.1时钟后置
假定攻击者能够把时钟设为过去的任何一个时间。这会导致各种可能的危害,机器会错误地相信自己生活在过去。
可能存在的威胁例子
- 攻击者过去曾有访问权限但已过期,时光倒流可能会回复
- 公司月底定时汇款,回拨时间可能导致动作重复进行
- 交易时回拨时间以避免太大的利息
16.3.2时钟停止
其他部分的设计者本能地认为时间不会静止
可能引发的问题
显示数据和实际数据不一致引发的混乱
聪明的改进方法
每个金融交易的报告用时间截标记,并且存放在本地的数据库中。
为了显示一致的报告,他采用一个特定的时间点,报告那个时间点对应的金融状况。以延迟换一致性。
16.3.3时钟前置
导致的问题
- 拒绝服务攻击:现有服务均已过期
- 不公平竞标:调整出价时间
- 增加不存在账单
- 提前公开秘密或提供权限
16.4建立可靠的时钟
依赖具体的工作环境和风险分析,难以给出通用的答案。
检查方法:
- 建立计时器与时钟芯片时间相对应
- 记录最后关机的时间,或是数据写入磁盘的最后时间
- 询问 Internet或intranet上的时间服务器。
16.5相同状态问题
讨论含小型CPU,小容量RAM,闪存的小型嵌入式计算机(门锁,智能卡读卡器...),很多没有实时时钟
为啥没有实时时钟?需要额外芯片,震荡晶体和电池,增加负载的且对环境敏感
那咋办?每次启动时都以同样的状态开始,它从同样的非易失存储器中读取同样的程序,初始化硬件,然后开始操作。
问题:状态完全可重复
解决方案:
- 一个实时时钟芯片,并使用固定密钥加密当前时间
- 硬件随机数生成器,能使计算机重启后有不同行为
- 若以上条件都不允许,可使用不同部件间时钟偏差值的累计熵,但时间过长
- 在闪存中放入重启计数器在熵中添加重启次数,但可能会崩溃
16.6时间
由于存在时区,时令等问题,不要使用本地时间
最好选择:使用国际时间标准UTC的时间
UTC存在的问题:跳秒,用来与地球旋转同步,每几年发生一次,会破坏时间值的唯一性和单调性
实际应用需求:单调性和唯一性远比完全同步重要
16.7结论
时钟的使用一定会带来一些潜在的安全问题,所以要尽可能地最小化对时钟的依赖
注意时间戳的唯一性和单调性
16.8习题
6.1 一些计算机在启动的时候,或者每过一段固定间隔使用NTP协议。关闭你的计算机中的NTP一周时间。编写一个程序,每隔一段时间(至少是两小时)就记录真实的时间和计算机报告的时间。设n是实验开始时的初始真实时间。对每次的测量数据。请绘制图表记录,其中横坐标是真实时间减去t,纵坐标是本机时间减去真实时间。一周之后你的计算机时钟和真实时间有多少差别? 你的图表有没有告诉你其他的信息?
16.2 同习题 16.1,但是这次对五台不同的计算机进行实验。
16.3 找到一个新的使用了(或者应该使用)时钟的产品或者系统。这可能和你在习题 1.8中所提到的是同一个产品或系统。请根据1.12 节的描述对该产品和系统进行安全审查。这次请围绕时钟所带来的安全问题和隐私问题进行讨论。
第17章 密钥服务器
仅仅从密码学角度讨论密钥管理
密钥服务器(key server):分发所有的密钥的一个可信实体
17.1基本概念
我们假定每个人都与密钥服务器建立一个共享密钥K,只有他和密钥服务器知道
一般情况:假定 Alice想与 Bob进行通信。
一般解决方案:她没有与Bob通信的密钥,但她可以与密钥服务器安全地通信。密钥服务器反过来也能与 Bob安全地通信。
存在的问题:对密钥服务器来说存在一些困难,因为它将不得不处理大量的通信。
更好的解决方案:让密钥服务器建立一个 Alice和Bob的共享密钥KAB。
17.2 Kerberos协议
以上即为Kerberos协议的基本思想,它建立在 Needham-Schroeder协议基础上
当Alice想与Bob对话时如何工作?
- Alice与密钥服务器联系
- 密钥服务器向 Alice发送一个新的密钥KAB以及使用 Bob的密钥KB对KAB加密后的值。这些消息都用KA加密,因此只有Alice能读。
- Alice解密之后,再用KB加密之后的消息,这条消息称为标签(ticket),发送给 Bob。
- Bob对它解密,然后得到KAB
会话密钥KAB:Alice 知 ,Bob 知,密钥服务器知
密钥服务器KDC特性:
- 不需要太经常地更新自己的状态。
- 记住与每个用户共享的密钥。
- 不记录用户间建立哪些共享密钥
17.3更简单的方案
允许密钥服务器来维护状态:当前计算机比以往强大得多
问题:,所有的密钥都放在一个地方,使得密钥服务器成为一个很有吸引力的攻击目标。
17.3.1安全连接
假定 Alice 和密钥服务器共享密钥K用于运行一个密钥协商协议时,密钥协商协议建立了密钥服务器和Alice之间的新密钥KA'。Alice 和密钥服务器用KA'来产生一个安全的通信信道.
安全信道能够提供保密性、可认证性、重放保护等特性,所有进一步的通信都发生在这个安全的信道上。
17.3.2建立密钥
我们只需考虑消息丢失、延迟,或者被攻击者删除的情况,因为安全信道已经防止了其他类型的操纵手法
过程
- Alice请求密钥服务器来建立她和Bob之间的密钥KA
- 密钥服务器把新密钥KAB发送给 Alice 和 Bob。
密钥服务器甚至可以通过Alice把消息传递给 Bob,Alice 就简单地等同于一个密钥管理器和 Bob 之间的安全信道的一个网络路由器。
限制: 在Alice请求密钥服务器建立同 Bob的共享密钥之前,Bob的密钥服务器必须运行密钥协商协议。
17.3.3重新生成密钥
KA'必须有一个有限的生命周期。
因为总能够重新生成密钥,密钥服务器不必以可靠的方式来存储安全信道的状态。
假定密钥服务器崩溃,失去了所有的状态信息,而只要它还记得KA即可重新运行密钥协商协议
虽然密钥服务器不是无状态的,但当运行协议时它不必修改自己的长期状态,也就是储存在非易失的介质上的部分。
17.3.4其他性质
易于监视:从理论角度更易于监视对协议的可能攻击渠道
前向安全性:所有过去的通信仍然是安全的。即使密钥KA泄露,安全信道密钥KA'不会泄露
17.4如何选择
尽可能使用Kerberos协议,或设计类似的密钥协商系统
17.5习题
17.1 在17.3节提到的协议中,密钥KA'的合理生命周期是多少?为什么?如果这个生命周期变长会出现什么后果?变短呢?
答:合理的生命周期是平均会话时间。因为这样能保证如果生命周期变长,那么若在会话结束后被窃取也会解密窃听消息,如果变短则要在会话中途重新建立安全信道
17.2 在17.3 节提到的协议中,攻击者如何能在KA'失效之前获取KA'?获得KA'后,攻击者能够做出哪些坏事? 有哪些坏事攻击者仍然不能做?
答:可以通过 可以实时监听该信道中的信息,仍不能监听到其他信道上的信息
17.3 在17.3 节提到的协议中,攻击者如何能在K失效之后获取KA'获得KA'后,攻击者能够做出哪些坏事?哪些坏事攻击者仍然不能做?
答:可以通过试错得到,若攻击者保留了之前的加密的消息记录的话,可以对该信道中的消息进行还原,但不能监听到其他信息
17.4 在17.3 节提到的协议中,假设攻击者可以窃听所有通信过程,那么KA、KB。暴露后,攻击者能否恢复出 Alice和 Bob 之间的通信内容?
答:不能,因为必须获得服务器生成的信道密钥才可恢复,而服务器状态已改变
17.5 在17.3 节提到的协议中,攻击者能否通过强迫密钥服务器重启来破坏协议,从而获得有用信息?
答:不能,密钥服务器会有一定的机制使每次重启后状态不同
第18章PKI之梦
18.1PKI的简短回顾
PKI:公钥基础设施(Public Key Infrastruecture),通过它可以知道哪个公钥属于谁。
CA:证书机构(Certificate Authority),有一对公私密钥对(例如 RSA密钥对),其中公钥是公开的。由于该公钥保持长期不变,一般假定所有人都知道CA的公钥。
How to加入PKI?
- 用户生成自己的公私密钥对
- 保持私钥不公开,并把公钥PKA传给 CA,声明PKA是自己的公钥
- CA证实用户的身份后,签署一个类似于"密钥PK、属于Alice"的数字声明。这个签署的声明就叫作证书,它证明密钥属于 Alice。
How to通信by PKI
在双方都相信CA公正性的前提下
- A将自己的公钥和证书发给B,B可以通过CA的公钥验证证书签名
- B将自己的公钥和证书发给A,A可以通过CA的公钥验证证书签名
此时双方知道彼此公钥,可运行密钥协商协议建立会话密钥
18.2PKI的例子
18.2.1全局PKI
终极梦想只是童话
全局PKI是一个非常庞大的组织,就像邮局,能够给每个用户发行公钥证书。
优势:就是每个用户仅仅需要得到一次证书,因为同样的公钥可以用在每个应用中。因为每个人都信任邮局,或信任其他任何一个成为全局CA的组织。这样所有人都可以安全地互相通信了。
18.2.2VPN访问
VPN:Virtual Private Network,允许公司雇员从家里或是旅行时从宾馆访问公司的网络。
识别:由VPN的访问接入点识别访问网络的人以及他们有何种确切的访问级别
PKI模型:公司的IT 部门扮演CA的角色,给每个雇员一个证书,使得 VPN 的访问接入点能够识别不同的雇员。
18.2.3电子银行
电子银行:允许银行客户在银行网站上进行金融交易。
识别:在应用中正确地识别客户的身份是至关重要的,就像在法庭上能提供可接受的证据一样重要。
PKI模型:银行本身就是CA,它能认证客户的公钥。
18.2.4炼油厂传感器
炼油厂传感器:可以测量几英里长的管道和通路间的温度、流速和压力之类的指标。
识别:用标准的认证技术来保证传感器数据没有被篡改,并通过PKI确认数据来自传感器
PKI模型:公司可以作为CA,为所有的传感器建立 PKI,使得每个传感器都能被控制室识别
18.2.5信用卡组织
信用卡组织:是遍布世界的数千个银行之间的合作组织。所有这些银行必须能够交换支付。
识别:采用PKI就可以让所有的银行,彼此识别身份以进行安全的交易。
PKI模型:信用卡组织就是CA,给每个银行颁发证书
18.3其他细节
PKI的各种拓展形式
18.3.1多级证书
很多情况下CA被分为多个层级,如密钥PKx属于区域机构X,它可以用来证明其他密钥
密钥证书则包含两个签名的消息:中心CA 证实区域机构密钥的授权消息和区域机构关于银行密钥的认证——证书链
缺点
- 证书体积变得更大,需要更多的计算来进行认证
- 加入系统的每个 CA 都会带来新的攻击点,降低安全性
解决方法:打破证书的层级结构
例:一旦银行有了两级证书,就把证书送到中心CA。中心CA对两级证书做验证,然后用主CA密钥签署一个银行密钥的单个证书。
18.3.2有效期
没有一种密码学密钥应该被无限期地使用
证书不该是永远有效的
- CA密钥和被认证的公钥都有有效期
- 更新证书以保持信息的时效性
证书还要包含啥?
有效时间\有效的起始时间\证书的不同类别\证书序列号\发行日期和时间等
18.3.3独立的注册机构
公司里只有R部门才能决定谁是雇员。但IT部门要运行CA,这是一个技术工作,他们不会允许HR部门来完成。
GOOD解决方案
-
使用多级证书结构,让 HR 部门成为子CA
自动提供了必需的灵活性来支持多站点
-
一旦用户有了两级证书,他就能从中心 CA得到一级的证书
通过把双消息协议加入系统,可以消除每次检查两级证书的额外开销
BAD解决方案
把第三方加入密码协议中,使CA 和RA 被看作完全独立的实体,产生了更多的描述联系
18.4结论
这是一个理想状态的梦想,它是密钥管理的起点和终点
18.5习题
18.1 假设CA 不可信,试问这样的 CA 可能引发什么样的后果?
答:证书数据存在被不公正地篡改、假冒的风险,证书文件不可信
18.2 假设有全局 PKI,那么在多个应用间使用单一的PKI会导致何种安全问题?
答:证书被多方知道而被其中的攻击者冒用
18.3 什么样的政策或者组织上的挑战会阻碍或者阻止全局 PKI的发展?
答:国家之间的计算阻碍,标准选择上的不同
第19章PKI的现实
现实世界中,PKI的宣传总是与实际不符
19.1名字
PKI把 Alice的公钥与她的名字绑定在一起。那么,什么是名字?
故事背景
名字可以是任何一种符号,我们用它来指代某个人,或更一般地说,指代某个实体。"官方"的名字仅仅是很多名字中的一个,对很多人来说还是很少被用到的一个。
隐含条件:
- 每个人都有一个名字
- 人名可能重复
- 人可以有多个名字
村庄:
- 每个人都互相认识,人名绑定人
城镇:
- 人变多,许多人没见过面,人名分离
城市:
- 人变多,重名人更多,人更可能接触多个重名人,名字与语境有关
互联网:
- 人名由于重名率极高而无意义,通过邮箱或唯一编码判断,但有人使用多个邮箱,有邮箱被多人使用
现实中的名字问题
- 政府机构’分配‘的官方名字,由不唯一的名字、可变的地址、不可证的驾照号、可变的性别、可欺骗的生日等标识构成,不具有唯一识别性
- 多个国家的不同标准间的多个名字
- 唯一的社会安全码(身份证号),无全球唯一性、与人的联系不紧密
大型PKI问题:庞大的人口基数,很多人有相同名字,很多人想用多个名字作不同用途,带来无与伦比的复杂度
19.2授权机构
谁是有权给名字分配密钥的这个CA呢?谁赋予这个CA关于用户名字的权力?谁来决定 Alice 是一个拥有VPN访问的雇员,或者仅仅是一个访问受限的银行客户
对大多PKI来说,问题不难,如老板知道谁是雇员,谁不是雇员,银行知道谁是客户。
对于全局PKI来说,没有权力来源
规划一个PKI必须考虑授权谁来发行证书
19.3信任
世界上没有一个组织能得到所有人的信任,甚至没有一个组织能得到大多数人的信任,因此永远不会有全局 PKI。但我们可以信任我们自己
So,我们不得不用大量小型PKI
被 CA使用的信任关系都是已经存在的,而且是建立在合同关系基础上的∶ 所建立的基本信任关系都是基于已有的合同关系之上的。
19.4间接授权
系统都不关心密钥属于谁,只是想知道密钥持有者被授权做什么
多数系统使用某种访问控制列表(Access Control List,ACL),这是一个关于谁被授权做什么事的数据库。
密钥授权
对象:密钥、名字、做某事的许可权
要求:系统想要知道的是哪个密钥授权哪种行为,换句话说,特定的密钥是否有特定的许可权
方法:通过把名字和密钥绑定以及用ACL把名字和许可权绑定来解决这一问题。
导致的额外攻击点
- PKI提供的名字-密钥证书
- 绑定名字和许可权的ACL数据库
- 名字混淆
技术设计是完全根据需求的幼稚表述而来的,人们考虑的问题是识别密钥持有者的身份以及谁能够访问
19.5直接授权
直接用PKI把密钥与许可权绑定,证书不再连接密钥和名字,它连接密钥和许可集合
去掉ACL和名字而避免了名字混淆问题,改变了对名字的依赖
19.6凭证系统
凭证系统是一个超级PKI,对于你做的每件事情要以签署证书的形式给出凭证
存在的问题
-
凭证系统是很复杂的,会带来显著的额外开销。
访问一个资源的授权也许要依靠数个证书组成的证书链来完成,而且每个证书都要被传递和检查
-
凭证系统会引起访问权限的细化管理。
容易把权限分成越来越小的部分,使得用户最终要花掉很多时间来决定分配给一个同事多少权限
-
要开发一种凭证和委托语言(credential and delegation language)
-
具体的授权委托对普通用户来说是过于复杂的概 念,似乎没有一种展示访问规则的方式能被用户理解。
凭证是有用而且必需的
如果使用分层的CA结构。中心CA签署关于子CA密钥的证书,如果这些证书不包含任何限制,那么每个子CA就都有无限的权利。这是很差的安全设计,我们只是增加了很多地方来存储关键的系统密钥。
19.7修正的梦想
修正后的梦想要现实的多,比原来的梦也更有效、更灵活、更安全,真悲伤
-
每个应用都有自己的PKI和自己的CA。
全世界包含了大量的小型PKI,每个用户同时是许多不同 PKI 的成员。
-
用户对每个PKI必须使用不同的密钥
为对于系统设计没有经过仔细协调的多个系统,用户不能使用相同的密钥。因此用户需要存储很多密钥,占用上万字节的存储空间
-
PKI的主要目的就是把密钥同凭证绑定在一起。
证书中仍然要包含用户的名字,但这主要是为了管理和审计的目的。
19.8撤销
有时一个证书不得不被撤销。也许 Bob 的计算机被黑客攻击。从而泄露了他的私钥。也许Alice被调到另一个部门或者被公司解雇了等等
问题:证书仅仅是一串位,已经在很多地方使用,而且储存在很多地方,不可能让所有人忘记
什么决定了撤销操作的需求
- 撤销的速度∶撤销命令发出与最后一次使用证书之间所允许的最大间隔时间是多少?
- 撤销的可靠性∶在某些情况下撤销不是完全有效的,这可以接受吗?什么样的遗留风险是可以接受的?
- 撤销的数目;撤销系统一次能处理多少撤销请求?
- 连接性;验证证书的过程是否为在线验证
可行的解决方案:撤销列表、短有效期以及在线证书验证
19.8.1撤销列表
撤销列表(certificate revocation list)、或称CRL,是一个包含撤销证书列表的数据库,每个验证证书的人都必须检查 CRL 数据库。看看那个证书是否已经被撤销。
过程:每个验证证书的人都必须检查 CRL 数据库。看看那个证书是否已经被撤销
优点:撤销几乎是瞬时的,也是可靠的。
缺点:CRL 系统的实现和维护都是很昂贵的,要求有自己的基础设施、管理程序、通信路径等。所需的额外功能相当可观,仅仅为了处理相对较少用到的撤销功能
19.8.2短有效期
利用已经存在的有效期机制来完成,使用证书时会从CA得到新证书
过程:每当 Alice想用她的证书时,她会从CA出得到一个新的证书。只要它是有效的,Alice就可以一直使用
优点:已经可用的证书发行机制,不需要独立的 CRL,降低系统复杂性
可行性:主要取决于应用是否要求撤销立即生效或者延迟是否可被接受。
19.8.3在线证书验证
证书状态协议(Online Certificate Status Protocol,OCSP)在一些领域(例如 Web浏览器)中已经有了很大的进展。
过程:为了验证一个证书,Alice 将证书的序列号提交给一个可信方进行查询,然后可信方在它自己的数据库中查询证书的状态,并发送一个经过签名的答复给 Alice。Alice已知可信方的公钥,所以可以验证答复的签名,如果可信方认为证书是有效的,那么 Alice 就可以知道证书并没有被撤销
优点:撤销几乎是瞬时的,也是可靠的。
缺点:验证证书时必须在线,并且可信方也成为一个故障点。但相对CRL避免了大量发布CRL的问题,也避免了客户端解析和验证 CRL。
实际使用中不如短有效期法
19.8.4撤销是必需的
没有撤销功能的PKI是相当无用的
虽然撤销很难实现,但必须实现,因为密钥肯定会被泄露
19.9PKI有什么好处
PKI目的:让Alice和Bob能生成共享密钥,用它来建立安全的信道,以便能彼此安全地通信。
实际上我们把环境建立在离线基础上,但没有一个撤销系统能完全离线工作。
但如果能在线,我们为什么不建立一个中心密钥服务器呢?
- 密钥服务器需要每个人实时在线。
- 密钥服务器是一个故障点。
- PKI提供了不可否认性。
- CA 根密钥被离线存储。
当然,这些不是非要不可的优势带来了更多的花费、更复杂的系统、更庞大的计算量
19.10如何选择
- 小型系统:密钥服务器
- 大型系统:PKI系统
19.11习题
19.1 如果 Alice 在不同的 PKI中采用相同密钥,会出现什么后果?
答:如果一个PKI中的密钥泄露,其他的PKI中Alice的信道也将不安全
19.2 假设一个系统中的每个设备能存储 50 条 CRL 数据。这种设计会导致何种安全问题?
答:一些CRL数据没有被记录在设备上而导致设备并不知晓证书的撤销
19.3 假设一个应用PKI的系统采用CRL。一台系统中的设备想要验证证书,但由于拒绝服务攻击而无法访问 CRL 数据库。那么这台设备可以采取哪些措施呢?试分析各种措施的优缺点。
答:可以通过其他副本得到CRL
第20章PKI的实用性
20.1证书格式
证书仅仅是带有多个必选域和可选域的数据类型。重要的是要注意特定数据结构的编码是唯一的。
20.1.1许可语言
除非你的PKI系统是最简单的那种,否则你一定会想要限制子CA 能够发行的证书。为此需要把某种限制编码到子CA的证书中
有一种语言来表示密钥的许可权,用来做何种限制由具体应用决定。
假如...
如果不能找到合理的限制条件,就应该重新考虑是否要使用PKI。
如果在证书中没有限制,那么每个子CA都会有一个主密钥,那是很不安全的设计。
如果把系统限制为单个CA,但那样就会失去很多 PKI 优于密钥服务器系统的优势。
20.1.2根密钥
CA的公钥及效期之类的数据被分配给每个参与者
自证明证书:CA对公钥签署证书,作用是将公钥吧附加数据绑在一起,包含许可权列表、有效期、联系人信息等,即为PKI的根证书
必要性:把根证书以安全的方式分配给所有的系统参与者。每个人必须知道根证书,而且必须有正确的根证书。
FIRST:计算机第一次加入PKI时,必须以安全的方式得到根证书。
验证方式:由于缺乏认证密钥,密码学上无法认证,必须保证来源安全性。用户指定本地或服务器上的文件为根证书。
问题:若CA私钥泄露,PKI必须初始化
LATER:根密钥到期后,CA会发行新的根证书。
验证方式:通过旧密钥签署认证,所以证书来源可不安全
问题:参与者可能没有得到新的根证书。
一个小问题
新的CA根证书可能有两个签名∶一个签名是用旧的根密钥签署的,使得用户能识别新的根证书;另一个(自证明的)签名是用旧密钥到期后产生的新密钥签署的。
解决方案:在证书格式中包含对多个签名的支持。或者仅仅是对同一个新的根密钥发行两个独立的证书。
20.2密钥的生命周期
它可以是CA 的根密钥,也可以是任何其他的公钥
-
创建
密钥生命周期的第一步是创建密钥。Alice创建一个公/私钥对,并以安全的方式存储私钥部分。
-
认证
Alice把她的公钥传给CA或子CA,让它来认证公钥。这时CA 决定给 Alice 的公钥赋予哪些许可权。
-
分发
根据具体的应用,Alice也许要在使用公钥前分发她的已认证公钥。例如,如果 Alice用自己的私钥来签名,能收到Alice签名的每一方都应该先有她的公钥。
最好的办法就是在Alice第一次使用公钥前的一段时间内分发密钥,这对于新的根证书尤为重要。例如。当CA切换成一个新的根密钥时,每个人都应该在接触到用新密钥签署的证书之前有机会知道新的根证书。
是否需要一个独立的分发阶段要根据具体的应用来决定。如果可能,应该尽量避免这一阶段,否则就要向用户解释该阶段,并且要在用户界面上可见。 -
主动使用
下一阶段是 Alice 主动用她的公钥进行交易。这是密钥使用的一般情况。
-
被动使用
主动使用阶段过后,一定会有一段时间 Alice 不再用她的密钥进行新的交易,但所有人仍然接收这个密钥。交易不是瞬时完成的,有时会有延迟。
Alice 应该停止主动地使用密钥,在密钥到期之前留出一段合理的时间,让所有待决的交易完成。
-
到期
密钥到期后,它不再被认为是有效的。
密钥阶段是如何进行定义的?
在证书中包含每个阶段过渡的确切时间。证书包含密钥分发阶段的开始时间、主动使用阶段的开始时间、被动使用阶段的开始时间以及有效期。
所有这些时间都必须提供给用户,因为它们影响着证书的工作方式
更灵活的方案:建立一个中心数据库,包含每个密钥的阶段。但会带来CRL使密钥立即到期的风险
额外且不必要的任务:Alice想要在几个不同的PKI中使用相同的密钥
虽然很危险但有时不可避免的例子:Alice 使用一个小的抗干扰模块,并随身携带它。这个模块包含她的私钥,并且能做数字签名所需的计算。这样的模块具有有限的存储能力,Alice关于公钥的证书能被存储在没有文件大小限制的公司内部网上,但是这个小模块不能存储无限数目的私钥。在这种情况下,Alice最终只能对多个PKI使用同样的私钥。
解决方案:保证在一个PKI中使用的签名不能在另一个PKI中使用。
最简单的解决方案:在签名的字节串中包含一些数据,用这些数据来做应用和 PKI 的唯一标识
20.3密钥作废的原因
什么限制了密钥的使用周期?
- 持有密钥的时间越长、使用它的次数越多,攻击者设法得到密钥的概率就越大
- 在攻击者得到密钥后,过去和以后的数据都有泄露的风险
短密钥周期的优势:
- 减少了攻击者得到密钥的机会
- 限制了攻击成功带来的危害
一个密钥合理的生命周期是多少?
最大值:一年
合理值:一个月以上
周期更短时应自动管理
保持密钥长期不变的最大危险也许是更换密钥功能从来没被用过,因此当要它时就不能正常运行了。一年的密钥生命周期可能是一个合理的最大值。
20.4深入探讨
密钥管理不单单是个密码学问题,而是和真实世界紧密相关的问题。
选择何种PKI以及如何配置,取决于具体应用和部署应用的工作环境。
20.5习题
20.1 你认为哪些字段需要出现在证书中,为什么?
答:用户需要知道证书有效期、有效起始时间、CA、被证实的文件、证书的摘要值等字段,这些字段保证了被签名文件的完整性和安全性
20.3 假设你已部署了一个PKI.这个PKI使用固定格式的证书。现在你需要进行系统更新。更新后的系统需要与之前原始版本的PKI以及证书格式保持向后兼容性,但是更新后的系统需要证书中有额外的字段。这种过渡会带来什么问题?在考虑到系统中的证书会更新为新格式的情况下,在最初设计系统时需要进行何种准备?
答:会导致系统中要针对旧版本做额外的安全性或功能性处理,会降低系统的处理效率。最初设计证书时应在各部分间留有升级拓展空间
第21章存储秘密
怎样存储像口令和密钥这样的长期秘密呢?
- 这个秘密应该保持其私密性
- 丢失这个秘密的风险应该尽可能小
21.1磁盘
直接办法:把秘密存储在计算机的硬盘上或其他永久存储介质上
问题:需确保设备安全、用户可能会用多台设备、秘密不便携
更好的解决方案:让 Alice把密钥存储在她的PDA或智能手机上
21.2人脑记忆
记住口令?
- 人脑记忆能力差
- 不存在简单又安全的口令
- 攻击者用穷举就能攻破
- 可能只能用单词记忆长字符
好的口令不可预测
- 好口令应包含大量熵
- 用户拒绝使用过长至安全性到128位的口令
密码短语的想法
- 密码短语相对单纯口令可以更长更好记,如句子中每个单词的首字母
- 要确保句子唯一性
- 储存128位熵依然困难
加盐
- 盐就是一个随机数,与加密的口令存放在一起
- 最好采用256 位的盐
攻击者同时攻击大量口令时。盐能够防止他利用规模扩大而节约计算量
扩展
- 对口令进行加密的数次长计算
- 令p是密码口令,s是盐。使用任意保密性强的散列函数h得到密钥K来实际加密数据。参数r是计算迭代的次数,只要实际情况允许,r值应该尽可能大。
攻击者角度
给定盐s和用K加密的数据,你试图通过尝试不同的口令来找到K。选择一个特定的密码口令p,计算相应的K,用它解密数据,检查解密结果是否有意义并且能通过相关的完整性检查。如果不是,则p必定是假的。为了检查单个的p,必须要做r次不同的散列计算。r越大,攻击者做的工作就越多。
21.3便携式存储
在计算机之外存储
最简单的存储方式:把口令写在一页纸上
问题:每次使用口令时仍然需要通过用户的眼睛、大脑和手指来处理。为了把用户的错误限制在一个合理的界限内、这种技术仅仅适用嫡比较低的口令和密码短语。
便携式存储:一张存储芯片卡、一张磁条卡、一个USB 盘或是任何其他种类的数字存储设备
优势:数字存储系统总是能存储至少256位的密钥,因此我们可以排除低熵的口令
特性:非常像一个密钥,无论谁得到它,都能够拥有访问权,因此需要安全地放置。
21.4安全令牌
更好但也更贵的解决方案:使用安全令牌设备。这是 Alice能够随身携带的一个小型计算机。
形态:从智能卡到iButton、USB 加密狗或PC卡。
主要性质:有一个永久性存储器和一个 CPU。
安全性改进:通过口令或类似的方法来限制访问被存储的秘密、 在物理层面上保护了令牌(偷+破解)
需要注意的问题:用户行为,用户应始终把令牌带在身边,通过用户培训或其他方式养成
21.5安全UI
我们并不信任PC
在令牌中内置安全的UI,可以直接输入令牌而不用信任外部设备,防止PIN被攻破
为了防止PIN被PC泄露,我们最好在令牌中也前任密码学过程
最终会发展成一台全功能计算机,最相近的产品是个人数字助理和智能电话
21.6生物识别技术
结合生物识别技术可以把安全做得漂亮些,但安全性不够
方案:将指纹扫描仪或虹膜扫描仪设备嵌入安全令牌
问题:安全性不高,能够简单低成本地被欺骗
不过可以提高攻击成本,提供一点点的安全性
21.7单点登录
用户都有很多口令,因此产生一个单点登录系统就变得很有吸引力。
用给Alice一个的主口令,来给不同应用中的不同口令加密。
准备工作:所有的应用都必须与单点登录系统对话。大规模的工作带来了挑战
简单方法:用一个小程序把口令都存在一个文本文件中,登录时自动读入
21.8丢失的风险
代价:至少是不得不给每个应用注册一个新密钥,严重的话会永远失去访问重要数据的许可权
经验法则:把功能分开。保持密钥的两个副本∶ 一个容易使用,另一个更可靠。如果容易使用的系统忘记了密钥,可以从可靠存储的系统中恢复它
21.9秘密共享
将个秘密分成几个不同的分块(share),其中若干个组合后可恢复
技巧:任意两个人在一起绝对不会知道关于密钥的任何事情。
问题:应用、管理、操作都很复杂,不适用于现实工作
21.10清除秘密
只要秘密不再被需要,它的存储就应该被清除,以免将来被泄露。
21.10.1纸
烧掉后碾成粉末或混成泥浆
21.10.2磁存储介质
反复重写数据,请注意:
- 每次重写应该使用新的随机数据
- 一定要在存储秘密的实际位置重写
- 保证每次重写是写到磁盘上,而不是写到磁盘缓存中
- 清除自秘密数据之前开始,且到它之后结束一段区域
消磁机或消除介质理论可靠但不现实
21.10.3固态存储
消除非易失性内存(像 EPROM、EEPROM 和闪存)时对旧数据进行重写不能根本地清除旧数据
最好销毁固态存储
21.11习题
1.1 了解登录口令是如何在你的计算机中存储的。试编写程序,根据给定的被存储的口令(经加密或散列后的),对真实口令进行穷举搜索。穷举头一百万个密钥口令需要多长时间?
答:登录口令被存储在C:\WINNT\system32\config目录下的SAM文件中,而微软的服务登录通过微软账户单点登录,使用Advanced Archive Password Recovery穷举十进制口令,平均需要260ms(i7-8750H,60%性能下)
21.3 给定一个24位的盐。64个用户中。两个用户有相同盐值的概率是多少?1024个用户呢?4096个用户呢? 16 777 216 个用户呢?
答:盐值有224个可能,两人中有相同的可能为224/224*2=1/224,64人中有2人相同的概率是C2 64/224=1/219 ,1024人中有2人相同的概率是C2 1024/224=1/215,16777216人中有2人相同的概率是C2 64/224=1/2
21.4 举出一个维护长期秘密的产品或系统。
答:银行保险箱、
第五部分 其他问题
第22章标准和专利
22.1标准
标准是一把双刃剑
YES:不会有人因为我们应用一项标准而挑我们的毛病
NO:许多安全标准并不奏效
22.1.1标准过程
标准化委员会
标准化组织(如IETF,IEEE等)组织建立委员会,提出新标准或改进标准的需要
- 委员会成员一般都是自愿参加的,申请者需要通过一些过程化的、不严格的考试
- 委员会有固定时间的会议,来决定继续进行的方向
- 成员是各路公司派来的,公司的动机为:跟踪标准化过程以提供产品兼容、监视对手、控制标准化进度
将占领市场的系统定义为标准。成功的委员会在几年后都会推出一个标准化文件。
互操作性测试
标准被制定出来后,每个制造商都要调整他们的实现,使它们能够协同工作。
最重要的是达成一致而不是优秀的技术。唯一的妥协方式是使所有公司具有同等的不满意度
1.标准
不明确的要求使大多数标准相当难读,只有少数委员会成员能理解和应用
大部分成员也不会读完,只阅读他感兴趣的章节
2.功能
标准通常包含大量的可选项,但是实际的实现仅仅使用了特定的可选项,当然会有一些限制和扩展,
主要功能的会同标准
3.安全性
为了技术上的安全性系统应当简单化,但委员会会妨碍简单化使得结果不安全
安全标准能够保证如果我们坚持遵守它就能达到一定的安全等级
22.1.2SSL
SSL是 Web 浏览器与Web 服务器进行安全连接使用的安全协议
SSL是个好协议,但不认为使用SSL的系统是安全的
SSL没有被标准化,但是成为了事实上的标准,被标准化和进一步开发为TLS
22.1.3AES:竞争带来的标准化
一个由竞争设计而不是委员会设计的标准
实现过程
-
说明系统最终要达到的目标
由一小群人结合许多不同来源的要求而提出
-
收集提案
请专家来开发满足给定需求的完整解决方案后作选择,让提交者互相竞争挑错,聘请外来专家评估
-
选出提案或稍加改动
得到的候选提案都是好标准,都比委员会设计得好
要点
如果没有足够的专家提出至少几个有竞争力的设计,标准化的竞争模型就不能工作
如果没有足够多的专家提出几个设计,就不应该对任何安全系统进行标准化
22.2专利
目前围绕专利的系统已经有了变化,它能够影响我们使用哪些协议,建议问律师
第23章关于专家
每个人都认为自己掌握了是够多的密码学知识,可以设计和构建他们自己的系统。
产生坏影响的例子
《应用密码学》:因关注度出名,因读者的‘自信’声名狼藉
802.11标准:无专家的委员会设计,完全被攻破,但与现有硬件配套而不得不升级使用WPA
本书也可能造成坏影响
证书让人们构成了自己会设计密码算法和协议的假象,可能设计出一个70%正确性的系统,但系统的安全性依赖于最脆弱的环节。为了安全,一切必须是正确的
本书能够帮助人们了解如何设计密码系统、提供足够的密码学实践的背景、灌输给读者专业批判的思想
当涉及实践时,最好是聘用密码学专家
项目文化更重要
安全第一,不该只是口号,应成为项目团队的基本共识,需要长期构建
安全是一个过程,而不是一个产品
由于信息技术对于我们的基础设施、我们的自由、我们的安全越来越重要,因此我们必须要不断提高系统的安全性。我们必须尽最大努力去做。
