
ASVspoof 2019_LA数据集处理
数据集基础信息
数据集地址:ASVspoof 2019_LA数据集
数据集描述:
ASVspoof 2019语料库的LA数据集中的语音数据全部是基于VCTK语料库得到的,VCTK语料库采集了包含46名男性和61名女性在内的107名说话人的真实语音,所有的真实语音均采用了相同的录音配置,且没有信道和背景噪声的干扰。LA数据集中的真实语音均直接选取自VCTK语料库,而数据集中欺诈语音则均是由这些真实语音使用不同的语音合成和语音转换技术得到的,所有语音数据的采样率均为16kHz。

数据集中的数据被分成了三个子集, 分别为训练集 (Train)、 开发集(Development)和测试集(Evaluation)。 其中,训练集和开发集中的欺诈语音均来源于6种相同的语音合成和语音转换技术,这6种技术作为已知的攻击类型,可以用来对合成语音检测系统进行训练和调整,而测试集中欺诈语音的生成方法包含了2种上述的已知攻击和11种与6种已知攻击不同的语音合成和语音转换技术,这11种技术作为系统面临的未知攻击类型。
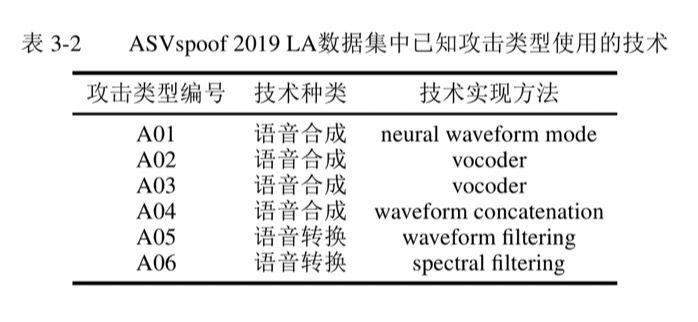

ASVspoof 2019_LA数据集描述及图表均来自论文【刘畅. 关于自动说话人确认系统的反语音合成欺骗攻击的研究[D].天津大学,2020.DOI:10.27356/d.cnki.gtjdu.2020.002592.】
数据集处理
该数据集的音频文件均为flac格式,且没有文本标注。基于自身研究需要,需要语音文本来对提取音素。现有的音频处理接口基本均支持wav格式音频,为了研究方便,需要对该数据集进行以下处理:
1.格式转换。flac格式转wav格式
2.语音识别。由语音得到文本
格式转换
flac格式是wav格式的一种无损压缩格式,它通过编码压缩的方式,可以达到节省空间的目的。此外,FLAC格式具有较好的抗损性,其压缩后每一帧都是不相关的,在压缩或传输过程中出
现损坏时,受影响的内容只有特定的损坏帧,而不会影响前后帧的内容。将flac格式转换为wav格式基本不会对丢失原始音频的信息。
使用pydub库实现对数据集的批量转换,转换后的文件存放在wav目录中,实现效果如下:
from pydub import AudioSegment
import os
def trans_flac_to_wav(outputdir,filepath,hz):
"""
flac格式转为wav格式
"""
audio = AudioSegment.from_file(filepath)
isExists = os.path.exists(outputdir) # 检查目录是否存在
if not isExists:
os.mkdir(outputdir) # 不存在,新建目录
filename = os.path.basename(filepath).split('.')[0]
audio.export(outputdir + filename +"."+str(hz), format=str(hz))
path=r"/Users/zhangxiao/Downloads/LA/ASVspoof2019_LA_train/flac/"
for fileName in os.listdir(path):
if os.path.splitext(fileName)[1] == '.flac':
savedir = "/Users/zhangxiao/Downloads/LA/ASVspoof2019_LA_train/wav/"
trans_flac_to_wav(savedir, path+fileName, "wav")
语音识别
数据集的语料是英文语料,语音识别使用了百度的API和科大讯飞的API进行了对比,两种API均可以查阅官方文档来实现。百度API的调用较科大讯飞API更简单,在10个文件的识别结果来看,科大讯飞API的识别效果好于百度API的识别效果,我选择使用科大讯飞的语音识别API来对数据集进行识别。
百度短语音识别API:https://cloud.baidu.com/doc/SPEECH/s/Vk38lxily
科大讯飞语音识别API:https://www.xfyun.cn/doc/asr/voicedictation/API.html#接口说明
import websocket
import datetime
import hashlib
import base64
import hmac
import json
from urllib.parse import urlencode
import time
import ssl
from wsgiref.handlers import format_date_time
from datetime import datetime
from time import mktime
import _thread as thread
import os
STATUS_FIRST_FRAME = 0 # 第一帧的标识
STATUS_CONTINUE_FRAME = 1 # 中间帧标识
STATUS_LAST_FRAME = 2 # 最后一帧的标识
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret, AudioFile):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.AudioFile = AudioFile
# 公共参数(common)
self.CommonArgs = {"app_id": self.APPID}
# 业务参数(business),更多个性化参数可在官网查看,zh_cn,en_us
self.BusinessArgs = {"domain": "iat", "language": "en_us", "accent": "mandarin", "vinfo":1,"vad_eos":10000}
# 生成url
def create_url(self):
url = 'wss://ws-api.xfyun.cn/v2/iat'
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + "ws-api.xfyun.cn" + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + "/v2/iat " + "HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": "ws-api.xfyun.cn"
}
# 拼接鉴权参数,生成url
url = url + '?' + urlencode(v)
# print("date: ",date)
# print("v: ",v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
# print('websocket url :', url)
return url
# 收到websocket消息的处理
def on_message(ws, message):
try:
code = json.loads(message)["code"]
sid = json.loads(message)["sid"]
if code != 0:
errMsg = json.loads(message)["message"]
print("sid:%s call error:%s code is:%s" % (sid, errMsg, code))
else:
data = json.loads(message)["data"]["result"]["ws"]
# print(json.loads(message))
result = ""
for i in data:
for w in i["cw"]:
result += w["w"]
############文本写入#################
resultName = "spoof_result.txt"
with open(resultName,'a') as f: #设置文件对象
if(result == "." or result =="?"):
f.write(result)
f.write("\n")
else:
f.write(fileName + ' ')
f.write(result) #将结果写入文件中
# print("sid:%s call success!,data is:%s" % (sid, json.dumps(data, ensure_ascii=False)))
except Exception as e:
print("receive msg,but parse exception:", e)
# 收到websocket错误的处理
def on_error(ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(ws, a1, a2):
print("### closed ###")
# 收到websocket连接建立的处理
def on_open(ws):
def run(*args):
frameSize = 16000 # 每一帧的音频大小
intervel = 0.04 # 发送音频间隔(单位:s)
status = STATUS_FIRST_FRAME # 音频的状态信息,标识音频是第一帧,还是中间帧、最后一帧
with open(wsParam.AudioFile, "rb") as fp:
while True:
buf = fp.read(frameSize)
# 文件结束
if not buf:
status = STATUS_LAST_FRAME
# 第一帧处理
# 发送第一帧音频,带business 参数
# appid 必须带上,只需第一帧发送
if status == STATUS_FIRST_FRAME:
d = {"common": wsParam.CommonArgs,
"business": wsParam.BusinessArgs,
"data": {"status": 0, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
d = json.dumps(d)
ws.send(d)
status = STATUS_CONTINUE_FRAME
# 中间帧处理
elif status == STATUS_CONTINUE_FRAME:
d = {"data": {"status": 1, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
ws.send(json.dumps(d))
# 最后一帧处理
elif status == STATUS_LAST_FRAME:
d = {"data": {"status": 2, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
ws.send(json.dumps(d))
time.sleep(1)
break
# 模拟音频采样间隔
time.sleep(intervel)
ws.close()
thread.start_new_thread(run, ())
if __name__ == "__main__":
# 测试时候在此处正确填写相关信息即可运行
path = "/Users/zhangxiao/mfa_data/my_corpus/audio_wav/LA_spoof/"
for fileName in os.listdir(path):
if os.path.splitext(fileName)[1] == '.wav':
audio_file = path + fileName
time1 = datetime.now()
wsParam = Ws_Param(APPID='XXXX', APISecret='XXXXXXXXXXXXXXXXXXX',
APIKey='XXXXXXXXXXXXXXXXXXX',
AudioFile=audio_file)
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = on_open
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
time2 = datetime.now()
# print(time2-time1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号