强制对齐普通话音频和分割音素
准备工作
1.安装MFA库,参考官方文档
2.拼音词典可使用MFA中自带的mandarin字典,或下载普通话词典mandarin-for-montreal-forced-aligner-pre-trained-model.lexicon
3.普通话模型,可使用MFA自带的mandarin模型,或下载普通话模型,或自行训练模型(参考官方文档在语料库上训练新的声学模型)。
4.音频数据,该目录下每个文件下包含.wav文件和.lab文件,.lab文件中存放的是.wav的拼音。
强制对齐普通话音频
1. 生成.lab文件
可通过执行text_pinyin.py文件将音频对应的文本文件转为.lab文件。
import os
import sys
import numpy as np
from pypinyin import pinyin, lazy_pinyin, Style
import re
root_dir = "/Users/mfa_data/my_corpus/synthesis_audio/"
pattern = re.compile(r'(.*)\.txt$')
for root, dir, files in os.walk(root_dir):
for filename in files:
#print(filename)
output = pattern.match(filename)
if output is not None:
print(root, filename)
text_file = open(root+"/"+filename)
line = text_file.read().strip()
line = line.replace(",", "")
pinyin = lazy_pinyin(line, style=Style.TONE3, neutral_tone_with_five=True)
pinyinline = ' '.join(pinyin)
print(line)
target_text_file = open(root+"/"+output.group(1)+".lab", "w")
target_text_file.write(pinyinline)
target_text_file.close()
text文件如下所示:
张大千国画有什么
.lab文件如下所示:
zhang1 da4 qian1 guo2 hua4 you3 shen2 me5
2.生成TextGrid文件
- 激活MFA。命令
conda activate aligner - 校验音频数据的格式是否适合MFA。命令
mfa validate 音频数据 普通话字典
mfa validate ~/mfa_data/my_corpus/test/input/ ~/mfa_data/my_corpus/mandarin-for-montreal-forced-aligner-pre-trained-model.txt
- 对齐音频。命令
mfa align 音频数据 普通话词典 普通话模型 保存目录
mfa align ~/mfa_data/my_corpus/test/input/ ~/mfa_data/my_corpus/mandarin-for-montreal-forced-aligner-pre-trained-model.txt mandarin ~/mfa_data/my_corpus/test/output
若出现报错信息,按报错信息检查或者更换模型,完成后的信息提示如下:
TextGrid文件格式如下:
File type = "ooTextFile"
Object class = "TextGrid"
xmin = 0
xmax = 2.1875
tiers? <exists>
size = 2
item []:
item [1]:
class = "IntervalTier"
name = "words"
xmin = 0
xmax = 2.1875
intervals: size = 10
intervals [1]:
xmin = 0
xmax = 0.22
text = "zhang1"
intervals [2]:
xmin = 0.22
xmax = 0.37
text = "da4"
intervals [3]:
xmin = 0.37
xmax = 0.69
text = "qian1"
intervals [4]:
xmin = 0.69
xmax = 0.84
text = "guo2"
可使用Praat软件打开TextGrid文件,同时打开.wav和.textGrid文件,可得到如下界面:
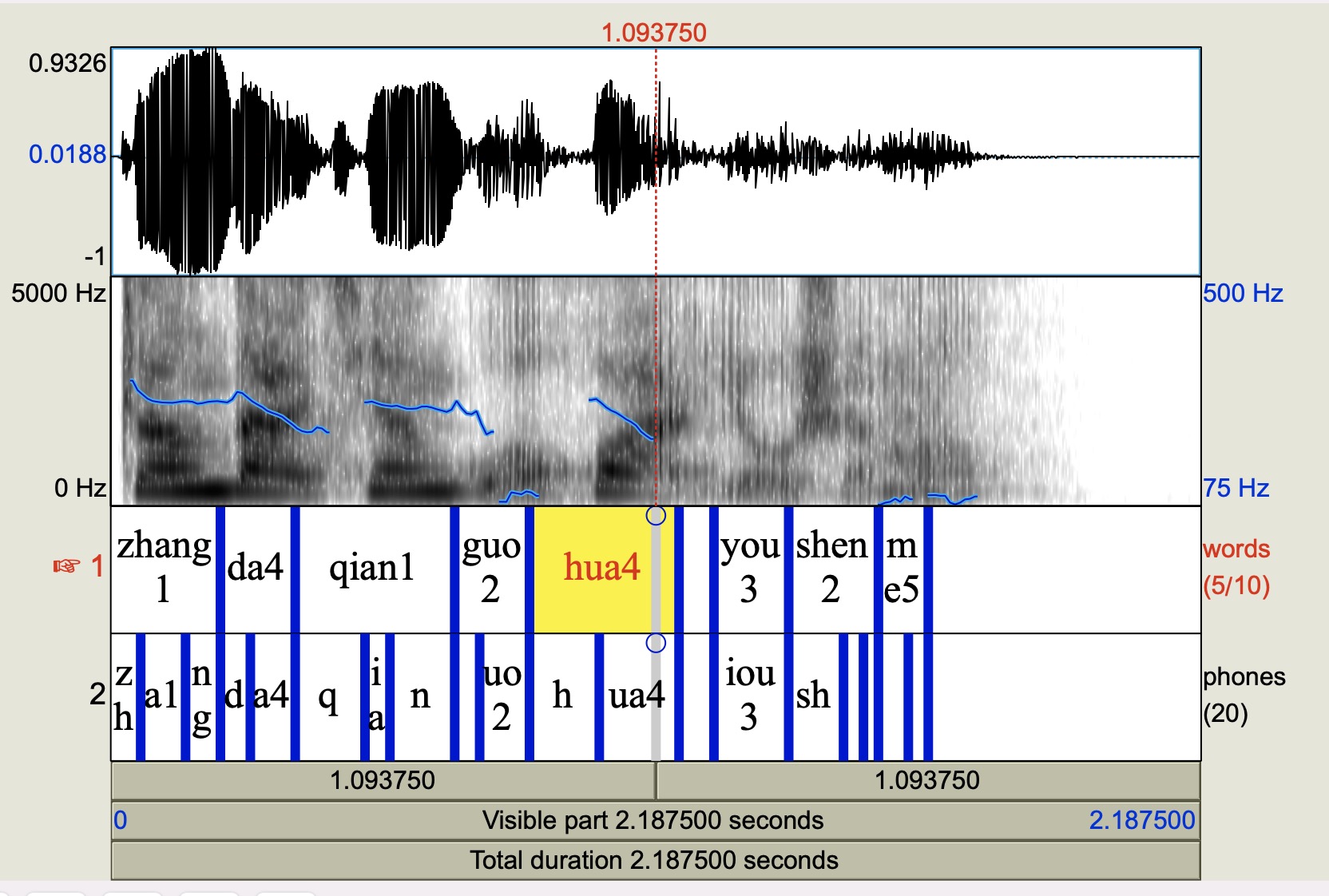
按TextGrid文件分割音频得到音素
1.执行read_textgrid.py,将音频文件按音素进行分割,并将分割信息保存至xls文件。
import textgrid
import xlwt
import datetime
from pydub import AudioSegment
import os
def read_textgrid(file_name):
"""
textgrid文件中的size的值是几就表示有几个item, 每个item下面包含class, name, xmin, xmax, intervals的键值对,
item中的size是几就表示这个item中有几个intervals, 每个intervals有xmin, xmax, text三个键值参数.
"""
datas = []
tg = textgrid.TextGrid()
tgrid = tg.read(file_name)
intervalTire = tg.tiers[1] #时长集合
intervals = intervalTire.intervals #返回所有的 interval 的列表
for i, interval in enumerate(intervalTire):
start = intervalTire[i].minTime
end = intervalTire[i].maxTime
text= intervalTire[i].mark
if(text != ""):
# print(start, end, text)
data = [start, end, text]
datas.append(data)
print(len(datas))
return datas
def cut_wav(datas, file_name):
for i, data in enumerate(datas):
start = datas[i][0] #音素开始时间
end = datas[i][1] #音素结束时间
text = datas[i][2] #音素文本
cut_start = start * 1000
cut_end = end * 1000
sound = AudioSegment.from_file(file_name, "wav")
save_name = text + "_"+ file_name.split('/')[-1] + "_"+ str(datetime.datetime.utcfromtimestamp(start).strftime('%H:%M:%S.%f')) + "-" + str(datetime.datetime.utcfromtimestamp(end).strftime('%H:%M:%S.%f')) +".wav"
print(save_name)
phon =sound[cut_start: cut_end]
phon.export(save_name, format="wav")
def write_xlsx(datas, filename):
workbook = xlwt.Workbook(encoding = 'utf-8')
# 创建一个worksheet
worksheet = workbook.add_sheet('sheet1', cell_overwrite_ok=True)
for i, data in enumerate(datas):
start = data[0] #音素开始时间
end = data[1] #音素结束时间
text = data[2] #音素文本
start_time = datetime.datetime.utcfromtimestamp(start).strftime('%H:%M:%S.%f')
end_time = datetime.datetime.utcfromtimestamp(end).strftime('%H:%M:%S.%f')
# 参数对应 行, 列, 值
worksheet.write(i, 0, text)
worksheet.write(i, 1, start_time)
worksheet.write(i, 2, end_time)
# 保存
workbook.save(filename)
print(filename + "XLS保存成功")
path=r"/Users/zhangxiao/mfa_data/my_corpus/test/input/"
for fileName in os.listdir(path):
if os.path.splitext(fileName)[1] == '.TextGrid':
textgrid_file = path + fileName
datas = read_textgrid(textgrid_file)
cut_wav(datas, textgrid_file.split(".")[0] + ".wav")
write_xlsx(datas, textgrid_file.split(".")[0] + ".xls")
2.将音素文件按音素类别归类
上述程序将音频切割后,所有的音素均在一个文件夹中,可执行下列程序,将同一音素进行归类。
import os
import shutil
"""
将同一文件夹下的不同音素文件分类到不同文件夹
"""
dir=r"/Users/zhangxiao/mfa_data/my_corpus/test/phoneme/"
files_list=os.listdir(dir)
files_list.sort()
for file in files_list:
filename, suffix = os.path.splitext(file)
if suffix == '.wav':
phoneme = filename.split('_')[0]
if not os.path.exists(os.path.join(dir, phoneme)):
# shutil.rmtree(phoneme) 删除目录
os.mkdir(os.path.join(dir, phoneme))
src = os.path.join(dir, file)
dst = os.path.join(dir, phoneme)
shutil.move(src, dst)
# print(filename)
print("文件归类完成")


 浙公网安备 33010602011771号
浙公网安备 33010602011771号