引擎之旅 Chapter.3 文件系统
引言
为什么会将文件系统放在引擎的底层核心代码呢?对于游戏而言,游戏的本质就是多媒体体验(模型、声音、视频等),而游戏引擎引擎需要在底层实现相关文件的读取作为支撑。
文件系统和资源管理器是两个概念。文件系统的功能是文件的读写,针对的是单文件或文件夹;而资源管理器则是目录级别的增删查改,可以成为引擎文件的简易版数据库。
- 对于游戏引擎来说,文件系统应该要实现一下几个部分:
- 操作文件名和文件路径
- 开、关、读、写单独的文件
- 处理异步文件输入/输出(IO)请求(做串流之用)
下面我们这几部分进行逐一分析,并展示实现的代码。
在此之前...
对于文件系统。字符串应该是密不可分的。且不说很多文件都与文本(字符串组成),文件路径也是通过字符串来表达的。因此,对字符串的处理对于文件系统来说是十分重要的。幸运的是,C提供了许多对字符串的操作函数,我们需要对它们进行封装整合即可。
Unicode和ASCII
关于使用ASCII还是Unicode,我的建议是尽量两种都实现,毕竟我们不知道仅仅使用一种类型的字符会不会在未来的开发中遇到麻烦,多多益善。
例如:在文件流处理中,我发现了宽字符版本的fputws和fgetws使用时其fopen()不能基于文本,只能基于二进制。而二进制对于要记录文字可读性是非常差的。因此,最好使用ASCII版的 fputs和fgets
而在Windows中字符和字符串的类型有众多定义(天晓得为什么会则么多)。为代码类型统一性,我现在这里做一个规范。在此引擎代码中,我将使用如下字符类型。
| 字符集 | 字符类型 | 常量字符类型 | 字符指针类型 | 常量字符串类型 |
|---|---|---|---|---|
| ASCII | CHAR | const CHAR | PSTR | PCSTR |
| Unicode | WCHAR | const WCHAR | PWSTR | PCWSTR |
C风格字符串的操作函数集合
接下来我们要将C风格字符串的操作函数用自己的命名风格对其进行封装。代码虽然比较多,但不复杂。每一种函数都要写ASCII和Unicode两种脚本。函数按功能分类主要有:
- 按功能分类
- 获取字符串长度
- 字符串复制
- 字符串拼接
- 字符串比较
- 字符串中查找字符(从左往右和从右往左两个版本)
- 字符格式化
- CHAR字符串和WCHAR字符串之间的相互转换
字符串操作
//TEString.h
//-------------------------------------------------------------------------
#include <wchar.h>
#include <tchar.h>
//获取宽字符串长度
//param:
// str:计算的字符串
//return:
// 返回字符串长度
inline size_t TStrLen(PCWSTR str)
{
return _tcslen(str);
}
//获取字符串长度
//param:
// str:计算的字符串
//return:
// 返回字符串长度
inline size_t TStrLen(PCSTR str)
{
return strlen(str);
}
//获取[char16_t]字符串长度
//param:
// str:计算的字符串
//return:
// 返回字符串长度
inline size_t TStrLen(register const char16_t* str)
{
if (!str)
return 0;
register size_t len = 0;
while (str[len++]);
return len - 1;
}
//获取[char32_t]字符串长度
//param:
// str:计算的字符串
//return:
// 返回字符串长度
inline size_t TStrLen(register const char32_t* str)
{
if (!str)
return 0;
register size_t len = 0;
while (str[len++]);
return len - 1;
}
//宽字符串复制
//param:
// dest:目标缓存指针
// destlen:目标缓存大小
// source:拷贝源字符串
inline errno_t TStrCpy(PWSTR dest, size_t destlen, PCWSTR source)
{
return _tcscpy_s(dest, destlen, source);
}
//char字符串复制
//param:
// dest:目标缓存指针
// destlen:目标缓存大小
// source:拷贝源字符串
inline errno_t TStrCpy(PSTR dest, size_t destlen, PCSTR source)
{
return strcpy_s(dest, destlen, source);
}
//宽字符串复制
//param:
// dest:目标缓存指针
// destlen:目标缓存大小
// source:拷贝源字符串
// cpylen:拷贝字符串长度
inline errno_t TStrCpy(PWSTR dest, unsigned int destlen, PCWSTR source, unsigned int cpylen)
{
return _tcsncpy_s(dest, destlen, source, cpylen);
}
//将宽字符串endStr拼接到dest上
//param:
// dest:目标缓存指针
// destlen:目标缓存大小
// endStr:拼接的字符串
inline errno_t TStrCat(PWSTR dest, size_t destlen, PCWSTR endStr)
{
return _tcscat_s(dest, destlen, endStr);
}
//将宽字符串endStr拼接到dest上
//param:
// dest:目标缓存指针
// destlen:目标缓存大小
// endStr:拼接的字符串
// catlen:需要从拼接字符串获取的长度
inline errno_t LStrCat(PWSTR dest, size_t destlen, PCWSTR endStr, int catlen)
{
return _tcsncat_s(dest, destlen, endStr, catlen);
}
//将字符串endStr拼接到dest上
//param:
// dest:目标缓存指针
// destlen:目标缓存大小
// endStr:拼接的字符串
inline errno_t TStrCat(PSTR dest, size_t destlen, PCSTR endStr)
{
return strcat_s(dest, destlen, endStr);
}
//宽字符串比较函数
//param
// str1:比较字符串1
// str2:比较字符串2
inline int TStrCmp(PWSTR str1, PWSTR str2)
{
return _tcscmp(str1, str2);
}
//宽字符串比较函数
//param
// str1:比较字符串1
// str2:比较字符串2
// cmplen:比较的长度
inline int TStrCmp(PWSTR str1, PWSTR str2, size_t cmplen)
{
return _tcsncmp(str1, str2, cmplen);
}
//宽字符查找函数(从左往右找)
//param
// opStr:查找字符串
// c:目标字符
inline PWSTR TStrChr(PWSTR opStr, WCHAR c)
{
return wcschr(opStr, c);
}
//字符查找函数(从左往右找)
//param
// opStr:查找字符串
// c:目标字符
inline PCSTR TStrChr(PCSTR opStr, CHAR c)
{
return strchr(opStr, c);
}
//宽字符查找函数(从右往左找)
//param
// opStr:查找字符串
// c:目标字符
inline PWSTR TStrRChr(PWSTR opStr, WCHAR c)
{
return wcsrchr(opStr, c);
}
//字符查找函数(从右往左找)
//param
// opStr:查找字符串
// c:目标字符
inline PCSTR TStrRChr(PCSTR opStr, CHAR c)
{
return strrchr(opStr, c);
}
字符串类型转换
Windows提供了API用以ASCII和Unicode之间的转化。
/*
* 将多字节字符串转换为宽字符串
* @param
* uCodePage:标识一个与多字节字符串相关的代码页号。一般设定为CP_ACP
* dwFlags:设定另一个控件,它可以用重音符号之类的区分标记来影响字符
* pMultiByteStr:要转换的多字节字符串
* cchMultiByte:转换字符串的长度。如果传递-1,则该函数用于确定源字符串的长度
* pWideCharStr:指向转换后获得的字符串缓存
* cchWideChar:缓存的最大值
*/
int MultiByteToWideChar(
UINT uCodePage,
DWORD dwFlags,
PCSTR pMultiByteStr,
int cchMultiByte,
PWSTR pWideCharStr,
int cchWideChar
);
/*
* 将宽字符串转换为多字节字符串
* @param
* uCodePage:标识一个与多字节字符串相关的代码页号。一般设定为CP_ACP
* dwFlags:设定另一个控件,它可以用重音符号之类的区分标记来影响字符.一般设为0
* pWideCharStr:要转换的款宽字符串
* cchMultiByte:转换字符串的长度。如果传递-1,则该函数用于确定源字符串的长度
* pWideCharStr:指向转换后获得的字符串缓存
* cchWideChar:缓存的最大值
* pDefaultChar:当一个字符转换失败时的默认替代字符
* pfUsedDefaultChar:本次操作是否存在为转换成功而用了默认字符的情况。有为TRUE,无为FALSE
*/
int MultiByteToWideChar(
UINT uCodePage,
DWORD dwFlags,
PCWSTR pWideCharStr,
int cchMultiByte,
PSTR pMultiByteStr,
int cchWideChar,
PCSTR pDefaultChar,
PBOOL pfUsedDefaultChar
)
关于这两个函数如何使用,我在TEString.h实现了ASCII和Unicode字符串。
//ASCII(char)字符串转Unicode
inline void TAsciiToUnicode(PCSTR source, PSTR dest, int destBufferSize)
{
size_t size = MultiByteToWideChar(CP_ACP, 0, source, -1, NULL, 0);
size = size > destBufferSize ? destBufferSize : size;
ULONGLONG len = sizeof(WCHAR) * size;
MultiByteToWideChar(CP_ACP, 0, (LPCCH)source, -1, (LPWSTR)dest, len);
dest[size + 1] = '\0';
}
//Unicode字符串转ASCII(char)
inline void TUnicodeToAscii(PCWSTR source, PSTR dest, int destBufferSize)
{
size_t size = WideCharToMultiByte(CP_ACP, NULL, source, -1, NULL, 0, NULL, FALSE);
size = size > destBufferSize ? destBufferSize : size;
WideCharToMultiByte(CP_ACP, NULL, (LPCWCH)source, -1, (LPSTR)dest, size, NULL, FALSE);
}
这样,我们得到了一些简单的字符串操作函数合集。这些函数对于文件系统来说足够使用了。
Part1:操作文件名和文件路径
文件名和文件路径构成了文件的一个标识。对于文件路径,我们想要获取的属性主要有:
| 重要熟悉 | 描述 | 用例 |
|---|---|---|
| 文件拓展名 | 路径字符串从右往左第一个'.'之后的字符串 | C:/log.txt 的拓展名是txt |
| 文件名(含拓展名) | 路径字符串从右往左第一个'/'或'\'之后的字符串 | C:/log.txt 的文件名是log.txt |
| 文件名(不含拓展名) | 路径字符串从右往左第一个'/'或'\'之后和第一个'.'之前的字符串 | C:/log.txt 的文件名是log |
| 文件所在的根盘符 | 路径字符串从左往右第一个"😕"或":\"之前的字符串 | C:/log.txt 的文件名是C:/ |
| 文件所在文件夹 | 路径字符串从右往左第一个'/'或'\'之前的字符串 | C:/Folder/log.txt 的文件夹名是C:/Folder/ |
在上述的表格中,通过对属性特征的描述,当我们得到一个文件路径的时候,我们便可以根据属性特征,利用字符串的操作函数来获取相应的属性。在路径解析函数集合中,我们主要利用的字符串函数如下:
- 使用的字符串操作函数列表
- TStrRChr:从右往左查找字符
- TStrCpy:字符串拷贝
- TStrCat:字符串拼接
//路径类
class TURBO_CORE_API TPath
{
public:
//修改文件拓展名(不做长度验证)
static bool ChangeExtension(PWSTR result, size_t resBufferLen, PWSTR path, PCWSTR extension);
//将传入字符串合成一个路径
static void Combine(PWSTR result, size_t resBufferLen, int combineCount, ...);
//获取目录名。
//若是个文件目录,则返回文件所在文件夹;
//若是文件夹目录,则返回上一级文件夹的路径
static bool GetDirectoryName(PWSTR result, size_t resBufferLen, PWSTR path);
//获取拓展名
static bool GetExtensionName(PWSTR result, size_t resBufferLen, PWSTR path);
//获取带拓展名的文件名
static bool GetFileName(PWSTR result, size_t resBufferLen, PWSTR path);
//获取不带拓展名的文件名
static bool GetFileNameWithoutExtension(PWSTR result, size_t resBufferLen, PWSTR path);
//获取根盘符
static bool GetPathRoot(PWSTR result, size_t resBufferLen, PWSTR path);
//路径是否包含文件拓展名
static bool HasExtension(PWSTR path);
//路径是否包含根盘符
static bool HasVolume(PWSTR path);
public:
inline static WCHAR DirectorySeparatorChar() { return ms_DirectorySeparatorChar;}
inline static WCHAR AltDirectorySeparatorChar() { return ms_AltDirectorySeparatorChar; }
inline static WCHAR VolumeSeparatorChar() { return ms_VolumeSeparatorChar; }
inline static WCHAR PathSeparatorChar() { return ms_PathSeparatorChar; }
inline static WCHAR ExtensionPrefixChar() { return ms_ExtensionPrefixChar; }
protected:
//获取路径最后一个目录分隔符的位置
static PWSTR GetLastDirSeparator(PWSTR path);
//获取路径第一个目录分隔符的位置
static PWSTR GetFirstDirSeparator(PWSTR path);
static const WCHAR ms_DirectorySeparatorChar; //常规的目录分隔符
static const WCHAR ms_AltDirectorySeparatorChar; //得到替换的目录分隔符(和常规的等价)
static const WCHAR ms_VolumeSeparatorChar; //Windows卷的分隔符
static const WCHAR ms_PathSeparatorChar; //路径分隔符
static const WCHAR ms_ExtensionPrefixChar; //文件拓展名前缀
};
const WCHAR TurboEngine::Core::TPath::ms_DirectorySeparatorChar = '\\';
const WCHAR TurboEngine::Core::TPath::ms_AltDirectorySeparatorChar = '/';
const WCHAR TurboEngine::Core::TPath::ms_VolumeSeparatorChar = ':';
const WCHAR TurboEngine::Core::TPath::ms_PathSeparatorChar = ';';
const WCHAR TurboEngine::Core::TPath::ms_ExtensionPrefixChar = '.';
Part2:单个文件的读写
C语言可以采用文件IO流的方式对于文件的读写。如何理解文件流呢?下面根据我自己的理解画了一张图(仅供参考)。
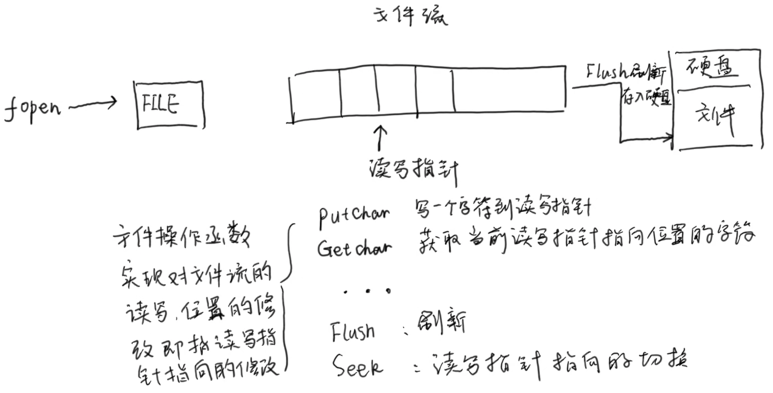
文件I/O流需要关注那些属性呢?我自己总结了一下几点:
- 文件使用字符集:ASCII或Unicode
- 读写权限:是否读、是否可写、若不存在文件是否可创建、文件打开写入时是否是追加模式等
- 文本存储格式:基于文本或基于二进制- 文件大小
在引擎中,我们将单个文件的读写方式全部封装在TFile这一个类中。并利用Open()函数传入路径并打开相应的文件。在Open中,我们调用了fopen_s()。函数的解释如下:
/*
* C语言函数,打开一个文件
* pFile:返回的打开文件的句柄
* filename:文件名(文件路径)
* mode:文件存储格式和文件读写权限的模式说明
*/
errno_t fopen_s( FILE** pFile, const char *filename, const char *mode );
//宽字符版本
errno_t _wfopen_s( FILE** pFile, const wchar_t *filename, const wchar_t *mode );
文件打开的模式
下面我讲重点介绍mode这个参数。mode 的类型是一个char字符串。对于mode字符串的解析,可参考如下表格:
- mode之读写权限
| 符号 | 意义 |
|---|---|
| r | 以只读的方式打开,文件必须存在 |
| r+ | 以可读写的方式打开,文件必须存在 |
| w | 打开只写文件。若文件存在则文件长度清0。若不存在则创建新文件 |
| w+ | 打开可读写文件,若文件存在则文件长度清0。若不存在则创建新文件 |
| a | 以附加的方式打开只写文件。若文件存在写入时追加在文件末尾。若不存在则创建新文件 |
| a+ | 以附加的方式打开可读写文件。若文件存在写入时追加在文件末尾。若不存在则创建新文件 |
- mode之文件存储格式
| 符号 | 意义 |
|---|---|
| t | 文件以文本存储 |
| b | 文件以二进制存储 |
基于此:我们可以将这两部分进行1对1的组合。例如:基于二进制的只读文件(文件必须存在),其 mode="rb"。再比如,基于文本的可读写文件,新打开会请空内容(文件不存在则创建),其 mode="w+t"
在引擎中。我利用模板实现了ASCII和Unicode两个版本的Mode生产函数。实现代码如下所示:
//相关字符
const WCHAR TurboEngine::Core::TFile::ms_ReadChar = 'r';
const WCHAR TurboEngine::Core::TFile::ms_WriteChar = 'w';
const WCHAR TurboEngine::Core::TFile::ms_AppendChar = 'a';
const WCHAR TurboEngine::Core::TFile::ms_PlusChar = '+';
const WCHAR TurboEngine::Core::TFile::ms_TextModeChar = 't';
const WCHAR TurboEngine::Core::TFile::ms_BinaryModeChar = 'b';
template<typename T>
inline void TFile::GetModeTag(T mode[4], FileMode fileMode, FileAccess fileAccess)
{
unsigned int index = 0;
switch (fileAccess)
{
case FileAccess::OnlyRead_NotCreate: mode[index++] = ms_ReadChar; break;
case FileAccess::ReadWrite_NotCreate: mode[index++] = ms_ReadChar; mode[index++] = ms_PlusChar; break;
case FileAccess::OnlyWrite_CreateAndClean: mode[index++] = ms_WriteChar; break;
case FileAccess::ReadWrite_CreateAndClean: mode[index++] = ms_WriteChar; mode[index++] = ms_PlusChar; break;
case FileAccess::OnlyAppendWrite_Create: mode[index++] = ms_AppendChar; break;
case FileAccess::AppendReadWrite_Create: mode[index++] = ms_AppendChar; mode[index++] = ms_PlusChar; break;
}
switch (fileMode)
{
case FileMode::Text: mode[index++] = ms_TextModeChar; break;
case FileMode::Binary: mode[index++] = ms_BinaryModeChar; break;
}
mode[index] = '\0';
}
//用例:
//ASCII版
CHAR mode[4];
GetModeTag<CHAR>(mode,FileMode::Text,FileAccess::OnlyRead_NotCreate);
TFile的定义
//文件类
class TURBO_CORE_API TFile
{
public:
//字符类型
enum class CharType
{
SingleByte, //单字节字符
DoubleByte //双字节字符
};
//文件存储格式
enum class FileMode
{
Text, //文本格式
Binary, //二进制格式
};
//文件读写权限
enum class FileAccess
{
OnlyRead_NotCreate, //(r) 只读模式。文件必须存在。
ReadWrite_NotCreate, //(r+) 读写模式。文件必须存在。文件打开后内容会清零。
OnlyWrite_CreateAndClean, //(w) 只写模式。文件打开后内容会清零。无文件则创建新的文件。
ReadWrite_CreateAndClean, //(w+) 读写模式。无文件则创建新的文件。打开后内容会清零。
OnlyAppendWrite_Create, //(a) 只写于尾。无文件则创建新的文件。
AppendReadWrite_Create, //(a+) 读写于尾。无文件则创建新的文件。
};
//文件流所在的位置
enum class StreamPos : int
{
Begin = SEEK_SET, //文件起始的位置
Current = SEEK_CUR, //当前流的位置
End = SEEK_END //文件末尾的位置
};
public:
TFile();
~TFile();
//打开或创建文件(宽字符版)
bool Open(PCWSTR filePath, FileMode fileMode, FileAccess fileAccess);
//打开或创建文件
bool Open(PCSTR filePath, FileMode fileMode, FileAccess fileAccess);
//按照临时文件打开
bool OpenAsTempFile();
//关闭文件
bool Close();
//刷新文件流,将文件写入磁盘中
bool Flush();
//输入一个字符到文件流中(宽字符版)
bool PutChar(WCHAR wc, StreamPos basePos = StreamPos::End, long offset = 0);
//输入一个字符到文件流中
bool PutChar(CHAR wc, StreamPos basePos = StreamPos::End, long offset = 0);
//从文件流中获取一个字符(宽字符版)
bool GetChar(WCHAR& result, StreamPos basePos = StreamPos::Current, long offset = 0);
//从文件流中获取一个字符
bool GetChar(CHAR& result, StreamPos basePos = StreamPos::Current, long offset = 0);
//输入一个字符串到文件流中(宽字符版)
bool PutStringtLine(PCWSTR str, StreamPos basePos = StreamPos::End, long offset = 0);
//输入一个字符串到文件流中
bool PutStringtLine(PCSTR str, StreamPos basePos = StreamPos::End, long offset = 0);
//从文件流中读取一行字符串(宽字符版)
bool GetStringLine(PWSTR result, int resBufferSize, StreamPos basePos = StreamPos::Current, long offset = 0);
//从文件流中读取一行字符串
bool GetStringLine(PSTR result, int resBufferSize, StreamPos basePos = StreamPos::Current, long offset = 0);
//格式化输入字符串到文件流中(宽字符版)
template<typename ...Args>
bool PutStringFormatInEnd(PCWSTR format, Args... args);
//格式化输入字符串到文件流中
template<typename ...Args>
bool PutStringFormatInEnd(PCSTR format, Args... args);
//写入二进制块(仅适用于基于二进制存储的文件)
bool WriteBinaryBlock(void* mem, size_t blockSize, size_t blockNum);
//读取二进制块(仅适用于基于二进制存储的文件)
bool ReadBinaryBlock(void* result, size_t blockSize, size_t blockNum);
//上次文件流是否是在文件尾部
bool IsPrevStreamInPosInEnd();
//将文件流读取指针指向流的起始端
void BackToStreamBegin();
//文件流跳转位置
bool SeekStreamPos(StreamPos basePos, long offset);
//获取文件流操作最后的错误代码
int GetLastErrorState();
//清除错误代码
void ClearError();
//删除文件(宽字符版)
bool Delete(PCWSTR filePath);
//删除文件
bool Delete(PCSTR filePath);
//获取文件大小
long FileSize();
public:
inline CharType GetCharType() { return m_CharType; }
inline FileMode GetFileMode() { return m_FileMode; }
inline FileAccess GetFileAccess() { return m_FileAccess; }
inline bool IsTempFile() { return m_IsTempFile; }
protected:
template<typename T>
void GetModeTag(T mode[4], FileMode fileMode, FileAccess fileAccess);
static const WCHAR ms_ReadChar;
static const WCHAR ms_WriteChar;
static const WCHAR ms_AppendChar;
static const WCHAR ms_PlusChar;
static const WCHAR ms_TextModeChar;
static const WCHAR ms_BinaryModeChar;
private:
CharType m_CharType;
FileMode m_FileMode;
FileAccess m_FileAccess;
FILE* m_pFile;
LONG m_Offset;
bool m_IsTempFile;
};
Part3:异步文件I/O
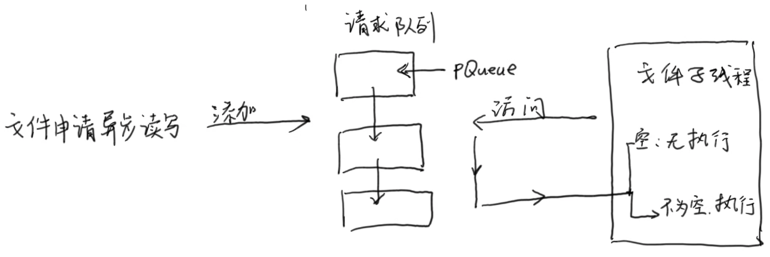
异步文件I/O的实现思路如下:
- 文件系统在第一次使用异步方法时,会开启一个I/O线程。此线程会查询一个队列。队列中即为I/O请求。
- 主线程调用文件系统的异步函数时,会向队列添加读或写的请求,以供子线程执行。
- 请求队列可以使用侵入式单链表的数据结构来实现
- 因为是多线程操作,因此需要注意公有变量的修改同步问题。因为复杂度不是很高,为了效率,可以使用关键段的同步方式。
异步I/O线程
enum class RequestType
{
Read,
ReadAll,
Write,
};
//异步文件IO请求()
typedef struct AyncFileIORequest
{
RequestType m_RequestType;
PTFile m_FileHandle;
void* m_RWBuffer;
size_t m_BufferSize;
AsyncFileIOCompleted m_CompletedFunc;
AyncFileIORequest* m_NextRequest;
SyncTrigger m_IsCompletedTrigger;
AyncFileIORequest()
: m_RequestType(RequestType::Read),
m_FileHandle(nullptr),
m_RWBuffer(nullptr),
m_BufferSize(0),
m_CompletedFunc(nullptr),
m_NextRequest(nullptr),
m_IsCompletedTrigger(true, false) {}
}* PAyncFileIORequest;
//关键函数的实现
//-------------------------------------------------------------------------------
//添加I/O请求
HANDLE AddRequest(RequestType rt, PTFile fileHandle, void* Buffer, size_t bufferSize, AsyncFileIOCompleted completedFunc)
{
PAyncFileIORequest pRequest = TNew AyncFileIORequest();
pRequest->m_RequestType = rt;
pRequest->m_FileHandle = fileHandle;
pRequest->m_RWBuffer = buffer;
pRequest->m_BufferSize = bufferSize;
pRequest->m_CompletedFunc = completedFunc;
pRequest->m_NextRequest = nullptr;
m_QueueLock.Lock();
if (m_Queue == nullptr)
m_Queue = pRequest;
else
{
PAyncFileIORequest pTemp = m_Queue;
while (pTemp->m_NextRequest)
pTemp = pTemp->m_NextRequest;
pTemp->m_NextRequest = pRequest;
}
m_QueueLock.Unlock();
return pRequest->m_IsCompletedTrigger.GetHandle();
}
//线程中的主执行函数
DWORD __stdcall TurboEngine::Core::TAsyncFileIOThread::Run()
{
PAyncFileIORequest pRequest = nullptr;
while (!m_TerminateThreadTrigger.IsTrigger())
{
pRequest = nullptr;
if (m_QueueLock.TryLock())
{
if (m_Queue != nullptr)
{
pRequest = m_Queue;
m_Queue = m_Queue->m_NextRequest;
}
m_QueueLock.Unlock();
}
//若pRequst不为空,则表示队列中有未执行的请求
if (pRequest != nullptr)
{
switch (pRequest->m_RequestType)
{
case RequestType::Read:
pRequest->m_FileHandle->Read(
pRequest->m_RWBuffer,
1,
pRequest->m_BufferSize
);
break;
case RequestType::ReadAll:
pRequest->m_FileHandle->ReadAll(
pRequest->m_RWBuffer,
pRequest->m_BufferSize
);
break;
case RequestType::Write:
pRequest->m_FileHandle->Write(
pRequest->m_RWBuffer,
1,
pRequest->m_BufferSize
);
break;
}
if (pRequest->m_CompletedFunc != nullptr)
(*(pRequest->m_CompletedFunc))(pRequest);
pRequest->m_IsCompletedTrigger.SetActive();
TDelete pRequest;
}
pRequest = nullptr;
}
return 0;
}
文件类中的异步方法
HANDLE TurboEngine::Core::TFile::ReadAsync(void* mem, size_t blockSize, size_t blockNum, AsyncFileIOCompleted completedFunc)
{
return AsyncIOHandle().AddRequest(
RequestType::Read,
this,
mem,
blockSize * blockNum,
completedFunc
);
}
HANDLE TurboEngine::Core::TFile::WriteAsync(void* result, size_t blockSize, size_t blockNum, AsyncFileIOCompleted completedFunc)
{
return AsyncIOHandle().AddRequest(
RequestType::Write,
this,
result,
blockSize * blockNum,
completedFunc
);
}
HANDLE TurboEngine::Core::TFile::ReadAllAsync(void* result, size_t resBufferLen, AsyncFileIOCompleted completedFunc)
{
return AsyncIOHandle().AddRequest(
RequestType::ReadAll,
this,
result,
resBufferLen,
completedFunc
);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号