一看就懂的:MySQL数据页以及页分裂机制
文章公号 首发!连载中~ 欢迎各位大佬关注, 回复:“抽奖” 还可参加抽📖活动
文末有二维码
一、知识回顾#
回顾一下之前和大家分享的知识点
看了前面的文章,想必你肯定了解了什么是Buffer Pool、LRU-List、Free-List、Flush-List,你也知道了当MySQL增删改查时,内存中发生了什么,以及这几个双向链表是如何配合工作的。
通过阅读上一篇文章你也一定了解了:你create出来的table其实是属于一个表空间的,而所谓的表空间其实对应着一个真实存在于物理磁盘上的文件。
并且在前面的文章中,白日梦曾不止一次的提及到:InnoDB从磁盘中读取数据的最小单位是数据页。而你想得到的id = xxx的数据,就是这个数据页众多行中的一行。
下面我们就一起看下,究竟什么是MySQL的数据页、数据区等概念。
二、数据页长啥样?#
数据页长下面这样:

三、什么是数据区?#
在MySQL的设定中,同一个表空间内的一组连续的数据页为一个extent(区),默认区的大小为1MB,页的大小为16KB。16*64=1024,也就是说一个区里面会有64个连续的数据页。连续的256个数据区为一组数据区。
于是我们可以画出这张图:
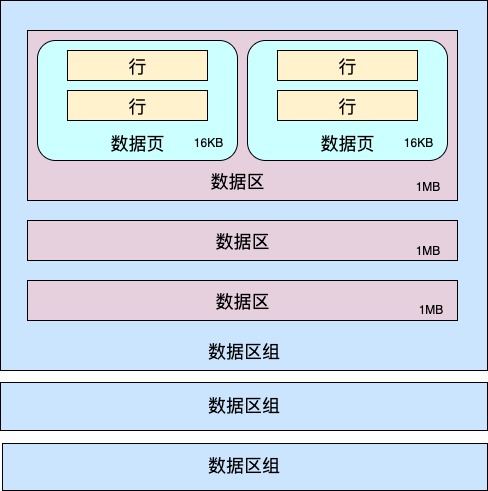
从直观上看,其实不用纳闷为啥MySQL按照这样的方式组织存储在磁盘上的数据。
这就好比你搞了个Java的封装类描述一类东西,然后再相应的给它加上一些功能方法,或者用golang封装struct去描述一类对象。最终的目的都是为了方便、管理、控制。
约定好了数据的组织方式,那MySQL的作用不就是:按照约定数据规则将数据文件中的数据加载进内存,然后展示给用户看,以及提供其他能力吗?
四、数据页分裂问题#
假设你现在已经有两个数据页了。并且你正在往第二个数据页中写数据。
关于B+Tree,你肯定知道B+Tree中的叶子结点之间是通过双向链表关联起来的。
在InnoDB索引的设定中,要求主键索引是递增的,这样在构建索引树的时候才更加方便。你可以脑补一下。如果按1、2、3...递增的顺序给你这些数。是不是很方便的构建一棵树。然后你可以自由自在的在这棵树上玩二分查找。
那假设你自定义了主键索引,而且你自定义的这个主键索引并不一定是自增的。
那就有可能出现下面这种情况 如下图:
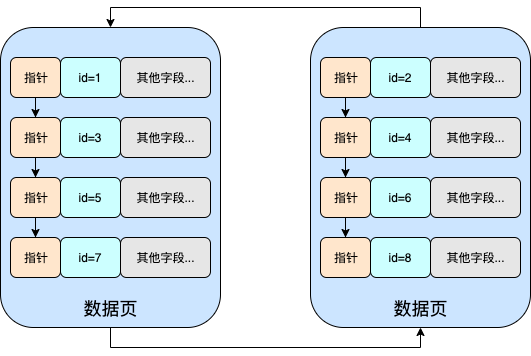
假设上图中的id就是你自定义的不会自增的主键
然后随着你将数据写入。就导致后一个数据页中的所有行并不一定比前一个数据页中的行的id大。
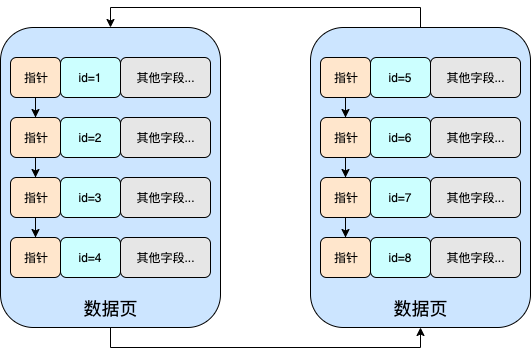
这时就会触发页分裂的逻辑。
页分裂的目的就是保证:后一个数据页中的所有行主键值比前一个数据页中主键值大。
经过分裂调整,可以得到下面的这张图。
参考:
https://dev.mysql.com/doc/refman/5.7/en/glossary.html
推荐阅读#

- 大家常说的基数是什么?(已发布)
- 讲讲什么是慢查!如何监控?如何排查?(已发布)
- 对NotNull字段插入Null值有啥现象?(已发布)
- 能谈谈 date、datetime、time、timestamp、year的区别吗?(已发布)
- 了解数据库的查询缓存和BufferPool吗?谈谈看!(已发布)
- 你知道数据库缓冲池中的LRU-List吗?(已发布)
- 谈谈数据库缓冲池中的Free-List?(已发布)
- 谈谈数据库缓冲池中的Flush-List?(已发布)
- 了解脏页刷回磁盘的时机吗?(已发布)
- 用十一张图讲清楚,当你CRUD时BufferPool中发生了什么!以及BufferPool的优化!(已发布)
- 听说过表空间没?什么是表空间?什么是数据表?(已发布)
- 谈谈MySQL的:数据区、数据段、数据页、数据页究竟长什么样?了解数据页分裂吗?谈谈看!(已发布)
- 谈谈MySQL的行记录是什么?长啥样?(已发布)
- 了解MySQL的行溢出机制吗?(已发布)
- 说说fsync这个系统调用吧! (已发布)
- 简述undo log、truncate、以及undo log如何帮你回滚事物! (已发布)
- 我劝!这位年轻人不讲MVCC,耗子尾汁! (已发布)
- MySQL的崩溃恢复到底是怎么回事? (已发布)
- MySQL的binlog有啥用?谁写的?在哪里?怎么配置 (已发布)
- MySQL的bin log的写入机制 (已发布)
面试官都关注了!你还在犹豫什么呢?




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
2019-11-26 串烧 JavaCAS相关知识