Ghost-无损DDL
一、什么是DDL?#
DDL全称:Data Definition Language
它包含三个主要的关键字:create、drop、alter
| 操作 | statement |
|---|---|
| 创建数据库 | create database |
| 删除数据库 | drop database |
| 修改数据库 | alter database |
| 创建表 | create table |
| 删除表 | drop table |
| 修改表 | alter table |
| 创建索引 | create index |
| 删除索引 | drop index |
二、表级锁和元数据锁#
MySQL的表级锁有两种,一种是表锁,一种是元数据锁MDL
2.1、什么是表锁?#
表锁的语法: lock tables ... read/write
释放时机:通过unlock tables 主动释放,当客户端断开时也会自动释放。
例如:线程A执行: lock tables t1 read, t2 write; 那其他线程写t1和读写t2时都会被阻塞, 而且线程A在unlock tables 之前,也只能执行读t1,读写t2,它自己也不被允许写t1。
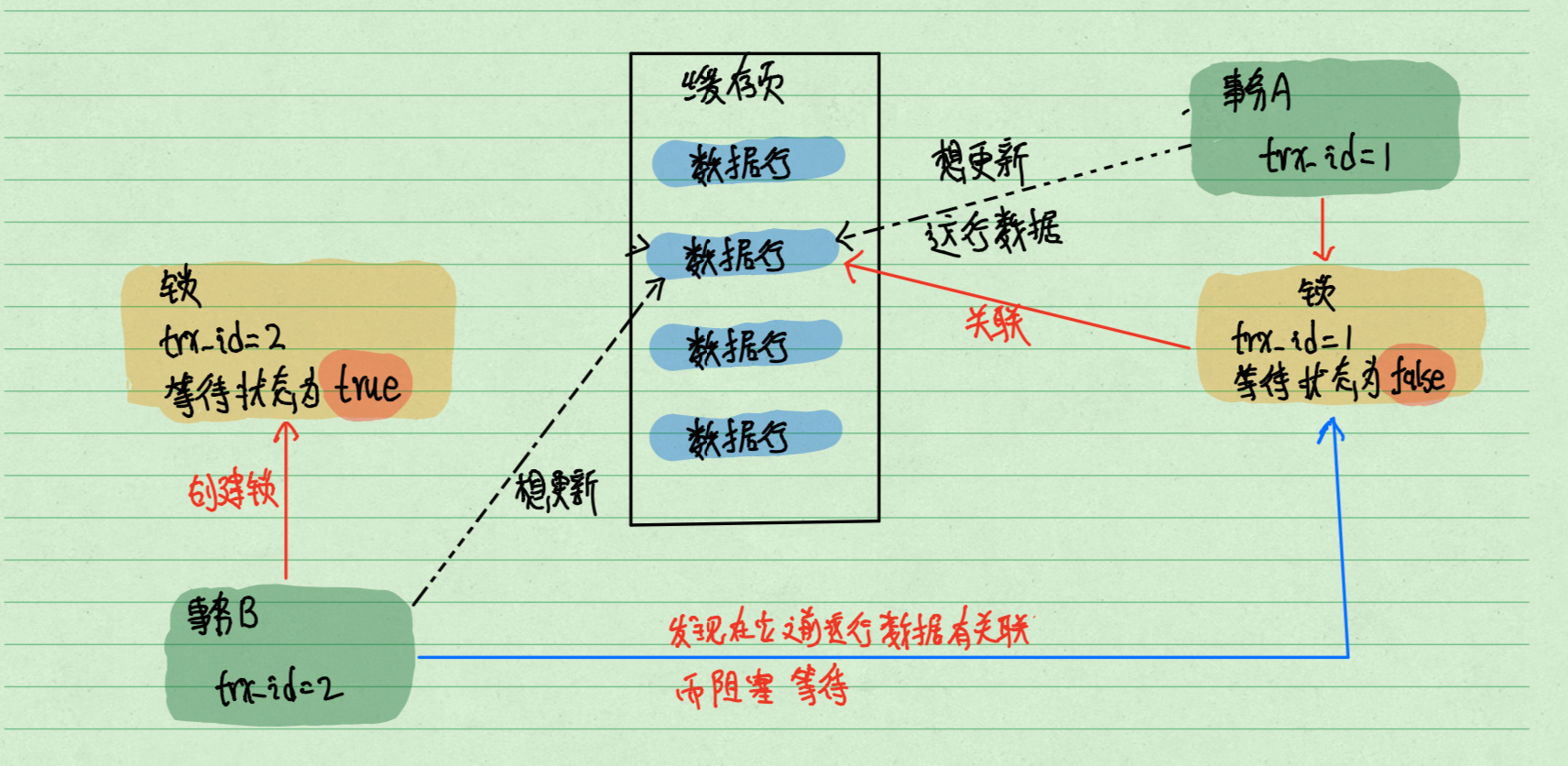
2.2、什么是MDL?#
元数据锁也是一种表级锁:metadata lock。
作用:
我们不需要显示的使用它,当访问一个表的时候,它会被自动加上。MDL锁的作用就是保证读写的正确性
说白了,就是实现:当有用户对表执行DML相关操作时,其他线程不能把表结构给改了(想改表结构也可以,等排在它前面的DML全部执行完)。反之,当有线程在更改表结构时,其他线程需要执行的DML也会被阻塞住。
特性:
1、系统默认添加。
2、读锁之间不互斥。
3、读写锁之间互斥。
三、什么是无损DDL?#
需求:
一般对公司对业务线来说,总是难免遇到需要修改线上表结构的需求。比如搞个活动,结果发现:现有的表中的列不够用了,那么就需要对现有的表进行无损DDL操作,添加一列。
有损DDL
为什么直接执行alter table add column有损?
如下图所示:你alter table时是需要获取元数据锁的写锁的,而所有的DML操作又会被默认的加上元数据读锁。如果所有的语句都是DML语句那皆大欢喜,大家都是读锁彼此不影响。
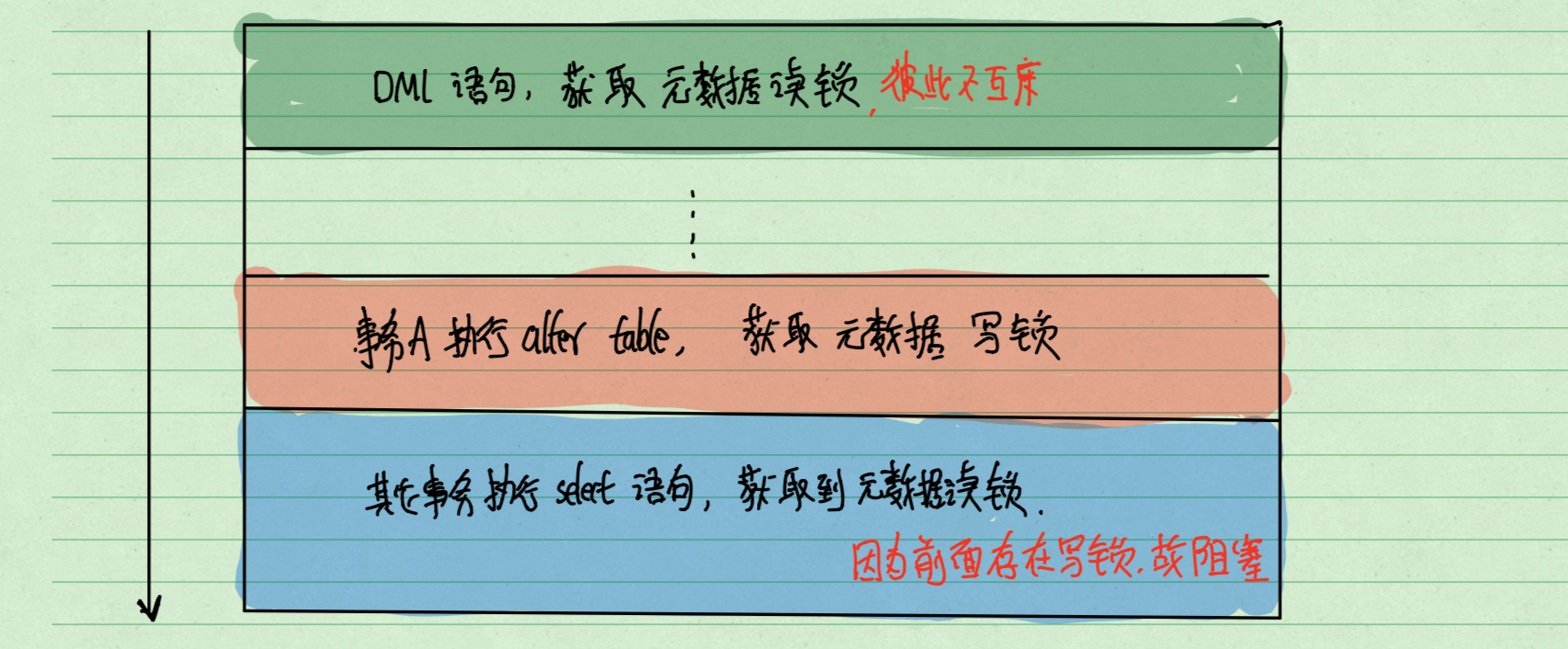
但是你看上图这突然整出来一个alter语句,一旦等他持有写锁后,去执行DDL语句时期间,所有的DML语句全部被阻塞,我们称这种情况对业务来说是有损的。
无损DDL
所谓的无损是相对于业务来说的,如果能做到执行DDL的过程中,对业务无影响,那我们称这种ddl是无损的。
至于如何无损的解决这个问题,接着看下文。
四、DDL重建表#
什么是重建表?为什么要重建表?
当我执行delete语句删除表A中的数据时,对应Innodb来说其实只是在标记删除,而是不实实在在的将表空间中的数据删除,对应innodb来将被标记删除的位置是可以可重复使用。
那么delete语句多了,表空间上的空洞就多了,磁盘的占用量也只增不减。这时我们就得重建表。缩小表A上的空洞。
重建表的方法:
方式1、可以新建一个新的表,然后将原表中的数据按照id生序一次拷贝过去。
方式2、也可以执行alter table A engine=InnoDB 来重建表。
这里的alter table 其实就是DDL语句
Mysql5.5之前重建表#
在5.5之前,mysql执行alter table A engine=InnoDB的流程如下图:

在上面的过程中,MySQL会自动的为我们创建临时表,拷贝数据,交换表名,以及删除旧表。
特点:
一、这个过程并不是安全的。因为在往tmp表中写数据的过程中,如果有业务流量写入表A,而且写入的位置是不久前完成往tmp中拷贝的位置,就会导致数据的丢失。
二、即使是MySQL会我们自动的创建临时表,数据拷贝的过程依然是在MySQL-Server层面做的。
Mysql5.6之后重建表#
重建表的过程如下图:
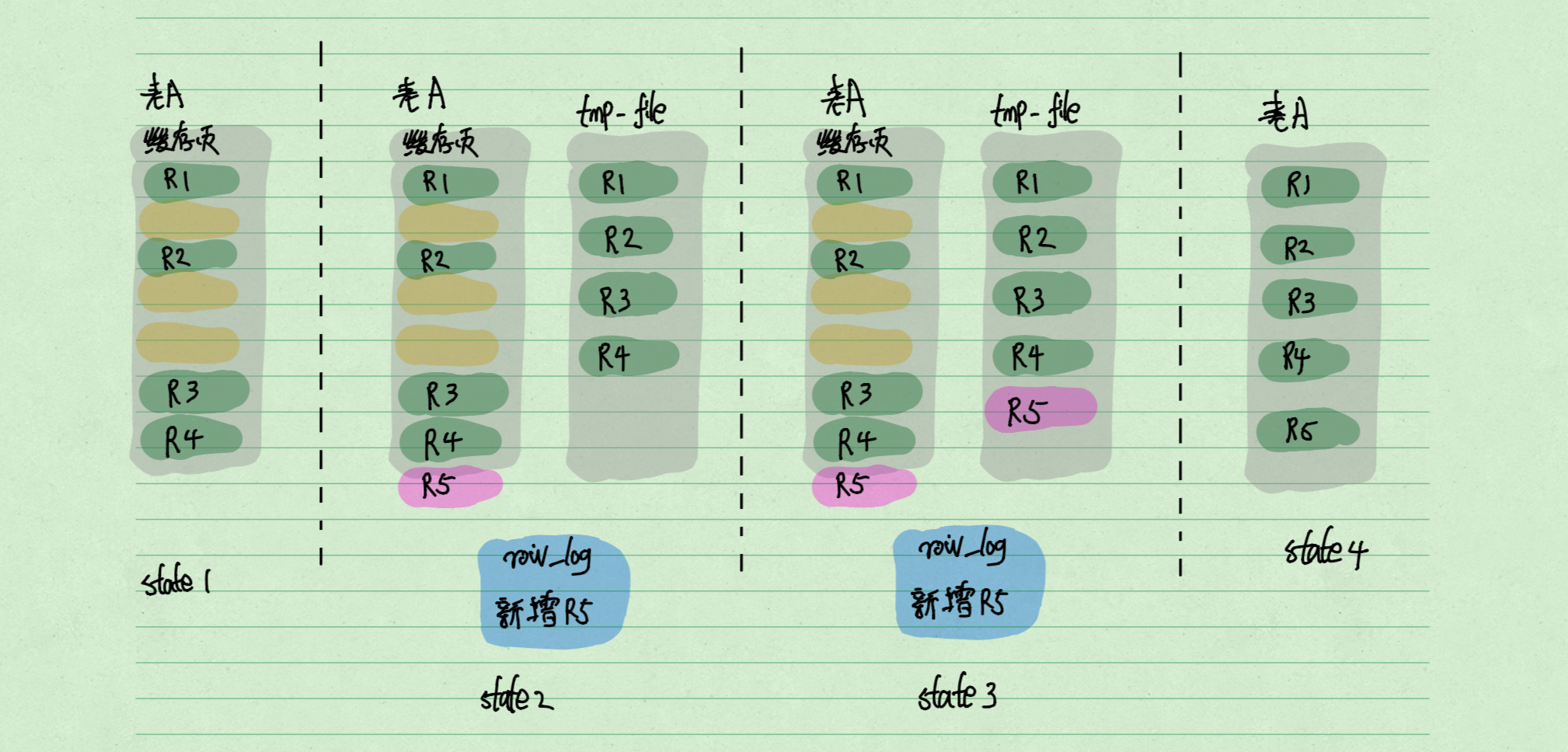
1、创建一个tmp_file, 扫描表A主键的所有数据页。
2、使用数据页中的记录生成B+树,存储进tmp_file中。
这一步是对针对数据文件的操作。由innodb直接完成。
3、在生成转存B+数的过程中,将针对A的写操作记录在row_log日志中。
4、完成了B+树的转存后,将row_log中记录的日志在tmp_file中回放。
5、使用临时文件替换A中的数据文件。
可以看到,这个过程其实已经实现无损了。因为在做数据迁移的过程中,允许对原表进行CRUD
局限性:
这种DDL本质上是在替换表空间中的数据文件,仅仅是用于对原表进行无损DDL瘦身。而不是解决我们开题所说的动态无损加列的情况。
五、ghost工具源码梳理#
5.1、工作模式#
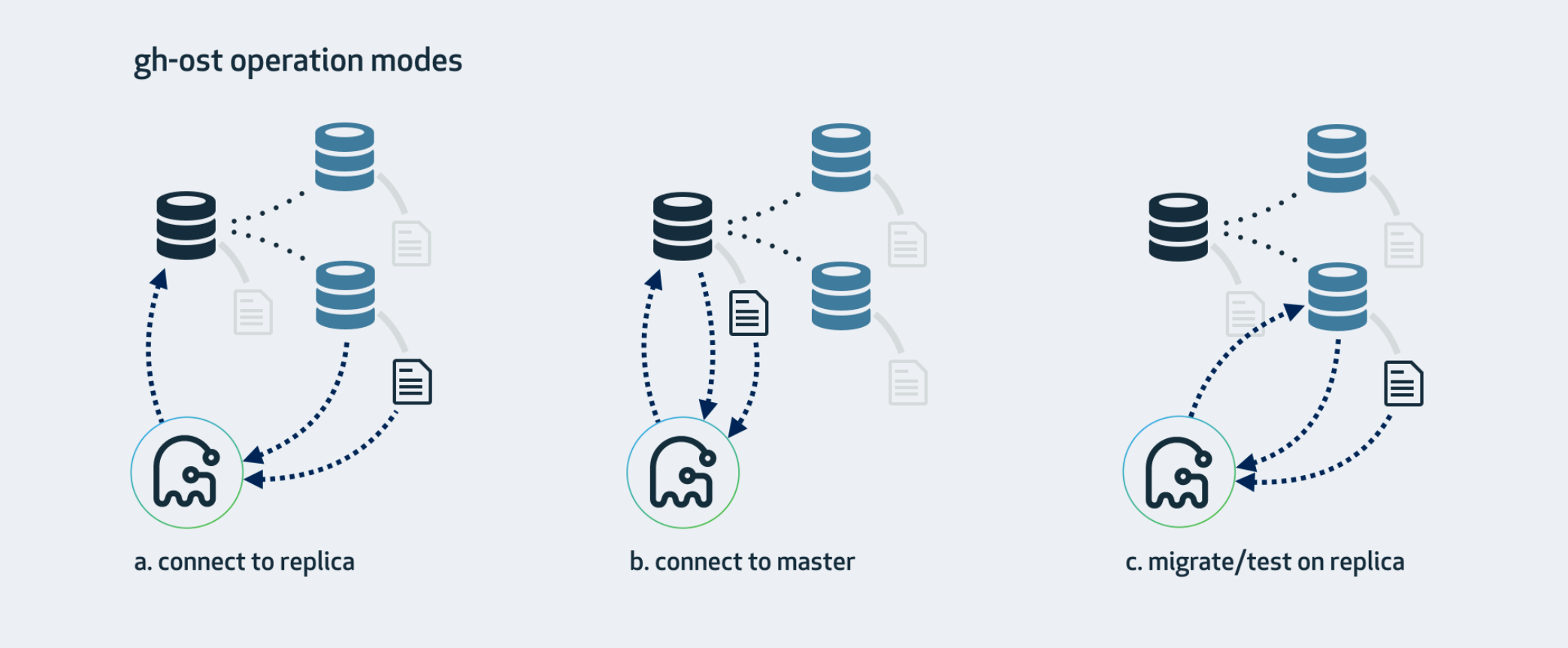
5.1.1 主从模式a
ghost会连接上主库
从主库中读取数据rowCopy主库上的影子表中。
添加对从库binlog的监听。将binlog-event转换成sql应用在主库上的影子表上。
因为ghost会去解析binlog,所以要求从库的binlog格式必须上row格式。不对主库的binlog格式有要求。
cutOver在主库上完成。
5.1.2 主主模式b
ghost会连接上主库
从主库中读取数据rowCopy主库上的影子表中。
添加对主库binlog的监听。将binlog-event转换成sql应用在主库上的影子表上。
要求主库的binlog格式为row格式。
cutOver在主库上完成。
5.1.3 migrate/test on relica
一般这中情况是在做预检查时完成才使用到的,ghost的任何操作都在从库上完成,主要是验证整个流程是否可以跑通,相关参数:-test-on-replica
上面所说的主主、主从、并不是MySQL实例的主从关系。说的是 rowCopy和binlog的同步是在谁身上进行。
5.1、前置性检查#
这一步主要是去检查从库的基础信息。比如执行table row count、schema validation、hearbeat 但是当我们有提供 --allow-on-master时,inspector指的是主库。
- 校验alter语句,允许重命名列名,但是不允许重命名表名
validateStatement()
- 测试DB的连通性: 实现的思路是使用根据用户输入的数据库连接信息获取到和主/从库的连接,然后使用db.QueryRow(sqlStr)执行指定的SQL,观察获取到的结果是否符合预期。
versionQuery := `select @@global.version`
err := db.QueryRow(versionQuery).Scan(&version);
extraPortQuery := `select @@global.extra_port`
db.QueryRow(extraPortQuery).Scan(&extraPort);
portQuery := `select @@global.port`
db.QueryRow(portQuery).Scan(&port);
- 权限校验,确保用户给定sql对相应的库表有足够的操作权限:思路获取db连接,执行如下的sql;将可能的情况枚举出来,和sql返回的语句比对
`show /* gh-ost */ grants for current_user()`
在控制台执行sql的shili
mysql> show grants for current_user();
+-------------------------------------------------------------+
| Grants for root@% |
+-------------------------------------------------------------+
| GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION |
+-------------------------------------------------------------+
1 row in set (0.01 sec)
err := sqlutils.QueryRowsMap(this.db, query, func(rowMap sqlutils.RowMap) error {
for _, grantData := range rowMap {
grant := grantData.String
if strings.Contains(grant, `GRANT ALL PRIVILEGES ON *.*`) {
foundAll = true
}
if strings.Contains(grant, `SUPER`) && strings.Contains(grant, ` ON *.*`) {
foundSuper = true
}
...
if foundAll {
log.Infof("User has ALL privileges")
return nil
}
- 校验binlog的格式:
实现的思路同样是执行下面的sql,查看bin-log是否是row格式。以及binlog_row_image是否是FULL格式。
从库强制要求:binlog为 ROW模式,还要开启log_slave_updates(告诉从服务器将其SQL线程执行的更新记入到从服务器自己的binlog中)。
为什么会这么要求binlog为row格式?
rowlevel的日志内容会非常清楚的记录下每一行数据修改的细节,而ghost有专门的go协程专门负责解析binlog同步增量数据。
相关参数:
--switch-to-rbr 作用:让gh-ost自动将从库的binlog_format转换为ROW格式。(ghost不会将格式还原回之前的状态)
--assume-rbr 作用: 如果你确定从库的bin-log格式就是row格式。可以使用这个参数,他可以保证禁止从库上运行stop slave,start slave
query := `select @@global.log_bin, @@global.binlog_format`
this.db.QueryRow(query).Scan(&hasBinaryLogs, &this.migrationContext.OriginalBinlogFormat);
query = `select @@global.binlog_row_image`
this.db.QueryRow(query).Scan(&this.migrationContext.OriginalBinlogRowImage);
#正常从控制台执行命令得到的结果如下:
mysql> select @@global.log_bin, @@global.binlog_format;
+------------------+------------------------+
| @@global.log_bin | @@global.binlog_format |
+------------------+------------------------+
| 1 | ROW |
+------------------+------------------------+
1 row in set (0.01 sec)
mysql> select @@global.binlog_row_image;
+---------------------------+
| @@global.binlog_row_image |
+---------------------------+
| FULL |
+---------------------------+
1 row in set (0.00 sec)
解析一下检测的两参数,一个要求binlog为row格式(比如主主模式,就强制主库的binlog是row格式),另一个参数期望 binlog_row_image为full模式, 原因是因为row格式的binlog记录sql对这行数据的做了哪些修改,而full + row 格式的binlog记录了最最详细的信息,包含sql对哪个库、哪个表、以及这个表的第一列、第二列...的值是什么 + 现在这条SQL想把这个表中的字段更新成什么,因为增量数据是从binlog里面拷贝出来的,所以记录最全的binlog 关于binlog格式+binlog_row_image 可参考:https://www.cnblogs.com/gomysql/p/6155160.html
5.2、创建streamer监听binlog#
这一步同样是在 migrator.go的Migrate()的this.initiateInspector(); 函数中。
首先创建一个 eventsStreamer,因为他要求同步bin-log,所以为他初始化一个DB连接。
if err := this.eventsStreamer.InitDBConnections(); err != nil {
return err
}
// 细节:
// 获取连接数据库的url:
this.connectionConfig.GetDBUri(this.migrationContext.DatabaseName)
// root:root@tcp(127.0.0.1:3307)/lossless_ddl_test?interpolateParams=true&autocommit=true&charset=utf8mb4,utf8,latin1&tls=false
// 其中参数:interpolateParams=true用于防止sql注入攻击
// 其中参数:autocommit=true 表示每一条sql都当做一个事物自动提交,一般推荐这样做,如果不自动提交的话很容易出现长事物,系统也会因为这个长事物维护很大的readView占用存储空间。还可能长时间占用锁资源不释放,增加死锁的几率。
// 获取DB实例
mysql.GetDB(this.migrationContext.Uuid, EventsStreamerUri);
// 校验连接的可用性
base.ValidateConnection(this.db, this.connectionConfig, this.migrationContext);
-- 思路还是和5.1小节一致,使用db.QueryRow(versionQuery).Scan(&version); 执行sql,观察结果
-- `select @@global.version`
-- `select @@global.extra_port`
-- `select @@global.port`
//获取当前binlog的位点信息
//在ghost启动的时候会先获取mysql集群的bin-log状态,因为ghost的设计哲学是,现有的数据从原表select出来灌进影子表,在同步的过程中增量的数据通过解析重放binlog来实现,那获取集群中当前的bin-log信息自然也是master中读取:如下:
query := `show /* gh-ost readCurrentBinlogCoordinates */ master status`
foundMasterStatus := false
err := sqlutils.QueryRowsMap(this.db, query, func(m sqlutils.RowMap) error {
//正常从console中执行命令获取到的结果如下:
mysql> show master status;
+------------------+----------+--------------+------------------+---------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+---------------------------------------------+
| MySQL-bin.000007 | 194 | | | a89eec96-b882-11ea-ade2-0242ac110002:1-8844 |
+------------------+----------+--------------+------------------+---------------------------------------------+
//获取到当前binlog位点后,ghost会将自己伪装成一个replica连接上master,同步master的binlog
//具体的实现依赖第三方类库: "github.com/siddontang/go-mysql/replication"
//调用 *replication.BinlogSyncer 的如下方法同步bin-log
func (b *BinlogSyncer) StartSync(pos Position) (*BinlogStreamer, error) {
// 这是你可以尝试往主库写几条语句,然后flush log,ghost是能感知到的
[info] binlogsyncer.go:723 rotate to (MySQL-bin.000008, 4)
INFO rotate to next log from MySQL-bin.000008:6074 to MySQL-bin.000008
[info] binlogsyncer.go:723 rotate to (MySQL-bin.000008, 4)
INFO rotate to next log from MySQL-bin.000008:0 to MySQL-bin.000008
5.3、创建xxx_ghc表,xxx_gho表。#
// 创建applier
NewApplier(this.migrationContext)
// 初始化DB连接(和上面说过的步骤雷同)
this.applier.InitDBConnections();
// 根据配置判断是否删除ghost表。相关的配置参数:--initially-drop-old-table
// 所谓的ghost就是xxx_ghc表,xxx_gho表,一个是日志表,一个是影子表,他们是ghost创建的表
// 其中前者中存放ghost打印的日志,后者是未来替换现以后表的影子表。ghost在这里判断,如果mysql实例中已经存在这两个表,是不允许进行剩下的任务的,但是可以使用--initially-drop-old-table参数配置,ghost在启动的过程中碰到这个表就把他删除。(ghost任务他们都是残留表)
if this.migrationContext.InitiallyDropGhostTable {
if err := this.DropGhostTable(); err != nil {
return err
}
}
// 删除表的语句如下:
drop /* gh-ost */ table if exists `lossless_ddl_test`.`_user_gho`
drop /* gh-ost */ table if exists `lossless_ddl_test`.`_user_del`
// 创建日志表,建表语句如下
create /* gh-ost */ table `lossless_ddl_test`.`_user_ghc` (
id bigint auto_increment,
last_update timestamp not null DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
hint varchar(64) charset ascii not null,
value varchar(4096) charset ascii not null,
primary key(id),
unique key hint_uidx(hint)
) auto_increment=256
// 创建影子表,一开始创建的影子表其实就是原表。
create /* gh-ost */ table `lossless_ddl_test`.`_user_gho` like `lossless_ddl_test`.`user`
// 对影子表执行alter语句,alter语句不在原表上执行也就不会出现所谓的表级锁或者MDL写锁去阻塞业务方的sql
alter /* gh-ost */ table `lossless_ddl_test`.`_user_gho` add column newC6 varchar(24);
// 写心跳记录
insert /* gh-ost */ into `lossless_ddl_test`.`_user_ghc`
(id, hint, value)
values
(NULLIF(?, 0), ?, ?)
on duplicate key update
last_update=NOW(),
value=VALUES(value)
insert /* gh-ost */ into `lossless_ddl_test`.`_user_ghc`
(id, hint, value)
values
(NULLIF(?, 0), ?, ?)
on duplicate key update
last_update=NOW(),
value=VALUES(value)
// 这时可以去数据库中查看ghost
mysql> select * from _user_ghc;
+-----+---------------------+------------------------------+--------------------+
| id | last_update | hint | value |
+-----+---------------------+------------------------------+--------------------+
| 2 | 2020-07-25 19:55:11 | state | GhostTableMigrated |
| 256 | 2020-07-25 19:55:39 | state at 1595678112426190000 | GhostTableMigrated |
+-----+---------------------+------------------------------+--------------------+
// 接着获取slave的状态,主要是获到slave落后于master到秒数
// 获取到方法如下:通过show slave status查看从库的主从同步状态,其中的Slave_IO_Running和Slave_SQL_Running为YES说明主从同步正常工作,Seconds_Behind_Master为当前的从库中的数据落后于主库的秒数
err = sqlutils.QueryRowsMap(informationSchemaDb, `show slave status`,
func(m sqlutils.RowMap) error {
slaveIORunning := m.GetString("Slave_IO_Running")
slaveSQLRunning := m.GetString("Slave_SQL_Running")
secondsBehindMaster := m.GetNullInt64("Seconds_Behind_Master")
5.4 开始迁移数据#
在开始migration数据之前做一些检查工作
// 校验master和slave表结构是否相同,具体的实现会分别获取到他们的列的name然后比较
table structure is not identical between master and replica
// 获取到原表和ghost表唯一键的交集
sharedUniqueKeys, err := this.getSharedUniqueKeys(this.migrationContext.OriginalTableUniqueKeys, this.migrationContext.GhostTableUniqueKeys)
// 校验唯一键。
for i, sharedUniqueKey := range sharedUniqueKeys {
this.applyColumnTypes(this.migrationContext.DatabaseName, this.migrationContext.OriginalTableName, &sharedUniqueKey.Columns)
uniqueKeyIsValid := true
// 校验唯一键的类型,ghost不支持FloatColumnType和Json列。
for _, column := range sharedUniqueKey.Columns.Columns() {
switch column.Type {
case sql.FloatColumnType:
{
log.Warning("Will not use %+v as shared key due to FLOAT data type", sharedUniqueKey.Name)
uniqueKeyIsValid = false
}
case sql.JSONColumnType:
{
// Noteworthy that at this time MySQL does not allow JSON indexing anyhow, but this code
// will remain in place to potentially handle the future case where JSON is supported in indexes.
log.Warning("Will not use %+v as shared key due to JSON data type", sharedUniqueKey.Name)
uniqueKeyIsValid = false
}
}
}
// 检验选出的唯一键,如果没有选出唯一键的话报错求助。
if this.migrationContext.UniqueKey == nil {
return fmt.Errorf("No shared unique key can be found after ALTER! Bailing out")
}
// 检查唯一键是否可以是空的。默认是不允许唯一键为空的,如果没办法改变让他不为空,ghost也提供了参数去适配
if this.migrationContext.UniqueKey.HasNullable {
if this.migrationContext.NullableUniqueKeyAllowed {
log.Warningf("Chosen key (%s) has nullable columns. You have supplied with --allow-nullable-unique-key and so this migration proceeds. As long as there aren't NULL values in this key's column, migration should be fine. NULL values will corrupt migration's data", this.migrationContext.UniqueKey)
} else {
return fmt.Errorf("Chosen key (%s) has nullable columns. Bailing out. To force this operation to continue, supply --allow-nullable-unique-key flag. Only do so if you are certain there are no actual NULL values in this key. As long as there aren't, migration should be fine. NULL values in columns of this key will corrupt migration's data", this.migrationContext.UniqueKey)
}
}
// 获取原表和影子表的交集列
this.migrationContext.SharedColumns, this.migrationContext.MappedSharedColumns = this.getSharedColumns(this.migrationContext.OriginalTableColumns, this.migrationContext.GhostTableColumns, this.migrationContext.OriginalTableVirtualColumns, this.migrationContext.GhostTableVirtualColumns, this.migrationContext.ColumnRenameMap)
//打印日志
INFO Shared columns are id,status,newC1,newC2,newC3,newC5,newC4
//做其他额外的检查
做完了上面的检查工作就可以真正的迁移数据了。
数据迁移部分的主要逻辑在如下函数中
// 统计当前有多少行
// 具体实现:新开协程,用于统计一共多少行,执行如下如下sql
// select /* gh-ost */ count(*) as rows from %s.%s`
if err := this.countTableRows(); err != nil {
return err
}
// 添加DML语句监听器
// addDMLEventsListener开始监听原始表上的binlog事件,并为每个此类事件创建一个写任务并将其排队。
// 由executeWriteFuncs专门负责消费这个队列。
if err := this.addDMLEventsListener(); err != nil {
return err
}
// 获取迁移的范围
// -- 执行sql:获取最小的id值
// select /* gh-ost `lossless_ddl_test`.`user` */ `id`
// from
// `lossless_ddl_test`.`user`
// order by
// `id` asc
// limit 1
// -- 执行sql:获取最大id值
// select /* gh-ost `lossless_ddl_test`.`user` */ `id`
// from
// `lossless_ddl_test`.`user`
// order by
// `id` desc
// limit 1
if err := this.applier.ReadMigrationRangeValues(); err != nil {
return err
}
// 这两个协程分别是迁移任务的执行者。
// 和迁移任务的创建者。
go this.executeWriteFuncs()
go this.iterateChunks()
下图是:上面代码中最后两个协程之间是如何配合工作的逻辑图
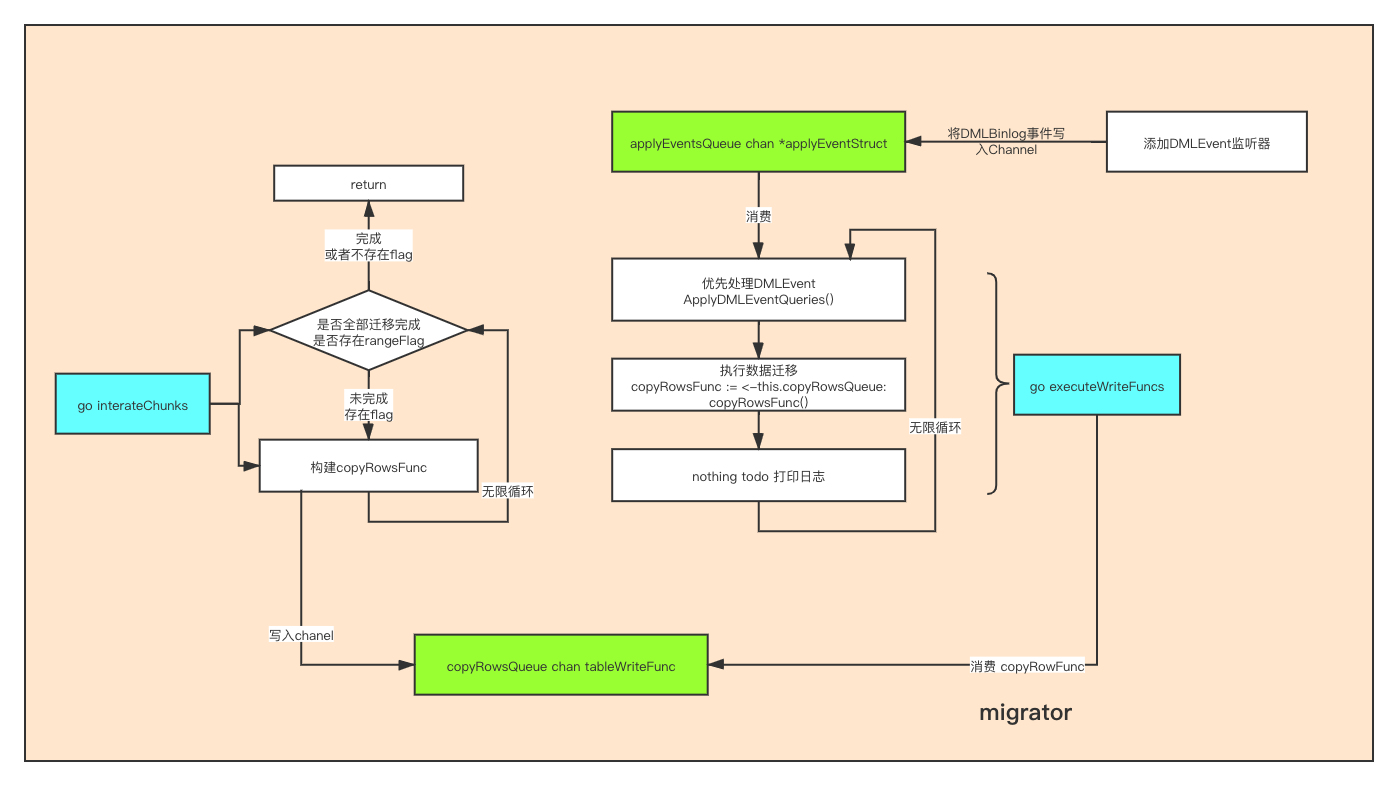
通过上图可以看出其中的executeWrite的主要作用其实是执行任务。
那他要执行的任务有主要有两种:
- 数据迁移任务:copyRowsFunc()
- 同步binlog事件的函数:ApplyDMLEventQueries()
其中copyRowsFunc()如下:
copyRowsFunc := func() error {
if atomic.LoadInt64(&this.rowCopyCompleteFlag) == 1 || atomic.LoadInt64(&hasNoFurtherRangeFlag) == 1 {
// Done. There's another such check down the line
return nil
}
// 当hasFurterRange为false时,原始表可能被写锁定,
// CalculateNextIterationRangeEndValues将永远挂起
hasFurtherRange := false
if err := this.retryOperation(func() (e error) {
hasFurtherRange, e = this.applier.CalculateNextIterationRangeEndValues()
return e
}); err != nil {
return terminateRowIteration(err)
}
if !hasFurtherRange {
atomic.StoreInt64(&hasNoFurtherRangeFlag, 1)
return terminateRowIteration(nil)
}
// Copy task:
applyCopyRowsFunc := func() error {
if atomic.LoadInt64(&this.rowCopyCompleteFlag) == 1 {
return nil
}
_, rowsAffected, _, err := this.applier.ApplyIterationInsertQuery()
if err != nil {
return err // wrapping call will retry
}
atomic.AddInt64(&this.migrationContext.TotalRowsCopied, rowsAffected)
atomic.AddInt64(&this.migrationContext.Iteration, 1)
return nil
}
if err := this.retryOperation(applyCopyRowsFunc); err != nil {
return terminateRowIteration(err)
}
return nil
}
如上函数有个需要关注的点:
第一:上面的CalculateNextIterationRangeEndValues()函数用于计算下一个迭代的范围,他会构建出类似如下的sql,默认的chunkSize是1000
select /* gh-ost `lossless_ddl_test`.`user` iteration:1 */
`id`
from
`lossless_ddl_test`.`user`
where ((`id` > ?)) and ((`id` < ?) or ((`id` = ?)))
order by
`id` asc
limit 1
offset 999
第二:也是如上函数中的核心逻辑是:this.applier.ApplyIterationInsertQuery()
func (this *Applier) ApplyIterationInsertQuery() (chunkSize int64, rowsAffected int64, duration time.Duration, err error) {
startTime := time.Now()
chunkSize = atomic.LoadInt64(&this.migrationContext.ChunkSize)
// 构建查询的sql
query, explodedArgs, err := sql.BuildRangeInsertPreparedQuery(
this.migrationContext.DatabaseName,
this.migrationContext.OriginalTableName,// 原表名
this.migrationContext.GetGhostTableName(), // 幽灵表名
this.migrationContext.SharedColumns.Names(),
this.migrationContext.MappedSharedColumns.Names(),
this.migrationContext.UniqueKey.Name,
&this.migrationContext.UniqueKey.Columns,
this.migrationContext.MigrationIterationRangeMinValues.AbstractValues(),
this.migrationContext.MigrationIterationRangeMaxValues.AbstractValues(),
this.migrationContext.GetIteration() == 0,
this.migrationContext.IsTransactionalTable(),
)
if err != nil {
return chunkSize, rowsAffected, duration, err
}
// 在这个匿名函数中执行查询,返回查询的结果
sqlResult, err := func() (gosql.Result, error) {
tx, err := this.db.Begin()
if err != nil {
return nil, err
}
defer tx.Rollback()
sessionQuery := fmt.Sprintf(`SET SESSION time_zone = '%s'`, this.migrationContext.ApplierTimeZone)
sqlModeAddendum := `,NO_AUTO_VALUE_ON_ZERO`
if !this.migrationContext.SkipStrictMode {
sqlModeAddendum = fmt.Sprintf("%s,STRICT_ALL_TABLES", sqlModeAddendum)
}
sessionQuery = fmt.Sprintf("%s, sql_mode = CONCAT(@@session.sql_mode, ',%s')", sessionQuery, sqlModeAddendum)
if _, err := tx.Exec(sessionQuery); err != nil {
return nil, err
}
// 执行查询
result, err := tx.Exec(query, explodedArgs...)
if err != nil {
return nil, err
}
if err := tx.Commit(); err != nil {
return nil, err
}
return result, nil
}()
if err != nil {
return chunkSize, rowsAffected, duration, err
}
// 获取到查询的影响行数
rowsAffected, _ = sqlResult.RowsAffected()
duration = time.Since(startTime)
log.Debugf(
"Issued INSERT on range: [%s]..[%s]; iteration: %d; chunk-size: %d",
this.migrationContext.MigrationIterationRangeMinValues,
this.migrationContext.MigrationIterationRangeMaxValues,
this.migrationContext.GetIteration(),
chunkSize)
return chunkSize, rowsAffected, duration, nil
如上函数会构建出两条SQL,
- 第一条是用于数据迁移的SQL如下:
insert /* gh-ost `lossless_ddl_test`.`user` */ ignore into `lossless_ddl_test`.`_user_gho` (`id`, `status`, `newC1`, `newC2`, `newC3`, `newC5`, `newC4`)(select `id`, `status`, `newC1`, `newC2`, `newC3`, `newC5`, `newC4` from `lossless_ddl_test`.`user` force index (`PRIMARY`) where (((`id` > ?)) and ((`id` < ?) or ((`id` = ?)))) lock in share mode)
SQL解读:
- 按照(((
id> ?)) and ((id< ?) or ((id= ?)))的范围从原表读数据。 - 从原表中读取出所有列的数据,强制使用索引 force index (
PRIMARY)。 - 将数据灌进影子表的操作使用的是 insert ignore into,表示如果影子表已经存在了相同的数据,不再重复写入
- 为了防止迁移数据时数据被改动,每次插入数据对原表的数据持有读锁(lock in share mode)。
- 构建的第二条SQL如下:主要是设置session
// 为这此执行sql的
SET SESSION time_zone = '+08:00',sql_mode = CONCAT(@@session.sql_mode, ', NO_AUTO_VALUE_ON_ZERO,STRICT_ALL_TABLES')
NO_AUTO_VALUE_ON_ZERO表示:让MySQL中的自增长列可以从0开始。默认情况下自增长列是从1开始的,如果你插入值为0的数据会报错,设置这个之后就可以正常插入为0的数据了。
STRICT_ALL_TABLES表示语句中有非法或丢失值,则会出现错误。语句被放弃并滚动。
第二个重点关注的函数是和 迁移应用增量数据相关的函数ApplyDMLEventQueries()
通过如下的方式可以断点顺利进入到ApplyDMLEventQueries()
首先:看下图
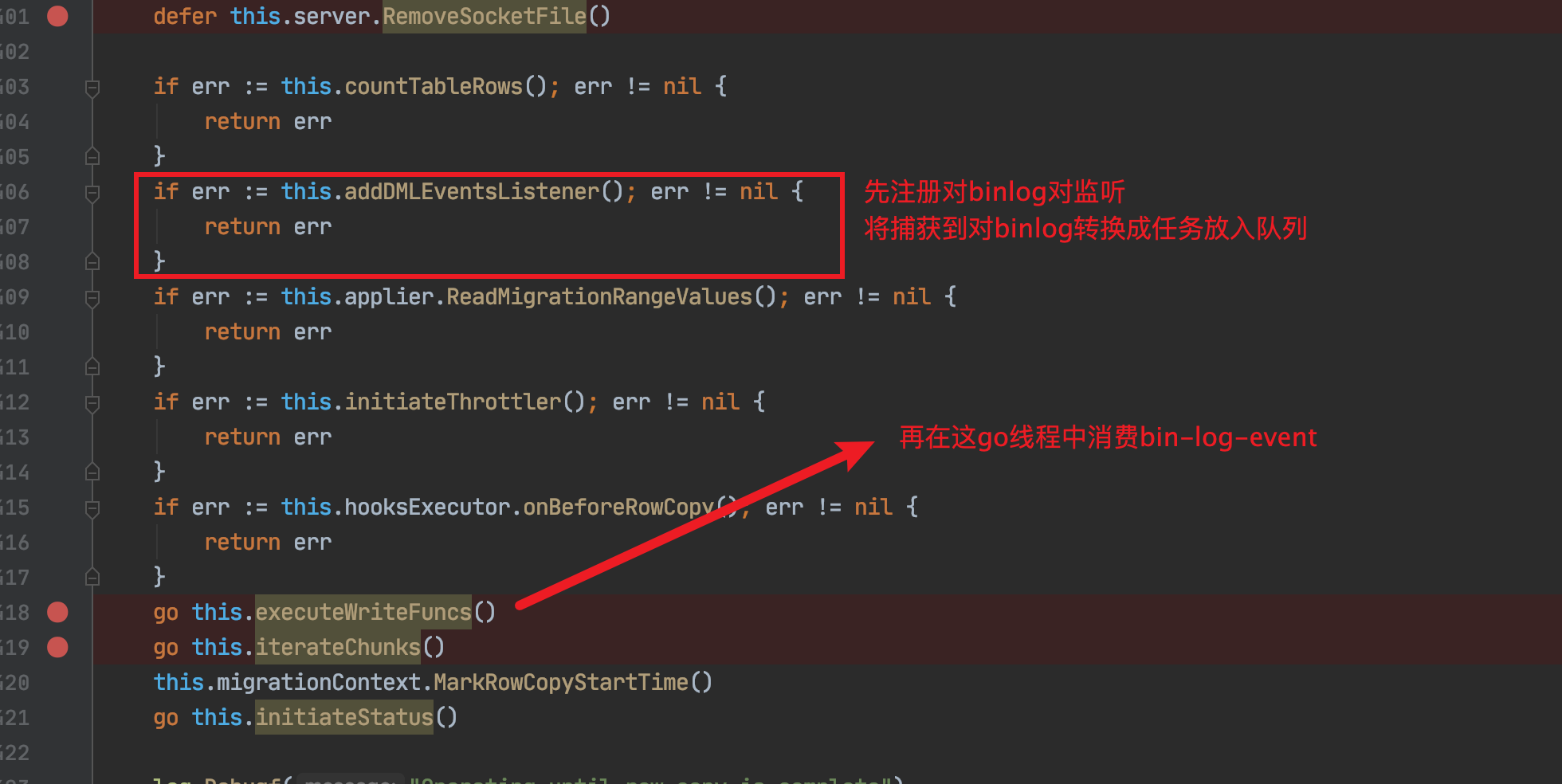
所以我们将断点打在第18行上,再通过控制台写入一条数据

在18行开启的协程中就会优先处理这个事件。
于是我们就会顺利进入到下面的代码中:
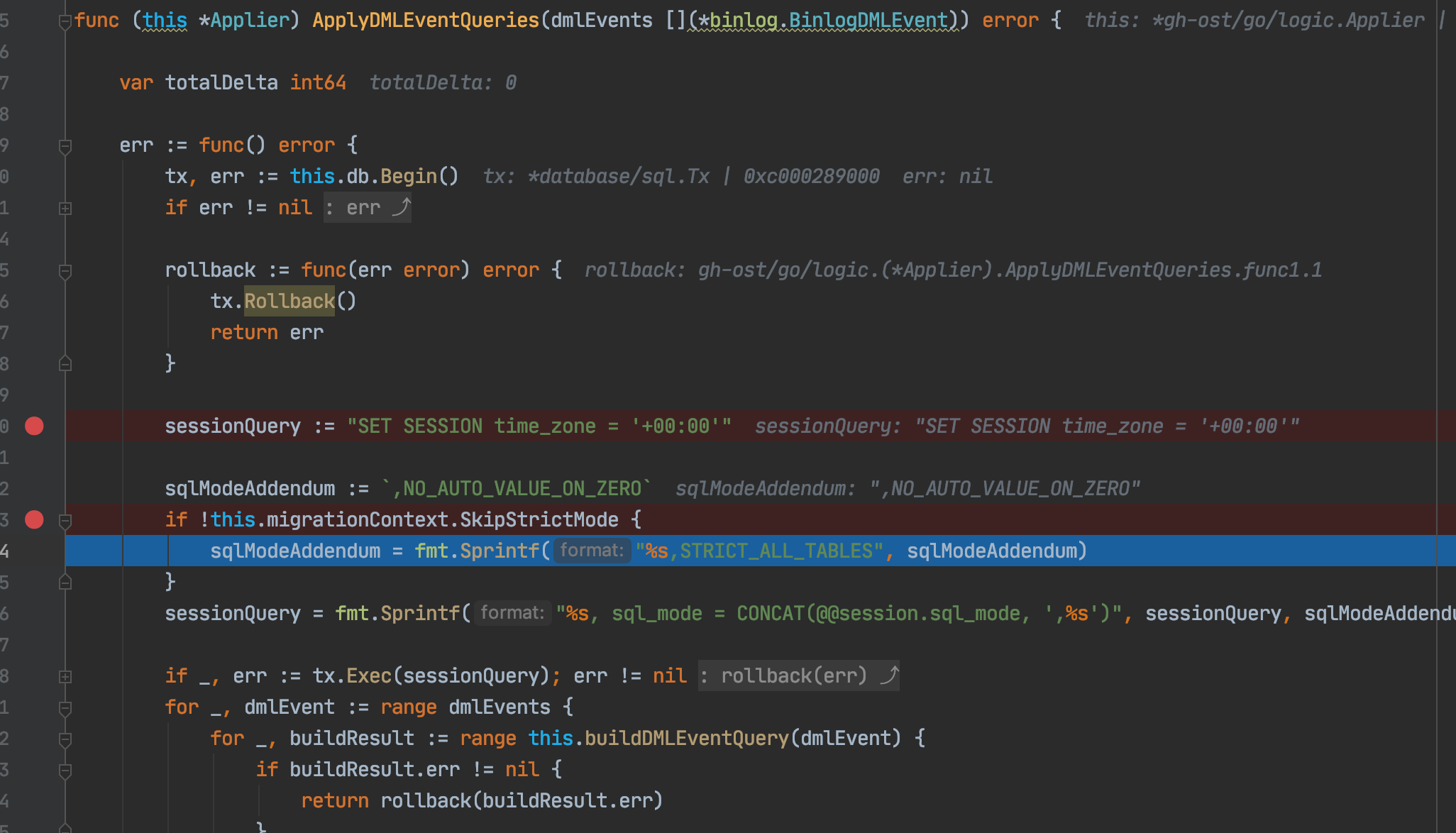
这段代码的逻辑如下:
- 开启事物
- 对当前session进行会话参数。
SET SESSION time_zone = '+00:00', sql_mode = CONCAT(@@session.sql_mode, ',,NO_AUTO_VALUE_ON_ZERO,STRICT_ALL_TABLES')
-
然后遍历所有的事件,将不同的binlog事件转换成不同的sql。
func (this *Applier) buildDMLEventQuery(dmlEvent *binlog.BinlogDMLEvent) (results [](*dmlBuildResult)) { switch dmlEvent.DML { case binlog.DeleteDML: { query, uniqueKeyArgs, err := sql.BuildDMLDeleteQuery(dmlEvent.DatabaseName, this.migrationContext.GetGhostTableName(), this.migrationContext.OriginalTableColumns, &this.migrationContext.UniqueKey.Columns, dmlEvent.WhereColumnValues.AbstractValues()) return append(results, newDmlBuildResult(query, uniqueKeyArgs, -1, err)) } case binlog.InsertDML: { query, sharedArgs, err := sql.BuildDMLInsertQuery(dmlEvent.DatabaseName, this.migrationContext.GetGhostTableName(), this.migrationContext.OriginalTableColumns, this.migrationContext.SharedColumns, this.migrationContext.MappedSharedColumns, dmlEvent.NewColumnValues.AbstractValues()) return append(results, newDmlBuildResult(query, sharedArgs, 1, err)) } case binlog.UpdateDML: { if _, isModified := this.updateModifiesUniqueKeyColumns(dmlEvent); isModified { dmlEvent.DML = binlog.DeleteDML results = append(results, this.buildDMLEventQuery(dmlEvent)...) dmlEvent.DML = binlog.InsertDML results = append(results, this.buildDMLEventQuery(dmlEvent)...) return results } query, sharedArgs, uniqueKeyArgs, err := sql.BuildDMLUpdateQuery(dmlEvent.DatabaseName, this.migrationContext.GetGhostTableName(), this.migrationContext.OriginalTableColumns, this.migrationContext.SharedColumns, this.migrationContext.MappedSharedColumns, &this.migrationContext.UniqueKey.Columns, dmlEvent.NewColumnValues.AbstractValues(), dmlEvent.WhereColumnValues.AbstractValues()) args := sqlutils.Args() args = append(args, sharedArgs...) args = append(args, uniqueKeyArgs...) return append(results, newDmlBuildResult(query, args, 0, err)) } } return append(results, newDmlBuildResultError(fmt.Errorf("Unknown dml event type: %+v", dmlEvent.DML))) }刚刚Insert类型的事件被转换成:注意哦,是replace into ,而不是insert into,也不是insert ignore into
replace /* gh-ost `lossless_ddl_test`.`_user_gho` */ into `lossless_ddl_test`.`_user_gho` (`id`, `status`, `newC1`, `newC2`, `newC3`, `newC5`, `newC4`) values (?, ?, ?, ?, ?, ?, ?)delete 类型的事件被转换成如下 :
delete /* gh-ost `lossless_ddl_test`.`_user_gho` */ from `lossless_ddl_test`.`_user_gho` where ((`id` = ?))update类型的事件转换为如下格式sql:
update /* gh-ost `lossless_ddl_test`.`_user_gho` */ `lossless_ddl_test`.`_user_gho` set `id`=?, `status`=?, `newC1`=?, `newC2`=?, `newC3`=?, `newC5`=?, `newC4`=? where ((`id` = ?))其中通过这个过程可以看出来,ghost重访binlog和执行数据迁移其实是同步进行的,甚至重访binlog的优先级比迁移数据的row copy还高。
5.5 cut-over#
cutOver是数据迁移的最后一步,它主要做的工作就是: 改表名
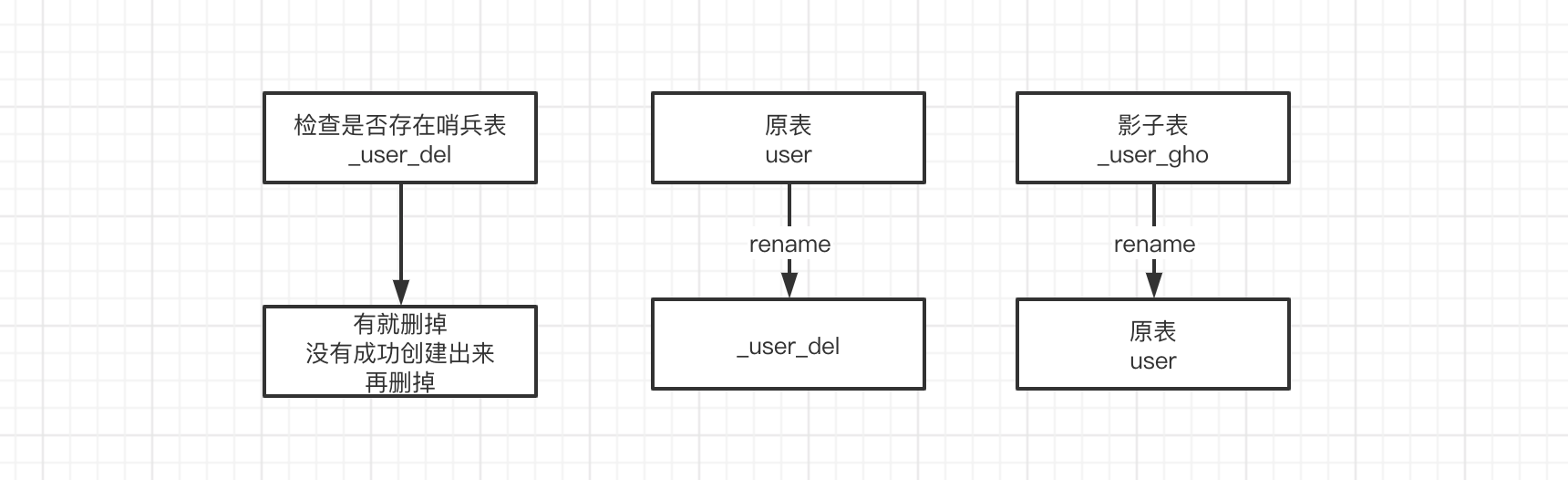
- 和哨兵表相关的操作:_xxx_del
- 检查哨兵表是否存在,如果有的话就干掉它
- ghost创建新的哨兵表
之所以要检查 _xxx_del 是否存在是因为,原表现将表名改成 : 原表名_del, 防止因为这个表名原来就有而导致改名出错。
//在如下函数中执行:show /* gh-ost */ table status from `lossless_ddl_test` like '_user_del'
showTableStatus(tableName string)
//如果哨兵表不存在的话,返回如下
mysql> show table status from `lossless_ddl_test` like '_user_del';
Empty set (0.00 sec)
//如果存在的话会返回一坨关于当前表的信息
mysql> show table status from `lossless_ddl_test` like '_user_gho';
+-----------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+-----------------+----------+----------------+---------+
| Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | Max_data_length | Index_length | Data_free | Auto_increment | Create_time | Update_time | Check_time | Collation | Checksum | Create_options | Comment |
+-----------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+-----------------+----------+----------------+---------+
| _user_gho | InnoDB | 10 | Dynamic | 8178 | 34 | 278528 | 0 | 0 | 0 | 8188 | 2020-07-26 17:01:57 | 2020-07-26 17:01:59 | NULL | utf8_general_ci | NULL | | |
+-----------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+-----------------+----------+----------------+---------+
1 row in set (0.01 sec)
// 如果哨兵表存在的话就会删除它
this.dropTable(tableName)
//创建哨兵表,执行如下的sql
create /* gh-ost */ table `lossless_ddl_test`.`_user_del` (
id int auto_increment primary key
) engine=InnoDB comment='ghost-cut-over-sentry'
// !!! 创建 _user_del表是为了防止cut-over提前执行,导致数据丢失!!!!!
// 如果_user_del 表都创建失败了,ghost会直接退出,因为ghost通过 _user_del表来控制cutOver在可控的时机执行(当ghost加的写锁被释放时执行)。那现在这个表都创建不成功,所以直接退出也罢。
- 加锁
//执行如下sql,我们称这个会话叫 会话A
lock /* gh-ost */ tables `lossless_ddl_test`.`user` write, `lossless_ddl_test`.`_user_del` write
// 加完write锁后,在这之后的诸如select 等 dml操作都会被阻塞等写锁的释放。
// 如果加锁失败了,ghost程序退出,因为没有加上任何锁,所以业务方的SQL不会受到任何影响。
// !!!!注意,在一个会话中,即使先加上了 writelock,依然是可以执行drop的!!!!!
对user表和哨兵表同时添加了写锁,当然终究还是看到了ghost也会将原表锁住,真真切切的加了写锁
但是我们依然会说ghost其实是无损的DDL,为啥这么说呢?因为做无损DDL的过程中,最耗时的步骤其实是数据迁移这一步,如果我们在数据迁移时将写锁,或者MDL写锁添加在原表上,那这迁移过程中业务表不能被访问,这才是不能被允许的,ghost完美避过了这个耗时的过程,而将写锁放在改表名这一步。该表名很快的,几乎瞬间就完成了。那用写锁保证该表名的过程中没有写流量打进来,完全是可以接受的。
- 改表名
// 执行如下sql,获取当前会话的sessionID
// select connection_id()
// 将sessionID写入channel
sessionIdChan <- sessionId
// 整个rename的操作seesion的超时时间,防止写锁一直存在阻塞业务方的dml
INFO Setting RENAME timeout as 3 seconds
// 如果这时会话A出现异常了,会话A持有的锁会被自动释放,保证了业务方的DML语句不被影响。此外ghsot设定的是 哨兵表在会话A没有任何异常的情况下删除的,现在会话A有了异常,_user_del就会一直存在,而这个表还存在,下面的rename操作就不会被执行成功。保证数据迁移整体的安全性。
// 执行如下sql,将原表名改为哨兵表名, 影子表改成原表名
// 这个rename操作会因为上面的lock 语句而等待。
// 我们称这个会话叫做 会话B
rename /* gh-ost */ table `lossless_ddl_test`.`user` to `lossless_ddl_test`.`_user_del`, `lossless_ddl_test`.`_user_gho` to `lossless_ddl_test`.`user`
// 如果在会话B执行rename等待过程中,这时会话A出现异常了,同样的:会话A持有的锁会被自动释放,保证了业务方的DML语句不被影响。此外ghsot设定的是 哨兵表在会话A没有任何异常的情况下删除的,现在会话A有了异常,_user_del就会一直存在,而这个表还存在,上面的rename操作就不会被执行成功。保证数据迁移整体的安全性。
// 执行完上面的rename语句后,业务方的sql会因为前面的lock语句和rename语句而等待。
// 会话A 通过如下sql,检查执行rename的会话B在等待dml锁。如果会话B异常失败了,会话A通过下面的sql就检测不出会话B的存在,会话A继续运行,释放写锁。
select id
from information_schema.processlist
where
id != connection_id()
and 17765 in (0, id)
and state like concat('%', 'metadata lock', '%')
and info like concat('%', 'rename', '%')
// 会话A,执行如下SQL,删除 _user_del 表,让cutOver可以正常执行。
drop table `_user_del`
// 会话A执行如下SQL释放writeLock
UNLOCK TABLES
// 现在writeLock被释放了,剩下的问题就是现有的诸多DML SQL和 rename SQL到底谁先执行的问题。
// MySQL有机制保证:无损DML和rename谁先打向MySQL,MySQL都会优先执行rename SQL。
// 所以下面rename SQL会优先于其他的DMLSQL 去改表名。
// 如果rename过程成功结果,ghost工作完成
INFO Tearing down applier
DEBUG Tearing down...
Tearing down streamer
INFO Tearing down throttler
DEBUG Tearing down...
# Done
Exiting.
// 去检查一下结果
mysql> show tables;
+-----------------------------+
| Tables_in_lossless_ddl_test |
+-----------------------------+
| _user_del |
| user |
+-----------------------------+
2 rows in set (0.00 sec)
5.6、如何保证数据一致性#
在数据迁移的过程中原表和影子表存在三种操作
- ghost对原表进行row copy,将数据迁移到影子表。
- 业务对原表进行DML操作。
- ghost对影子表重放binlog日志。
5.6.1、两种情况
-
情况1:rowCopy都进行完了,剩下的增量数据只需要从binlog-event中解析出sql然后在影子表重放就ok,这也是最简单的情况。因为重放binlog只会出现更新的状态覆盖旧状态的数据。
-
情况2: rowCopy还在进行的过程中。监听到了binlog-event。
上面记录ghost整个工作流程的时候有提到,对ghost来说,处理binlog-event的优先级比进行rowCopy的优先级还要高。那在未完成rowCopy的情况下,就重放binlog,数据一致性是如何保证的呢?
ghost会监听处理的dml类型binlog有 insert,delete,update,他们大概会被转换处理成下面样子的sql。
// insert 类型 replace /* gh-ost `lossless_ddl_test`.`_user_gho` */ into `lossless_ddl_test`.`_user_gho` (`id`, `status`, `newC1`, `newC2`, `newC3`, `newC5`, `newC4`) values (?, ?, ?, ?, ?, ?, ?) // delete 类型 delete /* gh-ost `lossless_ddl_test`.`_user_gho` */ from `lossless_ddl_test`.`_user_gho` where ((`id` = ?)) //update类型的事件 update /* gh-ost `lossless_ddl_test`.`_user_gho` */ `lossless_ddl_test`.`_user_gho` set `id`=?, `status`=?, `newC1`=?, `newC2`=?, `newC3`=?, `newC5`=?, `newC4`=? where ((`id` = ?))
5.6.2、对于insert
由于binlog-event的优先级更高,所以数据通过 replace into(看我上面列出来的sql) 的方式写进影子表。
注意这是replace into,表示不存在相同的数据就直接插入,数据已经存在的先把旧数据删除再将当前最新的数据插入。
而rowCopy时使用的插入语句时 insert ignore。表示,如果已经存在了,那好它肯定是通过重放binlog-event得到的,肯定比我新,那直接忽略当前记录处理下一个insert ignore。
5.6.3 、对于update
假设现在有1000条数据(id从1~1000)。 row'Copy拷贝完了前300条,这时ghost接受到了binlog-event竟然是对update id = 999的数据。又因为binlog-event对优先级比rowCopy高,所以ghost还不得不先处理这个update事件。可是ghost控制的影子表中还不存在id=999的数据啊~
其实不用差异。如果影子表里面没有就直接忽略好了,在影子表上执行这个sql又不会报错。
mysql> update user_gho set status = 123 where id = 9999;
Query OK, 0 rows affected (0.00 sec)
Rows matched: 0 Changed: 0 Warnings: 0
反正过一会我们通过rowCopy来的数据肯定是最新的。
5.6.4、对于delete
情况1: 完成了rowCopy,然后收到了 delete-binlog-event
这时执行回放 delete-binlog-event 就好了,因为原表中的数据已经被删除了。所以影子表中的数据自然要被删除。
情况2: 未完成rowCopy,然后收到了 delete-binlog-event
这时执行也是直接回放 delete-binlog-event 就好了,数据不存在只是说影响结果为空,这时原表中的数据已经被删除了。过一会的rowCopy也不会把已经删除的数据拷贝过来。所以还是安全的。
2020-08-13 补充第三种情况
情况3:构造迁移数据的协程生成了一个任务,将id从1000~1999的数据从原表拷贝到影子表,与此同时ghost收到了一个delete-bin-log-event,想删除id=1555的记录,又因为回放binlog的优先级比执行rowcopy的优先级高,所以执行从binlog事件中解析出来的函数,这时影子表中没有要删除的id=1555的记录,但是执行也不会报错只不过影响行数为0,然后执行rowcopy,这样岂不是没有删除掉id=1555的记录?难道是ghost的bug吗?
其实不是的~,因为ghost生成的迁移数据的SQL又存在 lock in share mode ,加了一把锁!因为有这把锁的存在,上面说的情况三就不可能出现,因为当MySql-Server执行rowcopy时,其他的DML SQL是不能修改这些数据的,因为他们没有锁,ghsot也就不会收到上述情况三中的deletebinlog事件。
而当ghost收到delete-binlog事件时,说明主库已经写完了redolog和binlog,而且ghost迁移数据的SQL也一定没有来得及发送到MySql-Server
六、ghost的暂停、继续、限流、终止#
- 暂停和继续
ghost可是实现真正的暂停,当我们出发暂停时,ghost不会再有任何行rowCopy,也不会再处理任何事件。不对主库产生任何压力
相关参数:throttle-additional-flag-file
//在ghost的main.go中有定义这个参数
//这个文件存在的话操作会停止 保留默认值即可,用于限制多个gh ost操作
flag.StringVar(&migrationContext.ThrottleAdditionalFlagFile, "throttle-additional-flag-file", "/tmp/gh-ost.throttle", "operation pauses when this file exists; hint: keep default, use for throttling multiple gh-ost operations")
//具体可以通过shell命令完成
echo throttle | socat - /tmp/gh-ost.test.sock
//继续
echo no-throttle | socat - /tmp/gh-ost.test.sock
- 限流相关
相关参数
--max-lag-millis
--chunk-size
--max-load
//这些参数在main.go中的定义如下
//限制操作的复制延迟, 当主从复制延迟时间超过该值后,gh-ost将采取节流(throttle)措施
maxLagMillis := flag.Int64("max-lag-millis", 1500, "replication lag at which to throttle operation")
//每次迭代中要处理的行数 范围从100 - 100000
//就是rowCopy过程中range
chunkSize := flag.Int64("chunk-size", 1000, "amount of rows to handle in each iteration (allowed range: 100-100,000)")
//当ghost检测到超过最大负载 ghost不会退出,为了不给系统负载造成更大的压力,ghost会等load低于这个值时再工作。
maxLoad := flag.String("max-load", "Threads_running=25", "Comma delimited status-name=threshold. e.g: 'Threads_running=100,Threads_connected=500'. When status exceeds threshold, app throttles writes")
- 终止
--panic-flag-file
//在main.go中,如下
//创建此文件时,gh ost将立即终止,而不进行清理
flag.StringVar(&migrationContext.PanicFlagFile, "panic-flag-file", "/tmp/ghost.panic.flag", "when this file is created, gh-ost will immediately terminate, without cleanup")
七、写有中文注释的ghost源码项目#

项目使用vender管理依赖,开箱即用
github地址:https://github.com/zhuchangwu/Ghost-source-code-reading-env
todo:GoMySqlReader



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)