Protocol Buffers
Google Protobuf
Why Protobuf
protobuf它是Google提供的一个技术, 一个类库, 也可以说是一套规范, 学java的人都知道java有自己的序列化机制, 对不同的java程序来说,他们可以使用同一种序列化机制进行数据的传递, 但是java的序列化机制并不适用于其他的语言比如python
如果想让他们共享数据,我们就得定义中数据格式, 比如xml, 通过xml定义出一个对象, 这样java,python都可以解析xml, 但是在网络上传输xml的话是不是有点浪费资源呢? xml中有大量的冗余的标签没有实际的意义还不能去除, 严重影响性能. 导致传输的效率急剧降低
protobuf的出现就是为了迎战这个效率低的问题
什么是protobuf?
protobuf 全称是: protocol buffers 是一种语言中立的用于序列化结构化数据 ,相对于XML这种格式的数据来说,protobuf极其小, 极其灵活,我们只要定义好数据的格式, 就可以使用代码生成器生成代码,我们只需要使用它生成出来的代码就能实现轻松编写,读取结构化数据, 并且目前Protobuf支持 C++ , C# , Dart , Go , Java , Python多种语言
安装环境
想使用protobuf的话我们要先去下载两个工具, 第一个就是protobuf的编译器也就是protoc , 我们一会将使用它把我们定义的 .proto 文件编译成java代码, 然后我们直接使用它生成的java代码就ok
下载链接: https://github.com/protocolbuffers/protobuf/releases>
根据同样的系统选择不同的编译器就ok,我用的windows, 所以选择 :protoc-3.11.0-win64.zip
如果我们想用java玩protobuf , 同样得在上面的链接中将protobuf-java-3.11.0.zip 下载到本地
上手使用
总体思路:
首先我们只要根据需求制定出 .proto 文件中对消息的描述就ok. 因为代码自动生成:
- 客户端代码生曾策略: stub(装)
- 服务端代码生曾策略: skeleton(骨架)
序列化encode和反序列decode化也叫做编码和解码:
使用流程:
- 定义结果说明文件: 描述接口对象(结构体), 对象成员,接口方法等一系列信息(这是个文本文件独立于任何变成语言)
- 通过RPC框架提供的编译器将接口说明文件编译成具体的语言实现
- 在客户端和服务端分别引入RPC编译器生成的文件,即可进行RPC远程过程调用
参照项目官方地址 https://github.com/protocolbuffers/protobuf/tree/master/java
我们需要添加maven依赖导入运行时环境, 确保我们下面导入的运行时依赖和protoc的版本一致
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.11.0</version>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java-util</artifactId>
<version>3.11.0</version>
</dependency>
一: 编写 .proto 文件
这个 .proto 文件, 是一个描述性质的文件,我们使用这个文件去描述通信的双方每次发送的数据的格式是怎么样的,就像XML能描述出一个对象出来
下面是 .proto 文件的示例,语法和java 神似
// proto有两个版本, 2和3, 这里使用的 proto2
syntax = "proto2";
// 以pakcet包名开始, 为了防止命名的冲突
package tutorial;
// 如果我们没有显示的指定 java_package 的话, 他就是用上面的packet当成生成的java类的包名
// 显示的指定了 java_package , 最终生成的java代码包的名字就用 java_package 为准
// 即便是 显示的提供了 java_package, 也得提供上面的packet(防止在其他语言中出现命名的冲突)
option java_package, = "com.example.tutorial";
// 最终经过protoc处理后 会生成一个 叫AddressBookProtos的外部类, 这个类中包含了我们指定的下面的所有类
// 如果我们没有显示的指定的话,最终就会将文件名转换为驼峰命名法得到的名,当成类名字
option java_outer_classname = "AddressBookProtos";
// message其实是不同类型的 field的聚合,比如 string, int32,bool,float,double
// 第一个消息
message Person {
// 这种等于1, 等于2, 并不是赋值, 而是进行一种唯一的标记,在同一个范围中 ,标记不重复
// 如下面的123, 跳过枚举后的4
// required 表示这个字段是必须要有的,如果不提供的话会抛出异常
required string name = 1;
required int32 id = 2;
// 表示这个字段的值是可选的
optional string email = 3;
// 枚举类型的消息
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
// 消息中的小 PhoneNumber
message PhoneNumber {
required string number = 1;
// Default表示这个字段的值, 默认就是枚举中的HOME值, 如果用户提供新的值, 会覆盖默认值
optional PhoneType type = 2 [default = HOME];
}
// repeated 表示是可重复的,可以任意次, 可以理解成java中的list
repeated PhoneNumber phones = 4;
}
// 第二个消息
// 可以使用下面这种消息的嵌套
message AddressBook {
repeated Person people = 1;
}
二. 编译 .proto 文件
编译的命令如下:
protoc -I=$SRC_DIR --java_out=$DST_DIR $SRC_DIR/addressbook.proto
例:
protoc --java_out=src/main/java src/protobuf/Person.proto
在上面的命令中我们需要指定两个文件目录,一个是 源代码的路径, 还有就是 目标路径
看一下生成的这个类的继承体系
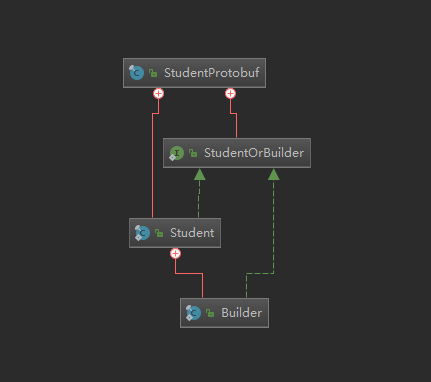
也不怕唠叨, 再说一次, 根据我们提供的 .proto文件, 最外面的是StudentProtobuf是我们在java_outer_classname指定的名字, 内部类Student,是我们指定的 消息类型
- 消息Student仅仅存在get方法,并且它是一个不可变的, 一经构建出来, 就不可再改变
- 消息的构建需要借助于构建器, 看上图, 构建器是消息内置对象
- 消息Student 中存在一个构建器, 这个构建器的作用就是通过构建者模式完成对Student的构建, 构造器提供了对消息Student的一系列set方法
所以就有了下面的构建对象的一幕
StudentProtobuf.Student student = StudentProtobuf.Student.newBuilder()
.setEmail("123123@qq.com")
.setId(1)
.setName("张三").build();
不要尝试去修改这个生成的类, 因为每次重新生成, 都会进行一次覆盖
然后protoc就会帮我们生成指定的文件AddressBookProtos.java 名子就是我们在 .proto文件中的 java_outer_classname指定的名字
补充 Message Method
这是Message中内置的一些方法
-
isInitialized(): 检查是否所有的 required类型的描述字段都被赋值了 -
toString(): 用人类可读的方式显示这些字段 -
mergeFrom(Message other): (builder only)将其他的消息合并到次消息中 -
clear(): (builder only)清除所有字段的空状态 -
byte[] toByteArray();: 将消息序列化成二进制数组 -
static Person parseFrom(byte[] data);: 从给定的二进制数组中反序列化成 对象 -
void writeTo(OutputStream output);: 序列化消息并将其写入OutputStream -
static Person parseFrom(InputStream input);: 读取和解析来自InputStream的消息。
三. 测试使用
代码如下, 虽然是在一个java文件中完成的,但是也是具有实际意义的, 就像前面说的 proto可以实现比XML更好,更快,更灵敏的对象的描述, 同样也是跨越语言的
// 构建对象
StudentProtobuf.Student student = StudentProtobuf.Student.newBuilder()
.setEmail("123123@qq.com")
.setId(1)
.setName("张三").build();
// 转换成字节数组
byte[] bytes = student.toByteArray();
// todo 从网络中传输发往其他客户端
// 其他客户端,将对象反序列化出来
StudentProtobuf.Student stu = StudentProtobuf.Student.parseFrom(bytes);
System.out.println(stu.getName());
System.out.println(stu.getEmail());
System.out.println(stu.getId());
RMI: remote method invocation 远程方法调用
只针对java, 服务端和客户端之间之间进行通信, 一般他的流程是这样的, 在client端生将消息序列化转换成字节码, 然后经过网络的传输作用,流向服务端, 服务负端再将这些数据返回序列化会消息信息进行下一步处理操作
Netty对Protobuf的支援
Netty+Protobuf是可以实现 RPC(remote procedure call,远程过程调用,达到跨语言的调用应用调用, 并且他们之间结合和传统web service对比他的优势是在编解码的效率上很高,在网络上的传输数据很快
思路: netty和protobuf之间的整合是必然的事情, protobuf 可以很好的完成对象的序列化, 而netty可以将这些已经完成序列化的数据发送出去
Netty服务端和客户端的编码其实挺机械化的,** 我们的关注点是netty提供了哪些针对protobuf编解码的处理器**, 以及怎么给netty添加上这些处理器, 实例代码如下:
毫无疑问,在netty启动过程中动态的添加多个处理器肯定是通过实现 ChannelInitializer 类来实现
public class MyClientInitializer extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
ChannelPipeline pipeline = socketChannel.pipeline();
// todo 顺序
pipeline.addLast(new ProtobufVarint32LengthFieldPrepender());
pipeline.addLast(new ProtobufDecoder(StudentProtobuf.Student.getDefaultInstance()));
pipeline.addLast(new ProtobufVarint32FrameDecoder());
pipeline.addLast(new ProtobufEncoder());
// 自定义的处理器
pipeline.addLast(new MyClientHandler());
}
}
如上代码中的 ProtobufVarint32LengthFieldPrepender 和 ProtobufVarint32FrameDecoder 这两个解码器都能处理半包信息, ProtobufDecoder中的泛型就是消息的实体的类型,表示按照这个类型完成数据的反序列化
踩坑
如上几个处理器的添加顺序中, ProtobufEncoder 这个处理器, 一定的放在处理半包数据的那两个处理器的后面, 不处理半包数据, 就得不到完整的数据, 对不完整的数据进行解码, 就会出现如下的异常

