十种排序方法
什么是算法的稳定性?
简单的说就是一组数经过某个排序算法后仍然能保持他们在排序之前的相对次序就说这个排序方法是稳定的, 比如说,a1,a2,a3,a4四个数, 其中a2=a3,如果经过排序算法后的结果是 a1,a3,a2,a4我们就说这个算法是非稳定的,如果还是原来的顺序a1,a2,a3,a4,我们就会这个算法是稳定的
1.选择排序
选择排序,顾名思义,在循环比较的过程中肯定存在着选择的操作, 算法的思路就是从第一个数开始选择,然后跟他后面的数挨个比较,只要后面的数比它还小,就交换两者的位置,然后再从第二个数开始重复这个过程,最终得到从小到大的有序数组
算法实现:
public static void select(int [] arr){
// 选取多少个标记为最小的数,控制循环的次数
for (int i=0;i<arr.length-1;i++){
int minIndex = i;
// 把当前遍历的数和它后面的数依次比较, 并记录下最小的数的下标
for (int j=i+1;j<arr.length;j++){
// 让标记为最小的数字,依次和它后面的数字比较,一旦后面有更小的,记录下标
if (arr[minIndex]>arr[j]){
// 记录的是下标,而不是着急直接交换值,因为后面可能还有更小的
minIndex=j;
}
}
// 当前最小的数字下标不是一开始我们标记出来的那个,交换位置
if (minIndex!=i){
int temp=arr[minIndex];
arr[minIndex]=arr[i];
arr[i]=temp;
}
}
}
}
时间复杂度: n + n-1 + n-2 + .. + 2 + 1 = n*(n+1)/2 = O(n^2)
稳定性: 比如: 5 8 5 2 7 经过一轮排序后的顺序是2 8 5 5 7, 原来两个5的前后顺序乱了,因此它不稳定
推荐的使用场景: n较小时
辅助存储: 就一个数组,结果是O(1)
2.插入排序
见名知意,在排序的过程中会存在插入的情况,依然是从小到大排序 算法的思路: 选取第二个位置为默认的标准位置,查看当前这个标准位置之前有没有比它还大的元素,如果有的话就通过插入的方式,交换两者的位置,怎么插入呢? 就是找一个中间变量记录当前这个标准位置的值,然后让这个标准位置前面的元素往前移动一个位置,这样现在的标准位置被新移动过来的元素给占了,但是前面空出来一个位置, 于是将这个存放标准值的中间元素赋值给这个空出来的位置,完成排序
代码实现:
/**
* 思路: 从数组的第二个位置开始,选定为标准位置,这样开始的话,可以保证,从标准位置开始往前全部是有序的
* @param arr
*/
private static void insetSort(int[] arr) {
int temp;
// 从第二个开始遍历index=1 , 一共length 个数,一直循环到,最后一个数参加比较, 就是 1 <-> length 次
for (int i=1;i<arr.length;i++){
// 判断大小,要是现在的比上一个小的话,准备遍历当前位置以前的有序数组
if (arr[i] < arr[i-1]){
// 存放当前位置的值
temp=arr[i];
int j;
// 循环遍历当前位置及以前的位置的有序数组,只要是从当前位置开始,前面的数比当前位置的数大,就把这个大的数替插入到当前的位置
// 随着j的减少,实际上每次循环都是前一个插到后一个的位置上
for (j=i-1;j>=0&&temp<arr[j];j--){
arr[j+1]=arr[j];
}
// 直到找出一个数, 不比原来存储的那个当前的位置的大,就把存起来的数,插到这个数的前面
arr[j+1]=temp;
}
}
}
时间复杂度:
- 最好的情况就是: 数组本来就是有序的, 这样算法从第2个位置开始循环n-1次, 时间复杂度就是 n
- 最坏的情况: 外层 n-1次, 内存分别是 1,2,3,4...n-2 ==> (n-2)(n-1)/2 = O(n^2)
- 平均时间复杂度: O(n^2)
稳定性: 从第2个位置开始遍历,标准位之前数组一直是有序的,所以它肯定稳定
辅助存储: O(1)
推荐的使用场景: n大部分有序时
3.冒泡排序
最熟悉的排序方式
- 从零位的数开始,比较总长度-1大轮
- 每一个大轮比较 总长度-1-当前元素的index 小轮
代码实现:
private static void sort(int[] ints) {
System.out.println("length == "+ints.length);
// 控制比较多少轮 0- length-1 一共length个数,最坏比较lenth-1次
for (int i=0;i<ints.length-1;i++){
// 每次都从第一个开始比较,每次比较的时候,最多比较到上次比较的移动的最新的下标的位置,就是 length-0-i
for (int j=0;j<ints.length-1-i;j++){
int temp;
if (ints[j] > ints[j+1]) {
temp=ints[j];
ints[j]=ints[j+1];
ints[j+1]=temp;
}
}
}
}
时间复杂度:
- 做好的情况下: 数组本身就有序,执行的就是最外圈的for循环中的n次
- 最坏的情况: (n-1) + (n-2) + (n-3) +...+ 1 = n(n-1)/2 当n趋近于无限大时, 时间发杂度 趋近于n^2
稳定性: 稳定
辅助存储空间: O(1)
推荐的使用场景: n越小越好
4.归并排序
算法的思路: 先通过递归将一个完整的大数组[5,8,3,6]拆分成小数组, 经过递归作用,最终最小的数组就是[5],[8],[3],[6]
递归到最底层后就会有弹栈的操作,通过这时创建一个临时数组,将这些小数组中的数排好序放到这个临时数组中,再用临时数组中的数替换待排序数组中的内容,实现部分排序, 重复这个过程
/**
* 为什么需要low height 这种参数,而不是通过 arr数组计算出来呢?
* --> 长个心,每当使用递归的时候,关于数组的这种信息写在参数位置上
* @param arr 需要排序的数组
* @param low 从哪里开始
* @param high 排到哪里结束
*/
public static void mergeSort(int[] arr, int low, int high) {
int middle = (high + low) / 2;
if (low < high) {
// 处理左边;
mergeSort(arr, low, middle);
// 处理右边
mergeSort(arr, middle + 1, high);
// 归并
merge(arr, low, middle, high);
}
}
/**
* @param arr
* @param low
* @param middle
* @param high
*/
public static void merge(int[] arr, int low, int middle, int high) {
// 临时数组,存储归并后的数组
int[] temp = new int[high - low + 1];
// 第一个数组开始的下标
int i = low;
// 第二个数组开始遍历的下标
int j = middle + 1;
// 记录临时数组的下标
int index = 0;
// 遍历两个数组归并
while (i <= middle && j <= high) {
if (arr[i] < arr[j]) {
temp[index] = arr[i];
i++;
} else {
// todo 在这里放个计数器++ , 可以计算得出 反序对的个数 (这样的好处就是时间的复杂度是 nlogn)
temp[index] = arr[j];
j++;
}
index++;
}
while (j <= high) {
temp[index] = arr[j];
j++;
index++;
}
while (i <= middle) {
temp[index] = arr[i];
i++;
index++;
}
// 把临时入数组中的数据重新存原数组
for (int x = 0; x < temp.length; x++) {
System.out.println("temp[x]== " + temp[x]);
arr[x + low] = temp[x];
}
}
按上面说的[5,8,3,6]来说,经过递归他们会被分成这样
---------------压栈--------------------
左 右
[5,8] [3,6]
[5] [8] [3] [6]
------------下面的弹栈-----------------
[5]和[8]归并,5<8 得到结果: [5,8]
[3]和[6]归并, 3<6 得到结果 [3,6]
于是经过两轮归并就得到了结果
[5,8] [3,6]
继续归并: 创建一个临时数组 tmp[]
5>3 tmp[0]=3
5<6 tmp[1]=5
8>6 tmp[2]=6
tmp[3]=8
然后让tmp覆盖原数组得到最终结果
推荐使用的场景: n越大越好
时间复杂度: 最好,平均,最坏都是 O(nlogn) (这是基于比较的排序算法所能达到的最高境界)
稳定性能: 稳定
空间复杂度: 每两个有序序列的归并都需要一个临时数组来辅助,因此是 O(N)
5.快速排序
是分支思想的体现, 算法的思路就是每次都选出一个标准值,目标是经过处理,让当前数组中,标准值左边的数都小于标准值, 标准值右边的数都大于标准值, 重复递归下去,最终就能得到有序数组
实现:
// 快速排序
public static void quickSort(int[] arr, int start, int end) {
// 保证递归安全的进行
if (start < end) {
// 1. 找一个中间变量,记录标准值,一般是数组的第一个,以这个标准的值为中心,把数组分成两部分
int standard = arr[start];
// 2. 记录最小的值和最大的值的下标
int low = start;
int high = end;
// 3. 循环比较,只要我的最开始的low下标,小于最大值的下标 就不停的比较
while (low < high) {
System.out.println("high== " + high);
// 从右边开始,如果右边的数字比标准值大,把下标往前动
while (low < high && standard <= arr[high]) {
high--;
}
// 右边的最high的数字比 标准值小, 把当前的high位置的数字赋值给最low位置的数字
arr[low] = arr[high];
// 接着从做low 的位置的开始和标准值比较, 如果现在的low位置的数组比标准值小,下标往后动
while (low < high && arr[low] <= standard ) {
low++;
}
// 如果low位置的数字的比 标准值大,把当前的low位置的数字,赋值给high位置的数字
arr[high] = arr[low];
}
// 把标准位置的数,给low位置的数
arr[low] = standard ;
// 开始递归,分开两个部分递归
// 右部分
quickSort(arr, start, low);
// 左部分
quickSort(arr, low + 1, end);
}
}
推荐使用场景: n越大越好
时间复杂度:
- 最坏: 其实大家可以看到,上面的有三个while,但是每次工作的最多就两个,如果真的就那么不巧,所有的数两两换值,那么最坏的结果和冒泡一样 O(n^2)
- 最好和平均都是: O(nlogn)
稳定性: 快排是不稳定的
6.希尔排序
希尔排序其实可以理解成一种带步长的排序方式, 上面刚说了插入排序的实现方式,上面说我们默认从数组的第二个位置开始算,实际上就是说步长是1,下标的移动每次都是1
对于希尔排序来说,它默认的步长是 arr.length/2 , 每次步长都减少一半, 最终的步长也会是1
代码实现:
/**
* 希尔排序,在插入排序的基础上,添加了步长 ,
* // todo 只要在本步长范围内,这些数字为组成一个组进行 插入排序
* 初始 步长=length/2
* 后来: 步长= 步长/2
* 直到最后: 步长=1; 正宗的插入排序
* @param ints
*/
private static void shellSort(int[] ints) {
// 记录当前的步长
int step=ints.length/2;
// 步长==》控制遍历几轮, 并且每次步长都是上一次的一半大小
for (int i=step;i>0;i/=2){
// 遍历当前步长下面的全部组,这里的j1, 就相当于插入排序中第一次开始的位置1前面的0下标
for (int j1=i;j1<ints.length;j1++){
// 遍历本组中全部元素 == > 从第二个位置开始遍历
// x 就相当于插入排序中第一次开始的位置1
for(int x=j1+i;x<=ints.length-1;x+=i){
// 从当前组的第二个元素开始,一旦发现它前面的元素比他小,
// 插入排序, 1. 把当前的元素存起来 2. 循环它前面的元素往前移 3. 把当前元素插入到合适的位置
if(ints[x]<ints[x-i]){
int temp=ints[x];
int j ;
for(j=x-i;j>=0&&ints[j]>temp;j=j-i)
{
ints[j+i]=ints[j];
}
ints[j+i]=temp;
}
}
}
}
}
空间复杂度: 和插入排序一样都是O(1)
稳定性: 希尔排序由于步长的原因,而不向插入排序,一经开始标准位置前的数组即刻有序, 所以希尔排序是不稳定的
希尔排序的性能无法准确量化,跟输入的数据有很大关系在实际应用中也不会用它,因为十分不稳定,虽然比传统的插入排序快,但比快速排序等慢
其时间复杂度介于O(nlogn) 到 O(n^2) 之间
7.堆排序
堆排序是借助了堆这种数据结构完成的排序方式,堆有大顶堆和小顶堆, 将数组转换成大顶堆然后进行排序的会结果是数组将从小到大排序,小顶堆则相反
什么是堆呢? 堆其实是可以看成一颗完全二叉树的数组对象, 那什么是完全二叉树呢? 比如说, 这颗数的深度是h,那么除了h层外, 其他的1~h-1层的节点都达到了最大的数量
算法的实现思路: 通过递归,将数组看成一个堆,从最后一个非叶子节点开始,将这个节点转换成大顶堆, 什么是大顶堆呢? 就是根节点总是大于它的两个子节点, 重复这个过程一直递归到堆的根节点(此时根节点是最大值),此时整个堆为大顶堆, 然后交换根节点和最后一个叶子节点的位置,将最大值保存起来
例: 假设待排序序列是a[] = {7, 1, 6, 5, 3, 2, 4},并且按大顶堆方式完成排序
- 第一步(构造初始堆):
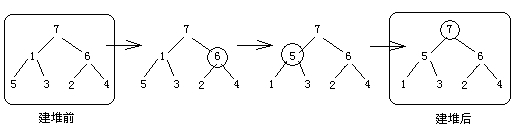
- 第二步(首尾交换,断尾重构):

代码实现:
public static void sort(int[] ints) {
// 开始位置是最后一个非叶子节点
int start = ints.length / 2-1;
// 调整成大顶堆
for (int i = start; i >= 0; i--) {
maxHeap(ints, ints.length, i);
}
// 调整第一个和最后一个数字, 在把剩下的转换为大定堆, j--实现了,不再调整本轮选出的最大的数
for (int j = ints.length - 1; j > 0; j--) {
int temp = ints[0];
ints[0] = ints[j];
ints[j] = temp;
maxHeap(ints, j, 0);
}
}
/**
* 转换为大顶堆, 其实就是比较根节点和两个子节点的大小,调换他们的顺序使得根节点的值大于它的两个子节点
*
* @param arr
* @param size
* @param index 从哪个节点开始调整 (一开始转换为大顶堆时,使用的是最后一个非夜之节点, 但是转换完成之后,使用的就是0,从根节点开始调整)
*/
public static void maxHeap(int[] arr, int size, int index) {
// 当前节点的左子节点
int leftNode = 2 * index + 1;
// 当前节点的右子节点
int rightNode = 2 * index + 2;
// 找出 当前节点和左右两个节点谁最大
int max = index;
if (leftNode < size && arr[leftNode] > arr[max]) {
max = leftNode;
}
if (rightNode < size && arr[rightNode] > arr[max]) {
max = rightNode;
}
// 交换位置
if (max != index) {
int temp = arr[index];
arr[index] = arr[max];
arr[max] = temp;
// 交换位置后,可能破坏之前的平衡(跟节点比左右的节点小),递归
// 有可能会破坏以max为定点的子树的平衡
maxHeap(arr, size, max);
}
}
推荐的使用场景: n越大越好
时间复杂度: 堆排序的效率与快排、归并相同,都达到了基于比较的排序算法效率的峰值(时间复杂度为O(nlogn))
空间复杂度: O(1)
稳定性: 不稳定
基数排序
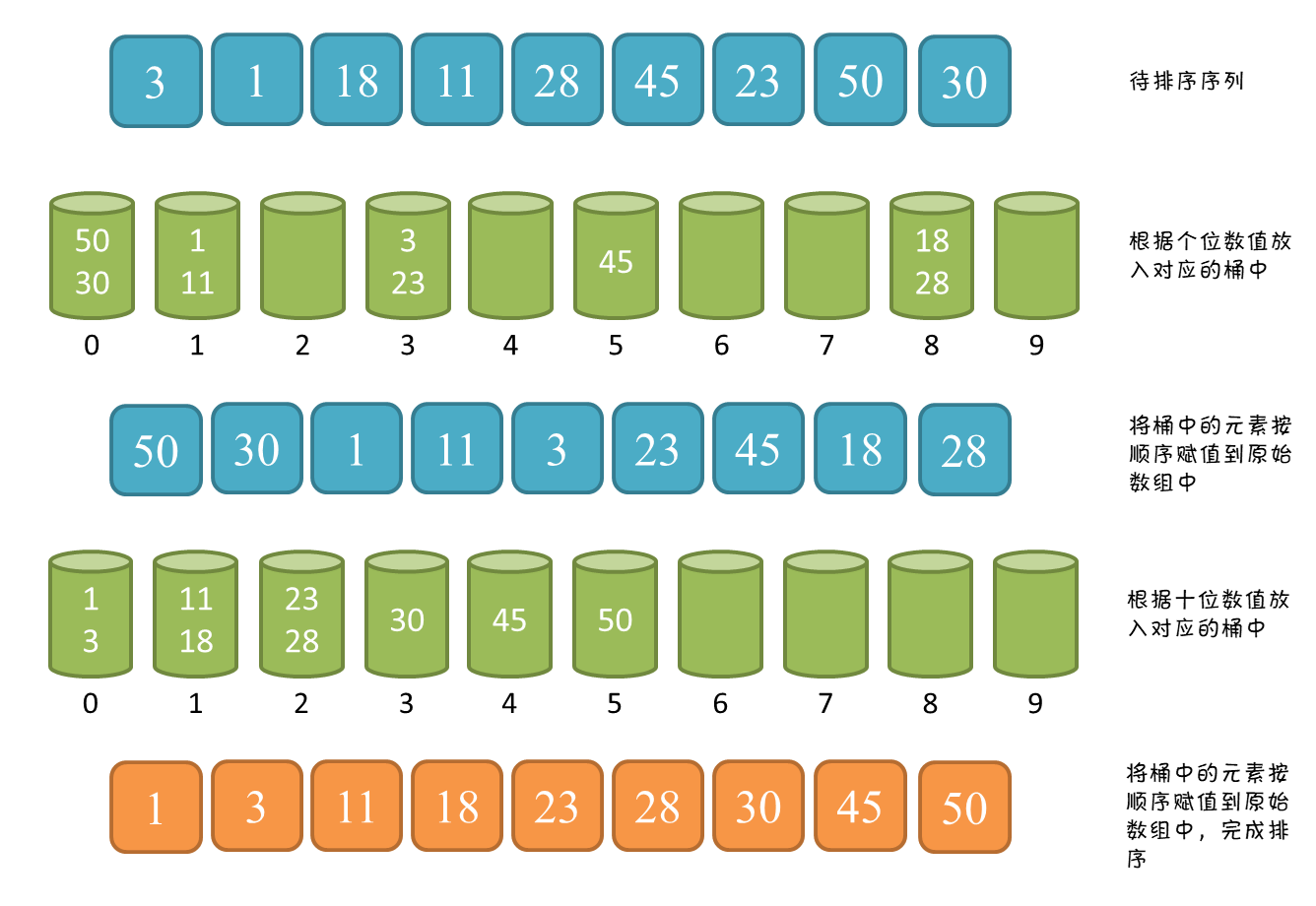
算法思路:
看上图中的绿色部分, 假设我们有下标从0-9,一共10个桶
第一排是给我们排序的一组数
我们分别对取出第一排数的个位数,放入到对应下标中的桶中,再依次取出,就得到了第三行的结果, 再取出三行的十位数,放入到桶中,再取出,就得到最后一行的结果
// 基数排序
// 创建10个数组,索引从0-9
// 第一次按照个位排序
// 第二次按照十位排序
// 第三次按照百位排序
// 排序的次数,就是数组中最大的数的位数
public static void radixSort(int[] arr){
int max = Integer.MIN_VALUE;
// 循环找到最大的数,控制比较的次数
for (int i : arr) {
if (i>max){
max=i;
}
}
System.out.println(" 最大值: "+max);
// 求最大数字的位数,获取需要比较的轮数
int maxLength = (max+"").length();
System.out.println(" 最大串的长度: "+maxLength);
// 创建应用创建临时数据的数组, 整个大数组中存放着10个小数组, 这10个小数组中真正存放的着元素
int [][] temp = new int[10][arr.length]; // 10个 长度为arr.length长度的数组
// todo 用于记录在temp中相应的数组中存放的数字的数量
int [] counts = new int[10];
// 还需要添加另一个变量n 因为我们每轮的排序是从的1 - 10 - 100 - ... 开始求莫排序
for(int i=0,n=1;i<maxLength;i++,n*=10){
// 计算每一个数字的余数,遍历数组,将符合要求的放到指定的数组中
for (int j=0;j<arr.length;j++){
int x = arr[j]/n%10;
// 把当前遍历到的数据放入到指定位置的二维数组中
temp[x][counts[x]] = arr[j];
// 更新二维数组中新更改的数组后的 新长度
counts[x]++;
}
int index =0;
// 把存放进去的数据重新取出来
for (int y=0;y<counts.length;y++){
// 记录数量的那个数组的长度不为零,我们才区取数据
if (counts[y]!=0){
// 循环取出元素
for (int z =0;z<counts[y];z++){
// 取出
arr[index++] = temp[y][z];
}
// 把数量置为0
counts[y]=0;
}
}
}
}
稳定性: 稳定
时间复杂度: 平均、最好、最坏都为O(k*n),其中k为常数,n为元素个数
空间复杂度: O(n+k)
桶排序
算法思路: 相对比较好想, 给我们一组数,我们在选出这组数中最大值和数组的length的长度,选最大的值当成新数组的长度,然后遍历旧的数组,将旧数组中的值放入到新数组中index=旧数组中的值的位置
然后一次遍历旧数组中的值,就能得到最终的结果
代码实现:
private static void sort(int[] ints) {
int max = Integer.MIN_VALUE;
for (int anInt : ints) {
if (anInt>max)
max=anInt;
}
int maxLength = ints.length-max >0 ? ints.length:max;
int[] result = new int[maxLength];
for (int i=0;i<ints.length;i++){
result[ints[i]] +=1 ;
}
for(int i=0 ,index = 0;i<result.length;i++){
if (result[i]!=0){
for (int j=result[i];j>0;j--){
ints[index++] = i;
}
}
}
}
时间复杂度:
- 平均时间复杂度:O(n + k)
- 最佳时间复杂度:O(n + k)
- 最差时间复杂度:O(n^2)
空间复杂度:O(n * k)
稳定性:稳定
典型的用空间换时间的算法
计数排序
算法思路: 根据待排序集合中最大元素和最小元素的差值范围,申请额外空间;
遍历待排序集合,将每一个元素出现的次数记录到元素值对应的额外空间内;
对额外空间内数据进行计算,得出每一个元素的正确位置;
将待排序集合每一个元素移动到计算得出的正确位置上。
代码实现:
public static int[] sort(int[] A) {
//一:求取最大值和最小值,计算中间数组的长度:中间数组是用来记录原始数据中每个值出现的频率
int max = A[0], min = A[0];
for (int i : A) {
if (i > max) {
max = i;
}
if (i < min) {
min = i;
}
}
//二:有了最大值和最小值能够确定中间数组的长度
//存储5-0+1 = 6
int[] pxA = new int[max - min + 1];
//三.循环遍历旧数组计数排序: 就是统计原始数组值出现的频率到中间数组B中
for (int i : A) {
pxA[i - min] += 1;//数的位置 上+1
}
//四.遍历输出
//创建最终数组,就是返回的数组,和原始数组长度相等,但是排序完成的
int[] result = new int[A.length];
int index = 0;//记录最终数组的下标
//先循环每一个元素 在计数排序器的下标中
for (int i = 0; i < pxA.length; i++) {
//循环出现的次数
for (int j = 0; j < pxA[i]; j++) {//pxA[i]:这个数出现的频率
result[index++] = i + min;//原来原来减少了min现在加上min,值就变成了原来的值
}
}
return result;
}
也是典型的用空间换时间的算法
时间复杂度: O(n+k)
空间复杂度: O(n+k)
稳定性: 稳定

