深入理解分布式锁
为什么需要分布式锁
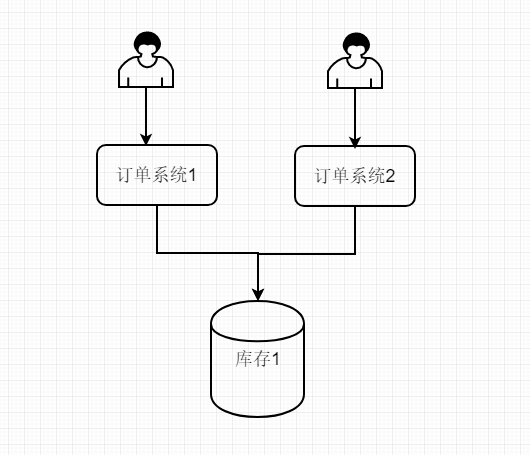
如上图,在分布式系统中,订单模块为了迎战高并发,订单服务被横向拆分,拆分成了不同的进程,就像上图,两个人同时访问订单服务,然后订单系统1和订单系统2共用一个Mysql当成数据库,经过他们查询发现仅有一件商品,所以他们自个认为都可以下单
如果不加锁限制,可能会出现库存减为负数的情况
怎么办呢?
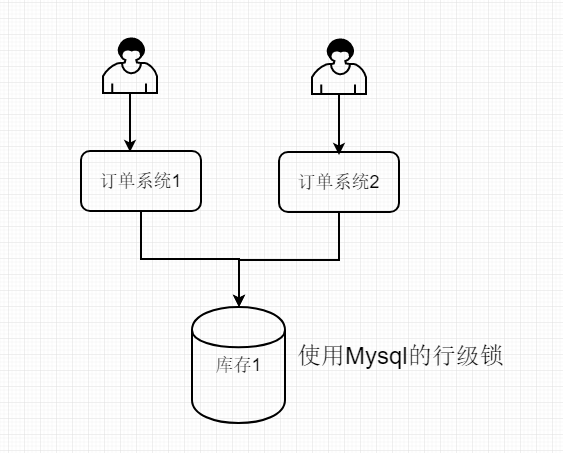
如上图
mysql自带行级锁,可以考虑使用它的行级锁,可以保证数据的安全,但是不足之处也跟着来了,使用MySql的行级锁,系统的中压力就全部集中在mysql,那mysql就是系统吞吐量的瓶颈了,系统的吞吐量也会收到mysql的限制
可以使用分布式锁
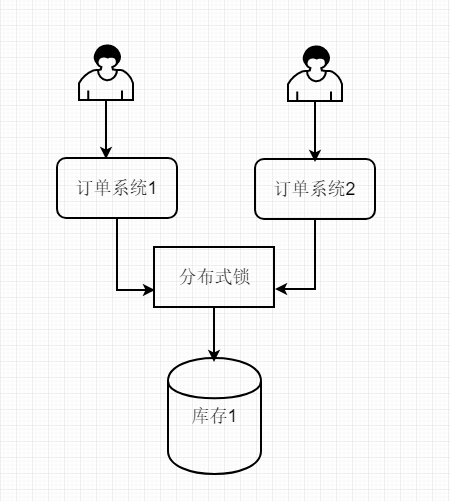
如上图,分布式锁将系统的压力从mysql上面转移到自己身上来
什么是分布式锁
一句话,分布式锁是实现有序调度不同的进程,解决不同进程之间相互干扰的问题的技术手段
分布式锁的应具备的条件
- 在分布式系统环境下,分布式锁在同一个时间仅能被同一个进程访问
- 高可用的获取/释放锁
- 高性能的获取/释放锁
- 具备锁的重入性
- 具备锁的失效机制,防止死锁
- 具备非阻塞锁的特性,即使没有获取锁也能直接返回结果
分布式锁的实现有哪些
- mechache: 利用mechache的add命令,改命令是原子性的操作,只有在key 不存在的情况下,才能add成功,也就意味着线程拿到了锁
- Redis: 和Mechache的实现方法相似,利用redis的setnx命令,此命令同样是原子性的操作,只有在key不存在的情况下,add成功
- zookeeper利用他的顺序临时节点,来实现分布式锁和等待队列,zookeeper的设计初衷就是为了实现分布式微服务的
使用Redis实现分布式锁的思路
- 先去redis中使用setnx(商品id,数量) 得到返回结果
- 这里的数量无所谓,它的作用就是告诉其他服务,我加上了锁
- 发现redis中有数量,说明已经可以加锁了
- 发现redis中没有数据,说明已经获得到了锁
- 解锁: 使用redis的 del商品id
- 锁超时, 设置exprie 生命周期,如30秒, 到了指定时间,自定解锁
三个致命问题
- 非原子性操作
- setnx
- 宕机
- expire
因为 setnx和expire不是原子性的,要么都成功要么都失败, 一旦出现了上面的情况,就会导致死锁出现
redis提供了原子性的操作 set ( key , value , expire)
- 误删锁
- 假如我们的锁的生命事件是30秒,结果我在30s内没操作完,但是锁被释放了
- jvm2拿到了锁进行操作
- jvm1 操作完成使用del,结果把jvm2 的锁删除了
解决方法, 在删除之前,判断是不是自己的锁
redis提供了原子性的操作 set ( key ,threadId, expire)
- 超时为完成任务
增加一个守护线程,当快要超时,但是任务还没执行完成,就增加锁的时间
使用ZooKeeper实现分布式锁的思路
使用ZooKeeper的临时顺序节点
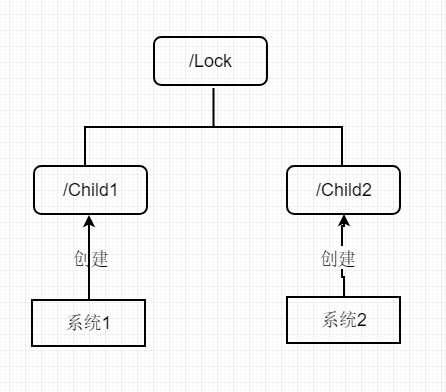
系统1和系统2在执行业务逻辑之前都需要先获取到锁,然后他们就是/Lock节点下创建临时顺序节点,序号最小的节点的创建者视为获取到了锁,可以进行其他业务操作,当它执行完成后,将这个节点删除掉视为释放了锁
释放锁后如何通知其他节点呢?
使用ZK的watcher回调机制, 让后一个节点对它的前一个临时顺序节点绑定watcher,当有事务性操作时发生回调,进而判断出自己刚才创建的节点是不是最小的,如果是说明自己拿到了锁
临时顺序节点保证了系统不会因为某台机器挂掉而出现死锁的情况
尝试加锁的方法如下:
public boolean tryLock() {
String path = LOCKNAME + "/zk_";
try {
// todo 判断父节点存在否, 不存在就先创建
// 创建临时顺序节点
currentNode.set(zooKeeper.get().create(path, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL));
// 获取指定的根节点下所有的 临时顺序节点
List<String> names = zooKeeper.get().getChildren(LOCKNAME, false);
// 获取到的是子节点的 pathName
Collections.sort(names);
String minName = names.get(0);
if (currentNode.get().equals(LOCKNAME + "/" + minName)) {
return true;
} else {
// 监听前一个节点
int currentNodeIndex = names.indexOf(currentNode.get().substring(currentNode.get().lastIndexOf("/")+1));
// 当前节点的前一个节点的名字
String preNodeName = names.get(currentNodeIndex - 1);
// 阻塞
CountDownLatch countDownLatch = new CountDownLatch(1);
zooKeeper.get().exists(LOCKNAME + "/" + preNodeName, new Watcher() {
@Override
public void process(WatchedEvent event) {
// 监听当前节点的删除事件
if (Event.EventType.NodeDeleted.equals(event.getType())) {
countDownLatch.countDown();
}
}
});
// 在countDownLatch减完之前,会阻塞在这里等待
countDownLatch.await();
return true;
}
} catch (Exception e) {
e.printStackTrace();
}
// 按理说应该在监听的回调里面返回true,但是在这个回调里面返回不了true,现在就使用countDownLatch,回调的时候去改变countDownLatch的值
return true;
}

