深入理解 ZK集群如何保证数据一致性
什么是数据一致性?#
只有当服务端的ZK存在多台时,才会出现数据一致性的问题, 服务端存在多台服务器,他们被划分成了不同的角色,只有一台Leader,多台Follower和多台Observer, 他们中的任意一台都能响应客户端的读请求,任意一台也都能接收写请求, 不同的是,Follower和Observer接收到客户端的写请求后不能直接处理这个请求而是将这个请求转发给Leader,由Leader发起原子广播完成数据一致性
理论上ZK集群中的每一个节点的作用都是相同的,他们应该和单机时一样,各个节点存放的数据保持一致才行
Leader接收到Follower转发过来的写请求后发起提议,要求每一个Follower都对这次写请求进行投票Observer不参加投票,继续响应client的读请求),Follower收到请求后,如果认为可以执行写操作,就发送给leader确认ack, 这里存在一个过半机制,就是说,在Leader发起的这次请求中如果存在一半以上的Follower响应了ack,Leader就认为这次的写操作通过了决议,向Follower发送commit,让它们把最新的操作写进自己的文件系统
还有新添加一台ZK服务器到集群中,也面临着数据一致性的问题,它需要去Leader中读取同步数据
Zab协议(ZooKeeper Atomic Brocadcast)#
什么是Zab协议#
Zab协议是一个分布式一致性算法,让ZK拥有了崩溃恢复和原子广播的能力,进而保证集群中的数据一致性
ZK对Zab的协议的实现架构: 主备模型,任何Learner节点接收到非事务请求查询本地缓存然后返回,任何事务操作都需要转发给Leader,由Leader发起决议,同集群中超过半数的Follower返回确认ack时,Leader进行广播,要求全部节点提交事务
特性:#
- 保证在leader上提交的事务最终被所有的服务器提交
- 保证丢弃没有经过半数检验的事务
Zab协议的作用#
- 使用一个单独的进程,保持leader和Learner之间的socket通信,阅读源码这个Thread就是learnerHandler,任何写请求都将由Leader在集群中进行原子广播事务
- 保证了全部的变更序列在全局被顺序引用,写操作中都需要先check然后才能写,比如我们向create /a/b 它在创建b时,会先检查a存在否? 而且,事务性的request存在于队列中,先进先出,保证了他们之间的顺序
Zab协议原理#
- 选举: 在Follower中选举中一个Leader
- 发现: Leader中会维护一个Follower的列表并与之通信
- 同步: Leader会把自己的数据同步给Follower, 做到多副本存储,体现了CAP的A和P 高可用和分区容错
- 广播: Leader接受Follower的事务Proposal,然后将这个事务性的proposal广播给其他learner
Zab协议内容#
当整个集群启动过程中,或者当 Leader 服务器出现网络中弄断、崩溃退出或重启等异常时,Zab协议就会 进入崩溃恢复模式,选举产生新的Leader。
当选举产生了新的 Leader,同时集群中有过半的机器与该 Leader 服务器完成了状态同步(即数据同步)之后,Zab协议就会退出崩溃恢复模式,进入消息广播模式。
当Leader出现崩溃退出或者机器重启,亦或是集群中不存在超过半数的服务器与Leader保存正常通信,Zab就会再一次进入崩溃恢复,发起新一轮Leader选举并实现数据同步。同步完成后又会进入消息广播模式,接收事务请求
源码入口#
单机版本还是集群版本的启动流程中,前部分几乎是相同的,一直到QuorumPeerMain.java的initializeAndRun()方法,单机模式下运行的是 ZooKeeperServerMain.main(args);, 集群模式下,运行的是 runFromConfig(config);
因此当前博客从QuorumPeerMain的runFromConfig()开始
其中的QuorumPeer.java可以看成ZK集群中的每一个server实体,下面代码大部分篇幅是在当前server的属性完成初始化
// todo 集群启动的逻辑
public void runFromConfig(QuorumPeerConfig config) throws IOException {
try {
ManagedUtil.registerLog4jMBeans();
} catch (JMException e) {
LOG.warn("Unable to register log4j JMX control", e);
}
LOG.info("Starting quorum peer");
try {
ServerCnxnFactory cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns());
// todo new QuorumPeer() 可以理解成, 创建了集群中的一个server
quorumPeer = getQuorumPeer();
// todo 将配置文件中解析出来的文件原封不动的赋值给我们的new 的QuorumPeer
quorumPeer.setQuorumPeers(config.getServers());
quorumPeer.setTxnFactory(new FileTxnSnapLog(
new File(config.getDataLogDir()),
new File(config.getDataDir())));
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId());
quorumPeer.setTickTime(config.getTickTime());
quorumPeer.setInitLimit(config.getInitLimit());
quorumPeer.setSyncLimit(config.getSyncLimit());
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
quorumPeer.setCnxnFactory(cnxnFactory);
quorumPeer.setQuorumVerifier(config.getQuorumVerifier());
quorumPeer.setClientPortAddress(config.getClientPortAddress());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
// sets quorum sasl authentication configurations
quorumPeer.setQuorumSaslEnabled(config.quorumEnableSasl);
if(quorumPeer.isQuorumSaslAuthEnabled()){
quorumPeer.setQuorumServerSaslRequired(config.quorumServerRequireSasl);
quorumPeer.setQuorumLearnerSaslRequired(config.quorumLearnerRequireSasl);
quorumPeer.setQuorumServicePrincipal(config.quorumServicePrincipal);
quorumPeer.setQuorumServerLoginContext(config.quorumServerLoginContext);
quorumPeer.setQuorumLearnerLoginContext(config.quorumLearnerLoginContext);
}
quorumPeer.setQuorumCnxnThreadsSize(config.quorumCnxnThreadsSize);
quorumPeer.initialize();
// todo 着重看这个方法
quorumPeer.start();
quorumPeer.join();
跟进quorumPeer.start()方法,源码如下, 主要做了如下几件事
- 数据恢复
- 经过上下文的工厂,启动这个线程类,使当前的server拥有接受client请求的能力(但是RequestProcessor没有初始化,因此它能接受request,却不能处理request)
- 选举Leader,在这个过程中会在Follower中选举出一个leader,确立好集群中的 Leader,Follower,Observer的三大角色
- 启动当前线程类
QuorumPeer.java
@Override
public synchronized void start() {
// todo 从磁盘中加载数据到内存中
loadDataBase();
// todo 启动上下文的这个工厂,他是个线程类, 接受客户端的请求
cnxnFactory.start();
// todo 开启leader的选举工作
startLeaderElection();
// todo 确定服务器的角色, 启动的就是当前类的run方法在900行
super.start();
}
看一下QuorumPeer.java的run方法,部分源码如下,逻辑很清楚通过了上面的角色的选举之后,集群中各个节点的角色已经确定下来了,那拥有不同角色的节点就会进入下面代码中不同的case分支中
- looking : 正在进行领导者的选举
- observer: 观察者
- leading : 集群的leader
- following: 集群的Follower
while (running) {
switch (getPeerState()) {
case LOOKING:
LOG.info("LOOKING");
if (Boolean.getBoolean("readonlymode.enabled")) {
LOG.info("Attempting to start ReadOnlyZooKeeperServer");
// Create read-only server but don't start it immediately
final ReadOnlyZooKeeperServer roZk = new ReadOnlyZooKeeperServer(
logFactory, this,
new ZooKeeperServer.BasicDataTreeBuilder(),
this.zkDb);
Thread roZkMgr = new Thread() {
public void run() {
try {
// lower-bound grace period to 2 secs
sleep(Math.max(2000, tickTime));
if (ServerState.LOOKING.equals(getPeerState())) {
roZk.startup();
}
} catch (InterruptedException e) {
LOG.info("Interrupted while attempting to start ReadOnlyZooKeeperServer, not started");
} catch (Exception e) {
LOG.error("FAILED to start ReadOnlyZooKeeperServer", e);
}
}
};
try {
roZkMgr.start();
setBCVote(null);
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
setPeerState(ServerState.LOOKING);
} finally {
roZkMgr.interrupt();
roZk.shutdown();
}
} else {
try {
setBCVote(null);
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
}
}
break;
case OBSERVING:
try {
LOG.info("OBSERVING");
setObserver(makeObserver(logFactory));
observer.observeLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e );
} finally {
observer.shutdown();
setObserver(null);
setPeerState(ServerState.LOOKING);
}
break;
case FOLLOWING:
// todo server 当选follow角色
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
follower.shutdown();
setFollower(null);
setPeerState(ServerState.LOOKING);
}
break;
case LEADING:
// todo 服务器成功当选成leader
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory));
// todo 跟进lead
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
setPeerState(ServerState.LOOKING);
}
break;
}
}
下面看一下,server当选成不同的角色后,后干了什么
总览Leader&Follower#
当选成Leader#
跟进源码,上面代码片段中makeLeader() 由这个方法创建了一个Leader的封装类
protected Leader makeLeader(FileTxnSnapLog logFactory) throws IOException {
// todo 跟进它的Leader 构造方法
return new Leader(this, new LeaderZooKeeperServer(logFactory,
this,new ZooKeeperServer.BasicDataTreeBuilder(), this.zkDb));
}
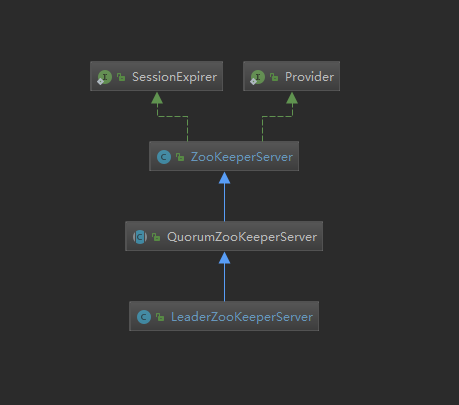
这是LeaderZooKeeperServer的继承图,可以看到其实他继承了单机模式下的ZKServer
调用leader.lead()方法,这个方法主要做了如下几件事
- 创建了
StateSummary对象- 这个对象封装了
zxid以及currentEpoch, 其中zxid就是最后一次和znode相关的事务id,后者是当前的epoch它有64位,高32位标记是第几代Leader,后32位是当前代leader提交的事务次数,Follower只识别高版本的前32位为Leader
- 这个对象封装了
- 针对每一个Learner都开启了一条新的线程
LearnerCnxAcceptor,这条线程负责Leader和Learner(Observer+Follower)之间的IO交流 - 在
LearnerCnxAcceptor的run()方法中,只要有新的连接来了,新开启了一条新的线程,LearnerHander,由他负责Leader中接受每一个参议员的packet,以及监听新连接的到来 - leader启动...
void lead() throws IOException, InterruptedException {
zk.registerJMX(new LeaderBean(this, zk), self.jmxLocalPeerBean);
try {
self.tick.set(0);
zk.loadData();
// todo 创建了 封装有状态比较逻辑的对象
leaderStateSummary = new StateSummary(self.getCurrentEpoch(), zk.getLastProcessedZxid());
// todo 创建一个新的线程,为了新的 followers 来连接
cnxAcceptor = new LearnerCnxAcceptor();
cnxAcceptor.start();
readyToStart = true;
// todo
long epoch = getEpochToPropose(self.getId(), self.getAcceptedEpoch());
zk.setZxid(ZxidUtils.makeZxid(epoch, 0));
synchronized(this){
lastProposed = zk.getZxid();
}
newLeaderProposal.packet = new QuorumPacket(NEWLEADER, zk.getZxid(),
null, null);
if ((newLeaderProposal.packet.getZxid() & 0xffffffffL) != 0) {
LOG.info("NEWLEADER proposal has Zxid of "
+ Long.toHexString(newLeaderProposal.packet.getZxid()));
}
waitForEpochAck(self.getId(), leaderStateSummary);
self.setCurrentEpoch(epoch);
try {
waitForNewLeaderAck(self.getId(), zk.getZxid());
} catch (InterruptedException e) {
shutdown("Waiting for a quorum of followers, only synced with sids: [ "
+ getSidSetString(newLeaderProposal.ackSet) + " ]");
HashSet<Long> followerSet = new HashSet<Long>();
for (LearnerHandler f : learners)
followerSet.add(f.getSid());
if (self.getQuorumVerifier().containsQuorum(followerSet)) {
LOG.warn("Enough followers present. "
+ "Perhaps the initTicks need to be increased.");
}
Thread.sleep(self.tickTime);
self.tick.incrementAndGet();
return;
}
// todo 启动server
startZkServer();
String initialZxid = System.getProperty("zookeeper.testingonly.initialZxid");
if (initialZxid != null) {
long zxid = Long.parseLong(initialZxid);
zk.setZxid((zk.getZxid() & 0xffffffff00000000L) | zxid);
}
if (!System.getProperty("zookeeper.leaderServes", "yes").equals("no")) {
self.cnxnFactory.setZooKeeperServer(zk);
}
boolean tickSkip = true;
while (true) {
Thread.sleep(self.tickTime / 2);
if (!tickSkip) {
self.tick.incrementAndGet();
}
HashSet<Long> syncedSet = new HashSet<Long>();
// lock on the followers when we use it.
syncedSet.add(self.getId());
for (LearnerHandler f : getLearners()) {
// Synced set is used to check we have a supporting quorum, so only
// PARTICIPANT, not OBSERVER, learners should be used
if (f.synced() && f.getLearnerType() == LearnerType.PARTICIPANT) {
syncedSet.add(f.getSid());
}
f.ping();
}
// check leader running status
if (!this.isRunning()) {
shutdown("Unexpected internal error");
return;
}
if (!tickSkip && !self.getQuorumVerifier().containsQuorum(syncedSet)) {
//if (!tickSkip && syncedCount < self.quorumPeers.size() / 2) {
// Lost quorum, shutdown
shutdown("Not sufficient followers synced, only synced with sids: [ "
+ getSidSetString(syncedSet) + " ]");
// make sure the order is the same!
// the leader goes to looking
return;
}
tickSkip = !tickSkip;
}
} finally {
zk.unregisterJMX(this);
}
}
当选成Follower#
通过上面的case分支进入FOLLOWING块,进入followerLeader方法
下面的Follower.java中的代码的主要逻辑:
- 和Leader建立起连接
registerWithLeader()注册进LeadersyncWithLeader()从Leader中同步数据并完成启动- 在
while(true){...}中接受leader发送过来的packet,处理packet
void followLeader() throws InterruptedException {
fzk.registerJMX(new FollowerBean(this, zk), self.jmxLocalPeerBean);
try {
// todo 找出LeaderServer
QuorumServer leaderServer = findLeader();
try {
// todo 和Leader建立连接
connectToLeader(leaderServer.addr, leaderServer.hostname);
// todo 注册在leader上(会往leader上发送数据)
//todo 这个Epoch代表当前是第几轮选举leader, 这个值给leader使用,由leader从接收到的最大的epoch中选出最大的,然后统一所有learner中的epoch值
long newEpochZxid = registerWithLeader(Leader.FOLLOWERINFO);
long newEpoch = ZxidUtils.getEpochFromZxid(newEpochZxid);
if (newEpoch < self.getAcceptedEpoch()) {
LOG.error("Proposed leader epoch " + ZxidUtils.zxidToString(newEpochZxid)
+ " is less than our accepted epoch " + ZxidUtils.zxidToString(self.getAcceptedEpoch()));
throw new IOException("Error: Epoch of leader is lower");
}
// todo 从leader同步数据, 同时也是在这个方法中完成初始化启动的
syncWithLeader(newEpochZxid);
QuorumPacket qp = new QuorumPacket();
// todo 在follower中开启无线循环, 不停的接收服务端的pakcet,然后处理packet
while (this.isRunning()) {
readPacket(qp);
// todo (接受leader发送的提议)
processPacket(qp);
}
} catch (Exception e) {
LOG.warn("Exception when following the leader", e);
try {
sock.close();
} catch (IOException e1) {
e1.printStackTrace();
}
// clear pending revalidations
pendingRevalidations.clear();
}
} finally {
zk.unregisterJMX((Learner)this);
}
}
Leader&Follower交互的细节流程#
这部分的逻辑流程图如下
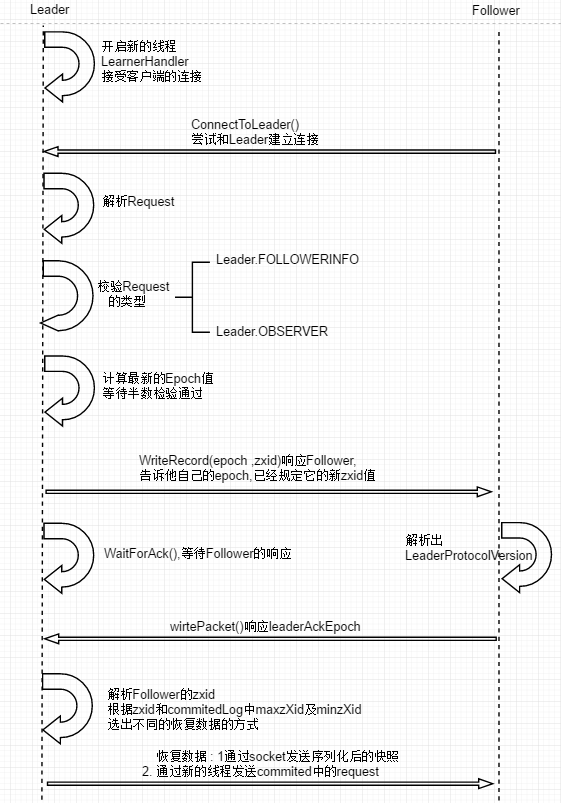
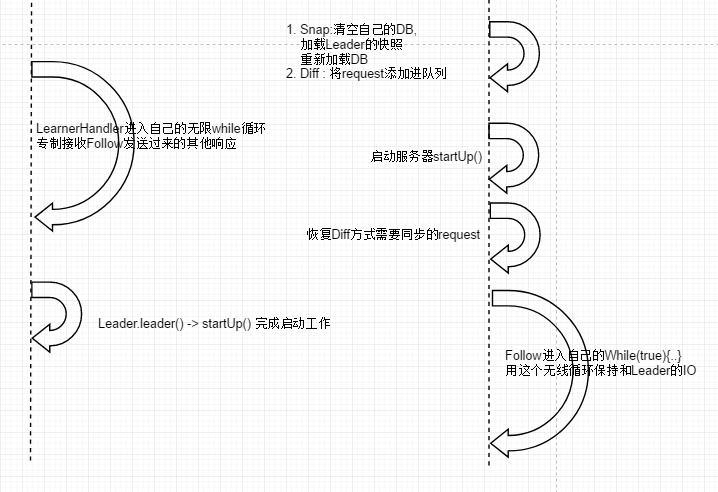
Follower同Leader之间建立起Socket长连接#
- 在Follower中源码如下, 尝试五次和Leader建立连接,重试五次后放弃
protected void connectToLeader(InetSocketAddress addr, String hostname)
throws IOException, ConnectException, InterruptedException {
sock = new Socket();
sock.setSoTimeout(self.tickTime * self.initLimit);
for (int tries = 0; tries < 5; tries++) {
try {
sock.connect(addr, self.tickTime * self.syncLimit);
sock.setTcpNoDelay(nodelay);
break;
} catch (IOException e) {
if (tries == 4) {
LOG.error("Unexpected exception",e);
throw e;
} else {
LOG.warn("Unexpected exception, tries="+tries+
", connecting to " + addr,e);
sock = new Socket();
sock.setSoTimeout(self.tickTime * self.initLimit);
}
}
Thread.sleep(1000);
}
self.authLearner.authenticate(sock, hostname);
leaderIs = BinaryInputArchive.getArchive(new BufferedInputStream(
sock.getInputStream()));
bufferedOutput = new BufferedOutputStream(sock.getOutputStream());
leaderOs = BinaryOutputArchive.getArchive(bufferedOutput);
}
- 在Leader中等待建立连接, 每当向上面有客户端请求和Leader建立连接,就在如下的run()逻辑中的
LearnerHandler()为每一条新的连接开启一条新的线程
Leader.java
@Override
public void run() {
try {
while (!stop) {
// todo 下面的主要逻辑就是,在当前线程中轮询,只要有一条连接进来就单独开启一条线程(LearnerHandler)
try{
// todo 从serversocket中获取连接
Socket s = ss.accept();
// start with the initLimit, once the ack is processed in LearnerHandler switch to the syncLimit
// todo 从initlimit开始,在learnerhandler中处理ack之后,切换到synclimit
s.setSoTimeout(self.tickTime * self.initLimit);
s.setTcpNoDelay(nodelay);// todo 禁用delay算法
// todo 读取socket中的数据
BufferedInputStream is = new BufferedInputStream(s.getInputStream());
// todo 创建处理所有leanner信息的 handler,他也线程类
LearnerHandler fh = new LearnerHandler(s, is, Leader.this);
fh.start();
Follower向Leader发送注册消息#
protected long registerWithLeader(int pktType) throws IOException{
/*
* Send follower info, including last zxid and sid
*/
long lastLoggedZxid = self.getLastLoggedZxid();
QuorumPacket qp = new QuorumPacket();
qp.setType(pktType);
qp.setZxid(ZxidUtils.makeZxid(self.getAcceptedEpoch(), 0));
/*
* Add sid to payload
*/
LearnerInfo li = new LearnerInfo(self.getId(), 0x10000);
ByteArrayOutputStream bsid = new ByteArrayOutputStream();
BinaryOutputArchive boa = BinaryOutputArchive.getArchive(bsid);
boa.writeRecord(li, "LearnerInfo");
qp.setData(bsid.toByteArray());
// todo 往leader发送数据
writePacket(qp, true);
readPacket(qp);
LearnerHandler接收数据#
下面的接受解析请求的逻辑,learner接收到Follower的注册响应后首先是从请求中,将request解析出来, 然后验证一下,如果不是Leader.FOLLOWERINFO 或者是Leader.Observer 类型的直接返回了,如果是接着往下处理
引出了epoch的概念,它全长64位,前32位代表的是第几代Leader,因为网络或者其他原因,leader是可能挂掉的,Leader有属于自己的一个epoch编号,从1,2..开始,一旦Leader挂了,从新选出来的Leader的epoch就会更新,肯定会比原来老leader的epoch值大, 后32位标记的就是当前leader发起的第几次决议
看它是怎么处理的,通过代码,它会选出所有的Follower中最大的epoch值,并且在此基础上+1,作为最新的epoch值,当然这是Leader自己选出来的值,那Follower能不能同意这个值呢?,跟进leader.getEpochToPropose(this.getSid(), lastAcceptedEpoch);,它里面使用了过半检查机制,不满足半数检验就会wait(), 那什么时候唤醒呢? 其实只要集群中再有其他的Follower启动,会重复执行以上的逻辑,再次来到这个方法进行半数检验,就有可能唤醒
if (connectingFollowers.contains(self.getId()) && verifier.containsQuorum(connectingFollowers)) {
waitingForNewEpoch = false;
self.setAcceptedEpoch(epoch);
connectingFollowers.notifyAll();
} else {
long start = Time.currentElapsedTime();
long cur = start;
long end = start + self.getInitLimit()*self.getTickTime();
while(waitingForNewEpoch && cur < end) {
connectingFollowers.wait(end - cur);
cur = Time.currentElapsedTime();
}
if (waitingForNewEpoch) {
throw new InterruptedException("Timeout while waiting for epoch from quorum");
}
}
再往后,leader向Follower发送确认ack,包含最新的epoch+zxid,告诉Follower以后它的事务就从这个zxid开始,这个ack的header= Leader.LEADERINFO
发送完成之后,leader开始等待Follower的响应的ack
public void run() {
try {
leader.addLearnerHandler(this);
tickOfNextAckDeadline = leader.self.tick.get()
+ leader.self.initLimit + leader.self.syncLimit;
ia = BinaryInputArchive.getArchive(bufferedInput);
bufferedOutput = new BufferedOutputStream(sock.getOutputStream());
oa = BinaryOutputArchive.getArchive(bufferedOutput);
QuorumPacket qp = new QuorumPacket();
// todo 读取follower发送过来的数据
ia.readRecord(qp, "packet");
// todo 第一次Follower发送的注册请求的header = Leader.FOLLOWERINFO
// todo leader 遇到非FOLLOWERINFO的 和 OBSERVERINFO的消息直接返回
if(qp.getType() != Leader.FOLLOWERINFO && qp.getType() != Leader.OBSERVERINFO){
LOG.error("First packet " + qp.toString()
+ " is not FOLLOWERINFO or OBSERVERINFO!");
return;
}
.
.
.
//获取出Follower中最后一次epoch
long lastAcceptedEpoch = ZxidUtils.getEpochFromZxid(qp.getZxid());
long peerLastZxid;
StateSummary ss = null;
long zxid = qp.getZxid();
// todo leader用当前方法从众多follower中选出epoch值最大的(而且还会再最大的基础上加1)
// todo this.getSid()指定的 learner 的myid
// todo this.getSid()指定的 learner 的lastAcceptedEpoch
long newEpoch = leader.getEpochToPropose(this.getSid(), lastAcceptedEpoch);
.
.
.
} else {
byte ver[] = new byte[4];
ByteBuffer.wrap(ver).putInt(0x10000);
// todo leader接收到learner的数据之后,给learnner 发送LEADERINFO类型的响应
// todo 返回了最新的epoch
QuorumPacket newEpochPacket = new QuorumPacket(Leader.LEADERINFO, ZxidUtils.makeZxid(newEpoch, 0), ver, null);
oa.writeRecord(newEpochPacket, "packet");
bufferedOutput.flush();
QuorumPacket ackEpochPacket = new QuorumPacket();
ia.readRecord(ackEpochPacket, "packet");
if (ackEpochPacket.getType() != Leader.ACKEPOCH) {
LOG.error(ackEpochPacket.toString()
+ " is not ACKEPOCH");
return;
}
ByteBuffer bbepoch = ByteBuffer.wrap(ackEpochPacket.getData());
ss = new StateSummary(bbepoch.getInt(), ackEpochPacket.getZxid());
// todo 等待learner的响应ack
leader.waitForEpochAck(this.getSid(), ss);
}
Follower接收leader的信息,并发送响应#
Follower获取到leader的响应信息,解析出当前leader的 leaderProtocolVersion,然后给leader发送 header=Leader.ACKEPOCH的ack
protected long registerWithLeader(int pktType) throws IOException{
.
.
.
.
readPacket(qp);
final long newEpoch = ZxidUtils.getEpochFromZxid(qp.getZxid());
if (qp.getType() == Leader.LEADERINFO) {
// we are connected to a 1.0 server so accept the new epoch and read the next packet
leaderProtocolVersion = ByteBuffer.wrap(qp.getData()).getInt();
byte epochBytes[] = new byte[4];
final ByteBuffer wrappedEpochBytes = ByteBuffer.wrap(epochBytes);
if (newEpoch > self.getAcceptedEpoch()) {
wrappedEpochBytes.putInt((int)self.getCurrentEpoch());
self.setAcceptedEpoch(newEpoch);
} else if (newEpoch == self.getAcceptedEpoch()) {
// since we have already acked an epoch equal to the leaders, we cannot ack
// again, but we still need to send our lastZxid to the leader so that we can
// sync with it if it does assume leadership of the epoch.
// the -1 indicates that this reply should not count as an ack for the new epoch
wrappedEpochBytes.putInt(-1);
} else {
throw new IOException("Leaders epoch, " + newEpoch + " is less than accepted epoch, " + self.getAcceptedEpoch());
}
QuorumPacket ackNewEpoch = new QuorumPacket(Leader.ACKEPOCH, lastLoggedZxid, epochBytes, null);
writePacket(ackNewEpoch, true);
return ZxidUtils.makeZxid(newEpoch, 0);
Leader接收到Follower的ack后,开始同步数据的逻辑#
看一下,如果Follower中最后一次的事务id和leader中的事务id值相同的话,说明没有数据可以同步
在看单机版本的ZKServer启动时,可以发现,在FinalRequestProcessor中存在一个commitedlog集合,这个集合中的存放着已经被持久化了的request,它的作用就是为了给当前Follower同步数据使用,因为Follower可以通过Leader最近的一次快照快速回复数据,但是快照是不定时打一次的,这就有可能出现缺失数据,所以搞了个commitedlog
用法:
-
查看当前Follower的zxid是不是处于
commitedlog集合中,最大的和最下的zxid之间,在这之间的话就说明从当前的Follower的zxid到commitedlog中最大的zxid之间的request中,都需要执行一遍,这种方式就称为Leader.DIFF,仅仅同步不一样的- 第一点: 并没有挨个发送同步的请求,而是把他们放到一个集合中,统一发送
- QuorumPacket的类型是
Leader.COMMIT, Follower接收到这个commit之后,直接会提交同步这个集合中的request,完成数据的同步操作
-
查看Follower中最后一次的zxid比Leader中的最大的zxid事务id还大,不管37 21 直接要求Follower将超过Leader的部分trunc,说白了就是删除掉
-
如果Follower中最大的zxid比leader中最小的zxid还小,使用快照的同步方式
区别:
快照中数据序列化后,使用Socket发送到Follower
给Follower发送同步数据的命令是通过下面方法中的一条单独的线程完成的
if (peerLastZxid == leader.zk.getZKDatabase().getDataTreeLastProcessedZxid()) {
// Follower is already sync with us, send empty diff
LOG.info("leader and follower are in sync, zxid=0x{}",
Long.toHexString(peerLastZxid));
packetToSend = Leader.DIFF;
zxidToSend = peerLastZxid;
} else if (proposals.size() != 0) {
.
.
.
if ((maxCommittedLog >= peerLastZxid) && (minCommittedLog <= peerLastZxid)) {
LOG.debug("Sending proposals to follower");
// as we look through proposals, this variable keeps track of previous proposal Id.
// todo 当我们查看以前的建议时,这个变量存放的是之前最小的 建议id
long prevProposalZxid = minCommittedLog;
// Keep track of whether we are about to send the first packet.
// todo 跟踪我们是否要发送第一个包
// Before sending the first packet, we have to tell the learner
//todo 在我们发送第一个包之前, 我们要告诉leanner是期待一个 trunc 还是一个 diff
// whether to expect a trunc or a diff
boolean firstPacket=true;
// If we are here, we can use committedLog to sync with follower. Then we only need to decide whether to send trunc or not
// todo 当我们执行到这里了,我们使用 committedLog 来给Follower提供数据同步
packetToSend = Leader.DIFF;
zxidToSend = maxCommittedLog;
for (Proposal propose: proposals) {
// skip the proposals the peer already has
if (propose.packet.getZxid() <= peerLastZxid) {
prevProposalZxid = propose.packet.getZxid();
continue;
} else {
// If we are sending the first packet, figure out whether to trunc
// in case the follower has some proposals that the leader doesn't
// todo 当我们发送第一个packet时, 弄明白是否trunc, 以防leader没有Follower拥有的proposals
if (firstPacket) {
firstPacket = false;
// Does the peer have some proposals that the leader hasn't seen yet
if (prevProposalZxid < peerLastZxid) {
// send a trunc message before sending the diff
packetToSend = Leader.TRUNC;
zxidToSend = prevProposalZxid;
updates = zxidToSend;
}
}
// todo 放入队列(未发送)
queuePacket(propose.packet);
// todo 这一步就是leader给leanner发送的commit响应. leanner接收到这个响应之后无须在发送确认请求,直接同步数据
QuorumPacket qcommit = new QuorumPacket(Leader.COMMIT, propose.packet.getZxid(),
null, null);
queuePacket(qcommit);
}
}
} else if (peerLastZxid > maxCommittedLog) {
// todo leanner最后一次提交的zxid 事务id比 leader中最大的事务id还大
LOG.debug("Sending TRUNC to follower zxidToSend=0x{} updates=0x{}",
Long.toHexString(maxCommittedLog),
Long.toHexString(updates));
packetToSend = Leader.TRUNC;
zxidToSend = maxCommittedLog;
updates = zxidToSend;
} else {
LOG.warn("Unhandled proposal scenario");
}
.
.
bufferedOutput.flush();
//Need to set the zxidToSend to the latest zxid
// todo 需要将zxidToSend 设置成最新的zxid
if (packetToSend == Leader.SNAP) {
zxidToSend = leader.zk.getZKDatabase().getDataTreeLastProcessedZxid();
}
oa.writeRecord(new QuorumPacket(packetToSend, zxidToSend, null, null), "packet");
bufferedOutput.flush();
/* if we are not truncating or sending a diff just send a snapshot */
if (packetToSend == Leader.SNAP) {
LOG.info("Sending snapshot last zxid of peer is 0x"
+ Long.toHexString(peerLastZxid) + " "
+ " zxid of leader is 0x"
+ Long.toHexString(leaderLastZxid)
+ "sent zxid of db as 0x"
+ Long.toHexString(zxidToSend));
// Dump data to peer
// todo 从快照中同步数据
leader.zk.getZKDatabase().serializeSnapshot(oa);
// todo 快照直接通过socket发送出去
oa.writeString("BenWasHere", "signature");
}
bufferedOutput.flush();
// Start sending packets
//todo 创建一条新的线程,用这条线程发送上面存放到队列里面的数据
new Thread() {
public void run() {
Thread.currentThread().setName(
"Sender-" + sock.getRemoteSocketAddress());
try {
sendPackets();
} catch (InterruptedException e) {
LOG.warn("Unexpected interruption",e);
}
}
}.start();
Follower接受到Leader不同的同步数据命名,做出不同的动作#
这个方法又是超级长的,好在也不会很难读,根据不同的type选择不同的数据恢复方法
- 如果是Snap,则将自己的ZKDB清空,然后加载Leader的快照
- 如果是trunc,就将不合法的zxid的记录全部删除,然后重新加载
- 如果是diff类型的,会进一步进入到
while (self.isRunning()) {..}循环块的case模块,将需要同步的request全部添加到集合中packetsCommitted.add(qp.getZxid());,收到服务端的UPTODATE后才会跳出这个循环 - 通过下面的代码查看,Follower并没有先消费leader发送过来的request,因为它现在没有完成启动,没法交给Processor处理,因此它需要先启动,就在下面的
zk.startup();完成启动 - 启动之后,将这里request加载到内存完成数据同步
protected void syncWithLeader(long newLeaderZxid) throws IOException, InterruptedException{
QuorumPacket ack = new QuorumPacket(Leader.ACK, 0, null, null);
QuorumPacket qp = new QuorumPacket();
long newEpoch = ZxidUtils.getEpochFromZxid(newLeaderZxid);
//todo 同步数据时,如果是diff这种情况, 我们不需要去生成一个快照,因为事务将在现有的快照的基础上完成同步
//todo 如果是 snap 或者 trunc 时,需要生成快照
boolean snapshotNeeded = true;
// todo 从leader中读取出一个 packet
readPacket(qp);
LinkedList<Long> packetsCommitted = new LinkedList<Long>();
LinkedList<PacketInFlight> packetsNotCommitted = new LinkedList<PacketInFlight>();
synchronized (zk) {
// todo diff
if (qp.getType() == Leader.DIFF) {
LOG.info("Getting a diff from the leader 0x{}", Long.toHexString(qp.getZxid()));
// todo 修改了一下这个变量的值,这个变量的值在下面的代码中赋值给了 writeToTxnLog
snapshotNeeded = false;
}
else if (qp.getType() == Leader.SNAP) {
// todo 快照
LOG.info("Getting a snapshot from leader 0x" + Long.toHexString(qp.getZxid()));
// The leader is going to dump the database clear our own database and read
// todo 清空我们自己的ZKDB 使用leader发送的快照重建
zk.getZKDatabase().clear();
// todo leaderIs就是server发送过来的数据,进行反序列化
zk.getZKDatabase().deserializeSnapshot(leaderIs);
String signature = leaderIs.readString("signature");
if (!signature.equals("BenWasHere")) {
LOG.error("Missing signature. Got " + signature);
throw new IOException("Missing signature");
}
// todo 同步当前Follower中最大事务zxid
zk.getZKDatabase().setlastProcessedZxid(qp.getZxid());
} else if (qp.getType() == Leader.TRUNC) {
//we need to truncate the log to the lastzxid of the leader
LOG.warn("Truncating log to get in sync with the leader 0x"
+ Long.toHexString(qp.getZxid()));
// TODO 删除log数据
boolean truncated=zk.getZKDatabase().truncateLog(qp.getZxid());
if (!truncated) {
// not able to truncate the log
LOG.error("Not able to truncate the log "
+ Long.toHexString(qp.getZxid()));
System.exit(13);
}
zk.getZKDatabase().setlastProcessedZxid(qp.getZxid());
}
else {
LOG.error("Got unexpected packet from leader "
+ qp.getType() + " exiting ... " );
System.exit(13);
}
zk.createSessionTracker();
long lastQueued = 0;
boolean isPreZAB1_0 = true;
// todo 如果不拍摄快照,请确保事务不应用于内存,而是写入事务日志
// todo diff模式下,snapshotNeeded=false
//todo writeToTxnLog = true
boolean writeToTxnLog = !snapshotNeeded;
outerLoop:
while (self.isRunning()) {
// todo 在这个循环中继续读取数据, 如果是diff的话,就会读取到下面拿到commit case
readPacket(qp);
switch(qp.getType()) {
case Leader.PROPOSAL:
PacketInFlight pif = new PacketInFlight();
pif.hdr = new TxnHeader();
pif.rec = SerializeUtils.deserializeTxn(qp.getData(), pif.hdr);
if (pif.hdr.getZxid() != lastQueued + 1) {
LOG.warn("Got zxid 0x"
+ Long.toHexString(pif.hdr.getZxid())
+ " expected 0x"
+ Long.toHexString(lastQueued + 1));
}
lastQueued = pif.hdr.getZxid();
packetsNotCommitted.add(pif);
break;
case Leader.COMMIT:
if (!writeToTxnLog) { //todo diff模式下 条件为false
pif = packetsNotCommitted.peekFirst();
if (pif.hdr.getZxid() != qp.getZxid()) {
LOG.warn("Committing " + qp.getZxid() + ", but next proposal is " + pif.hdr.getZxid());
} else {
zk.processTxn(pif.hdr, pif.rec);
packetsNotCommitted.remove();
}
} else {//todo 进入这个分支
// todo 读取到的qa 添加到packetsCommitted linkedList中 , 这个队列在下面代码中使用
packetsCommitted.add(qp.getZxid());
}
break;
case Leader.INFORM:
/*
* Only observer get this type of packet. We treat this
* as receiving PROPOSAL and COMMMIT.
*/
PacketInFlight packet = new PacketInFlight();
packet.hdr = new TxnHeader();
packet.rec = SerializeUtils.deserializeTxn(qp.getData(), packet.hdr);
// Log warning message if txn comes out-of-order
if (packet.hdr.getZxid() != lastQueued + 1) {
LOG.warn("Got zxid 0x"
+ Long.toHexString(packet.hdr.getZxid())
+ " expected 0x"
+ Long.toHexString(lastQueued + 1));
}
lastQueued = packet.hdr.getZxid();
if (!writeToTxnLog) {
// Apply to db directly if we haven't taken the snapshot
zk.processTxn(packet.hdr, packet.rec);
} else {
packetsNotCommitted.add(packet);
packetsCommitted.add(qp.getZxid());
}
break;
case Leader.UPTODATE:
// todo 想让下面的代码使用上面的队列就得跳出这个while 循环
// todo 这个while循环在当前case中完成跳出
// todo 也就是说,只有获取到Leader的uptoDate 请求时才来退出
if (isPreZAB1_0) {
zk.takeSnapshot();
self.setCurrentEpoch(newEpoch);
}
self.cnxnFactory.setZooKeeperServer(zk);
break outerLoop;
case Leader.NEWLEADER: // Getting NEWLEADER here instead of in discovery
// means this is Zab 1.0
// Create updatingEpoch file and remove it after current
// epoch is set. QuorumPeer.loadDataBase() uses this file to
// detect the case where the server was terminated after
// taking a snapshot but before setting the current epoch.
File updating = new File(self.getTxnFactory().getSnapDir(),
QuorumPeer.UPDATING_EPOCH_FILENAME);
if (!updating.exists() && !updating.createNewFile()) {
throw new IOException("Failed to create " +
updating.toString());
}
if (snapshotNeeded) {
zk.takeSnapshot();
}
self.setCurrentEpoch(newEpoch);
if (!updating.delete()) {
throw new IOException("Failed to delete " +
updating.toString());
}
writeToTxnLog = true; //Anything after this needs to go to the transaction log, not applied directly in memory
isPreZAB1_0 = false;
writePacket(new QuorumPacket(Leader.ACK, newLeaderZxid, null, null), true);
break;
}
}
}
ack.setZxid(ZxidUtils.makeZxid(newEpoch, 0));
writePacket(ack, true);
sock.setSoTimeout(self.tickTime * self.syncLimit);
// todo follower 完成初始化启动, 在跟下去就很熟悉了, 和单机启动流程神似
zk.startup();
self.updateElectionVote(newEpoch);
if (zk instanceof FollowerZooKeeperServer) {
} else if (zk instanceof ObserverZooKeeperServer) {
///////////////////////////////////////////////////////////////////////////////
ObserverZooKeeperServer ozk = (ObserverZooKeeperServer) zk;
for (PacketInFlight p : packetsNotCommitted) {
Long zxid = packetsCommitted.peekFirst();
if (p.hdr.getZxid() != zxid) {
LOG.warn("Committing " + Long.toHexString(zxid)
+ ", but next proposal is "
+ Long.toHexString(p.hdr.getZxid()));
continue;
}
packetsCommitted.remove();
Request request = new Request(null, p.hdr.getClientId(),
p.hdr.getCxid(), p.hdr.getType(), null, null);
request.txn = p.rec;
request.hdr = p.hdr;
ozk.commitRequest(request);
}
///////////////////////////////////////////////////////////////////////////////
} else {
// New server type need to handle in-flight packets
throw new UnsupportedOperationException("Unknown server type");
}
}
再回想一下,现在的状态就是完成了Follower.java中的方法followLeader()
现在的阶段是,server启动完成了,数据也和leader同步了,并且在下面的这个循环中可以和Leader一直保持IO交流
// todo 从leader同步数据, 同时也是在这个方法中完成初始化启动的
syncWithLeader(newEpochZxid);
QuorumPacket qp = new QuorumPacket();
// todo 在follower中开启无线循环, 不停的接收服务端的pakcet,然后处理packet
while (this.isRunning()) {
readPacket(qp);
// todo (接受leader发送的提议)
processPacket(qp);
}
Follower同步完数据,再跟Leader打交道就是 有客户端有了写请求,Follower需要将这个写请求转发leader进行广播
Leader中就在下面的逻辑中进行处理,
在learnerHandler.java的run()
case Leader.REQUEST:
// todo follower 接收到client的写请求之后,进入到这个case分支
bb = ByteBuffer.wrap(qp.getData());
sessionId = bb.getLong();
cxid = bb.getInt();
type = bb.getInt();
bb = bb.slice();
Request si;
if(type == OpCode.sync){
si = new LearnerSyncRequest(this, sessionId, cxid, type, bb, qp.getAuthinfo());
} else {
si = new Request(null, sessionId, cxid, type, bb, qp.getAuthinfo());
}
si.setOwner(this);
leader.zk.submitRequest(si);
break;
它开启了和Follower进行IO交流的线程之后,同样会执行启动的代码
总结: 在本篇博客中,可以看到在Follower向Leader同步数据的过程中的几个阶段
- 发现: leader发现Follower并与之建立通信
- 同步: Follower可以主要通过两种方式完成和leader的数据同步工作
- 通过Leader的快照
- 通过leader的commitedLog中存放的包含snapshot的已经被持久化的request
- 原子广播: 这种情景是当Follower接收到客户端的写请求时,它会将这个请求转发给Leader,因为要保证数据的一致性(源码就在learnerHandler的run()方法的最后的while无限循环中CASE: Request)
由Leader发起原子广播,通知集群中的全部节点提交事务,完成数据一致性
公众号首发、欢迎关注#



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步