深入理解 ZooKeeper单机服务端的启动
程序的入口QuorumPeerMain
public static void main(String[] args) {
//
QuorumPeerMain main = new QuorumPeerMain();
try {
// 初始化服务端,并运行服务端
// todo 跟进去看他如何处理 服务端的配置文件,以及根据服务端的配置文件做出来那些动作
main.initializeAndRun(args);
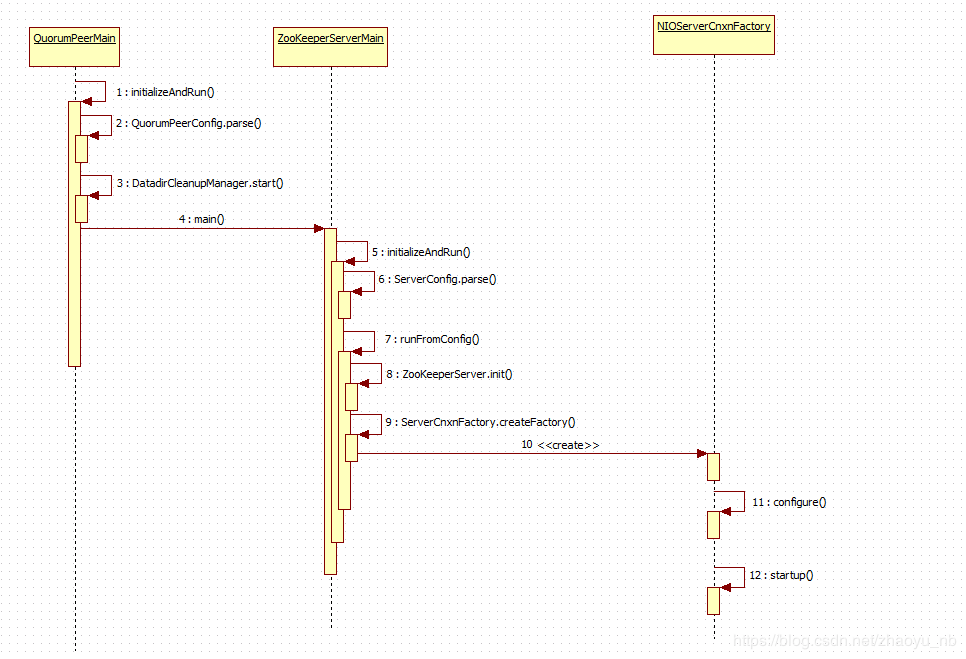
初始化和启动总览
跟进initializeAndRun()方法 , 这个方法中主要做了如下三件事
- 从
args[0]解析出配置文件的位置,创建QuorumPeerConfig配置类对象(可以把这个对象理解成单个ZK server的配置对象),然后将配置文件中的内容加载进内存,并完成对java配置类的属性的赋值 - 开启,启动并清除计划任务的逻辑
- 根据从内存中读取配置文件实例化好的配置类,启动ZKserver
protected void initializeAndRun(String[] args) throws ConfigException, IOException {
// todo 这个类是关联配置文件的类, 我们在配置文件中输入的各种配置都是他的属性
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
// todo
config.parse(args[0]);
}
// Start and schedule the the purge task
// todo 启动并清除计划任务
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config
.getDataDir(), config.getDataLogDir(), config
.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start();
// todo config.servers.size() > 0 说明添加了关于集群的配置
if (args.length == 1 && config.servers.size() > 0) {
// todo 根据配置启动服务器, 跟进去, 就在下面
runFromConfig(config);
} else {
// todo 没添加集群的配置
LOG.warn("Either no config or no quorum defined in config, running "
+ " in standalone mode");
// there is only server in the quorum -- run as standalone
// todo 启动单机
ZooKeeperServerMain.main(args);
}
}
读取配置文件
下面跟进parse, 这个方法的目的是将磁盘上的配置信息读取到文件中,完成对QuorumPeerConfig的初始化主要做了如下两件事
- 因为ZK的配置文件是
.properties结尾的,因此呢选择了Properties.java(格式是 key=value)来解析读取配置文件 parseProperties()方法,对解析出来的配置文件进行进一步的处理
public void parse(String path) throws ConfigException {
File configFile = new File(path);
LOG.info("Reading configuration from: " + configFile);
try {
if (!configFile.exists()) {
throw new IllegalArgumentException(configFile.toString()
+ " file is missing");
}
Properties cfg = new Properties();
FileInputStream in = new FileInputStream(configFile);
try {
// todo 使用 Properties 按行读取出配置文件内容
cfg.load(in);
} finally {
in.close();
}
// todo 将按行读取处理出来的进行分隔处理, 对当前的配置类进行赋值
parseProperties(cfg);
} catch (IOException e) {
throw new ConfigException("Error processing " + path, e);
} catch (IllegalArgumentException e) {
throw new ConfigException("Error processing " + path, e);
}
}
解析配置文件
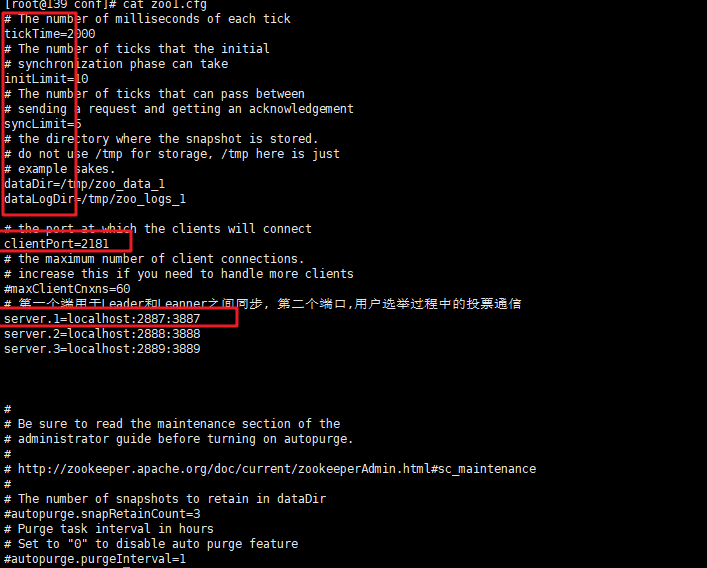
看一看,他是如何处理已经被加载到内存的配置文件的,
- 首先看一下上图中我截取的配置文件的截图,可以看到通过下面的if-else分支语句将配置文件的中的信息一对一的读取出来,完成对当前配置类的初始化
- if (value.toLowerCase().equals("observer")) {..}这个分支就是判断当前的配置文件是不是Observer的配置文件,比较推荐的observer的配置,就是添加一条配置写
peerType=observer,但是这是为了人们查看方便设计的,换句话说,一个普通的Follower的配置文件,即便是添加上了这条配置文件,它同样不是observer,后续还会有进一步的检验,因为zk集群的配置文件大同小异,一开始即便是我们不添加这个配置,observer角色的server依然会成为observer,但是对于人们来说,就不用点开dataDir中的myid文件查看究竟当前的server是不是Observer了 else if (key.startsWith("server."))标记着配置文件中有关集群的配置信息开始了,它根据不同的配置信息,将不同身份的server存放进两个map中,就像下面那样,如果是Observer类型的,就存放在observers中,如果是Follower类型的就添加进serversmap中- 它这样做是为了下一步实现ZAB协议,过半检查. 而设计的, 什么是过半检查机制呢? 首先是集群中的server存在一半以上健康时,集群才可用
- 其次是,Leader发起的决议,需要有一半的Follower同意决议才能通过,注意这里是Follower,而不是OBserver+Follower,因为OBserver不参加投票,因此在这个半数协议中,它不作数, 所以再看他现在的做法,就是创建过半检查机制封装类
QuorumVerifer时,使用servers的容量
- 合并servers和observers, 虽然后者不参加决议投票,但是它同样需要提供服务
- 读取myid文件,最终确定不同的server的身份划分,哪个是myid配置文件呢? 它是我们在配置集群信息时在dataDir中创建的, 里面仅仅存放一个数据,这个数字不是乱写的,对应的是配置文件的server.n中的n, 启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是那个server,只是一个标识作用。
public void parseProperties(Properties zkProp) throws IOException, ConfigException {
int clientPort = 0;
String clientPortAddress = null;
for (Entry<Object, Object> entry : zkProp.entrySet()) {
String key = entry.getKey().toString().trim();
String value = entry.getValue().toString().trim();
if (key.equals("dataDir")) {
dataDir = value;
} else if (key.equals("dataLogDir")) {
dataLogDir = value;
} else if (key.equals("clientPort")) {
clientPort = Integer.parseInt(value);
} else if (key.equals("clientPortAddress")) {
clientPortAddress = value.trim();
} else if (key.equals("tickTime")) {
.
.
.
.
} else if (key.equals("peerType")) {
if (value.toLowerCase().equals("observer")) {
// todo 这是推荐配置做法在 observer 的配置文件中配置上添加 peerType=observer
//todo 但是如果给一台不是observer的机器加上了这个配置, 它也不会是observer. 在这个函数的最后会有校验
peerType = LearnerType.OBSERVER;
} else if (value.toLowerCase().equals("participant")) {
peerType = LearnerType.PARTICIPANT;
} else
{
throw new ConfigException("Unrecognised peertype: " + value);
}
.
.
.
} else if (key.startsWith("server.")) {
// todo 全部以server.开头的配置全部放到了 servers
int dot = key.indexOf('.');
long sid = Long.parseLong(key.substring(dot + 1));
String parts[] = splitWithLeadingHostname(value);
if ((parts.length != 2) && (parts.length != 3) && (parts.length !=4)) {
LOG.error(value
+ " does not have the form host:port or host:port:port " +
" or host:por
.
.
.
// todo 不论是普通节点,还是观察者节点,都是 QuorumServer, 只不过添加进到不同的容器
if (type == LearnerType.OBSERVER){
// todo 如果不是观察者的话,就不会放在 servers,
// todo server.1=localhost:2181:3887
// todo server.2=localhost:2182:3888
// todo server.3=localhost:2183:3889
// todo port是对外提供服务的端口 electionPort是用于选举的port
// todo 查看zk的数据一致性我们使用的端口是 port
observers.put(Long.valueOf(sid), new QuorumServer(sid, hostname, port, electionPort, type));
} else {
// todo 其他的普通节点放在 servers
servers.put(Long.valueOf(sid), new QuorumServer(sid, hostname, port, electionPort, type));
}
.
.
.
.
/*
* Default of quorum config is majority
*/
if(serverGroup.size() > 0){
if(servers.size() != serverGroup.size())
throw new ConfigException("Every server must be in exactly one group");
/*
* The deafult weight of a server is 1
*/
for(QuorumServer s : servers.values()){
if(!serverWeight.containsKey(s.id))
serverWeight.put(s.id, (long) 1);
}
/*
* Set the quorumVerifier to be QuorumHierarchical
*/
quorumVerifier = new QuorumHierarchical(numGroups,
serverWeight, serverGroup);
} else {
/*
* The default QuorumVerifier is QuorumMaj
*/
// todo 默认的仲裁方式, 过半机制中,是不包含 observer 的数量的
LOG.info("Defaulting to majority quorums");
quorumVerifier = new QuorumMaj(servers.size());
}
// Now add observers to servers, once the quorums have been
// figured out
// todo 最后还是将 Observers 添加进了 servers
servers.putAll(observers);
/**
* todo 当时搭建伪集群时,在每一个节点的dataDir文件中都添加进去了一个 myid文件
* 分别在zk、zk2、zk3、的dataDir中新建myid文件, 写入一个数字, 该数字表示这是第几号server.
* 该数字必须和zoo.cfg文件中的server.X中的X一一对应.
* myid的值是zoo.cfg文件里定义的server.A项A的值,
* Zookeeper 启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是那个server,只是一个标识作用。
*
*/
// todo 找到当前节点的dataDir 下面的 myid文件
File myIdFile = new File(dataDir, "myid");
if (!myIdFile.exists()) {
throw new IllegalArgumentException(myIdFile.toString()
+ " file is missing");
}
BufferedReader br = new BufferedReader(new FileReader(myIdFile));
String myIdString;
try {
// todo 读取出myid里面的内容
myIdString = br.readLine();
} finally {
br.close();
}
try {
// todo myid文件中存到的数据就是 配置文件中server.N 中的 N这个数字
serverId = Long.parseLong(myIdString);
MDC.put("myid", myIdString);
} catch (NumberFormatException e) {
throw new IllegalArgumentException("serverid " + myIdString
+ " is not a number");
}
// todo 通过检查上面的Observers map 中是否存在 serverId, 这个serverId其实就是myid, 对应上了后,就将它的
// Warn about inconsistent peer type
LearnerType roleByServersList = observers.containsKey(serverId) ? LearnerType.OBSERVER
: LearnerType.PARTICIPANT;
if (roleByServersList != peerType) {
LOG.warn("Peer type from servers list (" + roleByServersList
+ ") doesn't match peerType (" + peerType
+ "). Defaulting to servers list.");
peerType = roleByServersList;
}
根据配置文件启动ZKServer
在一开始的QuorumPeerMain.java类中的Initializer()方法中,存在如下的逻辑,判断是单机版本启动还是集群的启动
if (args.length == 1 && config.servers.size() > 0) {
// todo 根据配置启动服务器, 跟进去, 就在下面
runFromConfig(config);
} else {
// todo 没添加集群的配置
LOG.warn("Either no config or no quorum defined in config, running "
+ " in standalone mode");
// there is only server in the quorum -- run as standalone
// todo 启动单机
ZooKeeperServerMain.main(args);
}
如果是单机版本的话,会进入else块从此构建ZookeeperServerMain对象, 可以把这个ZooKeeperServerMain理解成一个辅助类,经过它,初始化并启动一个ZooKeeperServer.java的对象
继续跟进
public static void main(String[] args) {
// todo 使用无参的构造方法实例化服务端, 单机模式
ZooKeeperServerMain main = new ZooKeeperServerMain();
try {
// todo 跟进去看他如何解析配置文件
main.initializeAndRun(args);
继续跟进
protected void initializeAndRun(String[] args) throws ConfigException, IOException {
try {
ManagedUtil.registerLog4jMBeans();
} catch (JMException e) {
LOG.warn("Unable to register log4j JMX control", e);
}
// todo 这个配置类, 对应着单机模式的配置类 , 里面的配置信息很少
ServerConfig config = new ServerConfig();
if (args.length == 1) {
config.parse(args[0]);
} else {
// todo 单机版本
config.parse(args);
}
// todo 读取配置,启动单机节点
runFromConfig(config);
}
启动单节点
这次再进入这个方法,我们直接跳过它是如果从配置文件中读取出配置信息了,然后直接看它的启动方法
runFromConfig方法主要做了如下几件事
- 创建
ZooKeeperServer它是单机ZK服务端的实例
如下的ZooKeeperServer相关的属性
private FileTxnSnapLog txnLogFactory = null;
private ZKDatabase zkDb;
protected RequestProcessor firstProcessor
以及它可以构建DataTree
- 创建
ZooKeeperServerShutdownHandler监控ZkServer关闭状态的处理器 - 创建
FileTxnSnapLog文件快照相关的工具类 - 给ZKServer绑定上
单位时间trickTime(节点心跳交流的时间) - 初始化 ZKServer
处理事务,快照相关的工具类 - 创建上下文的工厂
- 通过工厂,启动上下文
public void runFromConfig(ServerConfig config) throws IOException {
LOG.info("Starting server");
FileTxnSnapLog txnLog = null;
try {
// Note that this thread isn't going to be doing anything else,
// so rather than spawning another thread, we will just call run() in this thread.
// todo 请注意,当前线程不会做其他任何事情,因此我们只在当前线程中调用Run方法,而不是开启新线程
// create a file logger url from the command line args
// todo 根据命令中的args 创建一个logger文件
final ZooKeeperServer zkServer = new ZooKeeperServer();
// Registers shutdown handler which will be used to know the server error or shutdown state changes.
// todo 注册一个shutdown handler, 通过他了解server发生的error或者了解shutdown 状态的更改
final CountDownLatch shutdownLatch = new CountDownLatch(1);
zkServer.registerServerShutdownHandler(
new ZooKeeperServerShutdownHandler(shutdownLatch));
// todo FileTxnSnapLog工具类, 与 文件快照相关
txnLog = new FileTxnSnapLog(new File(config.dataLogDir), new File(config.dataDir));
txnLog.setServerStats(zkServer.serverStats());
zkServer.setTxnLogFactory(txnLog);
zkServer.setTickTime(config.tickTime);
zkServer.setMinSessionTimeout(config.minSessionTimeout);
zkServer.setMaxSessionTimeout(config.maxSessionTimeout);
// todo 创建Server上下文的工厂,工厂方法模式
// todo ServerCnxnFactory是个抽象类,他有不同是实现, NIO版本的 Netty版本的
cnxnFactory = ServerCnxnFactory.createFactory();
// todo 建立socket,默认是NIOServerCnxnFactory(是一个线程)
cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns());
// todo 跟进这个方法
cnxnFactory.startup(zkServer);
- 看一下如何创建处理事务,快照日志相关的数据文件的逻辑,可以看到,直接去关联我们配置的dataDir,snapDir,对应着日志存储的目录已经快照存储的目录, 然后封装进
FileSnap和FileTxnLog对象中
public FileTxnSnapLog(File dataDir, File snapDir) throws IOException {
LOG.debug("Opening datadir:{} snapDir:{}", dataDir, snapDir);
// todo 关联上指定数据文件和日志文件
// todo 给FileTxnSnapLog赋值
this.dataDir = new File(dataDir, version + VERSION);
this.snapDir = new File(snapDir, version + VERSION);
if (!this.dataDir.exists()) {
...
.
.
// todo 将这两个文件封装进 FileTxnLog 给当前类维护的两种事务快照( TnxnSnap ) 赋值
txnLog = new FileTxnLog(this.dataDir);
snapLog = new FileSnap(this.snapDir);
- 上下文工厂
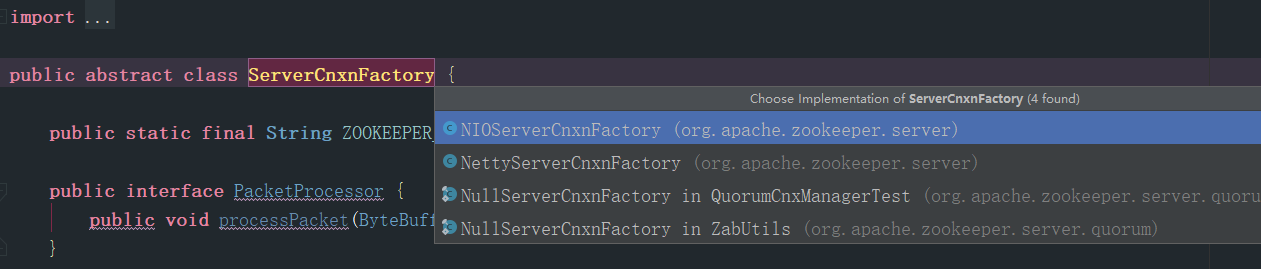
如上图,将ServerCnxnFactory.java的继承图,不同的上下文工厂的实现可以创建出不同的上下文,通过这个图可以看到,不仅支持传统的NIO,还有一套Netty的实现,当前我选择的是原生的实现NIOServerCnxnFactory的实现,那么由他创建出来的就是NIOServerCnxn
启动流程如下图
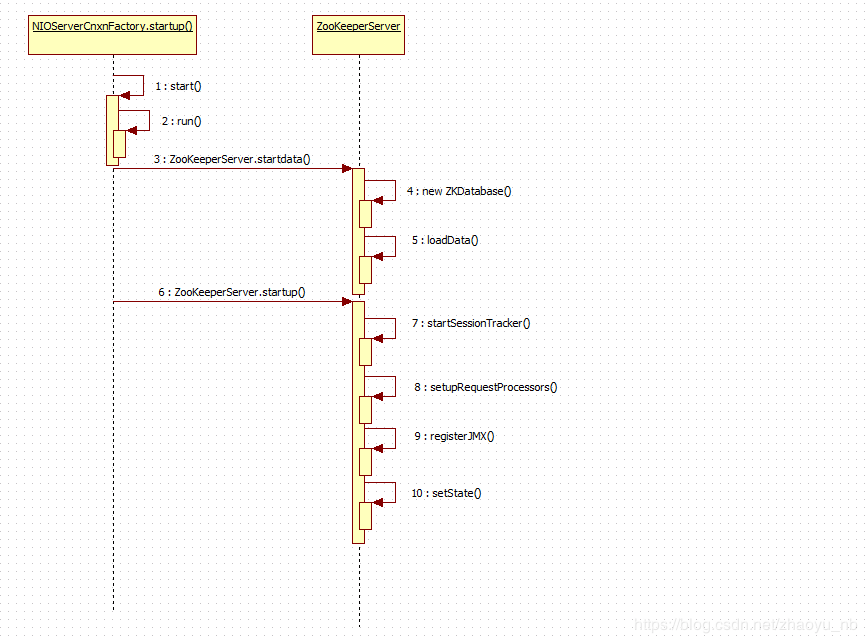
上下文工厂实例化服务端的NIOSocket
在这个方法中创建了ZooKeeperThread,这个类ZK中设计的线程类,几乎全部的线程都由此类完成,当前方法中的做法是将创建的Thread赋值给了当前的类的引用,实际上约等于当前类就是线程类,还有需要注意的地方就是虽然进行了初始化,但是并没有开启
此处看到的就是java原生的NIO Socket编程, 当前线程类被设置成守护线程
Thread thread;
@Override
public void configure(InetSocketAddress addr, int maxcc) throws IOException {
configureSaslLogin();
// todo 把当前类作为线程
thread = new ZooKeeperThread(this, "NIOServerCxn.Factory:" + addr);
//todo 所以这里的这个线程是为了和JVM生命周期绑定,只剩下这个线程时已经没有意义了,应该关闭掉。
thread.setDaemon(true);
maxClientCnxns = maxcc;
// todo 看到了NIO原生的代码,使用打开服务端的 Channel, 绑定端口,设置为非阻塞,注册上感兴趣的事件是 accept 连接事件
this.ss = ServerSocketChannel.open();
ss.socket().setReuseAddress(true);
LOG.info("binding to port " + addr);
ss.socket().bind(addr);
ss.configureBlocking(false);
ss.register(selector, SelectionKey.OP_ACCEPT);
}
- 由上下文工厂实例化的
NIOServerCnxn
下面是它的属性,可以看到其实这个上下文涵盖的很全面,甚至服务端的ZK都被他维护着,
NIOServerCnxnFactory factory;
final SocketChannel sock;
protected final SelectionKey sk;
boolean initialized;
ByteBuffer lenBuffer = ByteBuffer.allocate(4);
ByteBuffer incomingBuffer = lenBuffer;
LinkedBlockingQueue<ByteBuffer> outgoingBuffers = new LinkedBlockingQueue<ByteBuffer>();
int sessionTimeout;
protected final ZooKeeperServer zkServer;
上下文工厂(ServerFactoryCnxn)启动
看完了ZooKeeperServerMain中runFromConfig方法中的创建ZKServer,FileTxnSnapLog等重要对象的逻辑,下面,上下文启动, 直接点击去查看这个方法,肯定直接进入ServerFactoryCnxn,我们选择的是它的实现类NIOServerCnxnFactory
public void runFromConfig(ServerConfig config) throws IOException {
.
.
.
cnxnFactory.startup(zkServer);
下面是NIOServerCnxnFactory的实现,它做的第一件事就是开启上面实例化的所说的线程类,这条线程的开启标记着,服务端从此可以接收客户端发送的请求了
这个方法还做了如下三件事
- 将ZooKeeperServer交给上下文维护
- 因为这个是启动,所以从磁盘中完成数据的恢复
- 继续运行
- 创建计时器
- 开启计时器
- 开启三条处理器
- 注册JMX
- 修改运行的状态
- 唤醒全部线程
public void startup(ZooKeeperServer zks) throws IOException,
InterruptedException {
// todo start(); ==> run() 开启线程
start(); //todo 实现在上面, 到目前为止服务端已经可以接受客户端的请求了
// todo 将ZKS 交给NIOServerCnxnFactory管理,意味着NIOServerCnxnFactory是目前来说,服务端功能最多的对象
setZooKeeperServer(zks);
// todo 因为是服务端刚刚启动,需要从从disk将数据恢复到内存
zks.startdata();
// todo 继续跟进
zks.startup();
}
完成数据的恢复
跟进startData()方法, 看到先创建ZKDatabase,这个对象就是存在于内存中的对象,对磁盘中数据可视化描述
// todo 将数据加载进缓存中
public void startdata()
throws IOException, InterruptedException {
//check to see if zkDb is not null
if (zkDb == null) {
// todo 如果没初始化的话就初始化
zkDb = new ZKDatabase(this.txnLogFactory);
}
if (!zkDb.isInitialized()) {
// todo 恢复数据
loadData();
}
}
跟进创建ZKDataBase的逻辑, 最直观的可以看见,这个DB维护了DataTree和SnapLog
public ZKDatabase(FileTxnSnapLog snapLog) {
// todo 创建了DataTree 数据树的空对象
dataTree = new DataTree();
sessionsWithTimeouts = new ConcurrentHashMap<Long, Integer>();
//todo 用初始化好了的存有关于系统事务日志将snaplog初始化
this.snapLog = snapLog;
}
loaddata()
public void loadData() throws IOException, InterruptedException {
// todo zkDatabase 已经初始化了
if(zkDb.isInitialized()){
// todo zxid = 最近的一次znode的事务id
setZxid(zkDb.getDataTreeLastProcessedZxid());
} else {
//todo zkDB 没有初始化就使用 zkDb.loadDataBase() , 跟进去看, 他从快照中获取数据
setZxid(zkDb.loadDataBase());
}
// Clean up dead sessions
LinkedList<Long> deadSessions = new LinkedList<Long>();
for (Long session : zkDb.getSessions()) {
if (zkDb.getSessionWithTimeOuts().get(session) == null) {
deadSessions.add(session);
}
}
zkDb.setDataTreeInit(true);
for (long session : deadSessions) {
// XXX: Is lastProcessedZxid really the best thing to use?
killSession(session, zkDb.getDataTreeLastProcessedZxid());
}
}
- 继续启动
zks.startup();它的源码在下面,其中的计时器类也是一个线程类
// todo 继续启动, 服务端和客户端建立连接后会保留一个session, 其中这个sessiion的生命周期倒计时就在下面的 createSessionTracker();
public synchronized void startup() {
if (sessionTracker == null) {
// todo 创建session计时器
createSessionTracker();
}
// todo 开启计时器
startSessionTracker();
// todo 设置请求处理器, zookeeper中存在不同的请求处理器, 就在下面
setupRequestProcessors();
//todo 是一个为应用程序、设备、系统等植入管理功能的框架。
//todo JMX可以跨越一系列异构操作系统平台、系统体系结构和网络传输协议,灵活的开发无缝集成的系统、网络和服务管理应用
registerJMX();
// todo 修改状态 --> running
setState(State.RUNNING);
// todo 唤醒所有线程, 因为前面有一个线程等待处理器 睡了一秒
notifyAll();
}
设置请求处理器
着重看一下它的setupRequestProcessors()添加请求处理器,单机模式下仅仅存在三个处理器,除了最后一个不是线程类之外,其他两个都是线程类
- PrepRequestProcessor
- 校验权限
- 修改请求的状态
- SyncRequestProcessor
- 将request持久化日志文件
- 打快照
- FinalRequestProcessor
- 响应客户端的请求
protected void setupRequestProcessors() {
// todo 下面的三个处理器的第二个参数是在指定 下一个处理器是谁
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor syncProcessor = new SyncRequestProcessor(this,
finalProcessor);
// todo 在服务端, 数据的处理 socket -> packet -> request -> queue
// todo 然后由下面的requestprocessor 链 进行下一步处理request
// todo 开启新线程, 服务端接收的客户端的请求都放在了 队列中,用处理器异步处理
((SyncRequestProcessor)syncProcessor).start();
//todo 第一个处理器 , 下一个处理器是 syncProcessor 最后一个处理器 finalProcessor
firstProcessor = new PrepRequestProcessor(this, syncProcessor);
// todo 开启新线程 服务端接收的客户端的请求都放在了 队列中,用处理器异步处理
((PrepRequestProcessor)firstProcessor).start();
}
重理思路
代码看到这里,重新调整一下思路接着往下看,首先作为服务端我们看到了上面的NIOServerCnxnFactory.java类中的开启了本类维护的新线程,让服务端有了接收新连接的能力
既然是线程类,就存有Run方法,ZK的设计思路就是在NIOServerCnxnFactory.java的run()方法中检测客户端有感兴趣的事件时,就进入DoIO()从bytebuffer中将用户的请求解析出来,然后交由最后面的三个处理器排队处理
NIOServerCnxnFactory.java的run方法部分代码如下
} else if ((k.readyOps() & (SelectionKey.OP_READ | SelectionKey.OP_WRITE)) != 0) {
// todo 接收数据,这里会间歇性的接收到客户端ping
NIOServerCnxn c = (NIOServerCnxn) k.attachment();
// todo 跟进去, 和客户端的那一套很相似了
c.doIO(k);
} else {
继续跟进 readPayload()-->readRequest()-->zkServer.processPacket(this, incomingBuffer), 如下是processPacket()方法的部分源码
else {
// todo 将上面的信息包装成 request
Request si = new Request(cnxn, cnxn.getSessionId(), h.getXid(), h.getType(), incomingBuffer, cnxn.getAuthInfo());
si.setOwner(ServerCnxn.me);
// todo 提交request, 其实就是提交给服务端的 process处理器进行处理
submitRequest(si);
}
继续跟进submitRequest(),终于可以看到它尝试将这个request交给第一个处理器处理,但是因为这是在服务器启动的过程中,服务端并不确定服务器的第一个处理器线程到底有没有开启,因此它先验证,甚至会等一秒,直到处理器线程完成了启动的逻辑
// todo 交由服务器做出request的处理动作
public void submitRequest(Request si) {
// todo 如果 firstProcessor 不存在,就报错了
if (firstProcessor == null) {
synchronized (this) {
try {
while (state == State.INITIAL) {
wait(1000);
}
} catch (InterruptedException e) {
LOG.warn("Unexpected interruption", e);
}
if (firstProcessor == null || state != State.RUNNING) {
throw new RuntimeException("Not started");
}
}
}
try {
touch(si.cnxn);
// todo 验证合法性
boolean validpacket = Request.isValid(si.type);
if (validpacket) {
// todo request合法的化,交给firstProcessor (实际是PrepRequestProcessor)处理 跟进去
firstProcessor.processRequest(si);
if (si.cnxn != null) {
incInProcess();
}
经过上面的阅读,不难发现,最终来自于客户端的request都将会流经服务端的三个处理器,下面就看看它们到底做了哪些事
PrepRequestProcessor(线程类)
因为他本身就是线程类,我们直接看他的run(),最直接的可以看到,它将请求交给了pRequest(req)处理
public void run() {
try {
while (true) {
// todo 取出请求
Request request = submittedRequests.take();
long traceMask = ZooTrace.CLIENT_REQUEST_TRACE_MASK;
//todo 处理请求
if (request.type == OpCode.ping) {
traceMask = ZooTrace.CLIENT_PING_TRACE_MASK;
}
if (LOG.isTraceEnabled()) {
ZooTrace.logRequest(LOG, traceMask, 'P', request, "");
}
if (Request.requestOfDeath == request) {
break;
}
// todo 着重看这里, 跟进去
pRequest(request);
}
下面跟进它的pRequest(),下面是它的源码,通过switch分支针对不同类型的请求做出不同的处理,下面用create类型的请求举例
protected void pRequest(Request request) throws RequestProcessorException {
// LOG.info("Prep>>> cxid = " + request.cxid + " type = " +
// request.type + " id = 0x" + Long.toHexString(request.sessionId));
request.hdr = null;
request.txn = null;
// todo 下面的不同类型的信息, 对应这不同的处理器方式
try {
switch (request.type) {
case OpCode.create:
// todo 创建每条记录对应的bean , 现在还是空的, 在面的pRequest2Txn 完成赋值
CreateRequest createRequest = new CreateRequest();
// todo 跟进这个方法, 再从这个方法出来,往下运行,可以看到调用了下一个处理器
pRequest2Txn(request.type, zks.getNextZxid(), request, createRequest, true);
break;
.
.
.
request.zxid = zks.getZxid();
// todo 调用下一个处理器处理器请求 SyncRequestProcessor
nextProcessor.processRequest(request);
总览思路,现在当前的处理器进行状态的相关处理,处理完之后移交给下一个处理器
跟进pRequest2Txn(request.type, zks.getNextZxid(), request, createRequest, true);依然是用create类型距离, 它在下面的方法中做了如下几件事
- 因为create是事务类型的请求,它在一开始就给request构建了事务头 txnHeader
- 将request中的属性反序列化进
CreateRequest类中 - 校验一下权限,检查一下访问时是否需要访问权限,如果需要,当前访问者有没有足够的权限
- 根据用户想create新node而输入的string,进行截取取出它的父级路径,因为创建新节点时,需在修改父路径对应节点的相关信息
- 校验父节点是否是临时节点
- 修改父节点是属性
- 更新zxid(创建znode事务id)
- childCount++
- 更新cversion(针对当前子节点修改的次数)
- 将这条记录添加到
outstandingChanges集合中
// todo 第二个参数位置上的 record 是上一步new 出来的空对象-->
protected void pRequest2Txn(int type, long zxid, Request request, Record record, boolean deserialize)
throws KeeperException, IOException, RequestProcessorException
{
// todo 使用request的相关属性,创建出 事务Header
request.hdr = new TxnHeader(request.sessionId, request.cxid, zxid,
Time.currentWallTime(), type);
switch (type) {
case OpCode.create:
// todo 校验session的情况
zks.sessionTracker.checkSession(request.sessionId, request.getOwner());
CreateRequest createRequest = (CreateRequest)record;
if(deserialize) // todo 反序列化
ByteBufferInputStream.byteBuffer2Record(request.request, createRequest);
// todo 获取出request中的path
String path = createRequest.getPath();
int lastSlash = path.lastIndexOf('/');
if (lastSlash == -1 || path.indexOf('\0') != -1 || failCreate) {
LOG.info("Invalid path " + path + " with session 0x" +
Long.toHexString(request.sessionId));
throw new KeeperException.BadArgumentsException(path);
}
// todo 进行权限的验证
List<ACL> listACL = removeDuplicates(createRequest.getAcl());
if (!fixupACL(request.authInfo, listACL)) {
throw new KeeperException.InvalidACLException(path);
}
// todo 获取父级路径
String parentPath = path.substring(0, lastSlash);
// todo 跟进这个方法, 跟进父节点的路径找到 parentRecord
ChangeRecord parentRecord = getRecordForPath(parentPath);
// todo 校验
checkACL(zks, parentRecord.acl, ZooDefs.Perms.CREATE,
request.authInfo);
// todo 取出父节点的C version (子节点的version)
int parentCVersion = parentRecord.stat.getCversion();
CreateMode createMode =
CreateMode.fromFlag(createRequest.getFlags());
if (createMode.isSequential()) {
path = path + String.format(Locale.ENGLISH, "%010d", parentCVersion);
}
validatePath(path, request.sessionId);
try {
if (getRecordForPath(path) != null) {
throw new KeeperException.NodeExistsException(path);
}
} catch (KeeperException.NoNodeException e) {
// ignore this one
}
// todo 判断当前的父节点 是不是临时节点
boolean ephemeralParent = parentRecord.stat.getEphemeralOwner() != 0;
if (ephemeralParent) {
// todo 父节点如果是临时节点, 直接抛异常结束
throw new KeeperException.NoChildrenForEphemeralsException(path);
}
// todo 父节点不是临时节点, 将创建的节点的VCersion 就是在父节点的基础上+1
int newCversion = parentRecord.stat.getCversion()+1;
request.txn = new CreateTxn(path, createRequest.getData(),
listACL,
createMode.isEphemeral(), newCversion);
StatPersisted s = new StatPersisted();
if (createMode.isEphemeral()) {
s.setEphemeralOwner(request.sessionId);
}
// todo 修改了父节点的一些元信息
parentRecord = parentRecord.duplicate(request.hdr.getZxid());
parentRecord.childCount++;
parentRecord.stat.setCversion(newCversion);
//todo 添加两条修改记录
addChangeRecord(parentRecord);
addChangeRecord(new ChangeRecord(request.hdr.getZxid(), path, s,
0, listACL));
break;
SyncRequestProcessor(线程类)
一个create请求经过第一个处理器进行状态相关的处理之后,就来到当前这个第二个处理器, 当前处理器的主要作用就是负责同步持久化,将request持久化到磁盘,人们说的打快照,也就是将DataTree序列化后持久化的工作,他的主要逻辑都在下面的Run方法中
- 首先是
while(true)保证了作为线程类的它可以无休止的一直运行下去 - 尝试从队列中取出request
- 队列为空,阻塞等待,直接不为空取出req再处理
- 队列不为空,直接取出一个req,接着处理
- 请求被取出来之后通过
if-else分支进行不同的处理- 如果是事务类型的
- 非事务类型的request
public void run() {
try {
// todo 写日志的初始数量
int logCount = 0;
// we do this in an attempt to ensure that not all of the serversin the ensemble take a snapshot at the same time
// todo 设置RandRoll的大小, 确保所有服务器在同一个时间不使用同一个快照
setRandRoll(r.nextInt(snapCount / 2));
//todo 这个处理器拥有自己的无限循环
while (true) {
// todo 初始请求为null
Request si = null;
// todo toFlush是一个LinkedList, 里面存放着需要 持久化到磁盘中的request
if (toFlush.isEmpty()) { // todo 没有需要刷新进disk的
// todo 这个take()是LinkedList原生的方法
// todo 从请求队列中取出一个请求,如果队列为空就会阻塞在这里
si = queuedRequests.take();
} else {
// todo 如果队列为空,直接取出request, 并不会阻塞
si = queuedRequests.poll();
if (si == null) {
//todo 刷新进磁盘
flush(toFlush);
continue;
}
}
// todo 在关闭处理器之前,会添加requestOfDeadth,表示关闭后不再接收任何请求
if (si == requestOfDeath) {
break;
}
//todo 成功的从队列中取出了请求
if (si != null) {
// track the number of records written to the log
// todo 将request 追加到日志文件, 只有事物性的请求才会返回true
if (zks.getZKDatabase().append(si)) {
// todo 刚才的事物日志放到请求成功后,添加一次, log数+1
logCount++;
// todo 当持久化的request数量 > (快照数/2 +randRoll) 时, 创建新的日志文件
if (logCount > (snapCount / 2 + randRoll)) {
setRandRoll(r.nextInt(snapCount / 2));
// todo roll the log
// todo 跟进去这个方法, 最终也会执行 this.logStream.flush();
// todo 新生成一个日志文件
// todo 调用rollLog函数翻转日志文件
zks.getZKDatabase().rollLog();
// todo 拍摄日志快照
if (snapInProcess != null && snapInProcess.isAlive()) {
LOG.warn("Too busy to snap, skipping");
} else {
// todo 创建线程处理快照
snapInProcess = new ZooKeeperThread("Snapshot Thread") {
public void run() {
try {
// todo 打快照, 跟进去
zks.takeSnapshot();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
}
}
};
// todo 开启快照线程
snapInProcess.start();
}
// todo 重置为0
logCount = 0;
}
} else if (toFlush.isEmpty()) {
// todo 如果等待被刷新进disk的request为空
// optimization for read heavy workloads
// iff this is a read, and there are no pending
// flushes (writes), then just pass this to the next
// processor
// todo 查看此时toFlush是否为空,如果为空,说明近段时间读多写少,直接响应
if (nextProcessor != null) {
// todo 最终也会调用 nextProcessor 处理request FinalRequestProcess
nextProcessor.processRequest(si);
if (nextProcessor instanceof Flushable) {
((Flushable) nextProcessor).flush();
}
}
continue;
}
// todo 流里面的内容不了立即刷新, 调用 toFlush.add(si); 累积request
toFlush.add(si);
if (toFlush.size() > 1000) {
// todo 当toFlush中的 request数量 > 1000 将会flush
flush(toFlush);
}
}
}
究竟是不是 事务类型的req,是在上面的代码中的zks.getZKDatabase().append(si)实现的,true表示属于事务类型,跟进这个方法,最终回来到FileTxnLog.java的append(),源码如下
代码是挺长的,但是逻辑也算是清楚,如下
- 根据有没有request的头,判断是否是事务类型,对于查询一类的非实物类型的请求来说,直接返回false退出,也不用往日志文件中添加什么信息,事实上确实如此,就直接进入非事务类型的req,也可以看到
continue没有一点持久化到磁盘的逻辑 - 其他类型的会对服务端的数据状态造成改变的事务性请求,会在这里被持久化进logDir中的日志文件,,还有个细节第一次的事务类型的请求会在这里完成持久化进磁盘的操作,除了第一次之外,其他的都会被批处理,原酒就是下面代码中的这一行
if (logStream==null) { - 满足这个条件
if (logCount > (snapCount / 2 + randRoll))之后,就会进行一次日志文件的滚动,说白了,就是现在的日志文件体积太大了,然后得保存原来的就日志文件,创建一个新的空的日志文件继续使用 - 打快照, 实际上就是将内存中的DataBase序列化后持久保存进内存中,这样做对数据的恢复是很有帮助的,比如集群的Follower可以通过Leader的快照迅速完成数据的同步
public synchronized boolean append(TxnHeader hdr, Record txn)
throws IOException
{
if (hdr == null) {
return false;
}
if (hdr.getZxid() <= lastZxidSeen) {
LOG.warn("Current zxid " + hdr.getZxid()
+ " is <= " + lastZxidSeen + " for "
+ hdr.getType());
} else {
lastZxidSeen = hdr.getZxid();
}
// todo 第一次来==null。 再执行过来就不进来了,等着在 SyncRequestProcessor中批量处理
// todo logStream == BufferedOutputStream
if (logStream==null) {
if(LOG.isInfoEnabled()){
LOG.info("Creating new log file: " + Util.makeLogName(hdr.getZxid()));
}
// todo 关联上 我们指定的logdir位置的日志文件
logFileWrite = new File(logDir, Util.makeLogName(hdr.getZxid()));
// todo 包装进文件输出流
fos = new FileOutputStream(logFileWrite);
logStream=new BufferedOutputStream(fos);
oa = BinaryOutputArchive.getArchive(logStream);
FileHeader fhdr = new FileHeader(TXNLOG_MAGIC,VERSION, dbId);
fhdr.serialize(oa, "fileheader");
// Make sure that the magic number is written before padding.
logStream.flush();
filePadding.setCurrentSize(fos.getChannel().position());
streamsToFlush.add(fos);
}
filePadding.padFile(fos.getChannel());
byte[] buf = Util.marshallTxnEntry(hdr, txn);
if (buf == null || buf.length == 0) {
throw new IOException("Faulty serialization for header " +
"and txn");
}
Checksum crc = makeChecksumAlgorithm();
crc.update(buf, 0, buf.length);
oa.writeLong(crc.getValue(), "txnEntryCRC");
Util.writeTxnBytes(oa, buf);
return true;
}
FinalRequestProcessor
终于来到了FinalRequestProcessor处理器,它并不是线程类,但是它确实是和前两个线程类并列的,单机模式下最后一个处理器类
它处理request的逻辑那是相当长我挑着贴在下面,只是关注下面的几个点,代码并不完整哦
它的解释我写在源码的下面
public void processRequest(Request request) {
ProcessTxnResult rc = null;
// 看一看!!!!!!!!!
// 看一看!!!!!!!!!
// 看一看!!!!!!!!!
// 它在消费 outstandingChanges 队列, 没错,这个队列中对象, 就是第一个个处理器调用addChange()方法添加进去的record
// 看一看!!!!!!!!!
// 看一看!!!!!!!!!
// 看一看!!!!!!!!!
synchronized (zks.outstandingChanges) {
// todo outstandingChanges不为空且首个元素的zxid小于等于请求的zxid
while (!zks.outstandingChanges.isEmpty() && zks.outstandingChanges.get(0).zxid <= request.zxid) {
//todo 移除并返回第一个元素
ChangeRecord cr = zks.outstandingChanges.remove(0);
// todo 如果record的zxid < request.zxid 警告
if (cr.zxid < request.zxid) {
LOG.warn("Zxid outstanding "
+ cr.zxid
+ " is less than current " + request.zxid);
}
// todo 根据路径得到Record并判断是否为cr
if (zks.outstandingChangesForPath.get(cr.path) == cr) {
// 移除cr的路径对应的记录
zks.outstandingChangesForPath.remove(cr.path);
}
}
//todo 请求头不为空
if (request.hdr != null) {
// 获取请求头
TxnHeader hdr = request.hdr;
// 获取事务
Record txn = request.txn;
// todo 跟进这个方法-----<--!!!!!!-----处理事务的逻辑,在这里面有向客户端发送事件的逻辑, 回调客户端的watcher----!!!!!!-->
// todo 在这个方法里面更新了内存
rc = zks.processTxn(hdr, txn);
}
// do not add non quorum packets to the queue.
// todo 只将quorum包(事务性请求)添加进队列
if (Request.isQuorum(request.type)) {
zks.getZKDatabase().addCommittedProposal(request);
}
}
if (request.cnxn == null) {
return;
}
ServerCnxn cnxn = request.cnxn;
String lastOp = "NA";
zks.decInProcess();
Code err = Code.OK;
Record rsp = null;
boolean closeSession = false;
// todo 根据请求头的不同类型进行不同的处理
switch (request.type) {
//todo PING
case OpCode.ping: {
//todo 更新延迟
zks.serverStats().updateLatency(request.createTime);
lastOp = "PING";
//todo 更新响应的状态
cnxn.updateStatsForResponse(request.cxid, request.zxid, lastOp,
request.createTime, Time.currentElapsedTime());
cnxn.sendResponse(new ReplyHeader(-2,
zks.getZKDatabase().getDataTreeLastProcessedZxid(), 0), null, "response");
return;
}
.
.
.
// todo 如果是create , 在这里返回给客户端 结果
case OpCode.create: {
lastOp = "CREA";
rsp = new CreateResponse(rc.path);
// todo 在下面代码的最后 返回出去 rsp
err = Code.get(rc.err);
break;
}
long lastZxid = zks.getZKDatabase().getDataTreeLastProcessedZxid();
ReplyHeader hdr =
new ReplyHeader(request.cxid, lastZxid, err.intValue());
zks.serverStats().updateLatency(request.createTime);
cnxn.updateStatsForResponse(request.cxid, lastZxid, lastOp,
request.createTime, Time.currentElapsedTime());
// todo 在这里将向客户端返回信息, 跟进去查看就能看到socket相关的内容
cnxn.sendResponse(hdr, rsp, "response");
- 第一点,更新内存在内存DataTree中创建新的节点,回调watcher
rc = zks.processTxn(hdr, txn); - 第二点响应客户端
cnxn.sendResponse(hdr, rsp, "response");

 浙公网安备 33010602011771号
浙公网安备 33010602011771号