
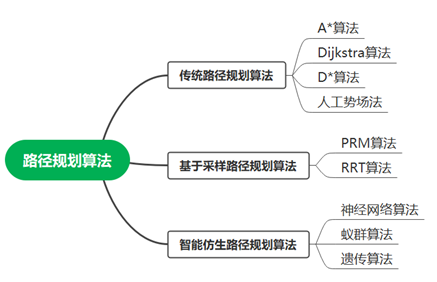
路径规划算法(1)
传统路径规划算法
1、BUG避障算法
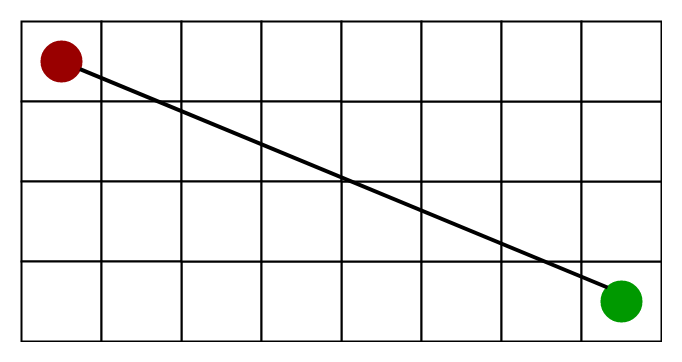
Bug算法大概是人们能想象到的最简单的避障算法。其基本思想是机器人在路途中,跟踪各障碍物的轮廓,从而绕开它。
BUG算法十分简单,就像虫子在黑盒中的移动一样,这种规划没有全局路径规划,只有局部路径规划。
根据规则的不同分为BUG0,BUG1,BUG2。
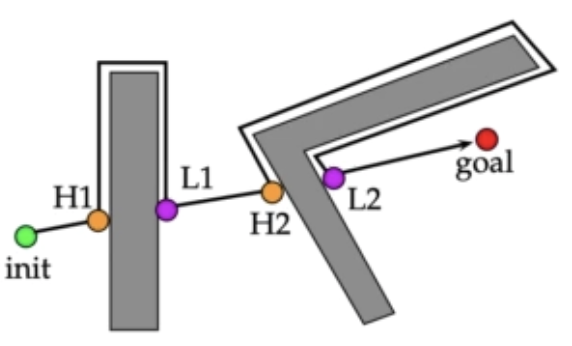
1.1、BUG0算法
规则1:超目标点径直移动
规则2:沿着障碍物边缘移动
遇到障碍物,则用规则2,其它时刻皆用规则1
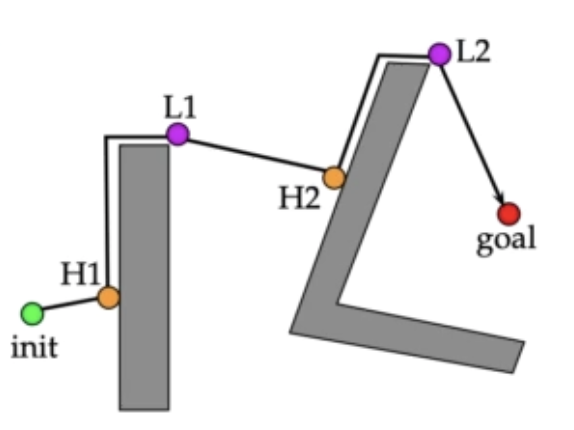
1.2、BUG1算法
规则1:超目标点径直移动
规则2:跟随障碍物的边缘,完全地围绕障碍物
规则3:从距离目标最短距离的点离开,然后再径直朝目标点移动
这种方法效率很低,但是可保证机器人会到达任何可达的目标。
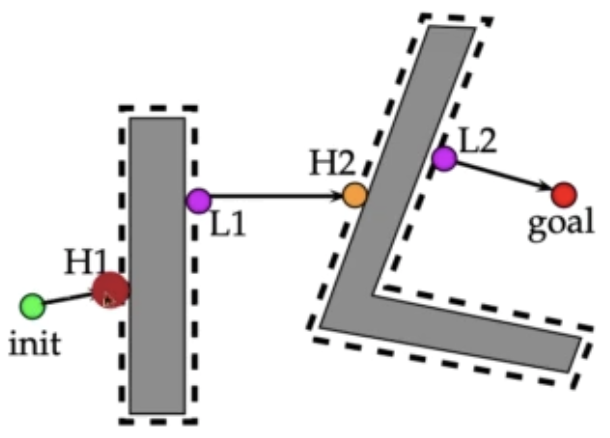
1.3、BUG2算法
规则1:超目标点作直线,径直移动
规则2:跟随障碍物的边缘,直道遇到规则1所做直线和障碍物的交点为止
2、A*算法及Dijkstra算法
A*算法是一种包含了启发的Djkstra算法,可以用来求带权值的图的最短路径。
A*算法比起Djkstra算法,在寻找最短路径的问题上更加有效率。
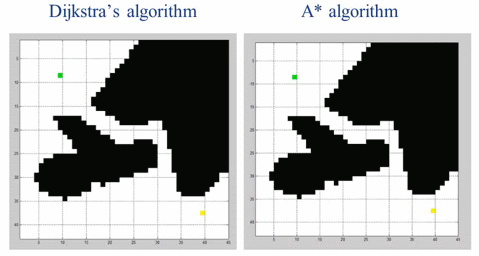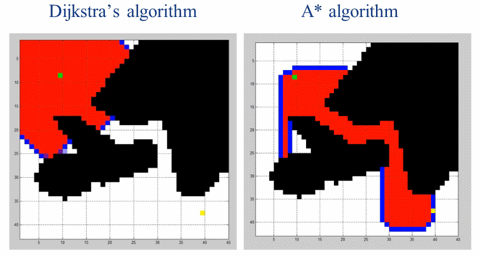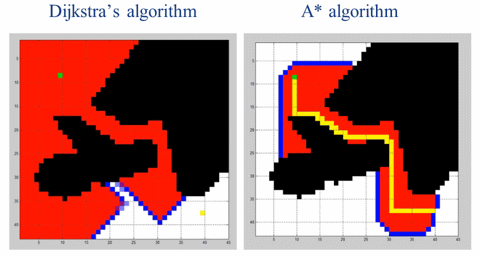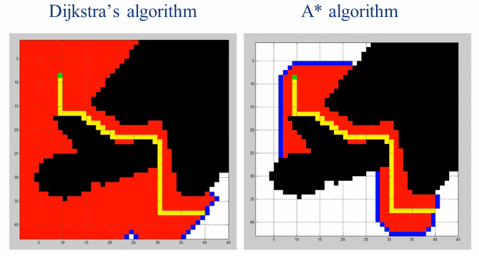
算法中,引入了距离作为启发,通过终点和节点的距离计算,选择迭代的点。
通常求距离有以下几种方案:
1. 曼哈顿距离
如果图形中只允许朝上下左右四个方向移动,则启发函数可以使用曼哈顿距离
h = abs (current_cell.x – goal.x) +
abs (current_cell.y – goal.y)

2、对角线距离
如果图形中允许斜着朝邻近的节点移动,则启发函数可以使用对角距离
h = max { abs(current_cell.x – goal.x), abs(current_cell.y – goal.y) }

3、欧式距离
如果图形中允许朝任意方向移动,则可以使用欧几里得距离。
h = sqrt ( (current_cell.x – goal.x)2 +
(current_cell.y – goal.y)2 )
3、Dijkstra算法
Dijkstra算法的基本思想是贪心思想,主要特点是以起始点为中心向外层层扩展,直到扩展到目标点为止。Dijkstra算法在扩展的过程中,都是取出未访问结点中距离该点距离最小的结点,然后利用该结点去更新其他结点的距离值。
Dijkstra算法流程:
1. 将初始点s放入到集合S中,初始时集合S中只有s;
2. 无自环的初始点s到自己的最短路径为0;
3. For(目标点ei不在集合S中):
4. 计算集合S中以外的所有结点到集合S中结点的最短距离,即从s出发,到达所有结点且只允许通过初始点s的最短路径。如果没有直达的通路,那么就设置为无穷,意味着暂时到达不了的结点。
5. While(集合V-S不是空集):
6. 选出第一次for循环之后在集合V-S中,且相对于集合S的最短路径中距离最短的目标点ej。
7. 将该目标点ej并入到集合S中。
8. 将目标点ej并入集合S之后会对V-S以外的顶点相对于集合S的最短路径长度产生影响。
9. For(更新S中的结点路径)
10. If(dist[s,ej]+wj,i < dist[s,ei])
11. dist[s,ei] = dist[s,ej]+wj,i
注:该算法不允许图中存在负权边。
优点:
1)如果最优路径存在,那么一定能找到最优路径
缺点:
1)有权图中可能是负边
2)扩展的结点很多,效率低
4、A*算法
A*算法是将Dijkstra算法与广度优先搜索算法(BFS)二者结合而成,通过借助启发式函数的作用,能够使该算法能够更快的找到最优路径。A*算法是静态路网中求解最短路径最有效的直接搜索方法。
A*算法的启发式函数:f(n)=g(n)+h(n)
f(n)表示结点的综合优先级,在选择结点时考虑该结点的综合优先级;
g(n)表示起始点到当前结点的代价值;
h(n)表示当前结点到目标点的代价估计值,启发式函数。
当h(n)趋近于0时,此时算法退化为Dijkstra算法,路径一定能找到,但速度比较慢;当g(n)趋近于0时,算法退化为BFS算法,不能保证一定找到路径,但速度特别快。我们可以通过调节h(n)的大小来调整算法的精度与速度。
在A*算法中,采用最多的是欧几里得距离,即dist = srqt((y2-y1)2+(x2-x1)2)。
A*算法流程: 1. 将起始点s加入到开启列表openlist中 2. 重复以下过程: a) 遍历开启列表openlist,寻找F值最小的结点,并将其作为当前要处理的结点 b) 将要处理的结点移到关闭列表closelist c) 对当前结点的8个相邻结点的每个结点: i. 如果他是不可抵达的或者已经在关闭列表closelist中,忽略; ii. 如果他不在开启列表openlist中,将其加入openlist,并把当前结点设置为其父节点,记录当前结点的F、G、H值; iii. 如果他已经在开启列表openlist中,检查这条路径(即经由当前结点到达相邻结点)是否更好,用G值做参考,更小的G值表示这个更好的路径,如果是这样,将其父节点设置为当前结点,并重新计算他的G值和F值,如果开启列表openlist是按F值进行排序,改变后需要重新排序。 d) 停止,当 i. 终点加入到了开启列表openlist中,此时路径已经找到 ii. 查找重点失败,并且开启列表openlist中是空的,此时没有路径 3. 保存路径,从终点开始,每个结点沿着其父节点移动直到起点。
优点:
1)利用启发式函数,搜索范围小,提高了搜索效率
2)如果最优路径存在,那么一定能找到最优路径
缺点:
1)A*算法不适用于动态环境
2)A*算法不太适合于高维空间,计算量大
3)目标点不可达时会造成大量性能消耗
5、D*算法
A*算法适用于在静态路网中寻路,在环境变化后,往往需要replan,由于A*不能有效利用上次计算的信息,故计算效率较低。D*算法由于储存了空间中每个点到终点的最短路径信息,故在重规划时效率大大提升。A*是正向搜索,而D特点是反向搜索,即从目标点开始搜索过程。在初次遍历时候,与Dijkstra算法一致,它将每个节点的信息都保存下来。
D*算法流程:
1. 先用Dijkstra算法从目标节点G向起始节点搜索。储存路网中目标点到各个节点的最短路和该位置到目标点的实际值h,k(k为所有变化h之中最小的值,当前为k=h)原OPEN和CLOSE中节点信息保存。
2. 机器人沿最短路开始移动,在移动的下一节点没有变化时,无需计算,利用上一步Dijkstra计算出的最短路信息从出发点向后追述即可,当在Y点探测到下一节点X状态发生改变,如堵塞。机器人首先调整自己在当前位置Y到目标点G的实际值h(Y),h(Y)=X到Y的新权值C(X,Y)+X的原实际值h(X)。X为下一节点(到目标点方向Y->X->G),Y是当前点。K值取h值变化前后的最小。
3. 用A*或其他算法计算,这里假设用A*算法,遍历Y的子节点,放入CLOSE,调整Y的子节点a的h值,h(a)=h(Y)+Y到子节点a的权重C(Y,a),比较a点是否存在于OPEN和CLOSE中,方法如下:用A*或者其他算法计算,这里假设用A*算法,遍历Y的子节点,放入CLOSE,调整Y的子节点a的h值,h(a)=h(Y)+Y到子节点a的权重C(Y,a),比较a点是否存在于OPEN和CLOSE中,方法如下:
while()
{
从OPEN表中取k值最小的节点Y;
遍历Y的子节点a,计算a的h值 h(a)=h(Y)+Y到子节点a的权重C(Y,a)
{
if(a in OPEN) 比较两个a的h值
if( a的h值小于OPEN表a的h值 )
{
更新OPEN表中a的h值;k值取最小的h值
有未受影响的最短路径存在
break;
}
if(a in CLOSE) 比较两个a的h值 //注意是同一个节点的两个不同路径的估价值
if( a的h值小于CLOSE表的h值 )
{
更新CLOSE表中a的h值; k值取最小的h值;将a节点放入OPEN表
有未受影响的最短路径存在
break;
}
if(a not in both)
将a插入OPEN表中; //还没有排序
}
放Y到CLOSE表;
OPEN表比较k值大小进行排序;
}
优点:
1)适用于动态环境的路径规划,搜索效率高
缺点:
1)不适用于高维空间,计算量大
2)不太适用于在距离较远的最短路径上发生变化的场景
6、人工势场法
该算法的基本思想是当机器人在周围环境中运动时,将环境设计成一种抽象的人造引力场,目标点对移动机器人产生“引力”,障碍物对移动机器人产生“斥力”,最后通过二者的合力来控制移动机器人的运动。应用人工势场法规划出来的路径一般是比较平滑并且安全的,但是存在着局部最优的问题。
利用势场函数U来建立人工势场,势场函数是一种可微函数,空间中某点处势场函数值的大小,代表了该点的势场强度。我们采用引力势场函数与斥力势场函数,用U(q)表示二者之和。
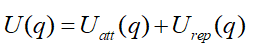
引力势场函数:
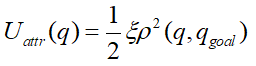
e为引力增益,p(q,qgoal)表示当前点到目标点的距离;
斥力势场函数:
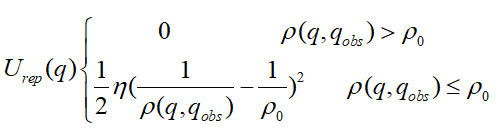
n为斥力增益,p(q,qgoal)表示当前点到障碍物的距离,p0表示障碍物作用距离阈值。
优点:
1)规划出的路径一般是比较平滑且安全
2)人工势场法是一种反馈控制策略,具有一定的鲁棒性
缺点:
1)容易陷入局部最优的问题
2)距离目标点较远时,引力特别大,斥力相对较小,可能会发生碰撞
3)当目标点附近有障碍物时,斥力非常大,引力较小,很难到达目标点
7、PRM算法
随机路线图(PRM)算法是一种基于图搜索的算法,可以将连续状态空间转换成离散状态空间,在利用A*等搜索算法在路线图上寻找路径,提高搜索效率。PRM算法是概率完备且不是最优的算法。
PRM算法流程:
1. 初始化,设G(V,E)为一个无向图,其中顶点集V代表无碰撞的状态点,连线集E代表无碰撞的路径。初始状态为空。
2. 状态点采样,在状态空间中采样无碰撞的状态点加入到无碰撞的状态点V中。
3. 邻域计算,定义距离p,对于已经存在于无碰撞的状态点V中的点,如果他与无碰撞的点的距离小于p,则将其称作无碰撞状态点的邻域点。
4. 边线连接,将无碰撞的状态点与其邻域相连,生成连线。
5. 碰撞检测,检测连线是否与障碍物发生碰撞,如果无碰撞,则将其加入到连线集E中。
6. 结束条件,当所有采样点均已完成上述步骤后结束,否则重复2~5。
优点:
1)适用于高维空间和复杂约束的路径规划问题
2)搜索效率高,搜索速度快
缺点:
1)概率完备但不是最优
8、RRT算法
RRT算法是适用于高维空间,通过对状态空间中的采样点进行碰撞检测,避免了对空间的建模,较好的处理带有非完整约束的路径规划问题,有效的解决了高维空间和复杂约束的路径规划问题。该算法是概率完备但不是最优的算法
RRT算法以初始点qinit作为根节点,通过随机采样增加叶子节点的方式,生成一个随机扩展树,当目标点位于随机扩展树上时,能够找到一天初始点到目标点的路径。首先,需要从状态空间中随机选择一个采样点qrand,然后从随机树中选择一个距离qrand最近的结点qnearest,从qnearest向qrand扩展一个步长的距离,得到一个新的结点qnew,如果qnew与障碍物发生碰撞,则返回空;否则,将qnew加入到随机树中,重复上述步骤直到qnearest和qgoal距离小于一个阈值。
优点:
1)搜索效率比较高,搜索速度比较快
2)适用于高维空间,不会产生维度灾难的问题
3)只需对状态空间采样点进行碰撞检测,避免了对空间的建模
缺点:
1)规划出的路径质量一般,可能存在棱角、不够光滑
2)RRT算法不太适用于存在狭长空间的环境
3)规划出的路径可能不是最优路径
4)不适用于动态环境的路径规划

 浙公网安备 33010602011771号
浙公网安备 33010602011771号