
卷积神经网络理解(5)
1、参数计算
在一次卷积过程中,卷积核进行共享,即每个通道采用一个卷积核即可。
在Pytorch的nn模块中,封装了nn.Conv2d()类作为二维卷积的实现。参数如下图所示
![]()
- in_channels:输入张量的channels数
- out_channels:输出张量的channels数
- kernel_size:卷积核的大小。一般我们会使用3x3这种两个数相同的卷积核,这种情况只需要写kernel_size = 3就行了。如果左右两个数不同,比如3x5,那么写作kernel_size = (3, 5)
- stride = 1:步长
- padding:填充图像的上下左右,后面的常数代表填充的多少(行数、列数),默认为0。padding = 1时,若原始图像大小为32x32,则padding后的图像大小为34x34
- dilation = 1:是否采用空洞卷积,默认为1(即不采用)
- groups = 1:决定了是否采用分组卷积,默认为1可以参考一下:groups参数的理解
- bias = True:是否要添加偏置参数作为可学习参数的一个,默认为True
- padding_mode = ‘zeros’:padding的模式,默认采用零填充
前三个参数需要手动提供,后面的都有默认值
代码示例

1 class Net(nn.Module):
2 def __init__(self):
3 nn.Module.__init__(self)
4 self.conv2d = nn.Conv2d(in_channels=3,out_channels=64,kernel_size=4,stride=2,padding=1)
5
6 def forward(self, x):
7 print(x.requires_grad)
8 x = self.conv2d(x)
9 return x
10
11 # 查看卷积层的权重和偏置
12 print(net.conv2d.weight)
13 print(net.conv2d.bias)
2、手写数字识别过程
- 将手写数字图片转换为像素矩阵
- 对像素矩阵进行Padding不为0的卷积运算,目的是保留边缘特征,生成一个特征图
- 对这个特征图使用六个卷积核进行卷积运算,得到六个特征图
- 对每个特征图进行池化操作(也可称为下采样操作),在保留特征的同时缩小数据流,生成六个小图,这六个小图和上一层各自的特征图长得很像,但尺寸缩小了
- 对池化操作后得到的六个小图进行第二次卷积运算,生成了更多的特征图
- 对第二次卷积生成的特征图进行池化操作(下采样操作)
- 将第二次池化操作得到的特征进行第一次全连接
- 将第一次全连接的结果进行第二次全连接
- 将第二次全链接的结果进行最后一次运算,这种运算可能是线性的也可能是非线性的,最终每个位置(一共十个位置,从0到9)都有一个概率值,这个概率值就是将输入的手写数字识别为当前位置数字的概率,最后以概率最大的位置的值作为识别结果。可以看到,右侧上方是我的手写数字,右侧下方是模型(LeNet)的识别结果,最终的识别结果与我输入的手写数字是一致的,这一点从图片左边最上边也可以看到,说明此模型可以成功识别手写数字
可用代码:


1 import torch 2 from torch import nn 3 import torchvision 4 from torchvision import datasets 5 from torchvision.transforms import ToTensor 6 import matplotlib.pyplot as plt 7 print(f"Pytorch version:{torch.__version__}\n torchvision version:{torchvision.__version__}") 8 9 10 11 train_data=datasets.FashionMNIST( 12 root="data", 13 train=True, 14 download=True, 15 transform=ToTensor(), 16 target_transform=None 17 ) 18 19 test_data=datasets.FashionMNIST( 20 root="data", 21 train=False, 22 download=True, 23 transform=ToTensor(), 24 target_transform=None 25 ) 26 27 28 #数据集查看 29 image, label = train_data[0] 30 # print(image) 31 # image, label #查看第一条训练数据 32 # print(image.shape) #查看数据的形状 33 34 # 查看类别 35 class_names = train_data.classes 36 # print(class_names) 37 38 39 # 图形可视化 40 # print(f"Image shape: {image.shape}") 41 plt.imshow(image.squeeze()) 42 plt.title(label) 43 # plt.show() 44 45 from torch.utils.data import DataLoader 46 47 # 设置批处理大小超参数 48 BATCH_SIZE = 32 49 50 # 将数据集转换为可迭代的(批处理) 51 train_dataloader = DataLoader(train_data, 52 batch_size=BATCH_SIZE, # 每个批次有多少样本? 53 shuffle=True # 是否随机打乱? 54 ) 55 ''' 56 shuffle:指对数据集进行随机打乱,以便在训练模型时以随机顺序呈现数据。这样做有助于提高模型的泛化能力并减少模型对输入数据顺序的依赖性。 57 相反,对于测试数据集通常被设置为False,因为在评估模型性能时,我们希望保持数据的原始顺序,以便能够正确评估模型在真实数据上的表现。 58 ''' 59 test_dataloader = DataLoader(test_data, 60 batch_size=BATCH_SIZE, 61 shuffle=False # 测试数据集不一定需要洗牌 62 ) 63 64 # #打印结果 65 # print(f"Dataloaders: {train_dataloader, test_dataloader}") 66 # print(f"Length of train dataloader: {len(train_dataloader)} batches of {BATCH_SIZE}") 67 # print(f"Length of test dataloader: {len(test_dataloader)} batches of {BATCH_SIZE}") 68 69 70 device = "cuda" if torch.cuda.is_available() else "cpu" 71 # print(device) 72 73 74 # Create a convolutional neural network 75 class FashionMNISTModelV2(nn.Module): 76 def __init__(self, input_shape: int, hidden_units: int, output_shape: int): 77 super().__init__() 78 self.block_1 = nn.Sequential( 79 nn.Conv2d(in_channels=input_shape, # 传入的图片是几层的,灰色为1层,RGB为三层 80 out_channels=hidden_units, # 输出的图片是几层 81 kernel_size=3, # 代表扫描的区域点为3*3 82 stride=1, # 就是每隔多少步跳一下 83 padding=1), # 边框补全,其计算公式 = (kernel - 1)/2 = (3-1)/2 = 1 84 # -->-- (10,3,3) 85 nn.ReLU(), 86 nn.Conv2d(in_channels=hidden_units, # 这里的输入是上层的输出为10层 87 out_channels=hidden_units, 88 kernel_size=3, 89 stride=1, 90 padding=1), 91 nn.ReLU(), 92 nn.MaxPool2d(kernel_size=2, 93 stride=2) 94 ) 95 self.block_2 = nn.Sequential( 96 nn.Conv2d(hidden_units, hidden_units, 3, padding=1), 97 nn.ReLU(), 98 nn.Conv2d(hidden_units, hidden_units, 3, padding=1), 99 nn.ReLU(), 100 nn.MaxPool2d(2) 101 ) 102 self.classifier = nn.Sequential( 103 nn.Flatten(), 104 nn.Linear(in_features=hidden_units*7*7, 105 out_features=output_shape) 106 ) 107 108 def forward(self, x: torch.Tensor): 109 x = self.block_1(x) 110 # print(x.shape) 111 x = self.block_2(x) 112 # print(x.shape) 113 x = self.classifier(x) 114 # print(x.shape) 115 return x 116 117 # 加入参数 118 torch.manual_seed(42) 119 model_2 = FashionMNISTModelV2(1, 10,len(class_names)).to(device) 120 # print(model_2) 121 122 123 # 设置loss和optimizer 124 # 导入accurcay_fn辅助函数文件 125 import requests 126 from pathlib import Path 127 128 # 从Learn PyTorch存储库中下载辅助函数(如果尚未下载) 129 if Path("helper_functions.py").is_file(): 130 print("helper_functions.py已存在,跳过下载") 131 else: 132 print("正在下载helper_functions.py") 133 # 注意:你需要使用"raw" GitHub URL才能使其工作 134 request = requests.get("https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/helper_functions.py") 135 with open("helper_functions.py", "wb") as f: 136 f.write(request.content) 137 138 # 创建loss、accuracy和optimizer 139 140 from helper_functions import accuracy_fn 141 142 # 设置loss和optimizer 143 loss_fn = nn.CrossEntropyLoss() # this is also called "criterion"/"cost function" in some places 144 optimizer = torch.optim.SGD(params=model_2.parameters(), lr=0.1) 145 146 147 # 创建一个计时器 148 from timeit import default_timer as timer 149 def print_train_time(start:float,end:float,device:torch.device=None): 150 total_time=end-start 151 print(f"Train time on {device}: {total_time:.3f} seconds") 152 return total_time 153 154 155 # 训练和测试循环 156 def train_step(model: torch.nn.Module, 157 data_loader: torch.utils.data.DataLoader, 158 loss_fn: torch.nn.Module, 159 optimizer: torch.optim.Optimizer, 160 accuracy_fn, 161 device: torch.device = device): 162 train_loss, train_acc = 0, 0 163 model.to(device) 164 for batch, (X, y) in enumerate(data_loader): 165 X, y = X.to(device), y.to(device) 166 y_pred = model(X) 167 loss = loss_fn(y_pred, y) 168 train_loss += loss 169 train_acc += accuracy_fn(y_true=y, 170 y_pred=y_pred.argmax(dim=1)) 171 optimizer.zero_grad() 172 loss.backward() 173 optimizer.step() 174 175 train_loss /= len(data_loader) 176 train_acc /= len(data_loader) 177 print(f"Train loss: {train_loss:.5f} | Train accuracy: {train_acc:.2f}%") 178 179 def test_step(data_loader: torch.utils.data.DataLoader, 180 model: torch.nn.Module, 181 loss_fn: torch.nn.Module, 182 accuracy_fn, 183 device: torch.device = device): 184 test_loss, test_acc = 0, 0 185 model.to(device) 186 model.eval() # put model in eval mode 187 # Turn on inference context manager 188 with torch.inference_mode(): 189 for X, y in data_loader: 190 X, y = X.to(device), y.to(device) 191 test_pred = model(X) 192 193 test_loss += loss_fn(test_pred, y) 194 test_acc += accuracy_fn(y_true=y, 195 y_pred=test_pred.argmax(dim=1) # Go from logits -> pred labels 196 ) 197 test_loss /= len(data_loader) 198 test_acc /= len(data_loader) 199 print(f"Test loss: {test_loss:.5f} | Test accuracy: {test_acc:.2f}%\n") 200 201 torch.manual_seed(42) 202 203 from timeit import default_timer as timer 204 train_time_start_model_2 = timer() 205 from tqdm import tqdm 206 207 epochs = 3 208 for epoch in tqdm(range(epochs)): 209 print(f"Epoch: {epoch}\n---------") 210 train_step(data_loader=train_dataloader, 211 model=model_2, 212 loss_fn=loss_fn, 213 optimizer=optimizer, 214 accuracy_fn=accuracy_fn, 215 device=device 216 ) 217 test_step(data_loader=test_dataloader, 218 model=model_2, 219 loss_fn=loss_fn, 220 accuracy_fn=accuracy_fn, 221 device=device 222 ) 223 224 train_time_end_model_2 = timer() 225 total_train_time_model_2 = print_train_time(start=train_time_start_model_2, 226 end=train_time_end_model_2, 227 device=device) 228 229 230 # 模型评估和结果输出 231 torch.manual_seed(42) 232 233 234 def eval_model(model: torch.nn.Module, 235 data_loader: torch.utils.data.DataLoader, 236 loss_fn: torch.nn.Module, 237 accuracy_fn, 238 device: torch.device = device): # 注意 239 loss, acc = 0, 0 240 model.eval() 241 with torch.inference_mode(): 242 for X, y in data_loader: 243 # 注意设备转移 244 X, y = X.to(device), y.to(device) 245 y_pred = model(X) 246 loss += loss_fn(y_pred, y) 247 acc += accuracy_fn(y_true=y, y_pred=y_pred.argmax(dim=1)) 248 249 loss /= len(data_loader) 250 acc /= len(data_loader) 251 return {"model_name": model.__class__.__name__, 252 "model_loss": loss.item(), 253 "model_acc": acc} 254 255 256 model_2_results = eval_model( 257 model=model_2, 258 data_loader=test_dataloader, 259 loss_fn=loss_fn, 260 accuracy_fn=accuracy_fn 261 ) 262 print(model_2_results)
3、补充知识点
如果输入图像的size为(N, N),卷积核的size为(F, F),输出的特征图的size为 (N-F)/ stride +1
如下图,当步长=3时,输出特征图size是小数,应该避免这种情况,在原图的周围使用0填充,使输出特征图size是整数。
使用padding后,输出特征图size公式变为:(N+2P-F)/ stride +1
p 代表原图周围padding几圈。如果 p =(F-1)/ 2,且步长=1,那么输入和输出特征图的size相同。

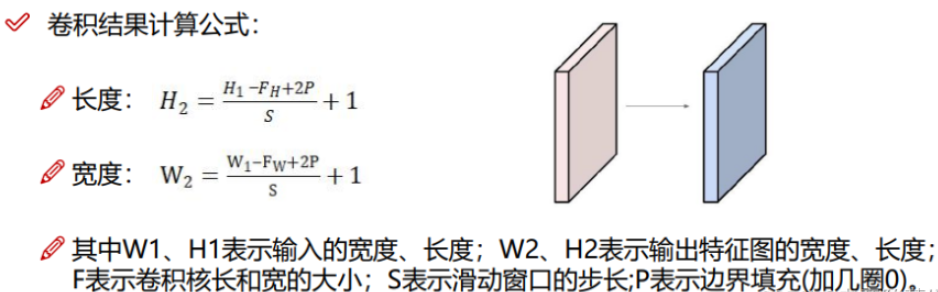
1x1卷积是指 卷积核的长宽都等于1。如下图所示,输入特征图的shape为 [64, 64, 192],一个卷积核shape为 [1, 1, 192],对应元素相乘再相加,得到卷积输出特征图的shape为 [64, 64, 1]
可以使用不同个数的1x1卷积核来升维或降维,如果1x1卷积核个数是128个,就将输入图像的shape从 [64, 64, 192] 降为 [64, 64, 128]。
1x1卷积的作用:(1)降维或升维;(2)跨通道信息交融;(3)减少参数量;(4)增加模型深度,提高非线性表示能力。
如下图(a)所示,使用 5x5x256 的卷积核计算,参数量有二十万。操作数160.5M,可理解为每张输出特征图都是由一次卷积得来的,每一次卷积的运算量就是每个卷积核的size = 5*5
如图(b)所示,先用1x1卷积核降维,再用5x5卷积提取特征,每个1x1卷积核的参数量只有1*1*256。大大减少了计算量
4、ReLU函数()
nn.ReLU()用来实现Relu函数,实现非线性。ReLU函数有个inplace参数,如果设为True,它会把输出直接覆盖到输入中,这样可以节省内存。之所以可以覆盖是因为在计算ReLU的反向传播时,只需根据输出就能够推算出反向传播的梯度。一般不使用inplace操作。
激活函数的作用是把神经元的输入线性求和后,放入非线性的激活函数中激活,正因为有非线性的激活函数,神经网络才能拟合非线性的决策边界,解决非线性的分类和回归问题

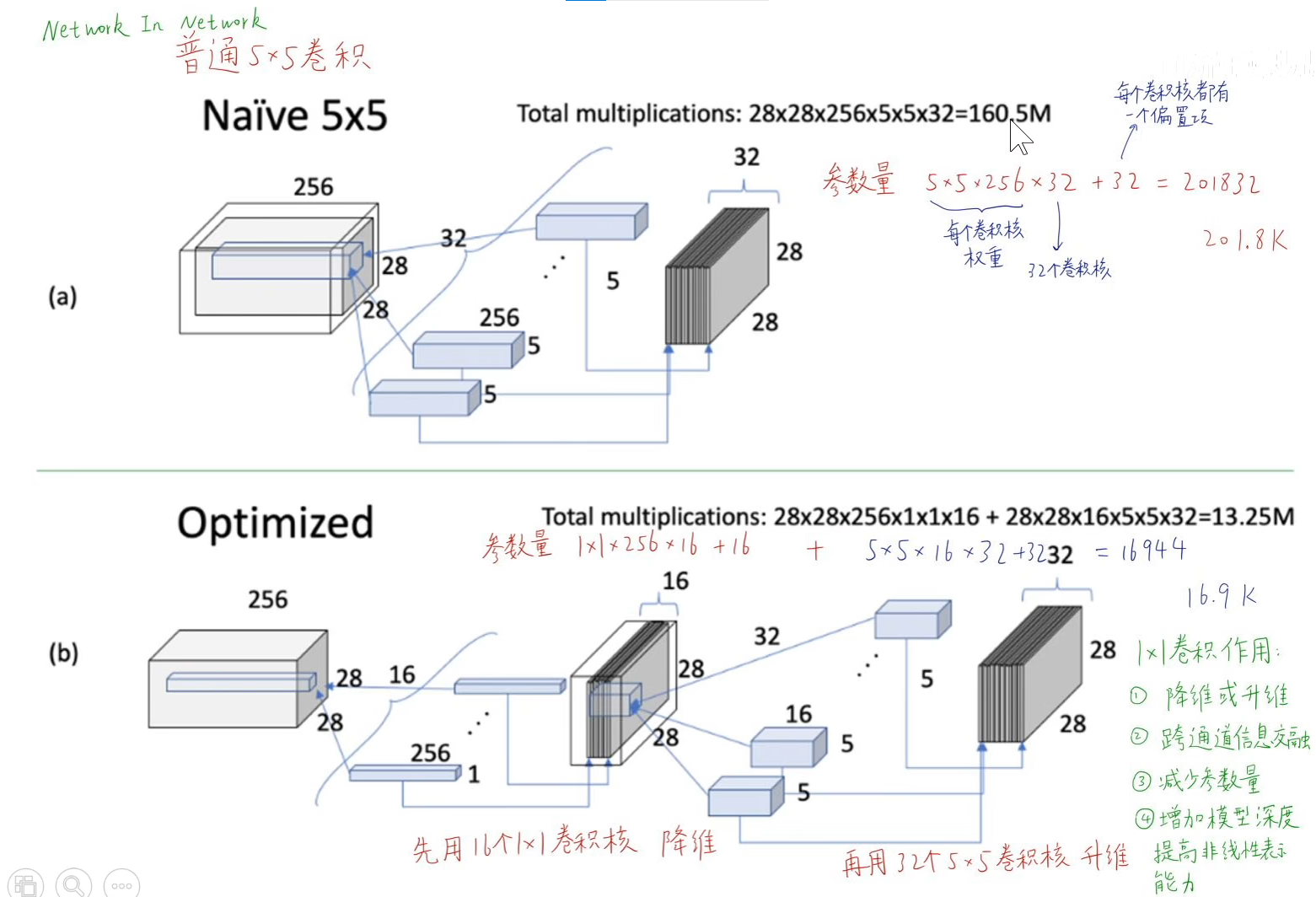
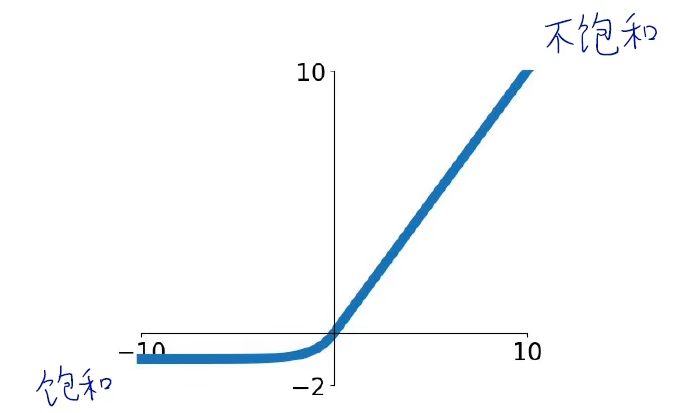
ReLU函数又称为修正线性单元,将输入小于0的数都抹为0。
公式:
特点:
(1)函数不会饱和,x大于0时,输入有多大,输出就有多大。
(2)计算简单,几乎不消耗计算资源。
(3)x大于0时,梯度能得到保留,因此ReLU函数比sigmoid函数的收敛速度快6倍以上。
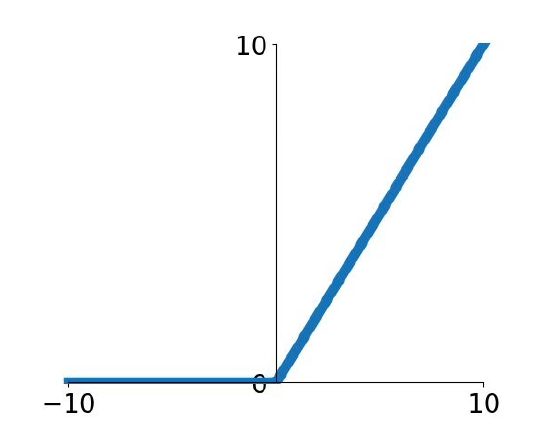
缺陷:
(1)输出不是关于0对称
(2)x小于0时,梯度为0。导致一些神经元是死的(dead ReLU),既不会产生正的输出,也不会产生正的梯度,也不会发生更新。
导致Dead ReLU原因是:① 初始化不良,随机初始化的权重,让神经元所有的输出都是0,梯度等于0;② 学习率太大,步子跨太大容易乱窜
为了解决Dead ReLU的问题,在ReLU的权重上加一个偏置项0.01,保证所有的神经元一开始都能输出一个正数,使所有的神经元都能获得梯度更新
ReLU函数改进:
为了解决ReLU函数x小于0,梯度为0的情况,推出了Leaky ReLU 和 ELU函数。
Leaky ReLU函数给x小于0时,乘以一个非常小的权重。
公式:
x小于0时满足线性关系
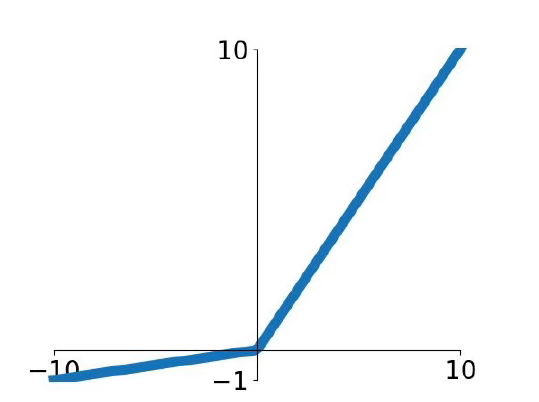
ELU函数给x小于0时,使用指数函数
公式:
改善了ReLU函数输出不关于0对称的问题,但是使用指数运算会带来更大的计算量


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律