
python卷积神经网络常见的命令理解(1)
1、drop()删除行列
drop()详细的语法如下:
删除行是index,删除列是columns:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, inplace=False)
参数:
labels:要删除的行或列的标签,可以是单个标签,也可以是标签列表。
axis:要删除的行或列的轴,0表示行,1表示列。
index:要删除的行的索引,可以是单个索引,也可以是索引列表。
columns:要删除的列的列名,可以是单个列名,也可以是列名列表。
inplace:是否在原DataFrame上进行操作,默认为False,即不在原DataFrame上进行操作。
(1)删除行、列
1 print(frame.drop(['a']))
2 print(frame.drop(['b'], axis = 1))#drop函数默认删除行,列需要加axis = 1
(2)inplace参数
1 DF.drop('column_name', axis=1); 2 DF.drop('column_name',axis=1, inplace=True) 3 DF.drop([DF.columns[[0,1, 3]]], axis=1, inplace=True)
对原数组作出修改并返回一个新数组,往往都有一个 inplace可选参数。
- 如果手动设定为True(默认为False),那么原数组直接就被替换。
也就是说,采用inplace=True之后,原数组名对应的内存值直接改变(如2和3情况所示);
- 而采用inplace=False之后,原数组名对应的内存值并不改变,
- 需要将新的结果赋给一个新的数组或者覆盖原数组的内存位置(如1情况所示)。
2、plt.imshow()函数:显示图像
2.1、概念
plt.imshow()是Matplotlib中的一个函数,用于显示图像。它可以传递一个二维或三维数组作为image参数, 并将图像数据显示为图形,并对图像进行不同的可视化设置。
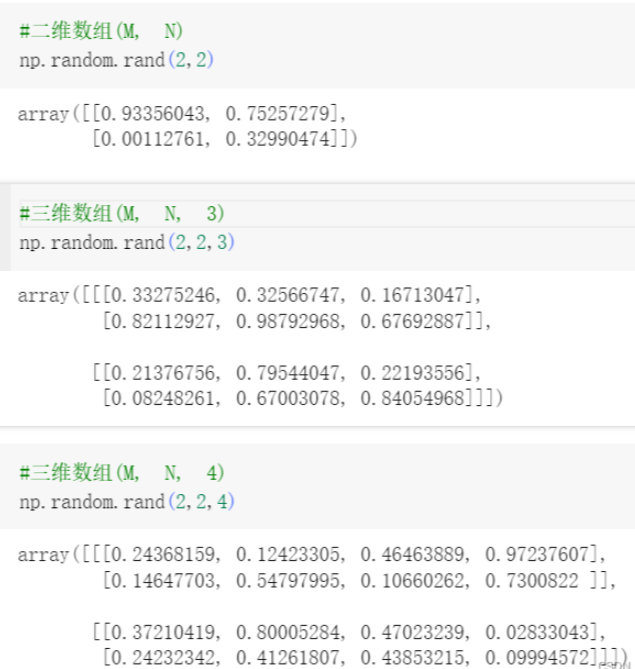
关于二维/三维数组的解释说明
image支持的数组形状包括:
(M, N):具有标量数据的图像。使用归一化和颜色映射将值映射到颜色。
(M, N, 3):具有RGB值(0-1浮点数或0-255整数)的图像。
(M, N, 4):具有RGBA值(0-1浮点数或0-255整数)的图像,即包括透明度。
前两个维度(M, N)定义了图像的行和列。
超出范围的RGB(A)值将被裁剪。
1 #二维数组(M, N)
2 np.random.rand(2,2)
3 #三维数组(M, N, 3)
4 np.random.rand(2,2,3)
5 #三维数组(M, N, 4)
6 np.random.rand(2,2,4)
matplotlib.pyplot.imshow(X, cmap=None, norm=None, aspect=None, interpolation=None, alpha=None,
vmin=None, vmax=None, origin=None, extent=None, shape=, filternorm=1, filterrad=4.0,
imlim=, resample=None, url=None, \*, data=None, \*\*kwargs)
参数:此方法接受以下描述的参数:
- X:此参数是图像的数据。
- cmap:此参数是颜色图实例或注册的颜色图名称。
- norm:此参数是Normalize实例,将数据值缩放到规范的颜色图范围[0,1]以映射到颜色
- vmin, vmax:这些参数本质上是可选的,它们是颜色栏范围。
- alpha:此参数是颜色的强度。
- aspect:此参数用于控制轴的纵横比。
- interpolation:此参数是用于显示图像的插值方法。
- origin:此参数用于将数组的[0,0]索引放置在轴的左上角或左下角。
- resample:此参数是用于类似的方法。
- extent:此参数是数据坐标中的边界框。
- filternorm:此参数用于防颗粒图像调整大小过滤器。
- filterrad:此参数是具有半径参数的滤镜的滤镜半径。
- url:此参数设置创建的AxesImage的url。
- cmap:颜色设置。常用的值有’viridis’、‘gray’、'hot’等。可以通过plt.colormaps()查看可用的颜色映射。
- aspect:调整坐标轴。这将根据图像数据自动调整坐标轴的比例。常用的值有’auto’、'equal’等。设置为’auto’时会根据图像数据自动调整纵横比,而设置为’equal’时则会强制保持纵横比相等。
- interpolation:插值方法。它定义了图像在放大或缩小时的插值方式。常用的值有’nearest’、‘bilinear’、'bicubic’等。较高的插值方法可以使图像看起来更平滑,但计算成本更高。
- alpha:透明度。它允许您设置图像的透明度,取值范围为0(完全透明)到1(完全不透明)之间。
- vmin和vmax:用于设置显示的数据值范围。当指定了这两个参数时,imshow()将会根据给定的范围显示图像,超出范围的值会被截断显示。
2.2、具体使用
1 import numpy as np
2 import matplotlib.pyplot as plt
3
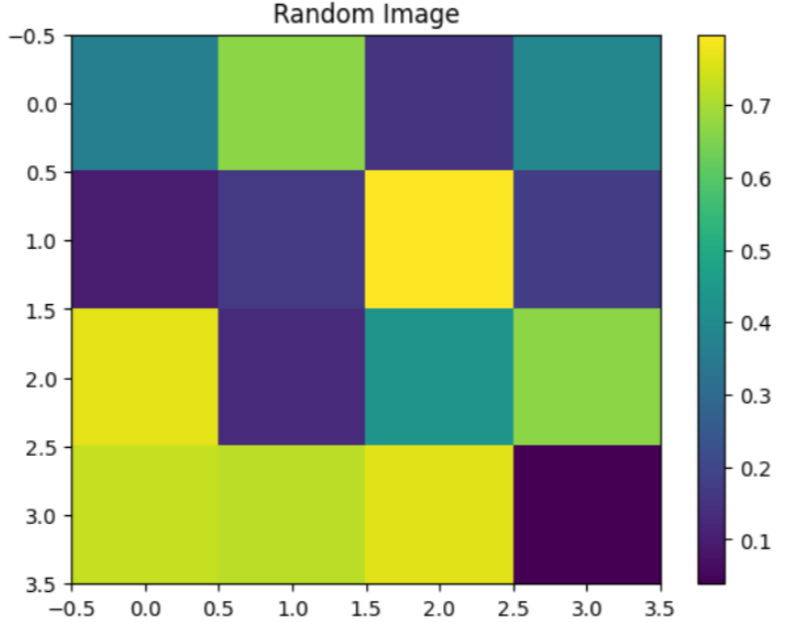
4 # 创建一个简单的二维数组作为图像数据
5 image = np.random.rand(4, 4)
6
7 # 显示图像
8 plt.imshow(image, cmap='viridis', interpolation='nearest', aspect='auto')
9 plt.colorbar() # 显示颜色条
10 plt.title('Random Image') # 设置标题
11 plt.show() # 注意必须带上这个,才会显示图像
显示彩色图像时,可以不使用cmap参数,因为默认颜色映射表是彩色的。
1 import matplotlib.pyplot as plt
2
3 color_img = plt.imread("color_image.jpg")
4 plt.imshow(color_img)
5 plt.show()
显示灰度图像时,可以使用cmap参数设置为'gray',这样可以将图像的颜色映射表设置为灰度级。
1 import matplotlib.pyplot as plt
2
3 gray_img = plt.imread("gray_image.jpg")
4 plt.imshow(gray_img, cmap="gray")
5 plt.show()
显示图像的一部分,有时候我们只需要显示图像的一部分,可以通过slicing方式实现。
1 import matplotlib.pyplot as plt
2
3 img = plt.imread("image.jpg")
4 cropped_img = img[100:200, 200:300] # 显示图像的第100~200行和第200~300列
5 plt.imshow(cropped_img)
6 plt.show()
显示多张图像可以通过subplot函数显示多张图像。
1 import matplotlib.pyplot as plt
2
3 img1 = plt.imread("image1.jpg")
4 img2 = plt.imread("image2.jpg")
5
6 plt.subplot(1,2,1)
7 plt.imshow(img1)
8 plt.subplot(1,2,2)
9 plt.imshow(img2)
10 plt.show()
3、 DataLoader作用
3.1、 基本概念
DataLoader是一个可迭代的数据装载器,组合了数据集和采样器,并在给定数据集上提供可迭代对象。可以完成对数据集中多个对象的集成。
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=None, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False,
drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None,
generator=None, *, prefetch_factor=2, persistent_workers=False, pin_memory_device='')
先导概念介绍:
- Epoch: 所有训练样本都已输入到模型中,称为一个epoch
- Iteration: 一批样本(batch_size)输入到模型中,称为一个Iteration,
- Batchsize: 一批样本的大小, 决定一个epoch有多少个Iteration
常用的主要有以下五个参数:
- dataset(数据集):需要提取数据的数据集,Dataset对象
- batch_size(批大小):每一次装载样本的个数,int型
- shuffle(洗牌):进行新一轮epoch时是否要重新洗牌,Boolean型
- num_workers:是否多进程读取机制
- drop_last:当样本数不能被batchsize整除时, 是否舍弃最后一批数据
3.2、具体使用
导入并实例化DataLoader
创建一个dataloader,设置批大小为4,每一个epoch重新洗牌,不进行多进程读取机制,不舍弃不能被整除的批次。
1 #导入数据集的包
2 import torchvision.datasets
3 #导入dataloader的包
4 from torch.utils.data import DataLoader
5 from torch.utils.tensorboard import SummaryWriter
6
7 #创建测试数据集
8 test_dataset = torchvision.datasets.CIFAR10(root="./CIRFA10",train=False,transform=torchvision.transforms.ToTensor())
9 #创建一个dataloader,设置批大小为4,每一个epoch重新洗牌,不进行多进程读取机制,不舍弃不能被整除的批次
10 test_dataloader = DataLoader(dataset=test_dataset,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
数据集中数据的读取
由于数据集中的数据已经被我们转换成了tensor型,我们用dataset[0]输出第一张图片,使用shape属性输出tensor类型的大小,target代表图片的标签。
1 img,target = test_dataset[0]
2 print(img.shape,target)

可以看到图片有RGB3个通道,大小为32*32,target为3。
在dataset中,每一个对象元组由一张图片对象img和一个标签target组成;
而dataloader中会分别对一个批次中的图片和标签进行打包,因此dataloader中,每一个对象由元组由batchsize张图片对象imgs和batchsize个标签targets组成。
- 对一个批次中的所有图片对象进行打包,形成一个对象,我们叫它imgs
- 对一个批次中所有的标签进行打包,形成一个对象,我们叫它targets
我们需要通过for循环来取出loader中的对象,loader中的对象个数=数据集中对象个数/batch_size,故应为10000/4=2500个对象。
1 #导入数据集的包
2 import torchvision.datasets
3 #导入dataloader的包
4 from torch.utils.data import DataLoader
5 from torch.utils.tensorboard import SummaryWriter
6
7 #创建测试数据集
8 test_dataset = torchvision.datasets.CIFAR10(root="./CIRFA10",train=False,transform=torchvision.transforms.ToTensor())
9 #创建一个dataloader,设置批大小为4,每一个epoch重新洗牌,不进行多进程读取机制,不舍弃不能被整除的批次
10 test_dataloader = DataLoader(dataset=test_dataset,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
11
12 #测试数据集中第一张图片对象
13 img,target = test_dataset[0]
14 print(img.shape,target)
15
16 #打印数据集中图片数量
17 print(len(test_dataset))
18
19 #loader中对象
20 for data in test_dataloader:
21 imgs,targets = data
22 print(imgs.shape)
23 print(targets)
24
25 #dataloader中对象个数
26 print(len(test_dataloader))
loader中的对象格式:

- imgs的维度变成了4*3*32*32,即四张图片,每张图片3个通道,每张图片大小为32*32。
- targets里有4个target,分别是四张图片的target。
3.3、改变shuffle
每一轮epoch之后就是分配完了一次数据,而shuffle决定了是否在新一轮epoch开始时打乱所有图片的属性进行分配。
在代码中epoch就是最外层的循环,假设我们的epoch=2,即需要分配两次数据:
- shuffle=TRUE代表第一轮循环结束后会打乱数据集中所有图片的顺序重新进行分配。
- shuffle=FALSE代表第一轮循环结束后不打乱数据集中所有图片的顺序,还是按原顺序进行分配。
shuffle=False时,可以看到epoch=0和epoch=1的每一个step中的图片都是分配的相同的,说明每一轮大循环开始前没有在数据集中重新打乱顺序。
shuffle=True时,可以看到epoch=0和epoch=1的每一个step中的图片不同了,说明每一轮大循环开始前都在数据集中重新打乱了顺序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号