
python中csv文件操作总结
1、csv文件简介
CSV文件是一种常见的文本文件格式,全称为Comma-Separated Values(逗号分隔值)。
它被广泛用于存储表格数据,如电子表格和数据库中的数据。
CSV文件的结构非常简单,每行表示数据中的一行,每个字段之间使用特定的分隔符(通常是逗号)进行分隔。
每行的字段数量应相同,以便正确解析数据。通常,第一行是字段名,用于标识每个字段的含义。
以下是一个示例CSV文件(data.csv,下文会用到)的内容:
1 Name,Age,Email
2 John,25,john@example.com
3 Emma,32,emma@example.com
在上面的示例中,第一行指定了三个字段的名称:Name、Age和Email。接下来的两行分别是具体的数据行,每个字段由逗号进行分隔。
CSV文件的优点是它的简单性和易读性。它可以被多个应用程序和编程语言轻松解析和处理。Python提供了许多库(如csv模块)来读取和写入CSV文件,能够轻松地处理和操作其中的数据。
2、读取CSV文件

1 import csv
2
3 with open('data.csv', 'r') as file:
4 reader = csv.reader(file)
5 for row in reader:
6 print(row)
7
8 """终端输出结果:
9 ['Name', 'Age', 'Email']
10 ['John', '25', 'john@example.com']
11 ['Emma', '32', 'emma@example.com']
12 """
上述代码将打开名为"data.csv"的CSV文件,并使用csv.reader函数创建一个阅读器对象。然后,通过循环迭代阅读器对象,逐行读取CSV文件的内容并进行处理。
如果CSV文件的第一行是标题行,可以使用next()函数跳过标题行,然后处理数据行:
1 import csv
2
3 with open('data.csv', 'r') as file:
4 reader = csv.reader(file)
5 headers = next(reader) # 跳过标题行
6 print(f"headers:{headers}\n--------------------------------")
7 for row in reader:
8 print(row)
9
10 """终端输出结果:
11 headers:['Name', 'Age', 'Email']
12 --------------------------------
13 ['John', '25', 'john@example.com']
14 ['Emma', '32', 'emma@example.com']
15 """
3、写入CSV文件
1 import csv
2
3 data2 = [
4 ['Name', 'Age', 'Email'],
5 ['Jobs', '20', 'jobs@example.com'],
6 ['cook', '35', 'cook@example.com']
7 ]
8
9 with open('data2.csv', 'w', newline='') as file:
10 writer = csv.writer(file)
11 writer.writerows(data2)
上述代码将创建一个名为"data2.csv"的CSV文件,并使用csv.writer函数创建一个写入器对象。
然后,使用writerows()方法将数据写入CSV文件。
注意,在打开文件时,我们将newline=''传递给open()函数,这是为了避免在Windows系统上出现额外的空行。
4、使用pandas读入csv文件
import pandas as pd
读取csv文件数据
读取train.csv数据:
train_df = pd.read_csv(r'C:\Users\86177\Desktop\experiment\train.csv')
查看数据信息
print(train_df)
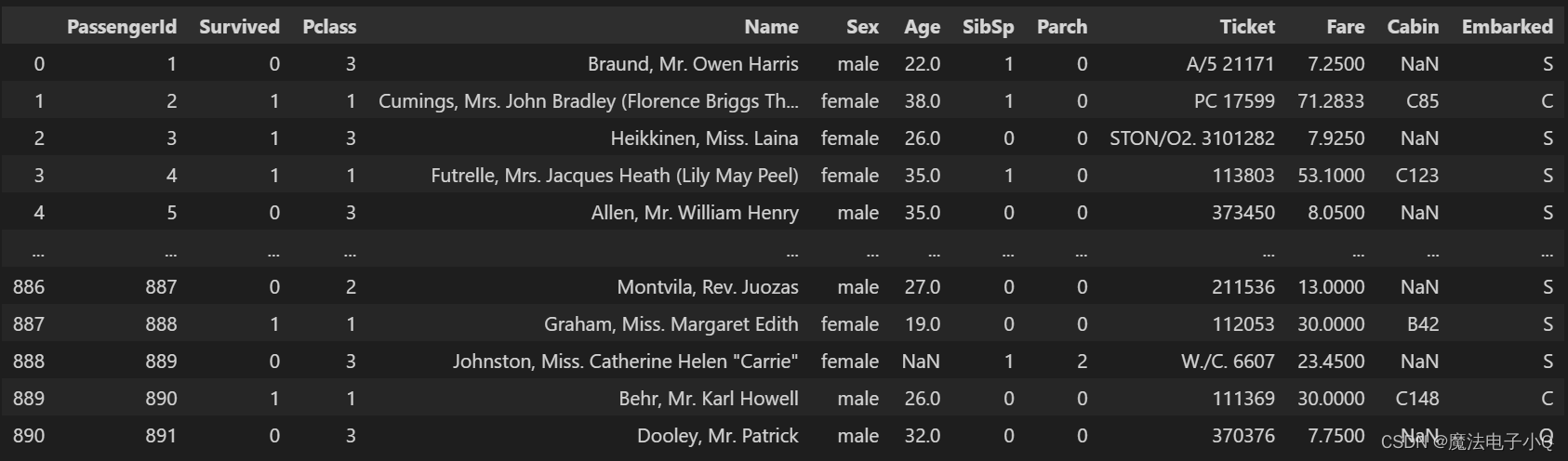
查看前五个数据
print(train_df.head())

查看是否有空值
train_df.isnull( ).any(

5、处理csv文件中的缺失值和特殊字符
当读取csv文件时,我们有时会遇到一些缺失值或者特殊字符。为了防止出现数据错误,我们需要对这些问题进行处理。
1、处理缺失值:
在csv文件中,缺失值通常用NaN或者空格表示。在Python中,我们可以使用Pandas库的read_csv()函数读取csv文件,并使用dropna()函数删除含有缺失值的行:
1 import pandas as pd
2
3 df = pd.read_csv('example.csv')
4 df.dropna(inplace=True)
2、处理特殊字符:
在csv文件中,有些特殊字符可能会打乱数据结构,影响后续的数据处理和分析。在Python中,我们可以使用csv模块的quotechar和quoting参数来处理特殊字符。
1 import csv
2
3 with open('example.csv', 'r') as csvfile:
4 reader = csv.reader(csvfile, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
5 for row in reader:
6 print(row)
上述代码中,我们使用quotechar='"'指定了csv文件中的引号符为双引号,使用quoting参数指定了csv.QUOTE_MINIMAL,表示尽可能保留原有数据结构。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏