
卷积神经网络理解(2)
1、卷积神经网络的特点
卷积神经网络相对于普通神经网络在于以下四个特点:
- 局部感知域:CNN的神经元只与输入数据的一小部分区域相连接,这使得CNN对数据的局部结构具有强大的敏感性,可以自动学习到图像的特征。
- 参数共享:在CNN中,同一个卷积核(filter)在整个输入图像上滑动,共享权重和偏置。这减少了网络的参数量,提高了模型的泛化能力。
- 池化层:通过池化层,CNN可以降低特征图的分辨率,减少计算量,同时保留主要的特征信息,提高了网络的抗噪能力和泛化能力。
- 层次化特征提取:通过堆叠多层卷积层和池化层,网络可以逐级提取图像的抽象特征,从低级特征如边缘到高级特征如纹理、形状等。
2、卷积核如何获得的理解
卷积核参数的学习是通过反向传播算法来实现的。
在卷积神经网络的训练过程中,首先随机初始化卷积核参数。
然后,通过前向传播将输入数据与卷积核进行卷积操作,得到输出特征图。
接着,将输出特征图与标签数据进行比较,计算损失函数。
最后,通过反向传播算法,根据损失函数的梯度更新卷积核参数,使得损失函数最小化。
总结起来:卷积神经网络的卷积核参数是通过反向传播算法学习出来的。
在训练过程中,通过前向传播将输入数据与卷积核进行卷积操作,得到输出特征图。
然后,通过计算损失函数并利用反向传播算法,根据梯度更新卷积核参数,使得网络能够自动提取输入数据中的特征。
这样,卷积神经网络就能够实现图像识别和计算机视觉任务。
3、卷积操作的理解
图像上每个像素点都是一个数据,我们可以把图像看出一个 n×m 的矩阵。
这里我们可以定义一个 x×y 的矩阵,这个矩阵就叫做卷积核。(按照上面的理解,初始的卷积核随机生成)
卷积核一般选择 3×3 或者 5×5 的,小尺寸的卷积核可以捕获图像中的局部特征,同时避免过度拟合。与较大的卷积核相比,小尺寸的卷积核需要更少的参数,因此层数可以更深,模型可以更加复杂。
举例说明:
设图像的矩阵为5X5的矩阵:
使用的卷积核是3X3的矩阵:
设步长为1,也就是卷积核每次移动一格
先取出图片矩阵中左上角3X3的矩阵:
将它们与卷积核相乘,这里不是矩阵的乘法,而是求内积,就是将两个矩阵对应位置的数相乘,然后再把数字相加起来.
即:
1 X 1 + 2 X 2 + 3 X 3 + 6 X 4 + 7 X 5 + 8 X 6 + 11 X 7 + 12 X 8 + 13 X 9 = 411
这样我们可以将运算后的结果放在矩阵中:
步长为1,就是将卷积核向右移动一格,接下来和卷积核进行卷积操作的矩阵是:
然后运算完成之后再填充入矩阵,放在411右边的位置。
对这一层的矩阵进行完卷积操作,由于步长为1,移动到下一层,如此循环,直到将图像遍历完成,就会输出一个比原图像小的矩阵:

步长改变为2
这里还可以将步长设置为2,对于图像来说,矩阵
与卷积核进行卷积后,跳过一格,接下来是
与卷积核进行操作。在换行的时候也是跳过一格,是
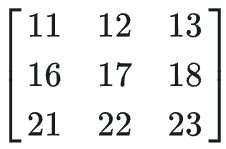 与卷积核进行操作,最后得到的是一个2 X 2 的矩阵。
与卷积核进行操作,最后得到的是一个2 X 2 的矩阵。
增加偏置系数b
我们也可以在卷积运算的基础上加上一个偏置系数b ,结果就是输出的矩阵每个数字都增加了 b。
拿刚才步长为1的情况来说,就是
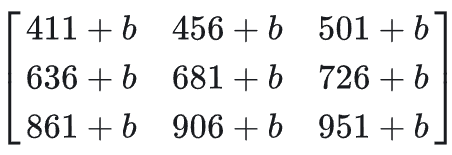
填充
有时候为了让输出图像和原图像大小相等,还会在图像外围加上 padding 。
比如上面的5 X 5 矩阵,当padding = 1 时,

这样对图像用 3×3 ,步长为1的卷积核进行卷积操作后,就会得到 5×5 的矩阵了。
我们知道,在线性回归 中,已知的是X和 y ,我们要找的就是拟合数据的最优的W .
在卷积神经网络中,卷积核就是W ,它的初始值可以随便设,然后通过梯度下降法最小化损失函数来实现找到最优的卷积核参数。
至于卷积核该选择多大的,步长多少,要不要偏置系数,要不要padding。
对于不同的数据我们也得进行不同的分析,只有不断地尝试,才能够找到最优的方案。
4、池化操作的理解
池化可以对图片数据进行降维处理,常见的池化有最大池化,平均池化。
下面用 4×4 的矩阵来举例子:
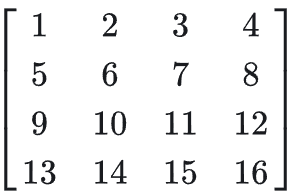
我们比如选择 2×2 的池化窗口,步长为1.
最大池化就是对取最大值,即6,然后移动到
中取最大值7,以此类推,步长同卷积操作,最后得到池化后的矩阵:

平均池化就是对取平均值,例如
,如果这时候不是整数,可以用向下取整的方式取3.
池化要考虑的同样有选择几乘几的池化窗口(池化核),选择平均池化还是最大池化,步长为多少,
还有 padding操作,这里也需要根据具体情况具体分析。
5、激活函数
在卷积操作中,我们将卷积核和图像在对应位置上进行相乘,再求和,这是一个线性的变换。
我们还需要一些非线性的变换,来增加模型的表达能力。
相信看过卷积神经网络结构(CNN)的伙伴们都知道,激活函数无处不在,特别是CNN中,在卷积层后,全连接(FC)后都有激活函数Relu的身影,
那么这就自然不得不让我们产生疑问:
问题1、为什么要用激活函数?它的作用是什么?
问题2、在CNN中为什么要用Relu,相比于sigmoid,tanh,它的优势在什么地方?
对于第1个问题:由 y = w * x + b 可知,如果不用激活函数,每个网络层的输出都是一种线性输出,而我们所处的现实场景,其实更多的是各种非线性的分布。
这也说明了激活函数的作用是将线性分布转化为非线性分布,能更逼近我们的真实场景。
下面介绍常见的几种激活函数:
ReLU函数: , 当x为负数时候
, 当x 为正数的时候, 它为x。
例如图像:经过ReLU函数激活就会变成
。
tanh(x)函数:
sigmoid函数:
6、全连接层
当我们把图像进行多次(也可以一次)卷积、池化、激活函数操作后,图像会变得相对较小,这时我们可以将它们转换成一维向量。
例如我们可以将 3×3 的矩阵转成 1×9 矩阵,然后我们可以放入全连接层。
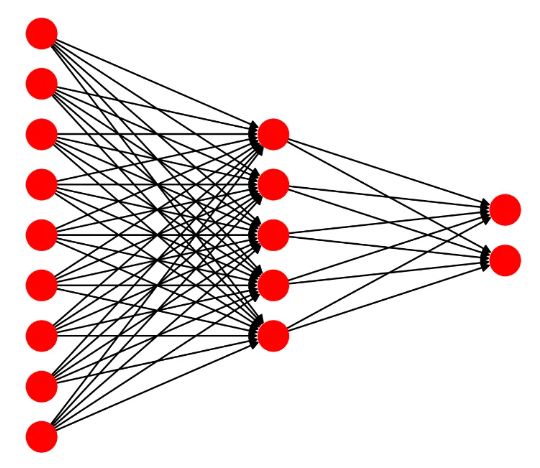
上图这些红色的点按列来看是3层,分别有9个,5个,2个数据点。比如我们进行2分类,最后一层就放2个点。
这些连接每一层的黑色的线就是权重,它们的值和卷积核一样,也是随便设置的,之后会随着损失函数的降低会自动调整成最优的参数.
前向传播
这里拿下图来举个例子.
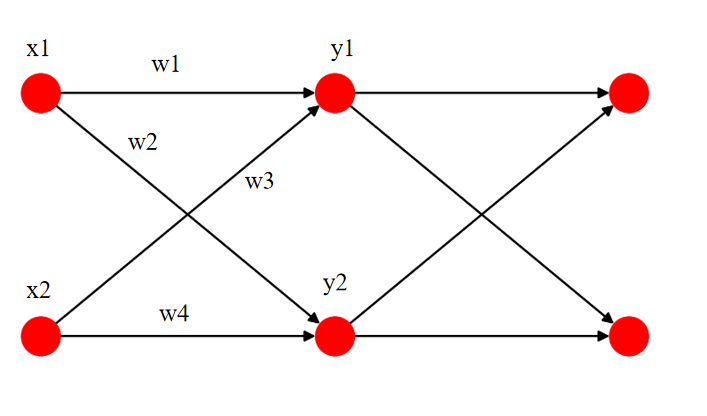
我们通过卷积和池化的操作得到了图像,然后将图像展平为一维向量 [x1, x2, ........, xn].
例如这里的 x1,x2 ,我们设置一个全连接层,设置输出的那层是2个点,即 y1,y2 .
我们已经初始化好了 w1,w2,w3,w4 .
故y1 = x1w1 + x2w3 , y2 = x1w2 + x2w4.
这样就将数据传入了下一层,由于我们是用梯度下降法更新权重,所以反向传播就是求偏导。
7、softmax函数
经过全连接层,我们进行几分类就会得到几个数据点。然后再对它们进行归一化处理,使这些数据点相加之和为1,并且每个点都是0~1之间的概率分布值。
softmax函数的表达式为
softmax函数用到了指数函数,所以当x变化一点,
变化会很大。能够将差距大的数值差距变得更大,容易区分;
但是,由于是指数函数,当x比较大的时候,会很大,容易出现数值溢出
当softmax作为输出节点的激活函数的时候,一般会将交叉熵作为损失函数。
因为 softmax函数将输出的数据转化成了一个个0~1之间的概率值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号