

FCN学习笔记
1.FCN
FCN,Fully Convolutional Network的缩写,中文名叫全卷积神经网络,它是语义分割算法的一个基本模型。所谓语义分割就是对图像中每一个像素点进行分类,确定每个点的类别,从而进行区域划分。
一般的CNN模型就是先用若干个卷积层和池化层组合连接在一起,然后再连接若干个全连接层,最后就是softmax层,这种CNN模型一般用于图像的分类。而FCN与这种模型的最大不同就是将全后面连接层换成了反卷积层,将经过特征提取后的逐渐变小的矩阵通过反卷积又逐渐将它放大到和输入图像同样大小的尺寸。也就是输入和输出的大小和尺寸是一样的,从而可以对输入图像的每个像素点进行分类,从而达到分割的效果。
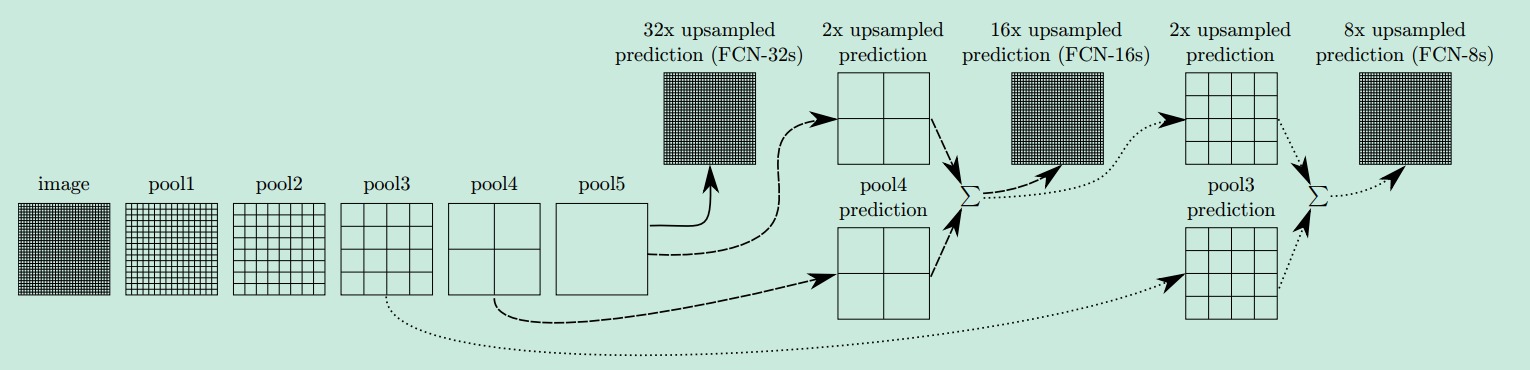
(注:卷积为kernel_size=3*3,stride=padding=1。池化为kernel_size=2*2,stride=2,padding=0。)
对于FCN-32s,直接对pool5 feature进行32倍上采样获得32x upsampled feature,再对32x upsampled feature每个点做softmax prediction获得32x upsampled feature prediction(即分割图)。
对于FCN-16s,首先对pool5 feature进行2倍上采样获得2x upsampled feature,再把pool4 feature和2x upsampled feature逐点相加,然后对相加的feature进行16倍上采样,并softmax prediction,获得16x upsampled feature prediction。
对于FCN-8s,首先进行pool4+2x upsampled feature逐点相加,然后又进行pool3+2x upsampled逐点相加,即进行更多次特征融合。具体过程与16s类似,不再赘述。
作者在原文种给出3种网络结果对比,明显可以看出效果:FCN-32s < FCN-16s < FCN-8s,即使用多层feature融合有利于提高分割准确性。
2.为什么要进行特征融合?特征融合有什么用?
低层特征分辨率更高,包含更多位置、细节信息,但是由于经过的卷积更少,它的语义性更低,噪声更多。高层特征具有更强的语义信息,但是分辨率很低,对细节的感知能力较差。
浅层网络会保留明显的内容信息,网络层越深,内容会减少,特征会增多,为了在深层网络添加内容的信息,故有此操作。将底层和高层的特征融合在一起,可以提高分割效果。
特征融合有两种做法,一种是对应位置的像素值直接相加。另一种做法是将两个特征图叠加在一起,也就是通道channel数量增加了,或者说维数增加了。
3.上采样(反卷积)
实际上,上采样(upsampling)一般包括2种方式:
Resize,如双线性插值直接缩放,类似于图像缩放
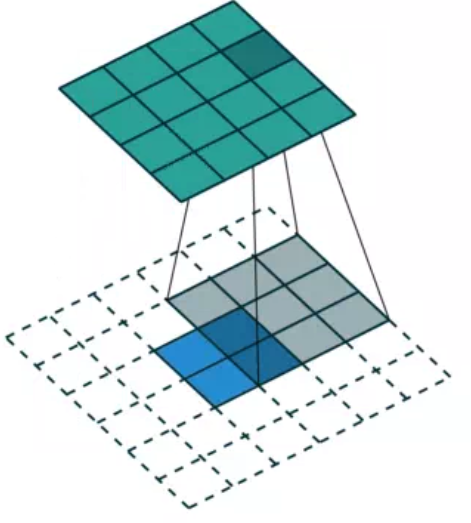
Deconvolution,也叫Transposed Convolution,反卷积:一般经过卷积层之后输出尺寸会变小(没有padding);而反卷积层的意义在于将小尺寸的高维度特征图恢复回去。卷积一般是特征图要比卷积核要大的,卷积核就一直再特征图里面从左往右从上往下地卷积。而反卷积的卷积核可以比特征图要大,与卷积不同的是,在反卷积中卷积核可以在与特征图有交集的部分开始计算,而不是在特征图完全包含卷积核的地方开始运算。比如最左上角的那个像素。
posted on 2020-07-28 22:53 ZhicongHou 阅读(481) 评论(0) 编辑 收藏 举报


