
R-CNN系列(4)—— Faster R-CNN
1.从Fast到Faster
1.1.Fast R-CNN的瓶颈
Fast R-CNN的区域提议由selective search方法提取出来。如果忽略提取区域提议在时间上的消耗,那么Fast R-CNN就能够达到实时检测的效果了。然而,基于selective search是在CPU上实现的,不能利用GPU进行加速(能利用GPU加速是因为有大量的矩阵运算,而 selective search似乎没有矩阵运算)。因此就无法忽略它在时间上的消耗,成为了Fast R-CNN的在运行速度上的瓶颈
1.2.Faster R-CNN
如果能将区域提议的提取从CPU转移到GPU上运行,那就能打破这个瓶颈了。卷积神经网络存在大量的矩阵运算,能够利用GPU进行加速,那么生成区域提议的任务能否由一个专门的卷积神经网络来承担呢?能。Faster R-CNN就是通过RPN(Region Proposal Network)来生成区域提议的。Faster R-CNN,有两处明显改动(改进)的地方:
(1)RPN代替selective search来生成区域提议;
(2)Faster R-CNN先对整张原始图像多次卷积和池化以获得特征图,再将特征图分两条路径,一条输入到RPN中用于生成区域提议,另一条输入到ROI层中(与RPN生成的区域提议进行ROI池化)。也就是说RPN提取候选框是在特征图上的,而selective search是在原始图像上的。而且,Fast RCNN的CNN特征提取部分也被提到了最前面,中间插入一个RPN用于候选框提取,之后就直接输入到ROI层了。
Faster R-CNN可以笼统地理解为:RPN + Fast R-CNN。它的结构图大致如下,注意:
(1)下图的RPN中的Backbone和Fast R-CNN的Backbone是共用的,也就是说只有一个Backbone。
(2)RPN的两个回归是没有全连接层的,直接在conv之后进行;而Fast R-CNN部分的两个回归是有全连接层的。
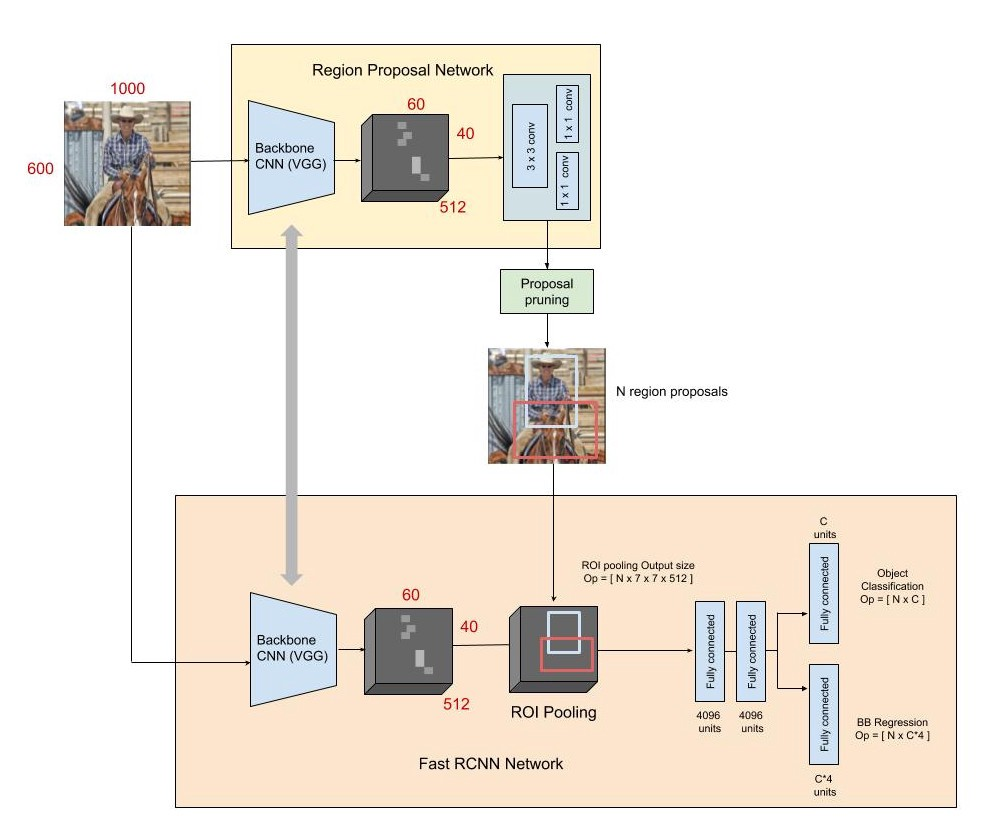
2.特征提取部分(Backbone)
因为RPN提取区域提议是在特征图上而非在原始图像上,所以就会设计到特征图与原始图像上的坐标转换。而特征图和原始图像的坐标比例如果能尽量简单而且比较好控制的话,会方便、简洁很多。特征提取部分采用VGG16,它的具体思想是:卷积层不改变尺度,池化层尺度减半。因此坐标比例就可以通过控制池化层的数量来轻松自如地调控了。卷积层的kernel_size=3,padding=1,stride=1,这样就能够控制经过卷积层之后尺度不发生变化;池化层的kernel_size=2,padding=0,stride=2,这样就能够控制经过池化层之后尺度减半。
根据Faster R-CNN的特征提取部分,特征图的尺度为原始图像尺度的1/16。

3.RPN结构
3.1.RPN外部接口
作用:用于生成区域提议
输入:原始图像的特征图
输出:一系列区域提议以及各自的score(score表示这个候选区域含有目标的可能性)
3.2.RPN内部结构
输入原始图像的特征图之后,首先进行一个进行一次卷积,估计这次卷积也设定为不改变特征图的尺度,否则就会改变了特征图与原始图像的坐标比例了。不知道这个卷积层的作用是什么?
之后,为特征图的每个点,配9个anchor(3种长度、3种比例,故共有3*3=9个)。于是整张特征图就有w*h*k个anchor(w、h分别为特征图的宽和高。注意:这里的anchor是二维的,不用考虑通道数,因为区域提议本身也不用考虑通道)。这种就划分了大概2万个anchor。
划分完anchor之后,就将特征图分两路:
(1)一路输入到kernel_size为1*1、通道数为18的卷积层中,1*1卷积的显式作用是不改变长宽只改变通道数(隐式的作用是合并通道的内容),通道数可以拆分成9*2=18,这里的9就是每个点对应的9个anchor,2就是“该区域提议存在目标的可能性”,即score(二分类的话不是1个输出就够了吗?为什么这里要两个?)
(2)一路输入kernel_size为1*1、通道数为36的卷积层中,36拆分成9*4,这里9也是每个特征图上每个点对应的9个anchor,而这里的4,则代表了对anchor精修过后得到的区域提议。
得到一系列区域提议各自的score之后,就可以根据score来对这些区域提议进行NMS了,从而筛选出优质的2千个左右的区域提议。
注意:其实划分2万个anchor的步骤是不存在的,因为这种划分在网络结构中就直接体现出来了。

4.RPN的训练与测试
4.1.损失函数
RPN的损失函数为多任务损失函数,通过lambda调节分类损失和回归损失之间的权值。

4.2.训练过程
(1)先搞出w*h*9个框,大约2万个。(注意,batch_size=1,即每次迭代只选取一张图片来训练)
(2)然后对这2万个anchor进行分类和边框回归,其中随机挑选256个正负1:1来作为损失值(而不用整体,因为整体会偏向负样本因为负样本多)。
(3)两个任务:边框回归、分类,注意这里的分类只是二分类,代表边框有无目标,所以训练只需的数据:代表边框4个数,代表有无目标1个数。无需原图像或者特征图。
(4)之后进行反向传播更新参数。
4.3.疑问
(1)如果样本是负的,怎么精修box?还要不要精修box?不用了,仔细看看损失函数,边框回归部分的损失只考虑正样本的。而分类则正负样本都考虑。
(2)anchor的正负性值的判断,是需要对应回原始图像中,然后看与Ground true box的IOU吗?
(3)关于anchor坐标/位置的问题?整理RPN的训练数据时,需要对anchor进行坐标转换,即anchor从特征图的坐标转换到原始图片上的坐标,这样才能计算出与ground true box的IoU。也因此推断,RPN输出的位置精修是基于原始图像的坐标轴,而不是特征图的坐标轴。
(4)Faster R-CNN究竟是怎么训练的?先单独训练好RPN,然后再利用RPN训练剩下的部分。
(5)
4.4.待解决疑问
(1)在RPN中,边框的位置要映射会原始图像吧?否则怎么计算与ground true box的IoU?那计算完IoU之后,边框回归输出的坐标究竟是基于原始图像的尺度,还是根据特征图的尺度?个人猜测是基于特征图的。总结:计算IoU时是使用原始图像的尺度,进行边框回归时是基于特征图的尺度。那么推测:Faster R-CNN的边框回归的坐标是基于特征图的尺度?最终输出时只需根据原始图像和特征图的大小比例将对边框从特征图映射回原始图像即可?
(2)RPN的训练阶段不需要进行NMS,而测试阶段需要NMS?好像是因为RPN的训练是单独进行的,即在训练阶段,模型的输出只是用来计算损失值并进行反向传播的。而在测试阶段,模型的输出是生成区域提议给下一部分使用的,故需要进行NMS,以此来挑选优质的区域提议。
4.5.训练集(补充)
正样本:至少满足以下两个条件的其中一个:(1)与ground true box的IoU最高的那个anchor;(2)与ground true box的IoU大于0.7的所有anchor。注意:一个ground true box可能会衍生出多个正样本的anchor。通常通过满足第(2)就能够有许多正样本了,但为了防止某个ground true box没有IoU大于0.7的anchor出现,所以还需要通过满足第一点(1),来保证有正样本的anchor。
负样本:与所有ground true box的IoU都小于0.3的anchor。
5.RPN的测试
(1)先搞出w*h*k个框,大约2万个。
(2)然后计算出这2万个边框的score和位置精修。
(3)最后通过NMS,RPN最终输出大约2000个候选框(selective也是输出2000个候选框)。
(注:测试时score是用来进行NMS的,所以RPN的最终输出只是候选框,而没有score)
posted on 2020-06-13 00:32 ZhicongHou 阅读(200) 评论(0) 编辑 收藏 举报

