Attention
Seq2Seq Model
缺陷:
由于Decoder的输入是且仅是Encoder输出在最后的\(H_m\), 因此可能会丢失部分前面的信息, 并在序列越长此问题越严重.
Attention 如何改进Seq2Seq model的遗忘问题
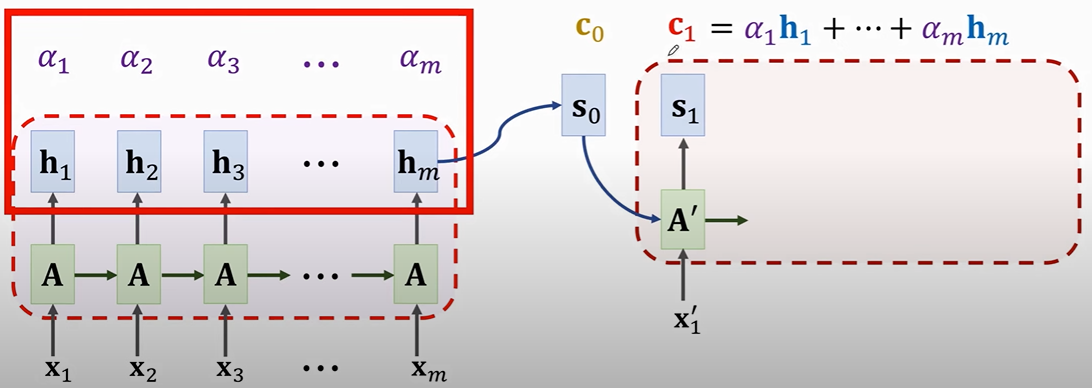
SimpleRNN + Attention:
- \(S_0\)现在不仅是最后一个\(h_m\), 而是对于每一个\(h_i\)都给予一个\(weight: \alpha_i = align(h_i, s_0)\).
- \(Context \space vector: c_0 = \sum\limits_{i=1}^{m}\alpha_i h_m\).
如何计算该weight:
-
Used in original paper:
\(\tilde{\alpha_i} = v^T \cdot tanh[w \cdot concat(h_i, s_0)]\), then normalize the weights with softmax.\(v^T, w\)为trainable parameters.
-
A more popular one, used in Transformer:
-
Linear maps:
- \(k_i = W_k \cdot h_i\), for i = 1 to m.
- \(q_0 = W_q \cdot s_0\).
-
Inner Product:
\(\tilde{\alpha_i} = k_i^T q_0\), for i = 1 to m.
-
Normalization with softmax.
-
时间复杂度: Encoder状态数 x Decoder状态数
Reference: shusen wang 老师讲解(强力推荐) https://www.youtube.com/watch?v=aButdUV0dxI&list=PLvOO0btloRntpSWSxFbwPIjIum3Ub4GSC

 浙公网安备 33010602011771号
浙公网安备 33010602011771号