深入理解nodejs的模块机制
- CommonJS规范回顾与nodejs模块机制基础内容
- 基于VS调式断点了解node模块加载编译源码流程
- 基于nodejs的VM模块手动模拟实现模块加载
- node的模块编译
- C/C++扩展模块
- 包与NPM
一、CommonJS规范回顾与nodejs模块机制基础内容
在深入了解nodejs模块机制之前首先回顾一下CommonJS规范和nodejs模块机制的基础内容,为什么叫做回顾呢?因为在两年前就以过一篇非常简单的nodejs模块相关的博客:js模块化入门与commonjs解析与应用,这篇博客简单的介绍了CommonJS的原理、应用、基于Browserify编译成浏览器能运行的JS代码。
1.1CommonJS规范出现的原因:
//javaScript的语言缺陷
没有模块系统。
标准库较少。比如ECMAScript仅定义了部分核心库,对于文件系统、I/O流等常见需求却没有标准的API。
没有标准接口。JavaScript几乎没有定义过web服务器或数据库之类的标准统一接口。
缺乏包管理工具。这导致JavaScript基本没有自动加载和安装依赖的能力。
1.2基于CommonJS规范解决了那些问题:
可以实现服务端的JavaScript应用程序。
命令行工具。
桌面图形界面应用程序。
混合应用
1.3CommonJS规范涵盖了那些内容:
模块、二进制、Buffer、字符集编码、I/O流、进程环境、文件系统、套字节、单元测试、web服务器网关接口、包管理等。
基于这些内容,再通过下面的示图来理解Node与浏览器及W3C、CommonJS组织、ECMAScript之间的关系,也可以理解为JavaScript的生态系统:

1.4Commonjs模块规范:
模块引入:require(module)
模块定义或导出:exports.attr 、module.exports = {k:y}
模块标识:必须符合小驼峰命名的字符串,或者以(.)和(..)开头的相对路径,或者绝对路径,可以没有(.js)后缀。
模块规范的具体表现特性:
任意一个文件就是一个模块,具有独立作用域
module属性:
在任意模块中可直接使用的包含模块信息
id:返回模块标识符,一般是一个绝对路径
filename:返回文件模块的绝对路径
loaded:返回布尔值,标识模块是否完成加载
parent:返回对象存放调用当前模块的模块
children:返回数组,存放当前模块调用的其他模块
exports:返回当前模块需要暴露的内容
paths:返回数组,存放不同目录下的node_modules位置
require属性:
基本功能是读取并执行一个模块文件
resolve:返回模块文件绝对路径
extensions:依据不同后缀名执行解析操作
main:返回组模块对象
exports与module.exports属性:导出模块数据
CommonJs规范定义模块的加载是同步完成
测试CommonJS规范在nodejs中的具体表现的属性:假设现在有一个依赖模块m.js和入口模块index.js:


1 //测试module 2 //m.js 3 module.exports = 111 4 console.log(module); 5 //index.js 6 require(./m.js); 7 8 //测试exports--module 9 //m.js 10 //exports = 111 //如果直接在这里使用一个原始值类型赋值给exports不会正常导出,在其他模块中导入这个模块获得的是一个空对象 11 // exports = {num:333}; //同上,直接使用一个引用值类型赋值给exports也会切断与module.exports的关联 12 exports.num = 222 //这个附加属性的方式能正常导出 13 console.log(module); 14 //index.js 15 require(./m.js) 16 17 //测试同步加载 18 //m.js 19 let iTime = new Date(); 20 console.log("--------------------"); 21 while(new Date() - iTime < 3000){} 22 console.log("...................."); 23 //index.js 24 let m = require("./m.js"); 25 console.log("index执行了"); 26 27 //测试入口文件 28 //m.js 29 console.log(require.main === module); 30 //index.js 31 require("./m.js"); 32 console.log(require.main === module);
1.5Node中的模块实现:
1.5.1在node中模块分为两类:Node提供的基础模块,也被称为核心模块、用户编写的模块,也被称为文件模块。
核心模块在node源代码编译过程中,编译进了二进制执行文件。在node进程启动时,部分核心模块就被直接加载进内存,所以这部分核心模块引入时,文件定位和编译可以省略,并且在路径分析中优先判断,所以它加载的速度是最快的。
文件模块则在运行时动态加载,需要完整的路径分析、文件定位、编译执行。
1.5.2在node中引入模块的3个步骤:路径分析、文件定位、编译执行。
在路径分析之前,其实node引入模块是优先从缓存中加载模块,当然这个缓存存在之前肯定是经历过模块加载的三个步骤。既然使用缓存就需要关注是使用缓存的副本还是直接使用缓存本身,这两者的区别核心就在于副本肯定不会产生依赖之间的项目共用和干扰问题,而不幸的是nodejs是直接使用缓存本身,也就是说在不同的模块里引入同一个模块,它们是共用这个模块的,也就是说如果有一个模块修改了这个依赖模块内的数据,就会导致其他模块依赖这个模块的数据发生变化。例如可以测试下面这个示例:
//项目根目录 index.js //入口文件 m1.js //公共被依赖模块 m2.js m3.js
代码我放到一个代码窗口了,测试的时候自行拆分:
1 //m1.js 2 module.exports = { 3 sum:0, 4 fun:function(){ 5 this.sum ++; 6 } 7 } 8 9 //m2.js 10 let m1 = require('./m1.js'); 11 console.log("m2加载:" + m1.sum); 12 m1.fun(); 13 console.log("m2执行:" + m1.sum); 14 15 //m3.js 16 let m1 = require('./m1.js'); 17 console.log("m3加载:" + m1.sum); 18 m1.fun(); 19 console.log("m3执行:" + m1.sum); 20 21 //index.js 22 let m1 = require("./m1.js"); 23 let m2 = require('./m2.js'); 24 let m3 = require('./m3.js'); 25 console.log("入口文件加载:" + m1.sum); 26 m1.fun(); 27 console.log("入口文件执行:" + m1.sum);
测试打印结果:
m2加载:0 m2执行:1 m3加载:1 m3执行:2 入口文件加载:2 入口文件执行:3
这种共用一个依赖可能在你依赖设置不严谨的情况下,就会导致出现数据冲突的问题。既然存在问题就必然有它的原因,这种使用同一个脚本缓存可以非常有效的提高性能。而且需要注意,node在加载模块时会初识化执行一次该模块,但如果引入的模块已经存在缓存中就不会再触发编译执行,而是直接使用之前的编译执行结果。
不论是核心模块还是文件模块,都采用的是优先使用缓存,唯一不同的是如果出现文件模块和核心模块重名会优先使用核心模块的缓存,这跟路径分析的优先级一致。
路径分析与文件定位:
文件标识符在node中分为四大类: 1.核心模块,如http、fs、path等 2.以.或..开始的相对路径文件模块 3.以/开始的绝对路径文件模块 4.非路径形式的文件模块
在对node的require路径分析进行解析之前,构建一个简单的测试代码:
1 //根目录 2 node_modules //文件夹:手动创建一个当前项目下的模块包文件夹 3 --fs //文件夹:自定义模块fs 4 ----index.js //自定义模块fs的入口文件 5 --aaa //文件夹:自定义模块aaa 6 ----index.js //自定义模块aaa的入口文件 7 --index.js //测试项目的入口文件 8 --fs.js //根目录下测试一个fs模块重名的自定义文件模块 9 10 //测试代码 11 //node_modules/fs/index.js 12 module.exports={ 13 fun:function(){console.log("--fs")} 14 } 15 //node_modules/aaa/index.js 16 module.exports={ 17 fun:function(){console.log("--aaa")} 18 } 19 //fs.js 20 module.exports={ 21 fun:function(){console.log("fun")} 22 } 23 //index.js 24 let fs1 = require('fs'); 25 let fs2 = require('fs.js'); //这个导入就会失败,报fs.js不是一个模块(执行失败以后注释这行代码再测试) 26 let fs3 = require('./fs.js'); //这个能导出根目录下的文件模块 27 let aaa = require('aaa'); 28 console.log(fs1.constants.S_IFREG); 29 fs2.fun(); //注意这行代码不会执行 30 fs3.fun(); 31 aaa.fun();
将25、29行代码注释后测试的结果:
32768
fun
--aaa
通过上面的测试结果可以得出:
按照模块标识符会将模块分为两大类:路径模块、非路径模块
路径模块:会通过路径直接导入模块
非路径模块:优先导入核心模块、然后匹配node_module中的包名导入其入口文件
node模块路径分析是不允许出现这两类情况之外的其他形式的,这也是require('fs.js')会报错的原因。
最后关于路径分析就是要注意非路径模块的逐层优先级问题,这时候你可以再刚刚的测试入口文件index.js中写入下面这行代码:
console.log(process.argv);
console.log(module.paths);
然后测试module.paths会打印出一系列的node_modules模块包文件夹路径的数组,在导入非路径模块时node会优先从node程序目录中的node_modules中去匹配核心模块,如果没有匹配到核心模块就会从module.paths的node_modules中去逐个匹配,直到匹配到为止,如果没有匹配到就会报改模块不存在。
扩展名分析:
无论是路径模块还是非路径模块,最后文件导入还有一个非常关键的环节,这个环节的工作就是分析路径模块或非路径模块的入口文件的扩展名,因为node模块包含三种文件类型:.js、.json、.node。
现在假设在根目录入口文件index.js中导入模块的代码如下所示:
console.log("./aaa")
按照上面的测试代码,node模块导入根据路径分析到了根目录下,它会一次在“./aaa”后面添加.js、.json、.node后缀去匹配模块。如果匹配到aaa.js就导入这个模块,后面的json和node后缀就不会再匹配,以此类推。
同样在非路径模块中如果没有配置文件package.json或package.json中配置的main指向的路径也没有后缀,也会按照.js、.json、.node优先顺序去匹配模块。
//模块加载流程 路径分析:确定目标模块位置 文件定位:确定目标模块中的具体文件 编译执行:对模块内容进行编译,返回可用exports对象
二、基于VS调式断点了解node模块加载编译源码流程
2.1基于VS Code调试断点分析node模块加载流程:
windows下快捷键:ctrl + shift + d
先准备两个最简单的模块:m.js、index.js
//m.js exports.name = "m"; //index.js let m = require("./m"); console.log(m.name);
然后快捷键:“ctrl + shift + d”自定义创建launch.json调试文件,选中node环境:

因为要查看node的源码,所以launch.json调试文件需要做一些修改:
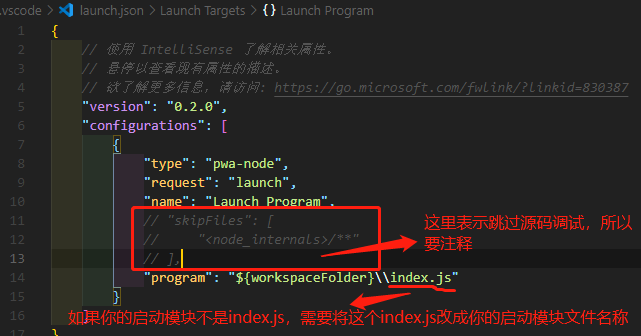
在“let m = require("./m");”这行代码前打上断点,使用F5启动调试:
具体的源码阅读这里就不做具体的介绍了,后面会对模块编译做归纳性解析,结合前面的模块加载流程对照源码调试执行理解就好。
三、基于nodejs的VM模块手动模拟实现模块加载
VM模块是Nodejs中的核心模块,支持require方法和Nodejs的运行机制。通过VM,JS可以被编译后立即执行或者编译保存下来稍后执行。
VM模块包含三个用常用的方法,用于创建独立的沙箱机制:
vm.runInThisContext(code, filename);
vm.createContext()
vm.runInNewContext(code, sandbox, opt)
了解一些详细内容可以参考这篇博客:https://www.jb51.net/article/65554.htm
基于VM模拟实现require()方法实现模块加载:
1 const fs = require('fs'); 2 const path = require('path'); 3 const vm = require('vm'); 4 5 function Module(id){ 6 this.id = id; 7 this.exports = {}; //最终被导出的对象 8 } 9 Module._resolveFilename = function(filename){ 10 //使用path将filename转换成绝对路径 11 let absPath = path.resolve(__dirname, filename); 12 //判断当前路径对应的内容是否存在 13 if(fs.existsSync(absPath)){ 14 //如果条件成立说明absPath对应的内容是存在的 15 return absPath; 16 }else { 17 //文件定位 18 let suffix = Object.keys(Module._extensions); 19 for(let i = 0; i < suffix.length; i++){ 20 let newPath = absPath + suffix[i]; 21 if(fs.existsSync(newPath)){ 22 return newPath; 23 } 24 } 25 } 26 throw new Error(`${filename} is not exists`); 27 }; 28 Module._extensions = { 29 '.js'(module){ 30 //读取模块文件内容 31 let content = fs.readFileSync(module.id,'utf-8'); 32 //包装 33 content = Module.wrapper[0] + content + Module.wrapper[1]; 34 //VM 35 let compileFn = vm.runInThisContext(content); 36 //准备参数值 37 let exports = module.exports; 38 let dirname = path.dirname(module.id); 39 let filename = module.id; 40 //调用执行 41 compileFn.call(exports, exports, myRequire, module, filename, dirname); 42 }, 43 '.json'(module){ 44 let content = JSON.parse(fs.readFileSync(module.id, 'utf-8')); 45 module.exports = content; 46 } 47 }; 48 Module.wrapper = [ 49 "(function(exports, require, module, __filename, __dirname){\n", 50 "\n})" 51 ]; 52 Module._cache = {}; //缓存 53 //加载 54 Module.prototype.load = function(){ 55 let extname = path.extname(this.id); 56 Module._extensions[extname](this); 57 }; 58 59 function myRequire(filename){ 60 //1 获取文件模块的绝对路径 61 let mPath = Module._resolveFilename(filename); 62 //2 缓存优先 63 let cacheModule = Module._cache[mPath]; 64 if(cacheModule) return cacheModule.exports; 65 //3 创建空对象加载目标模块 66 let module = new Module(mPath); 67 //4 缓存已加载过的模块 68 Module._cache[mPath] = module; 69 //5 执行加载(编译执行) 70 module.load(); 71 //6 返回数据 72 return module.exports; 73 } 74 75 let obj = myRequire('./test'); 76 let name = myRequire('./test.json'); 77 console.log(obj); 78 console.log(name);
测试代码test.js和test.json:
1 //test.js 2 const str = "基于vm手动实现模块加载"; 3 module.exports = str; 4 //test.json 5 { 6 "ame":"他乡踏雪" 7 }
四、node的模块编译
编译和执行是引入文件模块的最后阶段,定位到具体文件后,Node会新建一个模块对象,然后根据路径载入并编译。对于不同文件扩展名,其载入方法也有所不同:
.js文件:通过fs模块同步读取文件后编译执行。
.json文件:通过fs模块同步读取文件后,用JSON.parse()解析返回结果。
.node文件:这是用C/C++编写的扩展文件,通过dlopen()方法加载最后编译生成的文件。
其他扩展名文件会被当作.js文件载入。
4.1关于JavaScript模块的编译:
本质上就是在模块的内容上使用一个立即执行函数包装起来(参考第三节中的第33行示例代码),然后将这个包装后的字符串丢该VM上的runInThisContext编译成一个Function对象,然后将实例化模块时创建的Module对象等作为参数传入这个函数执行(参考第三节中的第35、41行代码),这个函数的执行就会将模块内module.exports导出的内容添加到Module实例上,然后require返回module.exports,这个过程就实现了模块的导入操作。
4.2关于JSON模块的编译:
这个类模块的编译就非常简单,是读取JSON字符串内容后直接交给JavaScript的JSON.parse()其转换后直接交给module.exports,然后由require返回。
4.3关于C/C++模块的编译:
由于在Node中使用C/C++是编译后的.node二进制文件,所以它并不需要编译,而是通过Module._extensions上的.node方法(参考第三节中的第28行示例代码)直接交给process.dlopen()方法进行加载和执行。dlopen()方法在windows和*nix平台下分别有不同的实现,其底层模块依赖于libuv兼容层进行封装。
同样,process.dlopen()加载执行过程中,模块的exports对象与.node模块产生联系,然后返回给调用者。
每个模块编译成功后的模块对象都会将其文件路劲作为索引缓存在Module._cache对象上,以提高二次引入的性能,所以在二次引入时导入模块不会在进行编译执行,而是直接将之前的编译执行结果通过require返回。
4.4核心模块的编译:
在nodejs入门的第一节课中的架构模式中就提到过,Node的核心模块由C/C++和JavaScript两部分编写,C/C++文件存放在Node项目的src目录下,JavaScript文件存放在lib目录下,核心模块在编译过程中被编译进了二进制文件。
4.4.1JavaScript核心模块的编译过程:
Node采用V8附带的js2c.py工具,将所有內置的JavaScript代码(src/node.js和lib/*.js)转换成C++里的数组,生成node_natives.h头文件。这个过程中,JavaScript代码以字符串的形式存储在node命名空间中,是不可直接执行的。
在node进程启动时,JavaScript代码直接加载进内存中。加载过程中,JavaScript核心模块经历了标识符分析后直接定位到内存中,所以比普通文件模块从磁盘中一处一处查找要块很多。
JavaScript模块在编译时同样要经历通过立即执行函数包装的过程,但它们是通过process.binding('natives')取出,编译成功后的模块存到NativeModule._cache对象上,而不是文件模块那样存到Module._cache对象上。它们与文件模块的区别就是:获取源码的方式不一样(核心模块从内存中加载,文件模块从磁盘的文件中读取),以及它们缓存执行结果的位置不同。
4.4.2C/C++核心模块的编译过程:
在Node中C/C++核心模块也被称为内建模块,其内部结构定义如下:
struct node_module_struct { int version; vid *dso_handle; const char *filename; void (*register_func) (v8:Handle<v8::Object> target); const char *modname; };
每个内建模块在定义之后,都通过NODE_MODULE宏将其模块定义到node命名空间中,模块的具体初识化方法挂载结构的register_func成员:
#define NODE_MODULE(modname, regfunc) extern "C" { NODE_MODULE_EXPORT node::node_module_struct modname ##_module = { NODE_STANDARD_MODULE_STUFF, regfunc, NODE_STRINGIFY(modname) }; }
node_extensions.h文件将这些散列的内建模块统一放进node_module_list的数组中,这些模块有:
node_buffer
node_crypto
node_evals
node_fs
node_http_parser
node_os
node_zlib
node_timer_wrap
node_tcp_wrap
node_udp_wrap
node_pipe_wrap
node_cares_wrap
node_tty_wrap
node_process_wrap
node_fs_event_wrap
node_signal_watcher
在Node中提供了get_builtin_module()方法从node_modeule_list数组中取出这些模块,内建模块的优势在于性能优于脚本语言,在进行文件编译时,它们被编译进二进制文件。一旦Node开始执行,它们被直接加载进内存中,无需在做标识符定位、文件定位、编译等过程,直接就可执行。
Node在启动时,会生成一个全局变量process,并提供Binding()方法来协助加载内建模块,Binding()的实现代码在src/node.cc。在加载内建模块时,先创建一个exports空对象,然后调用get_builtin_module()方法取出内建模块对象,通过register_func()填充exports对象,最后将exports对象按模块名缓存,并返回给调用方完成导出。
process.binding()除了能导出内建模块,前面的JavaScript核心模块被转换成C/C++数组存储后,便通过process.binding('natives')取出放置在NativeModule._source中的:
NativeModule._source = process.binding('natives');
该方法将通过js2c.py工具转换出的字符串数组取出,然后重新转换成普通字符串,以对JavaScript核心模块进行编译和执行。
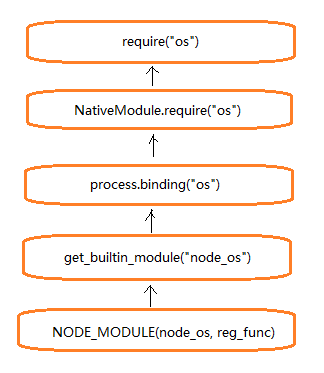
核心模块的引入流程:
五、C/C++扩展模块
5.1测试编译了《Nodejs深入浅出》和node官方文档中的示例及node-gyp在github上的示例代码都未成功,都是报各种语法问题,由于对C++语法不了解,这一节内容暂时不写了,后面学一下C++再来补充吧。
测试代码还是贴出来:
//hello.cc #include <node.h> #include <v8.h> using namespace v8; Handle<Value> SayHello(const Arguments& args){ HandleScope scope; return scope.Close(String::New("Hello world")); } void Init_Hello(Handle<Object> target){ target->Set(String::NewSymbol("sayHello"), FunctionTemplate::New(SayHello)->GetFunction()); } NODE_MODULE(hello, Init_Hello);
测试项目结构:
//根目录 --src ----hello.cc --binding.gyp
binding.gyp的内容:
{ 'targets':[ { 'target_name':'hello', 'sources':[ 'src/hello.cc' ], 'conditions': [ ['OS=="win"', { 'libraries': ['-lnode.lib'] }] ] } ] }
测试环境:
os:windows10
node -v:16.14.0
node-gyp -v:9.0.0
编译工具:
Python 3.7.2
Visual Studio Community 2019(C++桌面开发)
编译流程:
//根目录下 node-gyp configure //没有报错没有警告 node-gyp build //报错: warning C4312: “类型强制转换”: 从“int”转换到更大的“node::addon_register_func”
有知道问题出在哪里或者知道怎么解决的兄弟请留言,感激不尽!
最后贴一篇大佬的踩坑博客,里面提供了几种不错的思路值得借鉴:Nodejs插件引入第三方动/静态链接库(Libtorch)的踩坑记录。关于node的C++扩展需要具备较强的C++能力和编译功力,学习成本还是挺高的,但世界使用.node模块还是比较简单,他与使用其他模块表面上看起来没有什么区别。
5.2C/C++扩展模块的加载:
nodejs通过require导入.node文件实际上经历了四个过程:
1.基于requier()分析定位文件,并创建空模块对象 2.通过process.dlopen('xxx.node', exports) 3.调用uv_dlopen()方法打开动态链接库 4.调用uv_dlsym()方法找到动态链接库中通过NODE_MODULE宏定义的方法地址 //上面两个方法都是由node底层模块libuv库封装的,在*nix平台下实际调用的时dlfcn.h头文件中定义的dlopen()和dlsym();在windows平台则是通过LoadLibraryExW()和GetProcAddress()两个方法实现的,它们分别加载.so和.dll文件(实际为.node文件)。
注意第二步相当于前面加载js模块的vm那个环节,同样用第三节中的模块代码来说在示例代码的28~47的_extensions上还有一个“.node(module){}”,第二步差不多就是在这个方法的逻辑下调用的。
C++扩展模块与JavaScript模块的区别在于加载之后不用编译,直接执行之后就可以被外界调用,其加载速度比JavaScript略快。
六、包与NPM
Node组织了自身的核心模块,也使得第三方文件模块可以有序的编写和使用。但是在第三方模块中,模块与模块之间仍然是散列在各个地方,相互之间不能直接引用。在模块之外,包和NPM则是将模块联系起来的一种机制。
6.1包与node模块规范的关系:
包是组织模块实现一项或多项功能的模块集合,它由包结构和包描述文件组成。

包的描述文件就是常见的package.json文件(后面详细分析),下面来看看完全符合Commonjs规范的包目录应该包含那些文件及文件夹:
package.json:包的描述文件。
bin:用于存放可执行二进制文件的目录。
lib:用于存放JavaScript代码的目录。
doc:用于存放文档的目录。
test:用于存放单元测试用例的代码。
6.2包描述文件package.json与NPM:
包描述文件用于表达非代码相关信息,它是JSON格式的文件,位于包的根目录下。
NPM所有行为都与包描述文件的字段息息相关,由于Commonjs还处于草案阶段,NPM在实践中做了一定的取舍。下面先来看看Commonjs规范为package.json文件定义的必需的字段:
name:包名 description:包简介 version:版本号 keywords:关键词数组,NPM中主要用来做分类搜索(一个好的关键词数组有利于用户快速找到你编写的包) maintainers:包维护者列表,每个维护者由name、email、web三个属性组成([{"name":"xxx","email":"xxx@xx.xx","web":"http://xxx.com"}]) contributors:包贡献者(格式与maintainers相同) bugs:一个可以反馈bug的网页地址或邮件地址 licenses:当前包使用的许可证列表,表示这个包可以在哪些许可证下使用 repositories:托管代码的位置列表,表示通过哪些方式和地址访问包的源代码 dependencies:使用当前包所需要依赖的包列表,NPM会通过这个属性帮助自动加载依赖的包 homepage:当前包的网站地址 os:操作系统支持列表,如果为空则不对操作系统做任何假设 cpu:CPU架构的支持列表,如果为空则不对CPU做任何假设 engine:支持JavaScript引擎列表 builtin:标志当前包是否是内建在底层系统的标准组件 directories:包目录说明 implements:实现规范的列表 scripts:脚本说明对象,它主要被包管理器用来安装、编译、测试和卸载包。例如 "script":{ "install":"install.js", "build":"build.js", "doc":"make-doc.js", "test":"test.js" }
在NPM的package.json实际实现中,比Commonjs的包规范多了四个字段:
author:包作者 bin:一些包作者希望包可以作为命令行工具使用,配置好bin字段后,通过npm install package_name -g命令可以将脚本添加到执行路径中,之后可以在命令行中直接执行 main:模块引入方法require()在引入包时,会优先检查这个字段,并将其作为包中其余模块的入口,如果不存在这个字段,require()方法会查找包目录下的index.js、index.node、index.json文件作为默认入口。 devDependencies:一些模块只在开发时需要依赖,配置这个属性,可以提示包的后续开发者安装依赖包。
6.3NPM常用功能:
6.3.1查看帮助:
npm -v //查看NPM当前版本 npm //直接执行npm查看帮助引导说明
6.3.2安装依赖包:
全局安装:
npm install <package-name> -g
全局模式并不是一个模块包安装为一个全局包的意思,它并不意味着可以从任何地方通过require()来引用它。实际上,-g命令是将一个包安装为全局可用的可执行命令。它根据包描述文件中的bin字段配置到与Node可执行文件相同的路径下。但事实上,通过全局模式安装的所有模块都被安装进了一个统一的目录。
从本地安装:
npm install <tarball file> //tarball file(压缩文件)也就是可以是一个压缩文件的路径 npm install <tarball url> //tarball url(压缩文件链接)也就是可以是一个压缩文件的链接 npm install <folder> //folder(文件夹)也就是可以直接是一个包的根目录
从非官方源安装:
//例如安装cnpm镜像源 npm install -g cnpm --registry=https://registry.npm.taobao.org
详细可以参考: js模块化入门与commonjs解析与应用 中的第二节内容。
6.4NPM钩子命令:
包描述文件package.jsons中的scripts字段提出就是让包在安装或卸载等过程中提供钩子机制,示例:
"scripts":{ "preinstall":"preinstall.js", "install":"install.js", "uninstall":"uninstall.js", "test":"test.js" }
在以上字段中执行npm install <package>时,preinstall指向的脚本将会被加载执行,然后install指向的脚本会被执行。在执行npm uninstall <package>时,uninstall指向的脚本也许会做一些清理工作。执行npm test时,将会运行test指向的脚本,方便用户测试用例。
详细可以可以参考node官方文档:http://nodejs.cn/learn/the-package-json-guide
6.5发布包:
假设你现在有一个包,并编写好包描述文件package.json,在包根目录下执行以下命令:
npm publish .
前提是你需要注册或登入账户,如果没有站好使用 npm adduser 注册账号,如果注册出错也可以直接到NPM官方网站注册,如果有账号就通过 npm login 登入账户。详细可以参考这篇博客:https://www.cnblogs.com/sizhou/p/7992742.html
基于CNPM搭建私有NPM仓库可以参考这篇博客:https://mp.weixin.qq.com/s/9BLUE6M8MSNCC6ctij8RxQ

 浙公网安备 33010602011771号
浙公网安备 33010602011771号