数据库入门(mySQL):数据操作与查询
- 增删改
- 单表查询
- 多表查询
一、增删改
1.插入数据记录(增)
insert into table_name(field1,field2,field3,...fieldn)
valuses(value1,value2,value3,...valusen);
示例(依照上一篇博客的数据库示例的users表):
#查看表信息 describe users; #给users增加一条数据 insert into users(name,age,phone,password) values ("张三",22,"12345678901","abcdefg"); #查询校验 select * from users;
插入数据时,可以根据需求插入部分数据,但是非空数据必须添加,自动递增数据不需要添加。插入完整数据可以不写字段名称,但需要注意的是即便是自增字段也需要添加数据才能算是完整的数据,所以不写字段名称的insert into语句不添加自增字段的数据也会报错,不能添加成功。
除了插入单条数据,indert into支持一次添加多条数据:
insert into users(name,age,phone,password) values ("王五",23,"12345678903","abcdefg"), ("程程",24,"12345678904","abcdefg"); //插入多条数据同样可以插入部分数据和插入完整数据时可以不写字段名,规则与插入单条数据一样
插入数据库中的数据还可以是从数据库中查询的数据:
insert into table_name1(field11,field12,field13,...field1n) select (fileld21,field22,field23,...field2n) from table_name2 where ... //从数据表table_name2中查询插入到数据表table_name1中。
2.更新数据记录(改)
update table_name set field1=value1, field2=value2 where condition; //condition指定满足条件的数据记录
示例:
update users set password="gfedcba" where phone="12345678904";
更新数据根据条件修改符合条件的所有数据,如果condition符合多条数据,对应的多条数据都会被修改,如果不写where条件的话所有数据记录都会被修改。
3.删除数据记录(删)
delete from table_name where condition; //condition表示要删除的数据记录的条件,符合条件的所有数据记录都会被删除
示例:
delete from users where id=4;
如果要删除所有数据记录可以设置where条件符合所有条件,也可以不写where。(慎重操作)
二、单表查询
//查询所有字段、所有数据记录 select * from table_name //查询所有数据记录的指定字段 select field1,field2,...fieldn from table_name //查询符合条件的数据记录的所有字段(condition表示查询数据记录的条件) select * from table_name where condition //查询符合条件的数据记录的指定字段 select field1,field2,...fieldn from table_name condition
SQL关键字distinct避免查询重复数据:
//通过distinct去掉重复数据是匹配所有查询字段是否同时重复,类是查询内容即为查询条件 select distinct field1,field2,...fieldn table_name;
MySQL实现了数学四则运算数据查询,就是数值类型的数据可以实现加减乘除和取余操作(+ - * / %)。
//比如通过月薪查询某个员工的年薪(月薪字段:sal) select name, sal*12 from employee;
SQL关键字as实现查询字段重命名,比如上面查询年薪的语句最后还是sql作为查询年薪结果的字段名,显然不是很合适了,这时候就可以通过as关键字来重命名字段:
select name, sal*12 as yearsalary from employee;
2.1 条件数据记录查询
关系运算符(比较运算)和逻辑运算符的条件查询。
比较运算符【大于:>,小于:<,等于:=,不等于:!=(<>),大于等于:=>,小于等于:<=】。
逻辑运算符【逻辑与:AND(&&),逻辑或:OR(||),逻辑异或:XOR,逻辑非:NOT(!)】。
//查询月薪小于3500的员工 select name,sal from employee where sal<3500; //查询月薪3500到5000的员工 select name,sal from employee where sal=>3500 && sal<=5000; select name,sal from employee where sal=>3500 and sal<=5000;
MySQL提供关键字between and实现范围查询,类似(field>=n and field<=m),比如上面示例中的查询月薪3500到5000的员工数据就可以使用between and关键字来实现:
select * from employee where sal between 2000 and 5000;
MySQL提供关键字is null实现空值查询。
//查询电话为空的用户信息 select * from users where phone is null;
MySQL提供关键is not null实现非空值查询。
//查询领取奖金的雇员 select * from employee where comm is not null;
MySQL提供关键字in实现指定字段符合集合中的值条件查询。
//例如查询雇员名字为“张三”和“李四”的信息 select * from employee where name in("张三","李四"); //通过或运算符(||)或者or命令实现 select * from employee where name="张三" or name="李四"; select * from employee where name="张三" || name="李四";
MySQL提供关键字not in实现指定字段不符合集合中的值条件查询。
//例如查询雇员名字不是“张三”和“李四”的信息 select * from employee where name not in("张三","李四"); //通过不等于加上逻辑与运算符(and)实现 select * from employee where name!="张三" && name!="李四"; select * from employee where name!="张三" and name!="李四";
使用in和not in关键字查询需要注意的一点集合值null不会被匹配,用前面两个示例来说:
//下面这两个查询语句查询的结果一致 select * from employee where name in("张三","李四"); select * from employee where name in("张三","李四",null); //但是如果使用null作为非集合数据查询,则不会查询到任何数据 select * from employee where name not in("张三","李四",null);//查询结果为空 select * from employee where name not in(null);//查询结果为空
MySQL提供关键字like实现模糊查询。like实现的是匹配字符串,支持下划线“_”和百分号“%”两个通配符,下划线“_”用来匹配单个字符,百分号“%”用来匹配任意长度字符串。
//查询以“A”开头的employee数据表中ename字段的数据记录 select * from employee where ename like "A%" //查询以“A”开头且只有两个字符的employee数据表中ename字段的数据记录 select * from employee where ename like "A_"
like关键字可以与not或者(!)实现匹配字符串的逻辑非运算,例如:
//查询除第二个字符为“A”的employee数据表字段ename的数据记录 select * from employee where ename not like "_A%";
like关键字除了可以匹配字符串,数值字符串也同样可以匹配,例如:
//匹配不含有数字5的薪资雇员信息 select * from employee where sal not like "%5%"; //如果使用“%%”作为匹配条件会将所有数据记录查询出来
2.2 排序数据记录查询:(ORDER BY fileld [ASC|DESC])
select field1,field2,...fieldn from table_name where condition order by fileldm1 [ASC|DESC] [,fileldm2 [ASC|DESC]] //fileldm表示按照该字段排序 //ASC表示升序排序 //DESC表示降序排序 //并且可以按照单字段排序或者多字段排序
单字段升序排序示例:
//按照月薪升序排序,月薪字段sal不能为空(因为默认升序排序,所以最后的asc关键字可写不写) select name,sal from employee where sal is not null order by sal;
多字段升降混合排序排序:
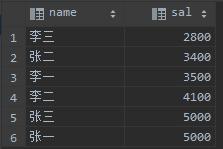
//先根据月薪升序排序,然后再根据名字降序排序 select name,sal from employee order by sal asc,name desc;
排序实际上是根据数据表的字符集的字符进行排列,所以上面示例的查询结果是这样:
2.3 限制数据记录查询数量:(LIMIT offset_start,row_count)
关键字limit实现查询记录数量和起始位置的限制,限制数据记录查询数量包含两个方面:指定查询数据记录的总量、指定查询数据记录的起始位置(通常被称为起始位置偏移)。
select field1,field2,...fieldn from table_name where condition limit offset_start,row_count //offset_start表示记录的起始偏移量 //row_count查询的总记录数 //只写一个限制数值时默认为查询的总记录数 select * from employee limit 3;//表示只查询前三条数据 select * from employee limit 2,3;//表示从第二条数据后面(第三条数据开始)查询三条数据
2.4 统计函数与分组数据记录查询
统计函数:COUNT()-统计记录条数、AVG()-计算字段值的平均值、SUM()-计算字段值的总和、MAX()-查询字段值的最大值、MIN()-查询字段值的最小值。语法:
select function(field) from table_name where condition
以统计员工薪资sal字段为例:
#统计记录条数 select count(name) from employee ; select count("sal") from employee ;#这样的查询也会有结果,但是不会忽略null值 select count(sal) from employee ;#sal字段值为null时不会被统计 #统计计算平均值 select avg(sal) from employee; #统计计算求和 select sum(sal) from employee; #统计最大值和最小值(统计时会忽略null值记录) select max(sal),min(sal) from employee;
分组数据记录查询:(GROUP BY field-根据字段field的值分组查询)。语法:
select * from table_name where condition group by field;
根据班级编号分组查询学生信息示例:
select * from students group by class_id;
查询结果:

从查询结果可以看到两个班级编号分别为1901、1902,学生名字字段student_name只出现一条数据,这显然不合理,往往我们需要将所有学员信息查询出来,这时候可以采用统计分组查询,关键字GROUP_CONCAT(field)。例如按照班级分组统计查询学员名字:
select class_id,group_concat(student_name) from students group by class_id;
查询结果:

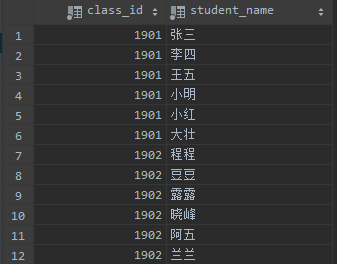
然而这种情况可能还不能满足业务需求,我们的业务可能需要每个学员信息作为一条数据记录查询出来,只是希望分组可以将班级一致的学员记录连续的查询出来,这时候就可以采用多字段分组,比如:
select class_id,student_name from students group by class_id,student_name;
查询结果:

这种多字段分组查询出来的结果非常类似排序查询,所以用排序可以获得类似的查询结果:
select class_id,student_name from students order by class_id;
查询结果:
但多字段分组一般不用来做这样排序的查询,而是分组统计查询的应用比较多,更具业务需要灵活应用吧。
三、多表查询
3.1关系数据操作
在连接查询中,需要对两张或两张以上的数据表进行连接操作,这种连接操作专门用于数据库操作的关系运算。传统的也是常用的运算包括并、笛卡尔积、连接。
3.1.1并(UNION):把具有相同字段数和字段类型的表合并到一起。比如有A、B两张数据表,它们的字段都是name、sex,这两个数据表并操作后数据记录合并到一张表(查询结果)。

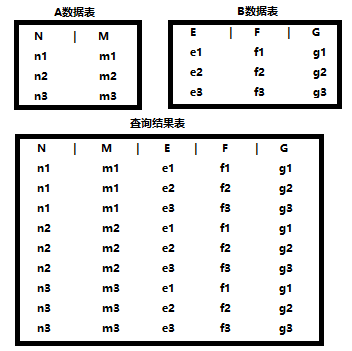
3.1.2笛卡尔积(CARTESIAN PRODUCT):笛卡尔积就是没有连接条件表关系返回的结果。它会将两个或多个表每条记录一一拼接合成查询记录,通常也被称为交叉连接。比如有A、B两张数据表,它们的字段分别为(N、M)和(E、F、G),如果A表中有3条记录、B表中也有3条记录,这时候它们就会查询合成一张5个字段(N、M、E、F、G)9条记录的数据表。
3.1.3连接查询:连接查询包括内连接查询和外连接查询,都是基于两表关联的字段进行查询。连接查询也就是说表与表之间存在至少一个相同的字段,然后通过这个相同的字段来匹配筛选查询。
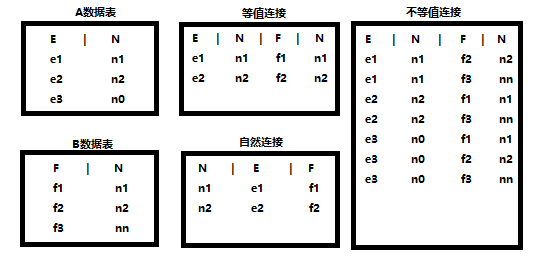
内连接查询又包括等值连接查询、不等值连接查询、自然连接查询(inner join ...on)。
等值连接查询就是从笛卡尔积中筛选出关联字段值相等的记录。如果关联字段中有值只出现在一个表中会被过滤出去,只保留值与值相等的记录。
不等值连接查询就是从笛卡尔积中筛选出关联字段值不相等的记录。如果关联字段中有值只出现在一个表中,该字段笛卡尔产生的所有记录都是不等值记录。
自然连接就是在等值连接的基础上,只保留一个关联字段,因为这时候关联字段的值是相同的。
外连接查询包括左外连接、右外连接、全外连接(outer join ...on)。在内连接查询中会将只出现在一张表中的关系字段值的记录过滤出去,但在实际业务中肯定会有需要保留这些数据记录的查询需求,外连接查询就可以在连接查询时保留只出现在一张表中的关系字段值的记录,并且可以指定JOIN关键字左右或者全部表的这类数据记录。

3.2关系数据操作的SQL语法与示例实现:
3.2.1合并查询数据记录(并):
//语法 SELECT field1 field2 ...fieldn FROM tablename1 UNION | UNION ALL SELECT field1 field2 ...fieldn FROM tablename2 UNION | UNION ALL SELECT field1 field2 ...fieldn FROM tablename3 ... //示例实现 select name,sex from a_table union select * from b_table;
3.2.2交叉连接查询
//语法 SELECT field1 field2 ...fieldn from join_tablename1 CROSS JOIN join_tablename2 //示例 select * from a_table cross join b_table;
3.2.3内连接查询
//语法 SELECT field1 field2 ...fieldn FROM join_tablename1 INNER JOIN join_tablename2 [INNER JOIN join_tablenamen] ON join_condition //示例:等值连接查询 select * from a_table inner join b_table on a_table.n = b_table.n; //示例:不等值连接查询 select * from a_table inner join b_table on a_table.n != b_table.n; //示例:自然连接查询 select * from a_table natural join b_table; //与等值连接查询结果一致(内部实现也一样,都是先通过笛卡尔积合并在筛选数据) select * from a_table,b_table where a_table.n=b_table.n;
3.2.4外连接查询
//语法 SELECT field1 field2 ...fieldn FROM join_tablename1 LEFT|RIGHT|FULL [OUTER] JOIN join_tablename2 ON join_condition //示例:左外连接查询 select * from a_table left join b_table on a_table.n = b_table.n; //示例:右外连接查询 select * from a_table right join b_table on a_table.n = b_table.n; //示例:全外连接查询(MySQL不支持) select * from a_table full join b_table on a_table.n = b_table.n;
3.3子查询
关于为什么使用子查询,这个问题来自看是可以解决一切查询的连接查询,因为连接查询回对连接的表进行笛卡尔积操作,因为笛卡尔积可以产生所有可能需要的数据记录,然后再在这个完整的表中筛选需要的数据记录。但是这种操作会有一个致命的缺陷,就是笛卡尔积产生的数据记录可能超出服务承载的范围,造成死机。针对这种情况连接查询一般都需要先进行统计查询获取笛卡尔积的记录数,然后依照这个记录数判断是否超出服务承载范围,如果没有超出再实现连接查询。但是,这只能起到保证服务不死机,并不能实际解决数据记录很大的查询需求,这时候就产生了子查询。
子查询就是指在一个查询中嵌套了其他若干个查询,即在where或from子句中包含另一个select查询语句。外层查询为主查询语句,where子句中的select查询语句被称为子查询,因此也被称为嵌套查询。
下面关于子查询的解析和示例都是用员工表(t_employee)和部门表(t_dept)作为数据基础,这是表的创建语句和添加的数据:


1 create table t_dept( 2 `deptno` int(11), 3 `dname` varchar(32), 4 `loc` varchar(32) 5 )engine=innoDB default charset=utf8mb4; 6 select * from t_dept; 7 insert into t_dept(deptno, dname, loc) values 8 (10,"ACCOUNTING","NEW YORK"), 9 (20,"RESEARCH","DALLAS"), 10 (30,"SALES","CHICAGO"), 11 (40,"OPERATIONS","BOSTON"); 12 13 create table t_employee( 14 `empno` int(11), 15 `ename` varchar(32), 16 `job` varchar(32), 17 `MGR` int(11), 18 `Hiredate` date, 19 `sal` float, 20 `comm` float, 21 `deptno` int(11) 22 )engine=InnoDB default charset=utf8mb4; 23 select * from t_employee; 24 insert into t_employee(empno, ename, job, MGR, Hiredate, sal, comm, deptno) 25 values (7369,"SMITH","CLERK",7902,'1981-03-12',800.00,null,20), 26 (7499,"ALLEN","SALESMAN",7698,"1982-03-12",1600.00,300,30), 27 (7521,"WARD","SALESMAN",7698,"1983-03-12",1250.00,500,30), 28 (7566,"JONES","MANAGER",7839,"1984-03-12",2975.00,null,20), 29 (7654,"MARTIN","SALESMAN",7698,"1985-03-12",1250.00,1400.00,30), 30 (7698,"BLAKE","MANAGER",7839,"1986-03-12",2850.00,null,30), 31 (7782,"CLARK","MANAGER",7839,"1987-03-12",2450.00,null,10), 32 (7788,"SCOTT","ANALYST",7566,"1988-03-12",3000.00,null,20), 33 (7839,"KING","PRESIDENT",null,"1989-03-12",5000.00,null,10), 34 (7844,"TURNER","SALESMAN",7698,"1990-03-12",1500.00,0.00,30), 35 (7876,"ADAMS","CLERK",7788,"1991-03-12",1100.00,null,20), 36 (7900,"JAMES","CLERK",7698,"1992-03-12",950.00,null,30), 37 (7902,"FORD","ANALYST",7566,"1993-03-12",3000.00,null,20), 38 (7934,"MILLER","CLERK",7782,"1994-03-12",1300.00,null,10);
子查询语句中包含IN、ANY、ALL、EXISTS等关键字,通常还会配合比较运算符号一起使用(>、<、=、!=)。
1.单行单列的子查询:
//查询雇员表(t_employee)中工资比SMITH的全部雇员信息 select * from t_employee where sal>(select sal from t_employee where ename='SMITH');
2.单行多列子查询:
//查询工资和职位与SMITH一样的员工信息 select * from t_employee where (sal,job)=(select sal,job from t_employee where ename="SMITH");
3.多行单列子查询:这时候一般会使用到子查询的关键字IN、ANY、ALL、EXISTS等关键字。
IN和NOT IN用来判断主查询结果是否在子查询结果中:
//查询雇员表的数据记录,这些数据记录的部门编号(deptno)必须是在部门表中出现的 select * from t_employee where deptno in(select deptno from t_employee);
ANY用来表示主查询结果满足子查询的任意其中一个结果:(ANY包含三种情况)
=ANY:主查询结果等于任意其中一个子查询结果,这个与IN的功能一样。
>ANY(>=ANY):主查询结果大于任意其中一个子查询结果(意思是主查询结果要大于子查询的其中一个就符合条件,也就是比子查询最小的结果要大)。
<ANY(<=ANY):主查询结果小于任意其中一个子查询结果(意思是主查询结果要小于子查询的其中一个就符合条件,也就是比子查询最大的结果要小)。
//查询雇员信息,工资不低于职位MANAGER的雇员信息 select * from t_employee where sal>=ANY(select sal from t_employee where job="MANAGER");
ALL用来表示主查询结果满足子查询的所有结果:(ALL包含两种情况)
>ALL(>=ALL):主查询结果大于所有子查询的结果(意思就是主查询结果要大于子查询中最大的记录)。
<ALL(<=ALL):主查询结果小于所有子查询的结果(意思就是主查询结果要小于子查询中最小的记录)。
//查询雇员信息,雇员工资要与职位MANAGER的工资 select * from t_employee where sal>ALL(select sal from t_employee where job="MANAGER");
EXISTS是一个布尔类型,用来表示子查询结果是否为真。如果子查询中有数据记录则为真,执行主查询语句。
查询EXISTS时对外表采用遍历方式逐条查询,每次查询都会比较EXISTS的条件语句,当EXISTS为真时此时返回外表的查询记录。
//查询已有员工的部门信息 select * from t_dept where exists(select * from t_employee where t_employee.deptno=t_dept.deptno); //对比查询没有员工的部门信息 select * from t_dept where deptno not in(select deptno from t_employee);
4.多行多列子查询:
//查询部门信息:部门编号、部门名称、部门地址、部门雇员人数、部门平均工资 select deptno,dname,loc,number,average from t_dept inner join (select deptno dno,count(empno) number,AVG(sal) average from t_employee group by dno) e on t_dept.deptno=e.dno;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号