HADOOP 与 jupyterlab 链接
首先 咱们先把jdk1.0.0_60.tar.gz 和 hadoop-2.7.2.tar.gz 的压缩包放到root根目录下的opt文件夹下 如图:
然后 进入opt目录下执行解压命令:
tar -zxvf hadoop-2.7.2.tar.gz Hadoop的解压命令
tar -zxvf jdk1.8.0_60.tar.gz jdk的解压命令
解压完以后,修改环境变量:
vim ~/.bashrc 修改环境变量
export JAVA_HOME="/opt/jdk1.8.0_60"
export PATH="$PATH:$JAVA_HOME/bin"
export HADOOP_HOME="/opt/hadoop-2.7.2"
export PATH="$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin"

添加完毕以后 保存退出! 保存退出以后一定要执行应用命令 不然还是报错:
source ~/.bashrc 应用修改后的环境
验证: 输入java或者javac, 能够找到这个命令, 说明JAVA环境配置完成
同样的操作, 在两个虚拟机内分别配置
在以下文件里加入下面的内容:
core-site.xml
从这一步开始, 把目录切换到 /opt/bigData/Hadoop/hadoop-2.7.2/etc/hadoop/ 下
编辑core-site.xml文件
<property>
<name>fs.default.name</name<
<value>hdfs://master:9000/</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
hdfs-site.xml
编辑hdfs-site.xml文件
<property>
<name>dfs.data.dir</name>
<value>/home/luds/bigData/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/luds/bigData/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>master:50090</value>
</property>
mapred-site.xml
编辑mapred-site.xml
这个目录下面没有这个文件, 但是有这个文件的模板, 可以先从这个模板拷贝一个方案
指令: cp mapred-site.xml.template mapred-site.xml
然后再编辑这个文件
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
<description>MapReduce JobHistory Server IPC host:port</description>
</property>
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>The hostname of the RM.</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
配置hadoop_env.sh 环境
编辑文件 hadoop-env.sh
添加一行:
export JAVA_HOME=/opt/bigData/Java/jdk1.8.0_60
mapred-env.sh
编辑文件 mapred-env.sh
添加一行:
export JAVA_HOME=/opt/bigData/Java/jdk1.8.0_60
添加masters
添加一个masters文件, 将master添加进去
指令: vi masters
添加:
master
修改slaves
添加:
slave0
slave1
Hadoop简单语法:
hdfs 常用命令
(1)查看帮助
hdfs dfs -help
(2)查看当前目录信息
hdfs dfs -ls /
(3)上传文件
hdfs dfs -put /本地路径 /hdfs路径
(4)剪切文件
hdfs dfs -moveFromLocal a.txt /aa.txt
(5)下载文件到本地
hdfs dfs -get /hdfs路径 /本地路径
(6)合并下载
hdfs dfs -getmerge /hdfs路径文件夹 /合并后的文件
(7)创建文件夹
hdfs dfs -mkdir /hello
(8)创建多级文件夹
hdfs dfs -mkdir -p /hello/world
(9)移动hdfs文件
hdfs dfs -mv /hdfs路径 /hdfs路径
(10)复制hdfs文件
hdfs dfs -cp /hdfs路径 /hdfs路径
(11)删除hdfs文件
hdfs dfs -rm /aa.txt
(12)删除hdfs文件夹
hdfs dfs -rm -r /hello
(13)查看hdfs中的文件
hdfs dfs -cat /文件
hdfs dfs -tail -f /文件
(14)查看文件夹中有多少个文件
hdfs dfs -count /文件夹
(15)查看hdfs的总空间
hdfs dfs -df /
hdfs dfs -df -h /
(16)修改副本数
hdfs dfs -setrep 1 /a.txt
然后设置IP映射:
vim /etc/hosts ip映射
文件里面只留下ip 和 master就行

vim /etc/hostname 修改主机名
同上 只留下master 不需要ip
下载:tree
yum install tree
tree . 当前目录
tree bigdata 查看bigdata目录
Hadoop namenode -format 格式化磁盘
格式化完了 就会生成一个bigdata目录
然后启动服务:
start-all.sh 启动服务
启动服务密码要输入root用户的密码,少了输入四次,多的时候五六次 不要怕麻烦
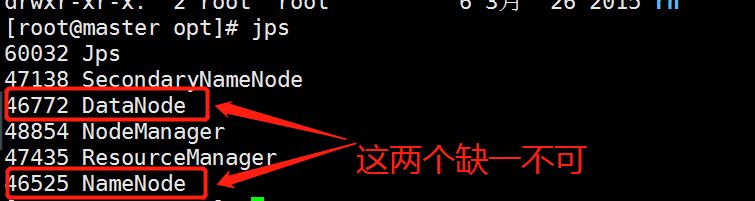
启动好了 查看 jps 就行
如果只有一个的情况下 建议删掉bigdata 然后重新格式化磁盘以后在运行
启动没有问题以后直接访问http://127.0.0.1:50070
链接jupyter
hdfs-site.xml文件中添加:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
执行:stop-all.sh
执行:start-all.sh
然后在jupyter中执行代码就可以了
#谨记: C:\Windows\System32\drivers\etc\hosts文件里做ip映射,否则连接不上

from hdfs.client import Client
#关于python操作hdfs的API可以查看官网:
#https://hdfscli.readthedocs.io/en/latest/api.html
#读取hdfs文件内容,将每行存入数组返回
def read_hdfs_file(client,filename):
lines = []
with client.read(filename, encoding='utf-8', delimiter='\n') as reader:
for line in reader:
#pass
#print line.strip()
lines.append(line.strip())
return lines
#创建目录
def mkdirs(client,hdfs_path) :
client.makedirs(hdfs_path)
#删除hdfs文件
def delete_hdfs_file(client,hdfs_path):
client.delete(hdfs_path)
#上传文件到hdfs
def put_to_hdfs(client,local_path,hdfs_path):
client.upload(hdfs_path, local_path,cleanup=True)
#从hdfs获取文件到本地
def get_from_hdfs(client,hdfs_path,local_path):
client.download(hdfs_path, local_path, overwrite=False)
#追加数据到hdfs文件
def append_to_hdfs(client,hdfs_path,data):
client.write(hdfs_path, data,overwrite=False,append=True)
#覆盖数据写到hdfs文件
def write_to_hdfs(client,hdfs_path,data):
client.write(hdfs_path, data,overwrite=True,append=False)
#移动或者修改文件
def move_or_rename(client,hdfs_src_path, hdfs_dst_path):
client.rename(hdfs_src_path, hdfs_dst_path)
#返回目录下的文件
def list(client,hdfs_path):
return client.list(hdfs_path, status=False)
# root:连接的跟目录
client = Client("http://192.168.161.134:50070",
root="/",timeout=5*1000,session=False)
# put_to_hdfs(client,'a.txt','/b.txt') #上传文件
# append_to_hdfs(client,'/b.txt','111111111111111'+'\n') #追加数据
# write_to_hdfs(client,'/b.txt','222222222222'+'\n') #替换数据


 浙公网安备 33010602011771号
浙公网安备 33010602011771号