聚类
聚类分析算法概述:
1.K-Means算法:
步骤:
-
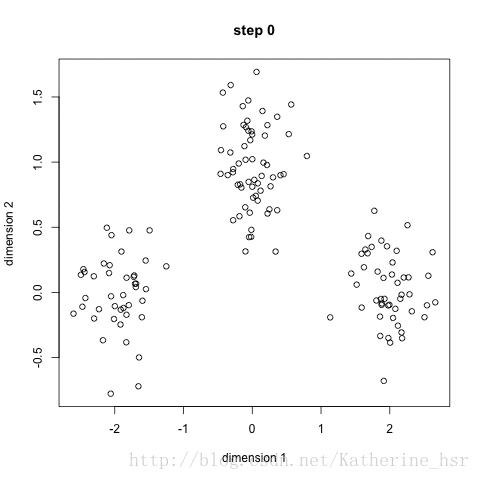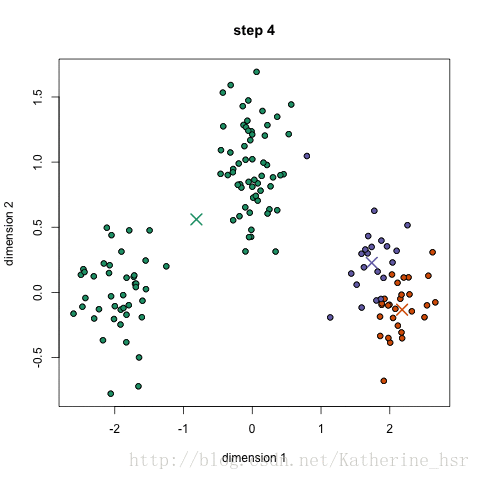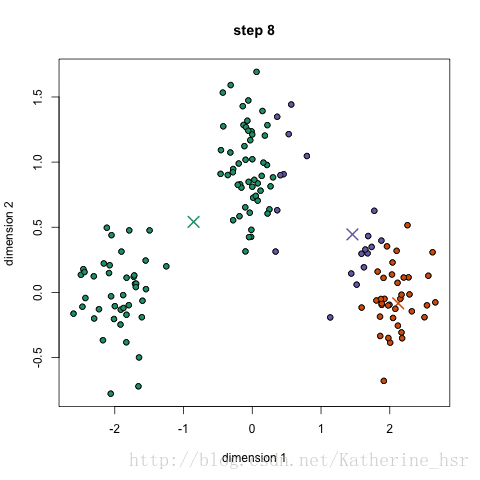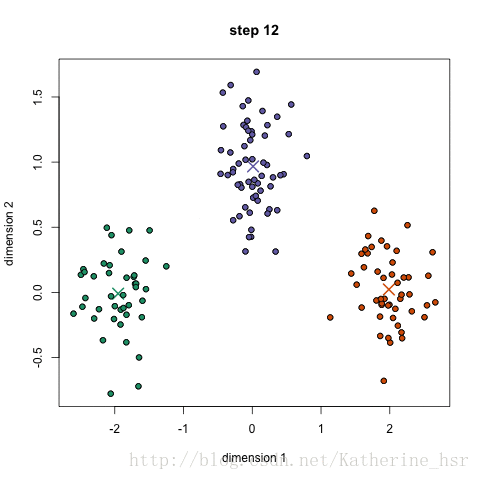
首先我们选择一些类/组,并随机初始化他们各自的中心点.中心点是与每个数据点向量长度相同的位置.这需要我们提前预知类的数量(即中心点的数量)
-
计算每个数据点到中心点的距离,数据点距离哪个中心点最近就划分到哪一类
-
计算每一类的中心点作为新的中心点
-
重复以上步骤,知道每一类中心点在每次迭代后变化不大为止
优点:
速度快,计算简便
缺点:
我们必须知道数据有多少组/类
数据集一样 可能同一个k值,分类却是不一样的
2.均值漂移聚类:
均值漂移聚类是基于滑动窗口的算法爱找到数据点密集区域.这是一个基于质心的算法,通过将中心点的候选点更新为滑动窗口的内点的均值来完成.来定位每个组/类的中心点.
具体步骤:
-
确定滑动窗口半径r,以随机选取的中心点C半径为r的圆形滑动窗口开始滑动。均值漂移类似一种爬山算法,在每一次迭代中向密度更高的区域移动,直到收敛。
-
每一次滑动到新的区域,计算滑动窗口内的均值来作为中心点,滑动窗口内的点的数量为窗口内的密度。在每一次移动中,窗口会想密度更高的区域移动。
-
移动窗口,计算窗口内的中心点以及窗口内的密度,知道没有方向在窗口内可以容纳更多的点,即一直移动到圆内密度不再增加为止。
-
步骤一到三会产生很多个滑动窗口,当多个滑动窗口重叠时,保留包含最多点的窗口,然后根据数据点所在的滑动窗口进行聚类。

优点:
不同于K-Means算法,均值漂移聚类算法不需要我们知道多少组/类
基于密度的算法相比于K-Means树军职影响小
缺点:
矿口半径的选择可能是不重要的
3.DBSCAN算法:
步骤:
-
标记所有对象是unvisited
-
DO
-
随机选择一个unvisited对象p
-
标记p是visited
-
if p的$\epsilon-$邻域至少有minpoints个对象
-
创建一个新簇C,并把p添加到新簇C中
-
令N是p的$\epsilon-$邻域中的对象集合
遍历N这个集合中每一个点$p_i$:
if $p_i$是unvisited:
标记p是visited
if p的$\epsilon-$邻域至少有minPts个对象,把这些对象添加到N中
如果p还不是任何簇的成员,把p添加到C中
end for
-
else p是噪声点
-
Until 没有标记为unvisited 的对象
参数选择:
- 半径$\epsilon:$可以根据K距离来设定:找突破点
- K距离:给定数据集$P={p(i);i=1,2,....,n}$,计算p(i)到集合D的子集S中所有点之间的距离,距离按照从小到大的顺序排序,d(k)就被称为k-距离
- MinPts:k-距离中k的值,一般取得很小,多洗尝试
优势:
不需要指定簇的个数
可以发现任意形状的簇
擅长找到离散点
两个参数就够了
劣势:
高纬度数据有些困难
参数难以选择
sklearn中效率很慢
4.凝聚层次聚类:
层次聚类算法分为两类:自上而下,自下而上.凝聚层次聚类算法(HAC)是自下而上的一种聚类算法.HAC首先将每个数据点视为一个单一的簇,然后计算机所有簇之间的距离来合并簇,知道所有簇聚合成为一个簇为止.
步骤:
- 首先将每个数据点视为一个单一簇,测量两个簇之间距离的度量标准
- 在每次迭代中,将两个具有最小距离的簇合并成一个簇
- 重复所有数据点成一个簇

 浙公网安备 33010602011771号
浙公网安备 33010602011771号