【RabbitMQ 实战指南】一 RabbitMQ入门
1、消息中间件
1.1、什么是消息中间件
消息中间件(Message Queue Middleware,简称 MQ)是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通道来进行分布式系统的集成。
1.2、消息中间件的作用
- 解耦:在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息队列在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
- 冗余(存储):有时在处理数据的时候处理过程会失败。除非数据被持久化,否则将永远丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。在被许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理过程明确的指出该消息已经被处理完毕,确保你的数据被安全的保存直到你使用完毕。
- 扩展性:因为消息中间件解捐了应用的处理过程,所以提高消息入队和处理的效率是很容 易的,只要另外增加处理过程即可,不需要改变代码,也不需要调节参数。
- 流量削峰: 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流 量 并不常 见。如果以能处理这类峰值为标准而投入资源,无疑是巨大的浪费 。 使用消息中间件能够使关 键组件支撑突发访问压力,不会因为突发的超负荷请求而完全崩惯 。
- 可恢复性: 当系统一部分组件失效时,不会影响到整个系统 。 消息中间件降低了进程间的 稿合度,所以即使一个处理消息的进程挂掉,加入消息中间件中的消息仍然可以在系统恢复后 进行处理 。
- 顺序保证: 在大多数使用场景下,数据处理的顺序很重要,大部分消息中间件支持一定程 度上的顺序性。
- 缓冲: 在任何重要的系统中,都会存在需要不同处理时间的元素。消息中间件通过 一个缓 冲层来帮助任务最高效率地执行,写入消息中间件的处理会尽可能快速 。 该缓冲层有助于控制 和优化数据流经过系统的速度。
- 异步通信: 在很多时候应用不想也不需要立即处理消息 。消息中间件提供了异步处理机制, 允许应用把一些消息放入消息中间件中,但并不立即处理它,在之后需要的时候再慢慢处理 。
1.3、消息中间件的缺点
- 系统可用性降低: 系统中加入了MQ,如果MQ挂了,整套系统奔溃了
- 系统复杂度提高:引入MQ会产生一些问题,比如怎么保证消息没有重复消费,怎么处理消息丢失的情况等
2、RabbitMQ 简介
RabbitMQ 是采用 Erlang 语言实现 AMQP (Advanced Message Queuing Protocol,高级消息 队列协议)的消息中间件。
2.1、RabbitMQ 特点
- 可靠性:RabbitMQ 使用一些机制来保证可靠性,如持久性、传输确认及发布确认等
- 灵活的路由: 在消息进入队列之前,通过交换器来路由消息。对典型的路由功能,RabbitMQ已经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个交换器绑定在一起,也可以通过插件机制来实现自己的交换器
- 扩展性: 多个 RabbitMQ 节点可以组成一个集群,也可以根据实际业务情况动态地扩展集群中的节点
- 插件机制: RabbitMQ 提供了许多插件,以实现从多方面进行扩展,当然也可以编写自己的插件
- 高可用性: 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队列任然可用
- 多种协议: RabbitMQ 除了原生支持AMQP协议,还支持STOMP、MQTT等多种消息中间件协议
- 多语言客户端: RabbitMQ 几乎支持所用常用语言,比如Java、Python、Ruby、PHP等
- 管理界面: RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集群中的节点等
2.2、相关概念
RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息。可以把消 息传递的过程想象成:当你将一个包裹送到邮局,邮局会暂存并最终将邮件通过邮递员送到收 件人的手上, RabbitMQ 就好比由邮局、邮箱和邮递员组成的一个系统。从计算机术语层面来说, RabbitMQ 模型更像是一种交换机模型。 RabbitMQ 的整体模型架构如图所示:
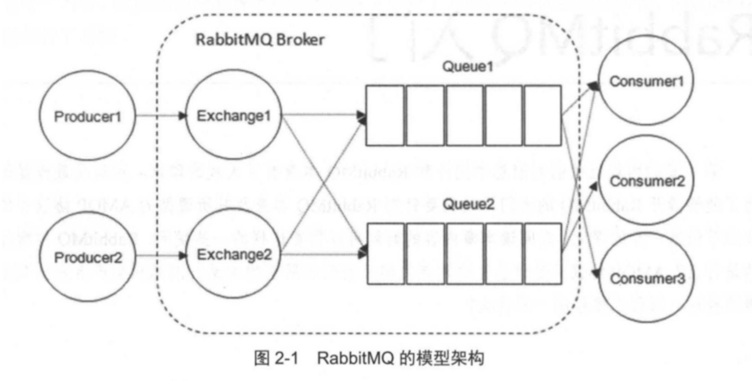
- Producer: 生产者,就是投递消息的 一方。
- Consumer: 消费者,就是接收消息的 一方。
- Broker: 消息中间件的服务节点。如图展示了生产者将消息存入 RabbitMQ Broker,以及消费者从 Broker中消费数据的整个流程
![]()
- Queue: 队列,是 RabbitMQ 的内部对象,用于存储消息。
- Exchange: 交换器。生产者将消息发送到 Exchange,由交换器将消息路由到一个或者多个队列中。如果路由不到,或许会返回给生产者,或许直接丢弃。 交换器的具体示意图如图所示
![]()
- RoutingKey: 路由键 。生产者将消息发给交换器 的时候, 一般会 指定 一个 RoutingKey,用 来指定这个消息的路由规则,而这个 RoutingKey 需要与交换器类型和绑定键 (BindingKey) 联 合使用才能最终生效。
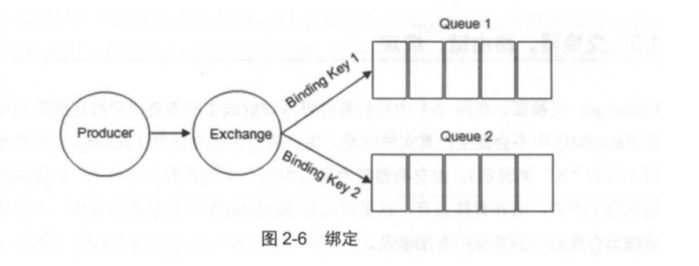
- Binding: 绑定 。 RabbitMQ 中通过绑定将交换器与队列关联起来,在绑定的时候一般会指定一个绑定键 (BindingKey),这样 RabbitMQ 就知道如何正确地将消息路由到队列了,如图所
![]()


2.3、交换器类型
RabbitMQ 常用的交换器类型有 fanout、 direct、 topic、 headers 这四种 。
- fanout: 它会把所有发送到该交换器的消息路由到所有与该交换器绑定的队列中。
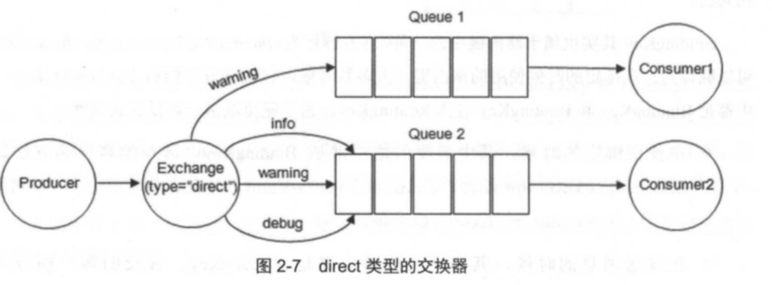
- direct: 它会把消息路由到那些 BindingKey和 RoutingKey 完全匹配的队列中。
![]()
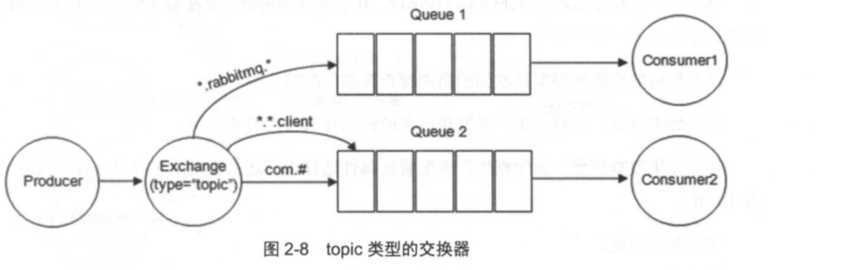
- topic: topic类型的交换器在匹配规则上进行了扩展,它与 direct类型的交换器相似,但是它支持模糊匹配,它有如下约定:
- RoutingKey 为一个点号" "分隔的字符串,比如“com.rabbitmq.client”, "java.util.concurrent", "com.hidden.client"
- BindingKey 和 RoutingKey 一样也是点号" "分隔的字符串;
- BindingKey 中可以存在两种特殊 字符串""和"#",用于做模糊匹配,其中""用于匹配一个单词,"#"用于匹配多规格单词(可以是零个)。
-
- 如图
- 路由键为" com.rabbitmq.client" 的消息会同时路由到 Queuel 和 Queue2;
- 路由键为" com.hidden.client" 的消息只会路由到 Queue2 中:
- 路由键为" com.hidden.demo" 的消息只会路由到 Queue2 中:
- 路由键为 "java.rabbitmq.demo" 的消息只会路由到 Queuel 中:
- 路由键为" java.util.concurrent" 的消息将会被丢弃或者返回给生产者(需要设置 mandatory 参数) ,因为它没有匹配任何路由键。
- 如图
- headers: headers 类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中 的 headers 属性进行匹配。在绑定队列和交换器时制定一组键值对 , 当发送消息到交换器时, RabbitMQ 会获取到该消息的 headers (也是一个键值对的形式) ,对比其中的键值对 是否完全 匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由 到该队列 。 headers 类型的交换器性能会很差,而且也不实用,基本上不会看到它的存在。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号