Spring源码系列(二)--bean组件的源码分析
 在上一篇博客(Spring源码系列(一)--详细介绍bean组件)中,我们讨论了 spring-bean 是什么?用来解决什么问题?如何使用 spring-bean?等等问题,算是从使用者的角度对 spring-bean 有了一定了解。这篇博客我们将开始分析 spring-bean 的源码,大致的思路如下:
1. spring-bean 是如何设计的
2. 开始看源码--从哪里开始
3. bean 冲突的处理
4. 先看看是否需要创建
5. 开始创建 bean
6. bean 的实例化
7. bean 的属性装配
8. bean 的初始化(省略)
在上一篇博客(Spring源码系列(一)--详细介绍bean组件)中,我们讨论了 spring-bean 是什么?用来解决什么问题?如何使用 spring-bean?等等问题,算是从使用者的角度对 spring-bean 有了一定了解。这篇博客我们将开始分析 spring-bean 的源码,大致的思路如下:
1. spring-bean 是如何设计的
2. 开始看源码--从哪里开始
3. bean 冲突的处理
4. 先看看是否需要创建
5. 开始创建 bean
6. bean 的实例化
7. bean 的属性装配
8. bean 的初始化(省略)
简介
在上一篇博客(Spring源码系列(一)--详细介绍bean组件)中,我们讨论了 spring-bean 是什么?用来解决什么问题?如何使用 spring-bean?等等问题,算是从使用者的角度对 spring-bean 有了一定了解。这篇博客我们将开始分析 spring-bean 的源码,大致的思路如下:
- spring-bean 是如何设计的
- 开始看源码--从哪里开始
- bean 冲突的处理
- 先看看是否需要创建
- 开始创建 bean
- bean 的实例化
- bean 的属性装配
- bean 的初始化(省略)
spring-bean 是如何设计的
sping-bean 的“设计图”
和往常一样,为了让思路更连贯一些,我们还是按套路来:从宏观到微观。这里我画了一张 spring-bean 的“设计图”。
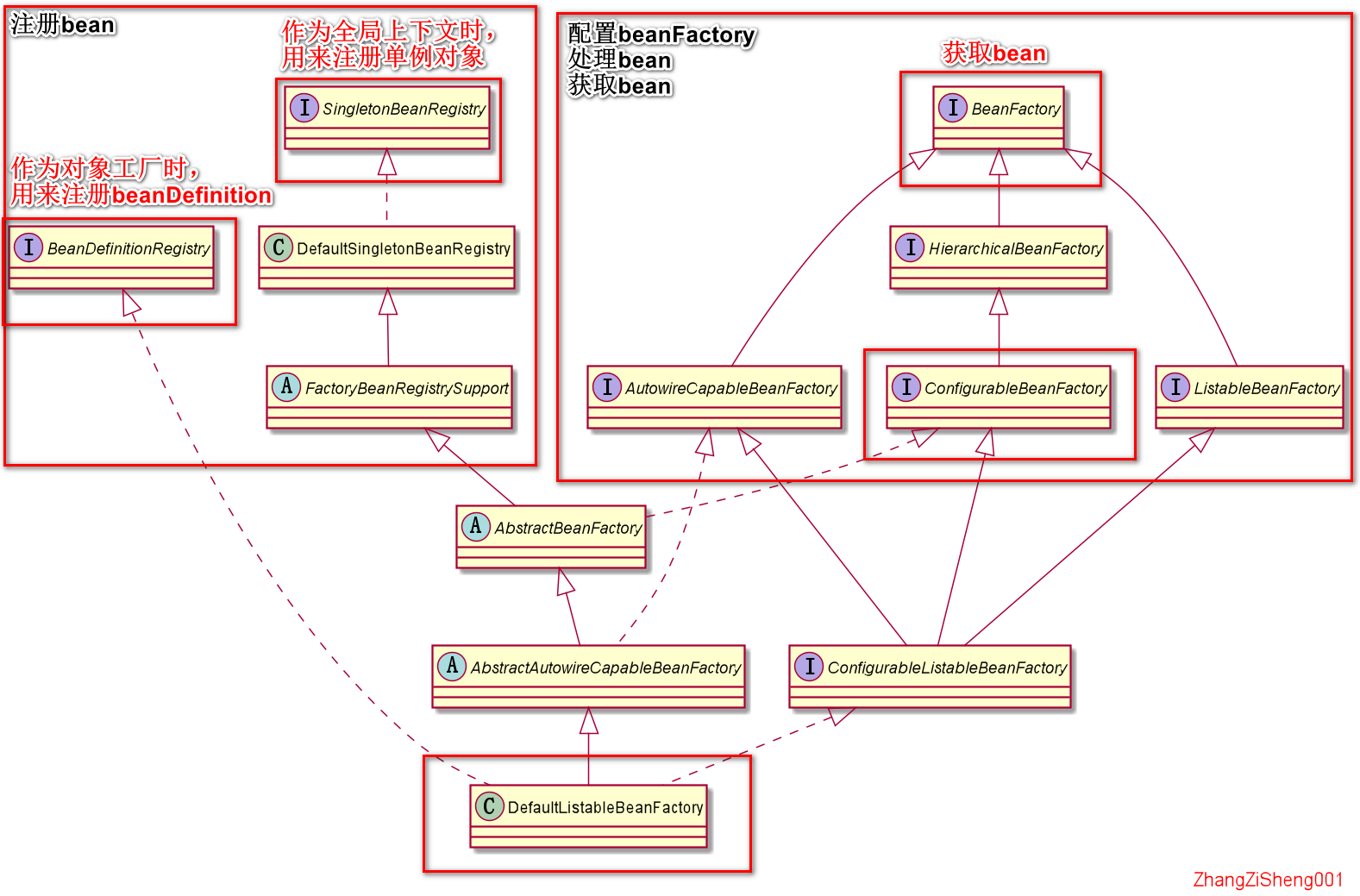
是不是看起来很复杂呢?单看这么多的类和线条确实挺复杂的,但我们知道,代码实现都是对上层设计的具体化,我们经常会强调说,写代码前要先设计一下,也是这个道理,所以只要我们适当地分层、抽象,就可以从宏观到微观逐步地了解一个表面看起来非常复杂的体系。
如果你看过 spring 源码就会发现,sping 的代码不能算是优秀,但人家的抽象设计还是比较厉害的。
从使用者的角度看
首先,我们从使用者的角度来看这个设计图:
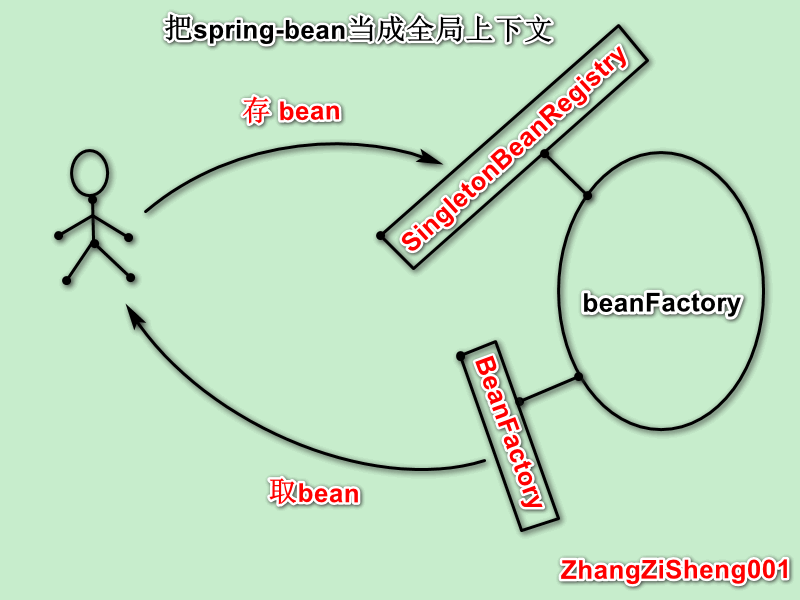
- 如果我们把 sping-bean 当成全局上下文时,会使用
SingletonBeanRegistry来存 bean,再用BeanFactory取 bean;
- 如果我们把 spring-bean 当成对象工厂时,会使用
BeanDefinitionRegistry注册 beanDefinition,再用BeanFactory获取 bean。
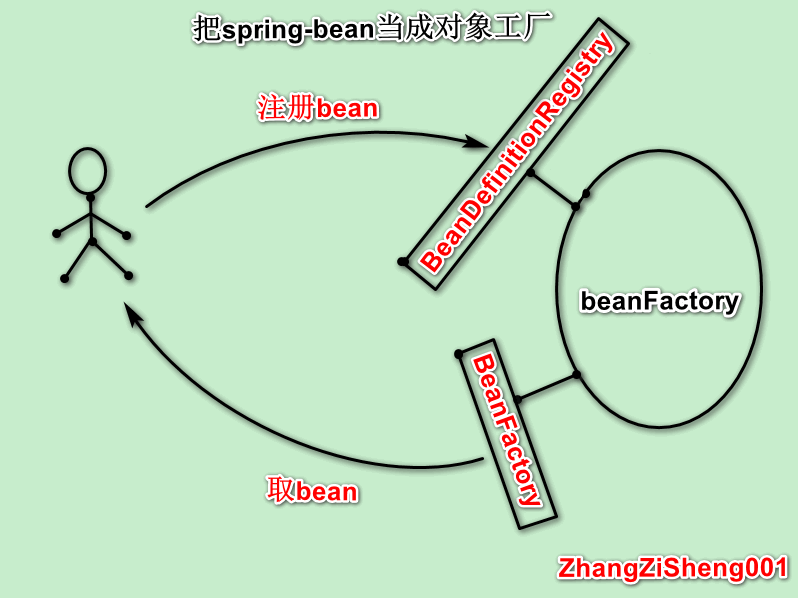
也就是说,作为 spring-bean 的使用者,我们一般只会使用到三个接口:SingletonBeanRegistry、BeanDefinitionRegistry和BeanFactory。
如果需要注册类型转换器、注册处理器等等,顶多还会用到一个ConfigurableBeanFactory。
这就是使用者眼里的 spring-bean。
从设计者的角度来看
接着,我们从设计者的角度来看。除了要提供上面的几个接口,还需要提供更多的东西。
- 如果 spring-bean 被当成全局上下文,需要有一个地方来存放这些全局对象。
class DefaultSingletonBeanRegistry {
// beanName=singletonObject键值对
// 除了registerSingleton的会放在这里,registerBeanDefinition生成的单例bean实例也会放在这里
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
}
- 如果 spring-bean 被当成对象工厂,也需要有一个地方来存放 beanDefinition。
class DefaultListableBeanFactory {
// beanName=beanDefination键值对
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);
}
- 如果 spring-bean 被当成对象工厂,还需要根据 beanDefinition 的信息来创建 bean,这部分功能独立成一个接口--
AutowireCapableBeanFactory,用来进行实例化、装配属性、初始化等。
这就是设计者眼里的 spring-bean。
补充
现在回头看看上面的“设计图”,还会觉得很复杂吗?
所以,研究源码不要直接看代码细节,那样做会让我们无从下手,我们应该从更上一层的设计入手,后面看源码的时候将势如破竹。另外,我们会发现,相比代码实现,抽象的设计会更吸引人,更容易让人记住。
接下来就是代码实现了。这部分可能会枯燥一些,如果兴趣不大,可以点到为止,理解抽象设计就足够了。
开始看源码--从哪里开始
spring-bean 的代码非常多,把所有代码都分析一遍非常难。这里我选择分析获取 bean 的过程,并且只关注单例 bean 的情况。起点从DefaultListableBeanFactory.getBean(Class)方法开始。
前面都是很多参数适配的方法,我们直接进入到DefaultListableBeanFactory.resolveBean(ResolvableType, Object[], boolean)。可以看到,beanFactory 是支持继承关系的,如果儿子没有,会尝试从父亲那里获取。
private <T> T resolveBean(ResolvableType requiredType, @Nullable Object[] args, boolean nonUniqueAsNull) {
// 根据beanType从当前beanFactory里获取bean
NamedBeanHolder<T> namedBean = resolveNamedBean(requiredType, args, nonUniqueAsNull);
if (namedBean != null) {
return namedBean.getBeanInstance();
}
// 如果当前beanFactory里没有,会尝试从parent beanFactory中获取
// 这部分代码省略······
return null;
}
bean冲突的处理
进入到DefaultListableBeanFactory.resolveNamedBean(ResolvableType, Object[], boolean)方法。这个方法主要做了这么一件事:处理 bean 冲突。
前面的使用例子我们说过,当同一类型存在多个匹配的 bean 时,将出现NoUniqueBeanDefinitionException的异常,这时,我们可以有三种方法解决。在下面的代码中就能够体现出来。
private <T> NamedBeanHolder<T> resolveNamedBean(
ResolvableType requiredType, @Nullable Object[] args, boolean nonUniqueAsNull) throws BeansException {
// 获取指定类型的所有beanName,可能匹配到多个
String[] candidateNames = getBeanNamesForType(requiredType);
// 匹配到多个beanName的第一道处理。只保留两种beanName:
// 1. 通过registerSingleton注册的
// 2. 通过registerBeanDefinition注册且autowireCandidate = true的
if (candidateNames.length > 1) {
List<String> autowireCandidates = new ArrayList<>(candidateNames.length);
for (String beanName : candidateNames) {
if (!containsBeanDefinition(beanName) || getBeanDefinition(beanName).isAutowireCandidate()) {
autowireCandidates.add(beanName);
}
}
if (!autowireCandidates.isEmpty()) {
candidateNames = StringUtils.toStringArray(autowireCandidates);
}
}
// 只有唯一匹配的beanName,那就根据beanName和beanType获取bean
if (candidateNames.length == 1) {
String beanName = candidateNames[0];
return new NamedBeanHolder<>(beanName, (T) getBean(beanName, requiredType.toClass(), args));
} else if (candidateNames.length > 1) {
Map<String, Object> candidates = new LinkedHashMap<>(candidateNames.length);
// 预处理,list转map,其中value有两种类型
// 1. 通过registerSingleton注册的且无参构造,则value为bean实例本身
// 2. 其他情况,value为bean类型
for (String beanName : candidateNames) {
if (containsSingleton(beanName) && args == null) {
Object beanInstance = getBean(beanName);
candidates.put(beanName, (beanInstance instanceof NullBean ? null : beanInstance));
}
else {
candidates.put(beanName, getType(beanName));
}
}
// 匹配到多个beanName的第二道处理。找到唯一一个primary=true的beanName
String candidateName = determinePrimaryCandidate(candidates, requiredType.toClass());
// 匹配到多个beanName的第三道处理。通过我们注册的OrderComparator来比较获得唯一beanName
if (candidateName == null) {
candidateName = determineHighestPriorityCandidate(candidates, requiredType.toClass());
}
// 只有唯一匹配的beanName,根据beanName和beanType获取bean
if (candidateName != null) {
Object beanInstance = candidates.get(candidateName);
if (beanInstance == null || beanInstance instanceof Class) {
beanInstance = getBean(candidateName, requiredType.toClass(), args);
}
return new NamedBeanHolder<>(candidateName, (T) beanInstance);
}
// 如果还是确定不了唯一beanName,根据nonUniqueAsNull选择抛错或返回null
if (!nonUniqueAsNull) {
throw new NoUniqueBeanDefinitionException(requiredType, candidates.keySet());
}
}
return null;
}
先看看是否需要创建
进入AbstractBeanFactory.doGetBean(String, Class<T>, Object[], boolean),这个方法代码比较多,我只保留了单例部分的代码。这个方法主要做了这么一件事:针对单例 bean,看看 bean 是否已经创建好了,创建好了就直接返回,没有就走创建。
protected <T> T doGetBean(final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly) throws BeansException {
// 转义我们传入的name,这里包括两个内容:
// 1. 如果是别名,需要转换为别名对应的beanName;
// 2. 如果是“&”+factoryBeanName,则需要去掉前面的“&”
final String beanName = transformedBeanName(name);
Object bean;
// 获取已经创建好的单例,这里包含两种bean
// 1. 完整的bean--从singletonObjects获取
// 2. 可能不完整的bean--从earlySingletonObjects或singletonFactories中获取到的bean,只是实例化好,可能还没初始化,设置还没属性装配(我觉得这种机制意义不大)
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
// 返回bean实例
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
} else {
// 这里标记对应的RootBeanDefinition需要重新merge(把RootBeanDefinition当成一个适配对象即可)
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
// 获取指定beanName对应的RootBeanDefinition对象
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
// 如果当前bean需要依赖其他bean,则会先获取依赖的bean
// 这部分省略······
// 根据scope创建bean,这里我们只看单例的情况
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
// 进入创建bean
return createBean(beanName, mbd, args);
});
// 获取bean实例
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
} else if (mbd.isPrototype()) {
// ·······
} else {
// ·······
}
}
// 如果获取到的bean实例不是我们指定的类型
if (requiredType != null && !requiredType.isInstance(bean)) {
// 使用我们注册的类型转换器进行转换
T convertedBean = getTypeConverter().convertIfNecessary(bean, requiredType);
// 如果转换不了,则会抛错
if (convertedBean == null) {
throw new BeanNotOfRequiredTypeException(name, requiredType, bean.getClass());
}
return convertedBean;
}
return (T) bean;
}
开始创建 bean
进入AbstractAutowireCapableBeanFactory.doCreateBean(String, RootBeanDefinition, Object[])。这个方法主要做了这么一件事:开始创建 bean,也可以说是定义了创建 bean 的一个主流程。
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// 实例化
BeanWrapper instanceWrapper = createBeanInstance(beanName, mbd, args);
final Object bean = instanceWrapper.getWrappedInstance();
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
// ······
// 单例的可以将还没装配和初始化的bean先暴露出去,即放在singletonFactories中
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
Object exposedObject = bean;
// 属性装配
populateBean(beanName, mbd, instanceWrapper);
// 初始化
exposedObject = initializeBean(beanName, exposedObject, mbd);
// ······
return exposedObject;
}
接下来是 bean 实例化、属性装配和初始化的内容,这部分代码量相当庞大,随便一项都可以分析个几天几夜,所以,这里不会讲太细,而且只是简单分析实例化和属性装配,不分析初始化。遗漏的地方感兴趣可以自己研究下。
实例化
判断走有参构造还是无参构造
进入AbstractAutowireCapableBeanFactory.createBeanInstance(String, RootBeanDefinition, Object[])。这个方法主要做了这么一件事:判断走有参构造还是无参构造。
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
// 解析bean类型
Class<?> beanClass = resolveBeanClass(mbd, beanName);
// 通过beanDefinition中定义的Supplier来获取实例化bean
Supplier<?> instanceSupplier = mbd.getInstanceSupplier();
if (instanceSupplier != null) {
return obtainFromSupplier(instanceSupplier, beanName);
}
// 通过beanDefinition中定义的FactoryMethod来实例化bean
if (mbd.getFactoryMethodName() != null) {
return instantiateUsingFactoryMethod(beanName, mbd, args);
}
// ······
// 如果beanDefination的自动装配模式为构造注入,或者beanDefination中指定了构造参数,或者我们传入的构造参数非空,则进入实例化bean
if (mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, null, args);
}
// ······
// 使用无参构造实例化bean或factoryBean
return instantiateBean(beanName, mbd);
}
接下来,本文只讨论有参构造实例化的情况。
确定构造方法和参数列表
进入到ConstructorResolver.autowireConstructor(String, RootBeanDefinition, Constructor<?>[], Object[])。这个方法主要做了这么一件事:确定构造方法和参数列表。代码太多了,相对地,我也删减了很多,整体上会更好理解一些。这段代码可以分成三种场景来看:
- 入参里显式指定构造参数;
- beanDefinition 中指定了构造参数;
- beanDefinition 的自动装配模式为构造注入。
public BeanWrapper autowireConstructor(String beanName, RootBeanDefinition mbd,
@Nullable Constructor<?>[] chosenCtors, @Nullable Object[] explicitArgs) {
BeanWrapperImpl bw = new BeanWrapperImpl();
this.beanFactory.initBeanWrapper(bw);
// 这两个局部变量很重要,这整段代码本质上就是为了确定这两个变量的值,即使用哪个构造对象以及哪些参数列表来进行实例化
Constructor<?> constructorToUse = null;
Object[] argsToUse = null;
// 场景1的情况,开局就知道了参数列表
if (explicitArgs != null) {
argsToUse = explicitArgs;
}
// 需要继续确定constructorToUse和argsToUse的值
if (constructorToUse == null || argsToUse == null) {
Constructor<?>[] candidates = chosenCtors;
// 一般chosenCtors都是null,这里我们利用反射初始化
if (candidates == null) {
Class<?> beanClass = mbd.getBeanClass();
candidates = (mbd.isNonPublicAccessAllowed() ?
beanClass.getDeclaredConstructors() : beanClass.getConstructors());
}
// bean对象只有一个无参构造且未指定参数列表时,直接走无参实例化
if (candidates.length == 1 && explicitArgs == null && !mbd.hasConstructorArgumentValues()) {
// ······
}
// 场景2和3的参数列表
ConstructorArgumentValues resolvedValues = null;
// 获取参数列表中参数的个数
int minNrOfArgs;
// 场景1:入参指定的构造参数个数
if (explicitArgs != null) {
minNrOfArgs = explicitArgs.length;
} else {
// 场景2:beanDefinition中指定的构造参数个数
// 场景3:0
ConstructorArgumentValues cargs = mbd.getConstructorArgumentValues();
resolvedValues = new ConstructorArgumentValues();
minNrOfArgs = resolveConstructorArguments(beanName, mbd, bw, cargs, resolvedValues);
}
// 根据参数列表的参数个数从大到小排列
AutowireUtils.sortConstructors(candidates);
// 判断是否走场景3的逻辑
boolean autowiring = (chosenCtors != null ||
mbd.getResolvedAutowireMode() == AutowireCapableBeanFactory.AUTOWIRE_CONSTRUCTOR);
// 遍历候选的构造方法
for (Constructor<?> candidate : candidates) {
int parameterCount = candidate.getParameterCount();
// 如果上一个循环已经确定了constructorToUse和argsToUse的值,或者参数个数已经无法匹配到对应的构造方法,则不再循环
if (constructorToUse != null && argsToUse != null && argsToUse.length > parameterCount) {
break;
}
// 如果当前构造方法的参数个数小于minNrOfArgs,则遍历下一个
if (parameterCount < minNrOfArgs) {
continue;
}
ArgumentsHolder argsHolder;
Class<?>[] paramTypes = candidate.getParameterTypes();
// 针对场景2、3的情况
if (resolvedValues != null) {
// 获取当前构造方法的参数的名字
ParameterNameDiscoverer pnd = this.beanFactory.getParameterNameDiscoverer();
if (pnd != null) {
paramNames = pnd.getParameterNames(candidate);
}
// 解析参数列表
argsHolder = createArgumentArray(beanName, mbd, resolvedValues, bw, paramTypes, paramNames,
getUserDeclaredConstructor(candidate), autowiring, candidates.length == 1);
} else {
// 场景1的情况
if (parameterCount != explicitArgs.length) {
continue;
}
argsHolder = new ArgumentsHolder(explicitArgs);
}
// 得到匹配的构造对象和构造参数
constructorToUse = candidate;
argsToUse = argsHolder.arguments;
}
// 如果找不到合适的构造对象,则会抛错
if (constructorToUse == null) {
// 省略代码······
}
}
// 接下来就是使用构造对象和参数来实例化对象
bw.setBeanInstance(instantiate(beanName, mbd, constructorToUse, argsToUse));
return bw;
}
实例化部分的整个逻辑基本是讲完了,很多的细节我都没有展开讲,但有了整体逻辑的引导,相信分析起来也不会很难。
属性装配
获取待装配属性
进入AbstractAutowireCapableBeanFactory.populateBean(String, RootBeanDefinition, BeanWrapper)。这个方法主要做了这么一件事:获取待装配属性。除了 beanDefinition 中定义的 name = value 待装配属性列表,还需要根据我们设置的自动装配类型来额外添加 name = value 待装配属性列表。例如,选择按名字装配时,发现 bean 有 setFoo 方法,而且 beanFactory 里刚好也有叫 foo 的 bean,这时就会加入这样一个待装配属性--name 为 foo,value为 foo 对应的 bean。
protected void populateBean(String beanName, RootBeanDefinition mbd, BeanWrapper bw) {
// 实例化后执行注册的处理器中的方法(如果有的话),如果返回了false,则不进行属性装配,直接返回
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
return;
}
}
}
}
// 获取beanDefinition中定义的name=value待装配属性列表
PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null);
// 根据beanDefinition的自动装配模式,在待装配属性列表里添加name = value
int resolvedAutowireMode = mbd.getResolvedAutowireMode();
if (resolvedAutowireMode == AUTOWIRE_BY_NAME || resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
if (resolvedAutowireMode == AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
if (resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
// ······
if (pvs != null) {
// 执行属性装配
applyPropertyValues(beanName, mbd, bw, pvs);
}
}
这个方法中主要涉及autowireByName、autowireByType和applyPropertyValues三个方法,前两个暂时不展开,只讲最后一个方法。
处理待装配属性的值
进入AbstractAutowireCapableBeanFactory.applyPropertyValues(String, BeanDefinition, BeanWrapper, PropertyValues)方法。这个方法主要做了这么一件事:处理待装配属性的值,具体需要经过“两次转换”,分别为:
- 如果 value 是
BeanDefinition、BeanDefinitionHolder等的对象,需要转换; - 如果 value 的类型与 bean 中成员属性的类型不一致,需要转换。
protected void applyPropertyValues(String beanName, BeanDefinition mbd, BeanWrapper bw, PropertyValues pvs) {
// ······
MutablePropertyValues mpvs = null;
// 获取属性列表
List<PropertyValue> original;
if (pvs instanceof MutablePropertyValues) {
mpvs = (MutablePropertyValues) pvs;
// 如果所有属性对象已经完成“两次转换”,则直接装配属性
if (mpvs.isConverted()) {
bw.setPropertyValues(mpvs);
return;
}
original = mpvs.getPropertyValueList();
} else {
original = Arrays.asList(pvs.getPropertyValues());
}
BeanDefinitionValueResolver valueResolver = new BeanDefinitionValueResolver(this, beanName, mbd, bw);
// 注意,这里并没有进行所谓的深度复制,不要被命名迷惑了
List<PropertyValue> deepCopy = new ArrayList<>(original.size());
boolean resolveNecessary = false;
// 遍历属性列表
for (PropertyValue pv : original) {
// 当前属性对象已经完成“两次转换”,直接添加到deepCopy
if (pv.isConverted()) {
deepCopy.add(pv);
} else {
String propertyName = pv.getName();
Object originalValue = pv.getValue();
// 第一次转换:例如value为BeanDefinition类型,需要转换
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
Object convertedValue = resolvedValue;
// 如果当前属性为可写属性,且属性名不是类似于foo.bar或addresses[0]的形式,则需要进行第二次转换
boolean convertible = bw.isWritableProperty(propertyName) &&
!PropertyAccessorUtils.isNestedOrIndexedProperty(propertyName);
if (convertible) {
// 第二次转换:例如setter方法类型为Integer,此时value为string,需要转换一下
convertedValue = convertForProperty(resolvedValue, propertyName, bw, converter);
}
pv.setConvertedValue(convertedValue);
// 当前属性对象已经完成“两次转换”,添加到deepCopy
deepCopy.add(pv);
}
}
// 标记该属性列表已经转换过了,下次再用就不需要重复转换
if (mpvs != null && !resolveNecessary) {
mpvs.setConverted();
}
// 属性装配
bw.setPropertyValues(new MutablePropertyValues(deepCopy));
}
propertyName的形式以及存取器propertyAccessor
在继续分析源码前,我们先来了解下属性装配的一些设计逻辑。在下面这个类中,存在三种成员属性。
public class User {
// 普通属性
private String name;
private Integer age;
// 对象属性
private Address address = new Address();
// 集合属性
private List<String> hobbies = new ArrayList<>();
}
相应地,spring-bean 支持三种 propertyName 的格式:
// 普通形式的propertyName
rootBeanDefinition.getPropertyValues().add("name", "zzs001");
// 嵌套对象形式的propertyName,可以一直嵌套下去,例如:user.address.name
rootBeanDefinition.getPropertyValues().add("address.name", "波斯尼亚和黑塞哥维那");
// 索引形式的propertyName
rootBeanDefinition.getPropertyValues().add("hobbies[0]", "发呆");
那么,针对上面三种形式的 propertyName,spring-bean 如何存取对象的属性呢?
在 spring-bean 中,使用org.springframework.beans.PropertyAccessor这个类来实现对成员属性的存取。
public interface PropertyAccessor {
boolean isReadableProperty(String propertyName);
boolean isWritableProperty(String propertyName);
Object getPropertyValue(String propertyName) throws BeansException;
void setPropertyValue(String propertyName, Object value) throws BeansException;
}
每个需要装配的对象都有一个对应的 propertyAccessor。需要注意一点,propertyAccessor 只能存取当前绑定对象的“一级属性”,例如,user 的 propertyAccessor 只能装配address=new Address("波斯尼亚和黑塞哥维那"),而不能装配address.name=波斯尼亚和黑塞哥维那。如果要存取 address.name,需要获取到 address 的 propertyAccessor 来进行存取。这里还是用一段代码来解释吧,后面的源码本质上也差不多。
// BeanWrapperImpl是`PropertyAccessor`,所以bw可以看成是user的存取器
BeanWrapperImpl bw = new BeanWrapperImpl();
bw.setBeanInstance(new User());
// 赋值name属性需要用到的存取器,nestedPa01 == bw
AbstractNestablePropertyAccessor nestedPa01 = bw.getPropertyAccessorForPropertyPath("name");
nestedPa.setPropertyValue("name", "zzs001");
assertEquals(bw, nestedPa01);
// 赋值address.name属性需要用到的存取器,nestedPa01 != bw
AbstractNestablePropertyAccessor nestedPa02 = bw.getPropertyAccessorForPropertyPath("address.name");
nestedPa.setPropertyValue("name", "波斯尼亚和黑塞哥维那");
assertEquals(bw, nestedPa02);
至于索引形式的处理,其实和普通属性差不多。我就不展开了。
那么,我们继续看源码吧。
给属性装配值
进入AbstractNestablePropertyAccessor.setPropertyValue(String,Object)。这个方法做了这么一件事:给属性装配值。现在看看这段代码是不是和我们的例子差不多呢?
public void setPropertyValue(String propertyName, @Nullable Object value) throws BeansException {
// 获取propertyName对应的存取器
// 如果缓存里有的话,将复用
AbstractNestablePropertyAccessor nestedPa = getPropertyAccessorForPropertyPath(propertyName);
// 创建PropertyTokenHolder对象,这里将解析“索引形式”的propertyName
PropertyTokenHolder tokens = getPropertyNameTokens(getFinalPath(nestedPa, propertyName));
// 使用存取器进行赋值操作
nestedPa.setPropertyValue(tokens, new PropertyValue(propertyName, value));
}
那么,属性装配部分的分析就点到为止吧。
最后补充
以上简单地分析了 spring-bean 的源码。针对 getBean 的过程,本文未展开的内容包括:
- 创建多例 bean;
- 无参构造实例化;
- 属性装配中,根据自动装配类型添加待装配属性;
- bean 的初始化。
后面有空我再做补充吧,感兴趣的读者也可以自行分析。另外,以上内容如有错误,欢迎指正。
最后,感谢阅读。
2021-09-27更改
相关源码请移步: spring-beans
本文为原创文章,转载请附上原文出处链接:https://www.cnblogs.com/ZhangZiSheng001/p/13196228.html
