Mybatis源码详解系列(一)--持久层框架解决了什么及如何使用Mybatis
 mybatis 是一个持久层框架,它让我们可以方便、解耦地操作数据库。 相比 hibernate,mybatis 在国内更受欢迎,而且 mybatis 更面向数据库,可以灵活地对 sql 语句进行优化。
针对 mybatis 的分析,我会拆分成使用、配置、源码、生成器等部分,都放在 Mybatis 这个系列里,内容将持续更新。这篇博客是系列里的第一篇文章,将从下面两个问题展开 :
1. 为什么要用持久层框架?
2. 如何使用 mybatis?
mybatis 是一个持久层框架,它让我们可以方便、解耦地操作数据库。 相比 hibernate,mybatis 在国内更受欢迎,而且 mybatis 更面向数据库,可以灵活地对 sql 语句进行优化。
针对 mybatis 的分析,我会拆分成使用、配置、源码、生成器等部分,都放在 Mybatis 这个系列里,内容将持续更新。这篇博客是系列里的第一篇文章,将从下面两个问题展开 :
1. 为什么要用持久层框架?
2. 如何使用 mybatis?
简介
mybatis 是一个持久层框架,它让我们可以方便、解耦地操作数据库。 相比 hibernate,mybatis 在国内更受欢迎,而且 mybatis 更面向数据库,可以灵活地对 sql 语句进行优化。
针对 mybatis 的分析,我会拆分成使用、配置、源码、生成器等部分,都放在 Mybatis 这个系列里,内容将持续更新。这篇博客是系列里的第一篇文章,将从下面两个问题展开 :
-
为什么要用持久层框架?
-
如何使用 mybatis?
为什么要用持久层框架
在分析如何用之前,我们先来分析为什么要用?和往常一样,我们只会回答为什么要使用某种类库,而不会去回答为什么要使用某个具体的类库。说来惭愧,用了这么久 mybatis,我从来没有认真思考过这个问题,要不是写这篇博客的缘故,估计永远也不会思考。
我们与数据库的交互过程
首先,先从一张图开始,这张图大致描述了我们与数据库交互的过程。这里我结合查询员工的例子来说明。
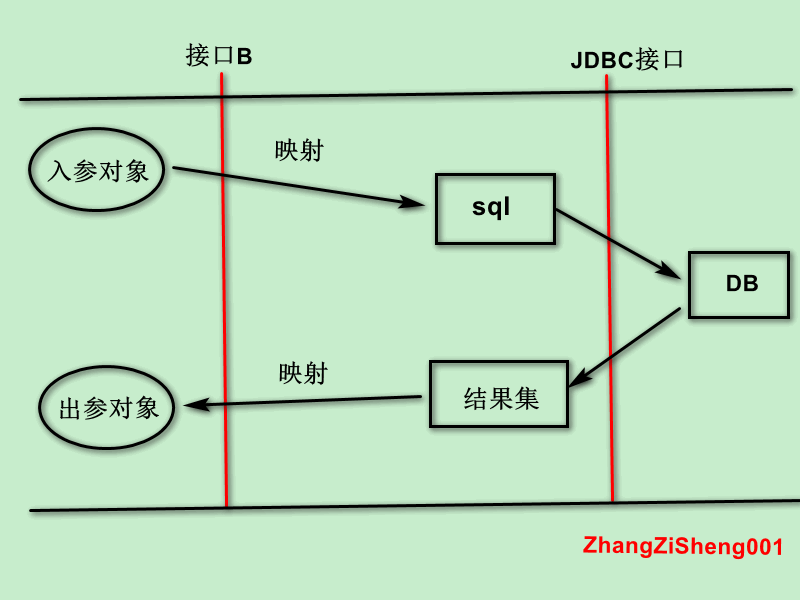
根据分层抽象的思想,接口 B 不应该对外暴露任何的数据库细节,从调用者的角度看,我们只需要想着从一堆员工里找出符合条件的那几个就行,而不需要去考虑从哪查、如何查。接口示例如下:
List<Employee> queryListByNameAndGenderAndPhone(String name, Integer gender, String phone);
而在接口 B 里面,逻辑就比较复杂了,需要先将入参对象映射到 sql 里面,然后执行 sql,最后将结果集映射为出参对象。那么,这段逻辑应该怎么实现呢?
使用JDBC实现接口B
在没有持久层框架之前,最直接的做法就是用 JDBC API 来实现接口 B 的逻辑。代码大致如下:
public List<Employee> queryListByNameAndGenderAndPhone(String name, Integer gender, String phone) throws SQLException{
String sql = "select * from demo_employee where name = ? and gender = ? and phone = ? and deleted = 0";
// 获得连接、语句对象
PreparedStatement statement = connection.prepareStatement(sql);
// 入参映射
statement.setString(1, name);
statement.setInt(2, gender);
statement.setString(3, phone);
// 执行sql
ResultSet resultSet = statement.executeQuery();
// 出参映射
List<Employee> employees = new ArrayList<>();
while(resultSet.next()) {
Employee employee = new Employee();
employee.setId(resultSet.getString("id"));
employee.setName(resultSet.getString("name"));
employee.setGender(resultSet.getInt("gender"));
employee.setNo(resultSet.getString("no"));
employee.setAddress(resultSet.getString("address"));
employee.setDeleted(resultSet.getInt("deleted"));
employee.setDepartmentId(resultSet.getString("department_id"));
employee.setPassword(resultSet.getString("password"));
employee.setPhone(resultSet.getString("phone"));
employee.setStatus(resultSet.getInt("status"));
employee.setGmtCreate(resultSet.getDate("gmt_create"));
employee.setGmtModified(resultSet.getDate("gmt_modified"));
employees.add(employee);
}
// 释放资源
resultSet.close();
statement.close();
return employees;
}
我们会发现,直接使用 JDBC API 操作数据库还是比较繁琐,尤其是出入参的映射。如果每个持久层方法都这么搞,麻烦程度可想而知。出于程序员的本能,我们自然会想要优化它。当我们尝试从这类代码中抽取共性时,将会发现一些规律:查询员工也好,查询部门也好,它们用的 JDBC 代码几乎是一模一样的,要说不一样的地方,只有三个:
- 我们要执行什么 sql;
- 入参对象如何映射进 sql;
- 结果集如何映射成出参对象。
基于以上思考,这里提供其中一种优化思路:我们可以将 JDBC 代码抽取为公共方法,而“三个不同“采用单独配置实现。mybatis、hibernate 就是按照这种思路设计的。
其实,分析到这一步,我们已经得到了答案,使用持久层框架本质上就是为了更简单地实现接口 B。
使用mybatis实现接口B
接下来,我们看看 mybatis 是如何实现上述思路的。
使用 mybatis 实现 B 接口时,我们不需要写任何 JDBC 代码,甚至 B 接口的实现类都不需要我们自己写,只需要把“三个不同“配置好就行(xml 或注解配置),mybatis 会自动帮我们生成 B 接口的实现类。
以下是 mybatis 注解版的员工查询,两个注解就完成了“三个不同”的配置,除此之外,我不需要增加任何多余代码,是不是相当方便呢?
@Select("select * from demo_employee where name = #{name} and gender = #{gender} and phone = #{phone} and deleted = 0")
@ResultType(Employee.class)
List<Employee> queryListByNameAndGenderAndPhone(@Param("name") String name, @Param("gender") Integer gender, @Param("phone") String phone);
所以,使用持久层框架,可以让我们更方便、更解耦地操作数据库。任何的持久层框架,都不应该脱离这个核心。
搞清楚为什么要用之后,我们接着分析如何用。
项目环境
这里先介绍下项目的一些“基础设施”。为了让 mybatis 更加纯粹,本项目不会引入任何的依赖注入框架,将使用 mybatis 原生的 API。
工程环境
JDK:1.8.0_231
maven:3.6.3
IDE:Spring Tool Suites4 for Eclipse 4.12 (装有 Mybatipse 插件)
mysql:5.7.28
依赖引入
mybatis 有自带的数据源,但实际项目中建议还是引入第三方的比较好。这里使用 HikariCP。
<!-- Mybatis -->
<dependency>
<groupId>org.Mybatis</groupId>
<artifactId>Mybatis</artifactId>
<version>3.5.4</version>
</dependency>
<!-- 数据库驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
<!-- 数据库连接池 -->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>2.6.1</version>
</dependency>
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
数据库脚本
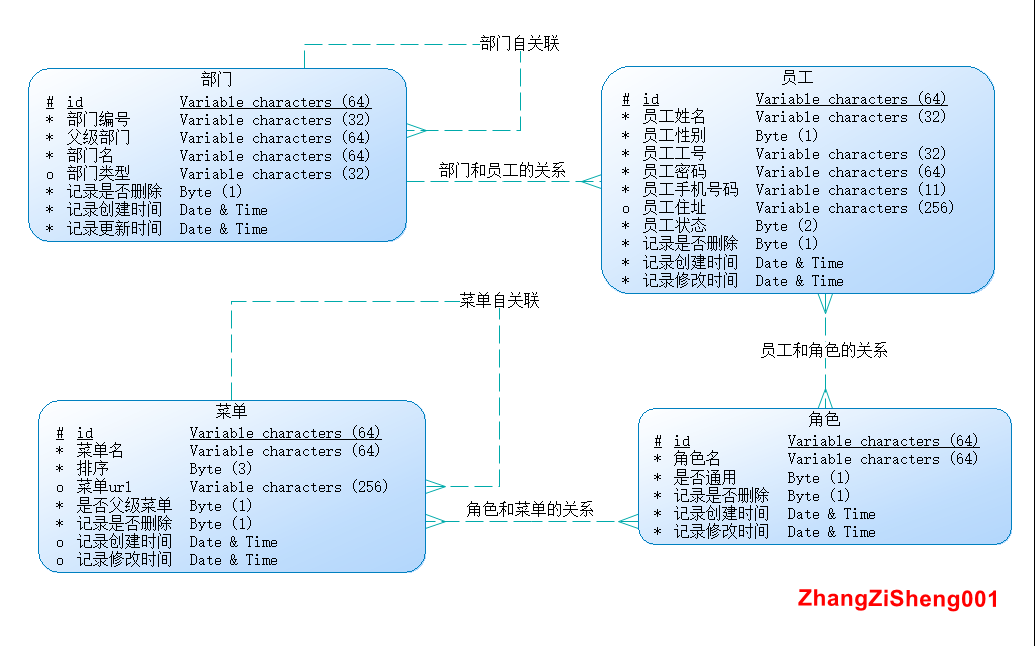
本项目的数据库概念模型如下。为了尽可能模拟出更多的场景,本项目给出的表会比较复杂,涉及到 4 张主表和 2 张中间表,具体的 sql 脚本也提供好了(脚本路径):
入门例子
入门例子需要实现:从数据库中查询出符合条件的员工。
配置configuration xml文件
首先,需要在 classpath (一般为 src\main\resources 目录)下新增 mybatis 的主配置文件 mybatis-config.xml,具体文件名无要求,随便取都行。配置文件的层级结构如下(注意:配置文件里的 xml 节点必须严格按以下顺序写,不然会报SAXParseException ):
configuration(配置)
- properties(全局参数)
- settings(全局行为配置)
- typeAliases(类型别名)
- typeHandlers(类型处理器)
- objectFactory(对象工厂)
- plugins(插件)
- environments(环境配置)
- environment(环境变量)
- transactionManager(事务管理器)
- dataSource(数据源)
- environment(环境变量)
- databaseIdProvider(数据库厂商标识)
- mappers(映射器)
作为入门例子,这里只进行了简单的配置(实际项目中其实也差不多,一般也只会用到加粗的几个节点)。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//Mybatis.org//DTD Config 3.0//EN"
"http://Mybatis.org/dtd/Mybatis-3-config.dtd">
<configuration>
<!-- 全局配置 -->
<settings>
<setting name="mapUnderscoreToCamelCase" value="true" />
</settings>
<!-- 配置环境:可以有多个 -->
<environments default="development">
<environment id="development">
<!-- 使用jdbc事务管理 -->
<transactionManager type="JDBC"/>
<!-- 数据源 -->
<!-- <dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}" />
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
</dataSource> -->
<dataSource type="cn.zzs.mybatis.factory.HikariDataSourceFactory" />
</environment>
</environments>
<!-- 映射器 -->
<mappers>
<package name="cn.zzs.mybatis.mapper"/>
</mappers>
</configuration>
以上配置作用如下:
- settings:一些影响 mybatis 行为的全局配置。例如,上面配置了 mapUnderscoreToCamelCase 为 true,在进行结果集映射时,只要对象字段和数据库字段之间遵循驼峰命名,mybatis 就能自动将它们映射好,而不需要我们手动配置映射。可配置参数见
org.apache.ibatis.builder.xml.XMLConfigBuilder.settingsElement(Properties)。 - environments:环境配置。这里简单说下 dataSource,如果使用 mybatis 自带的数据源,则直接配置数据源参数就行,如果引入第三方数据源,则需要配置你自己重写的
org.apache.ibatis.datasource.DataSourceFactory实现类。建议使用第三方数据源。 - mappers:其实就是告诉 mybatis 你的 Mapper 接口和 Mapper xml 文件放在哪里。这里需要注意下,如果我们把 Mapper 接口放在 src/main/java 下的 cn.zzs.mybatis.mapper,那么 Mapper xml 文件就应该放在 src\main\resources 下的 cn\zzs\mybatis\mapper。当然,你也可以把 Mapper xml 文件放在 src/main/java 下的 cn.zzs.mybatis.mapper(不建议),这种情况你就需要在 pom.xml 文件中额外增加以下配置。事实上,你怎么骚操作都可以,只要保证项目编译打包后 Mapper 接口和 xml 文件在你指定的路径下就行。
<build>
<resources>
<resource>
<directory>src/main/java</directory>
<filtering>false</filtering>
<includes>
<include>**/mapper/*.xml</include>
</includes>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**</include>
</includes>
</resource>
</resources>
</build>
创建Mapper接口
然后,我们需要在指定的包下创建好 EmployeeMapper 接口。上面的配置文件中,我们已经指定 Mapper 接口放在cn.zzs.Mybatis.mapper包下面,所以要保持一致才行。这里的@Param用来给入参配置别名。
public interface EmployeeMapper {
List<Employee> queryListByNameAndGenderAndPhone(@Param("name") String name, @Param("gender") Integer gender, @Param("phone") String phone);
}
配置mapper xml文件
接着,我们需要在指定路径下创建好 EmployeeMapper.xml 文件。EmployeeMapper.xml 只有很少的几个顶级元素:
cache– 该命名空间的缓存配置。cache-ref– 引用其它命名空间的缓存配置。resultMap– 描述如何将结果集映射为出参对象。parameterMap– 此元素已被废弃,并可能在将来被移除!sql– 可被其它语句引用的可重用语句块。insert– 映射插入语句。update– 映射更新语句。delete– 映射删除语句。select– 映射查询语句。
作为入门例子,这里只给出了简单的配置。其中,select 节点中配置了 queryListByNameAndGenderAndPhone 方法的“三个不同”,即需要执行的 sql、入参映射和出参映射。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.zzs.mybatis.mapper.EmployeeMapper">
<select id="queryListByNameAndGenderAndPhone" parameterType="map" resultType="cn.zzs.mybatis.entity.Employee">
select * from demo_employee where name = #{name} and gender = #{gender} and phone = #{phone} and deleted = 0
</select>
</mapper>
在本例中,我们指定了把结果集映射为Employee,通常情况下,只要对象字段和数据库字段遵循驼峰命名,都能自动映射成功。但是,总会有例外嘛,如果我的字段命名不遵循驼峰命名怎么办?这里我给出了两种可选方案:
<!-- 特殊字段的映射方法1:resultMap -->
<resultMap id ="BaseResultMap" type = "cn.zzs.mybatis.entity.Employee">
<result column="gmt_create" property="create" />
</resultMap>
<select id="queryListByNameAndGenderAndPhone" parameterType="map" resultMap="BaseResultMap">
select * from demo_employee where name = #{name} and gender = #{gender} and phone = #{phone} and deleted = 0
</select>
<!-- 特殊字段的映射方法2:as -->
<select id="queryListByNameAndGenderAndPhone" parameterType="map" resultType="cn.zzs.mybatis.entity.Employee">
select *, gmt_create as `create` from demo_employee where name = #{name} and gender = #{gender} and phone = #{phone} and deleted = 0
</select>
注意下参数符号 #{name}, 它告诉 mybatis 创建一个预处理语句(PreparedStatement)参数,在 JDBC 中,这样的一个参数在 SQL 中会由一个“?”来标识,并被传递到一个新的预处理语句中。不过有时你就是想直接在 SQL 语句中直接插入一个不转义的字符串。 这时候你可以使用 “$” 字符:
ORDER BY ${columnName}
编写测试类
在以下代码中,存在四个主要对象:
SqlSessionFactoryBuilder:一旦创建了 SqlSessionFactory,就不再需要它了,因此 SqlSessionFactoryBuilder 实例的最佳作用域是方法作用域。SqlSessionFactory:一旦被创建就应该在应用的运行期间一直存在,没有任何理由丢弃它或重新创建另一个实例, 因此 SqlSessionFactory 的最佳作用域是应用作用域。SqlSession:每个线程都应该有它自己的 SqlSession 实例。SqlSession 实例不是线程安全的,因此不能被共享,所以它的最佳的作用域是请求或方法作用域。 SqlSession 的作用类似于 JDBC 的 Connection ,使用完后必须 close。EmployeeMapper:默认情况下,因为 EmployeeMapper 和 SqlSession 绑定在一起,所以,EmployeeMapper 也是线程不安全的。有的人可能会问,既然 EmployeeMapper 是线程不安全的,那为什么 spring 把它作为单例使用?其实并不矛盾,EmployeeMapper 是否线程安全取决于 SqlSession,而 spring 中使用的 SqlSession 实现类是线程安全的,原理也并不复杂,具体见org.mybatis.spring.SqlSessionTemplate。
public class EmployeeMapperTest {
@Test
public void testSample() throws SQLException {
// 加载配置文件
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
// 获取sqlSession
// 第一种获取sqlSession方法:同一线程每次获取都是同一个sqlSession
/*SqlSessionManager sqlSessionManager = SqlSessionManager.newInstance(inputStream);
SqlSession sqlSession = sqlSessionManager.openSession();*/
// 第二种获取sqlSession方法:同一线程每次获取都是不同的sqlSession
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
// 获取Mapper代理类
EmployeeMapper employeeMapper = sqlSession.getMapper(EmployeeMapper.class);
// 执行查询
List<Employee> employees = employeeMapper.queryListByNameAndGenderAndPhone("zzs001", 1, "18826****41");
// 测试
assertTrue(!CollectionUtils.isEmpty(employees));
employees.stream().forEach(System.err::println);
// 释放资源
sqlSession.close();
}
}
运行测试
运行上面的方法,会在控制台输出了 sql 和匹配的员工数据。
==> Preparing: select * from demo_employee where name = ? and gender = ? and phone = ? and deleted = 0
==> Parameters: zzs001(String), 1(Integer), 18826****41(String)
<== Total: 1
Employee(id=cc6b08506cdb11ea802000fffc35d9fa, name=zzs001, gender=1, no=zzs001, password=666666, phone=18826****41, address=北京, status=1, deleted=0, departmentId=65684a126cd811ea802000fffc35d9fa, gmtCreate=Wed Sep 04 21:48:28 CST 2019, gmtModified=Wed Mar 25 10:44:51 CST 2020)
高级条件查询
在实际项目中,我们经常需要用到高级条件查询。这类查询和入门例子的查询最大的不同在于,高级条件查询的某个条件可能为空,所以,在配置入参映射时需要进行判断。mybatis 提供了丰富的动态 sql 语法以支持此类入参映射,如下:
<select id = "queryByCondition" parameterType="cn.zzs.mybatis.condition.EmployeeCondition" resultType="cn.zzs.mybatis.entity.Employee">
select e.* from demo_employee e where 1 = 1
<!-- 一般条件 -->
<if test="con.deleted != null">
and e.deleted = #{con.deleted}
</if>
<!-- 字符类条件 -->
<if test="con.name != null and con.name != ''">
and e.name = #{con.name}
</if>
<!-- 大于类条件 -->
<if test="con.createStart != null">
and e.gmt_create > #{con.createStart}
</if>
<!-- 集合类条件 -->
<if test="con.phoneInclude != null and con.phoneInclude.size() > 0">
and e.phone in
<foreach collection="con.phoneInclude" index="index" item="item" open="(" separator="," close=")">
#{item}
</foreach>
</if>
</select>
多表查询
大多数情况下,我们对外提供的查询员工接口,只是返回员工的字段是远远不够的,还需要返回员工关联对象的字段,例如,员工所属部门、员工管理的菜单等等。
这时,我们的查询将涉及到多个表,针对这种情况,我认为有三种解决方案:
- 手动分表查询;
- 自动分表查询;
- 联表查询。
手动分表查询
手动分表查询代码如下。顾名思义,我需要在代码中单独查每个表,再将查到的数据组装起来。
@Test
public void testMultiTableQuery1() throws Exception {
// 先查员工
Employee employee = employeeMapper.queryById("cc6b08506cdb11ea802000fffc35d9fe");
// 再查部门
Department department = departmentMapper.queryById(employee.getDepartmentId());
// 组装数据
EmployeeVO employeeVO = new EmployeeVO();
BeanUtils.copyProperties(employeeVO, employee);
employeeVO.setDepartmentName(department.getName());
employeeVO.setDepartmentNo(department.getNo());
// 测试
System.err.println(employeeVO);
}
这种方案的优点在于;
- 如果后期多表分库,代码无需改动;
- Mapper 接口中只要提供通用的基本方法就行,无需增加任何个性化方法;
- 在应对各种场景的不同 VO 时,这种方案非常灵活。
至于缺点嘛,就是会遇到N+1 查询问题,列表查询尤甚。
自动分表查询
自动分表查询的代码如下。与手动分表查询不同,这里的查部门,不是我们自己手动查,而是由 mybatis 帮我们查。
@Test
public void testMultiTableQuery2() throws Exception {
// 查员工(部门也会一起查)
Employee employee = employeeMapper.queryById("cc6b08506cdb11ea802000fffc35d9fe");
// 取出部门对象
Department department = employee.getDepartment();
// 组装数据
EmployeeVO employeeVO = new EmployeeVO();
BeanUtils.copyProperties(employeeVO, employee);
employeeVO.setDepartmentName(department.getName());
employeeVO.setDepartmentNo(department.getNo());
// 测试
System.err.println(employeeVO);
}
与手动分表查询不同,这里第一步返回的 employee 是一个非常“完整”的对象,它包括部门、角色等,如果你使用过 hibernate,对此应该并不陌生。所以,在某种程度上,这种方案更加面向对象。为了查出这样一个“完整”的对象,我们需要进行如下配置:
<resultMap id = "EmployResultMap" type = "cn.zzs.mybatis.entity.Employee">
<result column="id" property="id"/>
<result column="department_id" property="departmentId"/>
<association
property="department"
column="department_id"
select="cn.zzs.mybatis.mapper.DepartmentMapper.queryById"/>
<collection
property="roles"
column="id"
select="cn.zzs.mybatis.mapper.RoleMapper.queryByEmployeeId"
/>
</resultMap>
<!-- 多表查询1和2 -->
<select id = "queryById" parameterType = "string" resultMap = "EmployResultMap">
select e.*
from demo_employee e
where e.id = #{value}
</select>
需要注意的是,自动分表查询最好结合延迟加载使用,即当调用 getDepartment 时才触发查部门的动作。因为不是每种场景都需要查出那么“完整”的对象,延迟加载很好地避免不必要的性能开销。延迟加载的配置如下(默认不开启):
<!-- 全局配置 -->
<settings>
<setting name="lazyLoadingEnabled" value="true" />
</settings>
和手动多表查询一样,自动分表查询不需要在 Mapper 中增加个性化方法,但是呢,因为耦合多表的关联,所以,如果后期多表分库,改动就比较大了。而且,在应对各种场景的 VO 时,这种方案灵活性要比手动多表查询稍差。
当然,这种方案也有N+1查询问题。
联表查询
联表查询代码如下。这种方案不需要分表查询,多表数据一次查出。
@Test
public void testMultiTableQuery3() {
// 执行查询
EmployeeVO employeeVO = employeeMapper.queryVOById("cc6b08506cdb11ea802000fffc35d9fe");
// 测试
System.err.println(employeeVO);
}
具体做法就是采用联表查询,xml 配置如下。
<select id = "queryVOById" parameterType = "string" resultType = "cn.zzs.mybatis.vo.EmployeeVO">
select e.*, d.name as departmentName, d.no as departmentNo
from demo_employee e left join demo_department d on e.department_id = d.id
where e.id = #{value}
</select>
因为不需要分表查询,所以联表查询可以避免N+1查询问题,所以,相比前两种方案,它的性能一般是最好的。但是呢,联表查询严重耦合了多表的关联,如果后期多表分库,改动会比较大。而且,这种方案的灵活性非常差,它几乎需要在 Mapper 接口中为每个 VO 提供个性化方法。
以上三种方案,各有优缺点,实际项目中采用哪种,需要结合多表分库、性能等因素具体分析。
分页查询
最后再简单说下分页查询吧。其实,mybatis 提供了RowBounds来支持分页,但是呢,这种分页不是数据库分页,而是应用内存分页,非常的不友好,所以,分页查询还是得另辟蹊径。
引入插件依赖
本项目使用 pagehelper 插件来实现分页,首先,我们需要在 pom.xml 文件中增加以下依赖。
<!-- 分页插件 -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.1.10</version>
</dependency>
修改 mybatis 主配置文件
然后,在 mybatis 主配置文件中增加 plugins 元素,并配置分页插件。
<!-- 配置插件 -->
<plugins>
<!-- 分页插件 -->
<plugin interceptor="com.github.pagehelper.PageInterceptor"/>
</plugins>
编写测试方法
这里调用 startPage 相当于告诉分页插件对**本线程的下一个列表查询 sql **进行分页处理。
@Test
public void testPageQuery() {
// 构建条件
EmployeeCondition con = new EmployeeCondition();
con.setDeleted(0);
// 设置分页信息
PageHelper.startPage(0, 3);
// 执行查询
List<Employee> employees = employeeMapper.queryByCondition(con);
// 遍历结果
employees.forEach(System.err::println);
// 封装分页模型
PageInfo<Employee> pageInfo = new PageInfo<>(employees);
// 取分页模型的数据
System.err.println("结果总数:" + pageInfo.getTotal());
}
测试
运行上面的方法,会在控制台输出了 sql 和匹配的员工数据。我们发现,这里竟然多了一句查数量的 sql,而且,列表查询的 sql 被嵌入了分页参数。到底是怎么做到的呢?这个问题等我们分析源码的时候再解答吧。
==> Preparing: SELECT count(0) FROM demo_employee e WHERE 1 = 1 AND e.deleted = ?
==> Parameters: 0(Integer)
<== Total: 1
==> Preparing: select e.id,e.`name`,e.gender,e.no,e.password,e.phone,e.address,e.status,e.deleted,e.department_id,e.gmt_create,e.gmt_modified from demo_employee e where 1 = 1 and e.deleted = ? LIMIT ?
==> Parameters: 0(Integer), 3(Integer)
<== Total: 3
Employee(id=2e18f6560b25473480af987141eccd02, name=zzs005, gender=1, no=zzs005, password=admin, phone=18826****41, address=广东, status=1, deleted=0, departmentId=94e2d2e56cd811ea802000fffc35d9fa, gmtCreate=Sat Mar 28 00:00:00 CST 2020, gmtModified=Sat Mar 28 00:00:00 CST 2020, department=null, roles=null)
Employee(id=cc6b08506cdb11ea802000fffc35d9fa, name=zzs001, gender=1, no=zzs001, password=666666, phone=18826****42, address=北京, status=1, deleted=0, departmentId=65684a126cd811ea802000fffc35d9fa, gmtCreate=Wed Sep 04 21:48:28 CST 2019, gmtModified=Wed Mar 25 10:44:51 CST 2020, department=null, roles=null)
Employee(id=cc6b08506cdb11ea802000fffc35d9fb, name=zzs002, gender=1, no=zzs002, password=123456, phone=18826****43, address=广东, status=1, deleted=0, departmentId=65684a126cd811ea802000fffc35d9fa, gmtCreate=Thu Aug 01 21:49:43 CST 2019, gmtModified=Mon Sep 02 21:49:49 CST 2019, department=null, roles=null)
结果总数:9
结语
以上基本讲完为什么要使用持久层框架以及如何使用 mybatis。后续发现其他有趣的地方再做补充,也欢迎大家指正不足的地方。
最后,感谢阅读。
参考资料
2021-09-29更改
相关源码请移步:mybatis-demo
本文为原创文章,转载请附上原文出处链接:https://www.cnblogs.com/ZhangZiSheng001/p/12603885.html
