源码详解系列(二) -- jdbc-mysql的使用和分析
 JDBC 规定了 java 应用应该如何连接和操作数据库,它是规范,而非实现,具体的实现由不同的数据库厂商提供。对我们来说,JDBC 有效地将我们的代码和具体的数据库实现解耦合,这是非常有好处的,例如,当我的数据库从 mysql 切换到 oracle 时,几乎不需要调整代码。
本文将详细介绍如何使用 JDBC,这里使用 MySQL Connector/J 8.0 作为具体实现。
JDBC 规定了 java 应用应该如何连接和操作数据库,它是规范,而非实现,具体的实现由不同的数据库厂商提供。对我们来说,JDBC 有效地将我们的代码和具体的数据库实现解耦合,这是非常有好处的,例如,当我的数据库从 mysql 切换到 oracle 时,几乎不需要调整代码。
本文将详细介绍如何使用 JDBC,这里使用 MySQL Connector/J 8.0 作为具体实现。
什么是 JDBC
JDBC 规定了 java 应用应该如何连接和操作数据库,它是规范,而非实现,具体的实现由不同的数据库厂商提供。对我们来说,JDBC 有效地将我们的代码和具体的数据库实现解耦合,这是非常有好处的,例如,当我的数据库从 mysql 切换到 oracle 时,几乎不需要调整代码。
本文将详细介绍如何使用 JDBC,这里使用 MySQL Connector/J 8.0 作为具体实现。
当然,本文只是作为学习用途,实际项目中,建议还是使用 mybatis、hibernate 等持久层框架。
几个重要的类
JDBC 的 API 中,我们只需要关注下面几个类即可。
| 类名 | 作用 |
|---|---|
DriverManager |
驱动管理器,用于管理驱动以及获取Connection对象 |
Connection |
与指定数据库的连接/会话,用于获取Statement对象、管理事务、获取数据库元数据等。下面的几个类都是在 Connection的基础上工作的 |
Statement |
静态 sql 执行对象 |
PreparedStatement |
预编译 sql 执行对象。相比Statement,它可以有效避免 sql 注入,同一 sql 多次执行时性能更好 |
CallableStatement |
过程执行对象。这个本文不讲 |
ResultSet |
结果集,用于封装查询结果集。支持对结果集进行写入操作,并同步到数据库 |
如何使用JDBC
需求
使用 JDBC 对 mysql 数据库的用户表进行增删改查等操作。
项目环境
本文使用的 MySQL Connector/J 8.0,它实现了 JDBC 4.2,要求 JDK 版本 1.8 及以上,允许的 mysql 版本为 5.6,5.7 和 8.0。
JDK:1.8.0_231
maven:3.6.3
IDE:ideaIC-2021.1.win
mysql driver:8.0.15
mysql:5.7.28
创建表和数据
这里简单地新建一张用户表,并初始化三行记录。
CREATE DATABASE `github_demo` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
USE `github_demo`;
DROP TABLE IF EXISTS `demo_user`;
CREATE TABLE `demo_user` (
`id` varchar(32) NOT NULL COMMENT '用户id',
`name` varchar(16) NOT NULL COMMENT '用户名',
`gender` tinyint(1) DEFAULT '0' COMMENT '性别',
`age` int(3) unsigned DEFAULT NULL COMMENT '用户年龄',
`gmt_create` timestamp NULL DEFAULT NULL COMMENT '记录创建时间',
`gmt_modified` timestamp NULL DEFAULT NULL COMMENT '记录最近修改时间',
`deleted` tinyint(1) DEFAULT '0' COMMENT '是否删除',
`phone` varchar(11) NOT NULL COMMENT '电话号码',
PRIMARY KEY (`id`),
KEY `idx_phone` (`phone`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
INSERT INTO `demo_user` (`id`, `name`, `gender`, `age`, `gmt_create`
, `gmt_modified`, `deleted`, `phone`)
VALUES ('11111111111111111111111111111111', 'zzs001', 0, 17, '2021-04-28 11:25:18'
, '2021-05-02 09:33:56', 0, '188******42'),
('4480067e571040089cb6b821fe94085a', 'zzf001', 0, 18, '2021-05-02 09:33:56'
, '2021-05-02 09:33:56', 0, '188******26'),
('678c5d2daf0c43d4b97e0633c8fc255d', 'zzs003', 0, 18, '2021-04-28 11:25:18'
, '2021-04-28 11:25:42', 0, '188******43'),
('8b9eb24b87b34092a1c4bb1ef06f26be', 'zzs002', 0, 18, '2021-04-28 11:25:18'
, '2021-04-28 11:25:42', 0, '188******41');
引入依赖
项目类型 Maven Project,打包方式 jar。
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- mysql驱动的jar包 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
获得Connection对象
这里的DriverManager创建Connection对象本质是调用了com.mysql.cj.jdbc.Driver,以前我们需要显式向DriverManager注册驱动,JDK6 之后就不需要了。而且,当我在项目中同时存在 mysql 驱动和 oracle 驱动时,DriverManager能够自动判断使用哪个驱动来获取连接(其实就是遍历所有驱动直到正确获取连接,按照 JDBC 规范,当发现 url 类型不匹配时,java.sql.Driver#connect应立即返回 null)。
MySQL Connector/J 的 url 支持的格式和参数非常多,例如,可以设置对等、设置主从节点等等,详见[Connection URL Syntax](MySQL :: MySQL Connector/J 8.0 Developer Guide :: 6.2 Connection URL Syntax)和[Configuration Properties](MySQL :: MySQL Connector/J 8.0 Developer Guide :: 6.3 Configuration Properties)。这里设置了字符编码和时区,不然会报错。
private static Connection createConnection() throws Exception {
String url = "jdbc:mysql://localhost:3306/github_demo?characterEncoding=utf8&serverTimezone=GMT%2B8";
String username = "root";
String password = "root";
// 注册驱动,JDK6后不需要再手动注册,DirverManager的静态代码块会使用SPI机制自动发现和注册
// Class.forName("com.mysql.cj.jdbc.Driver");
// 获得连接
connection = DriverManager.getConnection(url, username, password);
return conn;
}
新增用户
以下代码使用PreparedStatement来执行语句,相比Statement,它可以更好地避免 sql 注入,当同一个语句多次使用时,PreparedStatement的性能更好。
在入参的映射上,java 类型和 jdbc 类型的对应关系为[Java, JDBC, and MySQL Types](MySQL :: MySQL Connector/J 8.0 Developer Guide :: 6.5 Java, JDBC, and MySQL Types)。
注意,使用后记得释放资源,Connection和Statement都需要关闭掉。
private void save(User user) throws SQLException {
// 开启事务
connection.setAutoCommit(false);
// 创建PreparedStatement对象
String sql = "insert into demo_user (id,name,gender,age,gmt_create,gmt_modified,deleted,phone) values(?,?,?,?,?,?,?,?)";
PreparedStatement prepareStatement = connection.prepareStatement(sql);
// 入参的映射
prepareStatement.setString(1, user.getId());
prepareStatement.setString(2, user.getName());
prepareStatement.setInt(3, user.getGender());
prepareStatement.setInt(4, user.getAge());
prepareStatement.setTimestamp(5, Timestamp.from(Instant.now()));
prepareStatement.setTimestamp(6, Timestamp.from(Instant.now()));
prepareStatement.setInt(7, 0);
prepareStatement.setString(8, user.getPhone());
// 执行sql
int result = prepareStatement.executeUpdate();
System.err.println(result);
// 提交事务
connection.commit();
// 释放资源
prepareStatement.close();
connection.close();
}
查询用户
新增、更新、删除调用executeUpdate方法执行语句,而查询调用的是executeQuery,但有些情况下,我们区分不了当前的 sql 是否为查询语句,这个时候可以直接调用execute() ,当返回值为 true 时即为查询。
通过例子我们发现,纯粹使用 JDBC 操作数据库是非常繁琐的,我们需要手动地进行入参映射、出参映射、释放资源等等操作。所以,持久层框架还是挺重要的。
private List<User> findAll() throws SQLException {
// 创建PreparedStatement对象
String sql = "select * from demo_user where deleted = 0";
PreparedStatement prepareStatement = connection.prepareStatement(sql);
// 执行sql
ResultSet resultSet = prepareStatement.executeQuery();
// 出参的映射
List<User> list = new ArrayList<User>();
while (resultSet.next()) {
User user = new User();
user = new User();
user.setId(resultSet.getString(1));
user.setName(resultSet.getString(2));
user.setGender(resultSet.getInt(3));
user.setAge(resultSet.getInt(4));
user.setGmt_create(resultSet.getDate(5));
user.setGmt_modified(resultSet.getDate(6));
user.setDeleted(resultSet.getInt(7));
user.setPhone(resultSet.getString(8));
list.add(user);
}
// 释放资源
resultSet.close();
prepareStatement.close();
connection.close();
return list;
}
默认情况下,ResultSet只能向前读取,也就是说,它只能被遍历一次,这个特点有点像InputStream。按照 JDBC 规范,ResultSet支持随机读取,并且在读取结果集时,我们还可以进行写入操作。在createStatement或prepareStatement方法中指定结果集的滚动和读写类型即可。
public void testResultSet() throws Exception {
String sql = "select * from demo_user where deleted = 0 order by name desc";
/**
ResultSet的几个属性
结果集不能滚动(默认值)
int TYPE_FORWARD_ONLY = 1003;
结果集可以滚动,但对数据库变化不敏感
int TYPE_SCROLL_INSENSITIVE = 1004;
结果集可以滚动,且对数据库变化敏感
int TYPE_SCROLL_SENSITIVE = 1005;
结果集不能用于更新数据库(默认值)
int CONCUR_READ_ONLY = 1007;
结果集可以用于更新数据库
int CONCUR_UPDATABLE = 1008;
*/
Statement statement = connection.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_UPDATABLE);
// 执行查询并返回结果集
ResultSet rs = statement.executeQuery(sql);
// 测试插入数据
rs.moveToInsertRow();// 把游标移动到插入行,默认在最后一行。
rs.updateString(1, IdUtils.randomUUID());
rs.updateString(2, "李四");
rs.updateInt(3, 0);
rs.updateInt(4, 26);
rs.updateTimestamp(5, Timestamp.from(Instant.now()));
rs.updateTimestamp(6, Timestamp.from(Instant.now()));
rs.updateInt(7, 0);
rs.updateString(8, "188******49");
rs.insertRow();// 插入数据
rs.moveToCurrentRow();// 把游标移动到新插入数据所在行
// 测试删除数据
// rs.absolute(2);// 移动游标到第二行
// rs.deleteRow();// 删除第二行数据
// 遍历所有数据
while (rs.next()) {
// 测试更新数据
rs.updateTimestamp(6, Timestamp.from(Instant.now()));
rs.updateRow();
}
statement.close();
}
几个小问题
为什么Class.forName可以注册驱动?
首先,这里说的注册驱动,指的是将java.sql.Driver实现类(例如,mysql 的com.mysql.cj.jdbc.Driver)注册到DriverManager。
以前我们会使用Class.forName("com.mysql.cj.jdbc.Driver")来注册驱动。只是加载了这个类,为什么可以注册上去呢?
其实,原理非常简单。打开com.mysql.cj.jdbc.Driver时,我们可以看到,静态代码块中会执行注册驱动的方法,而加载这个类时,静态代码块会被执行。
static {
try {
//静态代码块中注册当前驱动
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
为什么JDK6后不需要Class.forName也能注册驱动?
上面的使用例子中,Class.forName("com.mysql.cj.jdbc.Driver");这一行代码被我注释掉了,但不影响我们使用。也就是说,在项目的其他地方com.mysql.cj.jdbc.Driver被注册上去了。
答案在DriverManager这个类里面。JDK6 之后,DriverManager增加了以下静态代码块,在这段静态代码块中,会通过查询系统参数(jdbc.drivers)和SPI机制两种方式去加载数据库驱动。
注意:考虑篇幅,以下代码经过修改,仅保留所需部分。
static {
loadInitialDrivers();
}
//这个方法通过两个方式加载所有数据库驱动:
//1. 查询系统参数jdbc.drivers获得数据驱动类名,多个以“:”分隔
//2. SPI机制
private static void loadInitialDrivers() {
// 通过系统参数jdbc.drivers读取数据库驱动的全路径名
String drivers;
try {
drivers = AccessController.doPrivileged(new PrivilegedAction<String>() {
public String run() {
return System.getProperty("jdbc.drivers");
}
});
} catch (Exception ex) {
drivers = null;
}
// 使用SPI机制加载驱动
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
// 读取META-INF/services/java.sql.Driver文件的类全路径名
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
// 实例化对象java.sql.Driver实现类
// 这个过程会自动注册
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
if (drivers == null || drivers.equals("")) {
return;
}
// 加载jdbc.drivers参数配置的实现类
String[] driversList = drivers.split(":");
for (String aDriver : driversList) {
try {
// 这个过程会自动注册
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
} catch (Exception ex) {
println("DriverManager.Initialize: load failed: " + ex);
}
}
}
补充:SPI机制本质上提供了一种服务发现机制,通过配置文件的方式,实现服务的自动装载,有利于解耦和面向接口编程。具体实现过程为:在项目的META-INF/services文件夹下放入以接口全路径名命名的文件,并在文件中加入实现类的全限定名,接着就可以通过ServiceLoder动态地加载实现类。详见使用SPI解耦你的实现类。
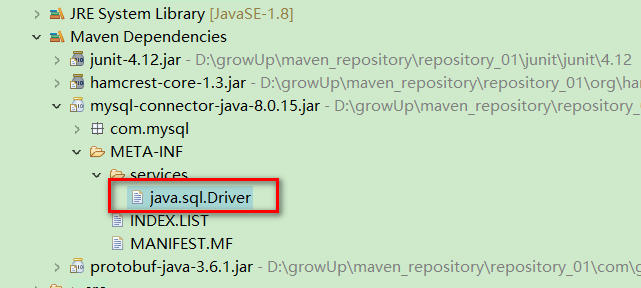
打开 mysql 的驱动包就可以看到一个java.sql.Driver文件,里面就是mysql驱动的全路径名。
以上简单讲完 JDBC 的内容,后面发现有趣的功能再作扩展。
最后,感谢阅读。
参考资料
MySQL Connector/J 8.0 Developer Guide
已停止更新
本文为原创文章,转载请附上原文出处链接:https://www.cnblogs.com/ZhangZiSheng001/p/11917307.html

