


中级软考知识点(自用侵删)

各75分,都超过45分则通过
https://blog.csdn.net/weixin_47872288/article/details/115868166
客观题
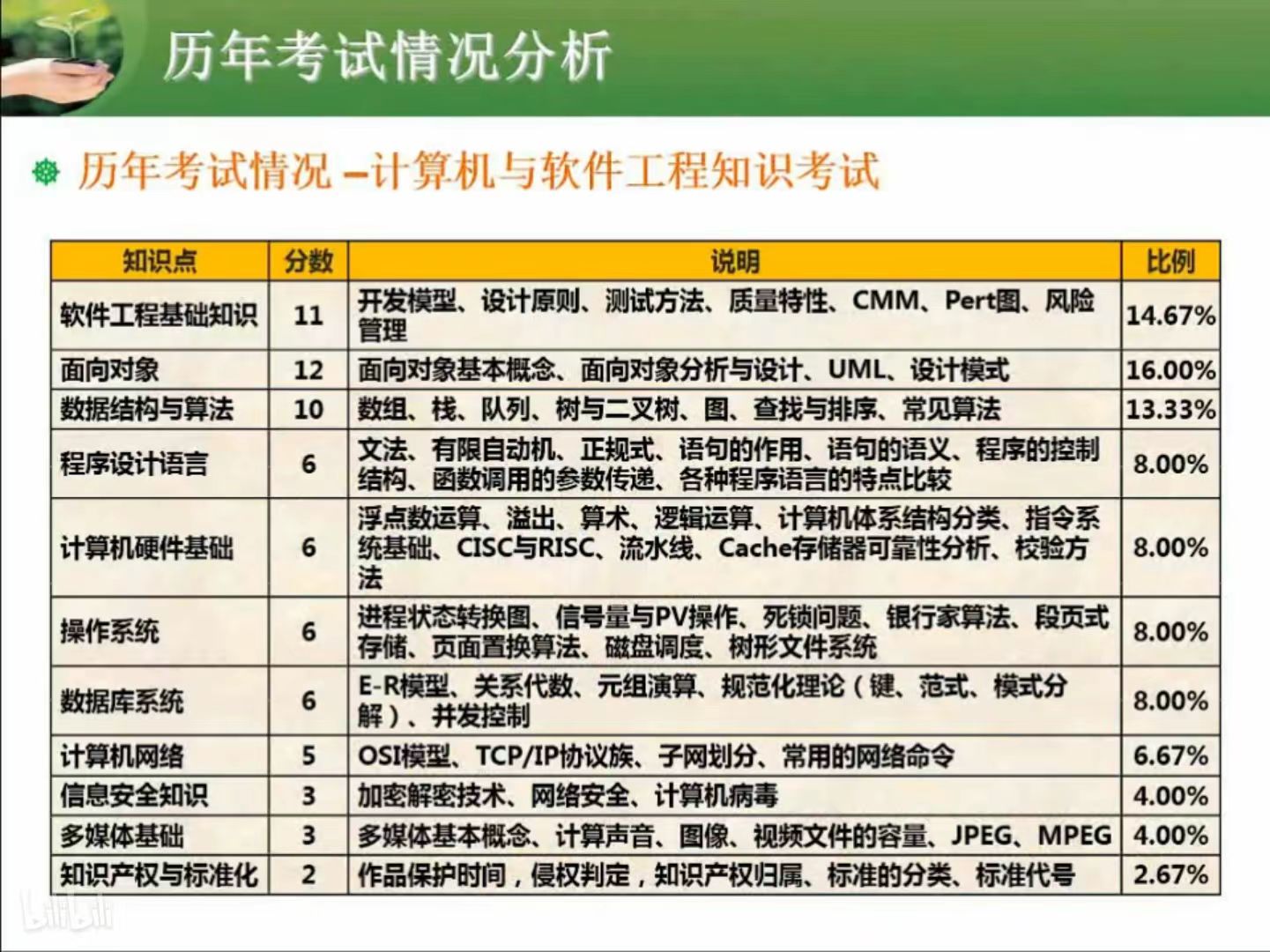
1. 计算机组成与体系结构(6)

1.1 数据表示
进制转换
- N转10:按权展开法
- 10转N:短除法
- 2进制转8进制、16进制:位数关系
原码反码补码移码
| 1 | -1 | 1-1(应该为0 | |
|---|---|---|---|
| 原码 | 0000 0001 | 1000 0001 | 1000 0010 |
| 反码 | 0000 0001 | 1111 1110 | 1111 1111 |
| 补码 | 0000 0001 | 1111 1111 | 0000 0000 |
| 移码 | 1000 0001 | 0111 1111 | 1000 0000 |
最高位用作符号位
原码:{范围:-(2^(n-1) - 1)~ 2^(n-1)-1}
反码:正数不变,负数符号位不变其他取反。{范围:-(2^(n-1) - 1)~ 2^(n-1)-1}
补码:正数不变,负数为反码+1。{范围:-(2^(n-1) )~ 2^(n-1)-1,如-128到128}
{-128}补 = {-127-1}补=1000 0000;其中{-127}补=1000 0001
模计算:{-128}补=模-|X|=1 0000 0000-1000 0000 = 1000 0000
移码:在进行浮点数计算中用作解码。在补码的基础上符号位取反
浮点数运算
浮点数表示:N=M*R^e
其中M称为尾数、e是指数、R是基数
运算步骤:对阶(把基数指数化成一样,一般把尾数化小)——>尾数计算——>结果格式化(小数点前留一位)
1.2 计算机结构

主机:CPU(运算器+控制器)+主储存器(内存)
- 运算器:算术逻辑单元ALU、累加寄存器AC、数据缓冲寄存器DR、状态条件寄存器PSW(常考,计算过程的标志位,如进位、溢出、中断状态信息等)
- 控制器:程序计数器PC、指令寄存器IR、指令译码器、时序部件
计算机体系结构分类——Flynn

依据指令流和数据流进行分类,根据单或多分为四种不同结构。
能够根据典型描述判断所属类型
CISC和RISC

- 复杂指令集计算机,Complex Instruction Set Computer。简称CISC:CISC是在计算机还没大规模使用时提出,指令是定制的,根据不同用户需求设计。
- 精简指令集计算机(RISC:Reduced Instruction Set Computer RISC):RISC泛用性更强。
流水线
概念
- 程序执行多条指令重叠进行操作的一种准并行处理实现技术。
- 各部件同时处理是针对不同指令而言,它们可同时为多条指令的不同部分进行工作,以提高各部件的利用率和指令的平均执行速度。
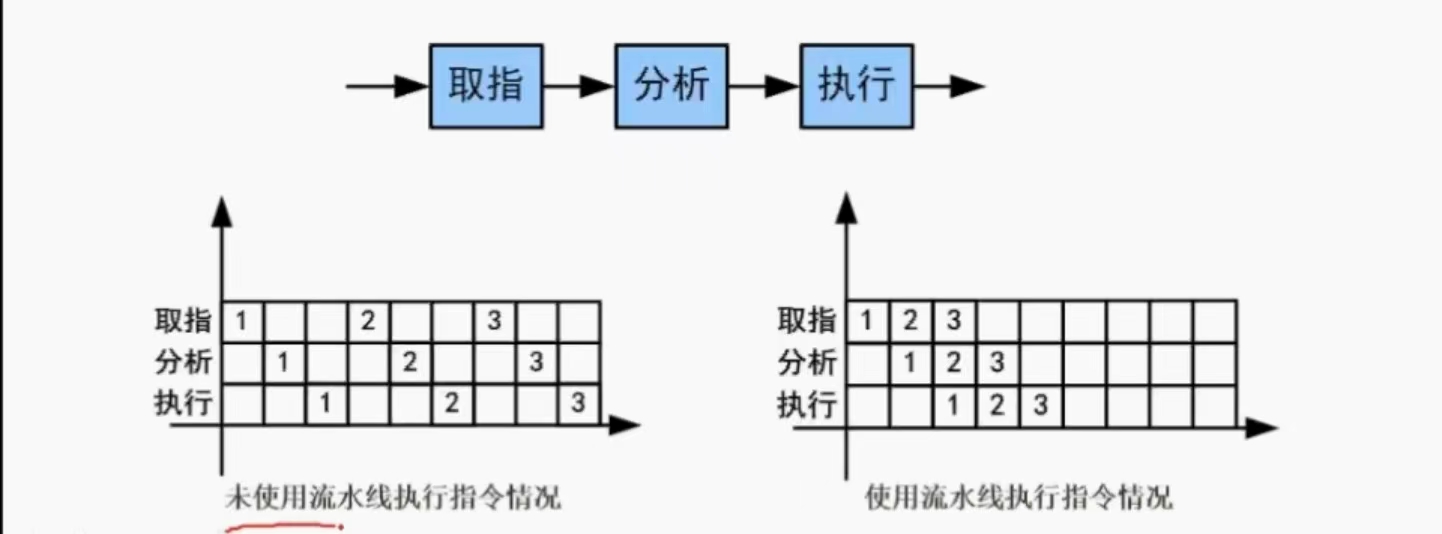
周期及执行时间计算
- 周期:流水线周期为执行时间最长的一段
- 计算公式:流水线执行时间计算公式为:
- 1条指令执行时间+(指令条数-1)*流水线周期
- 理论公式:(t1+t2+…tk)+(n-1)*△t
- 实践公式:(k+n-1)*△t (更接近工业,更工整)
eg:取值2ns,分析2ns,执行1ns,周期是多少,100条指令执行需要的时间。
周期:△t = Max{2ns,2ns,1ns} = 2ns
时间:(2ns+2ns+1ns)+99*2ns = 203ns
(3+100-1) *2ns = 204ns
吞吐率计算
吞吐率(Though Put rate,TP)是指在单位时间内流水线所完成的任务数量或输出的结果数量。基本公式如下:
TP= 指令条数/流水线执行时间{上题中为100/203}
最大吞吐量(理想状态,不考虑运行前后)=Lim(n—>max)n/(k+n-1)△t = 1/△t
加速比计算
流水线加速比:完成同一批任务,不适用流水线所用时间与使用流水线所用时间之比。越高越好
S = 不使用流水线用时/使用流水线用时{上题中为 500ns/203ns}
流水线效率:流水线设备的利用率。时空图上,流水线的效率定义为n个任务占用的时空区域k个流水段总的时空区之比

eg:假设一个任务分为四步,占用时间分别为△t、△t、△t、3△t。
效率为:4 * 6 △t /4*15△t = 2/5
计算机层次化存储结构

重点:整体结构、cache、内存
CPU中有运算器、控制器,二者当中存在寄存器使用(容量小速度快)。
cache高速缓存存储器,用来实现高效调用(减少CPU与内存的直接交互)。
不是所有存储结构都用寄存器是考虑到成本问题。
cache基本概念
功能:提高CPU数据输入输出效率,突破CPU与存储系统间数据传送宽带限制。
存储系统体系中,cache是访问速度最快的层次,使用cache改善性能的依据是程序的局部性原理。选最快,有寄存器寄存器否则cache。
将当下的高频访问指令和数据放入cache来避免不断访问内存。

局部性原理(时间局部性与空间局部性)

时间局部性:处理相关数据和程序时,有某个时段集中访问某些指令,或者说某一时段集中读取某些数据。
空间局部性:例如处理数组时,短时间内访问的路径地址是连续的。
工作集理论:进程运行时被频繁访问的页面集合。
随机存储器与只读存储器
-
随机存取存储器RAM:(如内存,断电后信息丢失)
- DRAM(动态RAM)
- SRAM(静态RAM)
-
只读存储器ROM:(如bios,掉电后信息不丢失)
- MROM(掩码ROM)
- PROM(Programmable ROM,一次可编程ROM)
- EPROM(可擦出PROM)
- 闪速存储器(Flash Memory,闪存)
编址:
容量小的芯片构成大的存储器,如两片8*4(8个地址空间,每个空间存4位)可以构成8 * 8或16 *4
计算地址单元数= 内存地址相减后+1

1k=2的十次方
磁盘工作原理

考点:磁盘运作原理、
磁盘:环形盘片。盘面用于保存数据,由专业的设备磁头进行读取。
平均等待时间为磁盘转一圈时间。注意:读取过程中磁盘一直匀速旋转。完整读完区域才能进行处理。
如图中,由于读取需要用时3ms,所以当R0存入存储器中时,磁盘继续转,等到读取完毕后磁头位于R2开头。
最长用时计算(前一位运行结束位置转一周再来到下一位位置):(周期33ms+处理3ms)*10(除了最后一个)+6(最后一个读和处理)=366ms

最短用时计算(修改各部分的布局):一周旋转33*2=66

计算机总线
根据所处位置的不同,分为三类:
- 内部总线
- 微机内部各个外围芯片与处理器之间的总线(芯片级)
- 系统总线
- 各个插件板和系统板之间的总线(如PCI接口、VGA的一些接口)
- 数据总线、地址总线、控制总线
- 数据总线:传输数据(32位指的是总线宽度是32bit位,一个周期传输数据是32个bit位)
- 地址总线:地址总线若是32位,它代表的地址空间是2的32次方。
- 例如32位电脑能处理的内存上限为4G。
- 控制总线:
*
- 外部总线
- 微机和外部设备的总线
串并联系统的可靠性计算
计算可靠性
- 串联系统
- 可靠率:各串联子模块可靠性相乘
- 失效率:各子系统失效率相加(不准确,仅在各系统每个失效率极低的情况下可用)

- 并联系统
- 并联某个子系统不失效系统就可以用
- 可靠率:1-所有子系统都失效的概率。
- 失效率:1-可靠度
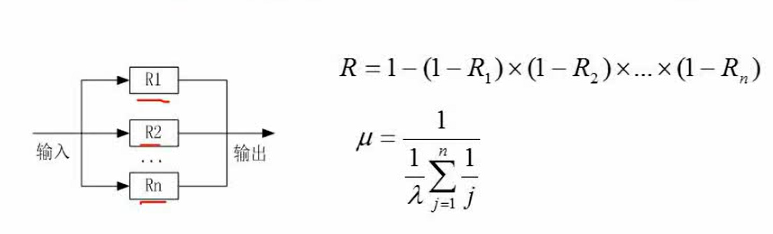
- 模冗余系统与混合系统
- 通过冗余部署,多个系统完成同一个任务,任务结果采用少数服从多数选择最终用作输出的结果,提高系统可靠性

串并联组合:

校验码的概念
差错控制
码距:整个编码系统中任意(所有)两个码字的最小距离。

码距和检错纠错的关系:
- 一个码组内为了检测e个误码,要求最小码距d应该满足:d>=e+1
- 一个码组内为了纠错t个误码,要求最小码距d应该满足:d>=2t+1
比如要检测一个误码,必须码距至少为2,纠错一个误码,码距至少为3
码距为1时,无法分辨传输的数据是被错误传输与否。大部分有误均假设仅改变了一个位的数据。
循环校验码(CRC)【可检错不能纠错】
模2除法是指在做除法运算过程中不计其进位的除法,不是用减法是做异或操作。
- 被除数为1则商为1,被除数为0则商为0;
- 余数去掉首位为新的被除数;
- 新的被除数以0开头,则除数变为全0,以1开头则除数不变;


编码后的数据能够与循环校验码的生成多项式相除余数为零。接收后相除余数非零说明传输出错。
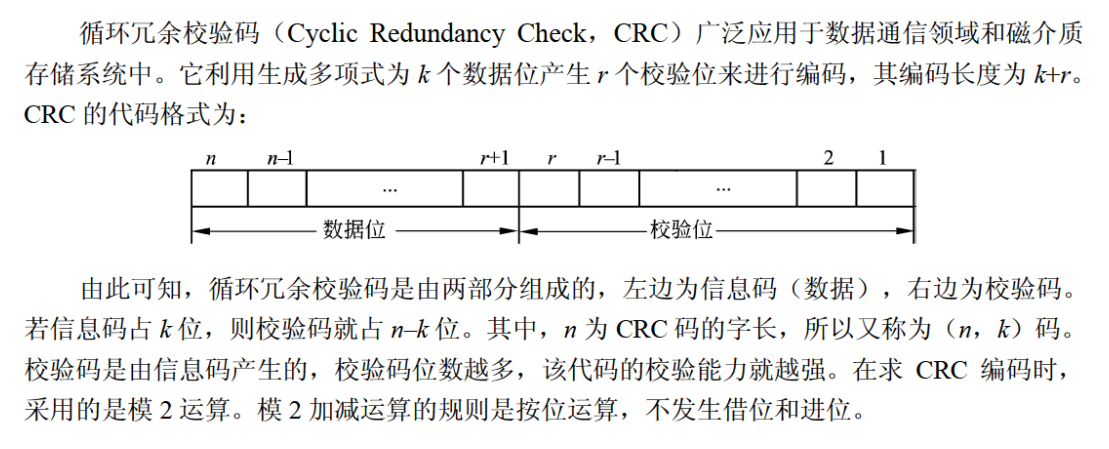

生成多项式的长度N减一,在原始报文后加上(N-1)个零。余数尾数也为(N-1),把余数替换掉报文后面加的(N-1)个零。
上题中的CRC编码是110010101010011(原始后接余数)
与生成多样式做除法,余数为0
海明校验码(高频难点)
编码基本规则、信息位数目、校验位数目
校验位位于信息编码的2的N次方位置,如下图。当只放一个信息位,就至少需要3位长度。当信息位5位,则编码需要9位(1、2、4、8都是校验位)

校验位r和信息位x一定会满足:2^r >= x + r +1
编码:1)填入信息位。2)校验位:按照规则填入
将信息位数拆解成由2的N次方公式组合,如:7=22+21+20,6=22+21,5=22+20,3=21+2^0
则计算对应位置的校验位时,将用到该位做组合的信息位的数值做异或。
2 操作系统基本原理(6)
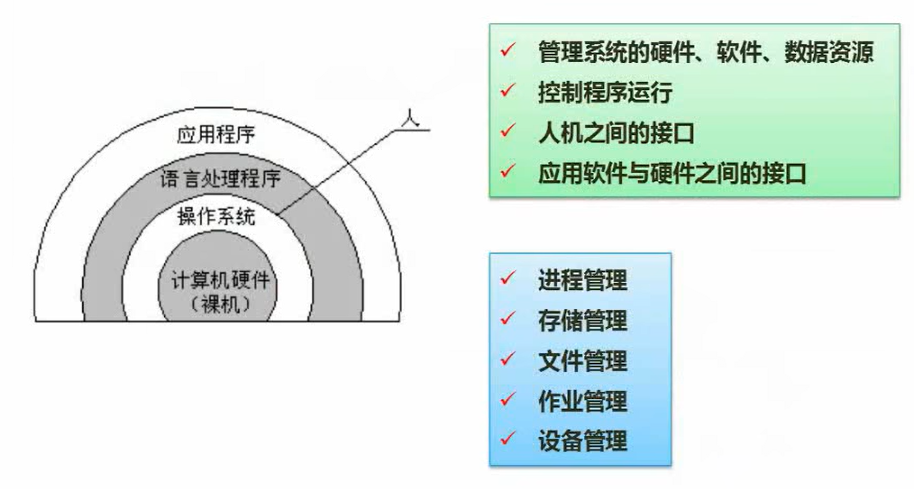
管理整个软硬件资源

2.1 进程管理
进程状态
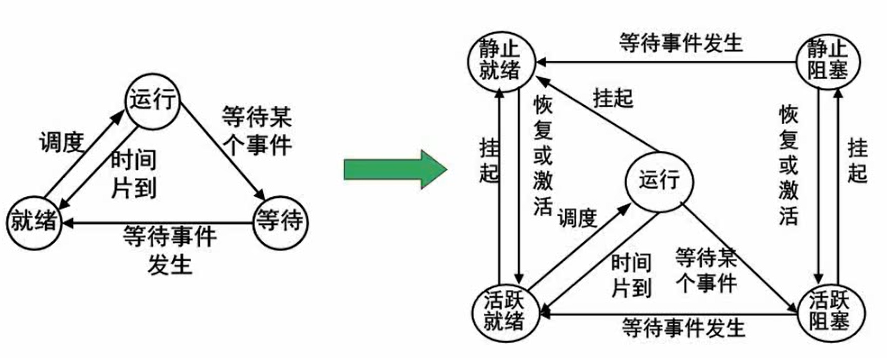
- 运行态、等待态、就绪态。
- 就绪:资源都配好了,差CPU
- 等待:除了没有CPU资源还差其他资源,如外设、数据之类
- 等待不能到运行,就绪不能回等待
- 时间片轮法:避免有长时间的进程长期挤占cpu资源
- 固定周期的进程暂停挂起
前趋图(和pv操作组合考察)

同步和互斥
互斥:同时只允许一个进程调用资源
同步:速度有差异,在一定情况下停下等待,有速度匹配要求
同步和互斥不是反义词!!
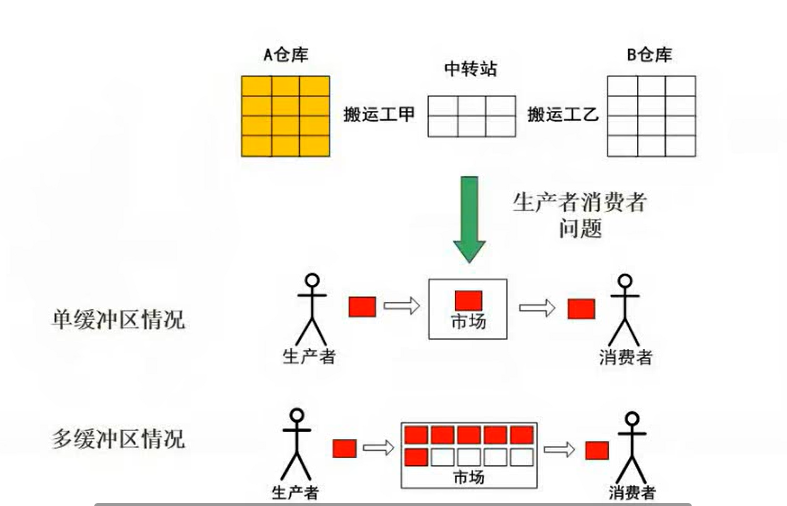
单缓冲区:生产者和消费者不能同时对一个内容做处理,当消费者未使用掉时生产者不能放入(互斥)
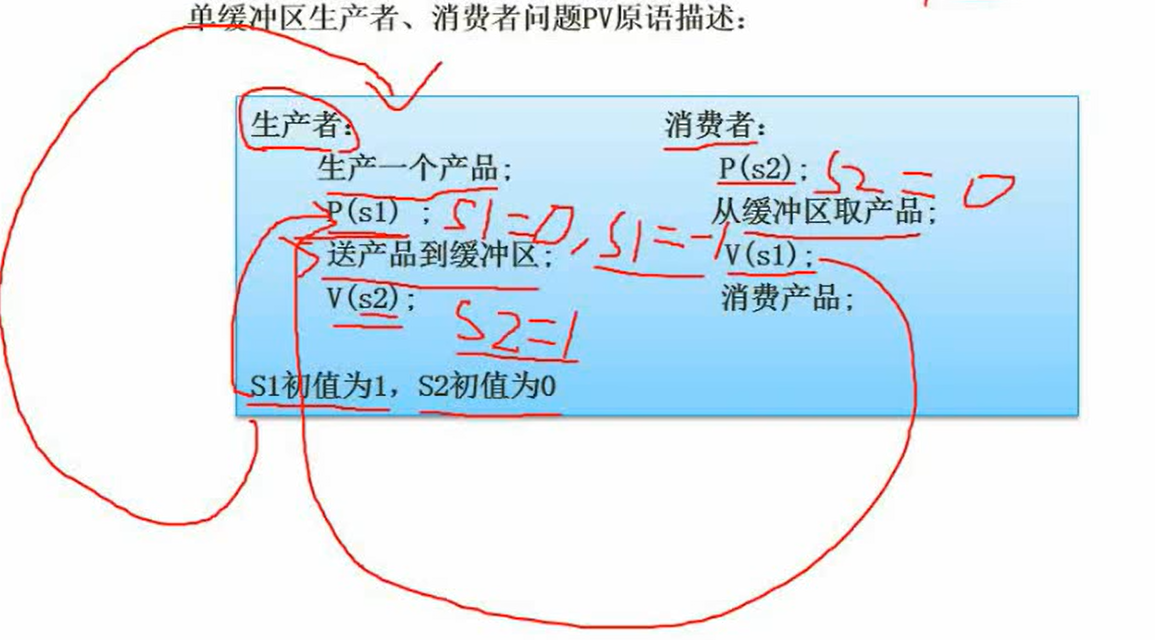
PV操作
利用到同步互斥的一些理念解决实际问题,用到的工具就是PV操作。
- 临界资源:进程间需要互斥进行占用的资源,如打印机
- 临界区:每个进程中访问临界资源的代码成为临界区
- 信号量:一种特殊变量,如P(S)、V(S),中的s即为信号量

- P操作:把信号量-1
- 当信号量小于零,阻塞当前P的执行位置,将进程放入到进程队列中。在进程列表中进入等待状态。
- 当信号量大于等于零,继续执行。
- V操作:信号量+1
- 当信号量小于等于零,则从进程队列中唤醒一个进程继续执行。
- 否则继续执行下去。
转自b站热评:用公共厕所蹲坑轻松理解PV操作:
进程就是急着蹲坑的每个人
- 信号量S代表剩余的闲置坑位,为负数时代表坑位不够即有人在排队当一个人来到厕所里面,Pronounce(正式宣布)要蹲坑,就相当于执行了P操作,在此之前:
- 当S>0,代表有空闲坑位,肯定没人排队,于是P操作后S减1,立刻开始蹲坑放大
- 当S=0,代表没有空闲坑位,坑位都被占了而且大概率还有人在排队(S<0时),于是P操作后S减1,再急也得乖乖站在旁边排队-当一个人从坑位出来,蹲坑放大成功获得胜利Victory,就相当于执行了V操作,在此之前:
- 当S>0,代表有空闲坑位,肯定没人排队,于是V操作后S加1,挥挥衣袖潇洒离开
- 当S<0,代表没有空闲坑位,坑位都被占了而且大概率还有人在排队(S<0时),于是V操作后S加1,出于人道主义精神,喊一个正在排队的人过来接坑,然后拂衣而去深藏功与名
PV操作例题:
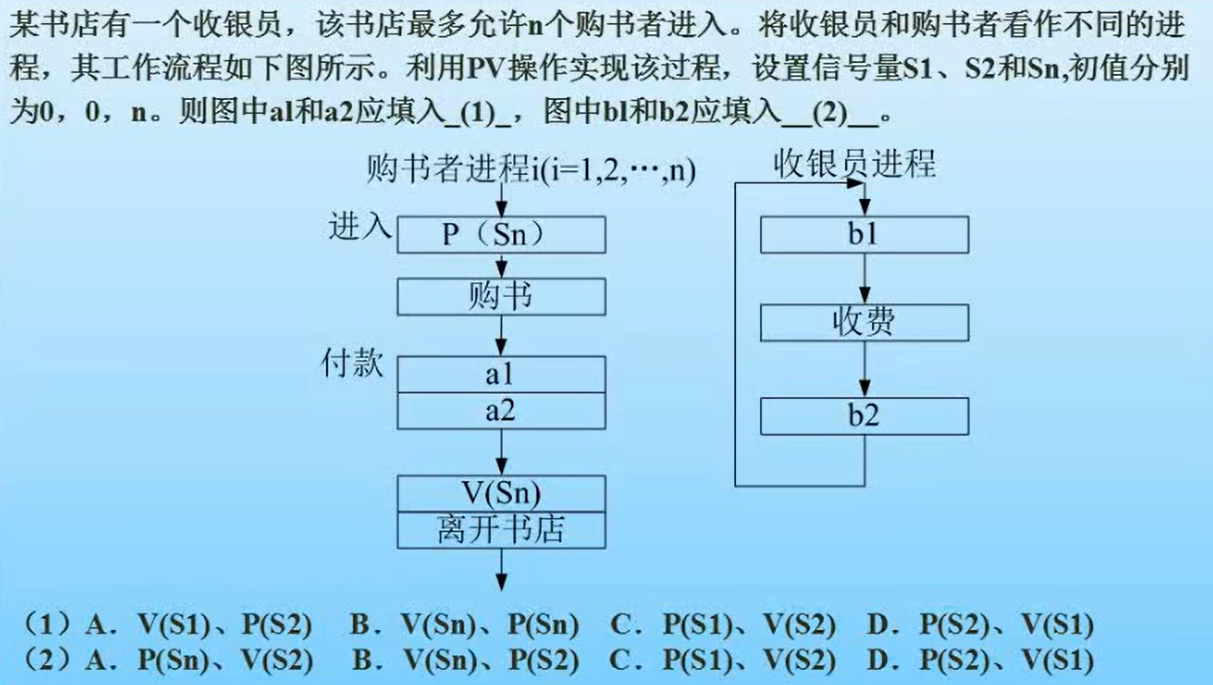
前趋图转PV:
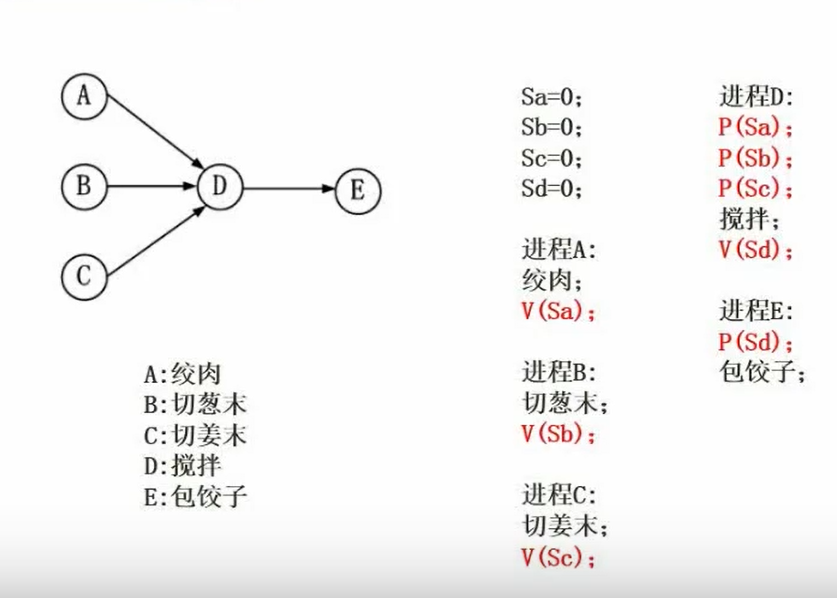

技巧:从左到右,从上到下标注信号量,然后箭头起点进程标V,箭头末尾进程标P,如上图所示。
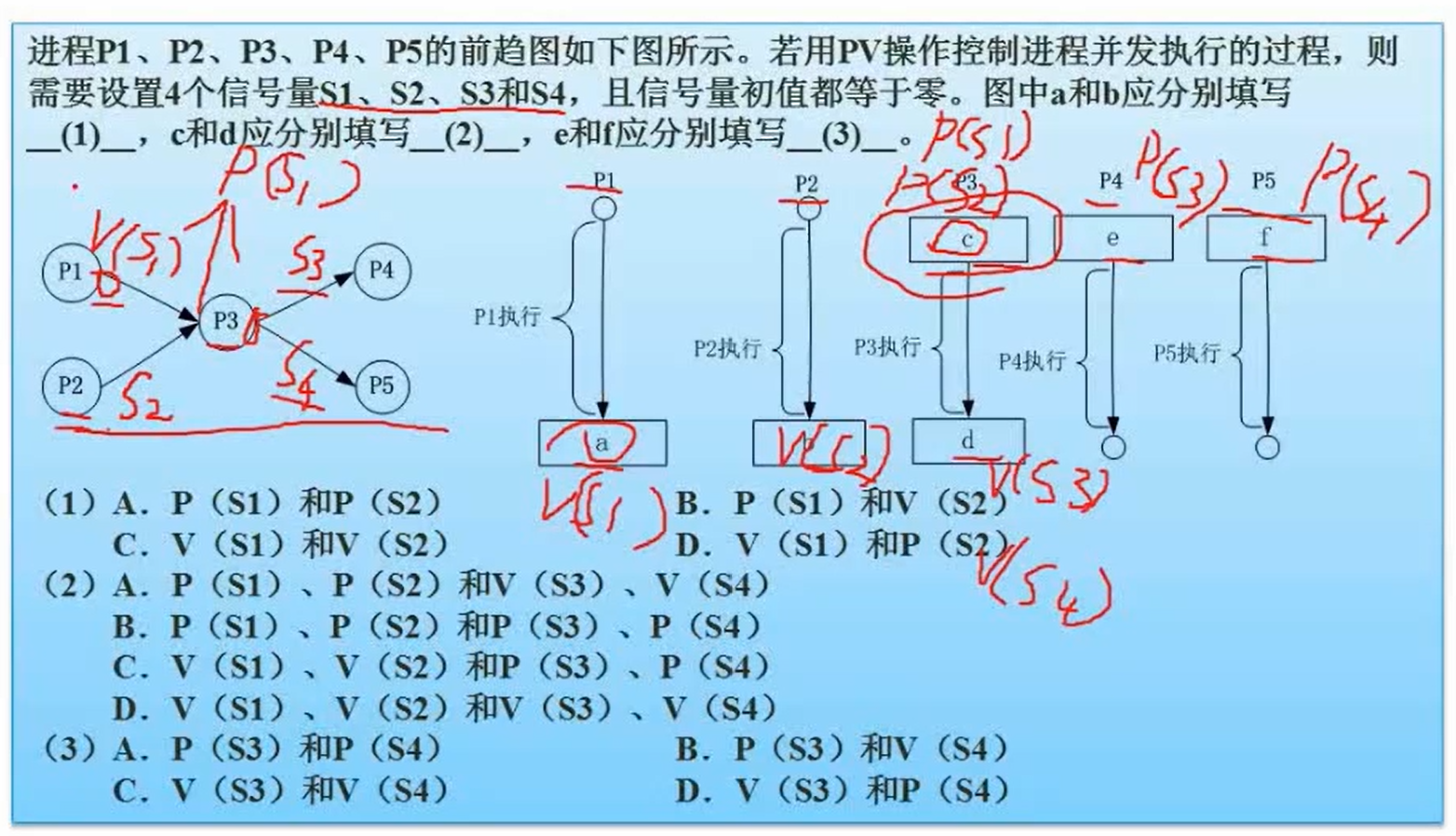
死锁
- 题型:给定一定数量进程,每个进程资源,计算至少多少资源系统不会死锁
- 死锁预防和避免问题(银行家算法)
死锁:所有可用资源均已分配,但所有进程都无法完成当前进程(需要进一步申请资源),导致无法释放占有的资源。
至少资源:假设各进程所需资源为Ni,则求和(Ni - 1),所得结果+1即为至少所需资源
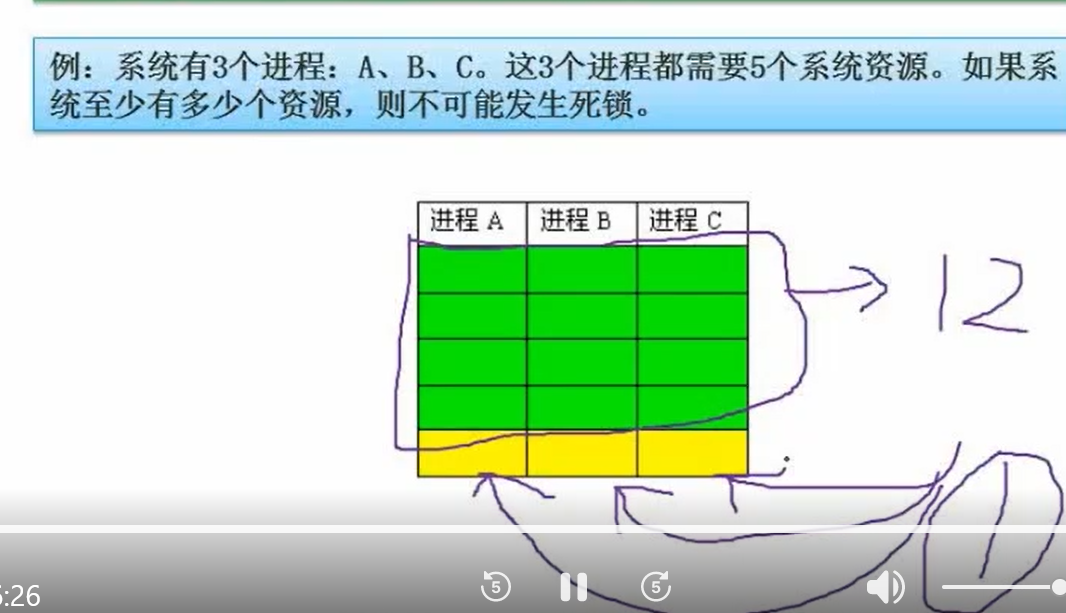
答案为13

死锁的四个条件:互斥;保持等待;不剥夺;环路等待(即等待资源成环)
死锁预防:打破四大条件
死锁避免:有序资源分配法(资源利用率低),银行家算法(重点)

先算剩下的资源数。
2.2 存储管理
分区存储(四种)

最佳适应法会导致多次分区后系统中很多小块内存
-
页式存储
页号(等大)和页内地址
逻辑地址与物理地址的转换

分成等分的区域
页表记录页号和块号关系,需要通过表进行转换
逻辑和物理地址转换:二者的页号不一定一样,页内地址一样。保留页内地址,求取页号。
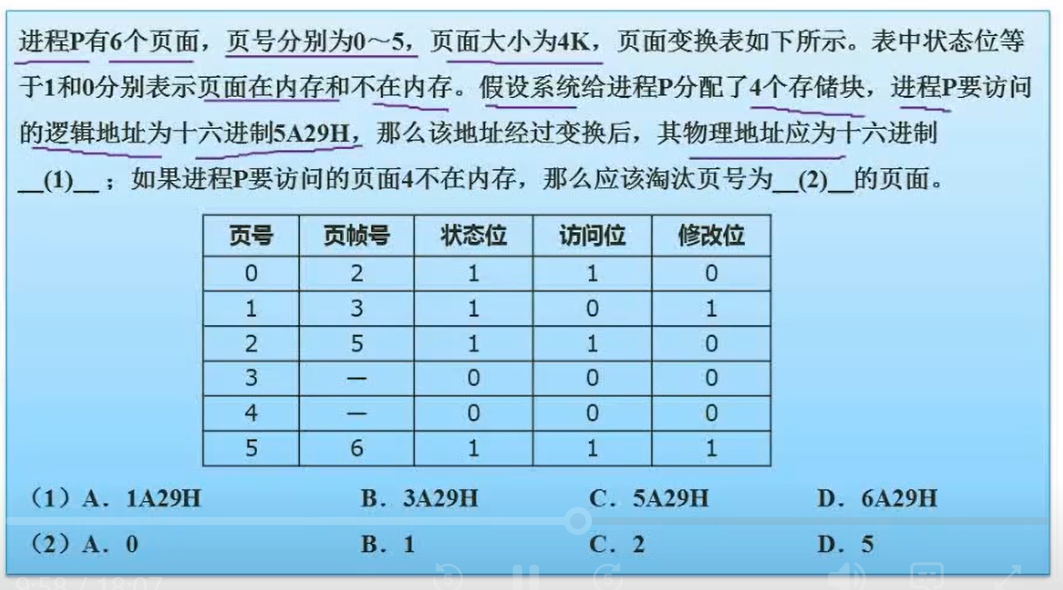
首先区分出页号和页内地址。
页面大小4K,即2^12次方,业内地址是12位。12位也就是16进制的后三位。页内地址保留,其前面的就是页号。页号通过查表得知。
应该淘汰的页号需要满足:1. 状态位为1(在内存上)2.
-
段式存储
段号(按逻辑层次划分段)和段内地址
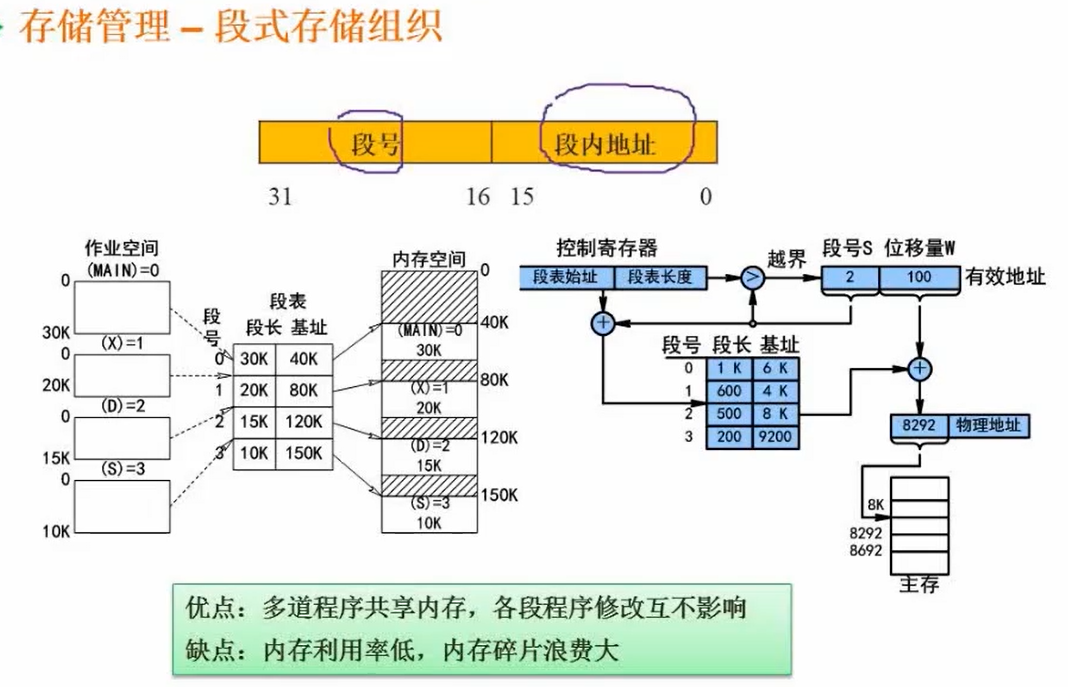
-
段页式存储
先分段、分段后再分页。
需要查两次表

页面淘汰算法

抖动:分配更多的资源,没起到正面效果,反而效率降低
实例:先入先出抖动情况
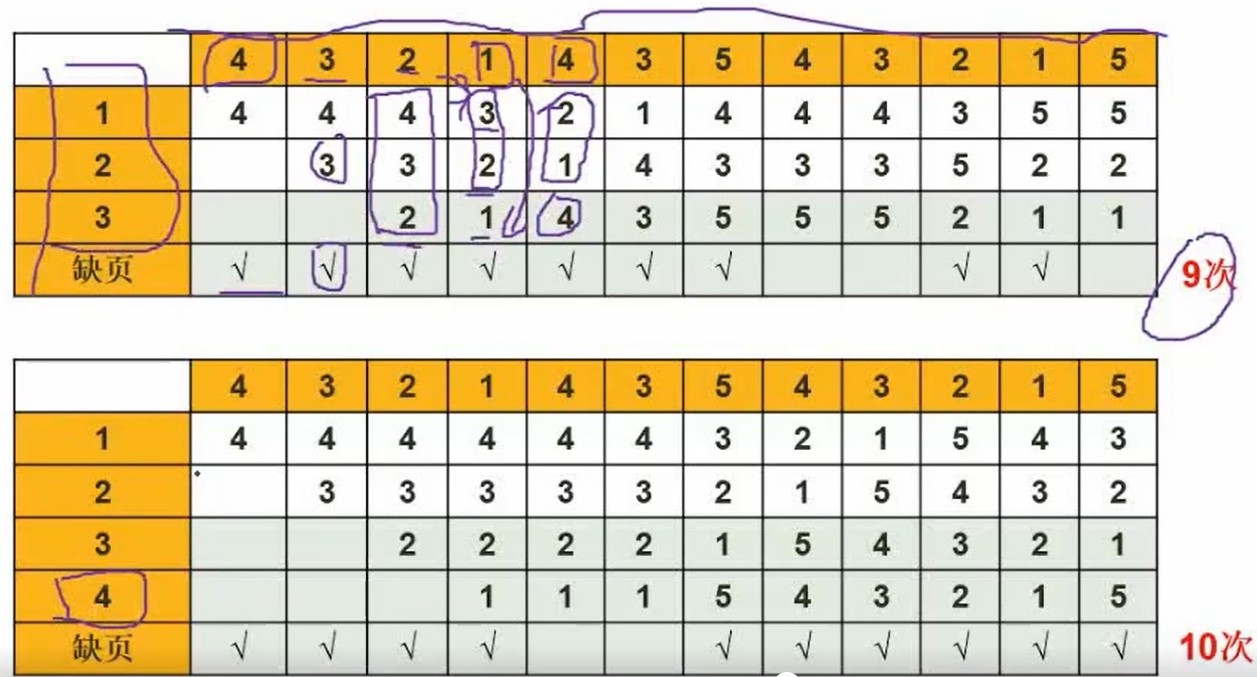
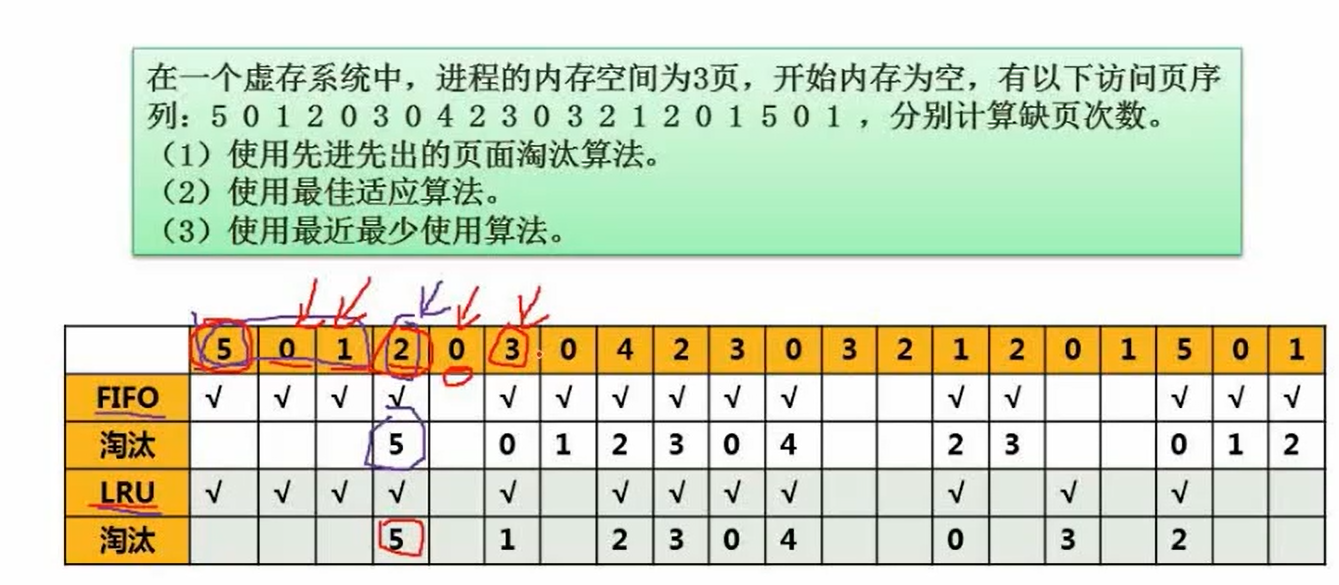
例题:

没有使用快表,说明需要每次都先在内存查表再访问内存,即每个块有两次内存访问。存储的位置刚好涉及六个块,因此6*2=12
指令一次性存储不会产生两次缺页中断,至多产生一次,而操作数有可能产生多次。
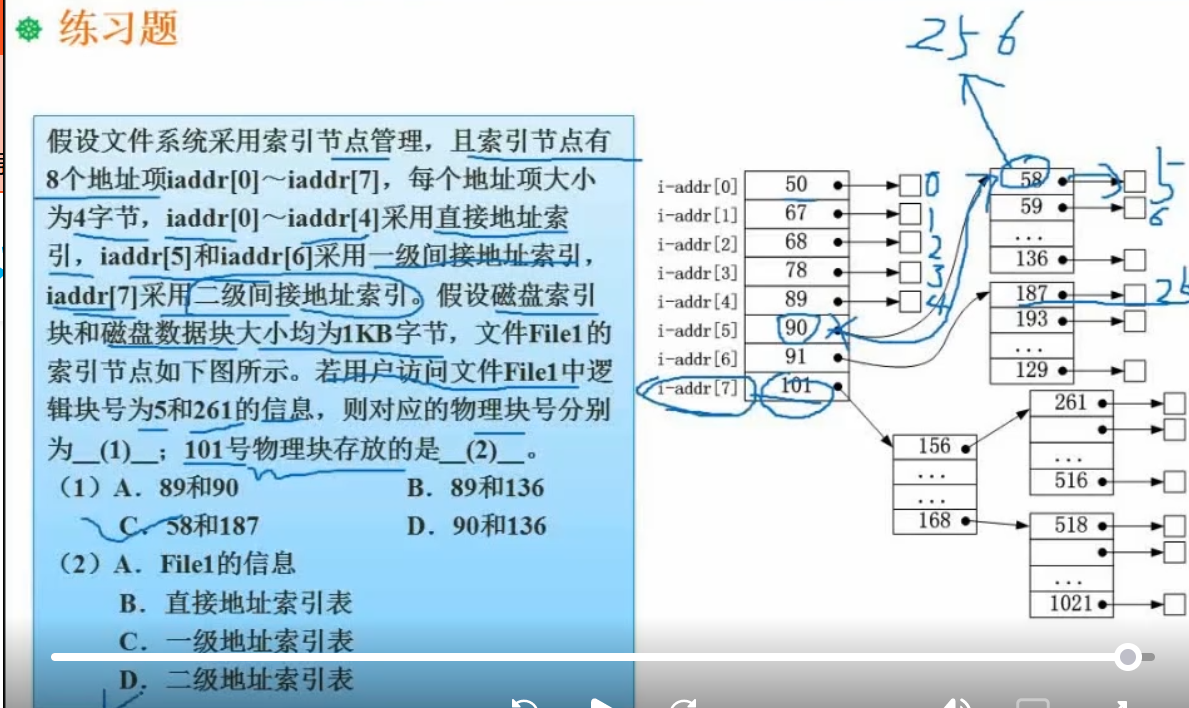
文件管理
索引文件结构
一般是13个节点
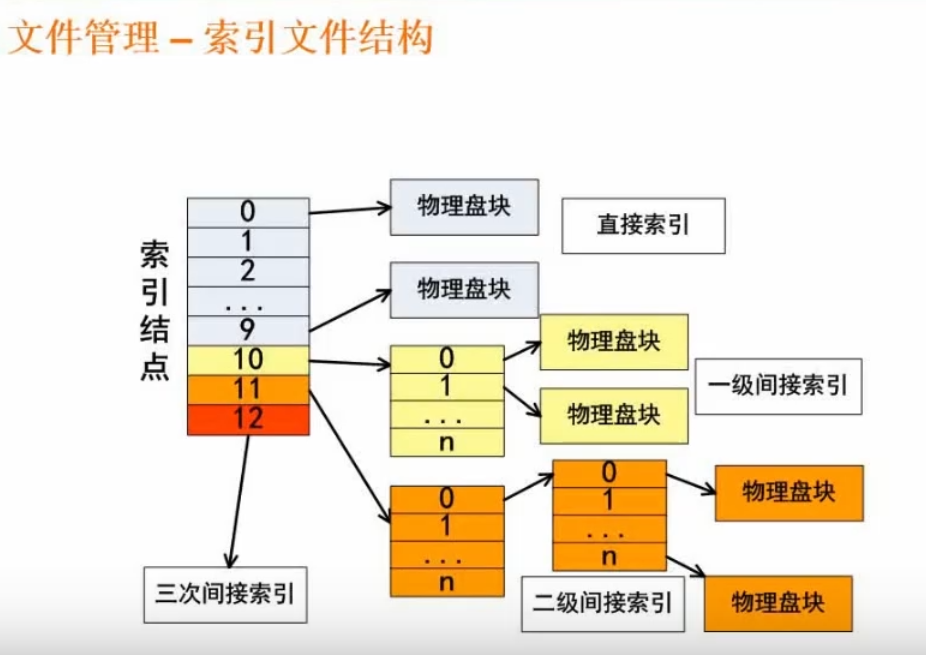
直接索引的话最大就是13N,其中N是单个的最大容量,假设4K,则总共52K
索引文件:
- 0-9:用直接索引;
- 10:用一级间接索引,存物理盘地址,假设一个地址4字节,则可以存1024地址;每个地址再指向一个物理盘块的位置,则可以存4k*1024
- 11:二级间接索引,第二个物理盘块还是存地址,可以存4K* 1024* 1024
- 12:三级
文件和树型目录结构
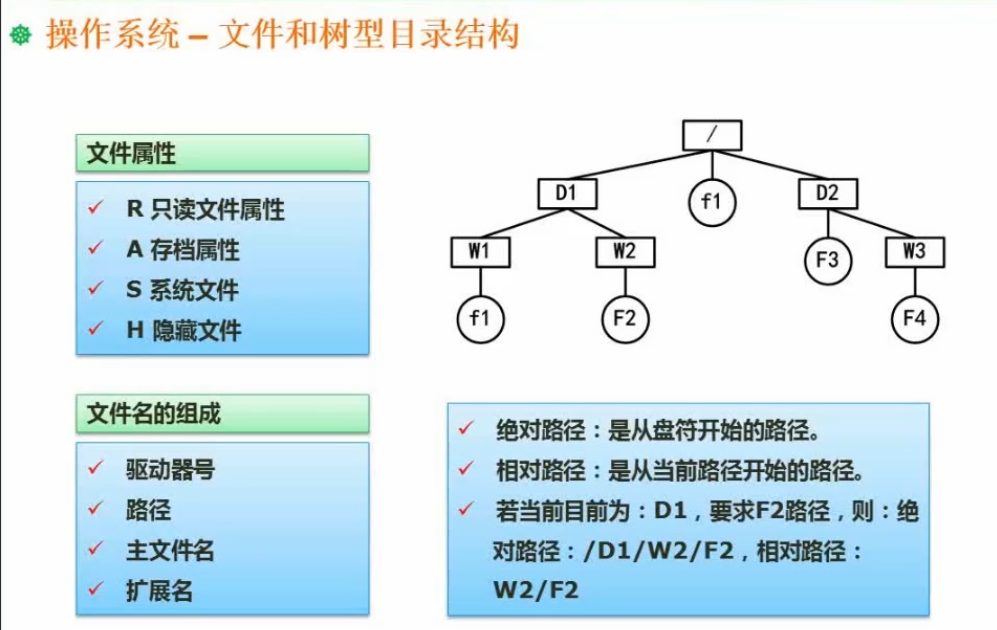
绝对路径、相对路径概念
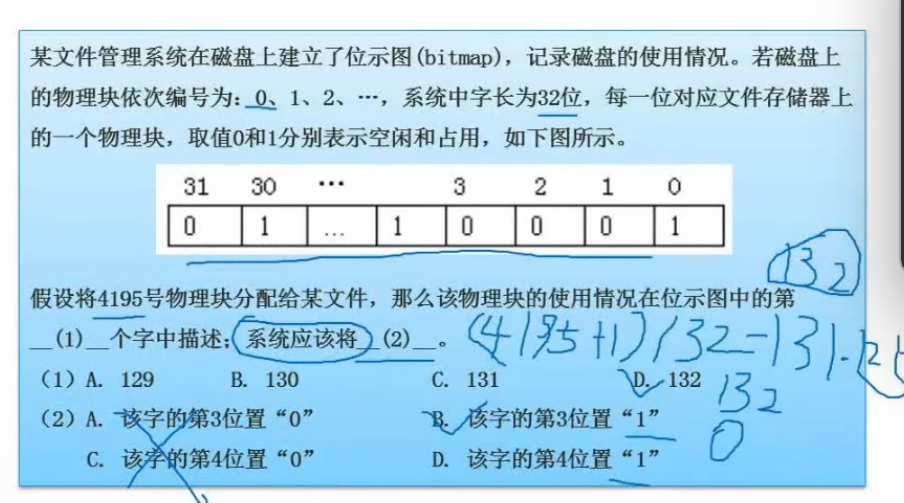
空闲存储空间管理
空闲区表法:用表记录空闲区域位置
空闲链表法:将空闲区域连城链表
位示图法:用0表示空的,1表示占用的(样式类似选座)

2.3 数据传输控制方法
内存和外设的数据传输方式
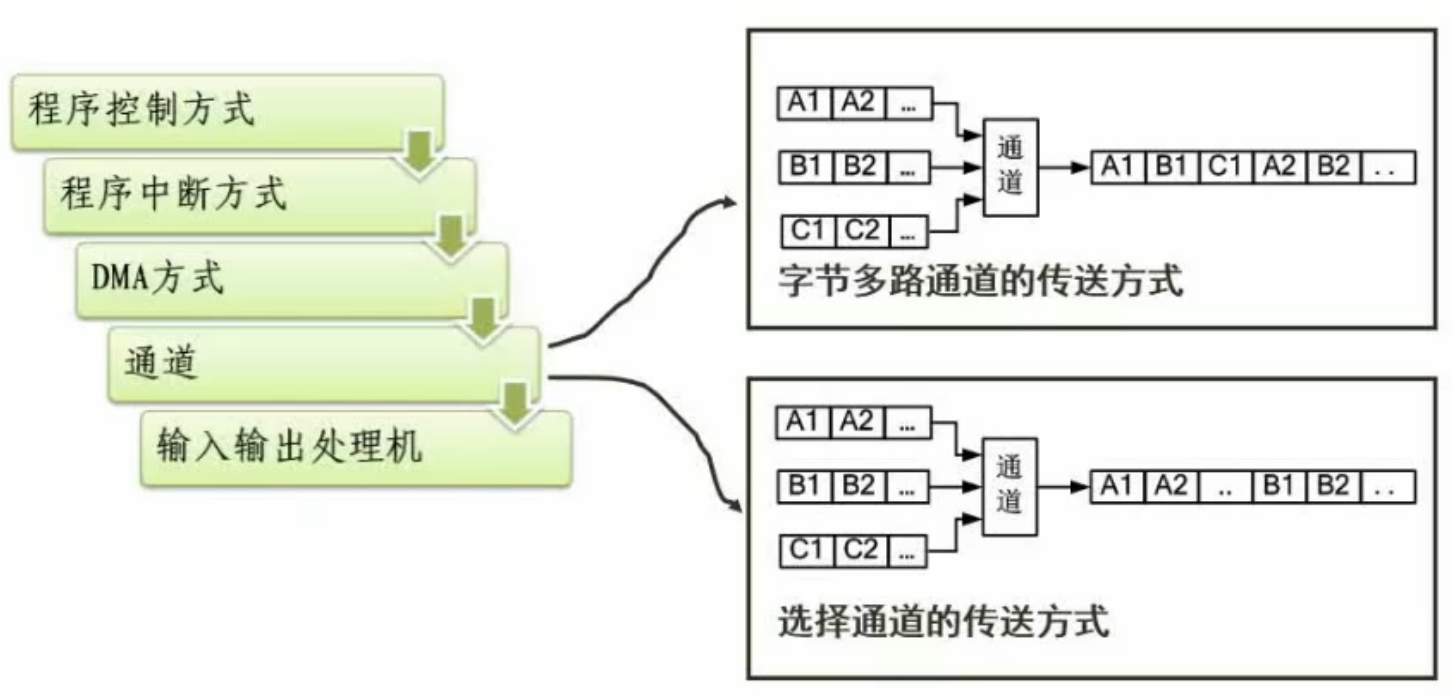
- 程序控制方式:CPU直接控制
- 程序中断方式:事件中断
- DMA方式:DMA控制器监管,完成后由CPU继续接收
- 后两种多用于专用机器
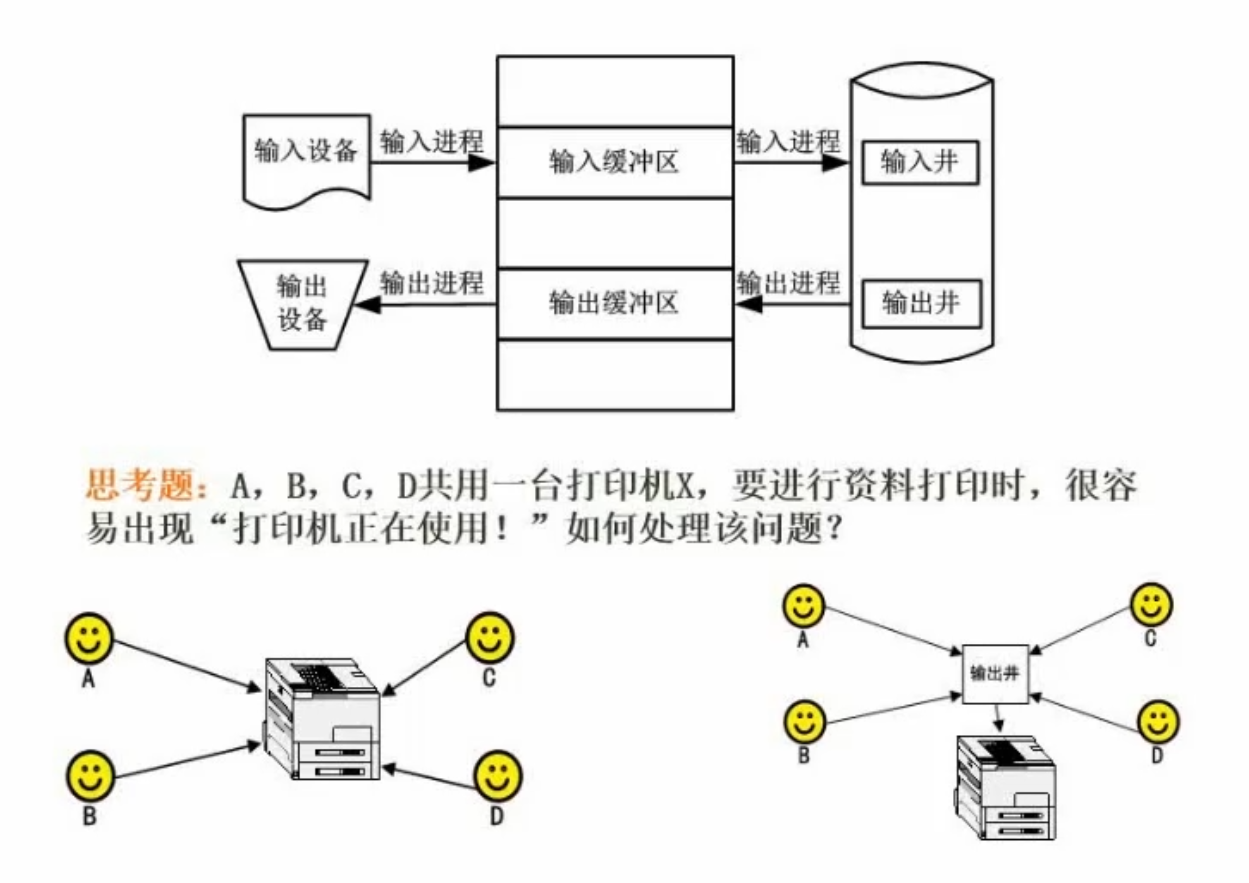
虚设备与SPOOLING技术
专门的程序做管控,会先把任务置入输出井,在磁盘上开缓冲区缓存起来,避免外设的低速和设备高速处理之间的冲突。
微内核操作系统
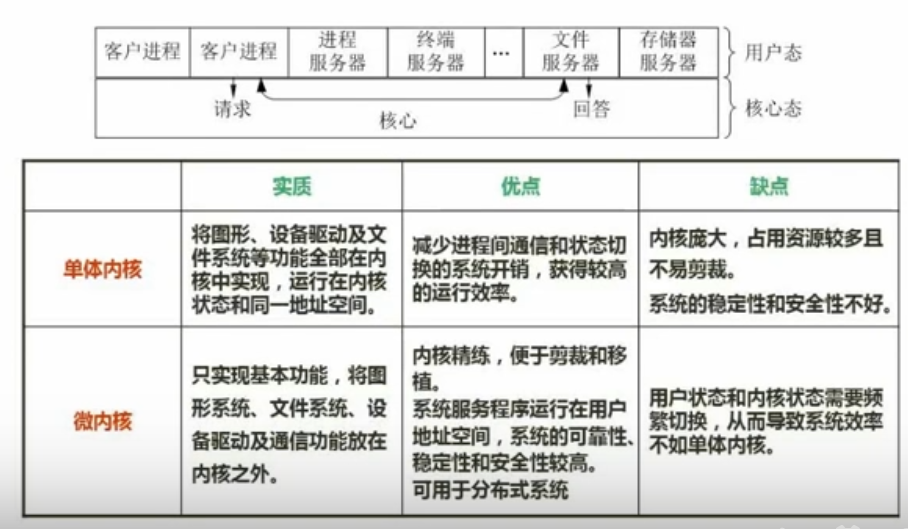
优点:更可靠(把专用系统分出,文件系统崩坏不影响到)
缺点:用户态和内核态频繁切换
3 数据库系统 (6)
3.1 数据库模式
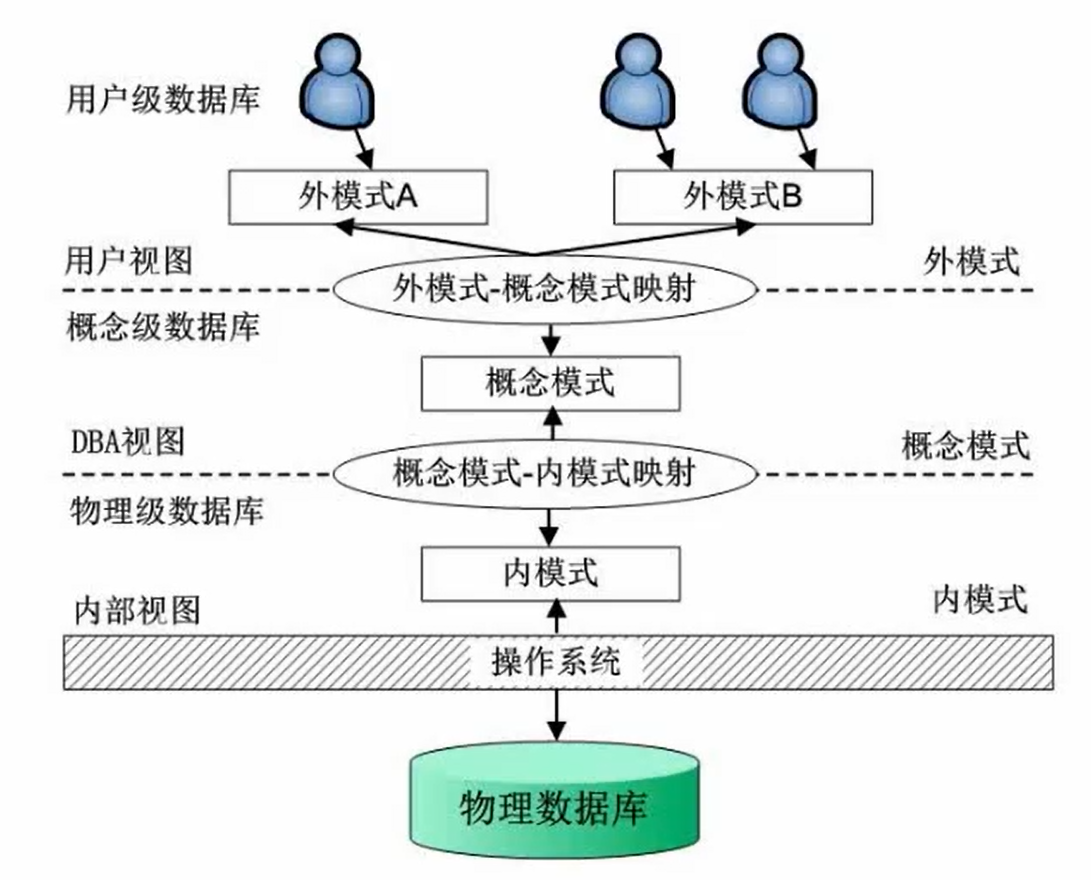
三级模式:
- 内模式(物理级数据库):数据库以什么形式去管理数据存放
- 概念模式(概念级数据库):数据库中的表
- 外模式(用户级数据库): 数据库里的视图(分割表,在不同场景选择表中的几个列构成一个表,增加灵活性)
两级映射:
- 外模式和概念模式映射:表和视图之间的映射
- 概念模式和内模式映射:存储结构和表的映射
3.2 数据库设计
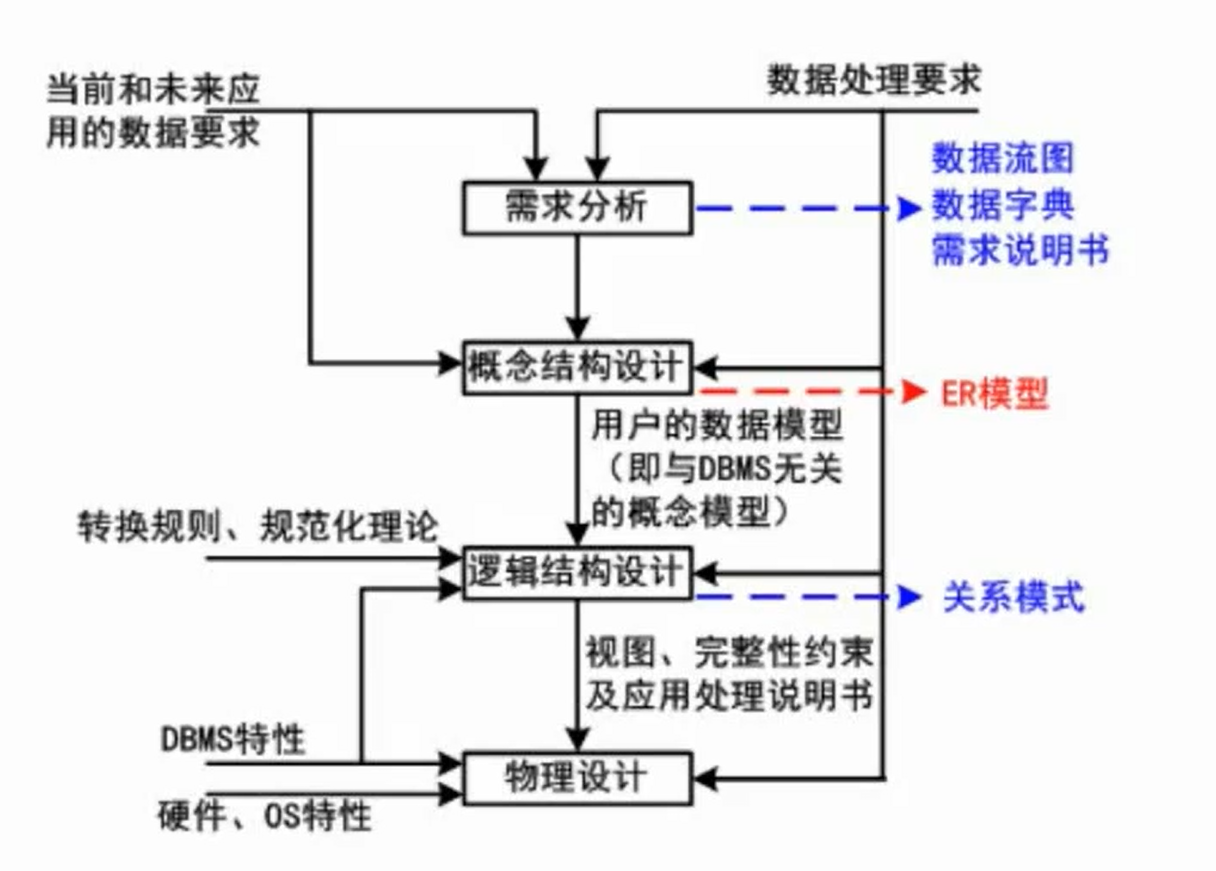
- 需求分析:系统对数据的要求;
- 数据流图、数据字典、需求说明书
- 概念结构设计:转换规则、规范化理论
- ER模型(与数据库管理系统DBMS无关的概念模型)
- 逻辑结构设计:
- 关系模型
- 物理设计:DBMS特性、硬件特性
ER模型
- 方框表示实体
- 椭圆表示属性
- 菱形表示联系

注意事项:
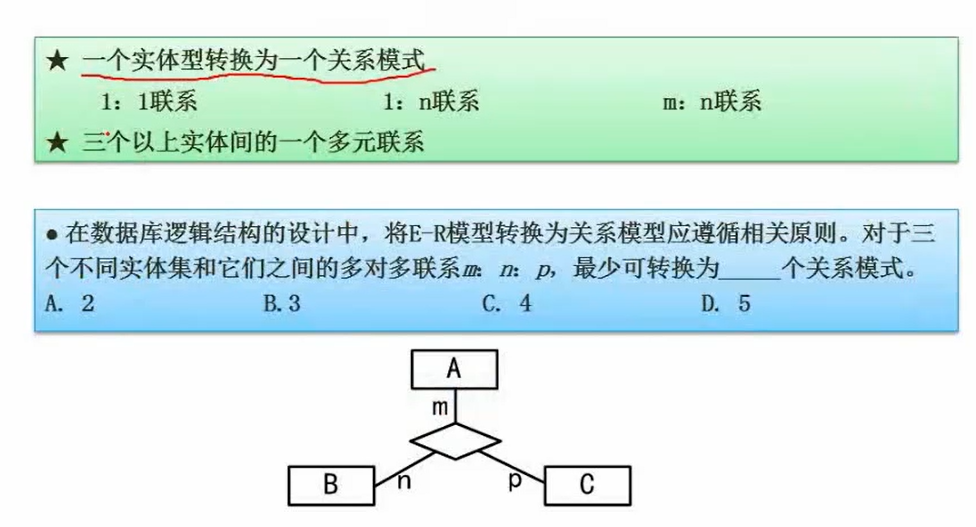
关系代数元组演算

笛卡尔积:两张表记录做整合,会有N*M条记录
投影:投影只保留指定的列
选择:选择只保留制定的行
联接:只保留两个表都有的字段,看联接条件。
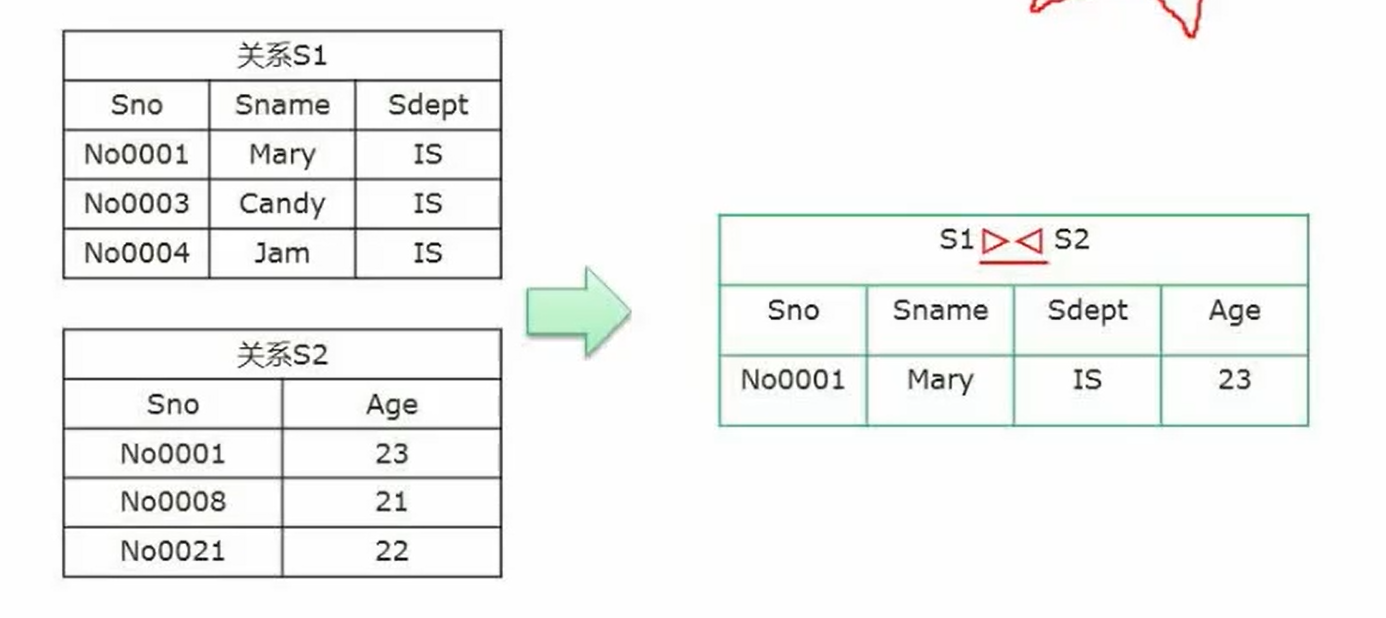
规范化理论
-
函数依赖:由x可以唯一的对应一个y
- 部分函数依赖:组件的一部分就能确定某个属性
- 传递函数依赖:A确定B,B确定C,则A确定C(但B不能反过来确定A)
-
规范化价值:非规范化的模式可能存在数据冗余、更新异常、插入异常、删除异常。
-
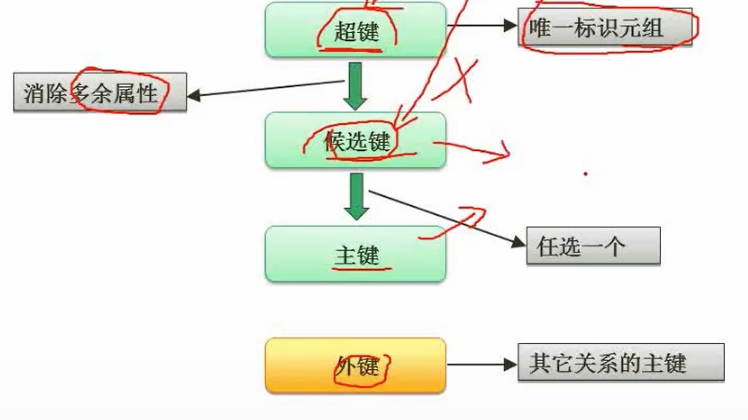
键(重点是候选键)
- 超键:唯一标识元组(可能冗余)
- 候选键:在超键基础上消除多余属性
- 主键:候选键任选一个可为主键
- PS:(学号,姓名)可以知道性别,所以这个组合可以是超键,但候选键只能是学号,因为姓名是冗余的属性
求候选键:图示法:


组合确定要用组合键。当没有入度为0的再考虑中间节点能不能遍历全图。
范式
规范化程度越高、数据表越小数据越细。一般到第三

-
第一范式:
- 属性不可分
-
第二范式
- 每一个非主属性完全依赖主键(不存在部分依赖)
- 每个表只描述一件事
-
第三范式
- 任何两个非主键属性的数据不存在函数依赖关系
-
BCNF(巴斯-科德范式)
- 任何主属性不能对主键子集依赖(在3NF基础上消除主属性对主码子集的依赖)

例题:
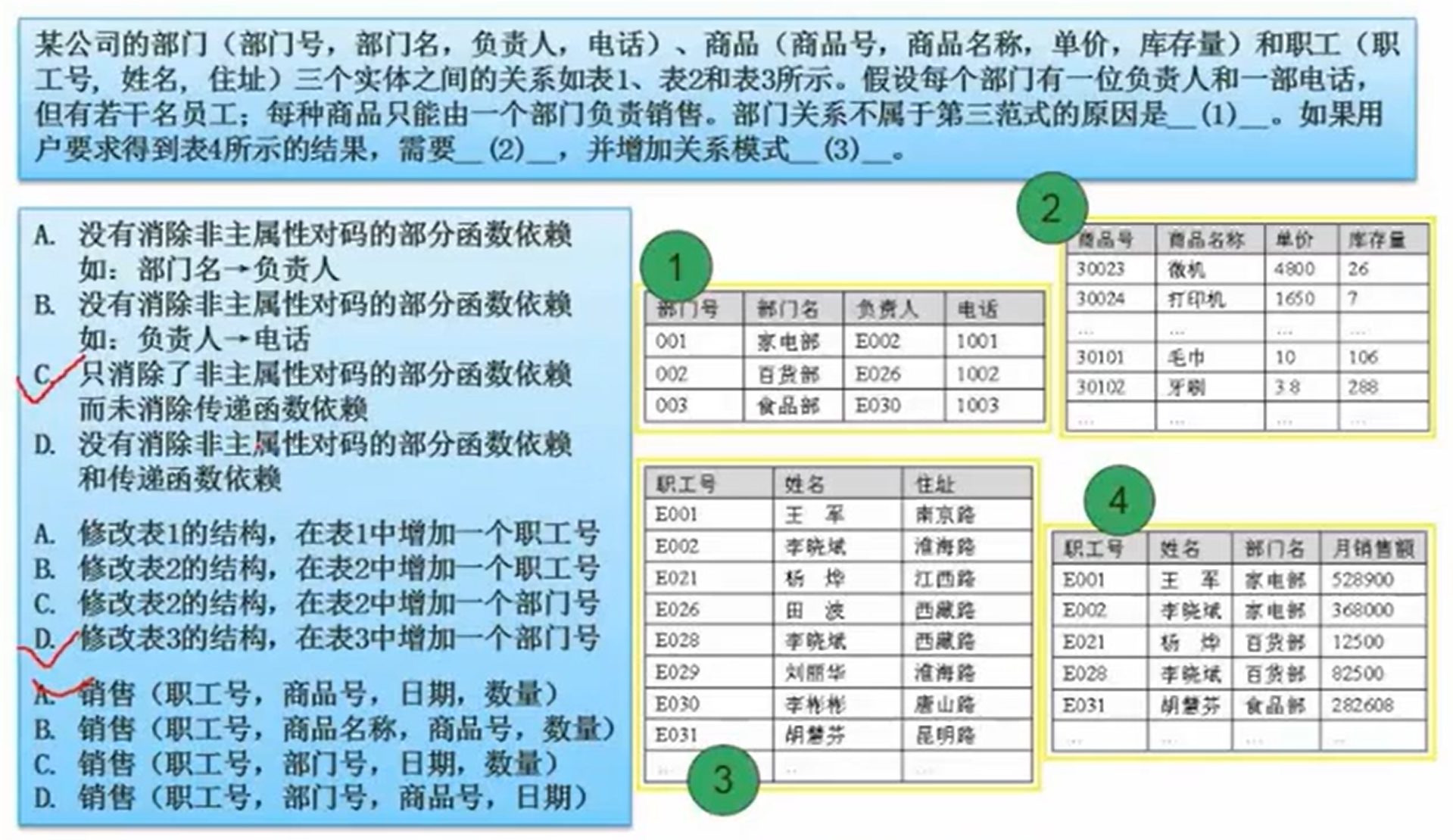
模式分解
分解时,依赖的关系属性要继续保持

只要所有属性都能被拆解后的根据关系推得,则无损。
分解为2时:

反规范化
过于规范效率大大下降。

3.3 并发控制

事务。
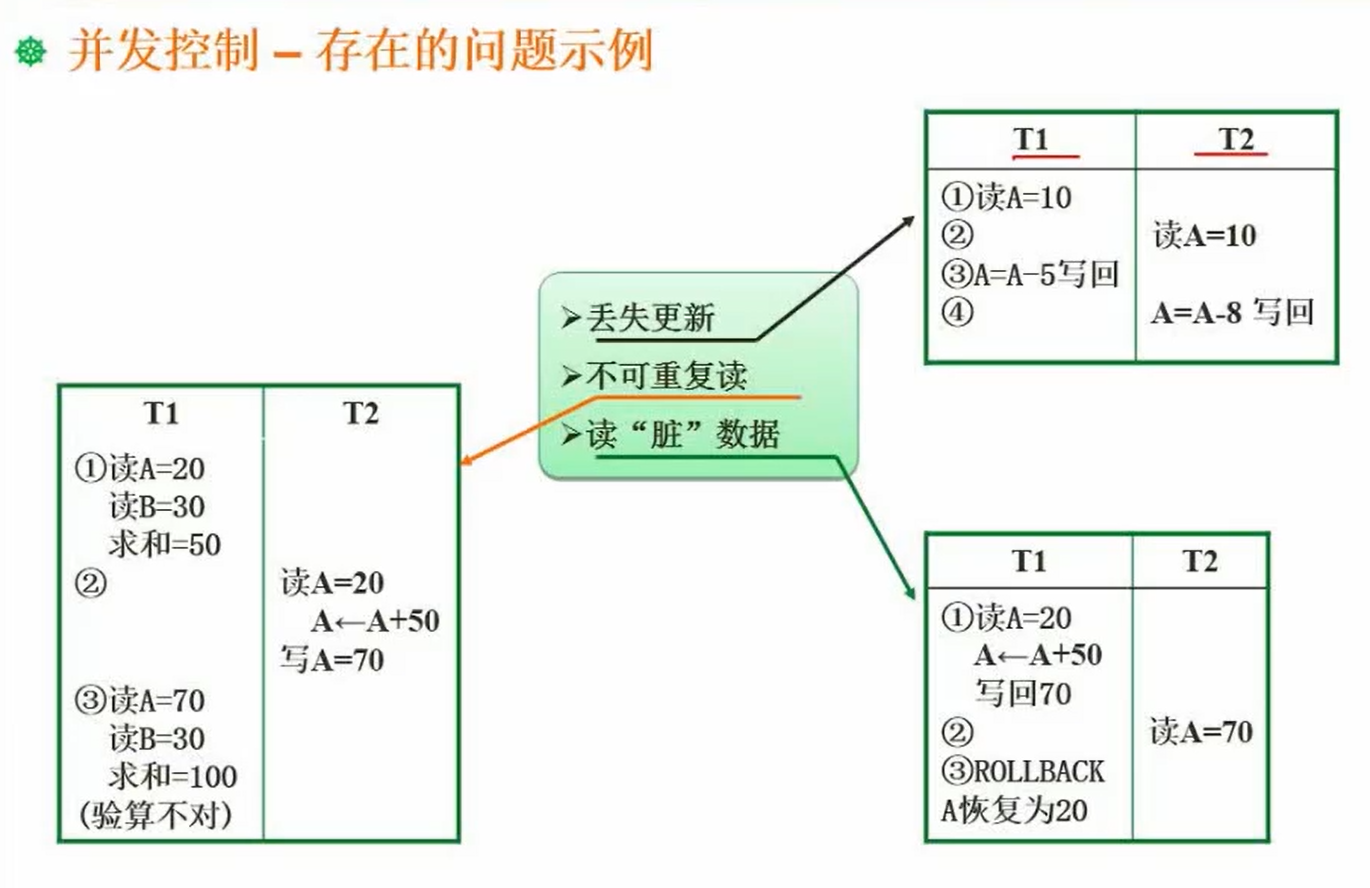
封锁协议:

- 完整性约束:
- 实体完整性:主键不能为空且不重复
- 参照完整性:数据类型,数据范围之类
- 用户自定义完整性约束

3.4 数据库安全
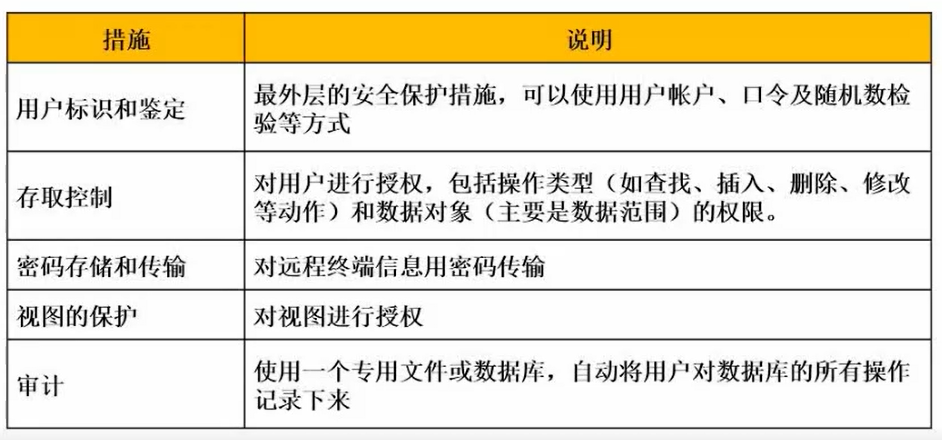
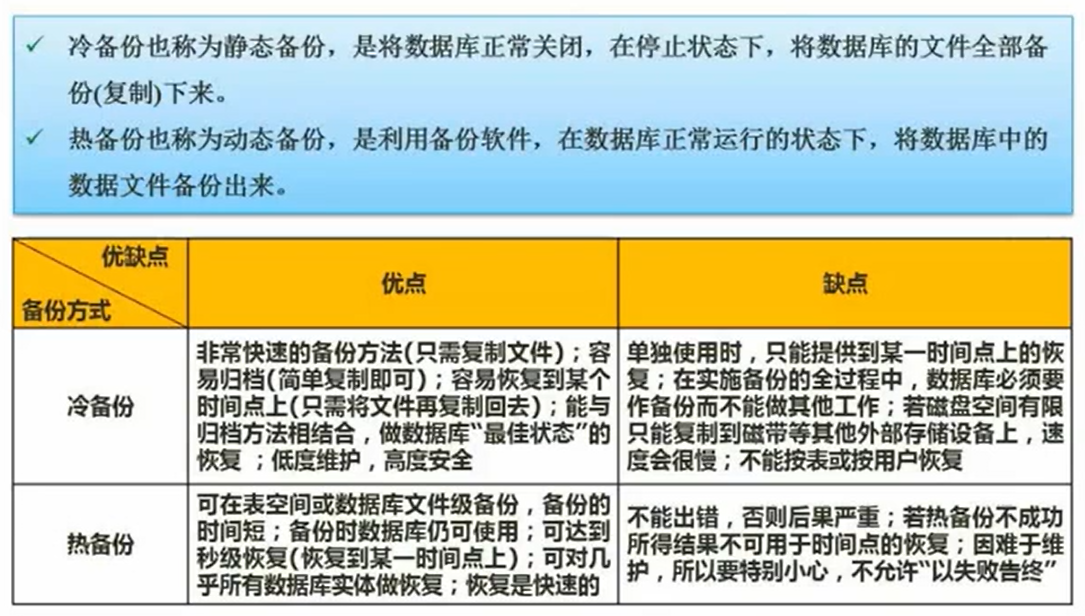
数据备份
- 冷备份:静态备份,关停应用的情况下备份。数据库全都拷下来,更简单、更安全、能与归档方法相结合、更快,但必须停机,且不能指定拷贝的表。
- 热备份:动态备份,在正常运行状态下将数据备份下来,可以有选择性的恢复,备份更快。

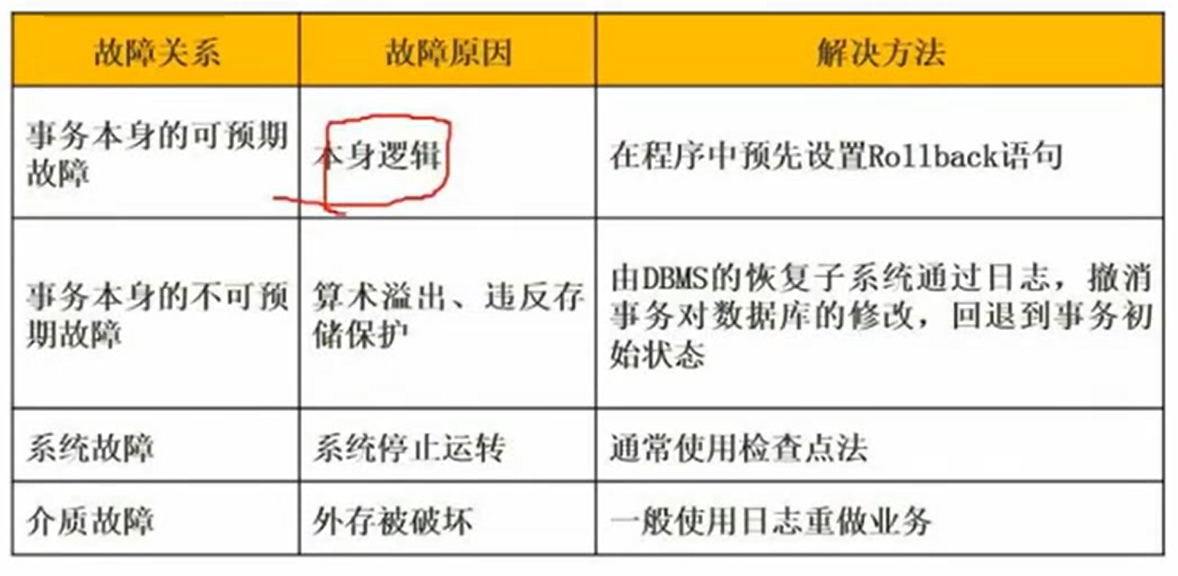
故障及恢复
3.5 大数据
对海量数据处理的相关技术

4. 计算机网络(5)
4.1 七层模型
顶到底
- 应用层
- 表示层
- 会话层
- 传输层
- 网络层:跨越网络层就不是同一个局域网
- 数据链路层
- 物理层

中继器:仅做传输,增加传输距离
网桥:连接两个同类型网络
交换机:连接多个设备,联网器
三层交换机:分组传输
路由器:路由选择
4.2 网络标准和协议
网络技术标准和协议
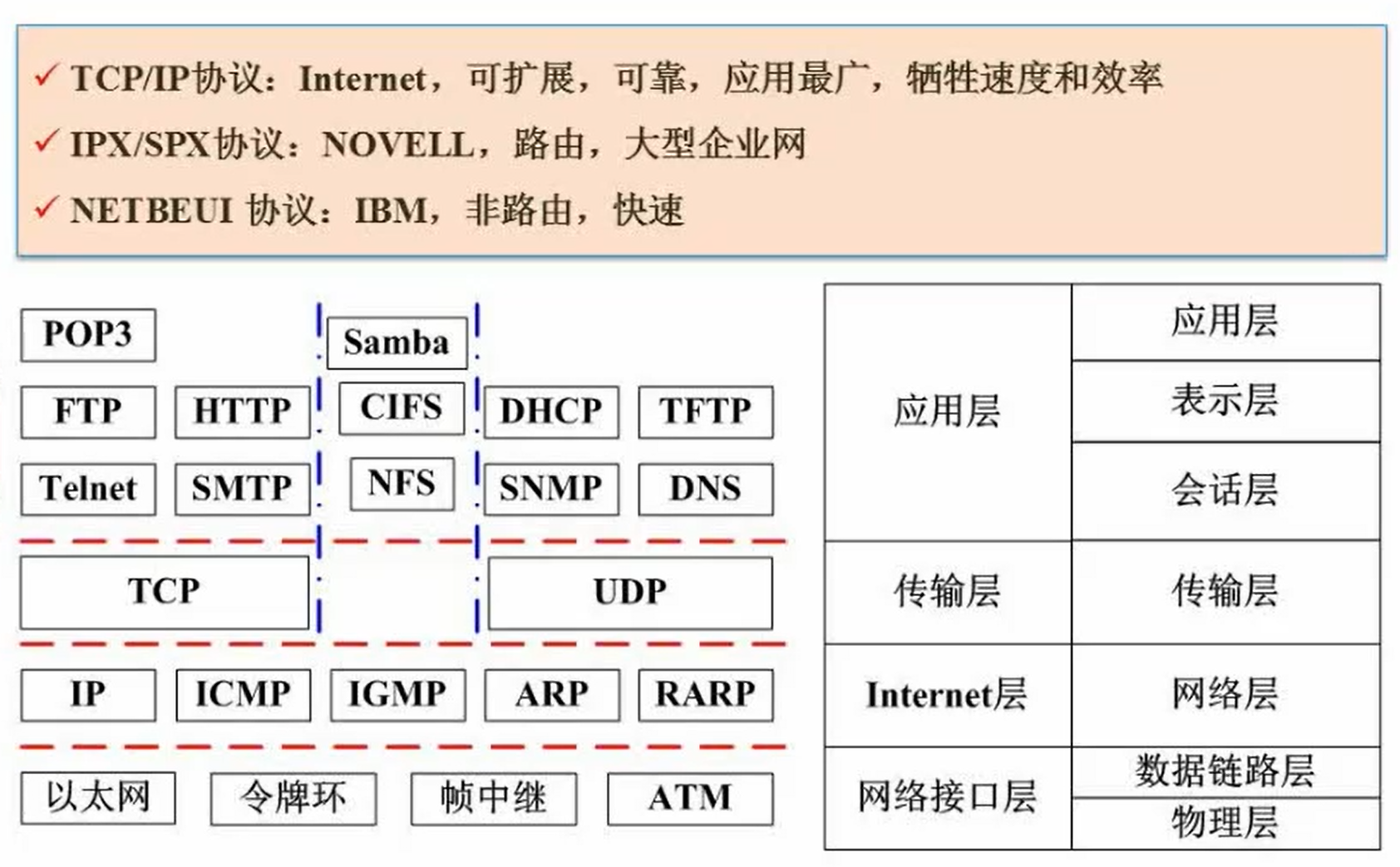
- TCP:三次握手四次挥手
- 邮件:POP3、SMTP、IMAP4协议、MIME协议、HTTP协议和HTML语言
- DNS协议:IP转域名

拓扑结构
- 总线型、星型(办公室常用的,交换机是星型的中间)、环型
- 局域网、城域网、广域网、因特网
网络设计

逻辑设计:

物理层设计:

分层设计:
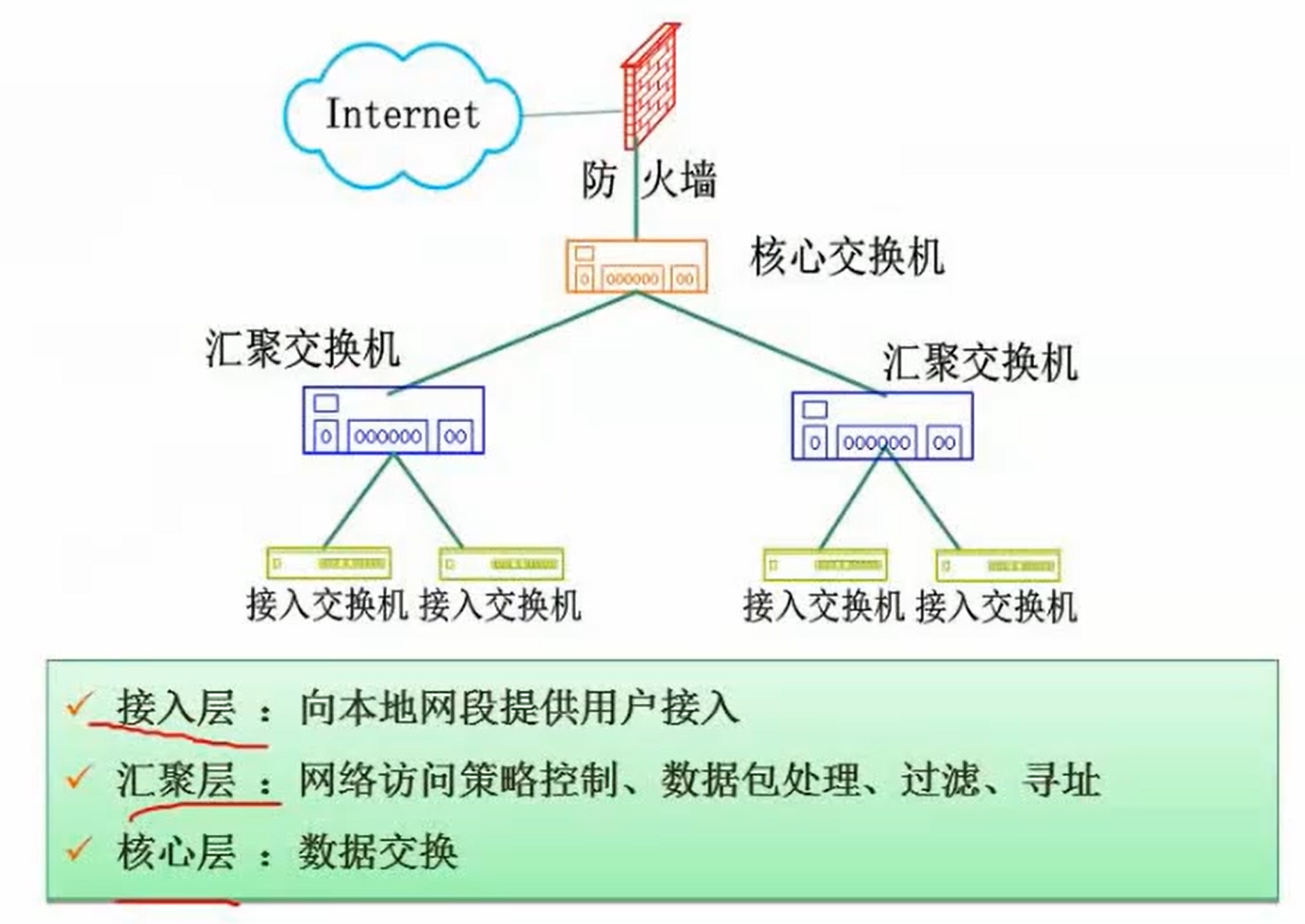
- 接入层:用户接入
- 汇聚层:访问策略、处理、过滤、寻址
- 核心层(防火层):数据交换转发
4.3 IP地址

A类地址:前8位网络号,后8*3位为主机号,所以可以表示2^24-2
B类地址:前两段16位为网络号,可以表示2^16-2个主机
C类地址:前三段24位网络地址,可以表示2^8-2主机
子网划分:
其中172.18.129.0/20表示前20位为网络号,则可以表示2^20-2
子网掩码:为1的部分为网络号,为0的部分为主机号

将IP地址化成二进制,把若干个主机位做子网,取几位就能有2^k个子网


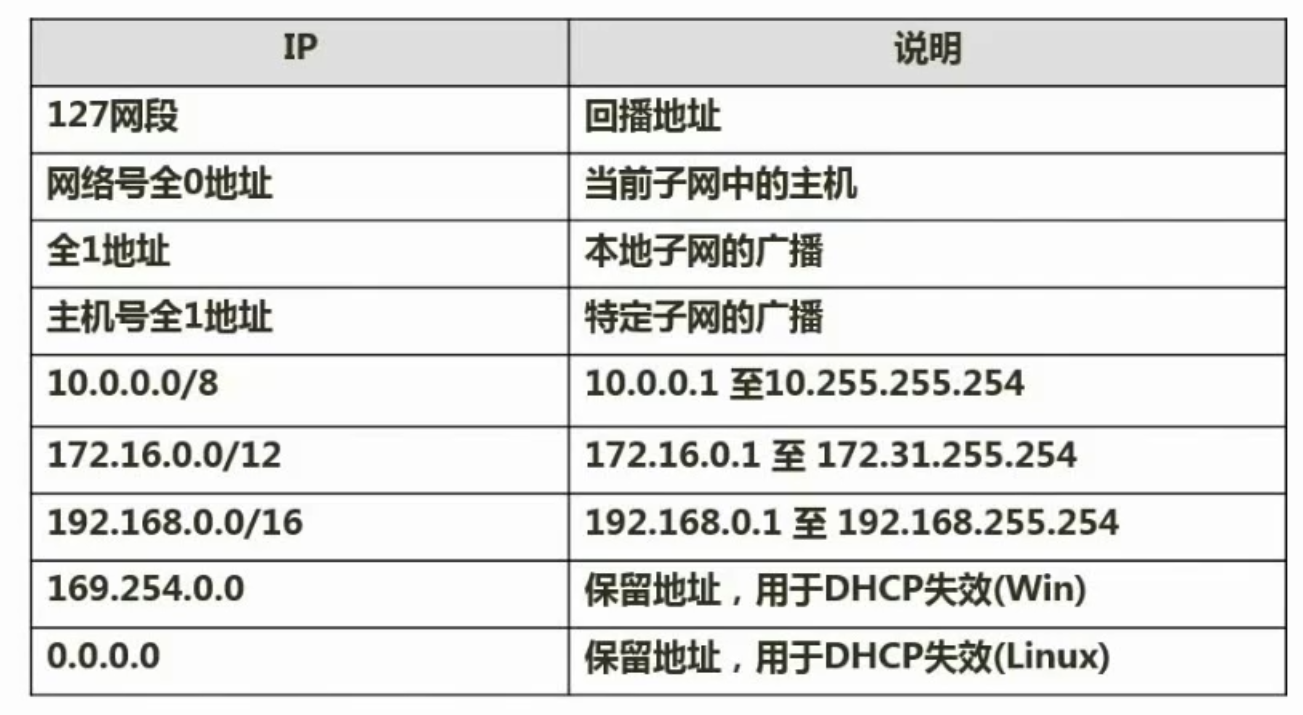
特殊含义ip
4.4 网络接入技术
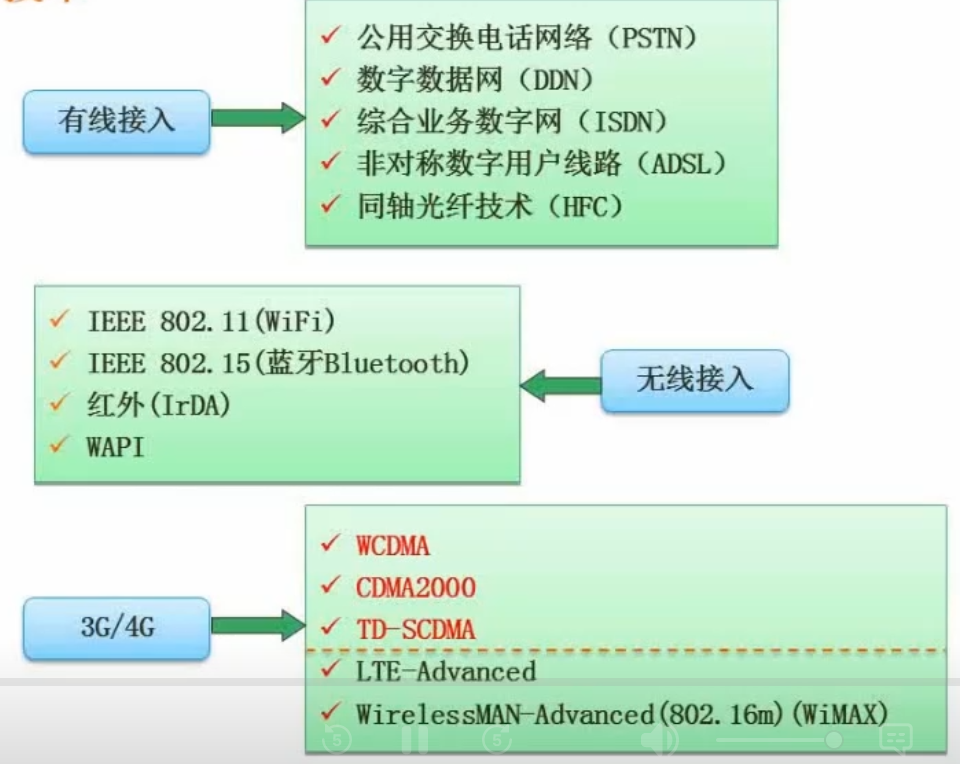
有线接入:ADSL
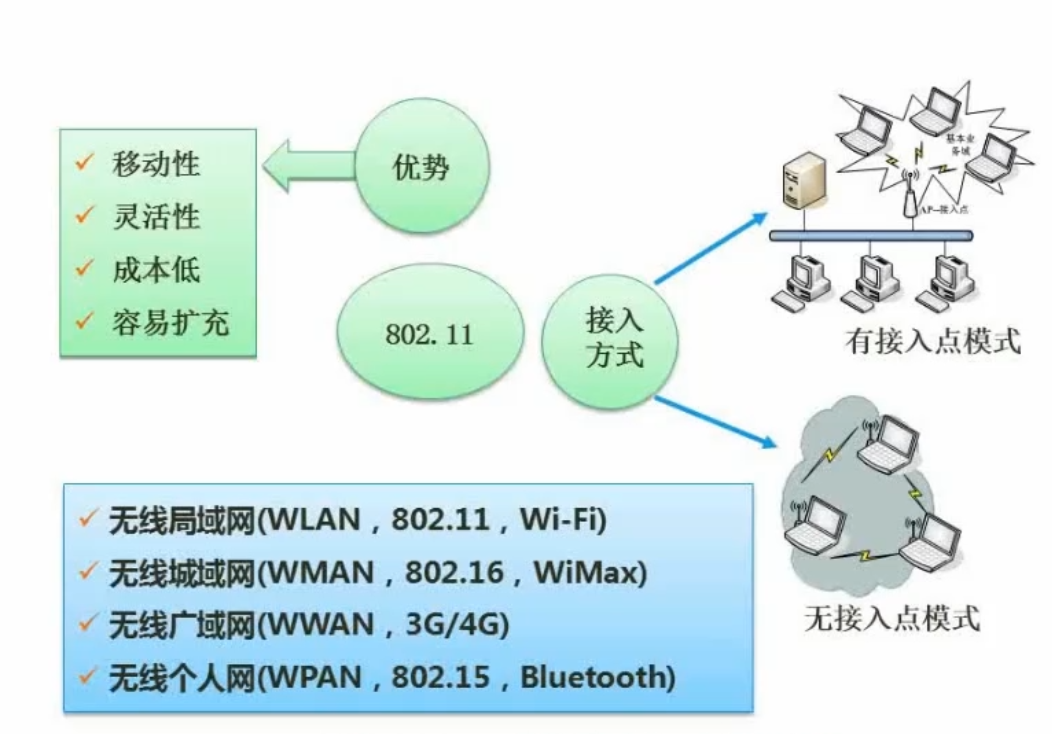
无线接入
无线网
4.5 IPV6
扩大地址空间

5. 系统安全分析与设计(3)
5.1 安全属性
- 保密性:最小授权原则、防暴露、信息加密、物理保密
- 完整性:安全协议、校验码、密码校验、数字签名、公证
- 可用性:综合保障(IP过滤、业务流控制、路由选择控制、审计跟踪)
- 不可抵赖性:数字签名
5.2 非对称加密技术
公钥加密的用私钥解密,私钥加密的用公钥解密
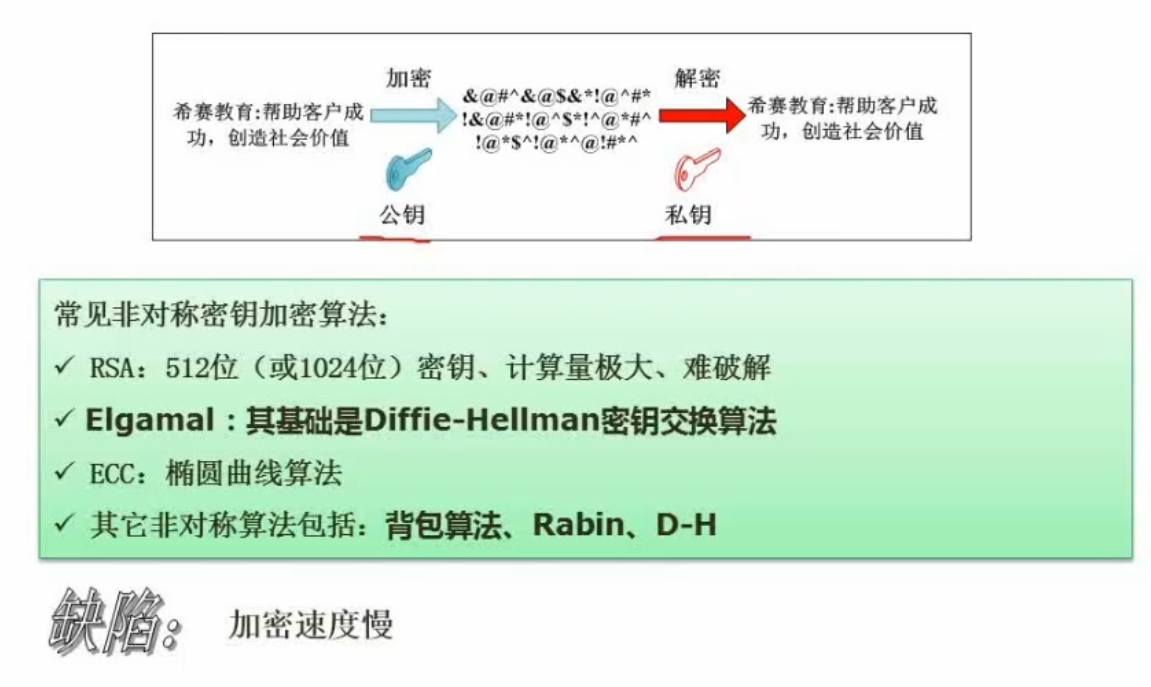

对称加密大量数据,非对称加密密钥
信息摘要
单向散列函数(单向Hash函数)、固定长度的散列值

两段摘要验证来是否匹配
数字签名
更好的验证手段,证明发出方防止抵赖

数字信封和PGP
数字信封:发送方将原文用对称密钥加密传输,将对称密钥用接收方的公钥加密。

5.3 层次安全保障
各个网络层的安全保障
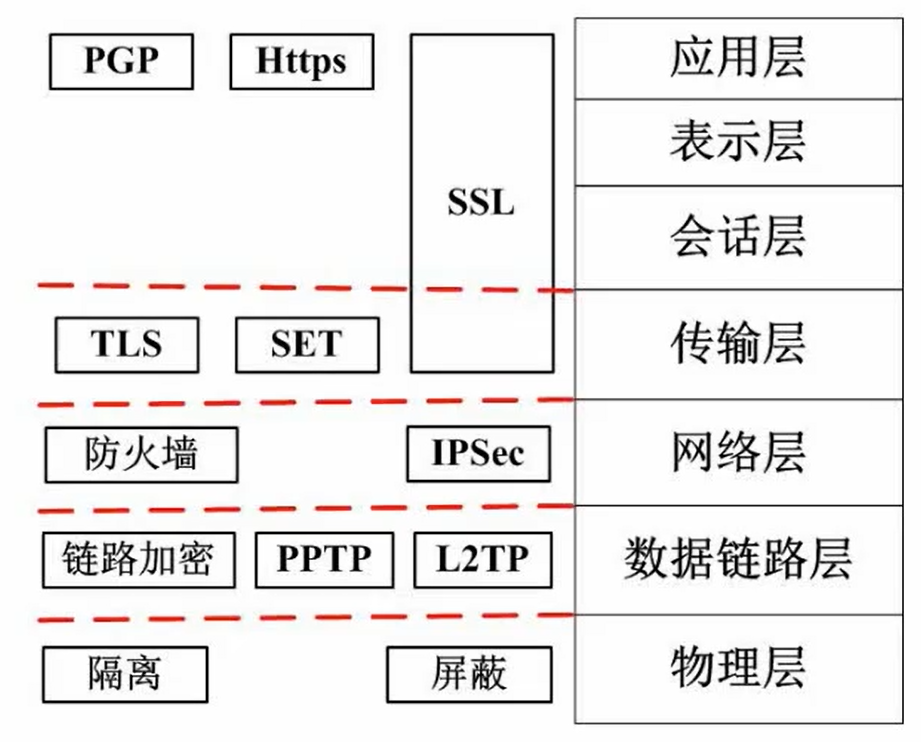
5.4 网络威胁与攻击(概念细节记清)

ARP:
DOS:
窃听和业务流:业务流除了监听还有分析的成分在

旁路控制:用到系统的缺陷
授权侵犯:授权不合理,内部攻击
防火墙
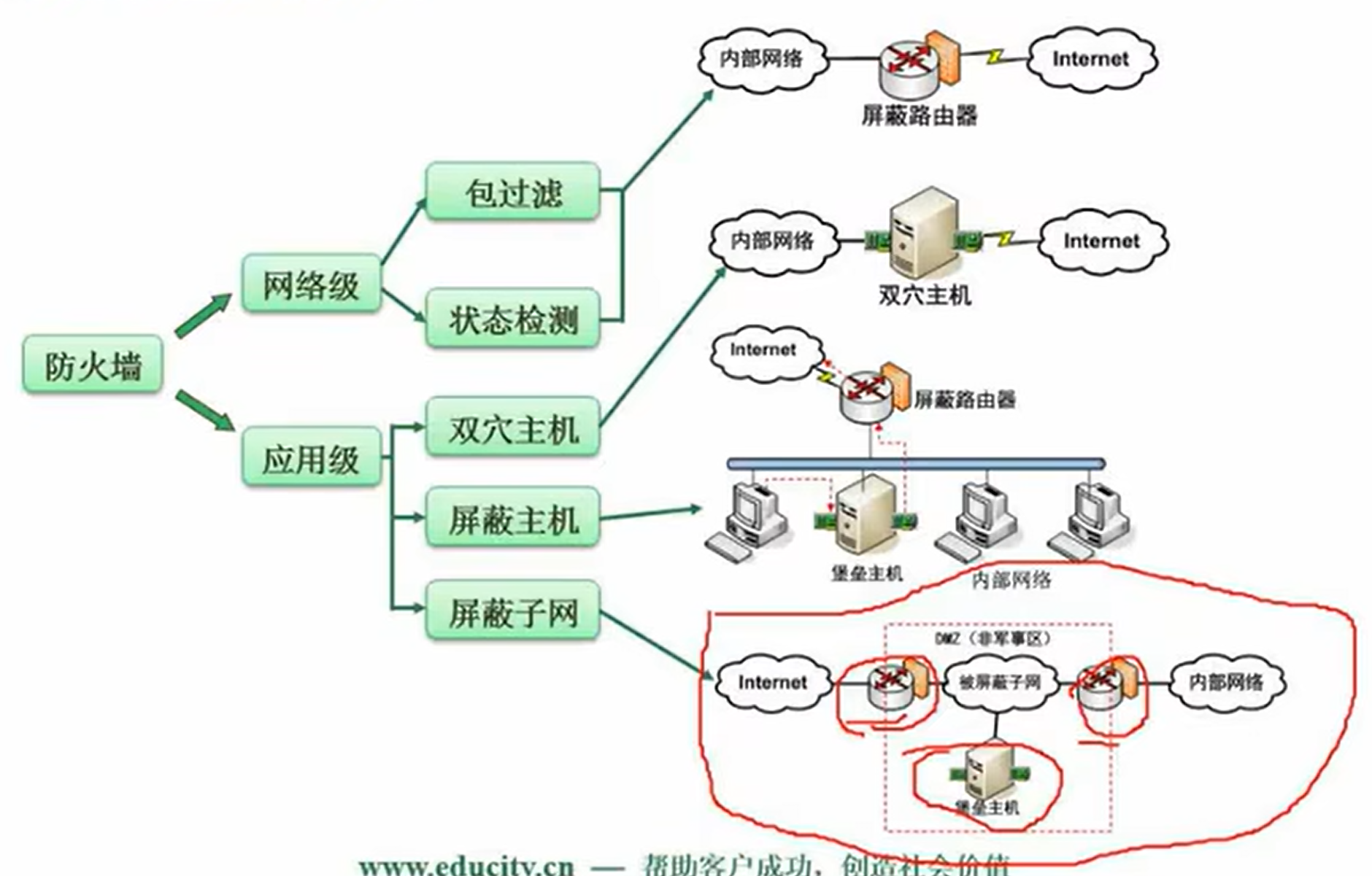
5.5 病毒
1、引导型病毒:引导型病毒隐藏在磁盘内,在系统文件启动前已经驻留在内存中。主要感染磁盘的引导区,影响软盘或硬盘的引导扇区
2、文件型病毒:通常感染执行文件(包括exe和com文件等)但也有些会感染其他可执行文件(如dll和scr等)。每次执行受感染的文件时电脑病毒就会发作,电脑病毒会将自己复制到其他可执行文件,并且继续执行原有的程序,以免被用户所察觉
3、宏病毒:专门针对特定的应用软件,可感染依附于某些应用软件内的宏指令,他很容易通过电子邮件附件、软盘、文件下载和群组软件等多种方式进行传播如Microsoft Word和Excel。
4、蠕虫病毒:蠕虫病毒一般是通过复制自身在互联网环境下进行传播,它的传染目标是互联网内的所有计算机,局域网条件下的共享文件夹、电子邮件Email、网络中的恶意网页、大量存在着漏洞的服务器等都成为蠕虫传播的良好途径。蠕虫病毒的传播过程一般表现为:蠕虫病毒程序驻于一台或多台机器中,它会扫描其它机器是否有感染同种计算机病毒,如果没有,就会通过其内建的传播手段进行感染,以达到使计算机瘫痪的目的。
5、特洛伊木马型病毒:是一种秘密潜伏的能够通过远程网络进行控制的恶意程序,控制者可以控制被秘密植入木马的计算机的一切动作和资源,是恶意攻击者进行窃取信息等的工具。但是特洛伊木马没有复制能力,也就是该病毒没有传染性,这是它与其他病毒不同的地方,它主要是通过将自身伪装起来,吸引用户下载执行。
6、CIH病毒:CIH病毒是一种能够破坏计算机系统硬件的恶性病毒,但是CIH病毒只在Windows95/98和Windows Me系统上发作,影响有限。
6. 数据结构与算法基础(10)
数据结构:存储和组织数据的方式。
数据逻辑结构:
6.1 数组与矩阵
存储地址计算
一维
二维:根据按行还是按列分类计算。
稀疏矩阵
稀疏矩阵对应下标。选特殊值代入计算。

6.2 线性表(重点是栈和队列)
线性结构的基本表现。
-
顺序表和链表
- 链表删除、插入
- 双向链表删除、插入
-
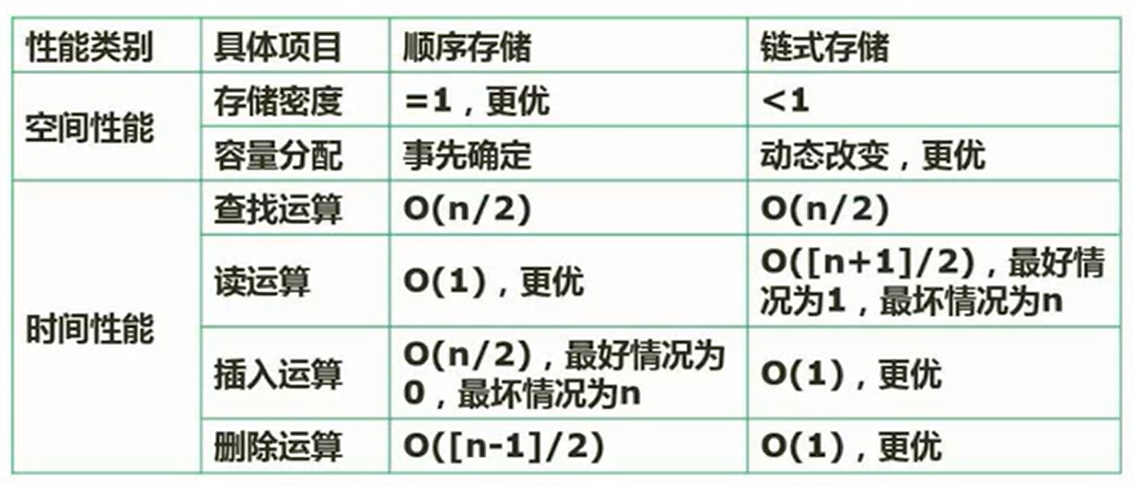
顺序存储与链式存储
-
队列和栈
- 队列:先进先出
- 栈:先进后出
-
循环队列
- 队满条件:(tail+1)%size=head
6.3 广义表(了解)
线性表的推广
长度:最外层的表最大元素量
深度:嵌套的次数
取数:表头是第一个元素,标尾是除了标头以外的全部合成一个广义表

6.4 树和二叉树
一些概念:
- 度:有几个孩子节点
- 内部结点:不是根节点也不是叶子结点
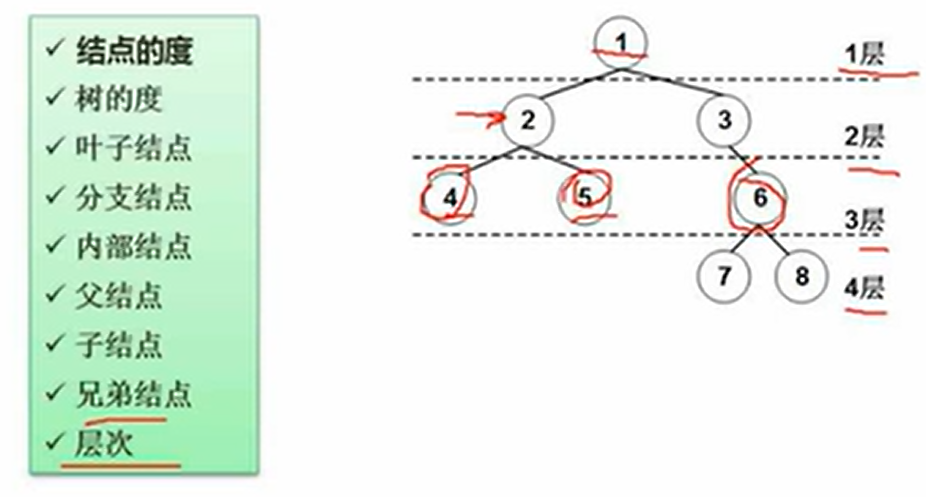
二叉树
满二叉树:
完全二叉树:除了最后一层都是满的,且最后一层空的只在右边

-
几种遍历方法。
-
构造二叉树:有前序中序或中序后序可以构造出二叉树(逐步找根)
树转二叉树:

左边第一个子树作为左子节点
查找二叉树
二叉排序树:左小右大,前序遍历为递增数列

插入:
删除:当有两个子节点时,取的是左边的最右(即比删除的节点小的当中最大的)
哈夫曼树(最优二叉树)
用来哈夫曼编码(压缩编码方式)
6.5 图(了解)
6.6 排序与查找
6.7 算法基础和常见算法
7. 程序设计语言与语言处理程序基础(6)
7.1 编译与解释
7.2 文法
7.3 正规式
7.4 有限自动机
7.5 表达式
7.6 传值与传址
7.7 多种程序语言特点
8. 法律法规(2)
9. 多媒体基础(3)
10. 软件工程(11)
10.1 开发模型

-
瀑布模型(SDLC):
- 瀑布模型的主要困难在于需求分析难以一开始就明确,所以瀑布模型适合需求明确,或者二次开发的项目。
- 软件计划——需求分析——软件设计——程序编码——软件测试——运行维护
-
原型模型(针对需求不明确的项目)
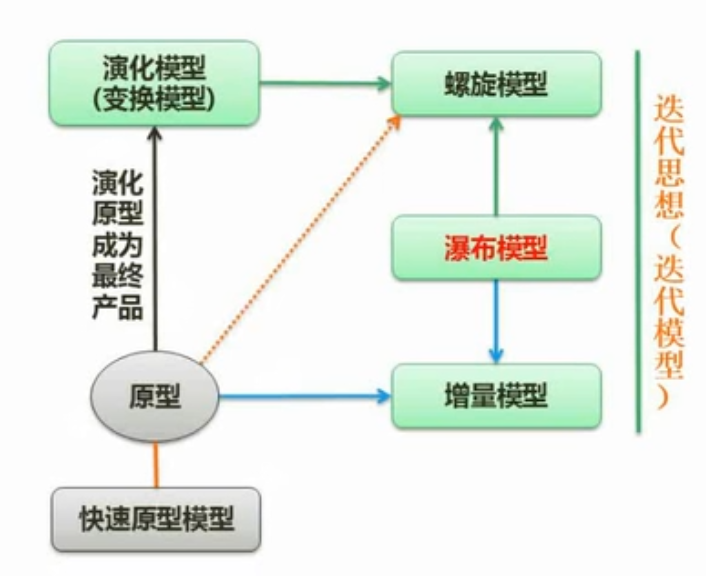
- 先用建议系统用于商讨需求,主要用于需求分析阶段。
- 原型模型结合瀑布模型则为增量模型(先做简易模型,然后修正优化迭代)
-
螺旋模型

- 不如原型灵活,但也具备原型特征。
- 引入风险分析
-
V模型

- 测试起着更重要作用
-
喷泉模型
- 针对面向对象的模型
-
RAD
- 结合构件开发
-
构件组装模型(CBSD)
- 思想:把软件开发的各个过程做成标准构建,再组装。提高软件开发的速度性,提高软件可靠性,缩短时间。模块化设计,专业的事交给专业的人做
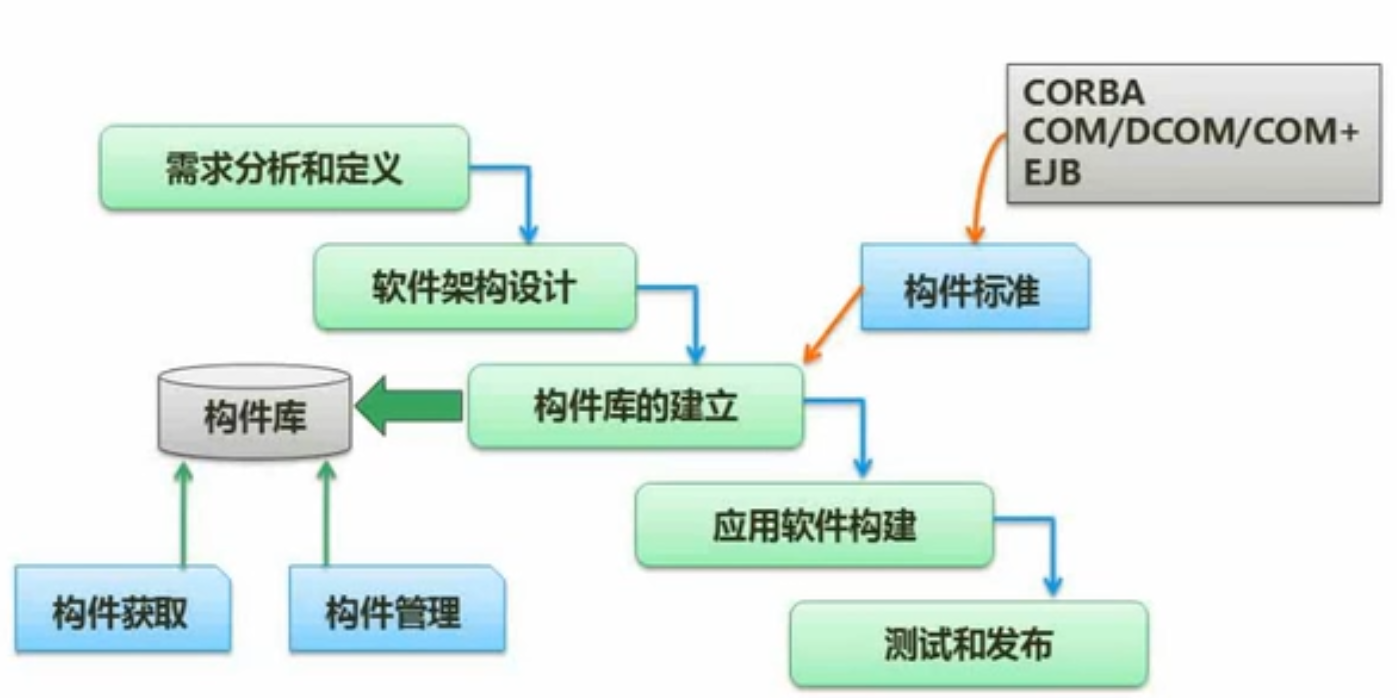
-
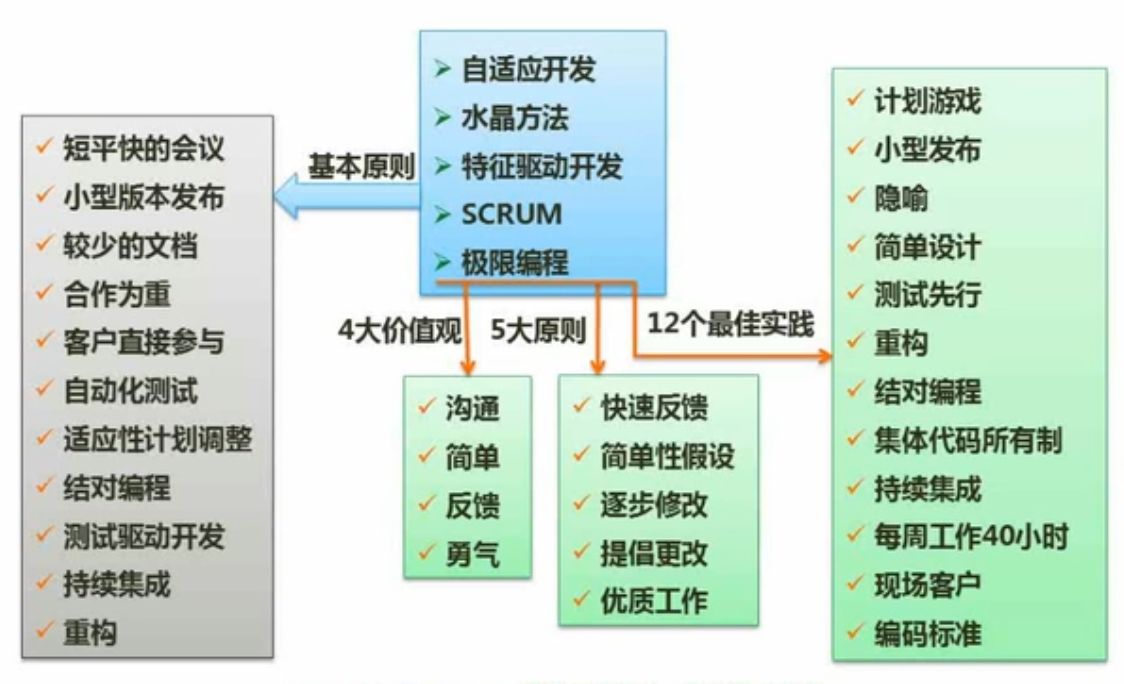
敏捷开发方法
10.2 信息系统开发方法(4)
四种:结构化方法、原型方法、面向对象方法、面向服务方法。
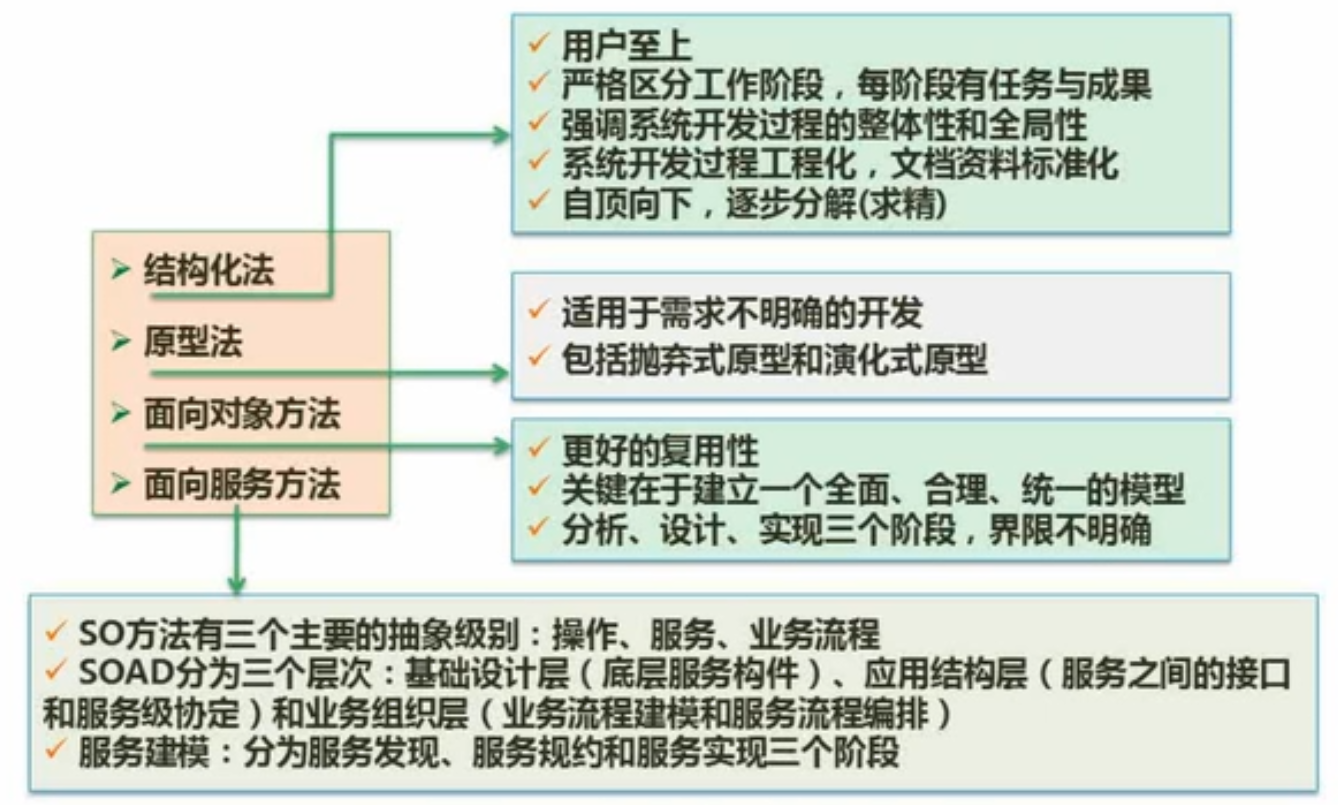
面向对象比结构化法复用性更强
10.3 需求工程
- 需求开发:
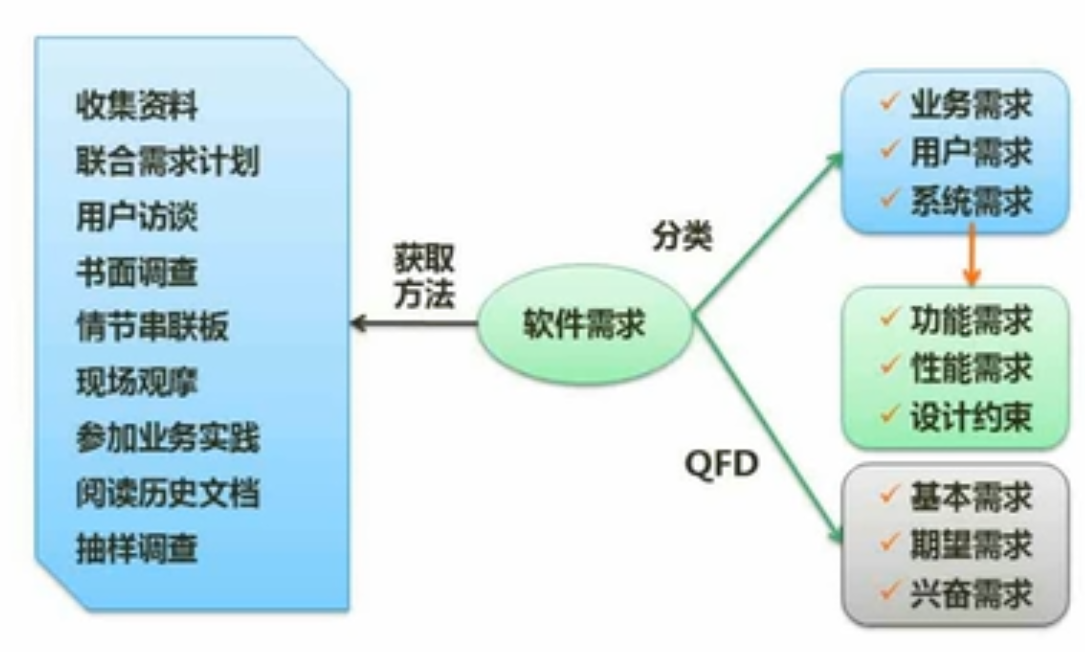
设计约束:除了功能和性能需求以外的约束,例如用户的使用要求(比如使用的语言)
10.4 结构开发
结构化设计:概要设计和详细设计
- 模块大小适中
- 减少调用深度
- 多扇入少扇出
- 单入口单出口
- 作用域在模块之内
- 功能应该可预测

内聚和耦合

10.5 软件测试与运维
测试原则和类型
- 尽早、不断的进行测试
- 程序员避免测试自己设计的程序
- 既要选择有效、合理的数据,也要选择无效、不合理的数据
- 修改后进行回归测试
- 未发现的错误数量与该程序已发现错误数成正比

桌前检查:程序员写完自查一遍
测试用例设计
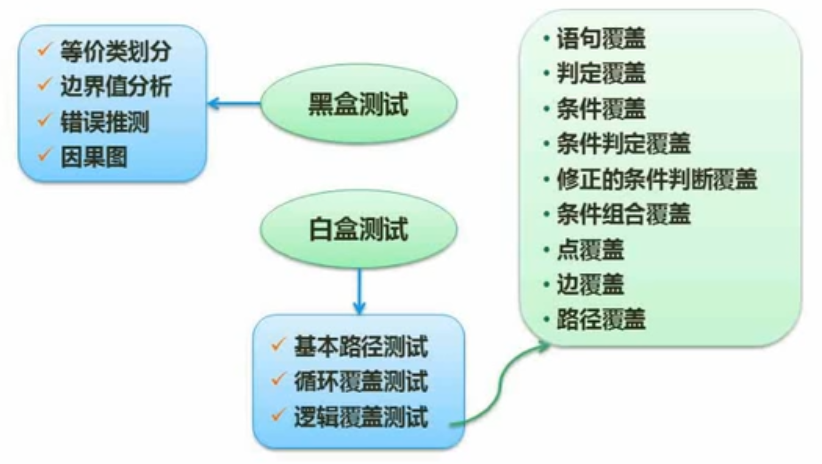
等价类划分:从功能划分设计测试用例
测试阶段
单元测试(模块、函数测试,局部功能和结构)
集成测试(一次性组装、增量式组装)
确认测试(内部确认测试、Alpha测试、Beta测试、验收测试)
系统测试

McCabe复杂度计算
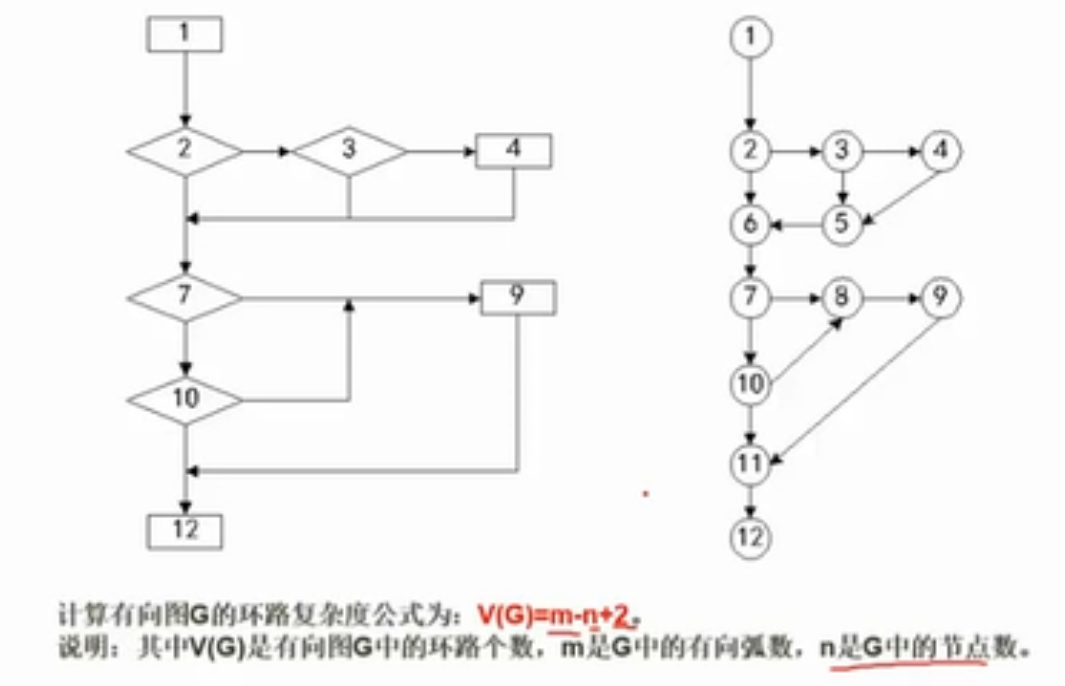
环路复杂度:弧线-节点+2
分叉也要抽象为节点(其实抽不抽象算的结果不变)。
10.6 项目管理(考的少)
系统运行与维护(周期最长)

完善性:扩充功能
软件能力成熟度模型集成(CMMI)
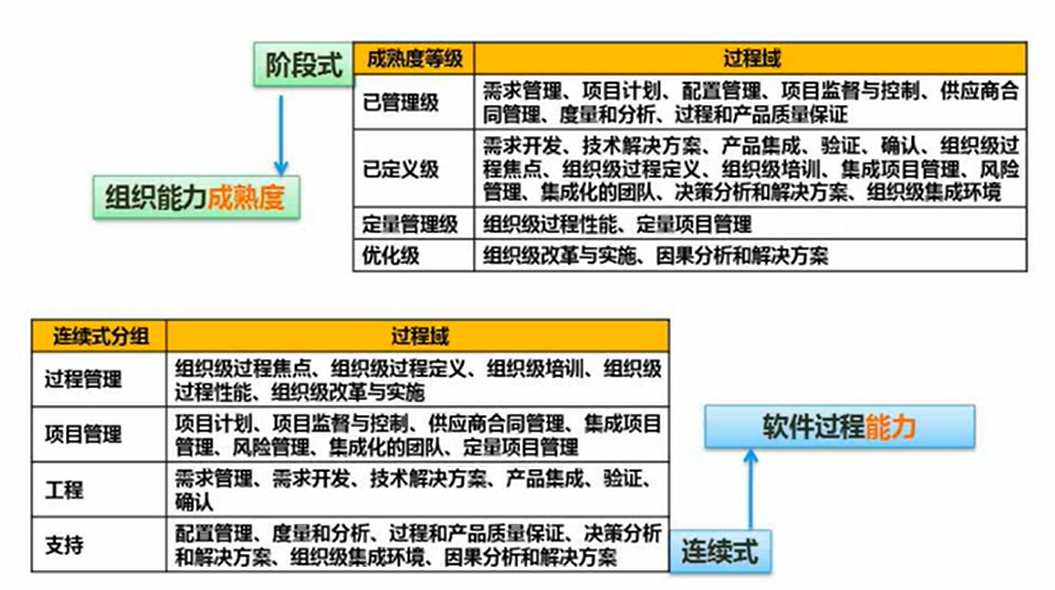
已管理级上一级是混乱级,共五级
项目管理基础知识

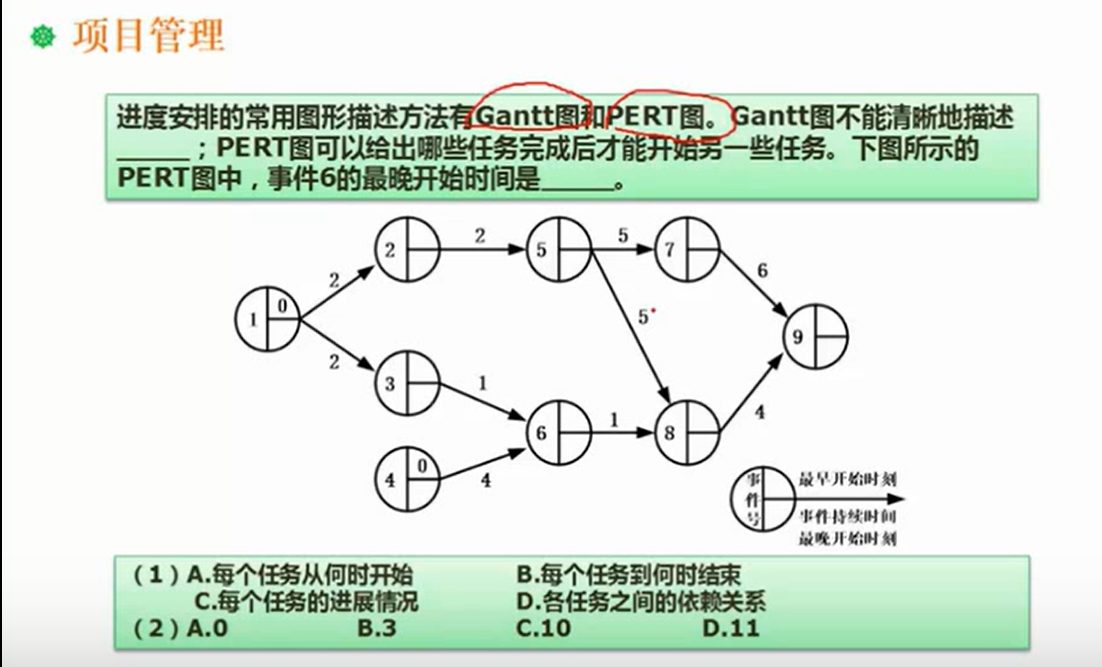
甘特图和PERT图
- pert图关键路径计算(开始到结束的最长路径,对应项目的最短工期)
- 甘特图特点和缺陷(没有依赖信息)
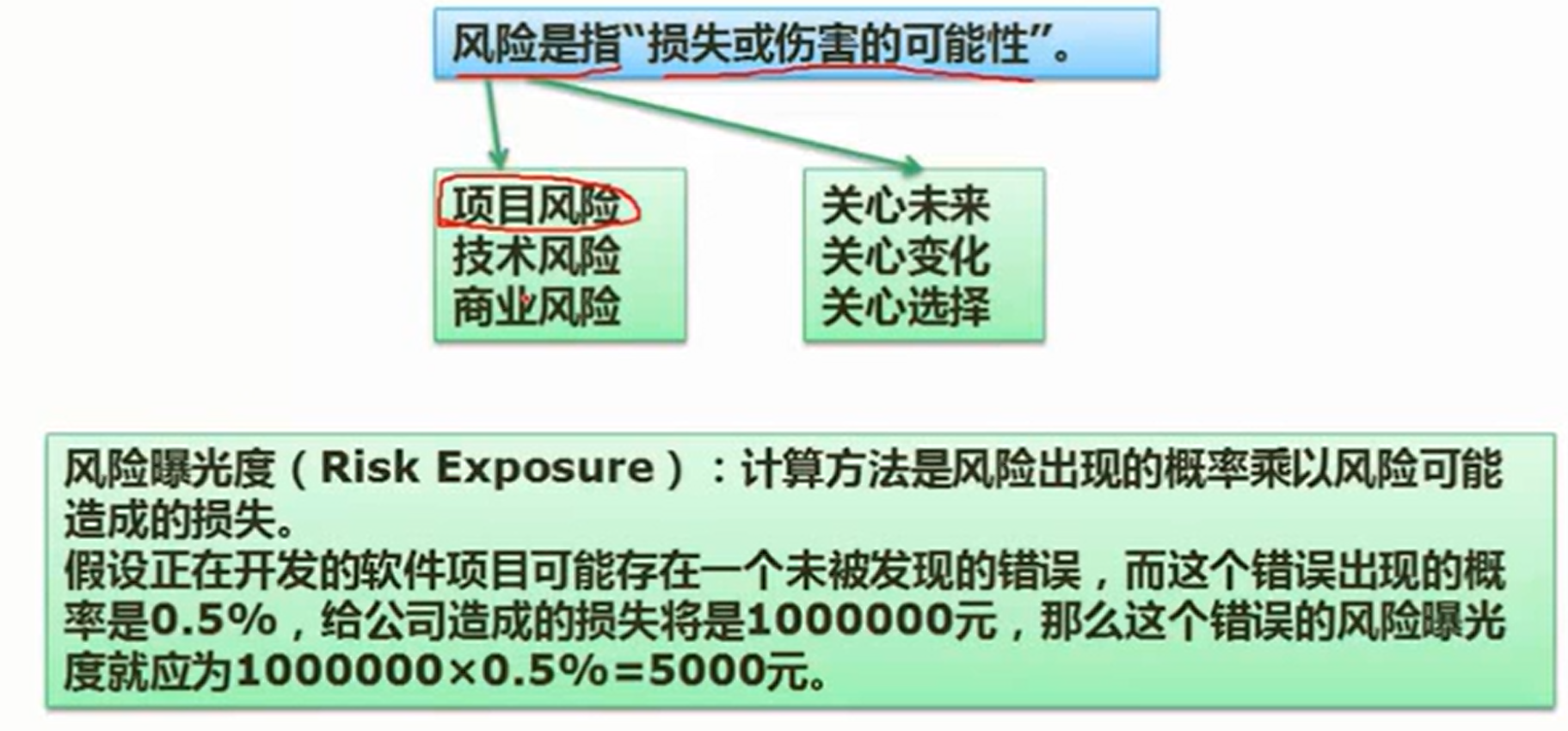
期望*损失
缺少的部分
ISO/IEC软件质量模型
11. 面向对象系统设计(12)
11.1 面向对象基本概念
- 封装继承多态:三大特性
- 对象:抽象为对象,对象的特征成为属性
- 类:抽象对象的共性
- 实体类:与数据对应的类
- 边界类:系统边界用于连接外部的类
- 控制类:类与类之间是有连接的,需要进行控制的
- 抽象
- 封装:只暴露出接口,只能由接口操作
- 继承与泛化:子类继承父类相关特性,多个类的共性泛化出上层类
- 多态:同样的操作,控制的可能是不同的对象,操作会有差异。
- 接口:一种特殊类,只有方法的声明没有实现
- 消息:进行对象之间的通信
- 组件:构件
- 模式与复用:设计模式之类的
11.2 设计原则

- 单一职责原则:降低耦合程度
- 开放-封闭原则
- 李氏替换原则(减少重载、修改):子类可以替父类
- 依赖倒置原则
- 接口隔离原则
- 组合重用原则
- 迪米特原则:最少知识法则(封装)
11.3 UML
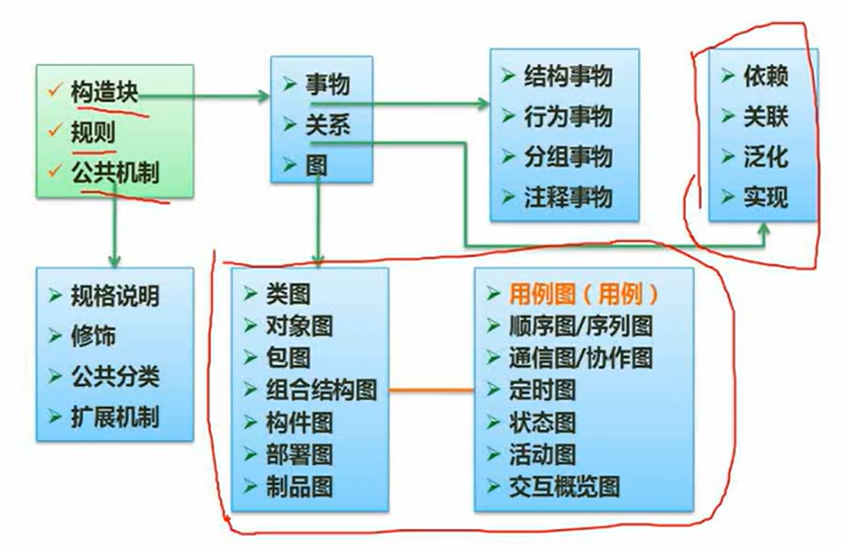
规则和公共机制没考过,构造块重要
结构图(静态)和行为图(动态)
部署图是讲软件的固件应该在哪个硬件上。
行为图:
- 用例图:系统功能和外界用户的交互
- 顺序图:按时间顺序
- 通信图:不强调时间顺序
- 定时图
- 状态图:状态变迁
- 活动图:流程图
- 交互概览图
11.4 设计模式
- 架构模式:软件设计中从全局决策,例如C/S架构,SOA架构,B/S架构。反应开发软件系统过程中所作的基本设计决策)
- 设计模式:主要关注软件系统的设计,与具体的实现语言无关
- 惯用法(看是否与语言相关):每种语言有自己特定的惯用法。
设计模式分类
- 创建型模式
- 工厂方法模式
- 抽象工厂模式
- 原型模式
- 单例模式
- 构造器模式
- 结构型模式
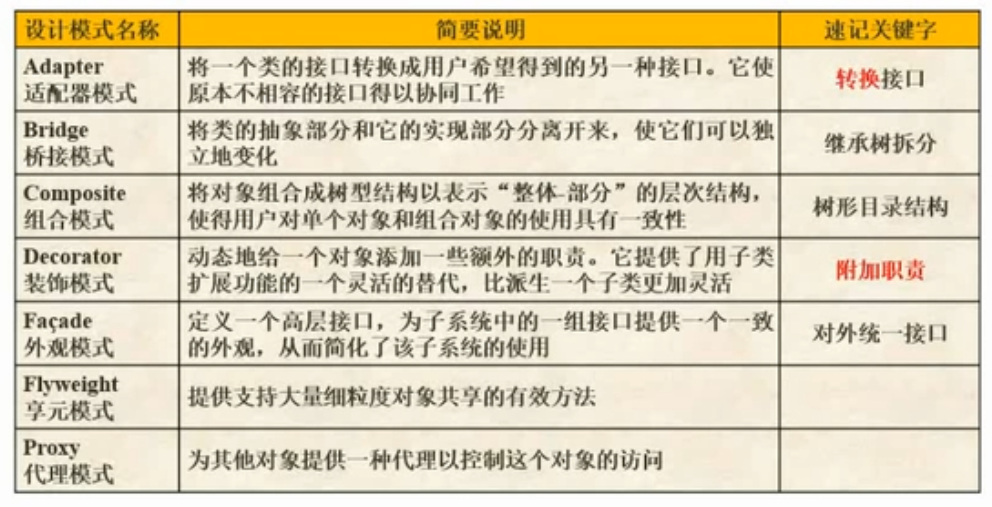
- 适配器模式
- 桥接模式
- 组合模式
- 装饰器模式
- 外观模式
- 享元模式
- 代理模式
- 行为型模式
- 职责链模式
- 命令模式
- 解释器模式
- 迭代器模式
- 中介者模式
- 备忘录模式
- 观察者模式
- 状态模式
- 策略模式
- 模板方法模式
- 访问者模式
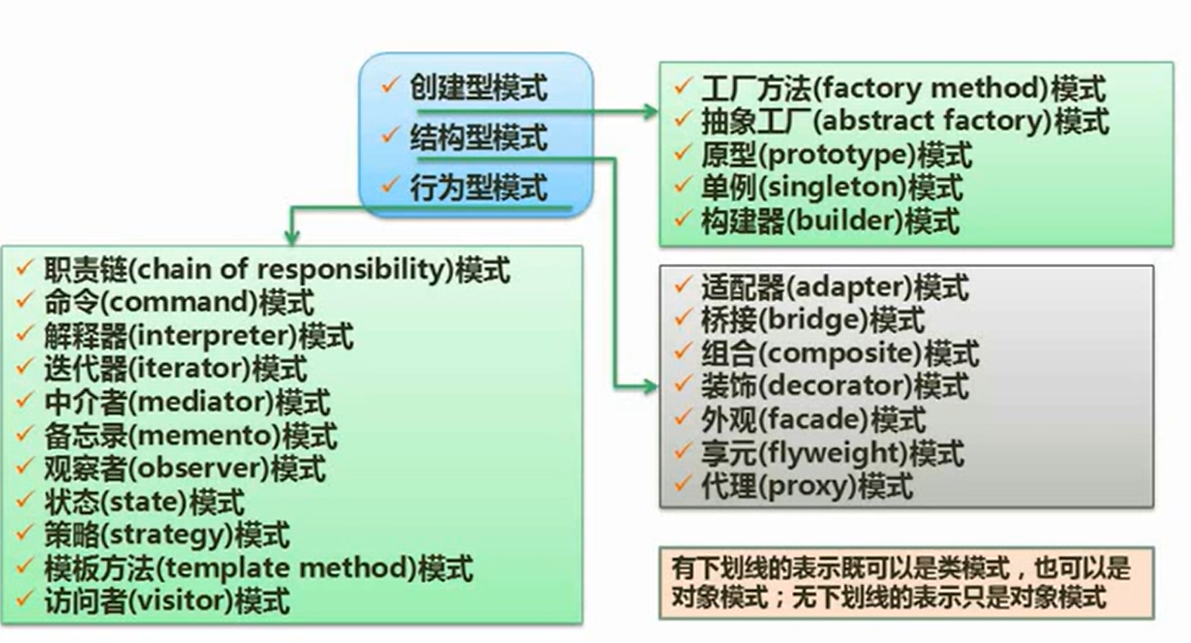
1. 创造型模式(5)

工厂方法:在运行时再决定生成什么类的对象
2 结构型模式(6)
3. 行为型模式(11)




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!