windows下使用LTP分词,安装pyltp
1.LTP介绍
ltp是哈工大出品的自然语言处理工具箱, 提供包括中文分词、词性标注、命名实体识别、依存句法分析、语义角色标注等丰富、 高效、精准的自然语言处理技术。pyltp是python下对ltp(c++)的封装. 在linux下我们很容易的安装pyltp, 因为各种编译工具比较方便. 但是在windows下需要安装vs并且还得做一些配置,但是经过本人查阅资料总结了一种不需要安装c++的方法。
2.windows下安装pyltp
想使用LTP进行nlp的任务,第一步就是要需要安装一个pyltp的包,如果直接pip insatll pyltp的话,很大概率时会报错的,所以本人使用另一种方法安装,那就是安装轮子文件(whl文件):
第一步:创建python3.6或者3.5
检查自己的电脑上是否有python3.6或(3.5)环境(python3.8不支持这种安装),如果没有python3.6(3.5)环境的话,需要先安装python3.6(3.6),最简便快捷的方法就是使用anaconda来安装,在你的电脑安装了anaconda的前提下,打开win+r输入cmd进入命令窗,输入
conda create --name python36 python=3.6 #这样你就创建了一个新的python3.6环境
注意,在创建的时候会出现创建失败的问题,具体问题有一堆如下的解释:
UnavailableInvalidChannel: The channel is not accessible or is invalid.
channel name: anaconda/pkgs/free
channel url: https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
error code: 404
这是因为清华园关闭了anaconda的服务,此时你需要输入以下指令恢复设置:
conda config --remove-key channels
回复完毕以后,继续上面的创建指令,就可以完成python环境的创建了。
在创建的时候会出现一个选择,直接输入 y 就好了。这样你的python环境就创建完毕了,你可以进入你的anaconda安装目录下,进入scripts文件就可以看到你的新环境了。
第二步:下载whl文件
python3.5:pyltp-0.2.1-cp35-cp35m-win_amd64.whl
python3.6:pyltp-0.2.1-cp36-cp36m-win_amd64.whl
根据上一步创建的python环境选择相应的whl文件,最好是单独创建一个文件夹来存放这些whl文件。
第三步:安装whl文件
这一步需要先进入到你创建的环境中去:
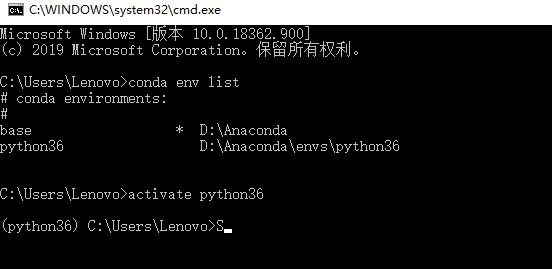
输入
conda env list
检查你的环境列表,然后输入
activate XXX(你的环境名字)
进行激活,在进入到你的环境之后需要转到你上一步存放whl文件的目录,进行安装:
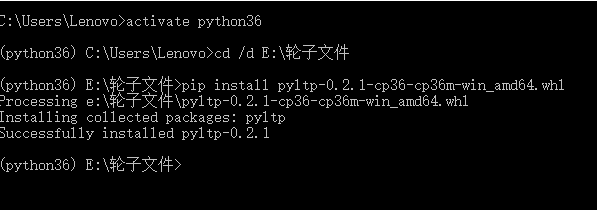
使用:
cd /d E:\轮子文件
直接进入到你存放whl的文件夹,然后使用pip install 进行安装。注意!!安装的时候,一定要加whl后缀,不然会报错
pip install pyltp-0.2.1-cp36-cp36m-win_amd64.whl
至此,whl安装完毕
第四步:下载模型
模型地址:哈工大语言云,我下载的是3.4版本的模型,下载好的模型解压到自己创建的一个文件夹里面。
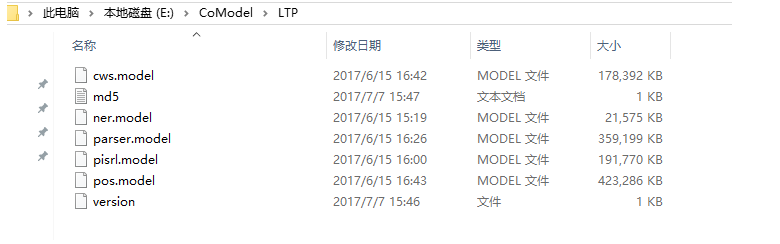
这里我为了方便使用,单独建了一个专门用于存放网上下载的模型的文件夹CoModel,然后将下载下来的ltp模型ltp_data_v3.4.0解压后拿出来,然后放到新建的一个叫做LTP的文件夹里面,可以看到里面有多个模型:
| 文件名 | 模型 |
|---|---|
| cws.model | 分句模型 |
| ner.model | 命名实体识别模型 |
| parser.model | 依存句法分析模型 |
| pisrl.model | 语义角色标注模型 |
| pos.model | 词性标注模型 |
接下来,你就可以在你的程序里面调用这个模型了~~
注意!
本人使用的是pycharm,在pycharm中选择解释器的时候一定要选择你第一步的环境(也就是你所安装pyltp的环境),我没用创建虚环境而是直接使用的python36环境,如果你想使用虚环境,在第一步的时候就要创建为虚环境:
conda create -n venvname python=3.6
最后附上自己分词和词频统计的程序
# -*- coding: utf-8 -*-
from pyltp import Segmentor
import json
import re
def clean(path): # 定义数据清理函数
with open(path, encoding='UTF-8') as f:
strs = ''
for line in f.readlines(): # 读取每一行,并将所有行存到一个strs里
dict = json.loads(line)
str = json.dumps(dict, ensure_ascii=False)
strs += str
strs_clean1 = strs.replace(' ', '') # 去掉文本中的空格
pattern = re.compile("[A-Z0-9元年月日\"\"{}::;,,、。.%%¥()《》—]")
# pattern = re.compile("^\d{1,9}$")
strs_clean2 = re.sub(pattern, '', strs_clean1) # 去掉文本中的数字和字母、符号等
return strs_clean2
def stopwordslist(filepath): # 定义函数创建停用词列表
stopword = [line.strip() for line in open(filepath, 'r',encoding='utf-8').readlines()] # 以行的形式读取停用词表,同时转换为列表
return stopword
def word_splitter(sentence): # 分词
segmentor = Segmentor() # 初始化实例
segmentor.load('./LTP/cws.model') # 加载模型
words = segmentor.segment(sentence) # 分词
words_list = list(words)
segmentor.release() # 释放模型
return words_list
def get_TF(wordslist):
TF_dic={}
for word in wordslist:
TF_dic[word] =TF_dic.get(word,0)+1
# 在字典中查找word的值,该list中的值都为none,找到了就加1,第二次找到就为2...最终返还的是一堆键的值
# print(TF_dic) # 打印键值
return sorted(TF_dic.items(),key=lambda x:x[1],reverse=True) # True:降序
#将字典定义为迭代器,[('word1',value1),('word2',value2)....]然后按照元组的[1]的值(value)来排序
data = clean('DataSet/testsp.json')
print('清洗后的数据:')
print(data)
words_list = word_splitter(data) # 分词后的结果
stopwords = stopwordslist('./DataSet/中文停用词表.txt')
words_clean =[word for word in words_list if word not in stopwords] # 去除停用词
print('去除停用词后的分词:')
print(words_clean)
result = str(get_TF(words_clean))
print(result)
运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号