阅读笔记——长文本匹配《Matching Article Pairs with Graphical Decomposition and Convolutions》
论文题目:Matching Article Pairs with Graphical Decomposition and Convolutions
发表情况:ACL2019 腾讯PCG小组
模型简介
模型如图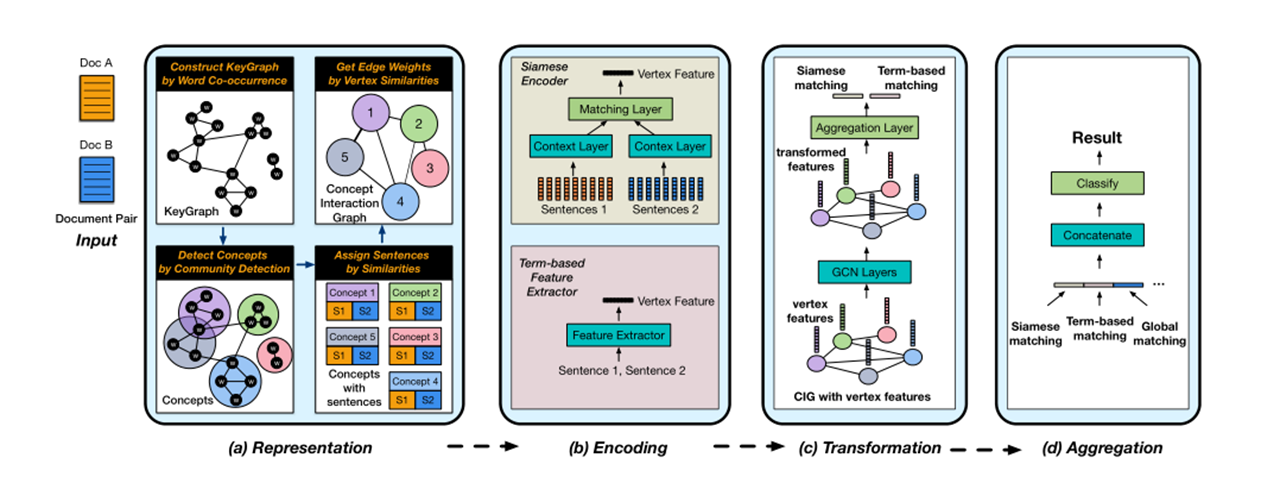
本文的工作是基于概念图 Concept Interac-tion Graph (CIG)来做的,关于CIG的详细解释可以参看腾讯发的另一篇论文:A User-Centered Concept Mining System for Query and Document Understanding at Tencent。
模型的输入是文档级别的,具体来说就是以一对粒度为文档级别的长文本。
1.KeyGraph构建
对于给定的文档D,首先利用TextRank来提取命名实体和关键字,然后根据找到的关键词构建共现图,如果两个关键字同时出现在同一句子中,我们将它们用边连接起来。
2.Concept检测(可选)
如果关键字的子集高度相关,则它们将在KeyGraph中形成紧密连接的子图,我们称之为概念。可以通过在构造的KeyGraph上应用社区检测算法来提取概念,这实际上是一个关键词聚类的过程,对于可能出现在多个概念中的关键词,使用度中心性来进行评分。但是这一步时可选择的,也可以直接用关键词来作为概念,但是匹配速度会有所减慢。
3.句子附加
对文档Da,Db的句子分别与各个概念计算余弦相似度(向量由TF-IDF表示),这样每个概念就得到分别对应文档Da,Db的两个句子集。与文档中任何概念都不匹配的句子将附加到不包含任何关键字的虚拟顶点。
4.边的构建
任意两个顶点之间的边权重,是由它们的句子集之间的TF-IDF相似度表示的。
5.节点匹配特征编码
对每个节点上的文本对(来自两篇文章的句子集合分别进行拼接)进行匹配,得到匹配特征。我们分别尝试了 Siamese Encoder 自动学习匹配特征:将两个句子集(序列的word embeddings)送入共享相同权重的上下文层将它们编码为两个上下文向量,CA(v),CB(V),然后通过公式\(mAB(v) = (|cA(v) − cB(v)|,cA(v) ◦ cB(v))\),得到节点特征;计算各种 term-based 特征来作为节点特征向量:TF-IDF余弦相似度,TF余弦相似度,BM25余弦相似度,1-gram的Jaccard相似度和Ochiai相似度,拼接\(m'AB(v)\),得到匹配向量\(x_{i}\)。
6.通过GCN进行节点特征的转化
GCN的输入为X与A,其中\(X=\left \{ x_{i} \right \}_{i=1}^{N}\),A是一个邻接矩阵,\(A_{ij}= w{_{ij}}\),对于GCN来说某一隐藏层可以表示为:\(f\left ( H^{(l)},A \right )=\sigma \left ( \hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}H^{(l)}W^{(l)}\right )\),\(\hat{A}\)是A加上一个单位矩阵得来的,\(\hat{D}\)是一个对角阵,\(\hat{D}_{ii}= \sum _{j}\hat{A}{_{ij}}\)。我们将最终经过GCN转化后的特征,整合成一个向量(这里采用了 mean aggregation),即获取最后一层中所有顶点的隐藏向量的平均值。
7.整合分类
在经过GCN层转化后,所得到的向量还可以拼接一些全局的特征,例如通过使用最新的语言模型(例如BERT)直接编码两个文档或直接计算它们term-based的相似度。但是论文实验部分证明这样的全局特征几乎无法给我们的方案带来更多好处,因为图形合并的匹配向量已经在我们的问题中充分表达了。我们将这些最终整合的特征向量,通过分类网络(例如多层感知器(MLP))进行计算,得到匹配分数。
结束
由于只是泛读了这篇文章,没有对实验和代码进行深入分析,想了解更多的可以去看原文。
相关链接:
论文地址:https://arxiv.org/abs/1802.07459

 浙公网安备 33010602011771号
浙公网安备 33010602011771号