
论文笔记——事件抽取之DMCNN
1.事件抽取介绍:
事件在不同领域中有着不同的含义,对于事件目前还没有统一的定义。在IE ( Information Extraction) 中,事件是指在某个特定的时间片段和地域范围内发生的,由一个或多个角色参与,由一个或多个动作组成的一件事情,一般是句子级的,事件抽取技术是从非结构化的信息中抽取出用户感兴趣的事件,并以结构化的形式呈现给用户。根据ACE2005 评测,组成事件的各元素包括: 触发词(event trigger)、事件类型(event type)、论元(event argument)及论元角色(argument role)。事件抽取任务可分解为4 个子任务: 触发词识别、事件类型分类、论元识别和角色分类任务。其中,触发词识别和事件类型分类可合并成事件识别任务。论元识别和角色分类可合并成论元角色分类任务。事件识别判断句子中的每个单词归属的事件类型,是一个基于单词的多分类任务。角色分类任务则是一个基于词对的多分类任务,判断句子中任意一对触发词和实体之间的角色关系。
2.摘要:
ACE事件提取任务的传统方法主要依靠精心设计的功能和复杂的自然语言处理(NLP)工具。这些传统方法缺乏通用性,需要大量的人工,并且易于出现错误传播和数据稀疏性问题。本文提出了一种新颖的事件提取方法,其目的是在不使用复杂的NLP工具的情况下自动提取词汇级和句子级特征。本文引入了一种词表示模型来捕获词的有意义的语义规律,并采用基于卷积神经网络(CNN)的框架来捕获句子级线索。但是CNN只能捕获句子中最重要的信息,并且在考虑多个事件句子时可能会丢失有价值的事实。本文提出了一种动态多池化卷积神经网络(DMCNN),它根据事件trigger和argument使用一个动态多池化层来保留更多关键信息,实验结果证明本文的方法比其他最好的方法(SOTA)都要明显地好。
3.任务与创新:
本篇论文将事件抽取分为两个子任务:1.trigger classification:利用DMCNN将句子中trigger word识别出来,若句子中存在触发词则进行第二步;2.argument classification:利用一个相似的DMCNN去识别arguments,并且识别出这些arguments对应的roles。
本文提出了一种新颖的事件提取框架,该框架可以自动从纯文本中引入词汇级和句子级功能,而无需复杂的NLP预处理;设计了一个动态多池化卷积神经网络(DMCNN),目的在于在捕获句子中更有价值的信息以进行事件提取;在广泛使用的ACE2005事件提取数据集上进行了实验,实验结果表明本文的方法优于其他最新方法。
4.模型介绍:
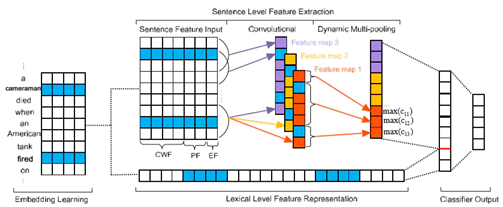
图片一:argument classification体系结构。其中触发词:fired,候选论元:cameraman
本篇论文两个子任务的模型结构是一样的,任务二argument classification相比于任务一有更多的特征信息,故文中主要对任务二的情况进行了记录,后面会阐述两个任务的DMCNN的不同。
- embedding learning和lexical-level feature representation
本文以无监督的方式得到词的嵌入向量,具体是用Skip-gram在NYT预料上训练得到,得到所有词的embedding后,进行触发词的向量、候选论元的向量、以及他们的左右相邻的词向量首位逐个拼接得到lexical-level feature representation,这也是模型的input之一。
- sentence-level feature extraction与卷积、Dynamic Multi-Pooling:
句子级的向量使用了三种向量拼接:Context-word feature(上下文词向量,维度为dw,模型中的例子维度为4)、Position feature(当前词语与预测trigger以及候选argument之间的相对距离的向量,维度为dp,文中没有具体展开讲解如何求解这个PF,但是可以知道的是采用的是相对位置信息,可以简单地认为就是位置距离:以 cameraman 为例,则a:-1,cameraman:0,died:1,when:2,an:3,等,也可以参考transformer中的PE编码方式)、Event-type feature(事件类型编码的向量,维度为de),最后三种向量拼接后形成一个新的向量,其中每一个词向量的维度为:d=dw+dp*2+de,若句子的长度为n则整个拼接向量的大小就是n*d。
卷积部分,设置h个词大小的窗口,filter大小就为h*d,本文实验部分选取的参数为:h为3,卷积核数为300,步长为1。多个filter与这个n*d大小的矩阵进行卷积后得到对应个数feature maps,结构语义信息被压缩到这些 feature map 中,不同的filter可能学习到不同的信息,比如一个 filter学 compositional feature,一个学习词依赖,一个学习构词法等。对于m个filter$( W = w1,w2,...,wm)$,则卷积运算可以表示为:$c_{ji}= f\left ( w_{j}\cdot x_{i:i+h-1}+b_{j} \right )$,卷积的结果是一个矩阵C,大小为$m*(n-h+1)$。
动态池化部分是论文的一个创新之处,传统的pooling策略有:max pooling即原来最大池化将一个经过卷积之后生成的特征序列池化成1个值,和average pooling ,而动态多池化操作则是使用候选论元以及触发词将每个特征图分割为3个部分(如上文模型结构图中,特征序列被“cameraman”和“fired”分成三个部分),然后每段分别做最大池化,与Chunk Max-Pooling类似,池化的过程公示为:$p_{ji}= max\left ( c_{ji} \right )$
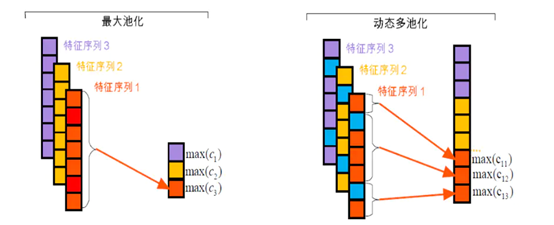
最后将所有pji连接起来形成一个向量$P∈R(3m)$,这个向量就是sentence-level feature extraction,也是整个模型的第二个input。
- argument classifier output:
将上面所讲的两个input进行拼接,得到一个新的特征向量F,然后过一个全连接层+softmax做分类,分类的结果包括各个 argument role 和 none role,为了计算每个argument role的置信度,将特征向量F大小$(3m + dl)$(其中m是feature map的数目,dl是lexical-level feature representation的维数)输入到分类器。
其中$Ws∈R[n1×(3m+dl)]$是变换矩阵,n1是argument role的个数,O就是最终的output。
- Trigger classification :
触发词的分类也用同样的模型架构,但是输入少了EF,dynamic pooling 分割时候也只根据当前 trigger candidate 进行分割,其他的都一样,这里不再赘述。
- 训练过程
本文实验中将argument classification阶段的所有参数定义为$θ=(E,P F1,P F2,EF,W,b,WS,bs)$。具体来说,E是词嵌入,PF1和PF2是位置嵌入,EF是事件类型的嵌入,W和b是filter的参数,Ws和bs是输出层参数。损失函数为交叉熵,采用随机梯度下降来更新参数θ,优化算法为AdaDelta,优化算法超参 𝜌为0.95,ε设置为$1e^-6$。
- 结果对比
![]() 从结果可以看出,本文提出的具有自动学习功能的DMCNN模型在所有比较方法中均实现了最佳性能。DMCNN可以将最先进的F1(Li et al,2013)提高到1.6%,而将自变量角色分类提高0.8%。这证明了所提出方法的有效性。
从结果可以看出,本文提出的具有自动学习功能的DMCNN模型在所有比较方法中均实现了最佳性能。DMCNN可以将最先进的F1(Li et al,2013)提高到1.6%,而将自变量角色分类提高0.8%。这证明了所提出方法的有效性。
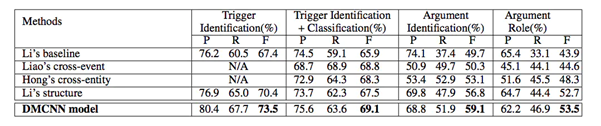 从结果可以看出,本文提出的具有自动学习功能的
从结果可以看出,本文提出的具有自动学习功能的5.总结
这篇论文提出的Dynamic multi-pooling 可以有效解决 argument candidate 可能作为多个 trigger 的 argument 但是扮演不同 role 的问题,并且对特征输入做的十分清晰,输入特征比较完整,这篇文章对事件抽取比较有启发性。
6.参考文献
- http://www.nlpr.ia.ac.cn/cip/yubochen/yubochenPageFile/acl2015chen.pdf
- https://blog.csdn.net/muumian123/article/details/82258819
- https://www.jianshu.com/p/84fd666b1900
- Li Q , Ji H , Huang L . Joint Event Extraction via Structured Prediction with Global Features[C]// Meeting of the Association for Computational Linguistics. 2013.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号