
redis的雪崩与穿透原理的浅理解
首先列一下主要说什么,
1、什么是Redis缓存的雪崩?
2、什么是Redis缓存的穿透?
3、Redis缓存崩溃会怎么样?
4、怎么预防Redis缓存崩溃?
1、什么是Redis缓存的雪崩?
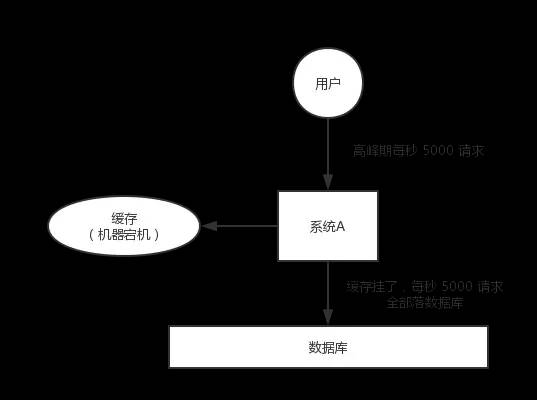
举个栗子:有系统A,每天高峰期每秒有5000个请求,缓存机抗4000,数据库最大阈值抗2000,本来系统缓存机可以抗住4000个请求,但是系统缓存机突然死翘翘宕机了,也就是缓存挂了。这个时候来的5000个请求全部砸到了数据库,远超数据库的可承受范围。数据库也可是傻眼了于是乎就业跟着挂了,系统本身也没有预制应急方案,没办法系统没有优质方案解决,重启数据库又不能有效解决,因为重启后又马上被干死了。当遇到这个场景的时候我就可以理解为缓存的雪崩。
2、缓存雪崩的解决发案
事前:Redis高可用,主从+哨兵。避免全盘崩溃。
哨兵的作用:
1、监控redis进行状态,包括master和slave ;
2、当master down机,能自动将slave切换成master;
3、双缓存。部署两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间,自己做缓存预热操作,主要思路如下:
- 从缓存A读数据库,有则直接返回;
- A没有数据,直接从B读数据,直接返回,并且异步启动一个更新线程;
- 更新线程同时更新缓存A和缓存B。
看到上边的作用,大概就知道怎么个原理了吧。可以配置多个或者一个主从。同时也可以配置多个哨兵。尽量做到有备份的效果。
缓存往往都设置有失效时间,在设置的时候需要注意避免大量缓存同时失效。可以设置缓存的有效期在某一个随机的有效期内,同时失效也在随机的一个有效期内。
具体的配置暂不说明,先把原理搞清楚了,在去实操巩固,实操部分后续补充。
事中:本地ehcache缓存+hystrix限流&降级。避免数据库被打死。
大致理解如下:系统接受到请求后先查本地ehcache再查Redis,如果都没有则再去查数据库,并同时将相关数据重新写入Redis和本地缓存中。避免下次再去请求时再访问数据库。
同时可以设置限流降级,当请求数大于系统所能够处理的请求数时,通过限流组件起到超出的部分走降级,不进行处理,确保系统核心功能一直处于可用状态。
事后:Redis做持久化处理,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
3、什么是Redis缓存的穿透?
还是举个栗子:对于系统A,假设高峰期一秒有5000个请求需要处理,结果其中4000个请求是恶意攻击所发出的。那么这4000个请求在缓存中查不到并且数据中也查不到。比如数据库存储的数据ID范围是1~500 ,而实际查询完全不在这个范围内。这样就导致每次查询的命中率为0.。这种场景就可以被理解为缓存穿透。
对此应该怎么解决呢?可以采用一种简单的方式:
1、每次系统A从数据库中要是没有查到就写一个空值到缓存,或者将查询进行标记,下次将接受的请求进行标记比对,最终要实现出现重复的或者没有空值均走缓存进行处理;
2、采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号