python并发编程
多道技术
单核实现并发的效果
必备的知识点
并发
""" 看起来像同时运行的就可以称之为并发 """
并行
""" 真正意义上的同时执行 """
PS
""" 并行肯定算并发 单核的计算机不能实现并行,但是可以实现并发!!! 补充:我们直接假设单核就是一个核,干活的就一个人,不要考虑cpu里面的内核数 ps:明星出轨 ----> 星轨 """
多道技术图解
节省多个程序运行的总耗时
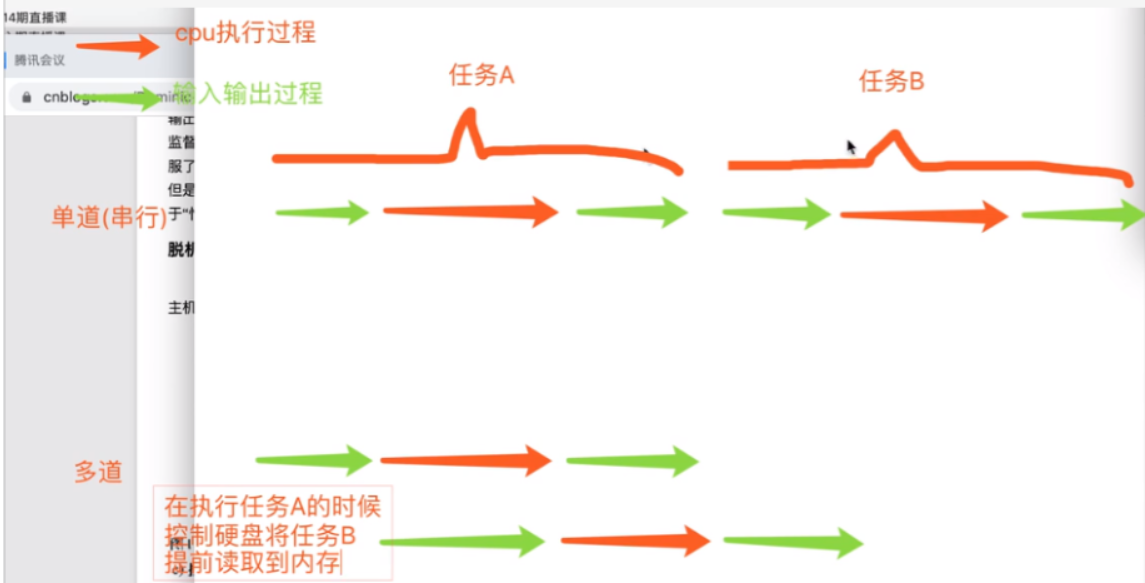
多道技术重点知识
""" 空间上的复用和时间上的复用 空间上的复用 多个程序公用一套计算机硬件 时间上的复用 例子:洗衣服30s,做饭50s,烧水30s 单道需要110s,多道只需要任务最长的那一个 节省切换时间 例子:边吃饭边玩游戏 保存状态 """
切换+保存状态
""" 切换(cpu)分为两种情况: 1、当一个程序遇到IO操作的时候,操作系统会剥夺该程序的cpu执行权限 作用:提高了CPU的利用率,也不影响程序的执行效率 2、当一个程序长时间占用CPU的时候,操作系统也会剥夺该程序的CPU执行权限 作用:降低了程序的执行效率(原本时间+切换时间) """
进程理论
程序与进程的区别
""" 程序就是一堆躺在硬盘上的代码,是‘死’的 进程则表示程序正在执行的过程,是‘活’的 """
进程的调度
""" 先来先服务调度算法 特点:对长作业有利,对短作业无益 短作业优先调度算法 特点:对短作业有利,多长作业无益 时间片轮转法+多级反馈队列 """
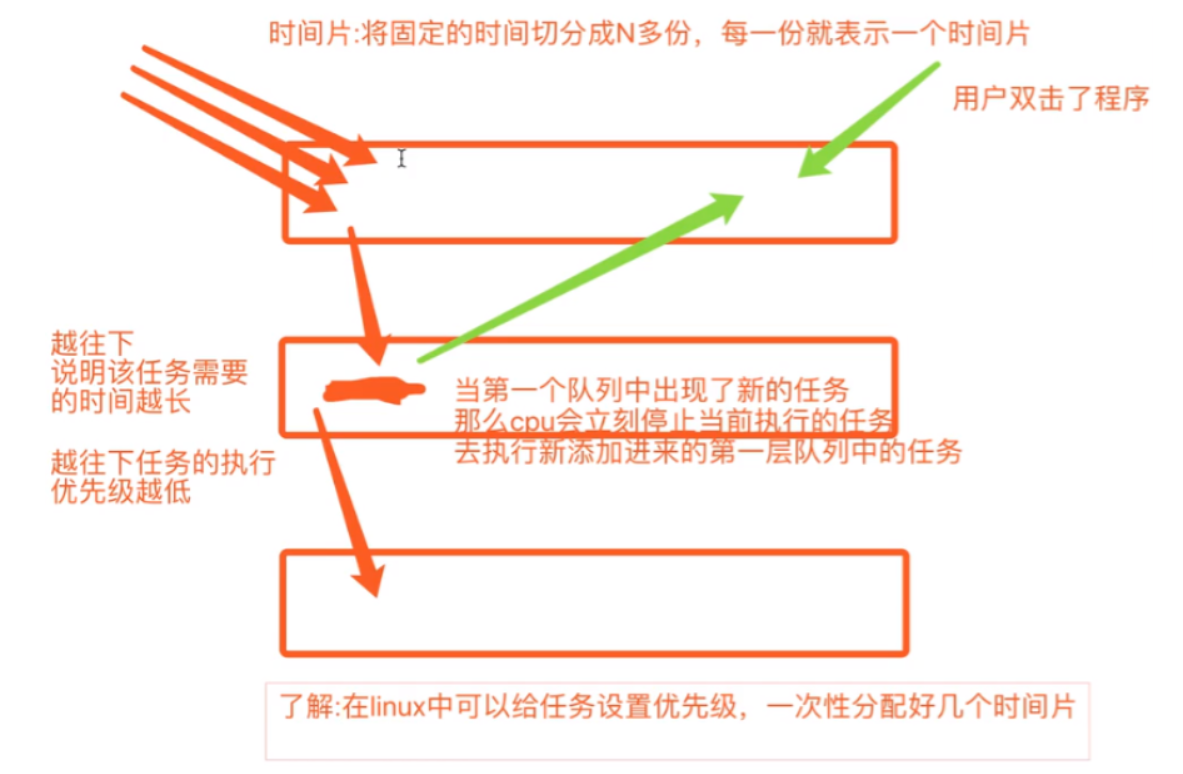
进程三状态图

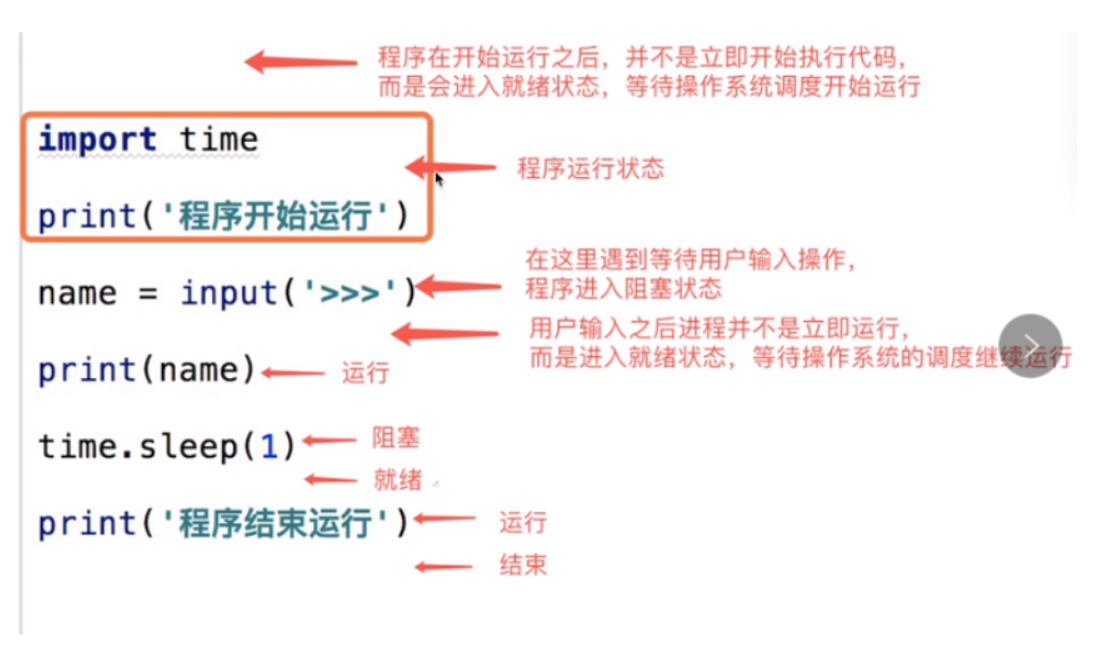
两对重要概念
同步和异步
""" 描述的是任务的提交方式 同步:任务提交之后,原地等待任务的返回结果,期间等待的过程中不做如何事情(干等) 程序层面上表现出来的感觉就是卡住了 异步:任务提交之后,不原地等待任务的返回结果,直接去做其他事情 我提交的任务结果如何获取? 任务的返回结果会有一个异步回调机制自动处理 """
阻塞和非阻塞
""" 描述的是任务的提交方式 同步:任务提交之后,原地等待任务的返回结果,期间等待的过程中不做如何事情(干等) 程序层面上表现出来的感觉就是卡住了 异步:任务提交之后,不原地等待任务的返回结果,直接去做其他事情 我提交的任务结果如何获取? 任务的返回结果会有一个异步回调机制自动处理 """
开启进程的两种方式
定心丸:代码开启进程和线程的方式,代码书写基本是一样的,你学会了如何开启进程就学会了如何开启线程
方式一
# 第一种 from multiprocessing import Process import time def task(name): print("%s is running" % name) time.sleep(3) print('%s is over' % name) if __name__ == '__main__': # 1、创建一个对象 p = Process(target=task, args=('jason',)) # 容器类哪怕里面有一个元素,建议一定要用逗号隔开 # 2、开启进程 p.start() # 告诉操作系统帮你创建一个进程 异步 print('主') ''' windows操作系统下 创建进程一定要在main内创建 因为windows下创建进程类似于模块导入的方式 会从上往下依次执行代码 linux中则是直接将代码完整的拷贝一份 '''
方式二
# 第二中方式 类的继承 from multiprocessing import Process import time class MyProcess(Process): def run(self): print('hello world') time.sleep(1) print('get out!') if __name__ == '__main__': p = MyProcess() p.start() print('主')
总结
""" 创建进程就是在内存中申请一块内存空间将需要运行的代码丢进去 一个进程对应在内存中就是一块独立的内存空间 多个进程对应在内存中就是多块独立的内存空间 进程与进程之间数据默认情况下是无法直接交互,如果想交互可以借助于第三方模块,工具 """
join方法
join是让主进程等待子进程代码运行结束之后,再继续运行。不影响其他子进程的执行
from multiprocessing import Process import time def task(name,n): print("%s is running" % name) time.sleep(n) print('%s is over' % name) if __name__ == '__main__': # 方式一: 1、创建一个对象 p1 = Process(target=task, args=('jason',1)) p2 = Process(target=task, args=('egon',2)) p3 = Process(target=task, args=('tank',3)) # 容器类哪怕里面有一个元素,建议一定要用逗号隔开 # 2、开启进程 start_time = time.time() p1.start() # 告诉操作系统帮你创建一个进程 异步 p2.start() p3.start() # 仅仅是告诉操作系统要创建进程 # p.join() # 主进程等待子进程p运行结束之后在继续往后执行 p1.join() p2.join() p3.join() print('主',time.time() - start_time) # 方式二: start_time = time.time() p_list = [] for i in range(1,4): p = Process(target=task,args=('子进程%s'%i,i)) p.start() p_list.append(p) for p in p_list: p.join() print('主', time.time() - start_time)
进程之间数据相互隔离
from multiprocessing import Process money = 100 def task(): global money # 局部修改全局 money = 666 print('子',money) if __name__ == '__main__': p = Process(target=task) p.start() p.join() print(money) # 子 666 # 100
进程对象及其他方法
""" 一台计算机上面运行着很多进程,那么计算机是如何区分并管理这些进程服务端的呢? 计算机会给每一个运行的进程分配一个PID号 如何查看? windows电脑 进入cmd输入tasklist即可查看 tasklist | findstr PID查看具体的进程 强制杀死进程 taskkill /F /PID PIP号 mac电脑,进入终端之后输入ps aux ps aux | grep PID查看具体的进程 """
查看当前进程的进程号
""" from multiprocessing import Process,current_process current_process().pid # 查看当前进程的进程号 import os os.getpid() # 查看当前进程的进程号 os.getppid() # 查看当前进程的父进程号 """
current_process
from multiprocessing import Process,current_process import time import os def task(): print('%s is running' %current_process().pid) # 查看当前进程的进程号 time.sleep(30) if __name__ == '__main__': p = Process(target=task) p.start() print('主',current_process().pid) # 主 13496 # 13352 is running
os
from multiprocessing import Process,current_process import time import os def task(): print('%s is running' %os.getpid()) # 查看当前进程的进程号 print('子进程的主进程号%s' %os.getppid()) time.sleep(30) if __name__ == '__main__': p = Process(target=task) p.start() print('主',os.getpid()) print('主主',os.getppid()) # 获取父进程的pid号 # 主 7864 # 主主 10108 # 3356 is running # 子进程的主进程号7864
了解
p.start() p.terminate() # 杀死当前进程 # 这句话是告诉操作系统帮你取杀死当前进程,但是需要一定的时间,而代码的运行速度极快 time.sleep(1) print(p.is_alive()) # 判断当前进程是否存活 ''' 一般情况下我们会默认将 存储布尔值的变量名 和返回的结果是布尔值的方法名 都起成is_开头 '''
僵尸进程与孤儿进程
""" 僵尸进程 死了,但是没有死透 当你开设了子进程之后,该进程死后不会立刻释放占用的进程号 因为我要让父进程能够查看到它开设的子进程的一些基本信息,占用的pid号,运行时间 所有的进程都会步入僵尸进程 父进程不死,并且在无限制的创建子进程并且子进程也不结束 回收子进程占用的pid号 父进程等待子进程运行结束 父进程调用join方法 孤儿进程 子进程存活,父进程意外死亡 操作系统会开设一个"儿童福利院",专门管理孤儿进程回收相关资源 """
守护进程
""" from multiprocessing import Process import time def task(name = 'egon'): print('%s总管正常活着' %name) time.sleep(3) print('%s总管正在死亡' %name) if __name__ == '__main__': # p = Process(target=task,args=('egon',)) p = Process(target=task,kwargs={'name':'egon'}) p.daemon = True # 将进程p设置成守护进程 这句话一定要放在start方法上面才有效果,否则报错 p.start() print('皇帝jason寿终正寝') """
互斥锁
""" 多个进程操作同一份数据的时候,会出现数据错乱的问题 针对上述问题,解决方法就是加锁处理,将并发变成串行,牺牲效率但是保证了数据的安全 扩展: 行锁 表锁 注意: 1、锁不要轻易的使用,容易造成死锁现象(我们一般写代码不会用到,都是内部封装好的) 2、锁只在处理数据的部分加起来保证数据安全(只在争抢数据的环节加锁处理即可) """
文件:data.txt
{"ticket_num": 1}
代码
from multiprocessing import Process,Lock import json import time import random # 查票 def search(i): # 文件操作,读取票数 with open('data','r',encoding='utf-8') as f: dic = json.load(f) print('用户%s查询余票%s' %(i,dic.get('ticket_num'))) # 字典取值不要用[]的形式,推荐使用get 你写的代码打死都不能报错!!! # 买票 1、先查 2、再买 def buy(i): # 先查票 with open('data','r',encoding='utf-8') as f: dic = json.load(f) # 模拟网络延迟 time.sleep(random.randint(1,3)) # 判断当前是否有票 if dic.get('ticket_num') > 0: # 修改数据库,,买票 dic['ticket_num'] -= 1 # 写入数据库 with open('data','w',encoding='utf-8') as f: json.dump(dic,f) print('用户%s 买票成功' %i) else: print('用户%s 买票失败' %i) # 整合上面两个函数 def run(i,mutex): search(i) # 给买票环节加锁处理 # 抢锁 mutex.acquire() buy(i) # 释放锁 mutex.release() if __name__ == '__main__': # 在主进程中生成一把锁,让所有的子进程抢,谁先抢到谁先买票 mutex = Lock() for i in range(1,11): p = Process(target=run, args=(i, mutex)) p.start()
进程间通信
队列介绍
""" 管道:subprocess stdin stdout stderr 队列:管道+锁 队列:先进先出 堆栈:先进后出 """
from multiprocessing import Queue # 创建一个队列 q = Queue(5) # 括号内可以传数据,标示生成的队列最大可以同时存放的数据量 # 往队列中存数据 q.put(111) q.put(222) q.put(333) print(q.full()) # 判断当前队列是否满了 print(q.empty()) # 判断当前队列是否空了 q.put(444) q.put(555) print(q.full()) # 判断当前队列是否满了 # q.put(666) # 当队列数据放满了之后,如果还有数据,程序会阻塞,直到有位置让出来,不会报错 ''' 存取数据 存是为了更好的取 千方百计的存,简单快捷的取 同在一个屋檐下 差距为何那莫大 ''' # 去队列中取数据 v1 = q.get() v2 = q.get() v3 = q.get() v4 = q.get() v5 = q.get() print(q.empty()) # 判断当前队列是否空了 # v6 = q.get_nowait() # 没有数据直接报错 queue.Empty # v6 = q.get(timeout=3) # 没有数据之后原地等待三秒之后再报错 queue.Empty # v6 = q.get() # 队列中如果已经没有数据的话,get方法会原地阻塞 try: v6 = q.get(timeout=3) print(v6) except Exception as e: print('一滴都没有了!') # print(v1,v2,v3,v4,v5,v6) ''' q.full() 判断当前队列是否满了 q.empty() 判断当前队列是否空了 q.get_nowait() 没有数据直接报错 在多进程的情况下是不精确的 '''
IPC机制
含义为进程间通信或者跨进程通信,是指两个进程之间进行数据交换的过程。
from multiprocessing import Queue,Process ''' 研究思路: 1、主进程跟子进程借助于队列通信 2、子进程跟子进程借助于队列通信 ''' def producer(q): q.put('我是23号技师,很高兴为您服务!') print('hello big baby~') def consumer(q): print(q.get()) if __name__ == '__main__': q = Queue() p = Process(target=producer,args=(q,)) p1 = Process(target=consumer,args=(q,)) p.start() p1.start() # print(q.get())
生产者消费者模型
""" 生产者:生产/制造东西 消费者:消费/处理东西的 该模型除了上述两个之外,还需要一个媒介 生活中的例子:做包子的将包子做好之后放在蒸笼(媒介)里面,买包子的去蒸笼里面拿 厨师做菜做完之后用盘子装着给消费者端过去 生产者和消费者之间不是直接做交互的,而是借助于媒介做交互 生产者(做包子的) + 消息队列(蒸笼) + 消费者(吃包子的) """
from multiprocessing import Queue,Process,JoinableQueue import random import time # 生产者 def producer(name,food,q): for i in range(5): data = '%s生产的%s%s' %(name,food,i) # 模拟延迟 time.sleep(random.randint(1,3)) print(data) # 将数据放入队列 q.put(data) # 消费者 def consumer(name,q): # 消费者胃口很大,光盘行动 while True: food = q.get() # 没有数据就会卡住 # 判断当前是否有结束的标识 # if food is None: # break time.sleep(random.randint(1,3)) print('%s吃了%s' %(name,food)) q.task_done() # 告诉队列你已经从里面取出了一个数据并且处理完毕了 if __name__ == '__main__': # q = Queue() q = JoinableQueue() p1 = Process(target=producer,args=('大厨egon','包子',q)) p2 = Process(target=producer,args=('马叉虫tank','煲汤',q)) c1 = Process(target=consumer,args=('春哥',q)) c2 = Process(target=consumer,args=('星哥',q)) p1.start() p2.start() # 将消费者设置守护进程 c1.daemon = True c2.daemon = True c1.start() c2.start() p1.join() p2.join() # 等待生产者生产完毕之后,往队列中添加特定的结束符号 # q.put(None) # 肯定在所有生产者生产的数据的末尾 # q.put(None) # 肯定在所有生产者生产的数据的末尾 q.join() # 等待队列中所有的数据被取完在执行往下执行的代码 ''' JoinableQueue 每当你往该队列中存入数据的时候,内部会有一个计数器+1 每当你调用task_done的时候,计数器-1 q.join() 当计数器为0的时候,才往后执行 ''' # 只有q.join执行完毕,说明消费者已经处理完数据了,消费者就没有存在的必要了
线程理论
什么是线程
进程:资源单位
线程:执行单位
将操作系统比喻成一个大的工厂
那么进程就相当于工厂里面的车间
而线程就是车间里面的流水线
每一个进程肯定自带一个线程
再次总结:
进程:资源单位(起一个进程仅仅只是在内存空间中开辟一块独立的空间)
线程:执行单位(真正被cpu执行的其实是进程里面的线程,线程指的就是代码执行的过程,执行代码中所需要使用到的资源都找所在的进程索要)
进程和线程都是虚拟单位,只是为了我们更加方便的描述问题
为何要有线程
开设进程 1、申请内存空间 耗资源 2、"拷贝代码" 耗资源 开线程 一个进程内可以开设多个线程,在同一个进程内开设多个线程无需再次申请内存空间的操作 总结:开设线程的开销要远远小于进程的开销 同一个进程下的多个线程数据是共享的 举例: 我们要开发一款文本编辑器 获取用户输入的功能 实时展示到屏幕的功能 自动保存到硬盘的功能 针对上面这三个功能,开设进程还是线程合适??? 开三个线程处理上面的三个功能更加的合理
开启线程的两种方式
方式一
from multiprocessing import Process from threading import Thread import time def task(name): print('%s is running' % name) time.sleep(1) print('%s is over' % name) # 方式一: # 开启线程不需要在main下面执行代码,直接书写就可以 # 但是我们还是习惯性的将启动命令写在main下面 t = Thread(target=task,args=('egon',)) t.start() # 创建线程的开销非常小,几乎是代码一执行线程就已经创建了 print('主') # >>>: # egon is running # 主 # egon is over if __name__ == '__main__': p = Process(target=task,args=('egon',)) p.start() print('主') # >>>: # 主 # egon is running # egon is over
方式二
# 方式二 from threading import Thread import time class MyThread(Thread): def __init__(self,name): ''' 针对双下划线开头双下划线结尾的方法(__init__),统一读成 双下xxx 双下init ''' # 重写了别人的方法,又不知道别人的方法里面有啥,你就调用父类的方法 super().__init__() self.name = name def run(self): print('%s is running' % self.name) time.sleep(1) print('egon DSB') if __name__ == '__main__': t = MyThread('egon') t.start() print('主') # >>>: # egon is running # 主 # egon DSB
TCP服务端实现并发的效果
服务端
import socket from threading import Thread from multiprocessing import Process ''' 服务端: 1、要有固定的IP和PROT(端口) 2、24小时不间断提供服务 3、能够支持并发 从现在开始要养成一个看源码的习惯 前期立志称为拷贝忍者 卡卡西 不需要有任何创新 等你拷贝到一定程度了 就可以开发自己的思想了 ''' server = socket.socket() # 括号内不加参数默认是TCP协议 server.bind(('127.0.0.1',8881)) # 一定要用小括号括起来 server.listen(5) # 将服务的代码单独封装成一个函数 def talk(conn): # 通信循环 while True: try: data = conn.recv(1024) # 针对mac linux 客户端断开连接后 if not data: break print(data.decode('utf-8')) conn.send(data.upper()) except Exception as e: print(e) break conn.close() # 连接循环 while True: # conn连接对象 addr对方的地址 conn,addr = server.accept() # 接客 # 叫其他人来服务客户 t = Thread(target=talk,args=(conn,)) # t = Process(target=talk,args=(conn,)) t.start()
客户端
import socket client = socket.socket() client.connect(('127.0.0.1',8881)) while True: client.send(b'hello world') data = client.recv(1204) print(data.decode('utf-8'))
线程对象的join方法
from threading import Thread import time def task(name): print('%s is running' %name) time.sleep(3) print('%s is over' %name) if __name__ == '__main__': t = Thread(target=task,args=('egon',)) t.start() t.join() # 主线程等待子线程运行结束再执行 print('主') # >>>: # egon is running # egon is over # 主
线程间数据共享
from threading import Thread import time money =100 def task(): global money money = 666 print(money) if __name__ == '__main__': t = Thread(target=task) t.start() t.join() print(money) # >>>: # 666
线程对象属性及其他方法
from threading import Thread,active_count,current_thread import os,time def task(n): # print('hello world',os.getpid()) # hello world主 13944 print('hello world',current_thread().name) time.sleep(n) if __name__ == '__main__': t1 = Thread(target=task,args=(1,)) t2 = Thread(target=task,args=(2,)) t1.start() t2.start() t2.join() # print('主',os.getpid()) # 13944 # print('主',current_thread().name) # 获取线程名字 print('主',active_count()) # 统计当前正在活跃的线程数
守护线程
from threading import Thread import time def task(name): print('%s is running' % name) time.sleep(1) print('%s is over' % name) if __name__ == '__main__': t = Thread(target=task, args=('egon',)) t.daemon = True # 守护线程 t.start() print('主') ''' 主线程运行结束之后不会立刻结束,会等待所有其他非守护线程结束才会结束 因为主线程的结束意味着所在的进程的结束 '''
稍微有迷惑性的例子
from threading import Thread import time def foo(): print(123) time.sleep(1) print('end123') def func(): print(456) time.sleep(3) print('end456') if __name__ == '__main__': t1 = Thread(target=foo) t2 = Thread(target=func) t1.daemon = True t1.start() t2.start() print('主。。。。。。') # 123 # 456 # 主。。。。。。 # end123 # end456
线程互斥锁
""" 当多个线程在操作同一份数据的时候可能会造成数据的错乱 这个时候为了保证数据的安全,我们通常都会加锁处理 锁: 将并发变成串行,降低了程序的运行效率但是保证了数据的安全 锁的问题在我们后面写代码的过程中一般不会遇到,都是别人底层封装好的,无需你考虑 例:行锁 表锁 """
from threading import Thread,Lock # from multiprocessing import Lock import time money = 100 mutex = Lock() # 生成锁 def task(): global money mutex.acquire() tmp = money time.sleep(1) #模拟网络延迟 money = tmp - 1 mutex.release() if __name__ == '__main__': t_list = [] for i in range(100): t = Thread(target=task) t.start() t_list.append(t) for t in t_list: t.join() print(money)
GIL全局解释器锁
''' 定义: In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.) ''' 结论:在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势 python解释器其实有多个版本 Cpython Jpython Pypypython 但是普遍使用的都是Cpython解释器 在CPython解释器中,GIL是一把互斥锁,用来阻止同一个进程下的多个线程的同时执行 同一个进程下的多个线程无法利用多核优势! 疑问:python的多线程是不是一点用都没有???无法利用多核优势 因为Cpython中的内存管理不是线程安全的 内存管理(垃圾回收机制) 1、引用计数 2、标记清除 3、分代回收 重点: 1、GIL不是python的特点而是Cpython解释器的特点 2、GIL是保证解释器级别的数据的安全 3、GIL会导致同一个进程下的多个线程无法同时执行即无法利用多核优势(******) 4、针对不同的数据还是需要加不同的锁处理 5、解释型语言的通病:同一个进程下多个线程无法利用多核的优势
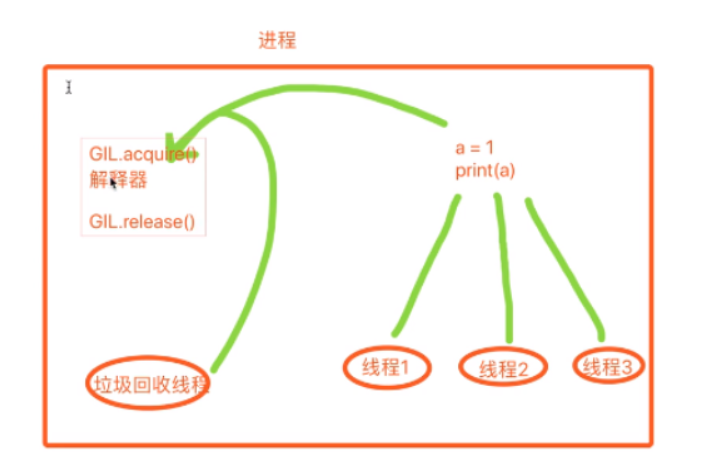
GIL与普通互斥锁的区别
from threading import Thread, Lock import time mutex = Lock() money = 100 def task(): global money # 方式一加锁: # with mutex: # tmp = money # time.sleep(0.1) # money = tmp - 1 # 方式二加锁: mutex.acquire() tmp = money time.sleep(0.1) # 只要你进入IO,GIL会自动释放 money = tmp - 1 mutex.release() if __name__ == '__main__': t_list = [] for i in range(100): t = Thread(target=task) t.start() t_list.append(t) for t in t_list: t.join() print(money) ''' 100个线程先起起来,要先去抢GIL 我进入IO,GIL自动释放,但是我手上还有一个自己的互斥锁 其他线程虽然抢到了GIL但是抢不到互斥锁 最终GIL还是回到你的手上,你去操作数据 '''
多进程与多线程的实际应用场景
Python同一个进程下的多线程无法利用多核优势,是不是就没有用了?
""" 多线程是否有用要看具体情况 单核:四个任务(IO密集型\计算密集型) 多核:四个任务(IO密集型\计算密集型) 计算密集型 每一个任务都需要10s 单核(不用考虑了): 多进程:额外的消耗资源 多线程:节省开销 多核: 多进程:总耗时10s+ 多线程:总耗时40s+ IO密集型 每一个任务都需要10s 多核: 多进程:相对浪费资源 多线程:更加节省资源 """
代码验证
# # 计算密集型 from multiprocessing import Process from threading import Thread import os,time def work(): res = 0 for i in range(100000000): res*=i if __name__ == '__main__': l = [] print(os.cpu_count()) # 获取当前计算机cup个数 start_time = time.time() for i in range(8): # p = Process(target=work) # 多进程 10.007959127426147 t = Thread(target=work) # 多线程 40.875465631484985 t.start() # p.start() # l.append(p) l.append(t) for p in l: p.join() print(time.time()-start_time) # IO密集型 from multiprocessing import Process from threading import Thread import os,time def work(): time.sleep(2) if __name__ == '__main__': l = [] print(os.cpu_count()) # 获取当前计算机cup个数 start_time = time.time() for i in range(400): # p = Process(target=work) # 多进程 16.720871686935425 t = Thread(target=work) # 多线程 2.098599433898926 t.start() # p.start() # l.append(p) l.append(t) for p in l: p.join() print(time.time()-start_time)
总结
""" 多进程和多线程都有各自的优势 并且我们在后面写项目的时候通常都是 多进程下面再开设多线程 这样的话既可以利用多核也可以节省资源消耗 我们开发的软件90%都是IO密集型的 """
协程理论
什么是协程
""" 是单线程下的并发,又称微线程,纤程。英文名Coroutine。 一句话说明什么是线程: 协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。 """
需要强调的是
""" 1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行) 2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关) """ 对比操作系统控制线程的切换,用户在单线程内控制协程的切换
优点
""" 1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级 2. 单线程内就可以实现并发的效果,最大限度地利用cpu """
缺点
""" 1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程 2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程 """
特点
""" 1、必须在只有一个单线程里实现并发 2、修改共享数据不需加锁 3、用户程序里自己保存多个控制流的上下文栈 4、附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制)) """
Gevent介绍
""" #安装 pip3 install gevent Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。
Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。 详情参见:https://www.cnblogs.com/linhaifeng/articles/7429894.html#_label4 """
IO理论
IO模型简介
""" 我们这里研究的IO模型都是针对网络IO的 Stevens在文章中一共比较了五种IO Model: * blocking IO 阻塞IO * nonblocking IO 非阻塞IO * IO multiplexing IO多路复用 * signal driven IO 信号驱动IO * asynchronous IO 异步IO 由于signal driven IO(信号驱动IO)在实际中并不常用,所以主要介绍其余四种IO Model。 """
""" (1)等待数据准备 (Waiting for the data to be ready) (2)将数据从内核拷贝到进程中(Copying the data from the kernel to the process) """
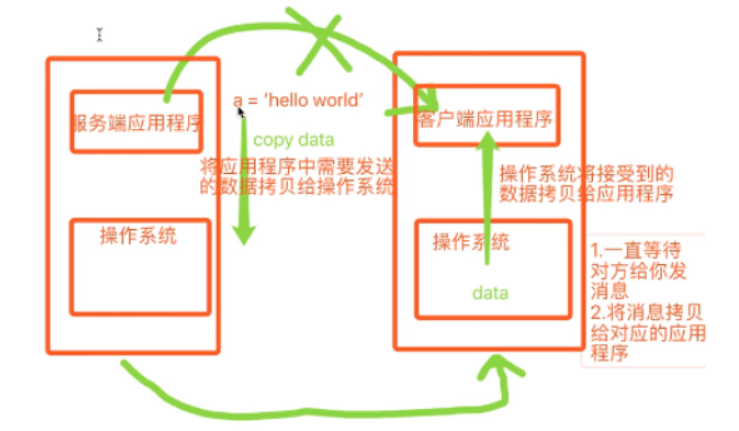
同步异步:描述的是任务的提交方式
同步:提交任务之后,原地等待任务的防范胡结果,期间等待的过程中不干如何事情(干等)
程序层面上表现出来的感觉就是卡住了
异步:任务提价之后,不原地等待任务的返回结果,直接去做其他事情
任务的返回结果会有一个异步回调机制自动处理
阻塞非阻塞:描述的是程序的运行状态
阻塞:阻塞态
非阻塞:就绪态,运行态
常见的网络阻塞状态:
accept
recv
recvfrom
send虽然也有IO行为,但是不在我们的考虑范围
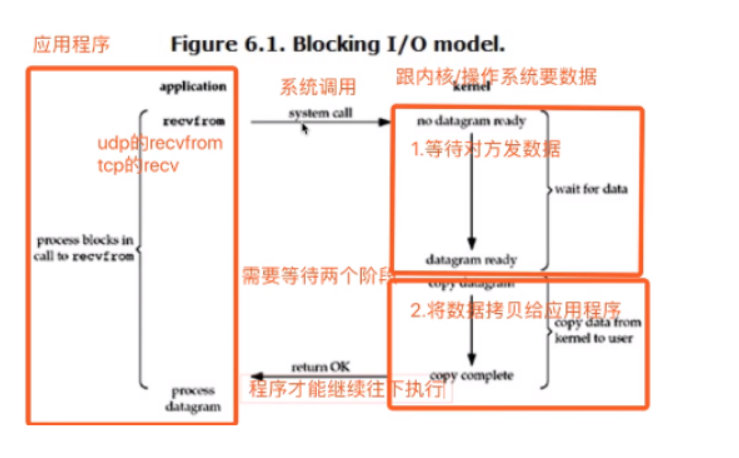
阻塞IO
""" 我们之前写的都是阻塞IO模型 协程除外 """
服务端
import socket server = socket.socket() server.bind(('127.0.0.1',8081)) server.listen(5) while True: conn,addr = server.accept() while True: try: data = conn.recv(1024) if not data: break print(data) conn.send(data.upper()) except ConnectionResetError as e: break conn.close() # 在服务端开设多进程或者多线程,其实还是没有解决IO问题 该等的地方还是得等,没有规避 只不过多个人等待的彼此互不干扰
非阻塞IO
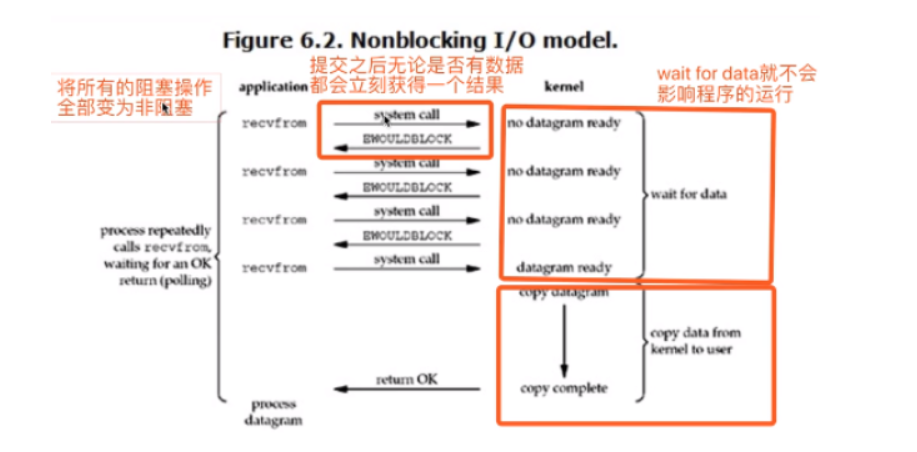
自己实现一个非阻塞IO模型
服务端
import socket import time server = socket.socket() server.bind(('127.0.0.1',8080)) server.listen(5) server.setblocking(False) # 默认为True # 将所有的网络阻塞变成非阻塞 r_list = [] del_lsit = [] while True: try: conn,addr = server.accept() r_list.append(conn) except BlockingIOError as e: # time.sleep(0.1) # print('列表的长度',len(r_list)) # print('做其他事情') for conn in r_list: try: data = conn.recv(1024) # 没有消息报错 if not data: # 客户端断开连接 conn.close() # 关闭conn # 将无用的conn从r_list中删除 del_lsit.append(conn) continue conn.send(data.upper()) except BlockingIOError as e: continue except ConnectionResetError: conn.close() # del_lsit.append(conn) # 回收无用的连接 for conn in del_lsit: r_list.remove(conn) del_lsit.clear()
客户端
import socket client = socket.socket() client.connect(('127.0.0.1',8080)) while True: client.send(b'hello world') data = client.recv(1024) print(data)
总结
""" 虽然非阻塞IO给你的感觉非常的牛逼 但是该模型会长时间占用着CPU,并且不干活,让CPU不停的空转 我们实际应用中也不会考虑使用非阻塞IO模型 任何的技术点都有它存在的意义 实际应用或者是思想借鉴 """
IO多路复用
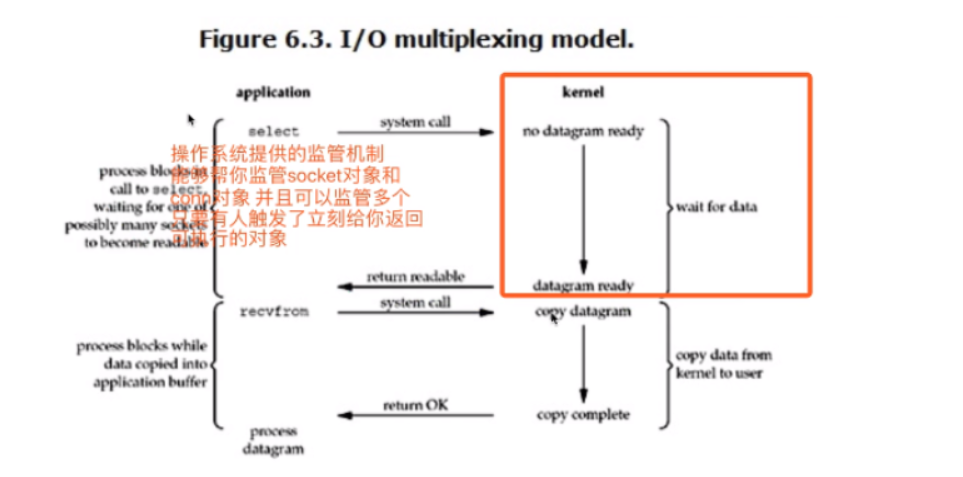
当监管的对象只有一个的时候,其实IO多路复用连阻塞IO都比不上!!! 但是IO多路可以一次性监管很多对象 server = socket.socket() connserver.accept() 监管机制是操作系统本身就有的,如果你想要用该监管机制(select) 需要你导入对应的select模块
服务端
import socket import select server = socket.socket() server.bind(('127.0.0.1',8086)) server.listen(5) server.setblocking(False) read_list = [server] while True: r_list,w_list,x_list = select.select(read_list,[],[]) ''' 帮你监管 一旦有人来了,立刻给你返回对应的监管对象 ''' # print(res) #([<socket.socket fd=124, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 8086)>], [], []) # print(server) # print(r_list) for i in r_list: ''' 针对不同的对象做不同的处理 ''' if i is server: conn,addr = i.accept() # conn也应该添加到待监管的队列中 read_list.append(conn) else: res = i.recv(1024) if not i: i.close() # 将无效的监管对象移除 read_list.remove(i) continue print(res) i.send(b'heiheihei')
客户端
import socket client = socket.socket() client.connect(('127.0.0.1',8086)) while True: # msg = input('>>>: ').strip() client.send(b'hello world') data = client.recv(1024) print(data)
总结:监管机制
""" 监管机制其实有很多: select机制 windows linux都有 poll机制 只在linux有 poll和select都可以监管多个对象,但是poll监管的数量更多 上述select和poll机制其实都不是很完美,当监管的对象特别多的时候可能会出现极其大的延时响应 epoll机制 只在linux有 它给每一个监管对象都绑定一个回调机制 一旦有响应,回调机制立刻发起提醒 针对不同的操作系统还需要考虑不同监测机制,书写代码太过繁琐 有一个人能够根据你跑的平台的不同,自动帮你选择对应的监管机制 selectors模块(了解即可) """
异步IO
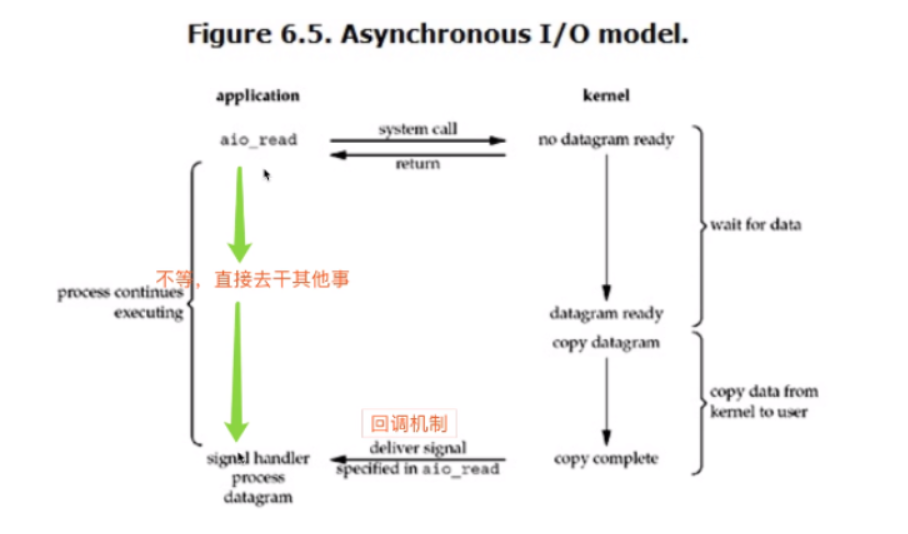
""" 异步IO模型是所有模型中效率最高的,也是使用最广泛的 相关的模块和框架 模块:asyncio模块 异步框架:sanic tronado twisted 速度快!!! """
import threading import asyncio @asyncio.coroutine def hello(): print('hello world % s' %threading.current_thread()) yield from asyncio.sleep(1) # 换成真正的IO操作 print('hello world % s' %threading.current_thread()) loop = asyncio.get_event_loop() tasks = [hello(),hello()] loop.run_until_complete(asyncio.wait(tasks)) loop.close() ''' E:\PYTHON\Python39\python.exe "E:/PYTHON/pycharm project/project/IO模型/04 异步IO/asyncio模块.py" hello world <_MainThread(MainThread, started 16180)> hello world <_MainThread(MainThread, started 16180)> E:\PYTHON\pycharm project\project\IO模型\04 异步IO\asyncio模块.py:5: DeprecationWarning: "@coroutine" decorator is deprecated since Python 3.8,use "async def"instead def hello(): hello world <_MainThread(MainThread, started 16180)> hello world <_MainThread(MainThread, started 16180)> '''
四个IO模型对比
参考下图

网络并发知识点梳理
软件开发架构 互联网协议 osi七层 五层 每一层都是干嘛的 以太网协议 广播风暴 IP协议 TCP/UDP 三次握手/四次挥手(******) socket简介 TCP粘包问题,定制固定长度的报头 UDP协议 sockerserver模块 操作系统的发展史 多道技术 进程理论 开启进程的两种方式(******) 互斥锁 生产者消费者模型 线程理论 开启线程的两种方式 GIL全局解释器锁 进程池线程池 协程的概念 IO模型的了解
并发编程高阶
死锁与递归锁
当你知道锁的使用,抢锁必须要释放锁,其实你在操作锁的时候也极其任意产生死锁现象(整个程序卡死(阻塞))
死锁
from threading import Thread,Lock import time mutexA = Lock() mutexB = Lock() # 类只要加括号多次,产生的肯定是不同的对象 # 如果你想要实现多次加括号得到的是相同的对象 单例模式 # 单例模式:https://www.cnblogs.com/huchong/p/8244279.html class MyThread(Thread): def run(self): self.func1() self.func2() def func1(self): mutexA.acquire() print('%s 抢到A锁' %self.name) # 获取当前线程名 mutexB.acquire() print('%s 抢到B锁' % self.name) mutexB.release() mutexA.release() def func2(self): mutexB.acquire() print('%s 抢到B锁' % self.name) time.sleep(2) mutexA.acquire() print('%s 抢到A锁' % self.name) mutexA.release() mutexB.release() if __name__ == '__main__': for i in range(10): t = MyThread() t.start() # >>>: # Thread-1 抢到A锁 # Thread-1 抢到B锁 # Thread-1 抢到B锁 # Thread-2 抢到A锁
递归锁
""" 递归锁的特点: 可以被连续的acquire和release 但是只能被第一个抢到这把锁执行上述操作 它的内部有一个计数器,每acquire一次计数加一,每realse一次计数就减一 只要计数不为0,那么其他人都无法抢到该锁 代码就是将上述的 from threading import Thread,Lock,RLock mutexA = Lock() mutexB = Lock() 换成 from threading import Thread,Lock,RLock mutexA = mutexB = RLock() """
信号量
信号量在不同的阶段可能对用不同的技术点 在并发编程中信号量指的是锁!!! """ 如果我们将互斥锁比喻成一个厕所的话 那么信号量就相当于多个厕所 """
from threading import Thread,Semaphore import time import random ''' 利用random模块实现打印随机验证码(搜狗的一道笔试题) ''' sm = Semaphore(5) # 括号内写数字 写几就表示开设几个坑位 def task(name): sm.acquire() print("%s 正在蹲坑" %name) time.sleep(random.randint(1,5)) sm.release() if __name__ == '__main__': for i in range(1,21): t = Thread(target=task,args=('伞兵%s号'%i,)) t.start()
Event事件
一些进程/线程需要等待另外一些进程/线程运行完毕之后才能运行,类似于发射信号一样 from threading import Thread,Event import time event = Event() # 造了一个红绿灯 def light(): print('红灯亮着') time.sleep(3) print('绿灯亮着') # 告诉等待红灯的人可以走了 event.set() def car(name): print('%s 车正在等红灯' % name) event.wait() # 等待别人给你发信号 print('%s 车加油门飙车走了' % name) if __name__ == '__main__': t = Thread(target=light) t.start() for i in range(20): t = Thread(target=car,args=('%s' %i,)) t.start()
线程q(队列)
''' 同一个进程下线程数据是共享的 为什么在同一个进程下还会去使用队列呢? 因为队列是 管道+锁 所以用队列还是为了保证数据的安全 ''' import queue # 我们现在使用的队列都是只能在本地测试使用 # 1、队列q 先进先出 # q = queue.Queue(3) # q.put(1) # q.get() # q.get_nowait() # q.get(timeout=3) # q.full() # q.empty() # 2、后进先出q # q = queue.LifoQueue(3) # last in first out # q.put(1) # q.put(2) # q.put(3) # print(q.get()) # 3 # print(q.get()) # 2 # print(q.get()) # 1 # 3、优先级q 你可以给放入队列中的数据设置进出的优先级 q = queue.PriorityQueue(4) q.put((10,'111')) q.put((100,'222')) q.put((0,'333')) q.put((-5,'444')) # put括号内放一个元组,第一个放数字表示优先级 # 需要注意的是 数字越小优先级越大 print(q.get()) print(q.get()) print(q.get()) print(q.get()) # >>>: # (-5, '444') # (0, '333') # (10, '111') # (100, '222')
进程池与线程池
先回顾之前TCP服务端实现并发的效果是怎么玩的
每来一个人就开设一个进程或者线程去处理
无论是开设进程也好还是开设线程还好,是不是都需要消耗资源
只不过开设线程的消耗比开设进程的稍微小一点而已
我们是不可能做到无限制的开设进程和线程的,因为计算机硬件的资源跟不上!!!
硬件的开发速度远远赶不上软件的
我们的宗旨应该是在保证计算机硬件能够正常工作的情况下最大限度的利用它
池的概念
""" 什么是池? 池是用来保证计算机硬件安全的情况下最大限度的利用计算机 它降低了程序的运行效率,但是保证了计算机硬件的安全,从而让你写的程序能够正常的运行 """
基本使用
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import time import os # 线程池 # pool = ThreadPoolExecutor(5) # 传值 意味池子里面固定只有五个线程 # 括号内可以传数字,不传的话默认:max_workers = min(32, (os.cpu_count() or 1) + 4) # 进程池 pool = ProcessPoolExecutor(5) # 括号内可以传数字,不传的话默认会开设当前计算机cpu个数进程 ''' 如果传值5的话 池子造出来之后,里面会固定存在五个线程 这五个线程不会重复出现重复创建和销毁的过程 池子造出来之后,里面会固定存在五个进程 这五个进程不会重复出现重复创建和销毁的过程 池子的使用非常的简单 你只需要将做的任务往池子中提交即可,自动会有人来服务你 ''' def task(n): print(n,os.getpid()) time.sleep(2) return n**n ''' 任务的提交方式 同步:提交任务之后原地等待任务的返回结果,期间不做如何事情 异步:提交任务之后不等待任务的返回结果,执行继续往下执行 返回结果如何获取??? 异步提交任务的返回结果,应该通过回调机制来获取 回调机制 就相当于给每个异步任务绑定了一个定时炸弹 一旦该任务有结果立刻触发爆炸 ''' def call_back(n): print('call_back',n.result()) if __name__ == '__main__': # pool.submit(task,1) # # 朝池子中提交任务 异步提交 # print('主') t_list = [] for i in range(20): # 朝池子中提交20个任务 # res = pool.submit(task,i) # <Future at 0x28597fd0f10 state=running> res = pool.submit(task,i).add_done_callback(call_back) # print(res.result()) # result方法 同步提交 join t_list.append(res) # 等待线程池中所有任务执行完毕之后再网址继续执行 # pool.shutdown() # 关闭线程池,等待线程池中所有的任务运行完毕 # for t in t_list: # print('>>>: ',t.result()) # 肯定是有序的 ''' 程序由并发变成了串行 任务的结果为什么打印的是None res.result() 拿到的就是异步体检的任务的返回结果 '''
总结
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor pool = ProcessPoolExecutor(5) res = pool.submit(task,i).add_done_callback(call_back)
协程
进程:资源单位 线程:执行单位 协程:这个概念完全是程序员自己意淫出来的,根本不存在 单线程下实现并发 我们程序员自己在代码层面上检测我们所有的IO操作 一旦遇到了IO,我们在代码级别完成切换 这样给CPU的感觉是你这个程序一直在运行,没有IO 从而提升程序的运行效率 多道技术 切换+保存状态 CPU两种切换: 1、程序遇到IO 2、程序长时间占用 TCP服务端 accept recv 代码如何做到 切换+保存状态 切换 切换不一定是提升效率,也有可能是降低效率 IO切 提升 没有IO切 降低 保存状态 保存上一次我执行的状态,下一次接着上一次的操作继续往后执行 yield
验证切换是否就一定提升效率
import time # 串行执行计算密集型的任务 1.0233955383300781 def func1(): for i in range(10000000): i+1 def func2(): for i in range(10000000): i+1 start_time = time.time() func1() func2() print(time.time() - start_time) # 切换+yield 1.2566502094268799 import time def func1(): while True: 10000000+1 yield def func2(): g = func1() # 先初始化出生成器 for i in range(10000000): i+1 next(g) start_time = time.time() func2() print(time.time() - start_time)
gevent模块
安装 第三方库:https://www.lfd.uci.edu/~gohlke/pythonlibs/
pip3 install gevent
# import time # # # 串行执行计算密集型的任务 1.0233955383300781 # def func1(): # for i in range(10000000): # i+1 # def func2(): # for i in range(10000000): # i+1 # # start_time = time.time() # func1() # func2() # print(time.time() - start_time) # # # # # # 切换+yield 1.2566502094268799 # import time # # def func1(): # while True: # 10000000+1 # yield # # def func2(): # g = func1() # 先初始化出生成器 # for i in range(10000000): # i+1 # next(g) # # start_time = time.time() # func2() # print(time.time() - start_time) from gevent import monkey;monkey.patch_all() import time from gevent import spawn ''' gevent模块本身无法检测常见的一些IO操作 需要在使用的时候需要你额外的导入一句话 from gevent import monkey # 猴子补丁 monkey.patch_all() 由由于上面的两句话在使用gevent模块的时候是肯定要导入的 所以还支持简写 from gevent import monkey;monkey.patch_all() ''' def heng(): print('哼') time.sleep(2) print('哼') def ha(): print('哈') time.sleep(3) print('哈') def heiheihei(): print('heiheihei') time.sleep(5) print('heiheihei') start_time = time.time() g1 = spawn(heng) g2 = spawn(ha) g3 = spawn(heiheihei) g1.join() g2.join() # 等待被检测的任务执行完毕,再往后继续执行 g3.join() # heng() # ha() # print(time.time() - start_time) # 5.013732671737671 print(time.time() - start_time) # 3.0434458255767822 # 哼 # 哈 # 哼 # 哈 # 3.0434458255767822 print(time.time() - start_time) # 5.042800664901733
协程实现TCP服务端的并发效果
服务端
from gevent import monkey;monkey.patch_all() import socket from gevent import spawn def communication(conn): while True: try: data = conn.recv(1024) if not data: break conn.send(data.upper()) except Exception as e: print(e) break conn.close() def server(ip,port): server = socket.socket() server.bind((ip, port)) server.listen(5) while True: conn,addr = server.accept() spawn(communication,conn) if __name__ == '__main__': g1 = spawn(server,'127.0.0.1',8080) g1.join()
客户端
from threading import Thread,current_thread import socket def x_client(): client = socket.socket() client.connect(('127.0.0.1',8080)) n = 0 while True: msg = '%s say hello %s' %(current_thread().name,n) n+=1 client.send(msg.encode('utf-8')) data = client.recv(1024) print(data.decode('utf-8')) if __name__ == '__main__': for i in range(500): t = Thread(target=x_client) t.start()
总结
""" 理想状态 我们可以通过 多进程下面开始多线程 多线程下面再开始多协程 从而使我们的程序执行效率提升 """

