面向对象编程
面向对象编程:
核心是对象二字,对象就是一个用来盛放数据与功能的容器
基于该思想编写程序就是创造一个个的容器
优点:扩展性强
缺点:编程的复杂度提升
在程序中,先定义类,后产生对象
类与对象
对象是"容器",用来存放数据与功能的 类也是"容器",用来存放同类对象共有的数据与功能 详情参见:https://www.cnblogs.com/ZhZhang12138/p/14251433.html
封装
详情参见:https://zhuanlan.zhihu.com/p/109310247
1、引入
面向对象编程有三大特征:封装、继承、多态。
封装指的就是把数据与功能整合到一起。
针对封装到对象或者类中的属性,我们还可以严格控制对它们的访问,分两步实现:隐藏与开放接口
2、隐藏属性
Python的class机制采用双下划线的方式将隐藏属性隐藏起来(设置成私有的),但其实这仅仅只是一种变形操作,类中所有双下滑线开头的属性都会在类定义阶段、检测语法时自动变成 " _类名__属性名 " 的形式。
class Foo: __N = 0 # 变形为_Foo__N def __init__(self): # 定义函数时,会检测函数语法,所以__开头的属性也会变形 self.__x = 10 # 变形为_Foo_x def __f1(self): # 变形为_Foo__f1 print('__f1 run') def f2(self): # 定义函数时,会检测函数语法,所以__开头的属性也会变形 self.__f1() # 变形为self._Foo__f1 print(Foo.__N) # 报错 # AttributeError: type object 'Foo' has no attribute '__N' obj = Foo() print(obj.__x) # 报错 # AttributeError: 'Foo' object has no attribute '__x'
注意
这种变形需要注意的问题是: 1、在类外部无法直接访问双下滑线的属性,但是知道了类名和属性名就可以拼出名字:_类名__属性。然后就可以访问了,例如:Foo._A_N。 所以说这种操作并没有严格意义上的限制外部访问,仅仅是语法意义上的变形。 2、在类内部是可以直接访问双下滑线开头的属性的,因为在类定义阶段内部双下划綫开头的属性同一发生了变形。 3、变形操作值在类定义阶段发生一次,在类定义之后的赋值操作,不会变形
3、开放接口
隐藏数据属性
将数据隐藏起来就限制了类外部对数据的直接操作,然后类内应该提供相应的接口来允许类外部间接的操作数据,接口之上可以附加额外的逻辑来对数据的操作进行严格的控制。
class Teacher: def __init__(self, name, age): # 将名字和年纪都隐藏起来 self.__name = name self.__age = age def tell_info(self): # 对外提供访问老师信息的接口 print('姓名:%s,年龄:%s' % (self.__name, self.__age)) def set_info(self, name, age): # 对外提供设置老师信息的接口,并附加类型检查的逻辑 if not isinstance(name, str): print('姓名必须是字符串类型') return if not isinstance(age, int): print('年龄必须是整型') return self.__name = name self.__age = age t = Teacher('lili',18) t.set_info('Lili','19') # 年龄必须是整型 # 年龄必须是整型 t.tell_info() # 查看老师的信息 # 姓名:lili,年龄:18
隐藏函数属性
目的是为了隔离复杂度,例如ATM程序的取款功能,该功能有好多其他功能组成,比如插卡、身份认证、输入金额、打印小票、取钱等,
而对于使用者来说,只需要开发取款这个功能接口即可,取余功能我们都可以隐藏起来。
class ATM: def __card(self): # 插卡 print('插卡') def __auth(self): # 身份认证 print('用户认证') def __input(self): # 输入金额 print('输入取款金额') def __print_bill(self): # 打印小票 print('打印账单') def __take_money(self): # 取钱 print('取款') def withdraw(self): # 取款功能 self.__card() self.__auth() self.__input() self.__print_bill() self.__take_money() obj = ATM() obj.withdraw()
4、property
property:可以将类中的函数"伪装成"对象的数据属性,对象在访问该特殊属时会触发功能的执行,然后将返回值作为本次访问的结果。
class People: def __init__(self, name, weight, height): self.name = name self.weight = weight self.height = height @property def bmi(self): return self.weight / (self.height ** 2) obj = People('lili', 75, 1.85) print(obj.bmi ) # 触发方法bmi的执行,将obj自动传给self,执行后返回值作为本次引用的结果 # 21.913805697589478 使用property有效的保证了属性访问的一致性 class Foo: def __init__(self, val): self.__NAME = val # 将属性隐藏起来 @property def name(self): return self.__NAME @name.setter def name(self, value): if not isinstance(value, str): # 在设定值之前进行类型检查 print('%s must be str' %value) return self.__NAME = value # 通过类型检查后,将值value存放到真实的位置self.__NAME @name.deleter def name(self): print('Can not delete') f = Foo('lili') f.name # lili f.name = 'LiLi' # 触发name.setter装饰器对应的函数name(f,’Egon') f.name = 123 # 触发name.setter对应的的函数name(f,123),抛出异常TypeError del f.name # 触发name.deleter对应的函数name(f),抛出异常PermissionError
继承
https://www.cnblogs.com/ZhZhang12138/p/14261563.html#yifengzhuang
1、继承介绍
继承是创建新类的一种方式
新建的类称之为子类或派生类
被继承的类称之为父类,基类,超类
继承的特点:
子类可以遗传父类的属性
通过类的内置属性__bases__可以查看类继承的所有父类
2、继承与抽象
要找出类与类之间的继承关系,需要先抽象,再继承。抽象即总结相似之处,总结对象之间的相似之处得到类,总结类与类之间的相似之处就可以得到父类,如下图所示
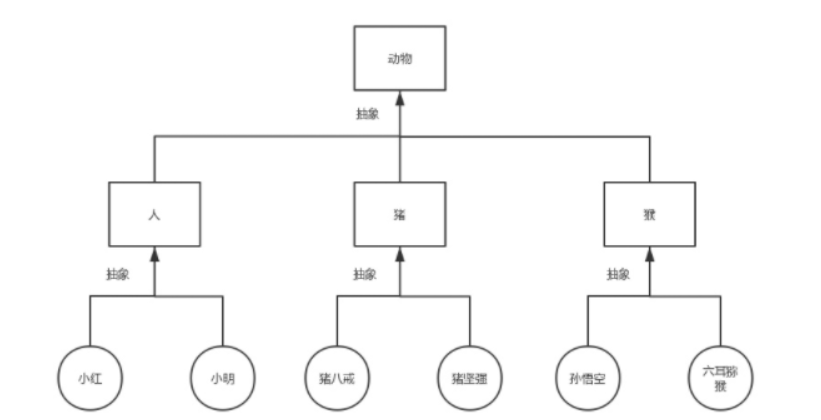
基于抽象的结果,我们就找到了继承关系

基于上图我们可以看出类与类之间的继承指的是什么’是’什么的关系(比如人类,猪类,猴类都是动物类)。
子类可以继承/遗传父类所有的属性,因而继承可以用来解决类与类之间的代码重用性问题。
3、属性查找
有了继承关系,对象在查找属性时,先从对象自己的__dict__中找,如果没有则去子类中找,然后再去父类中找……
>>> class Foo: ... def f1(self): ... print('Foo.f1') ... def f2(self): ... print('Foo.f2') ... self.f1() ... >>> class Bar(Foo): ... def f1(self): ... print('Foo.f1') ... >>> b=Bar() >>> b.f2() Foo.f2 Foo.f1 """ b.f2()会在父类Foo中找到f2,先打印Foo.f2,然后执行到self.f1(),即b.f1(),仍会按照:对象本身->类Bar->父类Foo的顺序依次找下去,在类Bar中找到f1,因而打印结果为Foo.f1 """
父类如果不想让子类覆盖自己的方法,可以采用双下划线开头的方式将方法设置为私有的。
>>> class Foo: ... def __f1(self): # 变形为_Foo__fa ... print('Foo.f1') ... def f2(self): ... print('Foo.f2') ... self.__f1() # 变形为self._Foo__fa,因而只会调用自己所在的类中的方法 ... >>> class Bar(Foo): ... def __f1(self): # 变形为_Bar__f1 ... print('Foo.f1') ... >>> >>> b=Bar() >>> b.f2() #在父类中找到f2方法,进而调用b._Foo__f1()方法,同样是在父类中找到该方法 Foo.f2 Foo.f1
4、继承的应用
class Student: school = '虹桥校区' def __init__(self, name, age, gender): self.name = name self.age = age self.gender = gender def choose(self): print('%s 选课成功' % self.name) stu1 = Student('jack', 18, 'mael') stu2 = Student('tom', 23, 'mael') stu3 = Student('lili', 28, 'femael') class Teacher: school = '虹桥校区' def __init__(self, name, age, gender, level): self.name = name self.age = age self.gender = gender self.level = level def score(self): print('%s 正在为学生打分' % self.name) teal1 = Teacher('egon', 18, 'male', 10) teal2 = Teacher('lxx', 28, 'female', 3)
很明显子类Teacher中init内的前三行又是在写重复代码,若想在子类派生出的方法内重用父类的功能,有两种实现方式:
class Base: school = '虹桥校区' def __init__(self, name, age, gender): self.name = name self.age = age self.gender = gender # 方法一:“指名道姓”地调用某一个类的函数 class Student(Base): school = '虹桥校区' def __init__(self, name, age, gender): Base.__init__(self,name, age, gender) # #调用的是函数,因而需要传入self def choose(self): print('%s 选课成功' % self.name) # 方法二:super() # 调用super()会得到一个特殊的对象, # 该对象专门用来引用父类的属性, # 且严格按照MRO规定的顺序向后查找 class Teacher(Base): school = '虹桥校区' def __init__(self, name, age, gender, level): super().__init__(name, age, gender) # #调用的是绑定方法,自动传入self self.level = level def score(self): print('%s 正在为学生打分' % self.name) stu1 = Student('jack', 18, 'mael') stu2 = Student('tom', 23, 'mael') stu3 = Student('lili', 28, 'femael') teal1 = Teacher('egon', 18, 'male', 10) teal2 = Teacher('lxx', 28, 'female', 3)
5、菱形问题

A类在顶部,B类和C类分别位于其下方,D类在底部将两者连接在一起形成菱形。 这种继承结构下导致的问题称之为菱形问题:如果A中有一个方法,B和/或C都重写了该方法,而D没有重写它,那么D继承的是哪个版本的方法:B的还是C的?如下所示 class A(object): def test(self): print('from A') class B(A): def test(self): print('from B') class C(A): def test(self): print('from C') class D(B,C): pass obj = D() obj.test() # 结果为:from B
要想搞明白obj.test()是如何找到方法test的,需要了解python的继承实现原理
6、继承原理
MRO方法
""" python到底是如何实现继承的呢? 对于你定义的每一个类,Python都会计算出一个方法解析顺序(MRO)列表,该MRO列表就是一个简单的所有基类的线性顺序列表,如下 """
>>> D.mro() # 新式类内置了mro方法可以查看线性列表的内容,经典类没有该内置该方法 [<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。 而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
""" 1.子类会先于父类被检查 2.多个父类会根据它们在列表中的顺序被检查 3.如果对下一个类存在两个合法的选择,选择第一个父类 """
PS:
1.由对象发起的属性查找,会从对象自身的属性里检索,没有则会按照对象的类.mro()规定的顺序依次找下去,
2.由类发起的属性查找,会按照当前类.mro()规定的顺序依次找下去,
7、继承顺序
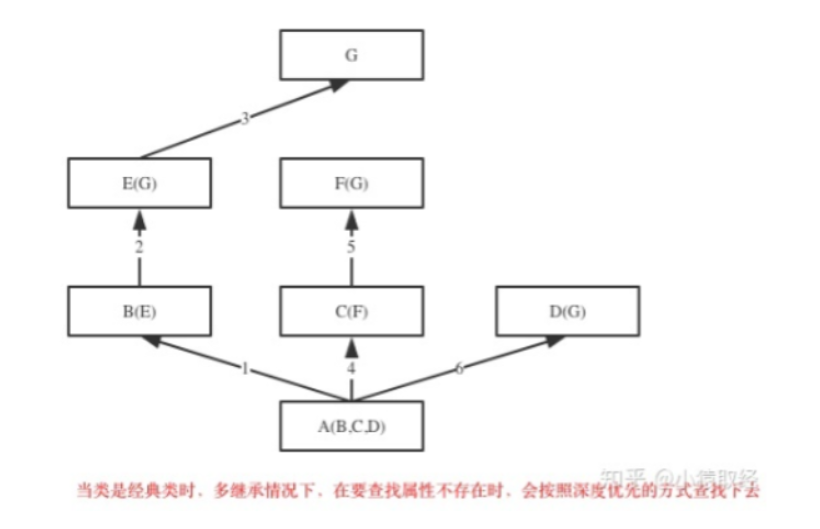
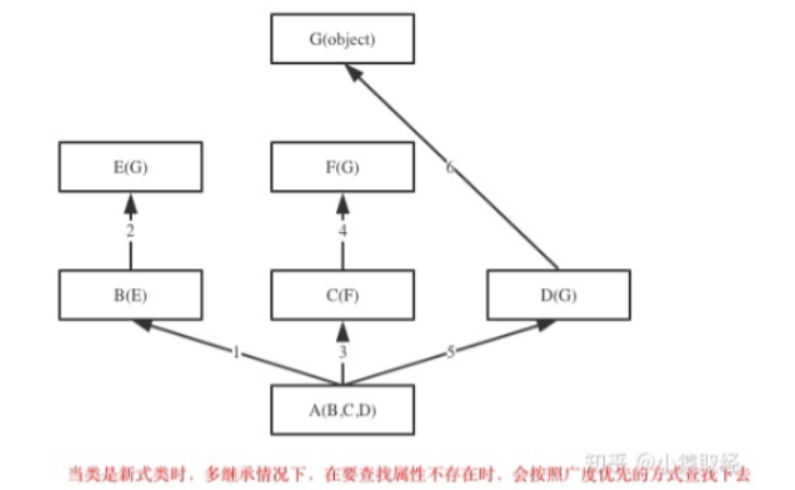
""" 在Python2中有经典类与新式类之分,没有显式地继承object类的类,以及该类的子类,都是经典类,显式地继承object的类,以及该类的子类,都是新式类。 Python3中,即使没有显式地继承object,也会默认继承该类 """ 如果继承关系为菱形结构,那么经典类与新式类会有不同MRO,分别对应属性的两种查找方式:深度优先和广度优先。 菱形继承/死亡钻石:一个子类继承的多条分支最终汇聚到一个非object的类上
经典类:深度优先
新式类:广度优先
即使没有直接继承关系,super仍然会按照mro继续往后查找
#A没有继承B,但是A内super会基于C.mro()继续往后找 class A: def test(self): super().test() class B: def test(self): print('from B') class C(A,B): pass c=C() c.test() #打印结果:from B print(C.mro()) #[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>]
注意
""" 当你使用super()函数时,Python会在MRO列表上继续搜索下一个类。 只要每个重定义的方法统一使用super()并只调用它一次,那么控制流最终会遍历完整个MRO列表, 每个方法也只会被调用一次 (注意注意注意:使用super调用的所有属性,都是从MRO列表当前的位置往后找, 千万不要通过看代码去找继承关系,一定要看MRO列表) """
8、python Minins机制
Python提供了Mixins机制,简单来说Mixins机制指的是子类混合(mixin)不同类的功能,而这些类采用统一的命名规范(例如Mixin后缀),以此标识这些类只是用来混合功能的,并不是用来标识子类的从属"is-a"关系的,所以Mixins机制本质仍是多继承,但同样遵守”is-a”关系。
class Vehicle: # 交通工具 pass class FlyableMixin: def fly(self): ''' 飞行功能相应的代码 ''' print("I am flying") class CivilAircraft(FlyableMixin, Vehicle): # 民航飞机 pass class Helicopter(FlyableMixin, Vehicle): # 直升飞机 pass class Car(Vehicle): # 汽车 pass # ps: 采用某种规范(如命名规范)来解决具体的问题是python惯用的套路
"""
可以看到,上面的CivilAircraft、Helicopter类实现了多继承,不过它继承的第一个类我们起名为FlyableMixin,而不是Flyable,
这个并不影响功能,但是会告诉后来读代码的人,这个类是一个Mixin类,表示混入(mix-in),
这种命名方式就是用来明确地告诉别人(python语言惯用的手法),
这个类是作为功能添加到子类中,而不是作为父类,它的作用同Java中的接口。
所以从含义上理解,CivilAircraft、Helicopter类都只是一个Vehicle,而不是一个飞行器。 """
-
首先它必须表示某一种功能,而不是某个物品,python 对于mixin类的命名方式一般以 Mixin, able, ible 为后缀
-
其次它必须责任单一,如果有多个功能,那就写多个Mixin类,一个类可以继承多个Mixin,为了保证遵循继承的“is-a”原则,只能继承一个标识其归属含义的父类
-
然后,它不依赖于子类的实现
-
最后,子类即便没有继承这个Mixin类,也照样可以工作,就是缺少了某个功能。(比如飞机照样可以载客,就是不能飞了)
9、派生与方法重用
子类可以派生出自己新的属性,在进行属性查找时,子类中的属性名会优先于父类被查找,例如每个老师还有职称这一属性,我们就需要在Teacher类中定义该类自己的__init__覆盖父类的
>>> class People: ... school='清华大学' ... ... def __init__(self,name,sex,age): ... self.name=name ... self.sex=sex ... self.age=age ... >>> class Teacher(People): ... def __init__(self,name,sex,age,title): # 派生 ... self.name=name ... self.sex=sex ... self.age=age ... self.title=title ... def teach(self): ... print('%s is teaching' %self.name) ... >>> obj=Teacher('lili','female',28,'高级讲师') #只会找自己类中的__init__,并不会自动调用父类的 >>> obj.name,obj.sex,obj.age,obj.title ('lili', 'female', 28, '高级讲师')
>>> class Teacher(People): ... def __init__(self,name,sex,age,title): ... People.__init__(self,name,age,sex) #调用的是函数,因而需要传入self ... self.title=title ... def teach(self): ... print('%s is teaching' %self.name)
""" 调用super()会得到一个特殊的对象,该对象专门用来引用父类的属性,且严格按照MRO规定的顺序向后查找 """
>>> class Teacher(People): ... def __init__(self,name,sex,age,title): ... super().__init__(name,age,sex) #调用的是绑定方法,自动传入self ... self.title=title ... def teach(self): ... print('%s is teaching' %self.name)
""" 在Python2中super的使用需要完整地写成super(自己的类名,self) ,而在python3中可以简写为super()。 """
""" 方式一是跟继承没有关系的,而方式二的super()是依赖于继承的,并且即使没有直接继承关系,super()仍然会按照MRO继续往后查找 """
>>> #A没有继承B ... class A: ... def test(self): ... super().test() ... >>> class B: ... def test(self): ... print('from B') ... >>> class C(A,B): ... pass ... >>> C.mro() # 在代码层面A并不是B的子类,但从MRO列表来看,属性查找时,就是按照顺序C->A->B->object,B就相当于A的“父类” [<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>,<class ‘object'>] >>> obj=C() >>> obj.test() # 属性查找的发起者是类C的对象obj,所以中途发生的属性查找都是参照C.mro() from B
10、组合
""" 在一个类中以另外一个类的对象作为数据属性,称为类的组合。组合与继承都是用来解决代码的重用性问题。
不同的是:继承是一种“是”的关系,比如老师是人、学生是人,当类之间有很多相同的之处,应该使用继承;
而组合则是一种“有”的关系,
比如老师有生日,老师有多门课程,当类之间有显著不同,并且较小的类是较大的类所需要的组件时,应该使用组合,如下示例 """
class Course: def __init__(self,name,period,price): self.name=name self.period=period self.price=price def tell_info(self): print('<%s %s %s>' %(self.name,self.period,self.price)) class Date: def __init__(self,year,mon,day): self.year=year self.mon=mon self.day=day def tell_birth(self): print('<%s-%s-%s>' %(self.year,self.mon,self.day)) class People: school='清华大学' def __init__(self,name,sex,age): self.name=name self.sex=sex self.age=age #Teacher类基于继承来重用People的代码,基于组合来重用Date类和Course类的代码 class Teacher(People): #老师是人 def __init__(self,name,sex,age,title,year,mon,day): super().__init__(name,age,sex) self.birth=Date(year,mon,day) #老师有生日 self.courses=[] #老师有课程,可以在实例化后,往该列表中添加Course类的对象 def teach(self): print('%s is teaching' %self.name) python=Course('python','3mons',3000.0) linux=Course('linux','5mons',5000.0) teacher1=Teacher('lili','female',28,'博士生导师',1990,3,23) # teacher1有两门课程 teacher1.courses.append(python) teacher1.courses.append(linux) # 重用Date类的功能 teacher1.birth.tell_birth() # 重用Course类的功能 for obj in teacher1.courses: obj.tell_info() 此时对象teacher1集对象独有的属性、Teacher类中的内容、Course类中的内容于一身(都可以访问到),是一个高度整合的产物
多态
1、多态
""" 多态指的是一类事物有多种形态 动物有多种形态:人,狗,猪 文件有多种形态:文本文件,可执行文件 """
import abc class Animal(metaclass=abc.ABCMeta): #同一类事物:动物 @abc.abstractmethod def talk(self): pass class People(Animal): #动物的形态之一:人 def talk(self): print('say hello') class Dog(Animal): #动物的形态之二:狗 def talk(self): print('say wangwang') class Pig(Animal): #动物的形态之三:猪 def talk(self): print('say aoao')
import abc class File(metaclass=abc.ABCMeta): #同一类事物:文件 @abc.abstractmethod def click(self): pass class Text(File): #文件的形态之一:文本文件 def click(self): print('open file') class ExeFile(File): #文件的形态之二:可执行文件 def click(self): print('execute file')
2、多态性
多态性是指在不考虑实例类型的情况下使用实例 """ 在面向对象方法中一般是这样表述多态性:向不同的对象发送同一条消息(!!!obj.func():是调用了obj的方法func,又称为向obj发送了一条消息func),
不同的对象在接收时会产生不同的行为(即方法)。也就是说,每个对象可以用自己的方式去响应共同的消息。所谓消息,就是调用函数,不同的行为就是指不同的实现,即执行不同的函数。 比如:老师.下课铃响了(),学生.下课铃响了(),老师执行的是下班操作,学生执行的是放学操作,虽然二者消息一样,但是执行的效果不同 """
多态性分为静态多态性与动态多态性
静态多态性:如任何类型都可以用运算符+进行运算
动态多态性:如下
peo=People() dog=Dog() pig=Pig() #peo、dog、pig都是动物,只要是动物肯定有talk方法 #于是我们可以不用考虑它们三者的具体是什么类型,而直接使用 peo.talk() dog.talk() pig.talk() #更进一步,我们可以定义一个统一的接口来使用 def func(obj): obj.talk()
1.增加了程序的灵活性 以不变应万变,不论对象千变万化,使用者都是同一种形式去调用,如func(animal) 2.增加了程序额可扩展性 通过继承animal类创建了一个新的类,使用者无需更改自己的代码,还是用func(animal)去调用
""" Python崇尚鸭子类型,即‘如果看起来像、叫声像而且走起路来像鸭子,那么它就是鸭子’ python程序员通常根据这种行为来编写程序。例如,如果想编写现有对象的自定义版本,可以继承该对象 也可以创建一个外观和行为像,但与它无任何关系的全新对象,后者通常用于保存程序组件的松耦合度。 """
#二者看起来都像文件,因而就可以当文件一样去用,然而它们并没有直接的关系 class Txt: #Txt类有两个与文件类型同名的方法,即read和write def read(self): pass def write(self): pass class Disk: #Disk类也有两个与文件类型同名的方法:read和write def read(self): pass def write(self): pass
绑定方法和非绑定方法
""" 类中定义的函数分为两大类:绑定方法和非绑定方法 其中绑定方法又分为绑定到对象的对象方法和绑定到类的类方法。 """
""" 在类中正常定义的函数默认是绑定到对象的,而为某个函数加上装饰器@classmethod后,该函数就绑定到了类。 """
""" 为类中某个函数加上装饰器@staticmethod后,该函数就变成了非绑定方法,也称为静态方法。该方法不与类或对象绑定,类与对象都可以来调用它,但它就是一个普通函数而已,因而没有自动传值那么一说。 """
""" 绑定方法: 特点:绑定给谁就应该由谁来调用,谁来调用就会将自己当做第一个参数传入 非绑定方法: 特点:不与类和对象绑定,意味着谁都可以来调用,但是无论谁来调用就是一个普通函数,没有自动传参的效果 """
class People: def __init__(self,name): self.name = name # 但凡在类中定义一个函数,默认就是绑定给对象的,应该由对象来调用 # 会将对象当做第一个参数自动传入 def tell(self): print(self.name) # 类中定义的函数被classmothod装饰过,就绑定给类,应该由类来调用 # 类来调用就会将类当做第一个参数自动传入 @classmethod def f1(cls): print(cls) # 类中定义的函数被staticmethod装饰过,就成一个非绑定的方法,即一个普通函数,谁都可以调用 # 无论谁来调用就是一个普通函数,没有自动传参的效果 @staticmethod def f2(x,y): pass p1 = People('egon') p1.tell() p2 = People.f1() # <class '__main__.People'> p1.f2(1,2) People.f2(1,2)
总结
绑定方法与非绑定方法的使用:
若类中需要一个功能,该功能的实现代码中需要引用对象则将其定义成对象方法、需要引用类则将其定义成类方法、无需引用类或对象则将其定义成静态方法。
异常处理
1、什么是异常
异常是程序发生错误的信号。程序一旦出现错误,便会产生一个异常,若程序中没有处理它,就会抛出该异常,程序的运行也随之终止。在Python中,错误触发的异常如下:
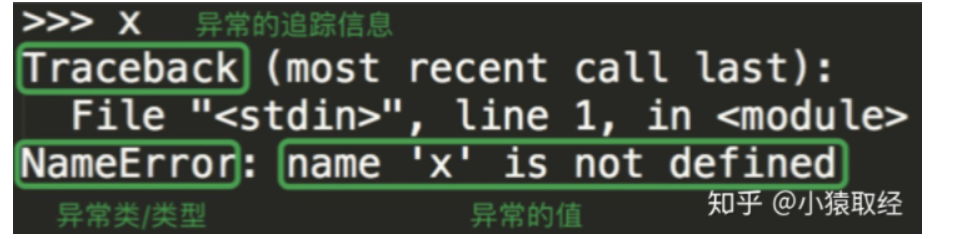
语法错误
""" 一种是语法上的错误SyntaxError,这种错误应该在程序运行前就修改正确 """ >>> if File "<stdin>", line 1 if ^ SyntaxError: invalid syntax
逻辑错误
""" 常见的逻辑错误: """ # TypeError:数字类型无法与字符串类型相加 1+’2’ # ValueError:当字符串包含有非数字的值时,无法转成int类型 num=input(">>: ") #输入hello int(num) # NameError:引用了一个不存在的名字x x # IndexError:索引超出列表的限制 l=['egon','aa'] l[3] # KeyError:引用了一个不存在的key dic={'name':'egon'} dic['age'] # AttributeError:引用的属性不存在 class Foo: pass Foo.x # ZeroDivisionError:除数不能为0 1/0
2、异常处理
为了保证程序的容错性与可靠性,即在遇到错误时有相应的处理机制不会任由程序崩溃掉,我们需要对异常进行处理,处理的基本形式为
try: 被检测的代码块 except 异常类型: 检测到异常,就执行这个位置的逻辑
try: 被检测的代码块 except 异常类型1: pass except 异常类型2: pass ...... else: 没有异常发生时执行的代码块
3、何时使用异常处理
""" 在了解了异常处理机制后,本着提高程序容错性和可靠性的目的,读者可能会错误地认为应该尽可能多地为程序加上try...except...,这其是在过度消费程序的可读性,
因为try...except本来就是你附加给程序的一种额外的逻辑,与你的主要工作是没有多大关系的。 """
可预知的
""" 如果错误发生的条件是“可预知的”,我们应该用if来进行”预防”,如下 """ age=input('input your age>>: ').strip() if age.isdigit(): # 可预知只有满足字符串age是数字的条件,int(age)才不会触发异常, age=int(age) else: print('You must enter the number')
不可预知的
""" 如果错误发生的条件“不可预知”,即异常一定会触发,那么我们才应该使用try...except语句来处理。例如我们编写一个下载网页内容的功能,
网络发生延迟之类的异常是很正常的事,而我们根本无法预知在满足什么条件的情况下才会出现延迟,因而只能用异常处理机制了 """ import requests from requests.exceptions import ConnectTimeout # 导入requests模块内自定义的异常 def get(url): try: response=requests.get(url,timeout=3)#超过3秒未下载成功则触发ConnectTimeout异常 res=response.text except ConnectTimeout: print('连接请求超时') res=None except Exception: print('网络出现其他异常') res=None return res get('https://www.python.org')
4、扩展
# 断言 l = [111,222,333] assert len(l) == 3 # 不满足条件则抛出异常 print('执行后续代码') # raise raise IndexError('索引错误') # 主动抛出异常 # 自定义异常 class Permission(BaseException): pass raise Permission('权限错误') ''' Traceback (most recent call last): File "E:\PYTHON\pycharm project\project\day21\异常处理.py", line 14, in <module> raise Permission('权限错误') __main__.Permission: 权限错误 '''

